
多主题受限玻尔兹曼机的长尾分布推荐研究
2018-03-27 01:23史明哲吴国栋
小型微型计算机系统 2018年2期
史明哲,吴国栋,2,张 倩,疏 晴
1(安徽农业大学 信息与计算机学院,合肥 230036) 2(东华大学 旭日工商管理学院,上海 200051)
1 引 言
互联网数据的研究发现,物品往往呈长尾分布[1].少部分物品吸引了大部分关注,网络技术的发展使关注的成本大大降低,数量巨大的长尾物品不仅满足了人们的多样化需求,而且冷门物品的购买总量已经能与畅销物品的销售量相当.现有推荐系统的研究中,倾向于热门物品的推荐,很少考虑挖掘那些真正的冷门物品.如协同过滤推荐通过用户相似度或物品相似度寻找近邻进行推荐[2];基于内容的推荐通过提取物品的特征进行推荐[3];基于知识的推荐通过领域知识表示成知识库进行推荐[4];混合推荐方法依赖各种算法的组合进行推荐等[5].由于很多长尾物品只有很少的评分,在传统的推荐系统中这些算法很难得到应用,造成长尾分布问题并未得到缓解.当前,尽管针对长尾物品的推荐有所研究,如基于约束关系的长尾推荐方法[6],利用各种约束关系进行推荐;基于聚类的长尾物品推荐方法[7,8],将整个物品构成的集合分为头部和尾部两个部分,并只对尾部物品进行聚类,根据聚类中的评分对尾部物品进行推荐.但这些研究,一方面由于评分数据的稀疏性问题,会严重造成推荐精度的下降;另一方面仅仅根据用户的历史偏好进行推荐,很难对用户的未来兴趣趋势进行预测和引导,而对用户未来兴趣进行预测又至关重要.
目前,推荐系统的预测算法,常用的如基于评分的预测、基于领域的方法、隐语义模型与矩阵分解模型、加入时间信息、模型融合及基于受限玻尔兹曼机的方法等.其中受限玻尔兹曼机是由可视层和隐藏层相互连接的一个完全二分图结构,每一个神经元是一个二值单元,也就是每一个神经元只能等于0或1[9].2007年Salakhutdinov等人首次将RBM模型应用于解决推荐问题,但是该模型的缺陷是:需要将实值的评分数据转化为一个K维的0-1向量,如果训练数据是浮点型的就无法转化[10].2013年Georgiev等人提出了可以直接处理实值数据的RBM模型并且改进了模型的训练过程,使RBM的可见单元可以直接表示实值,模型的训练和预测过程得到了简化[11].针对当前长尾推荐在用户偏好主题挖掘、热门物品与冷门物品之间关联度不强等方面的不足,本文提出一种基于多主题的改进受限玻尔兹曼机长尾分布推荐方法,通过挖掘商品信息的主题特征及用户偏好主题,构建用户和物品之间的联系,结合改进受限玻尔兹曼机对用户未知偏好主题进行预测,以提高长尾物品的推荐性能.
2 长尾分布及推荐流程
2.1 长尾分布
长尾理论最先由美国《连线》杂志主编克里斯·安德森于2004年10月提出,其思想是:如果存储和流通的渠道能足够大,需求或销量不佳的产品共同占据市场份额就可以同那些数量不多的热卖品所占据的市场份额相抗衡甚至更具有优势,这就是长尾理论[12].图1、图2分别展示了在MovieLens-1M数据集和Netflix数据集数据的长尾分布,表明了长尾分布的普遍存在性.
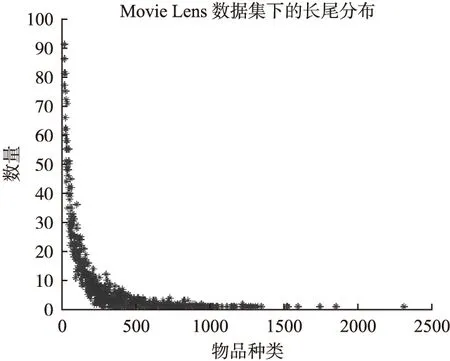
图1 MovieLens数据集下的长尾分布Fig.1 Long tailed distribution under movieLens

图2 Netflix数据集下的长尾分布Fig.2 Long tailed distribution under Netflix
2.2 长尾分布的推荐流程
基于多主题受限玻尔兹曼机的长尾分布推荐的基本思路:根据长尾分布的特点,把物品分为头部(即热门物品集)和尾部(即冷门物品集)两个物品集;利用主题模型分别对其提取主题,构建两集合之间的关系;将长尾分布头部提取的主题视为用户已知的偏好领域,通过近邻用户,并结合改进受限玻尔兹曼机对用户未知偏好领域进行预测,发现用户的未来偏好趋势,进而对尾部商品推荐,具体研究流程如图3所示.

图3 长尾物品推荐流程Fig.3 Long tail items recommended process
在图3所示流程中,利用分词工具,分别对头部物品内容信息及尾部物品内容信息进行分词.针对某一用户历史行为信息(用户有过行为的物品信息),利用主题模型提取出用户A初始偏好主题,结合用户A的近邻用户发现其未知偏好主题,通过改进受限玻尔兹曼机,对用户A的未知偏好主题进行预测,得到用户A的最终偏好主题.同时根据物品信息利用主题模型提取物品主题,根据用户A的最终偏好主题词和待推荐的每个物品的主题词进行相似度计算,并对相似度进行排名,推荐相似度较高的N个物品,最后对推荐结果做出解释,来增加用户对推荐结果的信任度.
3 主题提取
在推荐过程中,热门物品和冷门物品的主要区别是被关注的程度不同,如果能找到它们的共性(主题),就可以对长尾物品进行有效的推荐.将用户的偏好抽象为不同的主题,每个主题包含具有相似主题的热门物品和冷门物品,而每个物品因其主题特征的多样性,也可属于不同的主题.
经过分析,长尾分布的头部物品集和尾部物品集可以通过主题这一隐含变量,弥补尾部物品用户行为数据较为稀疏和很难得到推荐的问题.本文基于LDA主题模型提取主题,其中LDA模型是一个三层概率模型,它由文档、主题和词组成[13].为提取主题[14],两个重要的参数需要估计:主题-词语分布φk和文档-主题分布θm,参数估计采用以下步骤:
Step1.首先要对物品内容信息进行分词,去除停用词造成的影响以生成文档.
Step2.为文档中的所有商品信息单词采样初始主题:
zm,n=k~Info(K)
(1)
Step3.每当新观察到一个词语ωi=t,利用公式(2)计算当前的主题.
(2)

Step4.重复执行Step 2的抽样过程,直至所有的主题分布达到收敛,此时,每个单词的主题标号确定以后,两个参数的计算公式如下:
(3)
(4)

4 基于改进受限玻尔兹曼机的主题权重预测
在对海量商品信息数据的主题提取时,根据提取的用户偏好主题词,利用加权平均的方法得到加权平均权重,其中加权平均权重较大的主题词,从一定程度上反应了用户的历史偏好特征,但是加权平均权重较小的主题词不能简单地认为用户对这一主题不感兴趣,因为随着时间的推移,用户的兴趣会发生改变,这就需要去挖掘用户潜在兴趣即对主题词加权平均权重较小或没有涉及到的主题进行预测.在推荐时不但可以根据历史主题偏好发现长尾商品,而且可以通过预测用户未知偏好主题,提高用户的惊喜度及长尾商品的挖掘能力.
4.1 受限玻尔兹曼机的改进
针对文献[10,11]方面的不足,本文中每一个RBM对应一个用户,每个可视层单元对应一个主题词,相应主题词的权重通过计算各个主题中的主题词的加权平均,把加权平均值作为相应主题词的权重(把加权平均值最大的几个作为用户的偏好主题,而改进受限玻尔兹曼机的输入为所有相应主题词加权平均值).由图4可知,RBM由主题的可视单元、隐层单元及可视单元和隐层单元之间的RBM权重组成,其中RBM权重具有一定的随机性,不同的RBM经过训练达到收敛时会有不同的RBM权重值,为保证RBM能协同对每个主题权重预测,则要求不同RBM的每个相同主题对应的权重要有相同的权重和偏置.但是,在并行计算RBM时,造成同一主题有不同的RBM权重值,无法保证对于同一主题有相同的RBM权重值,缺乏可解释性.如果按线性方法计算每一个RBM,能达到相应主题RBM权重相同.根据图4的模型,可视层代表用户的偏好倾向,RBM权重代表每个主题所固有的潜藏特征.然而我们并不能清楚的了解到哪个用户RBM的训练权重能较好地描述主题所固有的潜藏特征.因此必须要找到一个代表用户,但是在推荐系统中,单个用户很难代表所有用户,因此本文通过以下方法就RMB这一问题做以下改进:
Step1.模型结构:对于每一个用户RBM模型,都是相互独立的,且不共享同一隐层,但是,隐层单元个数相同.
Step2.训练方法:独立训练每一个用户RBM模型.
Step3.数学表达:具体说明如下定义.
定义1.主题的向量表示:D=(T1,T2,…,Ti,…,Tn-1,Tn),其中Ti表示第i个主题;Ti=(t1,w1;t2,w2;…;ti,wi;…;tn-1,wn-1;tn,wn),其中ti表示主题词,wi表示主题词权重.
定义2.主题词权值表示:W={I1,I2,I3,…,Ii,…,In},其中Ii表示相应主题中第i个位置处主题词相应的权值.
用户偏好主题中某一主题词t的加权平均权重计算如公式(5)为:
(5)

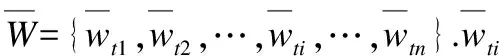
根据定义3可知,改进RBM训练结束后,经过预测模型得到的用户偏好未知主题的权重值是加权平均权重.但在实际中,我们需要的是没有经过加权的主题词权重,因此需要去权值,去权值的关键是如何确定预测得到未知主题词在相应用户偏好主题中的个数及位置,确定好这些就可以通过公式(5)得到去权值的主题词权重.对于未知主题的个数确定,通过比较用户近邻用户中相应主题的主题词与其他主题的主题词的众数,如果在某主题中相应主题词在近邻用户相应主题的众数小于一定阈值,则该预测主题词就不被分配到该主题中.由于对于所有近邻用户相应主题的主题词个数都相同,取这些近邻用户中相应主题中主题词的平均位置作为该主题词在相应主题中的位置.针对改进RBM主题预测模型的预测过程如图4所示,把用户A近邻用户中具有相同主题A,其相应的主题词的RBM权重取平均,以获得该主题词的潜藏特征(平均RBM权重),根据用户A的原有隐层和平均RBM权重,预测主题A的相应主题的加权平均权重.针对图4所示,改进的实值受限玻尔兹曼机主题预测模型中标注的主题,只有主题词的加权平均权重较大的N个被视为用户的偏好主题,其他主题词的加权平均权重也称为主题,但不是用户偏好主题,只是为保证在挖掘用户的潜在特征时信息不至于丢失,即参与模型的训练和预测,辅助完成用户偏好主题的挖掘过程.
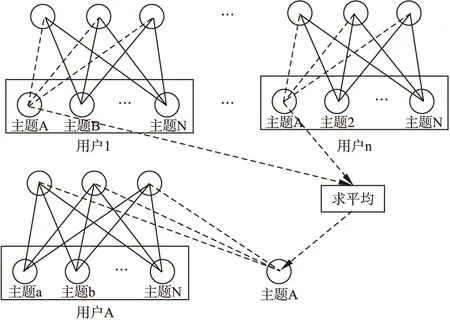
图4 改进的实值受限玻尔兹曼机主题预测模型Fig.4 Topic prediction model based on improved real RBM
4.2 用户未知主题偏好预测
根据上述模型,由于RBM模型是一个基于能量的模型[9,15](Energy Based Model,EBM),对于一组给定的状态(v,h),可定义如下能量函数
(6)
(7)
其中,vi,hj分别表示第i个可见单元与第j个隐单元的状态,wij则为第i个可见单元与第j个隐单元的链接权重,T表示主题的个数,F表示隐藏层的个数.
由式(6)(7),给定隐单元状态,可见单元的激活概率为:
(8)
其中,由于初值的影响需要加ζ为调节参数,给定可见单元状态,隐单元的激活概率为,
(9)
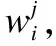
(10)
其中,I表示具有近邻用户相应同一主题的个数.
当训练结束,给定某个用户的已知偏好主题V,该用户对于未知主题q的预测的概率可直接计算,
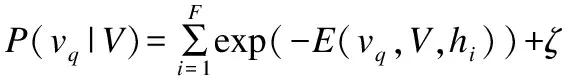
(11)
5 用户偏好主题和物品主题相似度计算及推荐
主题相似度计算是一个复杂的过程,文本处理中最常用的相似性度量方式如余弦相似度、向量空间模型等[16].
根据定义1用户某个偏好主题和物品某个主题相似度,通过向量的夹角余弦得出:
(12)
其中,Ti表示用户偏好主题的第i个主题词权重;Ii表示物品主题的第i个主题词权重,同时要求用户偏好主题词和物品主题词相同;n表示用户某一偏好主题和物品某一偏好主题中具有相同主题词的个数.
用户某个偏好主题Ti和相应物品所有主题相似度计算:
(13)
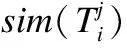
用户u对某一物品m的偏好度为:
(14)
其中,sim′(Ti)表示用户某个偏好主题Ti和相应所有物品主题相似度数值较高的N个相似度;N′表示取sim′(Ti)值的数量.
根据公式(12)(13)(14)用户偏好主题和物品主题相似度计算及推荐伪代码如下所示:
def getSim(persons,items):#用户偏好主题和物品主题相似度计算
P1=[]#存放用户某偏好主题和相应所有物品主题相似度列表
for P in persons:#取出用户偏好主题列表中某个主题
S=0
n=0
for T in items:#取出物品主题列表中某个主题
sim=sim(P,T)#用户和物品某个主题相似度
S+=sim#求和
n++
sim1=S/n#用户某个偏好主题物品的相似度
P1.append(sim1)
P1.sort()
P1.reverse()
sum=0
for t in P1[0:n]#取前n个数值
sum+=t
P′=sum/len(P1[0:n])
return P′
def getRecommendations(persons,items,I):#推荐
M={}
P=[]#用户偏好列表
for i in I:
M[i]=getSim(persons,items)
for j in M
P.append((M[j],j))
P.sort()
P.reverse()
return P
6 试 验
为了验证算法的可行性及其性能,首先,就本试验用到的数据集和执行方法进行阐述;其次,给出试验的评价指标并对结果进行分析.
6.1 数据集
为了验证算法的性能,在Intel(R)Core(TM)i5-4460 CPU@3.20GHZ处理器、8GB内存的台式机上进行试验,使用Python程序设计语言对数据集进行处理.数据源使用一个涉及电影评价的真实数据集——MovieLens,MovieLens是由明尼苏达州立大学的GroupLens项目组开发的.可以从http://grouplens.org/datasets/movielens/处下载到数据集,本论文采用的是ml-1m.zip数据集.
6.2 主题及权重提取
对于长尾物品,由于缺乏用户评价数据,导致长尾物品很难被用户发现,因此需要找到所有物品的共性,提取用户偏好主题就显得十分重要.利用LDA主题模型提取主题时,取主题数K=3,每类主题取经过排序后的前5个主题词,如表1所示为MovieLens数据集中某用户所喜欢的53部电影风格及通过主题模型提取得到的权重值.
表1 用户偏好主题词及权重值(概率)
Table 1 Subject and weighting (probability)of user preference
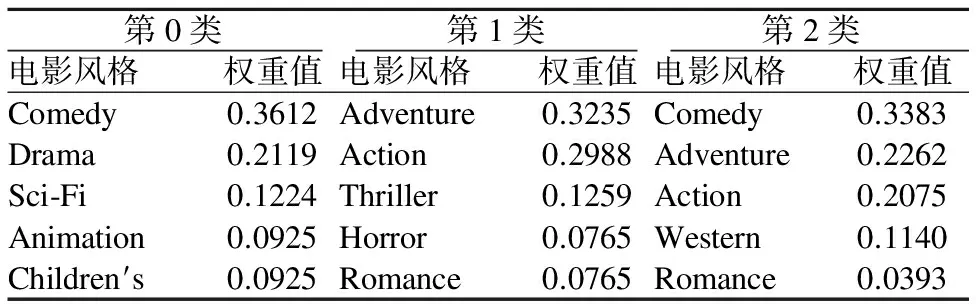
第0类第1类第2类电影风格权重值电影风格权重值电影风格权重值Comedy0.3612Adventure0.3235Comedy0.3383Drama0.2119Action0.2988Adventure0.2262Sci⁃Fi0.1224Thriller0.1259Action0.2075Animation0.0925Horror0.0765Western0.1140Children′s0.0925Romance0.0765Romance0.0393
在得到用户偏好主题类别后,需要选取3个主题词作为主题,为改进的受限玻尔兹曼机的主题预测做准备.具体计算采用加权平均的方法,其中每类(主题)中有5个排好序的主题词,从大到小给权值依次赋值为5、4、3、2、1.以“Comedy”为例,加权平均值为:(0.3612*5+0.3383*5)/2=1.74875,其他依次类推.在每类中选择加权平均值最大且与其他类别不重复的主题词作为该类别的主题,经过计算,三个类别相应的主题依次为“Comedy”“Adventure”“Action”.根据用户信息可知,该用户是一位小于18岁的女学生,提取的主题基本符合我们的认知,后面权重值较小的主题词可以确定为干扰因素,但也不排除用户兴趣发生改变,因此需要对主题词进行预测,来最终确定用户的偏好主题.
6.3 改进实值RBM对主题权重训练的性能验证
根据改进的受限玻尔兹曼机对主题权重进行训练时,需要确定对比散度中Gibbs采样步数为多少能使训练达到最优,其中学习率η=0.02.试验结果如图5、图6、图7所示,在图5中随着横坐标Gibbs采样步数的增加,相应纵坐标原始主题权重和经过训练后的主题权重的误差(取所有训练前后主题权重的最大值作为Error)趋于0,试验结果表明改进的RBM能较好的处理实值数据.

图5 RBM吉布斯采样步数优化确定Fig.5 RBM Gibbs sampling step number optimization
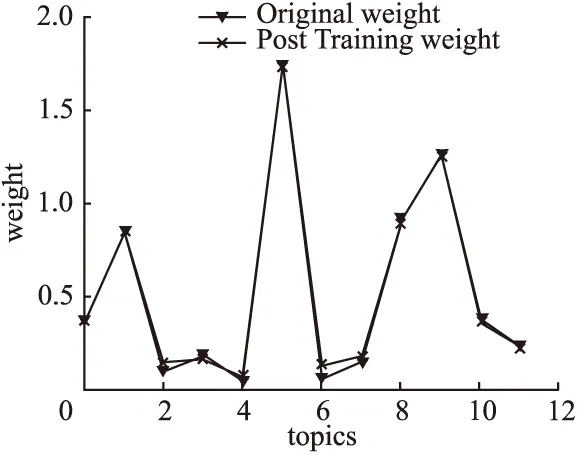
图6 经过2步吉布斯RBM训练效果Fig.6 After 2 steps Gibbs RBM training effect
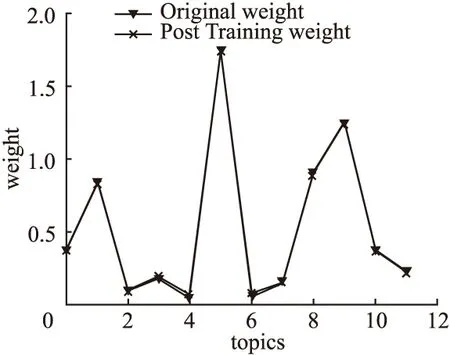
图7 经过3步吉布斯RBM训练效果Fig.7 After 3 steps Gibbs RBM training effect
6.4 近邻用户的选择对模型预测性能的影响
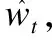
(15)
MAE采用绝对值计算预测误差,它的定义为:
(16)
在采用改进RBM对主题权重预测时,需找到与待预测主题的若干相同主题,来保证针对不同用户对于相同主题得到不同的主题权重值.寻找这些相同主题可以通过近邻用户方法,但是近邻用户方法存在用户偏好聚集,很难向其他偏好领域跨越.于是在采用近邻用户方法时,不再仅仅取近邻用户中相似度较高的N个用户,而是把近邻用户推荐列表按相似度大小分成3个部分,第一部分是和目标用户相似度最高的若干近邻用户,也就是在近邻用户方法中经常采用的对象;第二部分相似度次之;第三部分较次之.试验的目标是在第一部分数据的基础上,再从第二部分和第三部分数据中按照1:2的比例随机加入若干数据,这种方法的特点是明显增加了待选主题的多样性,但需要确定对模型的预测精度影响是否较大.本文根据MAE作为衡量指标,MAE越小则表明模型的预测性能越强.
其中,横坐标分为两组试验,第一组试验采用按三部分比例3:1:2取近邻用户,其中第一部分选择最相似的若干用户,第二、三部分按照比例随机选取;第二组试验只选取第一组试验的第一部分数据,每组都通过3次试验得到MAE.第一组试验结果表明随机加入的数据对模型预测造成一定的干扰,并且三次试验稳定性明显低于第二组.但是第一组绝对值误差MAE的表现通过和6.2节得到的最小用户偏好主题“Action”的加权平均值0.90885相比影响可以忽略.同时如若为增加待预测主题的多样性,帮助用户向未知领域引导,第一组的表现效果要强于第二组.
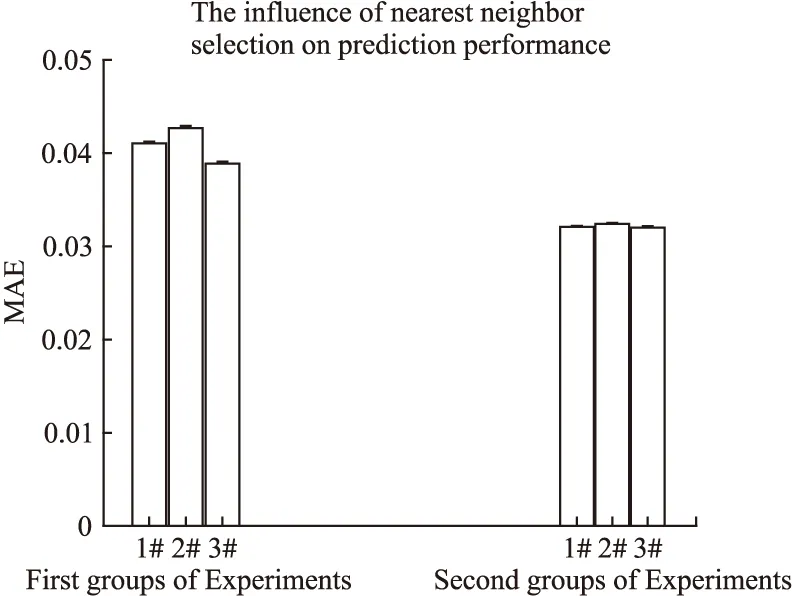
图8 第一组及第二组方法的MAE对比Fig.8 MAE comparison of the method for the first group and the two group
6.5 L_RRBM推荐性能验证
为验证本论文提出的L_RRBM算法的有效性,在推荐算法中以LFM(隐语义模型)就各自的准确率、召回率和覆盖率进行了分析比较,分别如图9、图10和图11所示.其中,横坐标ratio为用户没有过行为的物品/有过行为的物品,图11能较好的反应了本算法发掘长尾商品的能力.
试验结果表明,与传统的LFM推荐算法相比,本文所提出的L_RRBM算法,各项评测指标有明显的提高.
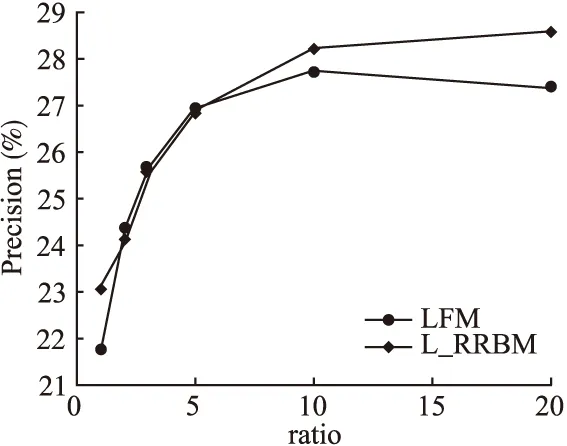
图9 LFM算法和L_RRBM算法的准确率试验对比结果Fig.9 Comparison results of LFM algorithm and L_RRBM algorithm for precision test

图10 LFM算法和L_RRBM算法的召回率试验对比结果Fig.10 Comparison results of LFM algorithm and L_RRBM algorithm for recall test
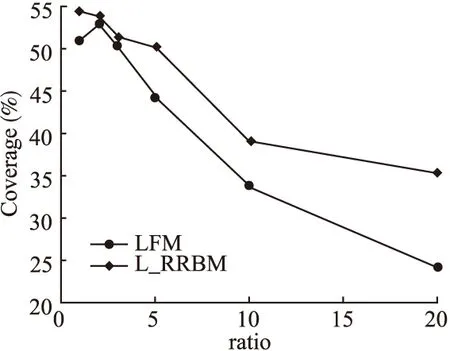
图11 LFM算法和L_RRBM算法的覆盖率试验对比结果Fig.11 Comparison results of LFM algorithm and L_RRBM algorithm for coverage test
7 结 论
论文针对长尾中冷门商品很难得到用户的关注,造成评价数据稀疏的问题,提出L_RRBM算法,从商品的内容信息着手,对商品信息进行主题提取,并改进RBM对提取主题中权重较小和未知主题权重进行预测,以增强因用户偏好改变,而多主题模型难以提取到用户偏好主题而造成的影响.
然而,我们的工作中还存在一些需要改进的地方.比如在对改进的实值RBM进行训练时涉及到“加权”和“去权”的问题,参数的调整过于复杂.另外,在对主题进行预测时,通过引入近邻用户,经过试验验证能较好的对主题进行较好的进行预测,但是在一定程度上增加了算法的复杂度.在未来的工作中,我们会尝试通过深度学习或深层受限玻尔兹曼机来解决这些问题.
[1] Xiang Liang.Recommendation system practice[M].Beijing:Posts and Telecom Press,2012.
[2] Goldberg D,Nichols D,Oki B M,et al.Using collaborative filtering to weave an information tapestry[J].Communications of the Acm,1992,35(12):61-70.
[3] Han P,Xie B,Yang F,et al.A scalable P2P recommender system based on distributed collaborative filtering[J].Expert Systems with Applications,2004,27(2):203-210.
[4] Xu Hai-ling,Wu Xiao,Li Xiao-dong,et al.Comparison study of Internet recommendation system[J].Journal of Software,2009,20(2):350-362.
[5] Jamali M,Ester M.TrustWalker:a random walk model for combining trust-based and item-based recommendation[C].Proceedings of the 15th Association for Computing Machinery Special Interest Group on Management of Data International Conference on Knowledge Discovery and Data Mining,Association for Computing Machinery,2009:397-406.
[6] Yin Gui-sheng,Zhang Ya-nan,Dong Hong-bin,et al.A long tail distribution constrained recommendation method[J].Journal of Computer Research and Development,2013,50(9):1814-1824.
[7] Feng Yuan-yuan,Wang Xiao-dong,Yao Yu.Long tail problem of recommender system in electronic commerce[J].Journal of Computer Applications,2015(s2):151-154.
[8] Park Y J,Tuzhilin A.The long tail of recommender systems and how to leverage it[C].Association for Computing Machinery Conference on Recommender Systems,Recsys 2008,Lausanne,Switzerland,2008:11-18.
[9] He Jie-yue,Ma Bei.Based on Real-valued conditional restricted boltzmann machine and social network for collaborative filtering[J].Chinese Journal of Computers,2016,(1):183-195.
[10] Salakhutdinov R,Mnih A,Hinton G.Restricted boltzmann machines for collaborative filtering[C].Machine Learning,Proceedings of the Twenty-Fourth International Conference.2007:791-798.
[11] Georgiev K,Nakov P.A non-IID framework for collaborative filtering with restricted boltzmann machines[C].International Conference on Machine Learning,2013:1148-1156.
[12] Chris Anderson.The long tail[M].Beijing:China Crtic Press,2006.
[13] Griffiths T L,Steyvers M.Finding scientific topics[J].Proceedings of the National Academy of Sciences of the United States of America,2004,101 Suppl 1(1):5228-5235.
[14] Zu Xian,Xie Fei.Review of the latent dirichlet allocation topic model[J].Journal of Hefei Normal University,2015,33(6):55-58.
[15] Luo Heng.Restricted boltzmann machines:a collaborative filtering perspective[D].Shanghai:Shanghai Jiao Tong University,2011.
[16] Chen Xiao-hai,Zhou Ya.A crawling algorithm based on topical similarity for guiding the web crawler though tunnels[J].Computer Engineering and Science,2009,31(10):126-128.
附中文参考文献:
[1] 项 亮.推荐系统实践[M].北京:人民邮电出版社,2012.
[4] 许海玲,吴 潇,李晓东,等.互联网推荐系统比较研究[J].软件学报,2009,20(2):350-362.
[6] 印桂生,张亚楠,董红斌,等.一种由长尾分布约束的推荐方法[J].计算机研究与发展,2013,50(9):1814-1824.
[7] 冯媛媛,王晓东,姚 宇.电子商务中长尾物品推荐方法[J].计算机应用,2015(s2):151-154.
[9] 何洁月,马 贝.利用社交关系的实值条件受限玻尔兹曼机协同过滤推荐算法[J].计算机学报,2016,(1):183-195.
[12] 克里斯·安德森.长尾理论[M].北京:中信出版社,2006.
[14] 祖 弦,谢 飞.LDA主题模型研究综述[J].合肥师范学院学报,2015,33(6):55-58.
[15] 罗 恒.基于协同过滤视角的受限玻尔兹曼机研究[D].上海:上海交通大学,2011.
[16] 陈小海,周 娅.基于主题相似度指导网络蜘蛛穿越隧道的爬行算法[J].计算机工程与科学,2009,31(10):126-128.
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
心理学报(2022年5期)2022-05-16
当代陕西(2020年17期)2020-10-28
小学生学习指导(高年级)(2020年6期)2020-07-07
汽车文摘(2019年3期)2019-03-04
人大建设(2018年5期)2018-08-16
证券市场红周刊(2018年3期)2018-05-14
中国诗歌(2016年6期)2016-11-25
档案管理(2014年6期)2014-10-30
商品与质量·消费研究(2013年7期)2013-08-29
