
Alltoall通信性能模型研究*
2018-04-08 00:48罗红兵张晓霞
计算机与生活 2018年4期
罗红兵,张晓霞,魏 勇
北京应用物理与计算数学研究所 高性能计算中心,北京 100094
1 引言
MPI(message passing interface)通信性能是影响并行应用程序性能的关键,特别是MPI集合通信性能对于应用的可扩展性往往具有决定性的作用。在MPI集合通信中,Alltoall是让所有参与通讯的进程彼此进行数据交换的集合通信操作,对于采用该通信模式的应用,例如三维快速傅里叶变换[1]和量子力学分子动力学模拟CPMD(Car-Parrinello molecular dynamics)[2],Alltoall性能对应用软件性能的影响非常大。为此,Alltoall相应的评估和优化研究一直是并行计算领域的研究热点,包括对Alltoall等集合通信的详细分析[3-5],针对当前多核CPU的Alltoall的优化[6-7],在通信算法层[8]针对特定高性能计算机[9]对Alltoall进行的优化等。
已有的研究结果[5]显示:Alltoall的理论预估值与实际测试值的差别往往较大,尤其在超大规模情况下,实测值甚至是理论值的数倍,反映出对Alltoall集合通信性能的理论建模仍然是值得深入研究的问题。如何利用理论模型解释Alltoall的性能,是MPI通信算法设计、评估和优化,乃至高性能计算机优化中必须要面对的问题。当前,对于Alltoall集合通讯的性能建模[10-11]大都基于基本的通讯模型进行,其中被广泛使用的通信性能模型是LogP(latency,overhead,gap,and processor)模型[12],该模型是一个针对分布式存储的多处理器模型,处理器间采用点对点通信。LogGP模型[13]在LogP模型的基础上增加了一个参数G,该参数可以描述在传递长消息时获得的带宽。从现有的研究和实验结果看,某些因素未在模型中准确地体现,导致Alltoall性能理论预测在大规模情况下的失真。
针对超大规模情况下Alltoall的理论性能模型存在的不足,本文从MPI通信的基本特征和Alltoall实现算法和模型两方面予以分析,希望刻画出实际互连网络系统中的某些特征,以期建立更为精确的Alltoall性能模型。
2 Alltoall实现算法分析
MPI的开源实现版本mpich中对Alltoall的实现涉及4个算法,分别面向不同的消息长度和进程数规模,具体为:
(1)对于短消息(缺省是不大于256 B)且MPI进程数大于等于8,采用存储前进算法,以多传输数据来减少通信延迟的影响,算法需执行lbp步,单进程的数据传输量增加到原传输量的lbp/2倍。
(2)对于中等规模的消息(缺省为不大于32 KB)且MPI进程数小于8,以同时进行irevs和isends,再进行一次waitall的方式实现,其中需避免所有进程在同一时刻向同一进程进行irevs和isends。
(3)对于长消息且进程数为2的幂,使用配对交换算法,需p-1个传输步。
(4)对于长消息且进程数不为2的幂,以第i步,每个进程从rank-1收消息,向rank+1发消息的流程进行,需p-1个传输步。
对于大规模的Alltoall通信,分别在短消息时用算法(1),在其余长度的消息时使用算法(3)和算法(4)。用k表示消息块的大小,p表示进程数,α表示通信延迟,β表示通信带宽的倒数,Alltoall时间开销分别可以表示为:
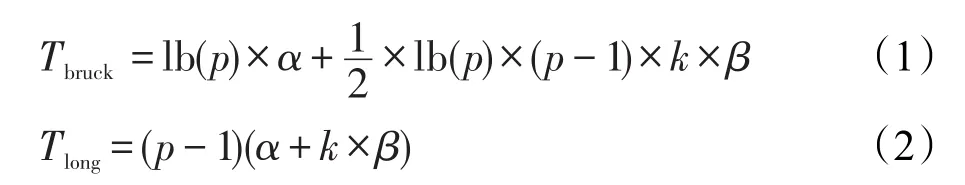
从以上算法体现的Alltoall时间开销看,Alltoall通信性能建模依赖于通信延迟和通信带宽的准确刻画。由于通信延迟和通信带宽一方面依赖于高性能计算机互连网络的实现技术,一方面依赖于系统负载情况,其性能的准确刻画并非易事。Alltoall涉及到p个进程同时进行通信,当p的数量达到一定规模时,其通信性能不可避免地有所差别,这也是在Aalltoall性能建模时需要考虑的。
3 Alltoall通信性能模型
Alltoall通信性能模型依赖于互连网络通信性能模型,考虑到大规模互连通信网络中通信性能模型的复杂性,本文首先选择一个实际系统进行评测,以期总结其性能特征。在此基础上,结合Alltoall的特点,建立一个较为合理的性能模型,然后在此基础上设计Alltoall通信性能模型。
3.1 测试平台
测试平台选择某国产并行机(简称BXJ),该系统的每个计算节点包含2颗英特尔微处理器,每颗微处理器包含6个计算核心;互连系统采用自主设计的高阶路由芯片(network route chip,NRC)和高速网络接口芯片(network interface chip,NIC),实现光电混合的二层胖树结构高阶路由网络互连。NRC采用了16×16高阶网络交换部件,计算节点最大跳转次数为3,工作主频为312.5 MHz,时钟周期为3.2 ns,基本传输单位为256 bit。BXJ并行机通信系统的性能参数详见表1,NRC路由交换芯片的基本参数详见表2。

Table 1 Basic parameters for communication system of BXJ parallel computer表1 BXJ并行机通信系统基本参数

Table 2 Basic parameters for NRC interconnection表2 NRC互连基本参数
3.2 基本通信性能分析
选用Intel IMB测试程序,测试BXJ上16至8 192个MPI进程执行Sendrecv操作的通信延迟和通信带宽情况。与Alltoall类似,测试程序中的每个MPI进程同时执行Sendrecv操作,都参与数据通信。测试含单计算节点启动8个MPI进程和12个MPI进程2组测试。表3和表4是有关通信延迟的部分测试结果,图1是测试中出现的通信延迟抖动(通信延迟的最大波动幅度与通信延迟的平均值之比)与进程数间的关系。其中的趋势线显示:通信延迟的抖动幅度随着进程数的增多明显呈增大的趋势。
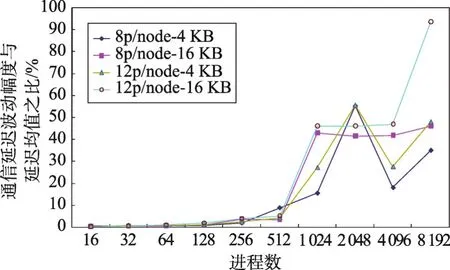
Fig.1 Relationship between latency and the number of processes图1 通信延迟抖动与进程数间的关系
表3和表4是16~8 192进程时,通信延迟的具体结果,其中单MPI进程的消息块分别是4 KB和16 KB。表3和表4中的数据显示:无论是单计算节点启动8个MPI进程,还是单计算节点启动12个MPI进程,这种通信延迟的抖动都在一定程度上存在。计算节点启动的MPI进程较多时,抖动的幅度更大。
图2和图3是BXJ上16进程至8 192进程下的通
信带宽情况。图2和图3的数据显示:计算节点的通信带宽随消息块的增大而增加,直到达到最大值,不同进程数下节点的增长趋势基本一致;单节点上所有MPI进程分享通信带宽,启动的MPI进程数越多,分享的带宽越少。
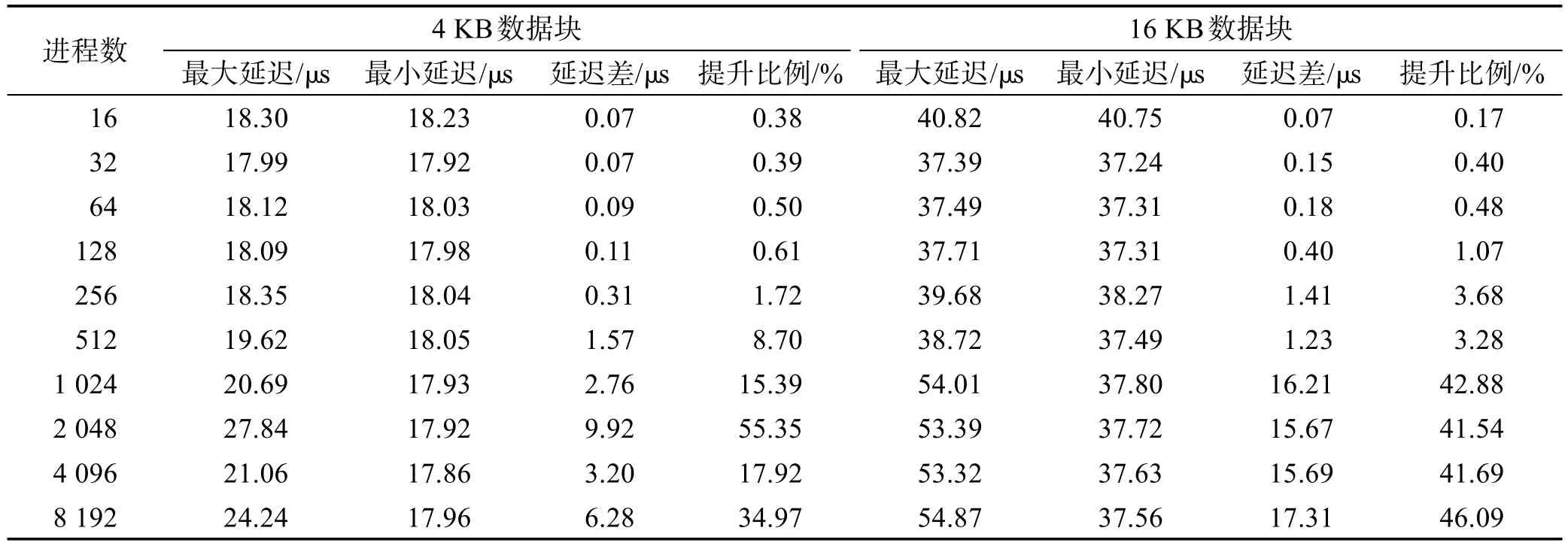
Table 3 Relationship between latency and the number of processes(8 processes per node)表3 通信延迟与进程数的关系(单节点8个MPI进程)
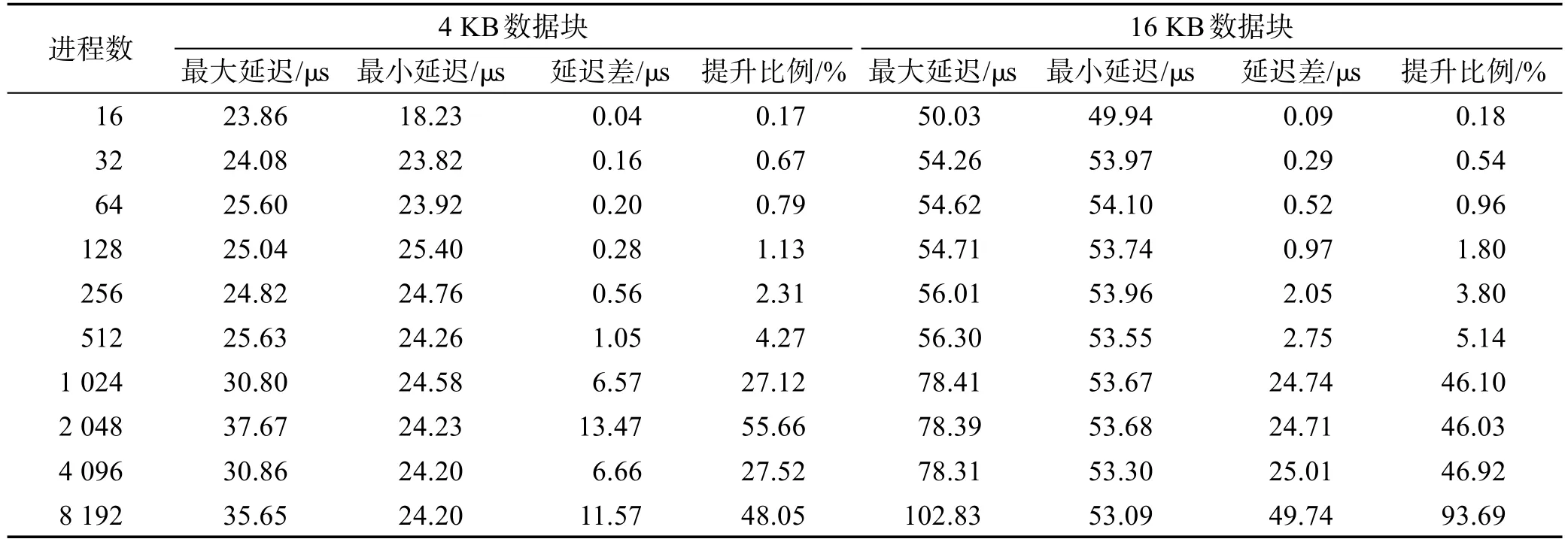
Table 4 Relationship between latency and the number of processes(12 processes per node)表4 通信延迟与进程数的关系(单节点12个MPI进程)
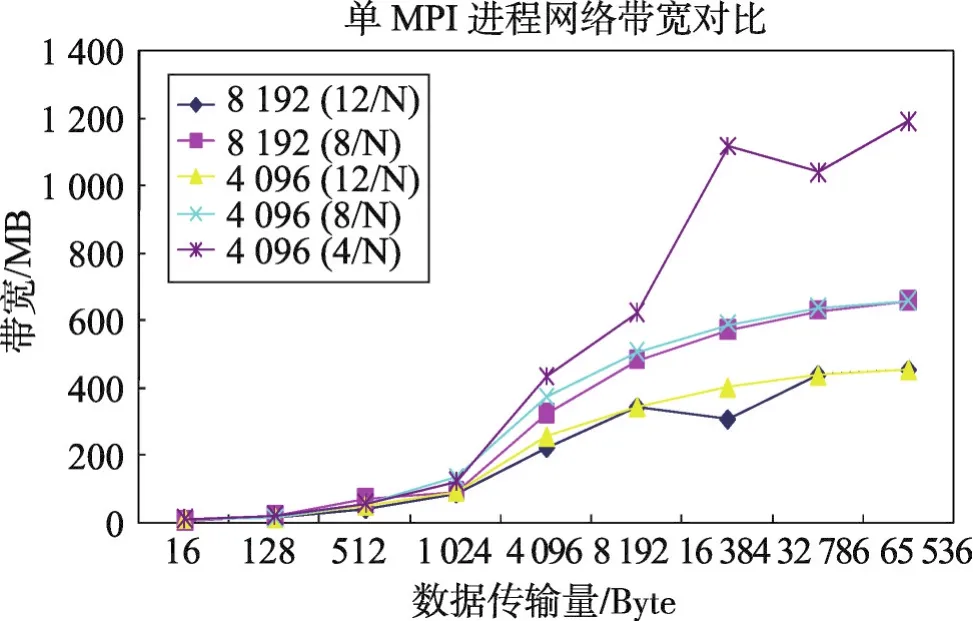
Fig.2 Relationship between communication bandwidth of single MPI process and the size of messages图2 单进程时MPI通信带宽与数据传输量间的关系

Fig.3 Relationship between cumulative communication bandwidth of single node and the size of messages图3 单计算节点通信带宽与数据传输量间的关系
基于以上对大规模并行情况下通信延迟和通信带宽情况的分析,可以得出以下基本结论:
(1)通信延迟的准确刻画并非易事,随着进程数和数据传输量的增加,网络传输会存在竞争,导致通信延迟的变化和性能抖动。
(2)对于通信带宽,利用MPI进程实测通信带宽基本可以反映其特征。
3.3 Alltoall性能模型
已有的研究[14]显示,通信性能与负载有关。评估互连网络性能需要定义负载模型,涉及目的分布、注入速率和消息长度等。
对于Alltoall集合通信而言,目的分布是均匀的,数据注入规律简单,消息长度固定,因而评估其通信延迟时可以在已有通信性能模型[15]上简化。考虑到互连网络的多样性,本文仅仅针对多级互连网络(multistage interconnection networks,MINs)进行建模,这是当前使用最为普遍的网络类别。
通常来说,实现N个计算节点互连的N×NMIN互连网络由L=logkN级k×k交换单元构成。为便于描述,假定网络完全由k×k交换部件构成,k×k交换部件含k个输入端口和k个输出端口,每个输出端口在单时钟周期内分别可以接受一个报文。为防止阻塞,每个输出端口的buffer实现为FIFO(first input first output)队列。到达的报文直接进入到与目的输出端口对应的buffer,不同的buffer之间不会有冲突。
对于以上理想的交换单元,令其时钟周期为tc,tT为从交换单元到下一交换单元的传输时间。假定在每个时钟周期,报文到达每个输入端口的可能性为ρ,令vn表示在时刻n加入到一个输出队列的报文的数目,那么v1,v2,…,vn为独立的符合伯努利分布的随机变量。到达报文数量的数学期望E=其方差令q为n时刻n在队列中的报文数目,qn和vn有如下关系式:
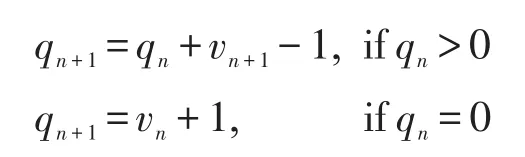
上面排队关系可以用M/G/1队列系统描述[16-17],相应地,到达输出端口报文数的数学期望为:
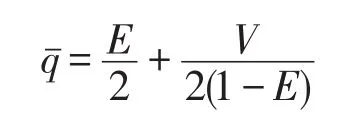
报文通过交换部件的时间的数学期望为:

报文通过交换部件的等待时间的数学期望为:
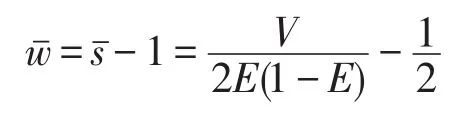
求出E和V代入上式,可以得到:

将式(3)引入到式(2),可以得到增加了网络竞争因素的Alltoall性能模型:

其中,kp是网络最小传输单位(报文)的大小;nhop是报文需要经过的交换单元数目。
4 模型验证和评估
由于BXJ测试平台处于生产性运行状态,实际测试时没有机会占用全系统,以下相关测试的最大并行规模为8 192个MPI进程,Alltoall的实测采用Intel IMB测试程序获得。
4.1 传统Alltoall性能模型评估
首先,评估实测值与采用传统模型时理论估值的对比情况,图4和图5是对比结果图。其中,理论值按照实际实现算法估算,在128 B短消息时使用Bruck算法,在16 KB消息时下使用Long算法,涉及的通信延迟α和通信带宽β分别使用系统标称的理论值和实测值。图中,Alltoall的实测值用Real标注,另外标注中的8和12表示单节点启动的MPI进程数;理论值用“算法名+数字+字母”标注,例如:Long8B表示理论值按Long算法估算,单节点启动8个MPI进程,字母B表示通信延迟α和通信带宽β采用理论值;Bruck12A表示理论值按Bruck算法估算,通信延迟α和通信带宽β采用实测值。
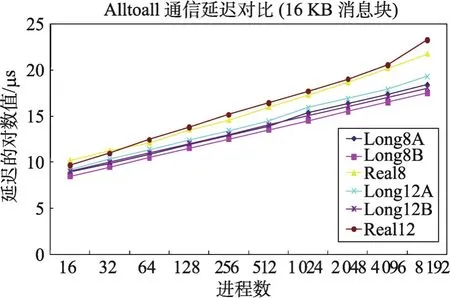
Fig.4 Comparison of actual value and predicted value by differentAlltoall models on BXJ(16 KB message)图4 BXJ上Alltoall传统模型估值与实测值对比(16 KB消息)
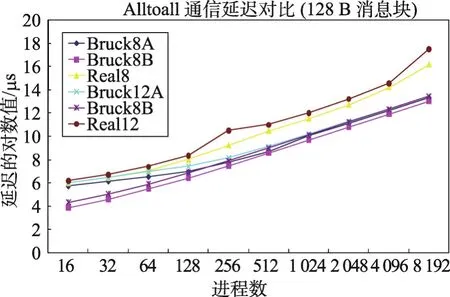
Fig.5 Comparison of actual value and predicted value by differentAlltoall models on BXJ(128 B message)图5 BXJ上Alltoall传统模型估值与实测值对比(128 B消息)
考虑到同一消息块不同进程数下Alltoall的实测值与传统模型理论估值的差别太大,为方便比较,图4和图5中延迟值是实际数的对数值(2为幂)。图4和图5中的结果显示:(1)相比使用通信延迟和通信带宽的理论值,以实测值为参数,Alltoall理论值更接近于实测值;(2)即便以实测值为参数,Alltoall理论值的准确性有所提高,但仅在MPI进程数小于128时有效,超过128进程后实测值基本上是理论值的数倍,显示出传统的Alltoall模型在大规模并行时对于Alltoall的性能评估存在明显缺陷。
4.2 新Alltoall性能模型评估
表5和表6分别是4 KB消息块和16 KB消息块时Alltoall实测性能(延迟值)与理论预估的对比,分为单计算节点启动8个MPI进程和12个MPI进程两组,MPI并行规模从512进程至最大8 192进程。表中“原模型”为利用式(2)的估算结果,“新模型”为式(4)的估算结果。
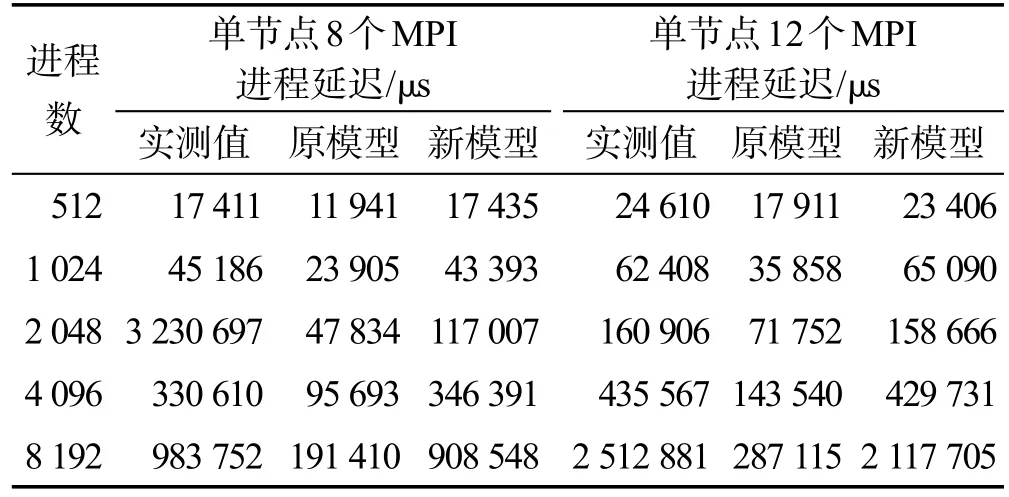
Table 5 Comparison of actual value and predicted value by differentAlltoall models(4 KB message)表5 Alltoall实测性能与理论值对比(4 KB消息块)
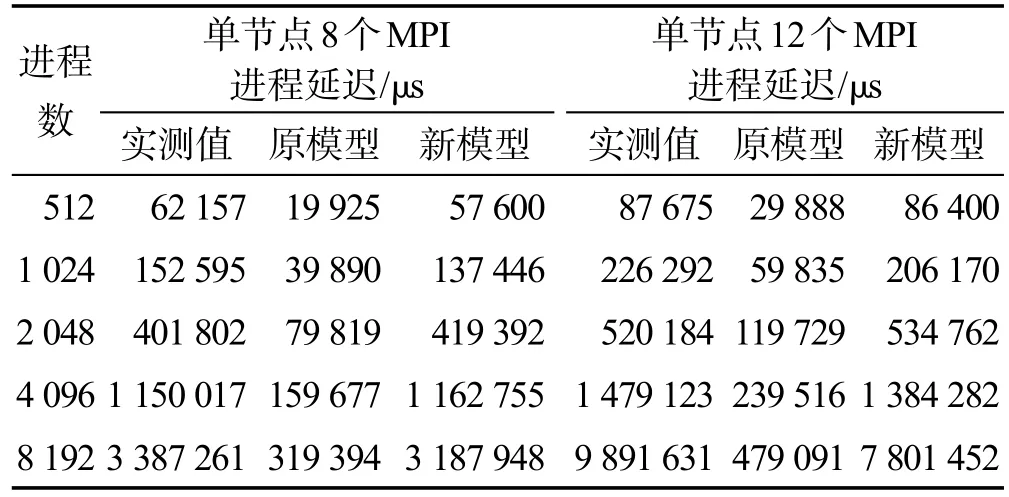
Table 6 Comparison of actual value and predicted value by differentAlltoall models(16 KB message)表6 Alltoall实测性能与理论值对比(16 KB消息块)
在理论估算中,通信延迟α,使用表1中的MPI通信延迟值和MPI单向通信带宽值,计算通信数据量时考虑单计算节点启动8个MPI进程和12个MPI进程对应到单个通信端口数据量的差别。在使用新模型时,依照数量传输量换算公式(3)的p值,其余参数选择表2中的数据。
表5和表6中的数据显示:(1)引入网络竞争后的Alltoall性能预估值与实测值非常接近,体现出网络竞争是可以预测的;(2)从数值上看,影响大规模Alltoall性能的主要因素是网络竞争开销,而网络的基本传输延迟和传输带宽的占比很小;(3)Alltoall性能实测时有时会有很大的波动,如表5中2 048个进程(单节点启动8个MPI进程)时Alltoall实测值存在明显的跳跃,这种现象是由于突发的网络拥塞造成的。
5 小结
综合以上测试和分析,不难看出:
(1)MPI通信性能对于底层互连通信系统性能的依赖性很强,并且与负载有关。尤其是对于Alltoall这种让所有参与通讯的进程进行彼此数据交换的集合通信操作,其性能对于底层互连通信系统的要求最高,最难实现非常好的可扩展性。
(2)预估Alltoall通信的理论值时,需要考虑网络竞争的影响,否则,无论是采用MPI的通信延迟和通信带宽的理论,还是采用实测值,都不一定能够反映出Alltoall的真实特性,尤其是面对大规模Alltoall操作。
(3)在大规模并行时,主导Alltoall性能的主要因素是网络竞争开销,而不是网络的基本传输延迟和传输带宽。
[1]Luszczek P,Dongarra J,KoesterD,et al.Introduction to the HPC challenge benchmark suite[R].Springfield:Lawrence Berkeley National Laboratory,2005.
[2]The CPMD Consortium.CPMD:Car-Parrinello molecular dynamics,Version3.15.3[EB/OL].(2015)[2016-07-30].http://cpmd.org/downloadable-files-authentication/manual.pdf.
[3]Rao Li,Zhang Yunquan,Li Yucheng.Performance test and analysis of Alltoall collective communication on domestic hundred trillion times cluster system[J].Computer Science,2010,37(8):186-188.
[4]Liu Yang,Cao Jianwen,Li Yucheng.Testing and analyzing of collective communication models[J].Computer Engineering andApplications,2006,42(9):30-33.
[5]Luo Hongbing,Zhang Xiaoxia.Analysis of scalability for MPI collective communication[J].Journal of Frontiers of Computer Science and Technology,2017,11(2):252-261.
[6]Xu Cong,Venkata M G,Graham R L,et al.SLOAVx:scalable logarithmic AlltoallV algorithm for hierarchical multicore systems[C]//Proceedings of the 13th International Symposium on Cluster,Cloud,and Grid Computing,Delft,May 13-16,2013.Washington:IEEE Computer Society,2013:369-376.
[7]Li Qiang,Sun Ninghui,Huo Zhigang,et al.Optimizing MPI Alltoall communications in multicore clusters[J].Journal of Computer Research and Development,2013,50(8):1744-1754.
[8]Bruck J,Ho C T,Kipnis S,et al.Efficient algorithms for all-to-all communications in multiport message-passing systems[J].IEEE Transactions on Parallel and Distributed Systems,1997,8(11):1143-1156.
[9]Kumar S,Mamidala A,Heidelberger P,et al.Optimization of MPI collective operations on the IBM blue gene/Q supercomputer[J].International Journal of High Performance ComputingApplications,2014,28(4):450-464.
[10]Mamadou H N,Nanri T,Murakami K,et al.Performance analysis and linear optimization modeling of all-to-all collective communication algorithms[C]//Proceedings of the 19th Symposium on Computer Architecture and High Performance Computing,Gramado,Oct 24-27,2007.Washington:IEEE Computer Society,2007:203-210.
[11]Chan E,Heimlich M,Purkayastha A,et al.Collective communication:theory,practice,and experience[J].Concurrency and Computation:Practice and Experience,2007,19(13):1749-1783.
[12]Culler D E,Karp R M,Patterson D,et al.LogP:a practical model of parallel computation[J].Communications of the ACM,1996,39(11):78-85.
[13]Alexanddrov A,Ionescu M F,Schauser K E,et al.LogGP:incorporating long messages into the LogP model-one step closer towards a realistic model for parallel computation[C]//Proceedings of the 7th Annual ACM Symposium on Parallel Algorithms and Architectures,Santa Barbara,Jul 17-19,1995.New York:ACM,1995:95-105.
[14]Duato J,Yalamanchili S,Ni L.Interconnection network:an engineering approach[M].Xie Lunguo,Zhang Minxuan,Dou Qiang,et al.Beijing:Publishing House of Electronics Industry,2004:341-345.
[15]Garofalakis J,Stergiou E.An analytical model for the performance evaluation of multistage interconnection networks with two class priorities[J].Future Generation Computer Systems,2013,29(1):114-129.
[16]Kruskal C P,Snir M.The performance of multistage interconnection networks for multiprocessors[J].IEEE Transactions on Computers,1983,32(12):1091-1098.
[17]Agarwal A.Limits on interconnection network performance[J].IEEE Transactions on Parallel and Distributed Systems,1991,2(4):398-412.
附中文参考文献:
[3]饶立,张云泉,李玉成.国产百万亿次机群系统Alltoall性能测试与分析[J].计算机科学,2010,37(8):186-188.
[4]刘洋,曹建文,李玉成.聚合通信模型的测试与分析[J].计算机工程与应用,2006,42(9):30-33.
[5]罗红兵,张晓霞.MPI集合通信性能可扩展性研究与分析[J].计算机科学与探索,2017,11(2):252-261.
[7]李强,孙凝晖,霍志刚,等.MPI Alltoall通信在多核机群中的优化[J].计算机研究与发展,2013,50(8):1744-1754.
[14]Duato J,YalamanchiliS,Ni L.并行计算机互连网络技术:一种工程方法[M].谢伦国,张民选,窦强,译.北京:电子工业出版社,2004:341-345.
猜你喜欢
中国教育网络(2022年8期)2022-12-21
汽车电器(2022年9期)2022-11-07
空间科学学报(2021年6期)2021-03-09
中国房地产业·下旬(2020年12期)2020-01-11
中国外汇(2019年11期)2019-08-27
教育与职业(下)(2019年7期)2019-08-15
电子制作(2018年23期)2018-12-26
中国管理信息化(2018年7期)2018-05-27
大陆桥视野·下(2016年11期)2017-02-28
山东工业技术(2016年7期)2016-04-08
