
最小化随机分组方法介绍及其SAS实现
2018-03-30 07:58赵丽君李宏田段蜚藩廖紫珺周玉博刘建蒙
中国生育健康杂志 2018年2期
赵丽君 李宏田 段蜚藩 廖紫珺 周玉博 刘建蒙
Zhao Lijun, Li Hongtian, Duan Feifan, Liao Zijun, Zhou Yubo, Liu Jianmeng.
随机分组主要目的是保证临床试验组间基线特征分布均衡,以最大限度控制干扰因素影响,更科学地估计干预效应。随机分组方法可分为简单随机分组、区组随机分组、分层随机分组和动态随机分组。简单随机分组和区组随机分组较为常见,但未对非处理因素加以限制,样本量少时难以保证组间特征的均衡。分层随机分组能较好实现分层因素的组间均衡,但不能控制较多因素。如考虑4个分层因素,每个因素3水平,则需分成34=81层。分层数量多不仅难于实施,更可能出现某些层内无病例的情况,无法达到均衡分层因素的目的。
动态随机分组指研究对象被分到各组的概率随一定条件而动态调整的方法,最小化法(minimization)是其中较为常见的一种。最小化法自提出以来就备受关注,被誉为临床试验的“铂金标准”[1]。其均衡能力强,在小样本及有多个重要预后因素的临床试验中优势尤为突出。如在孕产期疾病治疗的临床试验中,产妇的年龄、孕周、孕产史等因素对治疗效果影响较大,而试验例数往往有限,采用最小化法较其他方法更能均衡各组预后因素分布,提高研究效率。尽管优势明显,最小化法应用并不广泛,可能与其原理不如简单随机分组和区组随机分组直观易解、实施过程相对繁复有关。国内关于最小化法的研究多局限于阐述其思想原理及优缺点[2-3],对其如何实施应用的介绍少见。本文将通过模拟实例阐述最小化法基本原理及运算过程,并编制了专用SAS宏程序,供研究者在临床试验中参考使用。
资料与方法
通过查阅国内外相关文献,综述最小化法的基本原理及其运算过程。利用一个简单的模拟实例说明最小化法的具体运算过程,编制专用的SAS宏程序,并给出模拟实例的分组结果作为参考。
模拟实例为某两组设计的子痫前期药物临床试验,已知产妇年龄(Age)、治疗时孕周(GA)、既往子痫前期病史(History)三个非处理因素对结局有重要影响,希望其分布在各组趋于均衡。已入组的14个病例的分组结果(Group)如表1所示。现第15例患者为32岁,治疗时孕周为33周,无既往子痫前期病史。
表1前15个病例的预后因素水平及分组情况
Table1The levels of prognostic factors and treatment assignments of the first 15 patients
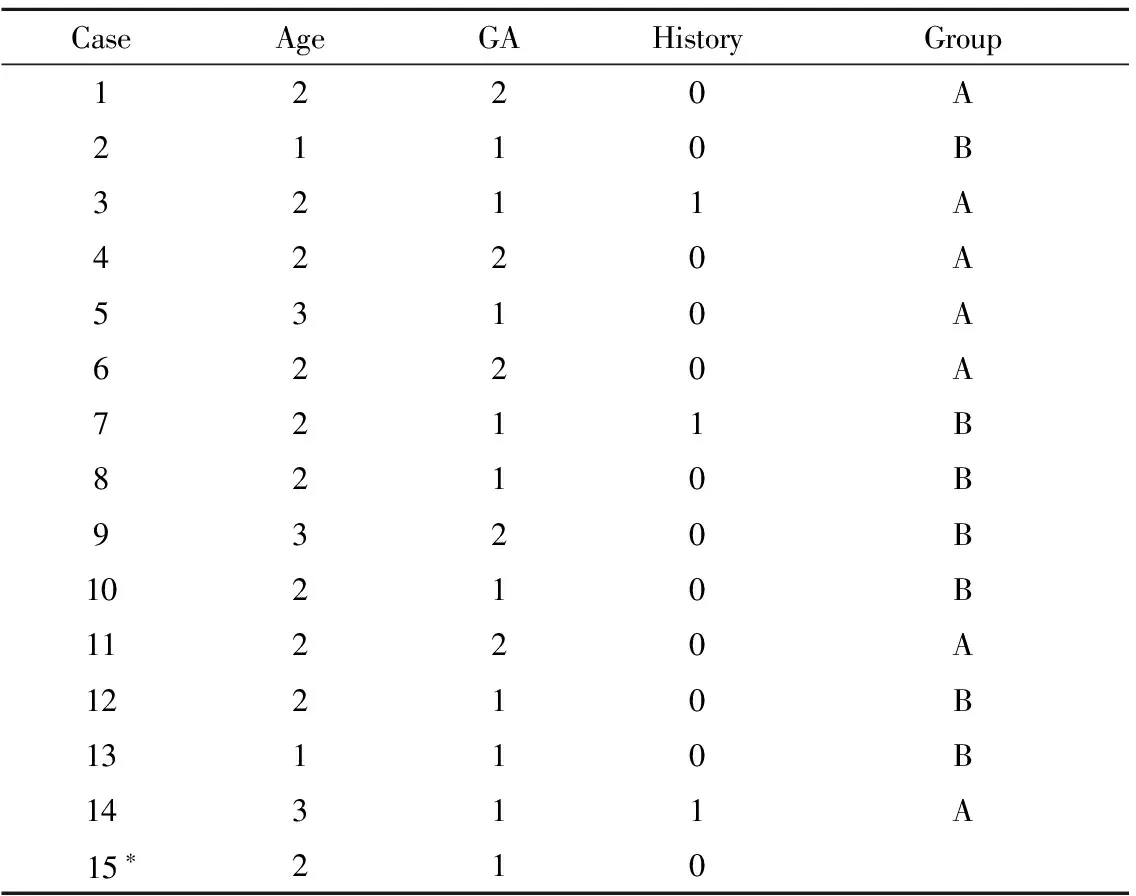
CaseAgeGAHistoryGroup1220A2110B3211A4220A5310A6220A7211B8210B9320B10210B11220A12210B13110B14311A15∗210
Value label:Age (1=“≤19 years”, 2=“19<~≤34 years”, 3=“>34 years”); GA (1=“<34 weeks”, 2=“≥34 weeks”); History (1=“Yes”, 0=“No”).*The variable “Group” was empty in the 15th case, indicating that the assignment result of this case was unknown.
结 果
一、方法综述
最小化法由Taves[4]于1974年提出并命名。其基本原理是:在试验开始前确定对结果有重要影响的预后因素,根据已入组病例预后因素的组间分布情况,将新病例分到使组间预后因素分布差异最小的一组中;当预后因素组间分布无差异时,新病例按等概率随机分配。
Pocock和Simon[5]于1975年用参数形式介绍了更为广义的最小化法。它根据三个参数确定病例的分组:因素不平衡函数(D)、总体不平衡函数(G)、最优分配概率(P)。因素不平衡函数指某一预后因素中与新病例相同的水平在各组分布的不均衡性,常用极差或方差表示。总体不平衡函数代表所有因素不平衡函数的总和,一般采用因素不平衡函数的直接求和;对于需要区分因素重要性的情况则采用因素不平衡函数的加权求和,需要设定因素权重(w)。最优分配概率指新病例分配到目标组(使组间差异最小的组)的概率。P=1时,新病例直接分配到目标组;P=a(0 当Pocock和Simon法参数设定为利用极差表示因素不平衡函数、各个因素不加权、且最优分配概率为1时,即为Taves提出的最小化法。目前,最小化法一般指Pocock和Simon最小化法。 二、分组运算过程 以下是利用最小化法对模拟实例进行分组运算的过程。首先将收集到的原始信息(表1)整理得到预后因素分布信息,如表2。 表2已入组的14例患者预后因素分布情况(例) Table2Distribution of prognostic factors of the first 14 patients by groups (n) PrognosticfactorsGroupAGroupBAge(year) ≤1902 19<~≤3454 >3421GA(week) <3436 ≥3441History Yes21 No56 按照Pocock和Simon最小化法设定相关参数:如采用极差表示因素不平衡函数;年龄、孕周、病史的权重分别设为1、2、3;最优分配概率P取0.8。首先计算各因素不平衡函数,A组和B组中与新病例(第15例患者)年龄在相同水平的各有5例和4例,当新病例分配到A组时,A组在该年龄水平上有(5+1)例,因此两组在该年龄水平上的极差(即年龄的因素不平衡函数)为D(age)=|(5+1)-4|=2;其他因素不平衡函数以此类推。对各因素不平衡函数进行加权求和,当新病例分配到A组时,总体不平衡函数G(A)= |(5+1)-4|×1+|(3+1)-6|×2+|(5+1)-6|×3=6;当新病例分配到B组时,总体不平衡函数G(B)= |(4+1)-5|×1+|(6+1)-3|×2+|(6+1)-5|×3=14。比较各组总体不平衡函数的大小,G(A)< G(B),则A组为目标组。将新病例按概率0.8分配到A组,概率0.2分配到B组。实现该种不等概率分组的方法很多,最简单的为生成一个范围在0~1的随机数,若该随机数在0~0.80范围则将新病例分配到A组,在0.81~1范围则分配到B组。 三、SAS宏程序 /*调用宏前的准备*/ /*定义宏变量*/ /*说明:Dataset指拟分组的数据集;GroupAll指试验组变量名;Group_n指试验组的个数;FactorAll指预后因素变量名;Factor_n指预后因素的个数;WeightAll指预后因素的权重(与FactorAll顺序一一对应);P指新病例分到各试验组的概率,按G从小到大顺序分别为p1、p2、p3,满足p1>p2>=p3,p1+p2+p3=1;Seed指生成随机数所用的参数,可取小于231-1的任意常数*/ %LET Dataset=CaseN; %LET GroupAll=%str(group1 group2 group3); %LET Group_n=3; %LET FactorAll=%str(factor1 factor2 factor3 factor4); %LET Factor_n=4; %LET WeightAll=%str(weight1 weight2 weight3 weight4); %LET P=%str(p1 p2 p3); %LET Seed=constant; /*宏主体及解释*/ /*宏名称为Minimization, 由3步生成*/ %MACRO Minimization; /*步骤1.计算新病例分配到各组时的总体不平衡函数G*/ %MACRO Stepa; DATA result; LENGTH Group $10. G 8; STOP; RUN; %DO i= 1 %TO &Group_n; %LET Group=%SCAN(&GroupAll, &i); %LET G=0; %DO j= 1 %TO &Factor_n; %LET Factor=%SCAN(&FactorAll, &j); %LET Weight=%SCAN(&WeightAll, &j); DATA Group_&Group; SET newcase end=eof; IF eof THEN Group="&Group"; IF eof THEN CALL SYMPUT("factor_x",&factor); RUN; PROC SQL NOPRINT; CREATE TABLE &factor AS SELECT Group, COUNT(&factor) AS n FROM Group_&Group WHERE &factor=&factor_x GROUP BY Group; SELECT range(n) INTO:d FROM &factor; DROP TABLE &factor; QUIT; %LET G=%EVAL(&G+&d*&weight); %END; DATA result_&Group; Group="&Group"; G=&G; RUN; DATA result; SET result result_&Group; RUN; %END; %MEND; /*步骤2.比较G的大小,计算并储存分组结果*/ %MACRO Stepb; PROC SQL NOPRINT; SELECT range(G) INTO:r FROM result; QUIT; DATA result; SET result; PROC SORT; BY G; RUN; DATA result; SET result; rank=_n_; IF rank=1 THEN CALL SYMPUT("target_1",Group); IF rank=2 THEN CALL SYMPUT("target_2",Group); IF rank=3 THEN CALL SYMPUT("target_3",Group); RUN; %DO k= 1 %TO &Group_n; %LET P_&k=%SCAN(&P, &k, " "); %END; %LET ep=%sysevalf(1/&Group_n); DATA &Dataset; SET &Dataset; randnum=RANUNI(&Seed); IF _n_=&newcase_n THEN DO; IF &r!0 THEN DO; IF randnum<=&p_1 THEN Group="&target_1"; IF (randnum>&p_1 & randnum<=(&p_1+&p_2)) THEN Group="&target_2"; IF randnum>(&p_1+&p_2) THEN Group="&target_3"; END; IF &r=0 THEN DO; IF randnum<=&ep THEN Group="&target_1"; IF (randnum>&ep & randnum<=%sysevalf(2*&ep)) THEN Group="&target_2"; IF randnum>%sysevalf(2*&ep) THEN Group="&target_3"; END; END; DROP randnum; RUN; %MEND; /*步骤3.循环运算,实现批量分组*/ %MACRO Stepc; DATA &Dataset; SET &Dataset end=eof; IF eof THEN CALL SYMPUT("total_n",_n_); RUN; PROC SQL NOPRINT; SELECT COUNT(Group) INTO:oldcase_n FROM &Dataset; QUIT; %DO %WHILE (%eval(&total_n-&oldcase_n)); %LET newcase_n=%EVAL(&oldcase_n+1); DATA newcase; SET &Dataset(OBS=&newcase_n); RUN; %Stepa; %Stepb; %LET oldcase_n=&newcase_n; %END; %MEND; %Stepc; %MEND; %Minimization; 四、模拟实例分组结果 以模拟实例数据为例(表1),如储存数据的文件名为Example,相关宏变量设定为:%LET Dataset=Example; %LET GroupAll=%str(A B); %LET Group_n=2; %LET FactorAll=%str(Age GA History); %LET Factor_n=3; %LET WeightAll=%str(1 2 3); %LET P=%str(0.8 0.2); %LET Seed=1; 运行上述宏程序后第15个病例会被分到B组。 最小化法主要优势在于能保证多个预后因素组间分布均衡。在小样本试验(如100例以内)中最小化法均衡能力总是优于简单随机分组和区组随机分组[7]。与分层随机分组相比,当预后因素较多(如3个以上)时,最小化法的均衡能力明显较高,可同时考虑10到20个预后因素[8]。其不仅适用于个体临床试验,在基线特征复杂且样本量往往有限的整群随机试验中优势也尤为突出[9]。 实施过程复杂是影响最小化法使用的一个重要方面。最小化法不像简单随机分组和区组随机分组等方法能在试验开始前一次性得到所有病例的分组结果,而需在试验过程中对每一名新入组病例重复分组运算过程,操作较为繁复,对临床试验的组织管理亦是一个挑战。有学者建议最小化法配合计算机使用[5]。本文通过编制SAS宏程序,可大大提高分组运算效率。在依照运算原理计算出每个新病例分组结果的基础上,程序还设计了循环运算,可实现批量分组,即研究者可在收集若干名新病例预后因素信息后一次性确定其分组结果。如在模拟实例中,前14名病例分组结果已确定,假如第15至20名病例都已收集预后因素信息,但尚未进行分组。此时运行宏程序,则程序先根据前14名病例特征分布情况计算第15名病例分组信息并存入原数据集中,再根据前15名病例特征分布情况计算第16名病例分组结果并储存,以此类推,直至第20名病例。如此可适当降低人工操作频率,简化实施过程。 本程序设定采用极差表示因素不平衡函数,若采用方差则需作相应更改;因素的权重和最优分配概率可根据实际情况在宏变量中定义。最优分配概率P的设定方法有多种。如考虑3组设计,可设定分配到目标组概率为0.6,分配到其他两组的概率各为0.2;或根据G值的大小对3组进行排序,如按G值从小到大的顺序分配概率分别设为0.6、0.3、0.1等。P值大小没有绝对的设定规则,研究者可综合考虑组间均衡和预测难度的需要进行设定。如两组设计时P一般可取值为2/3[10 ];但若样本量较小或对均衡要求更高,可进一步提高P值,如文天才等[11]研究中,对228例病例、两组设计的临床试验,P值设定为0.8。在多中心研究中,因预测难度大,P可取值为1,以实现均衡最大化[5,12]。程序以3个试验组、4个预后因素为例编制,可直接用于两组或三组设计的临床试验,三组以上设计的编制过程与之类似;预后因素个数无论多少,只需在定义宏变量时作相应设定即可。值得注意的是,当预后因素为连续变量时,需先将其转化为分类变量,如本例中的年龄、孕周。 采用基于网络的最小化随机分组系统亦是降低最小化法实施难度的一种方法[11,13],但其开发和维护成本较高,需要专业的程序开发人员参与。相较而言,SAS宏程序更为简便易行,成本低廉,便于研究者理解掌握,并可根据需要修改相关参数,适用性更强。目前,未见专门用于最小化随机分组的SAS宏程序。本文结合模拟实例,编制了可实现快速批量分组的SAS宏程序,简化了实施过程。合理使用该宏程序,可促进最小化法的应用,发挥其在小样本、基线复杂的临床试验中的均衡优势。 1 Treasure T,Macrae KD.Minimisation:the platinum standard for trials? Randomisation doesn't guarantee similarity of groups; minimisation does.BMJ,1998,317:362-363. 2 王倩,金丕焕.动态随机化在临床试验中的应用.中华预防医学杂志,2005,39:51-53. 3 闫世艳,姚晨,夏结来.简单随机化、中心分层区组随机化和最小化法的均衡性比较.中国循证医学杂志,2006,6:376-379. 4 Taves DR.Minimization:a new method of assigning patients to treatment and control groups.Clin Pharmacol Ther,1974,15:443-453. 5 Pocock SJ,Simon R.Sequential treatment assignment with balancing for prognostic factors in the controlled clinical trial.Biometrics,1975,31:103-115. 6 ICH Harmonised Tripartite Guideline.Statistical Principles for Clinical Trials.1998,12-13. 7 Scott NW,McPherson GC,Ramsay CR,et al.The method of minimization for allocation to clinical trials.a review.Control Clin Trials,2002,23:662-674. 8 Therneau TM.How many stratification factors are "too many" to use in a randomization plan? Control Clin Trials,1993,14:98-108. 9 Ivers NM,Halperin IJ,Barnsley J,et al.Allocation techniques for balance at baseline in cluster randomized trials:a methodological review.Trials,2012,13:120. 10 Efron B.Forcing a Sequential Experiment to be Balanced.Biometrika,1971,58:403-417. 11 文天才,闫世艳,刘保延,等.最小化随机算法在中医药改善脑积水临床研究中的应用.中国数字医学,2008,3:17-18. 12 White SJ,Freedman LS.Allocation of patients to treatment groups in a controlled clinical study.Br J Cancer,1978,37:849-857. 13 刘志臻,郑国华,曹治云,等.多中心临床试验中的最小化随机网络系统研究.中国循证医学杂志,2011,11:333-335.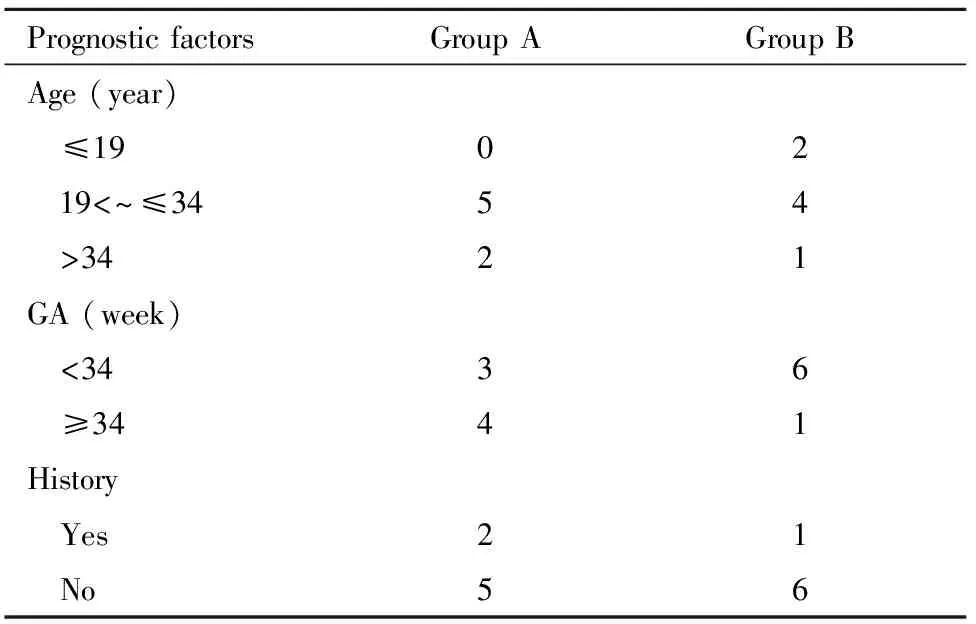
讨 论
猜你喜欢
智能制造(2021年4期)2021-11-04
海外星云(2021年9期)2021-10-14
现代仪器与医疗(2021年1期)2021-06-09
大众健康(2020年7期)2020-08-25
制造技术与机床(2019年10期)2019-10-26
小学生学习指导(低年级)(2019年3期)2019-04-22
小学生学习指导(低年级)(2018年9期)2018-09-26
制造技术与机床(2017年11期)2017-12-18
小学生导刊(低年级)(2017年1期)2017-06-12
中国合理用药探索(2012年2期)2012-03-20
