
基于语言学特征向量和词嵌入向量的汉语动词事件类型预测
2018-04-04 02:42刘洪超黄居仁侯仁魁李洪政
中文信息学报 2018年1期
刘洪超,黄居仁,侯仁魁,2,李洪政
(1. 香港理工大学 中文及双语学系,香港; 2. 鲁东大学文学院,山东 烟台 264001;3.北京师范大学 中文信息处理研究所,北京 100875)
0 引言
事件类型的研究由来已久,可以追溯到古希腊和古印度时期。亚里士多德时期,事件类型被明确提出[1]。Vendler根据[telic]、[durative]、[dynamic]这三个特征将事件类型划分为四种,如表1所示。

表1 Vendler (1967)事件类型[2]
事件类型实际上反映的是事件的内部时间结构(internal temporal structure)。内部时间结构包括几个不同的阶段(phase): 起点(inception)、续段(duration)和终点(final)[3-4]。而事件类型的划分事实上就是根据事件在各个时间阶段上表现出的特点进行的。
首先,根据在事件发生的过程中,事件是否具有同质性(homogeneity),将事件划分为状态的(stative)和非状态的(non-stative)。状态与其他三种事件类型的最大区别就在于其在发生过程中的同质性,状态没有起点和终点,在其发生的续段内,性质不发生任何变化。例如,Mary knows Tom. 因为Mary在任何时间都是认识Tom的,所以这个状态不随着时间发生变化。
其次,在非状态事件类型中,根据是否有界(telic),即是否具有起点和终点,可以将活动与其他两种事件类型区分开来。这里需要强调的是语言学上的有界和现实世界中的有界并不同。“run”本身的词义中并没有起点和终点,尽管一个人在现实世界中跑步有起点,最终也会有停止的终点。
最后,根据是否具有持续性(durative),可以将完成和达成区分开。达成没有持续性,其时间结构是点状,即起点和终点重合,因此也被称为点状事件(punctual)。完结事件,顾名思义,即事件发生并最终实现了某一个目标(attain a goal),比如“draw a circle”,既包含“draw”这个动作,又包含“a circle”这个最终的目标。
事件类型跟语言中的时间,尤其是体(aspect)有非常密切的关系。英语等屈折语言有相对丰富的时体标记,但是汉语中时体标记相对较少。因此,通过事件类型来认识汉语时体非常有必要,对于自然语言处理,尤其是机器翻译等有较为重要的意义。
展开讨论前,需要廓清本文的几个基本问题:
第一,动词、短语和句子都可以按照内部时间结构划分事件类型,事件类型具有组合性。我们同意文献[4]关于事件结构(event structure)的看法: 事件结构与论元结构(argument structure)和物性结构(qualia structure)一样,都是词语语义实现(semantic specification)的层面之一,都具有递归性;由于递归性的存在,从词语到短语和句子,都具有事件类型的属性。
第二,事件类型具有组合性。正如动词与动词的组合不一定是动词性短语一样,词语的事件类型与其组成的短语的事件类型并不一定相同[4]。如“破”的事件类型是“状态”,但是“破了”作为一个整体,其事件类型是“变化”。我们不同意将组成成分的事件类型与结构整体事件类型混淆的观点。以往不少研究就是没有认清事件类型的组合性和递归性,要么将整个结构的事件类型强加给其中的动词,如文献[5-8],要么就是将事件类型换了个名字,如文献[4]用体特征值(aspectual value)代替了事件类型,但是本质上却是一样的。
第三,事件类型所涉及的最小单位是词语的义项。事件结构是结构的语义层面之一,因此是由语义决定的,对于词语来说,就是由词义决定的。同一个动词有不同的义项,不同的义项可能对应不同的事件类型,从词语层面来讲,一个动词很可能同时具有多种事件类型。如动词“去”有三个义项,分别是“除去,去掉”(去皮);“从所在地到别的地方”(去了三次);“从事,做”(去讨论一下)。这三个义项分别对应了三种事件类型,第一个义项的事件类型是“状态”,第二个义项的事件类型是“变化”,第三个义项的事件类型是“状态”。
第四,本文不将体强迫现象(aspectual coercion)纳入考虑范围之内,如,“He played the sonata for one day.”如果不考虑体强迫,则事实上不合语法。因为“played the sonata”是一个完结事件,不能受持续性状语(durative adverbials)修饰。但是如果谓语事件类型随着持续性状语进行调整,即赋予“played the sonata”一个反复义(iterative interpretation),则又变得可以接受了。
体强迫(aspectual coercion)是非常有趣的现象,但是其事件类型的预测更多地与语用相关,超出了本文的研究范围。本文主要涉及的是非体强迫句中的汉语动词的事件类型。
本文研究的是汉语动词的事件类型,事件类型的组合性及其向量化表示将在另外一篇文章讨论。
1 汉语动词事件类型的标注
汉语动词事件类型的标注主要包括了三个步骤,即动词的选取、事件类型标注体系的确定及事件类型的标注。下文将分别介绍。
本文所选择的动词全部来自《汉语动词用法词典》[10]。词典从《现代汉语词典》[11]选择1223个动词,共划分出两千多个义项。
虽然词典中的动词都是以义项存在,但是语料库中的词语却只有词形及其词性标记,语料库中的词语及其词性标记与义项之间并没有规律性的对应关系。因此,只能对所有的动词,按照在语料库中的词性标记重新建立词条,对这些词条进行逐一标注。本文所使用的语料库为台湾中央研究院语料库[12],建立词条主要包括以下几步:
第一步,从台湾中央研究院语料库中抽取《汉语动词用法词典》收录的所有词形及其PoS。如果一个词形对应多个PoS则视为不同的词处理。如“长”有两个词性标记,VC和VH分别对应zhang3和chang2。这实际上是两个词,需要分别记录。
第二步,抽取第一步保留的动词在台湾中央研究院语料库中的所有例句,按照句子和《汉语动词用法词典》中的义项描述判定动词的语义或义项归属。如“除”有两个记录,一个PoS是VC,对应的例句表示的意义是“去掉”;另一个的PoS是VJ,对应的例句表示的是“用一个数把另一个数分为若干份”。对应这两个词性标记分别建立词条。
建立词条之后再对照文献[3]标注的动词事件类型进行标注就变得相对简单了。文献[3]对《汉语动词用法词典》中的所有义项进行了事件类型的标注。表2是其事件类型及其语言学特征。

表2 文献[3]事件类型及其语言学特征
注释: I表示“开始”(inception);F表示“结束”(final);TP表示“时间短语”。
文献[13]又进一步合并了上表中的事件类型,形成了一个事件类型体系,如图1所示。

图1 文献[13]的事件类型分类体系
本文并没有照搬文献[3]的事件类型体系,而是对其进行了验证和调整。
文献[3]的事件类型划分是以动词能否与其选择的体标记词(aspectual marker)共现,以及共现后表示的语义划分的事件类型,那么这种划分就是可以用计算方法验证的。验证实验的基本假设是按照文献[3]对事件类型及其与特征词的共现情况构建矩阵,那么按照语义距离形成的层级分类体系应当与文献[13]的层级分类体系相似。
表3是按照表2构建的矩阵。

表3 文献[3]的事件类型小类与其语言学特征矩阵

续表
注释: I表示“开始”(inception);F表示“结束”(final);T表示“时间短语”
以此矩阵为基础进行的层次聚类如下: 我们用同表象相关系数(CPCC,cophenetic correlation coefficient)来衡量聚类的好坏。CPCC主要是衡量未经建模的原始矩阵和建模之后的矩阵之间的相似度,后者代表的是层次聚类算法的矩阵[14-15]。实际上CPCC可以表示层次聚类算法所使用的矩阵在多大程度上保留了原始矩阵的信息。这个值越接近1,表明层次聚类采用的矩阵与原始矩阵之间的相似度越高。聚类结果如图2所示。

图2 文献[3]的典型事件类型聚类结果
上图结果的CPCC为0.85,表明聚类结果令人满意。从上图可以看出,Vb与Vc1的语义距离最近,Vc2与Vc3的语义距离最近,Vb、Vc1、Vc2和Vc3又聚成一个大类;Vc4与Vc5的语义距离最近,两者组成一个类别;Vd2和Ve的语义距离最近,Vd1、Vd2和Ve组成了一个大类;Va单独成类。
这基本上与文献[13]的分类一致。Vb、Vc1、Vc2和Vc3组成了“状态”;Vc4和Vc5组成“活动”;Vd1、Vd2和Ve组成“变化”。但是也有几点不同:
首先,文献[13]将Vc3归入activity,但是根据语义距离的计算,Vc3与Vc2的相似性更大,而不是Vc4。文献[3]事实上指出过,Vc1、Vc2和Vc3在以往的研究中都属于状态动词,但是他认为Vc3的“动作性已经非常强”。可是事实上,如果严格按照文献[3]提出的标准进行划类,则类似“爱”、“病”和“承担”这类Vc3词,事实上应当与Vc2和Vc1归入一类,同属于“状态”。
其次,文献[3]和文献[13]都将Va归入“状态”,但是层次聚类将其单独列为一类。Va是一个比较特殊的类别,其内部的词如“是”、“等于”和“敢”等表示的是一种绝对的状态,文献[6]将之称为“绝对状态动词”(absolute stative verb),这类词与其他状态动词的最大区别是无法用“很”进行修饰。
再次,文献[3]和文献[13]将“活动”和“变化”合并为“非状态动词”,而层次聚类的结果表明,“状态”跟“活动”的距离更近。
这实际上不能说是两者的不同,因为按照文献[2]提出的标准,完全可以将“状态”和“活动”合并为“无界动词”(non-telic verb),而将“变化”(包括“完结”和“达成”)称为“有界动词”(telic verbs)。由于文献[2]提出了telic、dynamic(或stative)和durative三个要素来区分三者,所以怎么样合并“状态”、“活动”和“变化”,实际上取决于采取什么样的观察角度,即首先使用哪个要素来对三者进行划类。如果按照文献[3]的标准,从语义距离上说,“状态”跟“活动”更相似,也就是文献[3]的标准实际上更接近于使用[telic]作为首次划类的标准。
所以实际需要解决的问题是Va和Vc3的归类问题。后文将通过多元逻辑回归分析证明,Va和Vc3归入state是较为合适的。
所以最终,本文所采用的分类体系实际上如下:
A. 状态: Va, Vb, Vc2, Vc3
B. 活动: Vc4, Vc5
C. 变化: Vd1, Vd2, Ve
最后一个问题是,文献[3]只是对占数据集绝大多数的10个典型类别进行了划类,对于剩余的29个其他例外类别并没有进行划类。之所以称之为例外类别,并不是因为这些类别不能通过选择的语言学特征来衡量,而是它们与选择的特征词的共现情况与10个典型的类别都不一致,所以无法对之进行归类。
但是通过层次聚类则可以解决这一点,层次聚类会按照语义距离对所有的类别进行聚类,结果如图3所示。
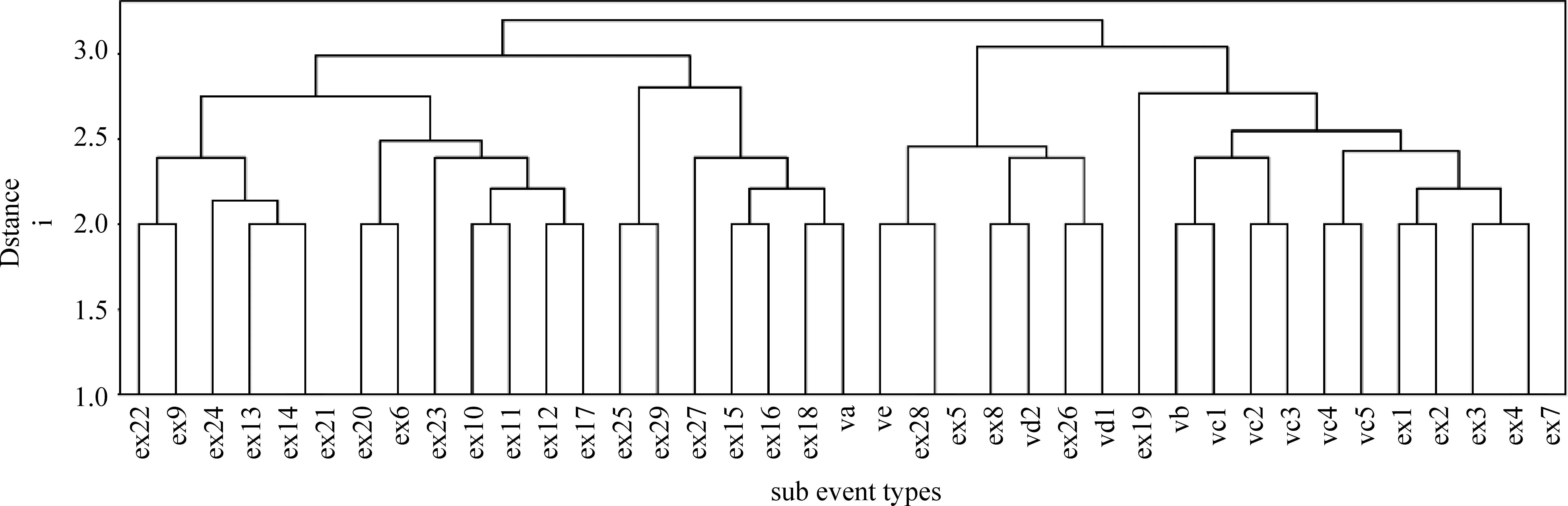
图3 文献[3]所有事件类型的聚类结果
CPCC为0.75,表明聚类结果也是令人满意的。例如,ex1与Vc4和Vc5的语义距离最近,因此可以归入“活动”,ex1包括的词如“表决”、“挑拨”及“提倡”;再如ex18与Va的语义距离最近,可以归为一类,ex18包含的词如“叫”(他叫张三)、“愿意”及“尊敬”等。
如此一来,所有的例外类别也都按照与典型类别的语义距离划入了相应的典型事件类型中去。本文所使用的标注体系也最终确定下来。我们采用人工标注的方式,对由台湾中央研究院语料库和《汉语动词用法词典》对照产生的各个词条进行了事件类型的标注,基本统计情况如表4所示。

表4 事件类型分布状况
3 汉语动词事件类型的预测
事件类型的预测是非常困难也很有意义的任务[16]。其困难在于即便是人工对其判定,未经训练的标注者准确率也非常低,只有经过专门的语言学训练的可靠标注者,准确率才令人满意。文献[16]采用“众包”(crowd sourcing)的方式对意大利语进行事件类型的标注试验,经过与金标准(golden standard)对比发现,普通标注者的准确率只有43%,而经过语言学训练的可靠标注者(trusted rater)准确率可以达到93%。
Siegel[17]是较早进行英语事件类型预测的研究者之一。他选择了14个语言学特征用于构建矩阵,在此基础上采用了决策树(decision tree)、逻辑回归(logistics regression)和基因编程(genetic programming)分类器实现了动词事件类型的预测,表5是其对“状态”和“非状态”(他称之为event)的区分。
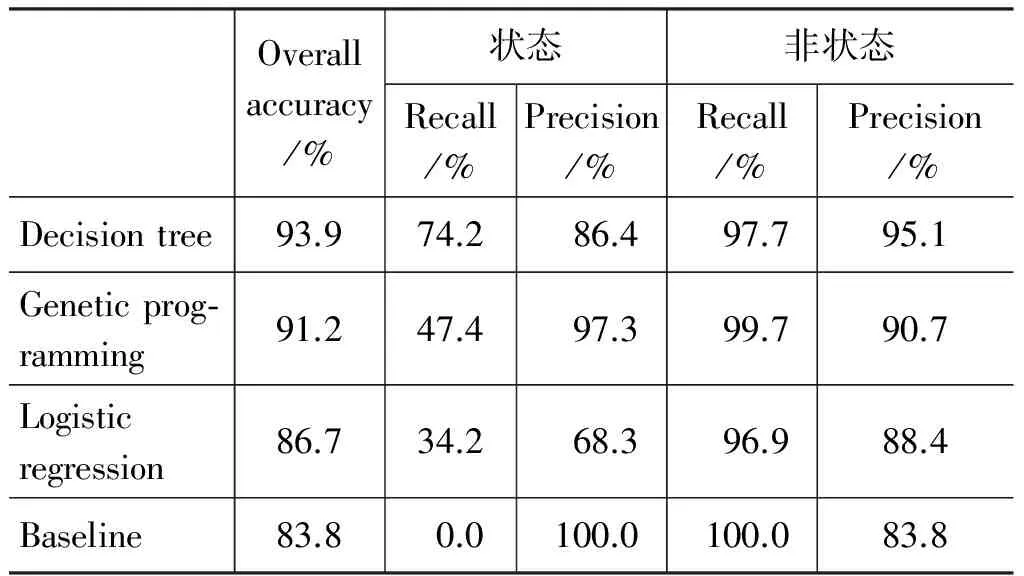
表5 文献[17]区分“状态”和“非状态”结果
但是也存在一些问题。
正如文献[7]所指出的,文献[17]分开两次进行分类试验,没有测试模型在多分类任务上的总体准确率。第二次试验通过分类回归树(classification and regression tree,CART)达到了最高的准确率74%(Basline: 63.3%);两次试验采用的均是hold out检验法,即简单地将数据集分为了训练集和测试集,这种方法对模型的验证说服力不强,应当进行K-fold cross validation。
文献[7]采用了两种方法构建用于事件类型分类的特征。一种是有监督的方法,一种是无监督的方法。其中有监督的方法通过在对动词标注大量的句法信息包括论元结构等构建向量矩阵,最终实现了85.4%的总体准确率;采用无监督的方法构造向量矩阵主要是基于分布式语义模型,通过抽取上下文(一定窗口范围内)的共现词频率来构建矩阵,最终实现了72.5%的准确率。
但是关于汉语动词事件类型预测的研究几乎没有。而且汉语的识别难度要高于英语和意大利语。这两者都是屈折语,带有丰富的屈折语标记,所以可以直接使用这些标记进行预测,取得较高的识别效果。但是汉语几乎没有这样的标记,根据以往的语言学研究如文献[3,6,13,18-20]等,只能发现“很”“在”“正在”“着”“了”“过”等几个体标记(aspectual marker)。
本文通过两种方式构建动词事件类型的特征矩阵。一种是使用语言学特征构建向量矩阵,另一种是使用word2vec构建向量矩阵。下面将分别介绍通过这种方式构建向量矩阵实现动词事件类型的预测过程。
对于语言学特征,本文选择了“很”“在”“正在”“着”“了”“过”及动词在台湾中央研究院语料库中的频率信息。值得注意的是,除了“很”之外,其他几个体标记都有同形词,如“在”既可以是介词(在家里),也可以是体标记(在吃饭),依靠词性标记可以将之区分开,特征词及其词性标记如表6所示。

表6 特征词及其词性标记
前文提及了只有将Va和Vc3归入“状态”才是较为合适的做法,这可以通过构建的语言学特征向量矩阵进行验证。既然文献[3]提出的事件类型都是按照其提出的语言学特征进行归类,那么如果依靠这些特征构建出的动词的特征向量应该可以实现动词事件类型的预测。我们采用动词与目标词的共现频率作为特征向量值。共现频率的计算是在台湾中央研究院的精标语料库上实现的。我们采用了多元逻辑回归分析来验证两者之间的关系。
实验的基本假设是,如果Va和Vc3归入“状态”才是较为合适的,那么使用选择的语言学特征就可以拟合出比随机模型好的多元逻辑回归模型;同时,将Va和Vc3归入其他事件类型,则不能实现比随机模型好的多元逻辑回归模型。
多元逻辑回归是逻辑回归的一种,使用最大似然估计出相关参数。使用多元逻辑回归对自变量和因变量进行分析时,需要先进行似然比检验,以确定特征的有效性,其基本原理就是通过引入了特征的模型和未引入特征的随机模型进行对比。由于两者似然值的差值服从χ2分布,因此可以借助该统计检验量来验证模型的有效性。
表7是将Va和Vc3归入“状态”时的似然比检验结果。

表7 将Va和Vc3归入“状态”时的似然比检验结果
p值表明模型是有效的,我们也检验了将Va和Vc3放入其他类别,p值都为1.00,这表明模型都是无效的。由于篇幅原因,不再具体展开。由此证明,Va和Vc3应当归入“状态”。
作为对比,本文引入了词性标记的语言学特征向量。基于这些语言学特征向量矩阵,除多元逻辑回归外,本文进一步使用支持向量机和人工神经网络分类器对标注的数据集进行了分类试验,所有的实现使用的都是十折交叉检验。表8是各个分类器在选择不同特征的情况下实现的总体准确率(overall accuracy):

表8 基于语言学特征向量的试验结果
注: MNLogit表示多元逻辑回归;SVM表示支持向量机;ANN表示人工神经网络。
仅仅使用体标记副词(aspectual adverb)基于多元逻辑回归了65.4%的准确率;作为对比的词性标记(PoS)基于多元逻辑回归实现了67.83%的准确率,单单从数字上看,似乎使用词性标记效果好于使用体标记副词,但是使用配对样本检验结果表明两者的差异并不具有显著性,如表9~10所示。

表9 MNLogit(adv)和MNLogit(PoS)试验结果统计

表10 MNLogit(adv)和MNLogit(PoS)试验结果配对样本t检验结果
所以两种特征在预测动词事件类型的能力上都相似。将所有特征考虑进来,实现了最高69.32%的整体准确率,与其他情况进行配对t检验表明,差异是显著的。
基于aspectual marker等共现词来判定动词的事件类型实际上是在某种程度上根据上下文来预测动词的事件类型,只是这里的上下文是经过了筛选的上下文。筛选工作是由语言学家进行的,但是这些信息很有可能是不全的,缺失的信息在一定程度上会影响动词事件类型的预测准确率。
既然很难将能够影响动词事件类型的所有上下文信息依靠人工的方式挑选出来,那么解决这个问题的一个办法是把上下文的所有信息都用来预测动词的事件类型。其理论基础就是分布式语义假设。
Distributional semantic hypothesis认为出现在相似的上下文中的词,在语义上更加相近[21]。基于分布式语义假设构建的词与上下文共现词形成矩阵就称为分布式语义模型。由于基于上下文共现词不需要人工的选择,因此是一种非常好的无监督构建向量矩阵的方法,并且目前在多种任务上都被证明有相当不错的表现[22-23]。
基于分布式语义假设,我们的推断是: 上下文相似的动词,其事件类型也相似。我们选择了与当前动词的距离为5(左5,右5)的所有的上下文,通过word2vec构建了500维的向量矩阵。Word embedding向量是在sinica corpus[12]及Chinese Gigaword corpus[24]上训练完成。所有的词性标记都与Sinica corpus一致。
分别采用多元逻辑回归、人工神经网络和支持向量机作为分类器进行了试验,模型的整体准确率如表11所示。
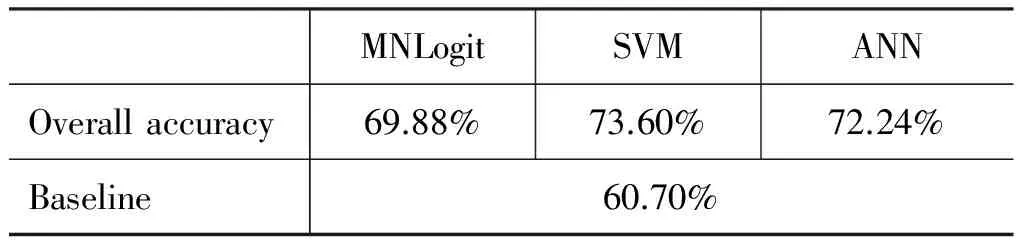
表11 基于词嵌入向量的动词事件类型预测效果
可以看出,使用支持向量机作为分类器达到了最高的分类准确率73.60%,比Baseline高12.9%,比使用语言学特征的模型的最高准确率69.32%,高4.3%。下面我们用配对t检验检查差异是否是显著的,如表12所示。
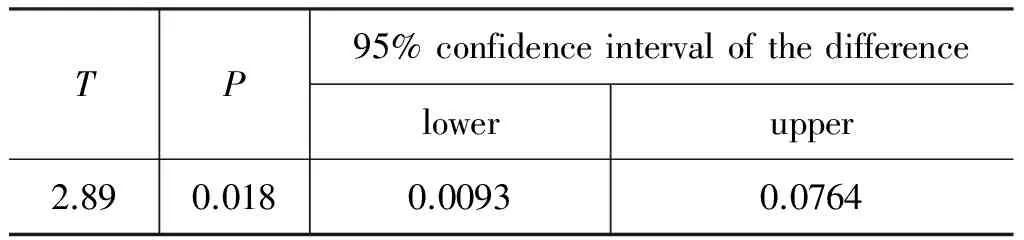
表12 SVM(word2vec)和MNLotgit(adv+freq+pos)的配对t检验结果
统计结果显示,使用无监督方式构造的上下文向量构建的模型,其预测准确率显著地高于使用语言学特征构建的模型。表13中是每个小类的分类效果。

表13 基于word2vec的支持向量机分类结果
4 结语
本文分别基于语言学特征向量和词嵌入向量实现了动词事件类型的预测,本文的主要贡献有:
第一,基于文献[3]对《汉语动词用法词典》重新标注和验证了动词事件类型,形成了总量达到1 610个的汉语动词事件类型数据集,可以直接用于相关模型的训练和评价;
第二,实现了汉语动词事件类型的预测,最高准确率达到73.60%。
我们的未来工作将集中于短语和句子事件类型的识别。
[1]Binnick R I. Time and the verb: A guide to tense and aspect[M]. Oxford: Oxford University Press,1991.
[2]Vendler Z. Linguistics and philosophy[M]. New York: Cornell University Press,1967.
[3]郭锐.汉语动词的过程结构[J].中国语文, 1993,6: 410-419.
[4]Pustejovsky J. The syntax of event structure[J]. Cognition, 1991,41(1): 47-81.
[5]Smith C S. The parameter of aspect[M]. Berlin: Springer Science & Business Media,1991.
[6]He B. Situation types and aspectual classes of verbs in Mandarin Chinese[D]. The Ohio State University Ph.D.thesis, 1992.
[7]Zarcone A, A Lenci. Computational Models for Event Type Classification in Context[C]//Proceedings of LREC. 2008.
[8]Xu H. The Chinese aspectual system[D]. The Hong Kong Polytechnic University Ph.D.thesis, 2015.
[9]Verkuyl H J. On the compositional nature of the aspects[M]. Dordrecht: Reidel, 1972.
[10]孟琮.汉语动词用法词典[M].北京: 商务印书馆, 1982.
[11]中国社会科学院语言研究所词典编辑, 现代汉语词典[M]. 北京: 商务印书馆, 1990.
[12]Chen K-J, et al. Sinica corpus: Design methodology for balanced corpora[J]. Language, 1996. 167: 176.
[13]郭锐.过程和非过程--汉语谓词性成分的两种外在时间类型[J].中国语文, 1997,(3): 162-175.
[14]Hou R, M Jiang. Analysis on Chinese quantitative stylistic features based on text mining[J]. Digital Scholarship in the Humanities, 2014: 67.
[15]Hou R, J Yang, M Jiang. A Study on Chinese Quantitative Stylistic Features and Relation Among Different Styles Based on Text Clustering[J]. Journal of Quantitative Linguistics, 2014. 21(3): 246-280.
[16]Tommaso C, C-R Huang. Sourcing the Crowd for a Few Good Ones: Event Type Detection[C]//Proceedings of COLING. 2012.
[17]Siegel E V. Linguistic indicators for language understanding: using machine learning methods to combine corpus-based indicators for aspectual classification of clauses[D]. Columbia University Ph.D.thesis, 1998.
[18]Tai J. Verbs and times in Chinese: Vendler’s four categories[C]//Proceedings of the parasession on lexical semantics. 1984.
[19]邓守信. 汉语动词的时间结构[J].语言教学与研究, 1985,(4): 7-17.
[20]陈平. 论现代汉语时间系统的三元结构[J].中国语文, 1988,6: 22.
[21]Harris Z S. Distributional structure[J]. Word, 1954,10(2-3): 146--162.
[22]Liu H, et al. EVALution-MAN: A Chinese Dataset for the Training and Evaluation of DSMs[C]//Proceedings of the Tenth International Conference on Language Resources and Evaluation.Paris: European Language Resources Association (ELRA), 2016.
[23]Santus E, et al.EVALution 1.0: an Evolving Semantic Dataset for Training and Evaluation of Distributional Semantic Models[C]//Proceedings of ACL-IJCNLP 2015, 2015.
[24]Hong J-F, C-R Huang. Using chinese gigaword corpus and chinese word sketch in linguistic research[C]//Proceedings of the 20th Pacific Asia Conference on Language, Information and Computation (PACLIC-20).2006.
猜你喜欢
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
天津外国语大学学报(2021年1期)2021-03-29
农业科技与信息(2021年2期)2021-03-27
天津外国语大学学报(2020年4期)2020-08-24
开放教育研究(2020年2期)2020-03-31
中国交通信息化(2018年5期)2018-08-21
中国修辞(2017年0期)2017-01-31
中国社会历史评论(2016年2期)2016-06-27
辞书研究(2016年5期)2016-05-14
