
带邻近作用的高增益率co-location模式挖掘
2018-04-12 07:18李晓伟
计算机应用 2018年2期
曾 新,李晓伟,杨 健
(大理大学 数学与计算机学院,云南 大理 671003)(*通信作者电子邮箱hbzengxin@163.com)
0 引言
随着信息技术的快速发展,空间数据集呈现爆炸式的增长。面对具有海量性、高维性等特点的空间数据集,如何从空间数据库当中挖掘出潜在的、人们感兴趣的知识或其他没有显示在存储空间数据库中的模式,从而指导科学决策,显得尤为重要,目前空间数据挖掘已经成为热点研究内容之一。
空间co-location模式是空间特征的一个子集,它们的实例在空间中频繁关联。空间co-location模式广泛存在于现实生活当中,如西尼罗河病毒通常发生在蚊子泛滥、饲养家禽的区域;植物学家们发现“半湿润常绿阔叶林”生长的地方80%会有“兰类”植物生长[1]。
目前大多数空间co-location模式挖掘的一般流程为:
1)根据用户设定的邻近距离阈值计算出不同对象实例间的邻近关系集;
2)通过连接k阶频繁模式,生成(k+1)阶模式候选集;
3)依据邻近关系集生成候选模式的表实例;
4)从模式的表实例中获取模式的参与度,如果模式参与度大于或等于用户设定的阈值,则模式为频繁模式,否则为非频繁模式。
从空间co-location模式挖掘的一般流程中可以看出:大多数co-location模式挖掘仅仅利用距离阈值确定实例间的邻近关系,进而依据参与度阈值确定co-location模式,并未考虑不同对象的邻近实例相互作用和模式的增益率问题,使得用户感兴趣的部分高增益率模式并没有被捕捉到,造成决策失误。例如:A、B两种蔬菜,如果按照传统的co-location模式挖掘方法,A、B不满足频繁模式条件,但是将A和B进行套间种植,可以相互促进生长,增加各自的收益,最终获得的模式增益率要远高于传统挖掘方法获得的频繁模式的增益率,这类高增益率模式也是用户感兴趣的模式。
1 相关工作
近年来,空间co-location模式挖掘取得了丰硕成果。文献[2]提了出基于全连接的方式生成候选项集,并计算候选项集表实例的join-based算法;文献[3]提出了将实例进行分块处理,对块内、块间实例进行连接的partial-join(部分连接)算法;文献[4]提出了一种基于星型邻近扩展的join-less(无连接)算法,通过查询操作来代替连接操作,以解决候选模式生成中的连接开销问题;文献[5]提出了基于前缀树的CPI-tree(Co-location Pattern Instance tree)算法,以树型结构表示空间对象实例间的邻近关系,co-location表实例通过CPI-tree快速生成,算法性能超过了join-less算法;文献[6]针对空间对象实例存在约束条件问题,提出了带有时间约束的co-location模式挖掘。
高效用模式挖掘综合考虑了项的出现次数和项本身的权重,其在实际场景当中具有更广泛的应用。文献[7]提出了不产生候选项集的高效用项集挖掘算法;文献[8]针对高效用项集挖掘算法,提出了一些剪枝策略;文献[9]提出了从事务数据库当中挖掘出高效用项集的有效算法;文献[10]利用估计效用同现的剪枝策略,提出了快速高效用挖掘算法;文献[11]提出了目前已知最优高平均效用项集挖掘算法HAUI-Miner(High Average Utility Itemset Miner),该算法采用AU-list(Average Utility List)结构保存项集效用信息,通过AU-list连接比较挖掘出所有的高平均效用项集,实验表明其时空性能最优;文献[12]将效用概念引入到空间co-location模式挖掘中,定义了模式效用、模式效用率、扩展模式效用等概念,并提出了完全剪枝算法;文献[13]提出了挖掘高平均效用项集的改进算法FHAUI(Fast High Average Utility Itemset),其将效用信息保存到效用列表中,通过效用列表的比较挖掘出高平均效用值;文献[14]充分考虑同一特征不同实例间的差异,提出了带效用值的空间实例,定义了新的效用参与度UPI(Utility Participation Index)作为高效用co-location模式的有趣度量指标,并将领域知识应用到挖掘过程当中。
2 问题描述
下面以一个例子来描述本文研究的问题:不同对象的邻近实例相互作用对co-location模式增益率的影响。
四种不同种类的蔬菜名称及其季均收益如表1所示。

表1 蔬菜名称及其季均收益Tab. 1 Vegetable name and its seasonal average income
其中季均收益表示对象某个实例在一个季度内的平均收益,默认同一对象的所有实例具有相同的季均收益,此处的季均收益就是对象的效用值,在高效用co-location模式挖掘的相关文献[7-14]中都以效用值来表示。
四种不同种类的蔬菜套间种植对收益的影响,即不同对象的邻近实例相互作用对收益产生的影响如表2所示。

表2 相互作用率Tab. 2 Interaction between objects
其中套间种植是指在用户给定的距离阈值内,对F1和F2进行合理种植,对象之间会在阳光、土壤、水分等方面相互影响、互相补充,促进各自生长。而(F1,F2)的相互作用率由两部分组成:1%~5%,1%~5%,前1个数据表示套间种植时,F1的季均收益会提升1%~5%,后1个数据表示F2的季均收益会提升1%~5%,即二者进行套间种植能够达到共同增加收益的目的。例如:韭菜和豇豆套间种植会相互促进生长,提升总收益。
以增益率为目的的co-location模式挖掘与传统的co-location模式挖掘有一定的区别,其以增益率作为衡量co-location模式挖掘效果的标准,下面以实例进行详细阐述。
四种不同种类的蔬菜F1、F2、F3和F4,分别有3、2、3和4个不同的品种,不同品种的种植分布情况如图1所示。
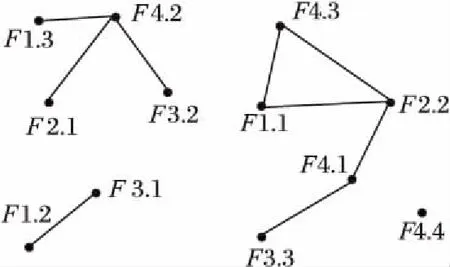
图1 不同种类蔬菜及其品种分布图Fig. 1 Distribution of different kinds of vegetables and their varieties
如果两种不同品种的蔬菜进行间套种植(邻近),则用实线将二者连接起来。
用户设定参与度阈值为:min_prev=0.7,从图1中可以分析出,二阶模式{F2,F4}和{F3,F4}的表实例分别为:{(F2.1,F4.2),(F2.2,F4.1),(F2.2,F4.3)}和{(F3.2,F4.2),(F3.3,F4.1)}。PI({F2,F4})=min(2/2,3/4)=0.75≥min_prev,{F2,F4}为频繁模式;PI({F3,F4})=min(2/3,2/4)=0.5≤min_prev,{F3,F4}为非频繁模式。而模式{F2,F4}和{F3,F4}的收益为:
SY({F2,F4})=2×2×(1+(5%~10%))+
3×2×(1+(-10%~-5%))
SY({F3,F4})=2×5×(1+(1%~10%))+
2×2×(1+(1%~10%))
模式{F2,F4}和{F3,F4}的增益率分别为:
由于作用率还受到其他因素的影响,因此是一个变化的值,在研究当中,我们将在给定的作用率范围内随机取值。
假设模式收益SY({F2,F4})和SY({F3,F4})分别取各自的最大值和最小值,那么max(ZYRate({F2,F4}))=0.01,而min(ZYRate({F3,F4}))=0.01,则有如下关系式:
ZYRate({F3,F4})≥ZYRate({F2,F4})
因此将模式增益率作为co-location模式挖掘标准,模式{F3,F4}更让用户感兴趣,而在传统模式挖掘中,其作为非频繁模式被丢弃。
现实生活当中,很多农户将不同作物进行套间种植,期望获得更好的收益,但是盲目的作物套间种植有可能会导致作物减产。例如西红柿和土豆进行套间种植,它们会被同样的枯萎病袭击,导致双减产,因此研究带邻近影响的co-location模式挖掘为科学进行作物套间种植提供理论依据。
3 相关概念及定义
3.1 空间co-location模式挖掘概念
空间对象是指空间不同类别的事物,而在空间某个确定位置上的对象称为空间对象实例。例如图2中有A、B、C三个不同空间对象,每个空间对象分别有4、2和3个对象实例。
空间邻近关系R用来表示空间对象实例之间的空间关系,一般采用欧几里得距离来表示:
R(A.1,B.1) ⟺distance(A.1,B.1)≤d
其中:d是预先设定的距离阈值,例如图2中A.1和B.1是邻近的,用实线连接。
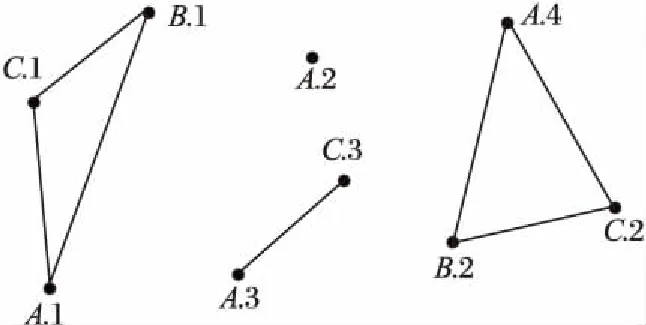
图2 空间对象及其实例Fig. 2 Spatial objects and their instances
假设实例集为I={i1,i2,…,in},如果I中的任何两个实例间都满足{R(ix,iy)|1≤x≤n,1≤y≤n},则I称为团,例如在图2中{A.1,B.1,C.1}就是一个团。
空间co-location模式表示一组空间对象的集合,用c表示,例如在图2中c={A,B,C}就是一个空间co-location模式。如果存在一个团包含模式c的所有对象,并且此团的任何子集都不包含模式c的全部对象,则称此团为模式c的行实例。例如在图2中{A.4,B.2,C.2}就是模式c的一个行实例。而模式c的所有行实例的集合称为表实例,用table_instance(c)来表示。例如在图2中模式c的表实例为:{{A.1,B.1,C.1},{A.4,B.2,C.2}}。
假设fi为空间的某个对象,fi在模式c={f1,f2,…,fk}中的参与率表示为:
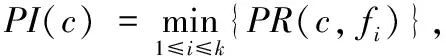
定理1参与度和参与率随着co-location模式c的阶的增大而单调递减。
证明假设模式c的行实例中包含某一空间对象fi的实例,如果模式c′是c的子集,那么fi的实例也一定被包含在c′的行实例中,反之则不然,因此空间对象的参与率随着模式阶的增长而递减。
假设:
c={f1,f2,…,fk}
所以模式c的参与度也是单调递减的。
3.2 高增益率co-location模式挖掘定义
高增益率co-location模式挖掘是指挖掘增益率大于或等于用户给定增益率阈值的模式。
假设给定的数据集中有n个不同对象,对象集表示为F={f1,f2, …,fn},每个对象fi的季均收益表示为jas(fi);模式c由k个对象组成,表示为c={f1,f2,…,fk},其中k≤n;模式c的表实例表示为table_instance(c),那么模式c中某个对象fi的实例在table_instance(c)中不重复出现的个数表示为ct=fi(table_instance(c))。
定义1模式c={f1,f2,…,fk},模式c中的一组对象(fi,fj)进行套间种植的相互作用率为(xi%~yi%,xj%~yj%),xi%~yi%表示套间种植fj→fi产生正或负的作用率,xj%~yj%表示套间种植fi→fj产生正或负的作用率,用EZYRate(fj→fi)来表示fj→fi的作用率,其中1≤i,j≤k,i≠j。
由于模式c中每个对象fi与其他(k-1)个对象进行套间种植,同时受到(k-1)个对象的影响,所以对象fi在模式c中的作用率为:
称DZYRate(fi,c)为对象作用率。
若由总体X的样本X1,X2,…,Xn确定的两个统计量为:
θ1=θ1(X1,X2,…,Xn),θ2=θ2(X1,X2,…,Xn)
且θ1<θ2,则称[θ1,θ2]为随机区间。
如果获得样本值x1,x2,…,xn,那么θ1(x1,x2,…,xn)和θ2(x1,x2,…,xn)都是常数,[θ1,θ2]成为常数区间。
设θ是总体X的一个未知参数,0<α<1能满足P{θ1≤θ≤θ2}=1-α,则区间[θ1,θ2]是θ置信度为1-α的置信区间。
对象作用率DZYRate(fi,c)等于多个不同实例的相互作用率之和,因此,存在区间[θ1,θ2]使得θ=DZYRate(fi,c)满足P{θ1≤θ≤θ2}=1-α,并具有1-α置信度,所以对象作用率具有一定的有效性。
定义2模式c={f1,f2,…,fk},模式c中某个对象fi的总收益等于fi的实例在table_instance(c)中不重复出现的个数ct与对象fi的季均收益jas(fi)的乘积,用YDZSY(fi,c)表示:
YDZSY(fi,c)=ct×jas(fi)
称YDZSY(fi,c)为原对象总收益。
定义3模式c={f1,f2,…,fk},模式c的原始总收益等于模式内所有对象的原对象总收益之和,用YSZSY(c)表示:
称YSZSY(c)为模式c的原始总收益。
定义4在带邻近作用的co-location模式挖掘中,模式c={f1,f2,…,fk},模式c中某个对象fi的套间总收益等于fi的实例在table_instance(c)中不重复出现的个数ct、对象fi的季均收益jas(fi)和其对象作用率DZYRate(fi,c)三者的乘积,称为套间对象总收益,用TDZSY(fi,c)表示:
TDZSY(fi,c)=ct×jas(fi)×(1+DZYRate(fi,c))
定义5在带邻近作用的co-location模式挖掘中,模式c={f1,f2,…,fk},模式c的套间总收益等于模式内所有对象的套间对象总收益之和,用TJZSY(c)来表示,称为套间总收益:
定义6模式c={f1,f2,…,fk}的原始总收益为YSZSY(c),进行套间种植,并受到邻近影响后,模式c的套间总收益为TJZSY(c),则模式c的增益率的计算公式为:
称ZYRate(c)为模式c的增益率。
定义7用户给定的增益率阈值为zyr_thre,若模式c={f1,f2,…,fk}的增益率ZYRate(c)≥zyr_thre,模式c为高增益率模式,否则为非高增益率模式。
传统co-location模式满足反单调性质,但是高增益率模式并不满足反单调性性质,例如:模式{fi,fj}属于非高增益率模式,当对象fk可同时正作用率于对象fi和fj,那么模式{fi,fj,fk}可能为高增益率模式,因此高增益率模式并不满足反单调性性质。
4 挖掘算法
首先给出带邻近作用的高收益率co-location模式挖掘的基础算法,然后在其基础上给出有效的剪枝算法,提高算法的运行效率。
4.1 基础算法NAGA
由于带邻近作用的高收益率co-location模式不满足反单调性性质,所以不能采用传统co-location模式挖掘的一般算法,因此其中心思想是利用组合的方式生成对象集F={f1,f2,f3,…,fn}的所有子模式,然后计算出每个子模式的表实例,最后求出每个子模式的增益率,并与用户给定的增益率阈值进行比较,输出高增益率模式。基础算法(NAGA)描述如下:
输入
F={f1,f2,f3,…,fn}表示有n个对象的对象集;
I={i11,i12,…,i1m,…,inm}表示有n个对象,每个对象至多有m个实例的实例集;
jas(fi)表示对象fi的季均收益;
d表示邻近距离阈值;
zyr_thre表示增益率阈值
中间参数
Ck表示k阶co-location模式的候选集;
Tab(ci)表示Ck中第i个模式的表实例;
邻近关系集:neiR
输出
输出高增益率模式zyrP
算法过程
1)
k=2;
2)
zyrP=∅;
3)
计算不同对象实例间的邻近距离,将邻近距离小于邻近距离阈值d的实例对并入邻近关系集neiR;
4)
whilek≤n
a)
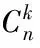
b)
for(i=1;i≤len(Ck);i++)
i)
根据邻近关系集neiR,计算候选模式集Ck中第i个模式ci的表实例Tab(ci);
ii)
根据模式ci表实例Tab(ci)和对象fi的季均收益jas(fi),计算出每个对象的原对象总收益,最后得到模式ci的原始总收益YSZSY(ci);
iii)
根据Z,计算模式ci中每个对象的作用率DZYRate(fi,ci);
iv)
根据模式ci表实例Tab(ci)、对象fi的季均收益jas(fi)和DZYRate(fi,ci),计算出每个对象的套间对象总收益,最后得到TJZSY(ci);
v)
最后利用YSZSY(ci)和TJZSY(ci)计算出模式ci的增益率ZYRate(ci);
vi)
ifZYRate(ci)≥zyr_thre
zyrP=zyrP∪ci;
c)
k=k+1;
5)
输出高增益率模式zyrP
4.2 剪枝算法NAGA_JZ
剪枝算法NAGA_JZ在基础算法NAGA的基础上进行剪枝,以提高高增益率模式的挖掘效率。NAGA_JZ算法对NAGA算法主要进行两个剪枝步:一个是对候选模式集Ck中的模式ci,首先计算其每个对象的作用率,如果其所有对象的作用率都小于或等于0,那么就有ZYRate(ci)≤0,则模式ci肯定为非高增益率模式;另一个是模式ci的套间总收益小于或等于原始总收益,那么ZYRate(ci)≤0,模式ci为非高增益率模式。剪枝算法NAGA_JZ与基础算法NAGA的不同集中在NAGA算法的b)步内,因此只对NAGA_JZ算法的4.2步作详细描述:
1)
for(i=1;i≤len(Ck);i++)
i)
根据Z,计算模式ci中每个对象的作用率DZYRate(fi,ci),如果所有对象的作用率都小于或等于0,那么Ck=Ck-ci,并转入下一次循环;
ii)
根据邻近关系集neiR,计算候选模式集Ck中第i个模式ci的表实例Tab(ci);
iii)
根据模式ci表实例Tab(ci)和对象fi的季均收益jas(fi),计算出每个对象的原对象总收益,最后得到模式ci的原始总收益YSZSY(ci);
iv)
根据模式ci表实例Tab(ci)、对象fi的季均收益jas(fi)和DZYRate(fi,ci),计算出每个对象的套间对象总收益,最后得到TJZSY(ci);
v)
ifTJZSY(ci)≤YSZSY(ci)
Ck=Ck-ci,并转入下一次循环;
vi)
最后利用YSZSY(ci)和TJZSY(ci)计算出模式ci的增益率ZYRate(ci);
vii)
ifZYRate(ci)≥zyr_thre
zyrP=zyrP∪ci;
5 实验分析
为了评估NAGA算法的正确性、实用性以及NAGA_JZ算法的高效性等性能,本文进行了大量的对比实验与分析。实验的硬件平台为Intel Core i3处理器,4 GB内存,64位Windows 7操作系统,软件编程环境为Python 2.7。实验采用的数据集均随机产生,产生数据集的区域为[1,100],每个对象的实例个数、季均收益和对象间的相互作用率也随机产生。
5.1 基础算法与剪枝算法的效率比较
数据集中的10个对象随机产生各自的实例个数,得到的实例总数分别为:344、580、803、1 102和1 414,每个实例的坐标将在[1,100]范围内随机产生,其中,邻近距离阈值d=5,高增益率阈值zyr_thre=0.2,算法的效率比较如图3所示。在图3中,NAGA_JZ算法与NAGA算法在实例总数较小时,执行效率并没有明显的差距,但是随着实例总数的不断增大,NAGA_JZ算法的执行效率要优于NAGA算法,因此NAGA_JZ算法起到了一定的优化效果。
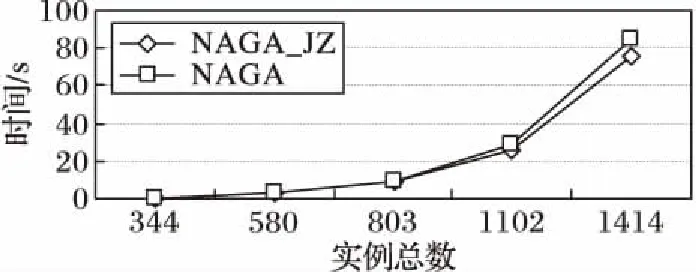
图3 基础算法与剪枝算法执行效率比较Fig. 3 Comparison of execution efficiency between NAGA and NAGA_JZ
5.2 实例总数对高增益率模式数的影响
与5.1节相同的参数设置下,实例总数对高增益率模式数的影响如图4所示。由于对象个数为10,随着对象实例数的增多,模式的行实例数会随之增多,低阶高增益模式数会增加,同时会产生部分高阶高增益率模式,因此总的高增益率模式数会不断增大。
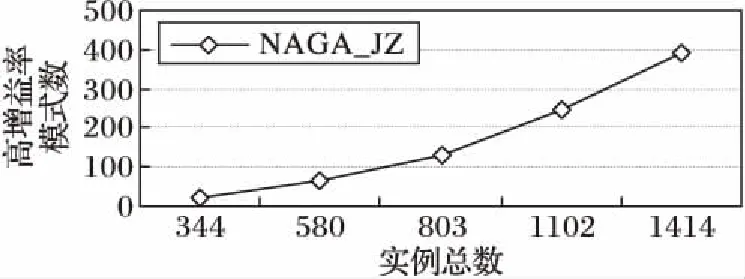
图4 实例总数对高增益率模式数的影响Fig. 4 Influence of number of instances on number of high gain rate patterns
5.3 邻近距离阈值对算法的影响
在数据集对象数为10,实例总数为1 102,高增益率阈值zyr_thre=0.2的情况下,分别对邻近距离阈值为1、3、5、7和9进行实验,并统计挖掘出的高增益率模式数,如图5(a)所示。随着邻近距离阈值的不断增大,高增益率模式数也不断增多,由于数据集大小一定,高增益率模式数会趋于某一值。在相同的条件下,对NAGA算法和NAGA_JZ算法的执行效率进行对比,结果如图5(b)所示。邻近距离阈值会直接影响模式行实例数,随着实例数的增大,邻近距离阈值对算法的效率影响将更加明显。
5.4 增益率阈值对算法的影响
在数据集对象数为10,实例总数为1 102,邻近距离阈值d=5的情况下,分别对增益率阈值为0.1、0.15、0.2、0.25和0.3进行实验,并统计高增益率模式数,如图6(a)所示。随着增益率阈值的不断增大,满足条件的高增益率模式数会不断减少。同时,在相同条件下,对NAGA算法和NAGA_JZ算法的执行效率进行对比,结果如图6(b)所示。由于算法的主要耗时在于模式表实例的计算,因此增益率阈值对算法的效率几乎没有影响。
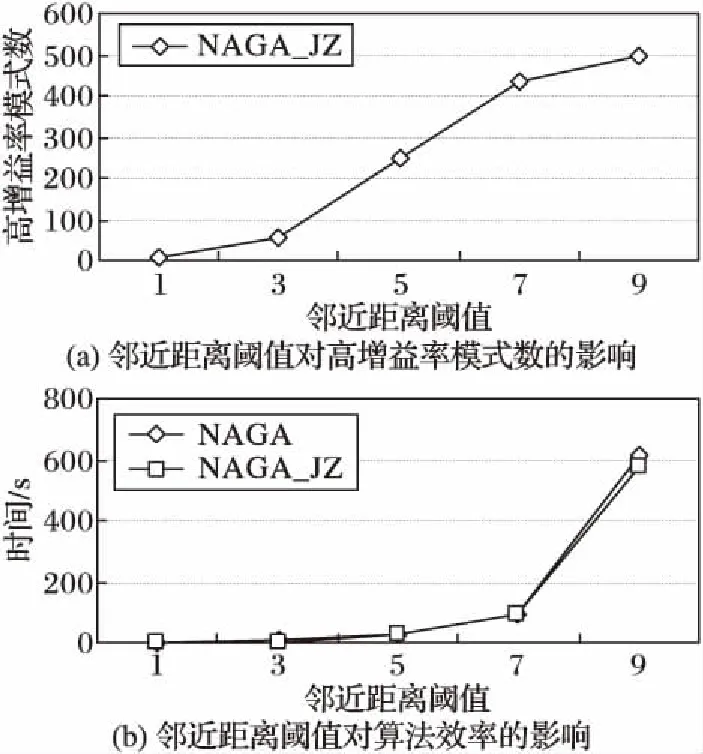
图5 邻近距离阈值对高增益率模式数和算法效率的影响Fig. 5 Influence of neighboring distance threshold on number of high gain patterns and algorithm efficiency
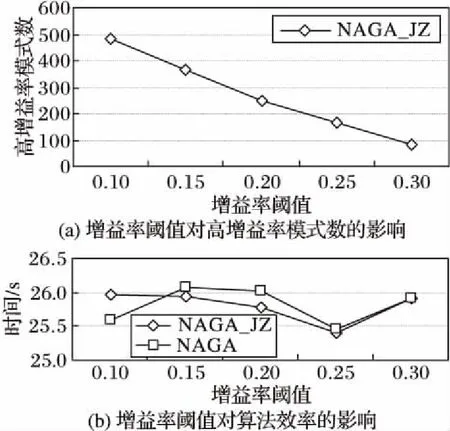
图6 增益率阈值对高增益率模式数和算法效率的影响Fig. 6 Influence of gain rate threshold on number of high gain patterns and algorithm efficiency
5.5 对象个数对算法效率的影响
在实例总数为600,邻近距离阈值d=5,高增益率阈值zyr_thre=0.25的条件下,分别对对象个数为5、10、15、20和25进行实验,比较NAGA算法和NAGA_JZ算法在不同对象个数下的运行效率,结果如图7所示。对象个数的不断增加会导致模式数增加,需要计算更多模式的表实例,所以算法的执行时间也会随之增加。然而,算法NAGA_JZ能够将部分非高增益率模式剪枝,避免计算它们的表实例,因此,其执行效率要高于NAGA算法。
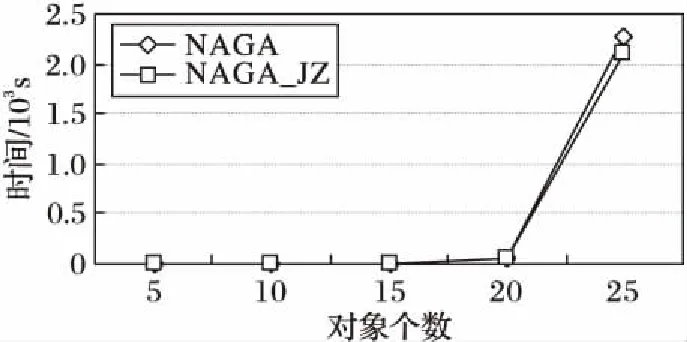
图7 对象个数对算法效率的影响Fig. 7 Influence of number of objects on algorithm efficiency
6 结语
在单个对象季均收益一定的情况下,如何将不同对象进行套间种植,利用不同对象间的相互作用,提高模式的整体收益,具有一定应用价值。从邻近关系中计算出每个模式的表实例,并根据增益率阈值挖掘出高增益率模式,为科学指导套间种植提供理论依据。在未来的研究工作当中,可以继续研究高效的剪枝策略和基于top-k的高增益率co-location模式挖掘。
参考文献:
[1]王丽珍,周丽华,陈红梅,等.数据仓库与数据挖掘原理及应用[M].2版.北京:科学出版社,2009:1-19. (WANG L Z, ZHOU L H, CHEN H M, et al. The Principle and Applications of Data Warehouse and Data Mining [M]. 2nd ed. Beijing: Science Press, 2009: 1-19.)
[2]HUANG Y, SHEKHAR S, XIONG H. Discovering co-location patterns from spatial data sets: a general approach [J]. IEEE Transactions on Knowledge and Data Engineering, 2004, 16(12): 1472-1485.
[3]YOO J S, SHEKHAR S, SMITH S, et al. A partial join approach for mining co-location patterns [C]// GIS ’04: Proceedings of the 12th Annual ACM International Workshop on Geographic Information Systems. New York: ACM, 2004: 241-249.
[4]YOO J S, SHEKHAR S, CELIK M. A join-less approach for co-location pattern mining: a summary of results [C]// ICDM ’05: Proceedings of the 5th IEEE International Conference on Data Mining. Washington, DC: IEEE Computer Society, 2005: 813-816.
[5]WANG L, BAO Y, LU J, et al. A new join-less approach for co-location pattern mining [C]// CIT 2008: Proceedings of the 8th IEEE International Conference on Computer and Information Technology. Washington, DC: IEEE Computer Society, 2008: 197-202.
[6]曾新,杨健.带时间约束的co-location模式挖掘[J].计算机科学,2016,43(2):293-296,301. (ZENG X, YANG J. Co-location patterns mining with time constraint [J]. Computer Science, 2016, 43(2): 293-296, 301.)
[7]LIU M, QU J. Mining high utility itemsets without candidate generation [C]// CIKM ’12: Proceedings of the 21st ACM International Conference on Information and Knowledge Management. New York: ACM, 2012: 55-64.
[8]KRISHNAMOORTHY S. Pruning strategies for mining high utility itemsets [J]. Expert Systems with Applications, 2015, 42(5): 2371-2381.
[9]TSENG V S, SHIE B-E, WU C-W, et al. Efficient algorithms for mining high utility itemsets from transactional databases [J]. IEEE Transactions on Knowledge and Data Engineering, 2013, 25(8): 1772-1786.
[10]FOURNIER-VIGER P, WU C W, ZIDA S, et al. FHM: faster high-utility itemset mining using estimated utility co-occurrence pruning [C]// ISMIS 2014: Proceedings of the 21st International Symposium Foundations of Intelligent System, LNCS 8502. Cham: Springer, 2014: 83-92.
[11]LIN J C-W, LI T, FOURNIER-VIGER P, et al. An efficient algorithm to mine high average-utility itemsets [J]. Advanced Engineering Informatics, 2016, 30(2): 233-243.
[12]杨世晟,王丽珍,芦俊丽,等.空间高效用co-location模式挖掘技术初探[J].小型微型计算机系统,2014,35(10):2302-2307. (YANG S S, WANG L Z, LU J L, et al. Primary exploration for spatial high utility co-location patterns [J]. Journal of Chinese Computer Systems, 2014, 35(10): 2302-2307.)
[13]王敬华,罗相洲,吴倩.基于效用表的快速高平均效用挖掘算法[J].计算机应用,2016,36(11):3062-3066. (WANG J H, LUO X Z, WU Q. Fast high average-utility itemset mining algorithm based on utility-list structure [J]. Journal of Computer Applications, 2016, 36(11): 3062-3066.)
[14]江万国,王丽珍,方圆,等.领域驱动的高效用co-location模式挖掘方法[J].计算机应用, 2017, 37(2):322-328. (JIANG W G, WANG L Z, FANG Y, et al. Domain-driven high utility co-location pattern mining method [J]. Journal of Computer Applications, 2017, 37(2): 322-328.)
猜你喜欢
成都信息工程大学学报(2022年4期)2022-11-18
北京航空航天大学学报(2021年6期)2021-07-20
电子制作(2019年19期)2019-11-23
电子制作(2018年19期)2018-11-14
电子制作(2016年1期)2016-11-07
科技视界(2016年8期)2016-04-05
湖南大学学报·自然科学版(2016年2期)2016-03-15
现代电子技术(2015年15期)2015-08-14
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
