
云数据中心高效的虚拟机整合方法
2018-04-12 07:16喻新荣李志华闫成雨李双俐
计算机应用 2018年2期
喻新荣,李志华,2,闫成雨,李双俐
(1.江南大学 物联网工程学院,江苏 无锡 214122; 2.物联网应用技术教育部工程研究中心(江南大学),江苏 无锡 214122)(*通信作者电子邮箱wxzhli@aliyun.com)
0 引言
云计算是一种新兴的计算模式,它通过互联网为全球提供可扩展、按需供应的服务[1],但是,云计算的广泛使用使得数据中心的能源消耗不断攀升[2]。而在整个数据中心,物理主机的能源消耗最为突出,其能耗与CPU的利用率近似呈线性关系[3],且空闲状态的主机能耗相当于其能耗峰值的70%,因此,如何减少低利用率物理主机,同时保持良好的系统性能,是数据中心亟待解决的问题之一[4]。虚拟机整合(Virtual Machine Consolidation, VMC)通过在单个主机上部署多个虚拟机,提高主机CPU的利用率并关闭低利用率主机,从而降低数据中心的能源消耗[5];同时,周期性的整合能够及时调整虚拟机和主机的映射关系,缓解由于虚拟机资源请求变化导致的主机过载风险,从而提升数据中心的服务质量(Quality of Service, QoS)。但是,虚拟机整合是一个NP问题[6],难以在多项式时间内求解,因此,文献[7]将整合问题进行分解,通过解决过载物理主机检测、待迁移虚拟机选择、迁移虚拟机放置以及活动物理主机规模收缩四个子问题来整合虚拟机。
文献[7]提出了静态阈值(Static Threshold, ST)算法进行过载物理主机检测,该算法通过给活动物理主机设置CPU资源利用率的上限和下限,来确保所有活动物理主机处于一个相对合理的资源利用率区间。然而,虚拟机的资源需求具有随机性,设置固定的阈值难以适应各活动物理主机的工作负载变化,使得确保服务质量和节约能耗无法同时兼顾。
针对虚拟机工作负载的随机性,文献[8]提出了自适应主机过载检测算法,包括绝对中位偏差(Median Absolute Deviation, MAD)算法、四分位距 (InterQuartile Range, IQR)算法和局部回归 (Local Regression, LR)算法。其中,前两个算法分别通过主机近期CPU资源利用率的绝对中位偏差和四分位距来确定主机上资源请求的波动区间,根据波动区间自适应地调整主机当前的过载阈值并用于过载检测;LR算法通过主机CPU资源利用率历史记录直接预测下一时刻的资源利用率,然后根据资源利用率预测值判断主机是否过载。同时,文献[8]还提出了最小迁移时间(Minimum Migration Time, MMT)、随机选择(Random Choice, RC)和最大相关 (Maximum Correlation, MC)三个虚拟机选择算法以及用于放置虚拟机的能耗感知最适降序(Power Aware Best Fit Decreasing, PABFD)算法。通过组合不同的过载检测算法和选择策略进行对比研究,证实使用MAD与MMT相结合的整合方法能够有效地降低数据中心能耗并且确保服务质量;但是,主机负载出现突然性的波动会增大MAD算法的绝对中位偏差,导致过载阈值不精确,进一步影响节约能耗的目标。PABFD算法在放置虚拟机时倾向于将虚拟机部署在资源利用率较高的主机上,容易导致过度的虚拟机整合,从而影响服务质量。
从已有的虚拟机整合方法中发现,精确的工作负载预测对优化整合目标大有裨益。其中,文献[9]使用三次指数平滑算法(Holt-Winters’ exponential smoothing method)对虚拟机负载进行预测,并且针对三次指数平滑法只能进行短期预测这一缺点,提出参数自动优化的模型,该模型能够调整预测模型的参数和设置合理的预测周期长度;文献[10]提出了基于线性回归的CPU资源利用率预测(Linear Regression-based CPU Utilization Prediction, LiRCUP)算法,通过线性回归对主机CPU资源使用情况进行预测,并利用预测结果进行虚拟机整合。虽然上述的两种方法在降低数据中心能耗方面表现优秀,但都未对服务质量进行深入的研究。
本文在以往研究的基础上,提出基于高斯混合模型的虚拟机整合(Gaussian Mixture Model-based Virtual Machine Consolidation, GMM-VMC)方法。该方法首先使用高斯混合模型(Gaussian Mixture Model, GMM)[15]为物理主机建立工作负载的随机模型,通过该模型计算主机的过载概率;然后根据主机过载概率自适应地计算各主机的过载阈值并用于主机过载检测。当过载主机上的虚拟机被选择为待迁移虚拟机时,该主机的过载概率会被重新计算并作为最后迁移选择的依据之一;同样在放置虚拟机时,根据主机负载的高斯混合模型所计算的主机过载概率是确定最终虚拟机放置策略的参考依据。
1 基于GMM的主机过载概率估计
1.1 数据中心相关概念
为了清晰地描述本文观点和论证相关方法,在此对云计算数据中心的一些相关概念进行相应描述。在一个数据中心里有许多不同配置的物理主机H={h1,h2,…,hn},物理主机hi有各自的CPU资源配置,可以表示为Ci;VM={vm1,vm2,…,vmm}是整个数据中心虚拟机的集合,这些虚拟机分别部署在不同的物理主机上,rj表示虚拟机vmjCPU资源请求的容量;VMi表示部署在主机hi上的虚拟机集合。当虚拟机集合VMi部署在主机hi上并产生相应的资源请求,那么主机接收到的CPU资源需求容量Di如式(1)所示,主机的CPU资源利用率如式(2)所示。
(1)
(2)
其中aj表示分配给虚拟机vmj的CPU资源量。
1.2 基于GMM的物理主机随机负载模型
文献[11-14]用正态分布来描述虚拟机上CPU资源请求的分布模型,并通过各自的方法将部署在物理主机上各虚拟机的负载模型进行累加,从而得到主机CPU资源利用率的分布模型,但是,使用单峰正态分布去描述虚拟机资源需求的随机模型不具备通用性,尤其是当实际的资源需求为多峰分布时,正态分布偏差较大,不能完全拟合资源需求的分布情况,因此,由累加虚拟机需求分布得到的物理主机负载分布模型也不够准确。针对这一问题,本文使用高斯混合模型(GMM)对主机的负载分布进行拟合。以下对在主机上建立GMM的具体过程进行描述。
假设主机hi接收到的CPU资源需求Di服从某个随机分布,该分布可用高斯混合模型来近似表示。若高斯混合模型是由K个高斯模型组成,那么Di的概率分布模型如式(3)所示:
(3)
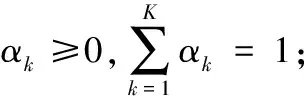
Di的高斯混合模型参数将通过期望最大化(Expectation Maximization, EM)算法来估算,具体步骤如下所示:
步骤1设定高斯混合模型参数的初始值。
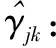
(4)
步骤3通过式(5)~(7)计算新一轮迭代的模型参数:
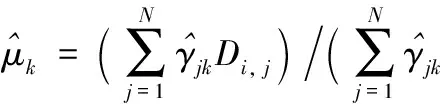
(5)
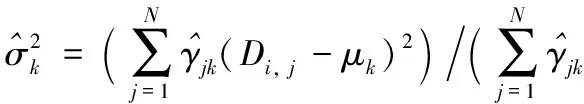
(6)
(7)
步骤4重复以上两个步骤,至模型参数收敛。
1.3 物理主机过载概率估计
主机过载是指虚拟机请求的资源量超出了物理主机所能提供的最大资源量,从而导致虚拟机资源请求不能够被满足而影响云服务质量的情况。结合1.2节介绍的随机负载模型,可以对物理主机的过载概率进行估计,过载概率如式(8)所示。通过主机过载概率可以反映出当前该主机面临过载风险的大小:当过载风险较大时,整合方法应使主机预留充足的资源应对负载变化,从而确保服务质量;当过载风险较小时,主机的资源利用率应适当提高,从而达到降低数据中心能耗的目的。
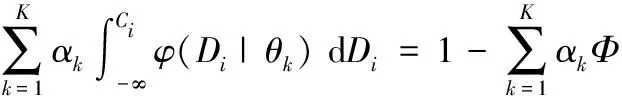
(8)
2 基于随机负载模型的虚拟机整合方法
2.1 主机过载检测算法
由于数据中心的工作负载具有随机性,活动物理主机经常面临过载风险。一旦主机过载,就会对服务质量和服务等级协议(Service Level Agreement, SLA)产生影响,因此,在进行虚拟机整合时,及时预测主机的负载变化,有利于主机规避过载风险,确保云计算供应商和用户双方的利益。
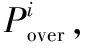
(9)
GAOHD算法描述如下。
算法1GAOHD算法。
输入H;
输出Hover。
步骤1获取数据中心各物理主机H={h1,h2,…,hn},并按照当前的顺序,对每个主机进行步骤2到步骤4的过载检测。
步骤2使用EM算法估算主机hi的GMM参数。
步骤4将主机当前的CPU资源利用率ui和过载阈值Ti进行对比,如果ui>Ti,则将主机hi加入到过载主机集合中。
步骤5输出过载物理主机集合Hover并结束。
GAOHD算法的时间开销主要来自于过载阈值的求解,而要计算过载阈值需要首先确定主机负载的高斯混合模型参数。因为使用EM算法求解GMM参数的时间复杂度为O(ρ·K·N),所以GAOHD算法的时间复杂度为O(ρ·K·N·|Hactive|)。其中:ρ为EM算法迭代次数,K为高斯混合模型中分模型的个数,N为观测数据长度,|Hactive|为数据中心需要进行过载检测的活动物理主机数量。最初的ST检测算法求解主机过载阈值的时间复杂度为O(|Hactive|),但是ST算法在整合开始时为所有物理主机设定统一的固定过载阈值,无法根据主机负载对检测过程作出调整,难以适应主机负载的变化。为克服固定阈值的缺陷,基于自适应阈值的过载检测算法被提出,其中最为经典的MAD算法的时间复杂度为O(N·|Hactive|)。与MAD相比,GAOHD算法的复杂度明显偏高,但是MAD算法在追求快速运算的同时也忽略了对主机负载的准确预测,这一点从3.3节的实验结果部分可以看出,因此,GAOHD算法的目的是在合理的运算时间内,尽可能准确地预测主机负载变化。
2.2 虚拟机选择算法
物理主机的过载会给云服务的使用者和提供商的利益带来影响,因此,解决物理主机过载就成为虚拟机整合过程中重要的部分。通常,解决过载的方式是将一些虚拟机从面临过载风险或已经过载的主机上迁出,缓解当前主机上资源紧张的状态。在进行待迁移虚拟机选择时,需要考虑到迁移操作将会影响迁移中虚拟机的服务质量,同时也要兼顾迁移的有效性即迁移选择应有助于当前主机保持长期的稳定。
本文在MMT选择算法的基础上结合主机过载概率,提出最低内存容量和过载概率选择(Minimum RAM and Overload Probability Selection, MROPS)算法来进行虚拟机选择。该算法通过内存和过载概率综合指标(Ram and Probability, RAP)进行虚拟机选择:
(10)
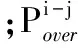
(11)
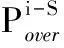
MROPS算法描述如下。
算法2MROPS算法。
输入Hover;
输出VMa。
步骤1获取过载物理主机的集合Hover,并按照当前的顺序对每个主机hi∈Hover进行步骤2到步骤3的虚拟机选择。
步骤2使用式(10)得到主机hi上迁出后的RAP指标,然后根据式(12)选择出该指标最小的虚拟机:
(12)
并将vmmig加入当前主机的待迁移虚拟机集合VMS中。
步骤3判断当前主机是否满足式(11),如果不满足则继续对当前主机执行步骤2;否则,将当前主机的待迁移虚拟机集合VMS加入到所有待迁移虚拟机集合VMa中,然后对下一个主机进行虚拟机选择。
步骤4输出所有待迁移虚拟机集合VMa并结束。
MMT算法在进行虚拟机选择时,主要参考虚拟机内存的大小,采用该算法能够确保主机负载的稳定性。MMT算法的时间复杂度为O(|VMi|),其中|VMi|为主机上虚拟机的个数。MROPS算法在MMT算法的基础上加入主机过载概率作为虚拟机选择的参考指标,根据上一节对过载概率求解的分析,MROPS算法的时间复杂为O(ρ·K·N·|VMi|),MROPS算法虽然时间复杂度偏高,但是在降低整合过程中虚拟机的迁移次数和稳定主机负载方面比MMT算法表现优秀,具体的对比见3.3节。
2.3 虚拟机放置算法
待迁移虚拟机需要迁移到新的目的主机继续运行,当虚拟机部署到目的主机上,该主机的资源需求必然发生变化,过载风险随之提高,因此,合理的放置策略是在尽量降低主机过载风险的前提下提升主机资源利用率。
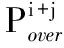
具体MOPP算法描述如下。
算法3MOPP算法。
输入Ha,VMa;
输出Map〈host,vm〉。
步骤1获取适合放置虚拟机的活动物理主机集合Ha∈{H-Hover-Hs}(Hs为处于休眠或关闭状态的虚拟机集合)。
步骤2对待分配虚拟机按资源请求降序排列,并对集合中的每一个虚拟机进行步骤3到步骤5的放置步骤。
步骤3将待迁移虚拟机vmj(vmj∈VMa)依次部署在Ha的各个主机上,并根据式(8)求得放置后各主机的过载概率。
步骤4根据式(13)选择最优的主机进行放置:
(13)
步骤5将当前求得的分配关系加入到分配映射集合Map〈host,vm〉中。
步骤6输出待分配虚拟机新的放置关系集合。
MOPP算法与经典的PABFD算法有着明显的不同。PABFD主要关注能耗增量,时间复杂度为O(|VMa|·|Ha|),其中:|VMa|为待放置虚拟机数量,|Ha|为适合放置的活动物理主机数量。而MOPP算法关注的是虚拟机重新部署后主机的稳定性,其时间复杂度为O(|VMa|·|Ha|·ρ·K·N),主要体现在计算放置虚拟机后主机负载的高斯混合模型,并求得当前的过载概率用于新目的主机的挑选。虽然PABFD算法的时间复杂度较低但是在稳定主机负载方面不如MOPP算法;而MOPP算法通过更复杂的计算判断放置后的主机稳定性,从而确保充分利用主机资源,降低数据中心能源消耗。
2.4 活动物理主机规模收缩
由于数据中心工作负载的不确定性,活动物理主机不仅可能出现过载状况,也有可能出现主机CPU资源利用率偏低的情况,这就容易导致资源浪费,因此,通过迁移低负载物理主机上的所有虚拟机并关闭该主机,以此来提高活动物理主机的CPU资源利用率,从而达到节约能耗的目的。所以在收缩活动物理主机规模时,首先挑选CPU资源利用率最低的物理主机,尝试将该主机上所有的虚拟机都迁移出去,并且使用MOPP算法放置到合适的目的主机上。如果该主机上所有的虚拟机都能被合理地放置,就说明该主机可以被关闭。循环执行上述步骤,直到当前数据中心中的物理主机都不能迁出全部虚拟机为止。
2.5 GMM-VMC方法及分析
结合前文提出的GAOHD、MROPS、MOPP算法以及活动物理主机规模收缩的过程,提出了GMM-VMC方法,该方法主要包括四个执行过程:首先,使用GAOHD算法检测出当前数据中心存在过载风险的物理主机;然后,使用MROPS算法从过载主机中选出待迁移虚拟机,解除主机过载风险;接着,使用MOPP算法将待分配的虚拟机集合放入合适的活动物理主机;最后,通过收缩活动物理主机规模减少整个数据中心活动物理主机的数量。
具体的GMM-VMC方法描述如下。
步骤1使用GAOHD算法得到过载物理主机集合。具体步骤为:首先采用高斯混合模型对各活动物理主机的工作负载进行拟合,得到的各个高斯混合模型能够准确地描述对应主机的近期负载变化;然后根据高斯混合模型计算相应的过载概率,通过过载概率求得自适应的主机过载阈值;最后根据主机当前的过载阈值进行过载检测。与ST算法相比,GAOHD算法采用自适应的阈值计算法方式,能够及时适应主机负载变化,对虚拟机整合过程进行调整。MAD、IQR和LR算法虽然也采用自适应的阈值计算方式,但是在对主机负载的描述方面远远没有高斯混合模型精确。通过高斯混合模型对主机负载的准确预测能确保主机长时间的稳定,从而对整合方法的服务质量指标有相当大的提升。
步骤2使用MROPS算法对每个过载物理主机进行虚拟机选择,并得到待迁移虚拟机集合。MROPS算法在虚拟机选择的过程中加入主机过载概率作为选择依据,优先选择迁移后主机工作负载更加稳定的虚拟机。所以,MROPS算法比MMT、RC、MC等虚拟机选择算法更加有利于数据中心活动物理主机的负载稳定,能够相应地提升服务质量。
步骤3使用MOPP算法将待分配虚拟机放入合适的物理主机。MOPP算法在为虚拟机进行新的目的主机挑选时,注重放置后主机工作负载的稳定性,避免了PABFD算法因追求低能耗带来的过度整合。由于MOPP算法提升了主机负载的稳定性,所以在整合过程中主机不要预留过多的资源应对负载的突然变化,从而可以更加充分地利用主机资源,降低数据中心的能源消耗。
步骤4进行活动物理主机规模收缩。该过程通过将低负载主机上的虚拟机重新部署到其他主机上,提升整个数据中心的主机资源利用率。在重新部署时,用高斯混合模型预测放置后的主机负载,以确保服务质量不受到影响。
步骤5结束。
3 实验结果及分析
3.1 实验环境
本文使用CloudSim[16]作为实验平台,该平台由CLOUDBUS实验室所研发,是当今研究虚拟机整合的主要仿真工具之一。平台包含了CoMon项目中PlanetLab研究的相关数据,其中有超过1 300台虚拟机在10 d运行过程中的CPU资源利用率记录。
在模拟整合过程中,数据中心将创建800台物理主机。这些物理主机的型号为:HP ProLiant ML110 G4(Intel Xeon 3040 2cores 1 860 MHz, 4 GB)与HP ProLiant ML110 G5(Intel Xeon 3075 2cores 2 260 MHz, 4 GB)这两种。对应于PlanetLab中某一天每个虚拟机CPU资源利用率记录,数据中心会创建相应个数的虚拟机,这些虚拟机分成多个种类:High-CPU Medium Instance (2 500 MIPS, 0.85 GB)、Extra Large Instance (2 000 MIPS, 3.75 GB)、Small Instance (1 000 MIPS, 1.7 GB)、Micro Instance (500 MIPS, 613 MB)。
3.2 评价指标
为合理、有效地评价GMM-VMC方法的有效性,本文采用了文献[8]提出的评价指标来对各个整合方法进行对比。这些评价指标分别是:数据中心物理主机的能源消耗(Energy Consumption, EC),每个活动物理主机违背SLA的平均时间比(SLA violation Time per Active Host, SLATAH),虚拟机迁移所带来的服务性能下降比例(Performance Degradation due to Migration, PDM),服务等级协议违背率(SLA Violation, SLAV),虚拟机迁移次数Migrations,能耗与服务等级协议违背率综合指标(Energy and SLA Violation, ESV)。
3.3 结果分析
文献[6,8]在CloudSim平台上对虚拟机整合过程进行了深入的研究,并提出相应的算法。其中包括用于虚拟机放置的PABFD,物理主机过载检测检测算法ST、MAD、IQR、LR,虚拟机选择算法MMT、RC、MC。通过将这些算法组合,可以得到12个不同的虚拟机整合方法,每一个整合方法都包含过载检测算法、虚拟机选择算法和放置算法。四种过载检测算法都有各自的安全系数:当安全系数设置得越大,表明过载检测时将注重主机的稳定性以确保服务质量;相反安全系数越小,检测算法就会放弃一些稳定性来追求主机资源的充分利用,以达到节约能源的目的。通过对各检测算的不同安全参数取值进行实验对比,发现将MAD、IQR、LR、ST的安全参数分别设置为2.5,1.5,1.2,0.8时能够让相应的整合方法在节约能耗和保证服务质量方面做到相对的均衡。本文提出的GMM-VMC方法的安全参数设置为2.0,过载阈值上限Tmax设为1,均为经验值。
表1列出了各虚拟机整合方法在能耗和服务质量方面的结果,由于PlanetLab中有10 d的数据,所以在表中列出的是10 d数据仿真结果的均值。通过表1可以对各个方法在EC、SLAV以及ESV指标上进行对比。由表1可以看出:本文提出的GMM-VMC方法在这三个指标中表现都非常优秀;相比其他整合方法,GMM-VMC降低了数据中心的能源消耗,同时在服务质量方面有很大的提升。为作图清晰,图1~3中的各虚拟机整合算法用表1中的序号代替。
图1描述了各个整合方法所对应的虚拟机迁移次数。通过图1对比发现GMM-VMC的迁移次数最少,而且结合表1可知该方法降低迁移次数的同时大幅提升了服务质量。这就说明,根据主机负载模型得到的主机过载阈值设置合理,能有效地提高主机资源利用率,降低数据中心的能耗;该模型使也得主机处于长期稳定的状态。其他算法中,使用MMT作为虚拟机选择算法的整合方法迁移次数比较高,这是因为MMT算法每次选择迁移时间最少的虚拟机,所以解除过载时较其他算法必然需要更多的迁移次数。
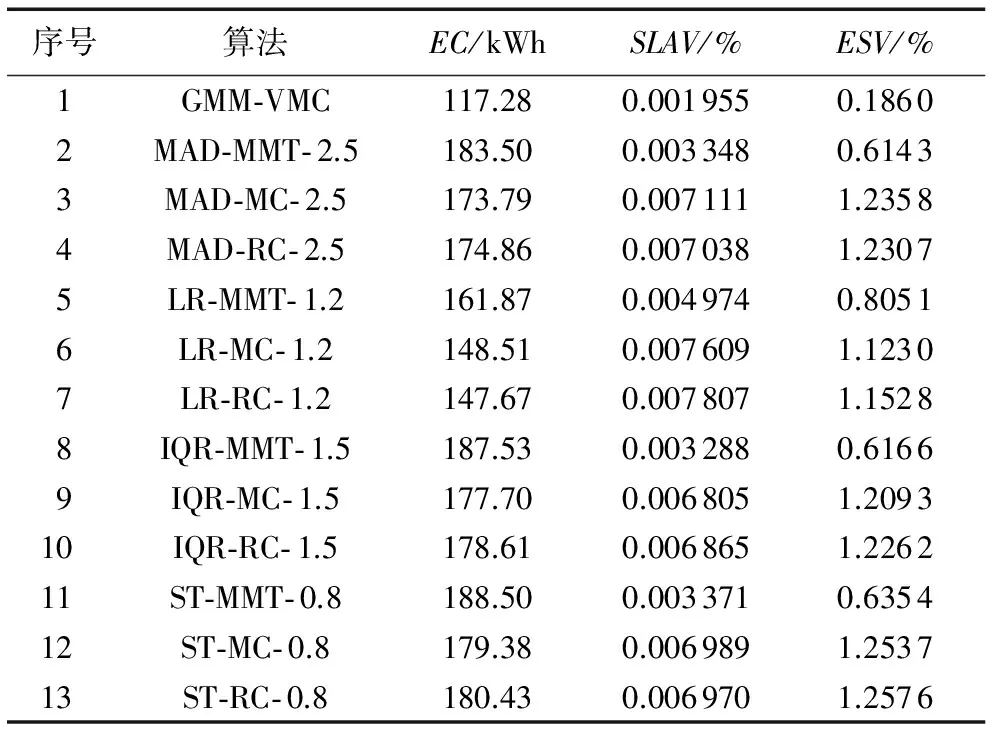
表1 各个算法能耗及服务质量数据Tab. 1 Results of EC and QoS by algorithms
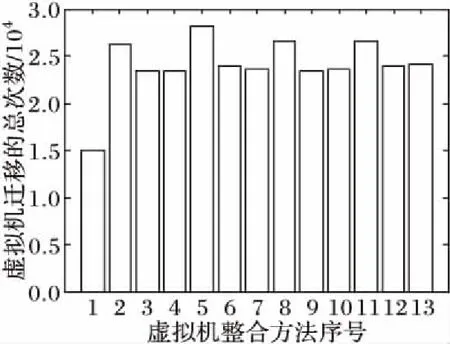
图1 虚拟机迁移次数对比Fig. 1 Comparison of VM migration times
虚拟机从源主机迁移到新的目的主机,必然会对虚拟机所提供的计算服务产生影响。图2对比了各算法在整合过程中由虚拟机迁移产生的PDM。从图2可以看出,使用MMT作为选择算法的整合方法在PDM上低于其他选择算法。根据图1中迁移次数的表现,可知虽然MMT算法虚拟机迁移次数多,但是迁移时间短,所带来的服务质量下降也就少。GMM-VMC方法由于迁移次数少,而且MROPS算法总是选择迁移时间少且迁移后主机过载概率低的主机,所以在PDM这一指标上表现依然优秀。
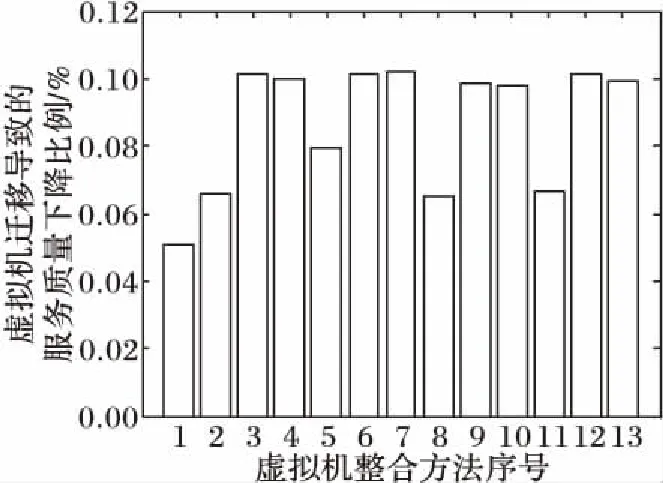
图2 虚拟机迁移引起的服务质量下降对比Fig. 2 Comparison of PDM due to migration
虚拟机整合最主要的目的之一就是确保服务质量,而主机负载稳定则是确保服务质量的首要前提。图3对衡量数据中心主机过载情况的SLATAH指标进行了对比。从图3可以看出,GMM-VMC方法在SLATAH这一指标上领先于其他整合方法。由于GMM-VMC方法对主机工作负载的建模准确度高,通过自适应的过载阈值调整物理主机和虚拟机之间的映射关系,所以过载情况大量减少。而使用MMT作为选择算法的整合方法在解除主机过载风险时迁移较多的虚拟机,所以使得主机留有更多资源应对负载变化,从而提升了服务质量。
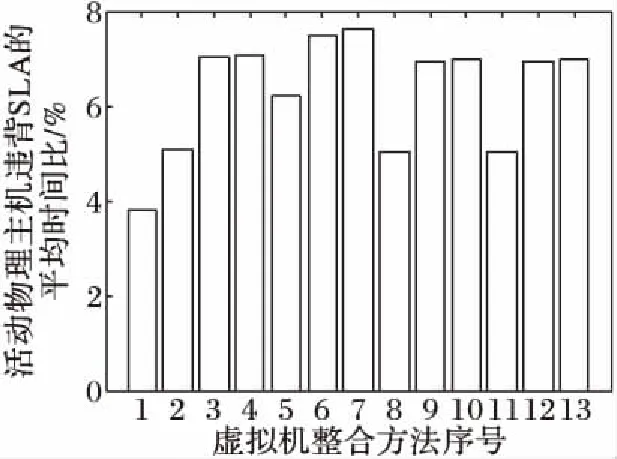
图3 活动物理主机违背SLA的平均时间对比Fig. 3 Comparison of SLATAH
根据表1中的数据和图1~3的对比可以发现,不同的过载检测算法搭配MMT作为虚拟机选择算法的整合方法比搭配其他选择算法的整合方法在PDM指标上降低了21%~34%,同样在SLATAH指标上也降低了17%~28%。MMT算法在服务质量方面总体表现较好的原因是MMT算法解除主机过载时会迁移较多的虚拟机,这使得采用MMT算法的整合方法需要开启更多的活动物理主机来放置虚拟机,因此虚拟得到的主机资源相对充足;同时开启较多的活动物理主机也导致MMT算法在能耗上的表现不如其他算法,但相比MMT算法在服务质量方面的提升幅度,其在节约能耗方面的不足就能够被接受了。在使用MMT作为选择算法的整合方法中,LR-MMT- 1.2方法的能耗最低,但是其在服务质量方面的表现远不及能耗次低的MAD-MMT- 2.5方法,因此,为了更深入地对GMM-VMC方法进行论证,接下来对GMM-VMC方法和在能耗和服务质量的表现上都较为均衡的MAD-MMT- 2.5方法进行更多指标的详细对比。
图4反映的是在虚拟机整合过程中数据中心活动物理主机的变化。因为GMM-VMC需要一段工作负载来建立主机负载模型,所以在1到12次整合中GMM-VMC和MAD-MMT采用了同样的整合方法,即ST-MMT- 0.7。根据图4中显示,在第12次整合之后,采用GMM-VMC方法的活动物理主机的数量明显低于MAD-MMT方法。最终,GMM-VMC方法使得活动物理主机数在40到45的范围内且波动性不大。MAD-MMT方法使得活动物理主机在55到60之间,且整合过程中主机数波动大于GMM-VMC方法。GMM-VMC方法能够将虚拟机集中在部署在较少的物理主机上,因此其能耗低于MAD-MMT方法。
将数据中心活动物理主机数控制在较低的水平充分说明GMM-VMC算法在整合上的有效性。接下来,通过图5来说明GMM-VMC算法在整合时的速度。图5对比了两种方法在整合过程中虚拟机迁移次数的变化。在第12次整合之后GMM-VMC方法经过一个短暂的频繁迁移之后,迁移次数大幅降低并稳定于40次上下;MAD-MMT方法则没有急剧的变化,而是逐渐减少最终在80次上下波动。GMM-VMC方法在整合时使得数据中心虚拟机的放置更加稳定,从而带来其在虚拟迁移次数上的优势。迁移次数直接影响服务质量,这也是GMM-VMC方法在服务质量上表现出色的原因。经过图4、5两个指标的详细对比,验证了GMM-VMC方法在整合时的高效性。
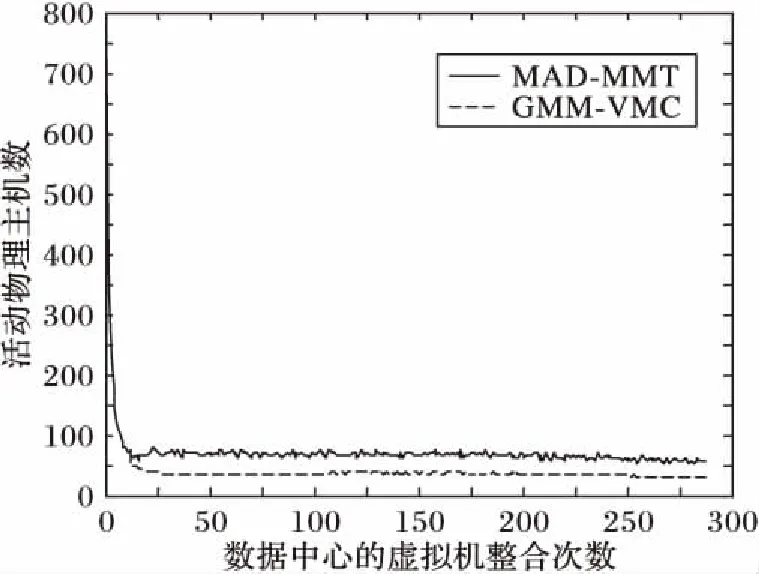
图4 活动物理主机数变化Fig. 4 Changes of active physical hosts
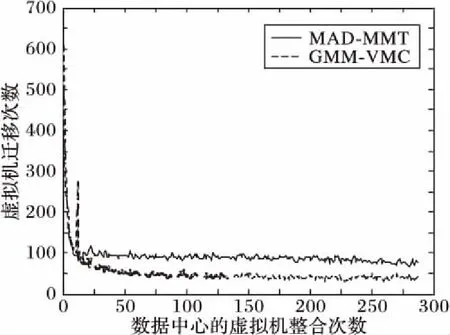
图5 虚拟机迁移次数的变化Fig. 5 Changes of VM migration times
4 结语
针对云数据中心由于资源请求的随机性容易导致主机负载不稳定的问题,本文通过使用GMM建立主机工作负载模型,提出了GMM-VMC方法。该方法在整合过程中利用主机负载模型自动调整物理主机过载阈值,并且将主机负载模型应用到虚拟机选择和放置的决策过程当中。实验表明,GMM-VMC方法在减少能耗的同时能够有效地改善服务质量,这也说明了GMM对主机工作负载进行建模的有效性。GMM-VMC方法主要考虑的是与能耗和服务质量最为相关的CPU资源,在实验中其他主机资源都被认为是资源量充足暂未进行考虑,如何兼顾实际数据中心中所有的影响因素,研究出更为高效、实用的虚拟机整合方法将是未来研究的重点。
参考文献(References)
[1]GOSCINSKI A, BROCK M. Toward dynamic and attribute based publication, discovery and selection for cloud computing [J]. Future Generation Computer Systems, 2010, 26(7): 947-970.
[2]MOSA A, PATON N W. Optimizing virtual machine placement for energy and SLA in clouds using utility functions [J]. Journal of Cloud Computing, 2016, 5(1): 17.
[3]FAN X B, WEBER W D, BARROSO L A. Power provisioning for a warehouse-sized computer [C]// Proceedings of the 34th Annual International Symposium on Computer Architecture. New York: ACM, 2007: 13-23.
[4]房丙午,黄志球.云计算中能耗和性能感知的虚拟机优化部署算法[J].计算机工程与科学,2016,38(12):2419-2424. (FANG B W, HUANG Z Q. An energy-and-performance-aware virtual machine placement optimization algorithm in cloud computing [J]. Journal of Computer Engineering & Science, 2016, 38(12): 2419-2424.)
[5]刘德欣,闫永明,郭军,等.云环境下基于多目标决策的待整合服务器选择方法研究[J].小型微型计算机系统,2016,37(4):699-704. (LIU D X, YAN Y M, GUO J, et al. Method of selecting consolidating server in cloud environment based on multi-objective decision [J]. Journal of Chinese Computer Systems, 2016, 37(4): 699-704.)
[7]BELOGLAZOV A, ABAWAJY J, BUYYA R. Energy-aware re-source allocation heuristics for efficient management of data centers for cloud computing [J]. Future Generation Computer Systems, 2012, 28(5): 755-768.
[8]BELOGLAZOV A, BUYYA R. Optimal online deterministic algo-rithms and adaptive heuristics for energy and performance efficient dynamic consolidation of virtual machines in cloud data centers [J]. Concurrency and Computation: Practice and Experience, 2012, 24(13): 1397-1420.
[9]CAO J, WU Y H, LI M L. Energy efficient allocation of virtual machines in cloud computing environments based on demand forecast [J]. Advances in Grid and Pervasive Computing, 2012, 7296: 137-151.
[10]FARAHNAKIAN F, LILJEBERG P, PLOSILA J. LiRCUP: linear regression based CPU usage prediction algorithm for live migration of virtual machines in data centers [C]// Proceedings of the 39th EUROMICRO Conference on Software Engineering and Advanced Applications. Washington, DC: IEEE Computer Society, 2013: 357-364.
[11]YU L, CHEN L, CAI Z, et al. Stochastic load balancing for virtual resource management in datacenters [J]. IEEE Transactions on Cloud Computing, 2016, PP(99): 1-1.
[12]CHEN M, ZHANG H, SU Y Y, et al. Effective VM sizing in virtualized data centers [C]// Proceedings of the 2011 IFIP/IEEE International Symposium on Integrated Network Management. Piscataway, NJ: IEEE, 2011: 594-601.
[13]JIN H, PAN D, XU J, et al. Efficient VM placement with multiple deterministic and stochastic resources in data centers [C]// Proceedings of the 2012 IEEE Global Communications Conference. Piscataway, NJ: IEEE, 2012: 2505-2510.
[14]WANG M, MENG X, ZHANG L. Consolidating virtual machines with dynamic bandwidth demand in data centers [C]// INFOCOM 2011: Proceedings of the 30th IEEE International Conference on Computer Communications, Joint Conference of the IEEE Computer and Communications Societies. Piscataway, NJ: IEEE, 2011: 71-75.
[15]STAUFFER C, GRIMSON W E L. Adaptive background mixture models for real-time tracking [C]// Proceedings of the 1999 Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 1999: 246-252.
[16]CALHEIROS R N, RANJAN R, BELOGLAZOV A, et al. CloudSim: a toolkit for modeling and simulation of cloud computing environments and evaluation of resource provisioning algorithms [J]. Software Practice & Experience, 2011, 41(1): 23-50.
猜你喜欢
机械研究与应用(2022年4期)2022-09-15
昆钢科技(2022年2期)2022-07-08
健康护理(2022年3期)2022-05-26
当代水产(2021年10期)2022-01-12
建材发展导向(2021年7期)2021-07-16
建材发展导向(2021年23期)2021-03-08
科技传播(2019年23期)2020-01-18
收藏界(2019年2期)2019-10-12
西藏艺术研究(2019年1期)2019-09-04
电子制作(2018年18期)2018-11-14
