
基于机器学习技术的在线疾病诊疗方案倾向性识别研究
2018-03-22 03:53:10,,
中华医学图书情报杂志 2018年7期
,,
随着互联网的快速发展,在线医疗咨询受到广大互联网用户的青睐。根据2018年1月发布的第41次《中国互联网络发展状况统计报告》[1]可知,在线医疗已取得了快速发展。
近年来,民众进行健康咨询时,对西医和中医治疗效果的关注有增加趋势。不同病症有各自适合的治疗方案,因此有必要分析具体病症的西医或中医治疗方案的倾向性。如果能从疾病症状描述中提取有用信息,识别出适合的治疗方案,则可快速为用户提供具有针对性的备选治疗方案。心血管疾病症状典型,既有西医也有中西医结合治疗方案,适合用作研究对象[2]。
鉴于此,本文抓取在线医疗网站的疾病信息,以心血管疾病作为具体对象,采用机器学习技术识别其治疗方案的倾向性。
1 研究方法
随着数据挖掘技术的快速发展,医学文本挖掘已经成为医学研究的一个重要方向。在中医药治疗哮喘处方规律的研究上,孟繁璞[3]采用文本挖掘技术,从中国生物文献数据库以及中国学术期刊数据库中总结出治疗支气管哮喘的常用药剂;刘俊丽等[4]以万方医学网收录的乙肝研究的期刊文献为数据源,采用文本挖掘技术,构建了共词矩阵并绘制乙型肝炎相关文献的知识图谱;姜春燕[5]利用文本挖掘技术分析银屑病中医用药规律和中医治疗银屑病的核心药物及其组合配伍关系。以上相关研究大都侧重对已有文本数据的挖掘和统计,缺乏对挖掘出来的信息进行有效预测。从应用角度上讲,对于新病例的咨询预测,是需要重点解决的核心问题。
机器学习技术为医学文本挖掘提供了有效的支持。如杨帆[6]通过计算病人与各种不良反应的关联强度建立的个性化药物不良反应排序表,实现了基于机器学习的药物不良反应预测及分析;叶雷[7]引入4种机器学习算法(k近邻、决策树、支持向量机和随机森林),实现了对慢性肾病数据的分类预测。尽管机器学习已在医疗领域取得广泛应用,但有关在线医疗数据诊疗方案倾向性的研究鲜有涉足。本文以中、西医分类作为切入点,对疾病的症状进行分析,预测出该疾病适合的诊疗方案,证明机器学习技术对在线医疗数据的预测效果。
网络爬虫(web crawler)技术是获取互联网资源的一种有效方法。在网络爬虫与医疗领域相结合方面,卞伟玮[8]利用网络爬虫技术,构建了健康医疗大数据,实现了对多类型医疗数据的自动爬取;为构建医疗主题搜索引擎,陈祖德[9]通过Map/Reduce框架,创建了面向医疗主题的网络爬虫。但在现有基于网络爬虫的医疗数据分析研究中,通常仅对数据做简单统计,有必要将机器学习技术与医疗主题的爬虫系统结合,实现对在线医疗数据的分析与预测。
2 研究设计
基于上述分析,本文使用网络爬虫从互联网上采集疾病症状数据,利用文本挖掘技术提取特征向量,以疾病的中、西医诊疗方案倾向性为分类目标,采用机器学习分类算法(支持向量机、决策树、人工神经网络等)构建分类模型,有效识别病症数据的中、西医诊疗方案倾向性。
具体流程设计如下:获取在线医疗数据→文本分词和过滤→提取特征关键词→文本向量化→分类算法训练→对新的文本数据进行预测。其中,医疗数据的获取是通过网络爬虫对病症信息进行爬取;文本分词和过滤,采用分词技术对文本进行预处理,使用停用词字典将高频但对研究无意义的词去除;提取特征关键词,是使用词频-逆向文件频率方法实现关键词的自动抽取;文本向量化,即使用Python机器学习工具包scikit-learn完成文本向量化;分类算法训练,是采用机器学习分类算法,构建分类模型;对新的文本数据进行预测,是指对新采集的文本预处理,并输入分类模型进行预测。实验流程如图1所示。
2.1 数据来源与获取
以39健康网的子网站39疾病百科网作为数据来源。该网站所提供的信息来自中国前100名三甲医院的健康科普内容和一线专家的原创健康科普视频和文章,数据可靠性较高。该网站收录了14 502种疾病,并提供了病因、症状、预防以及治疗等内容。其中“治疗”链接中,为有的病例提供了西医治疗方案或中西医结合的治疗方案。通过对病例的“症状”和“治疗”2个模块的获取,可以得到该病例的症状数据和治疗方案类别标签。本文使用Python语言编写网络爬虫,共获取439条有效的症状数据。
2.2 文本处理
首先,使用“结巴”中文分词工具[10],对爬取到的数据进行中文分词、过滤停用词及初步精简;其次,通过TF-IDF算法提取出文本中的关键词。词频-逆向文件频率(TF-IDF)[11]可以过滤掉一些常见的无关紧要的词语,同时保留影响整个文本的重要字词。对每条病例进行特征关键词统计,计算特征关键词频率,组成一个词频矩阵,得到病症的特征向量。
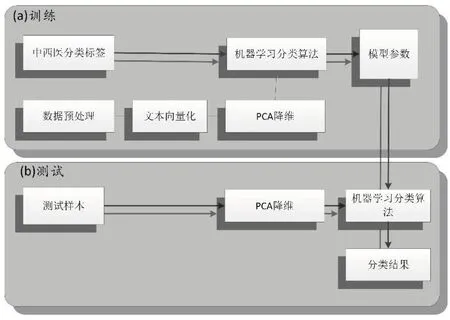
图1基于机器学习的治疗方案类别预测流程
由于不同病例中特征关键词的分布和频率差异较大,所以对关键词进行分析,有助于发现疾病症状与治疗方案倾向性的内在关系。部分特征关键词及对应词频见表1。
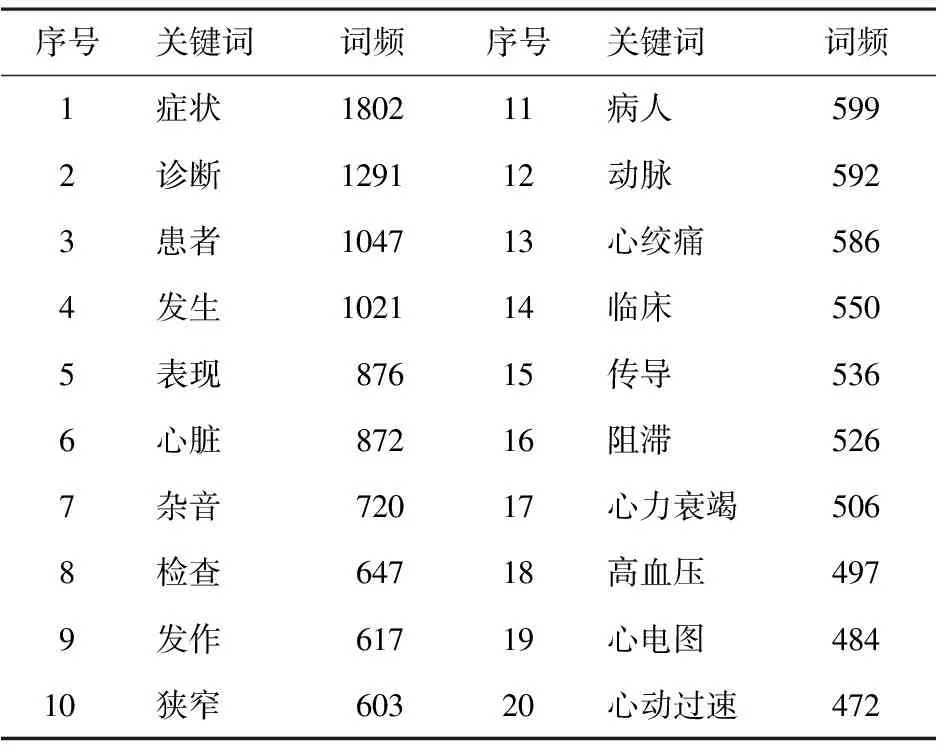
表1 排名前20的高频特征词及词频
以心脏病和血栓病为例,心脏病的治疗方案有西医治疗方案和中医治疗方案,血栓病的治疗方案只有西医治疗方案,二者在疾病症状上的特征关键词的频率存在较大差异:心脏病的部分高频特征关键词,如“心脏”“心力衰竭”“呼吸困难”“心悸”等,在血栓症症状中恰恰是低频词;而血栓症中的部分高频特征关键词,如“动脉”“血管”“静脉”“梗死”等,在心脏病症状中却是低频词。从关键词集合可以发现,适用于西医方案的特征关键词多趋向于一个集合,而适合中西医结合方案的特征关键词多存在于另一个集合。
西医治疗方案、中西医结合治疗方案的部分高频关键词见表2、表3。从表2、表3可以看出,不同疾病的治疗方案所对应的特征关键词集合不同,如西医治疗方案高频关键词是“杂音”“狭窄”等,而中西医结合方案高频关键词为“心绞痛”“发作”等。正是由于这两种分类所包含的关键词存在较大区别,数据有明确的可分性,因此适合建立机器学习分类模型进行识别。
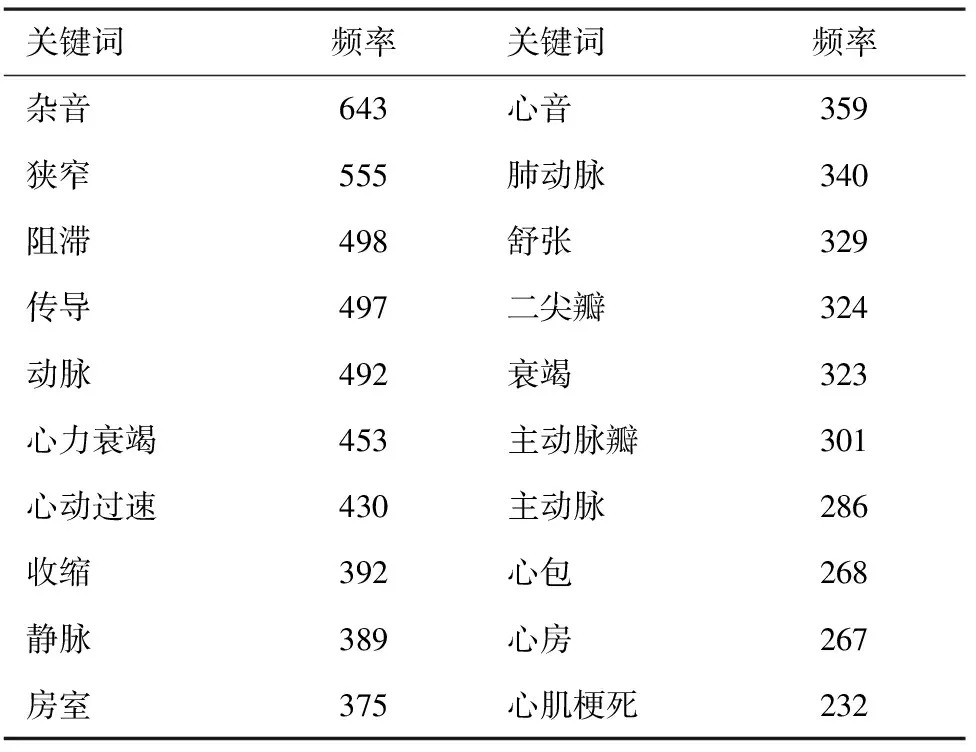
表2 西医治疗方案的部分高频关键词
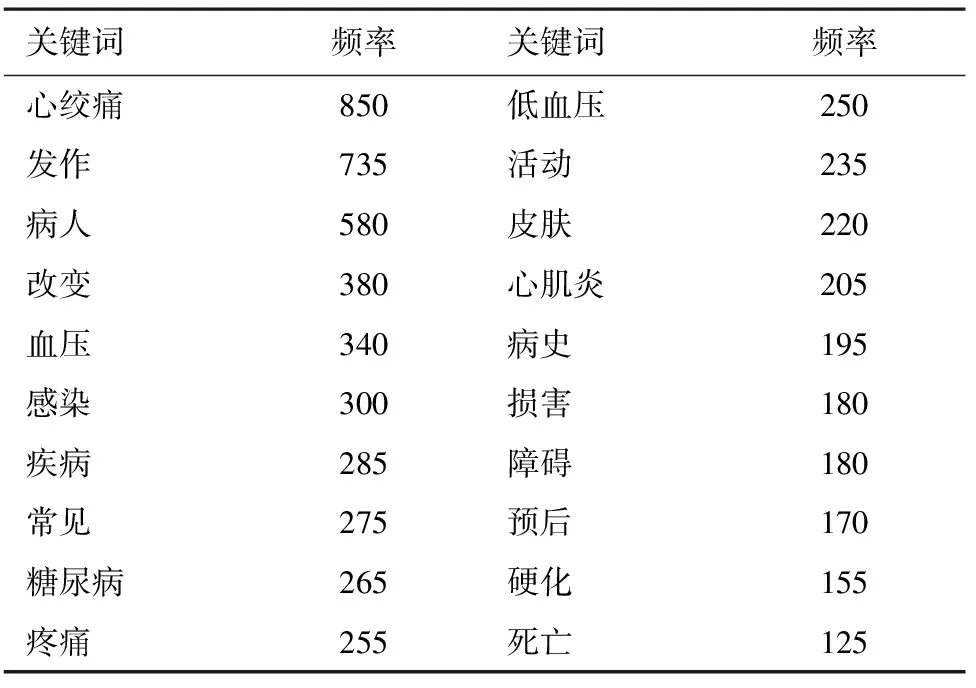
表3 中西医结合治疗方案的部分高频关键词
同时,考虑到高维特征向量对识别效果的影响,需要对其进行主成分分析(Principal Component Analysis,PCA)降维操作,使高维数据投影到较低维空间,尽可能少丢失信息,增加数据的可分性。
2.3 分类标签处理
为每条疾病的特征向量添加类别标签,如心肌炎对应西医治疗方案标签,心源性休克对应西医治疗方案标签,心脏病对应中西医结合治疗方案标签,低血压对应中西医结合治疗方案标签等。每条疾病症状都对应了一条西医方案治疗方案或者中西医结合治疗方案,将疾病特征向量和对应的治疗方案类别结合,最终得到样本集。
2.4 分类实验设计
本文选用3种机器学习算法构建分类模型,具体如下。
支持向量机(Support Vector Machine,SVM)[12]是一种有监督的分类算法。通过构造一个最优超平面,令正负类别样本之间距离最大,从而达到最佳预测效果。SVM在解决小样本、非线性及高维模式识别中表现出许多特有的优势,取得了广泛应用。其原理如图2所示。图中,五角星和圆形分别代表西医和中西医结合2类样本,中间的红色斜线为分类线。SVM基本思想就是计算能够正确分类尽可能多样本,并且使分类间隔最大的分类线作为最优分类模型。
决策树[13]是一种基于信息熵的分类算法。通过计算对象属性与类别值之间的信息增益,并利用一系列规则对样本进行分类。因其输出结果易于理解和解释而被广泛应用于医学信息领域。
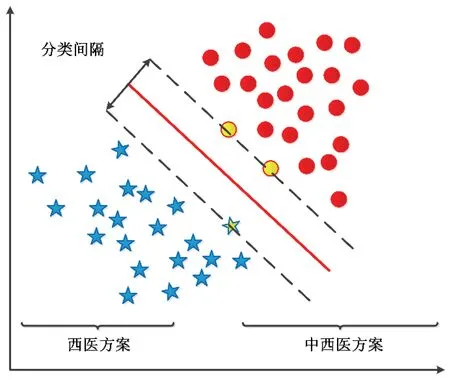
图2 支持向量机的分类示意图
人工神经网络[14]是模仿生物神经作用模式而提出的一种机器学习算法,是机器学习分类的重要方法,其基本思路是通过激活函数来模拟非线性映射,从而实现非线性分类。
实验中,首先是将样本集随机打散,随机选取70%的样本作为训练集,剩下的30%作为测试集;其次是采用PCA将原始特征向量从10 583维降到300维;最后,对测试集进行预测,采用准确率(accuracy)、查准率(precision)、查全率(recall)评判效果。其中查准率衡量分类的效果,查全率衡量分类的效率。此外,本文引入ROC曲线来评判综合分类性能。
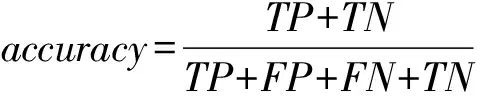
(1)
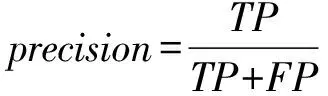
(2)
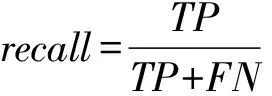
(3)
式中,TP在对中医西医类别的分类预测中被正确划分为中医西医类别的数量,FP在对西医类别的分类预测中被错误划分为中医西医类别的数量,FN在对中医西医类别的分类预测中被错误划分为西医类别的数量,TN在对西医类别的分类预测中被正确划分为西医类别的数量。
3 结果分析
实验中采用Python环境下的scikit-learn工具包。其中,支持向量机采用C-SVM算法,决策树采用C5.0,神经网络采用多层感知机网络MLP Network。支持向量机下正则化系数C设为1,该值越大对分错样本的惩罚程度越大,训练精度越高。核函数采用RBF高斯核函数,核参数gamma设为样本特征数的倒数。MLP网络采用单隐层结构,有100个神经元。
每次实验样本集都是随机的,导致每次结果有轻微波动。因此,循环运行实验100次,取预测正确率的平均值和标准差(表4)。从表4可看出,3种分类算法结果的区别不大,均保持在92%左右,表明利用疾病的症状特征对疾病治疗方案进行预测的方法是可行的。
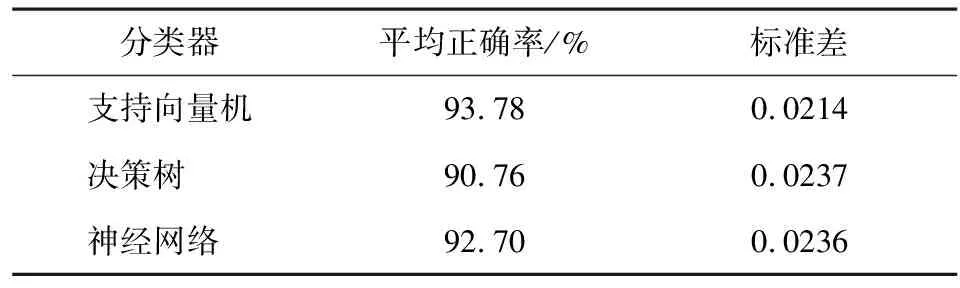
表4 100次试验的平均精准度和标准差
3种分类器的查准率和查全率见表5。从表5可以看出,查全率均接近100%或为100%,查准率为90%左右,表明分类效果和效率均比较理想。3种分类算法的ROC曲线对比见图3。从图3中3条曲线可以看出,3种分类器最终分类结果基本相似,验证了3种分类器的合理性和可行性。
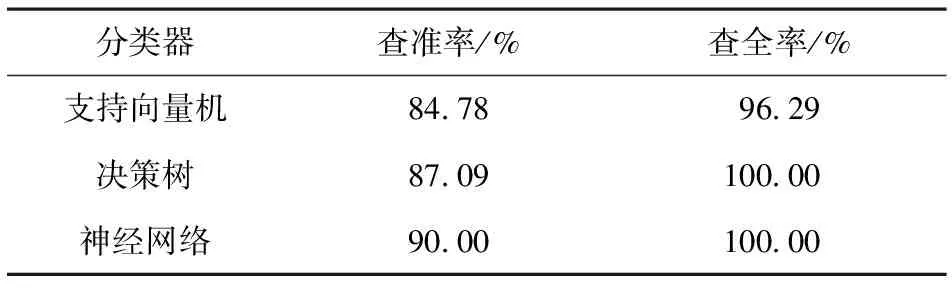
表5 3种分类算法的查准率和查全率
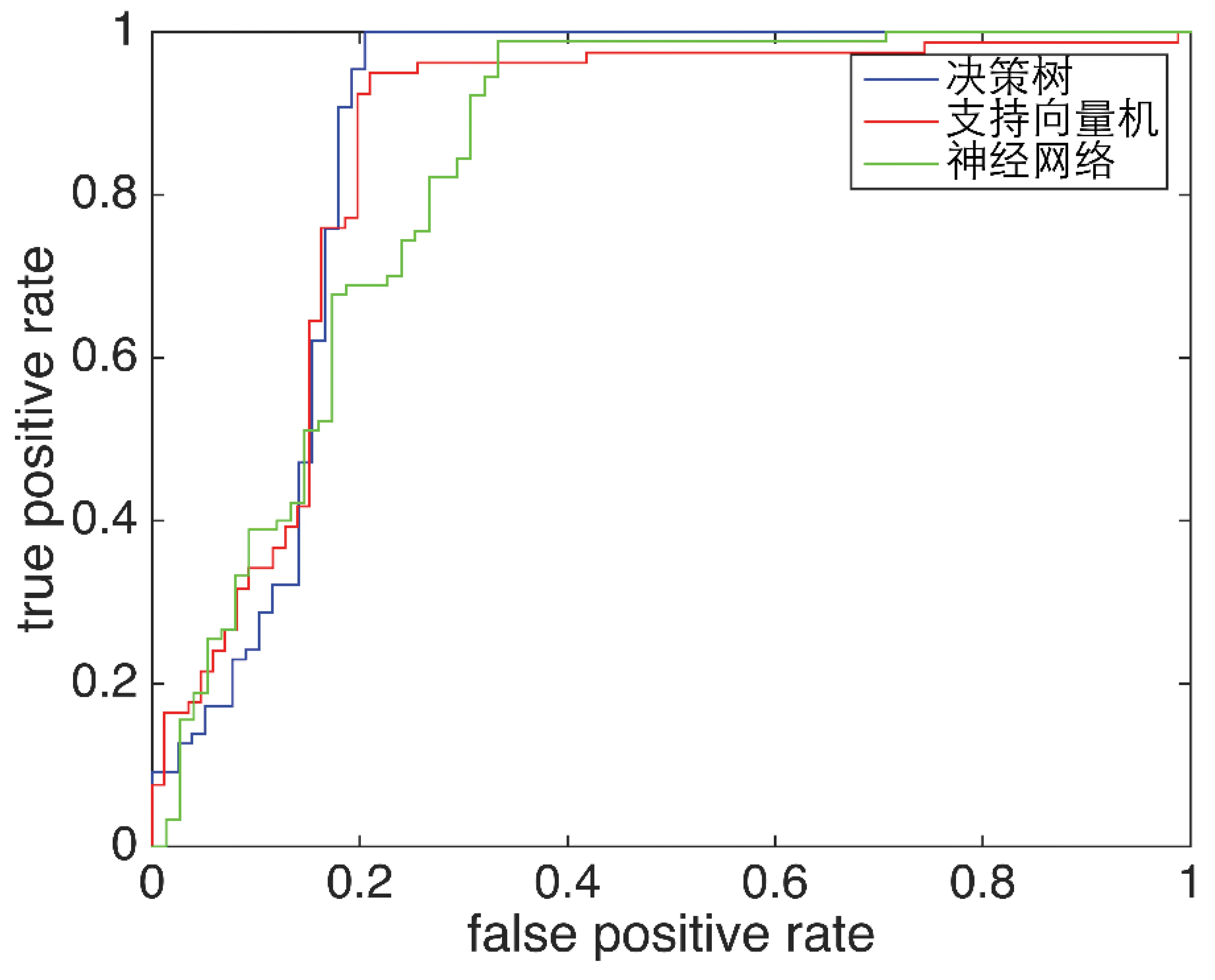
图3 3种分类算法的ROC曲线对比
4 结语
本文运用机器学习技术对在线医疗网站数据内容进行的实证分析,检验了机器学习技术在在线医疗网站文本分析中的有效性,实现了对心血管类疾病治疗方案的预测和推荐,最终揭示了疾病症状和治疗方案之间内在的联系,并可推广至其他类似病例。本文的不足之处在于未能将治疗方案进行细分,也未能将实验结果与用户的实际需求相结合。下一步拟将机器学习运用到其他具有多种治疗方案选择的疾病,并对治疗方案进一步细分,同时将此实验结果应用到实际需求当中,使之更加贴合用户的信息需求和使用习惯等。
猜你喜欢
环球时报(2022-07-13)2022-07-13 17:18:39
环球时报(2022-03-14)2022-03-14 18:19:44
电影(2018年8期)2018-09-21 08:00:06
中国民族医药杂志(2016年7期)2016-05-09 07:49:15
中国民族医药杂志(2016年5期)2016-05-09 07:43:56
中国民族医药杂志(2016年4期)2016-05-09 07:41:07
新校长(2016年8期)2016-01-10 06:43:59
小猕猴智力画刊(2015年4期)2015-04-28 23:55:53
商事法论集(2014年1期)2014-06-27 01:20:42
中央民族大学学报(自然科学版)(2014年1期)2014-06-11 01:28:48
