
基于Spark与词语相关度的KNN文本分类算法
2018-03-20 09:14于苹苹倪建成韦锦涛姚彬修
计算机技术与发展 2018年3期
于苹苹,倪建成,韦锦涛,曹 博,姚彬修
(1.曲阜师范大学 信息科学与工程学院,山东 日照 276826;2.曲阜师范大学 软件学院,山东 曲阜 273100)
0 引 言
随着Internet技术以及社交媒体的发展,文本信息规模越来越大,如何高效地在海量文本信息中挖掘出有价值的信息成为当前的研究热点[1]。文本分类技术作为文本处理的关键技术,在提高信息检索、利用等方面应用广泛。当前,使用较多的分类算法有朴素贝叶斯、支持向量机(support vector machine,SVM)、K-最近邻(K-nearest neighbor,KNN)等[2]。由于KNN分类算法具有稳定性强、准确率高等优点,在数据挖掘领域得到了广泛应用[3]。
近年来,国内外学者对KNN分类算法的准确率和分类效率进行了深入研究。在准确率上,文献[4]在传统KNN文本分类算法的基础上提出了一种基于关联分析的KNN改进算法,能够较好地确定K值,降低时间复杂度。文献[5]提出了一种基于KNN文本分类的伪装入侵检测方法,使得有区分性的命令权重增大,有利于更准确地表示用户的行为特征。在时间效率方面,Deng等[6]使用K-means方法对大规模训练集进行聚类裁剪,从而减少相似度的计算,提高分类效率。同时,有研究者将KNN算法应用于分布式平台,进一步提高分类效率。如文献[7]将SVM分类算法与KNN分类算法相结合,利用Hadoop云计算平台实现算法并行化。Anchalia等[8-9]依托MapReduce框架实现了KNN分类算法的并行化,缩短了分类时间。MapReduce框架[9]利用并行分布式计算模型对数据进行处理,是有效处理大数据集的关键所在。但研究人员在实验中发现MapReduce在Hadoop[10]中具有限制性[11]:MapReduce在执行过程中,每轮作业都需要重新启动,开销过大;同时,通过磁盘对数据进行I/O操作,执行效率较低。而Spark框架[12]改善了以上问题,它通过建立弹性分布式数据集,在内存中对数据进行存取操作,加快了数据处理速度。
分类算法中的距离机制直接影响分类效果。传统KNN的距离机制仅通过词频计算两样本间的相似度,而在实际分类过程中,文本词语间具有一定相关性。同时,在大数据环境中,数据集不断增大,KNN分类算法的计算复杂度不断增加,导致运行时间增多。
因此,文中在KNN相似度计算过程中引入词语相关度进行特征项加权,同时在Spark框架下实现KNN文本分类算法的并行化,以提高分类的准确度。
1 相关技术
1.1 KNN文本分类算法
KNN分类算法的核心原理为:通过相应距离机制计算待测样本与已知样本的相似度,找出与待测样本相似度最大的K个最近邻样本,利用决策函数判断K个样本中大多数属于哪个类别,则待分类样本也属于这个类别,并具有这个类别上样本的特性。
余弦相似度计算公式如下:

(1)
其中,wik表示Di文本中第k个特征的权重。
通过相似度计算得到K个相似度最大的样本即K个最近邻,并利用式(2)计算权重判断最终归类。
(2)

1.2 词语间相关度
一个词条对于文档的主题是否具有代表性与该词条所在一定范围内其他词语在文档中的出现频率(同现频率)是相关的[13],词语间相关度指两个词语同时出现在一定语言范围内的概率大小。
计算方法如下:
(1)依据文本预处理后特征空间基向量所包含的词条个数定义一个N×N维的词语相关度矩阵,其中N为特征空间中的基向量数目,基向量的一个词条对应矩阵中的一维数据,矩阵内各对应值初始为0。
(2)计算全部段落范围内同时出现的词条对得到段落同现频率。在同一段落中,如果词条Ti和词条Tj同时出现,则词语相关度矩阵中的对应值加一。
(3)直到所有文档的所有段落都学习后停止。
在得到对应的同现频率后,即可计算相应的词语相关度,词条Ti和词条Tj基于段落同时出现频率的相关度RPij计算为:
(3)
其中,PFi和PFj表示词条Ti和Tj在文档dj中所有段落范围内的出现频率。
1.3 Spark框架
Spark是由UCBerkeley开发的一种基于内存的计算框架。Spark框架由两个主要部分组成:弹性分布式数据集和并行运算。RDD是Spark框架计算中重要的概念,是Spark框架的核心和基础。
RDD是Spark框架的核心,是各个集群节点中数据共享的一种有效抽象。Spark所执行的数据处理是基于RDD进行的。RDD是可并行的数据结构,同时允许用户将数据存储在内存中,方便用户对数据的重复调用,减少了磁盘I/O的负载。RDD是不可变的集合,不能在原有RDD上实现内容的修改,只能创建一个新的RDD:
(1)通过对文件共享系统(HBase、HDFS、Hive)的读取得到RDD;
(2)通过驱动程序中用作并行计算的Scala集合创建;
(3)通过对已存在的RDD执行转换操作新建一个RDD;
(4)通过持久化操作进而转变现有的RDD。
并行运算包括转换(transform)和动作(action)。转换操作只依据原有的RDD定义一个新的RDD,而不对它进行直接计算;动作是对某个值立即进行计算,并返回结果给驱动程序[14]。
对RDD的控制还可利用缓存和分区操作。将RDD缓存在内存中,便于下次计算时的重复利用,减少了磁盘开销。RDD可根据key来指定分区顺序,将数据划分到不同分区中。
2 Spark框架下基于词语相关度的KNN算法
为了提高文本分类效率,分类算法的并行化处理是当前的一大趋势,但通过研究发现,在KNN文本分类的一般并行化过程中会降低分类准确率。因此文中在训练样本与待测样本的相似度计算过程中引入词语相关度,提高分类准确度并在Spark计算框架下实现并行化,降低运算时间。
2.1 基于词语相关度的相似度计算
通常情况下,传统KNN相似度计算方法单纯使用TF-IDF[15]计算相关度,忽略了文本数据本身词语间的关系,易导致文本内容表达的不完整,影响文本分类的准确率[16]。因此,定义合适的距离机制是分类准确的前提。文中在KNN分类算法相似度距离计算中引入词语相关度概念。
基于词语相关度的权值通过该词条词频与该词条在一定语言范围内其他词的平均相关度的乘积而得到,选用段落范围内词语相关度。词条Ti基于段落同现频率的词语相关度的加权值公式如下所示:
(4)
其中,K表示该文档中除词条Ti外其他词条的个数。
式(4)含义为:基于词语相关度的权重等于原有的TF*IDF乘以平均相关度。通过该方法计算的平均相关度结果较小,不利于区分,所以添加区分系数ρ。则新的相似度计算公式为:
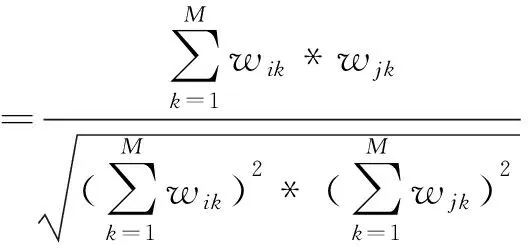
(5)
2.2 Spark框架下基于词语相关度的KNN算法
对传统KNN文本分类算法的并行化处理会提高分类的效率,但并行化处理通常会降低分类的准确度。因此,文中在Spark框架下实现KNN算法并行化的同时引入词语相关度对特征项进行加权处理,提高文本分类的准确度和分类效率。
2.2.1 预处理并行化
首先采用中科院分词软件ICTCLAS2015对数据集进行分词、去除停用词等预处理。去停词结果以
2.2.2 分类并行化
在KNN算法并行化过程中,以MapReduce模型为基础,采用Spark计算框架来实现算法的并行化。首先将训练集D与测试集Ti在HDFS中读取出来并建立RDD对象,然后将训练集分割到相应分片中,并将数据集进行缓存以备重复利用,通过分区处理每个Map都将对相近数量的训练集进行处理。
文中并行化算法为了使分类准确,对每个测试样本指定一个textID作为key值,然后利用RangePartitioner函数将测试集分成不同的子集Ti,进而通过转换操作filterByRange函数将测试集Ti读取进每一个Map任务中。算法1描述了此过程。
算法1:Spark框架下基于词语相关度的KNN算法。
输入:训练集D,测试集T,K
输出:分类结果
(1)将训练集在HDFS中读取并作为RDD对象读取进Map中;
(2)将测试集在HDFS中读取并作为RDD对象;
(3)对训练集和测试集进行规范化处理,并缓存;
(4)Map过程:
使用式(5)计算测试样本与训练样本的距离,并得到每个Map中最小的K个近邻;
将最小的K个近邻建立成类别-距离组成的CD向量,并将CD定义进value值中;
将结果发布给Reduce。
(5)Reduce过程:
在Map中读取结果;
更新距离CDnew向量。对于每个测试样本,从最近的邻居开始逐一比较每个邻居的距离值,如果Map任务转发来的距离小于当前值,则使用该值更新Reduce过程中相应位置的类和距离;否则,继续与下一个值比较;
通过判定公式计算最后分类;
输出结果。
步骤(1)、(2)将训练集与测试集在HDFS中读取出来并建立为RDD对象,然后对训练集D进行分片,同时设置K值。为了使分类准确,将测试集作为RDD读取但是不与训练集一起分片,而是根据key值读取进每个map中比较每一个测试样本和所有的训练集。
由于使用余弦相似度来计算样本间的相似度,将两个数据集在步骤(3)中进行规范化处理。同时,将数据集进行缓存以备重复利用。
在Map过程中,首先利用式(5)计算测试样本与每个分片中训练样本的相似度距离。通过相似度计算,在每个Map任务中都将得到最近的K个邻居,将这K个邻居的类别与相应的相似度距离保存为
每完成一次Map任务,Reduce就将CDnew中的距离值与来自Map中CD的对应距离值进行比较,直到得到最终K个近邻。所有的值更新完毕后,CDnew将包含所有待测样本的K个最近邻的类和距离。最后,执行KNN算法的判定函数确定测试集的所属类别,并将结果作为Reduce阶段的最终结果输出。对于每个测试样本,Reduce过程将采用ReduceByKey根据之前描述的函数聚集value。
图1给出了KNN分类并行化处理流程。

图1 Spark框架下KNN算法并行化过程
3 实 验
3.1 实验环境与数据集
在Hadoop平台上部署了Spark计算框架,通过Vcenter创建了6台虚拟机,其中包含1个Master节点和5个Slave节点。虚拟机中操作系统均为Ubuntu 14.04.3-Server-amd64版本,Hadoop版本为2.6.0,Spark版本为1.4.0,Java开发包版本为jdk1.7.0_79,程序开发工具为Eclipse Mars.1 Release (4.5.1)。其中Master节点担任NameNode角色,主要负责管理与调用并维护着所有文件的元数据,Slave节点担任DataNode角色,根据NameNode的调用检索和处理数据。
数据集采用Sogou实验室提供的分类语料库,选择语料库中整理过的搜狐新闻网站新闻语料以及对应的分类信息。实验中采用的文本为教育、互联网、财经、军事、旅游、体育、文化、健康、招聘等20大类,每个类别中有2 000篇文本,共40 000篇文档。逐个在每个类别中随机选取500篇文本组成训练集。为了确保实验的充分性和有效性,将剩余文本划分为不同大小,组成不同规模的测试集,如表1所示。
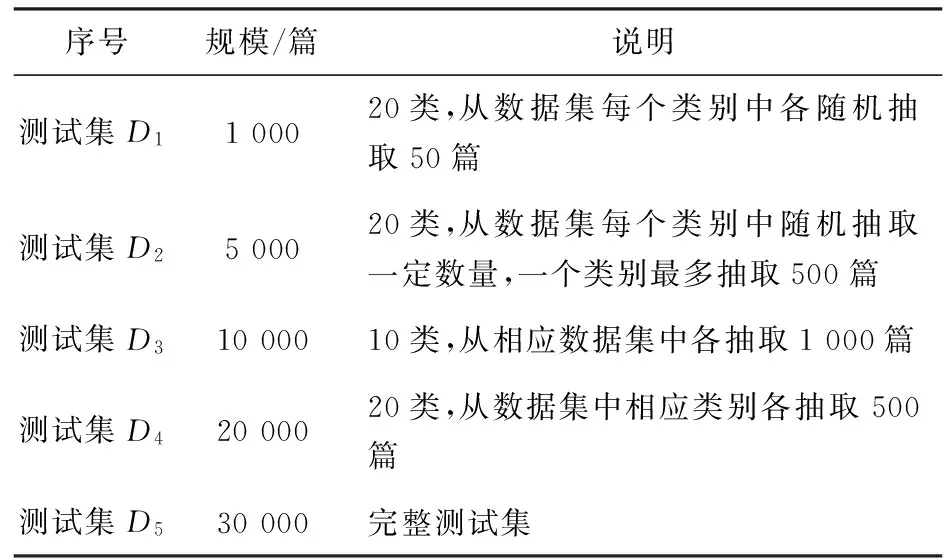
表1 测试集
3.2 评价指标
选用分类方法中常用的准确率(Pr)和查全率(Re)。准确率用于表示分类的正确性,即检测出分类文档中正确分类的文档所占的比率;查全率表示分类的完整性,即所有应分类的文档中被正确分类的文档所占的比率,公式如下:
(6)
(7)
同时为了综合评价分类效果,使用F1值:
(8)
选用加速比对Spark并行化框架进行评价:
(9)
3.3 实验结果与分析
实验首先基于词语相关度对KNN算法的影响进行验证。以准确率、查全率以及F1值为指标,在单一节点上对比基于词语相关度算法、距离加权KNN算法以及传统KNN算法的性能,如表2所示。

表2 三种算法性能比较
由表2可知,在串行状态下,基于词语相关度的算法较传统KNN算法在准确率上提高了2.5~4.9个百分点。而与距离加权KNN算法相比,在小数据集上两者分类准确率基本相似,但在较大数据集上,基于词语相关度的KNN算法的准确率随数据集的增大而逐渐提高。在查全率方面,文中算法较传统KNN算法与距离加权都有所提高,平均查全率提高了1.3和0.34个百分点。在综合指标F1中,可以看出文中算法分类效果更佳,较传统KNN算法与加权KNN算法平均值各提高了2.35和0.24个百分点。因此,在串行状态下,基于词语相关度算法可以有效提高KNN文本算法的分类效果。
为了验证文中算法是否能够有效弥补并行化过程中分区操作带来的分类准确率下降的缺陷,对传统KNN算法、基于Spark框架的传统KNN算法(3个节点)以及Spark框架下基于词语相关度优化的KNN算法(3个节点)在不同测试集下进行了比较,结果如表3所示。

表3 并行化算法性能比较
由表3可知,在运行时间方面,Spark框架下基于词语相关度的KNN算法运行时间较传统KNN算法缩短了5%~26%,与Spark框架下的传统KNN算法运行时间基本一致。表明Spark框架下的并行化KNN文本分类算法能够实现大规模文本数据的分类。而在准确率上,Spark框架下的传统KNN算法的准确度较串行状态传统KNN算法平均降低了2.1%,这是由于通常情况下的并行化算法要对数据集进行分区操作,会降低分类的准确度。而Spark框架下基于词语相关度的KNN文本分类算法较串行状态下的传统KNN分类算法准确率平均提高了1.56个百分点,较Spark框架下的传统KNN算法提高了3.68个百分点。这是由于使用词语相关度对相似度进行了优化,弥补了由并行化导致的准确度的影响。因此,文中利用词语相关度建立的距离机制有效改善了通常情况下并行化分区操作对准确度的影响。
在4个节点的情况下,Spark框架与Hadoop平台中算法在5个不同规模数据集的运行时间如图2所示。
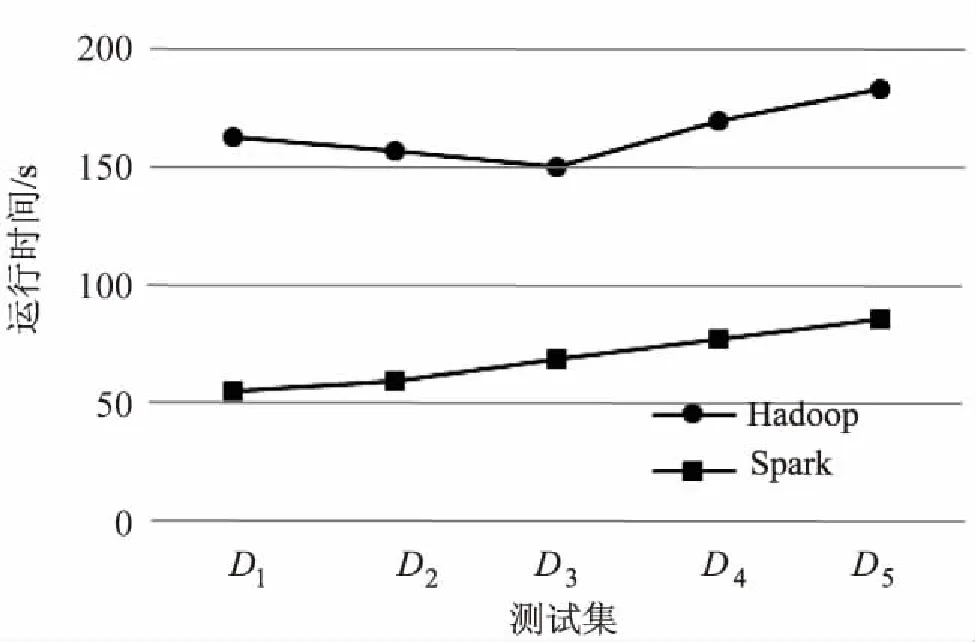
图2 两种架构运行时间比较
由图2可知,Hadoop在处理小数据集合时,运行时间较长,这是由于Hadoop平台处理过程中磁盘I/O计算时花费时间较多,在处理小样本时较为明显。而Spark框架将数据存储在内存中不需要磁盘I/O,因此在各规模数据集下运行时间平缓增长并优于Hadoop。
加速比主要用于衡量一个系统的扩展性能。当采用D4数据集时,Spark和Hadoop在不同节点下的加速比比较如图3所示。
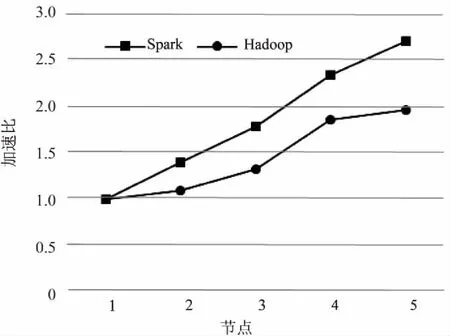
图3 两种架构加速比比较
由图3可知,加速比在Spark框架下随节点增加呈线性增长趋势,由此可知随着节点的增加能更好地提高分类处理效率,这说明Spark框架在处理KNN分类算法上具有较好的加速比。并且由此可知,节点数不断增加时Spark的加速比优势将会更为凸显。因此,Spark优于Hadoop平台具有较好的加速比,能够高效地实现大数据集的处理。
4 结束语
针对KNN分类算法在当前大数据环境下的分类问题,结合词语相关度对常用的KNN分类相似度进行优化,并在Spark框架下实现算法的并行化,提高分类效率。实验结果表明,文中提出的并行化算法在保证分类准确率的情况下,较传统KNN算法在时间效率上有明显提高。但该算法没有考虑相似度中其他属性值的影响,分类效果仍有可提高的空间。
[1] 王小林,陆骆勇,邰伟鹏.基于信息熵的新的词语相似度算法研究[J].计算机技术与发展,2015,25(9):119-122.
[2] 苏金树,张博锋,徐 昕.基于机器学习的文本分类技术研究进展[J].软件学报,2006,17(9):1848-1859.
[3] 王邦军,李凡长,张 莉,等.基于改进协方差特征的李-KNN分类算法[J].模式识别与人工智能,2014,27(2):173-178.
[4] 范恒亮,成卫青.一种基于关联分析的KNN文本分类方法[J].计算机技术与发展,2014,24(6):71-74.
[5] 王秀利.基于K最近邻文本分类的伪装入侵检测[J].小型微型计算机系统,2014,35(12):2650-2654.
[6] ZHANG L,ZHANG C J,XU Q Y,et al.Weigted-KNN and its application on UCI[C]//Proceedings of the 2015 IEEE international conference on information and automation.[s.l.]:IEEE,2015:1748-1750.
[7] 李正杰,黄 刚.基于Hadoop平台的SVM_KNN分类算法的研究[J].计算机技术与发展,2016,26(3):75-79.
[8] LU S P,TONG W Q,CHEN Z J.Implementation of the KNN algorithm based on Hadoop[C]//2015 international conference on smart and sustainable city and big data.Shanghai,China:IET,2015:123-126.
[9] ANCHALIA P P,ROY K.The k-Nearest neighbor algorithm using MapReduce paradigm[C]//Proceedings of the 2014 5th international conference on ISMS.[s.l.]:IEEE,2014:513-518.
[10] DEAN J,GHEMAWAT S.MapReduce:simplified data processing on large clusters[J].Communications of ACM,2008,51(1):107-113.
[11] GHEMAWAT S.The Google file system[J].ACM SIGOPS Operating Systems Review,2003,37(5):29-43.
[12] GROLINGER K,HAYES M,HIGASHINO W A,et al.Challenges for MapReduce in big data[C]//Proceedings of the IEEE world congress on services.Anchorage,AK:IEEE,2014:182-189.
[13] ZAHARIA M,CHOWDHURY M,DAS T,et al.Resilient distributed datasets: a fault-tolerant abstraction for in-memory cluster computing[C]//Proceedings of the 9th USENIX conference on networked systems design and implementation.Berkeley:USENIX Association,2012:141-146.
[14] 楼华锋.面向文本聚类的语义加权研究[D].上海:上海交通大学,2010.
[15] ZAHARIA M,CHOWDHURY M,FRANKLIN M J,et al.Spark:cluster computing with working sets[C]//USENIX conference on hot topics in cloud computing.Boston,MA:USENIX Association,2010:1765-1773.
[16] 梁喜涛,顾 磊.中文分词与词性标注研究[J].计算机技术与发展,2015,25(2):175-180.
猜你喜欢
黑龙江大学自然科学学报(2022年1期)2022-03-29
小资CHIC!ELEGANCE(2022年1期)2022-01-11
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
健康体检与管理(2021年10期)2021-01-03
电脑知识与技术·经验技巧(2020年3期)2020-05-07
燕山大学学报(2015年4期)2015-12-25
现代企业(2015年2期)2015-02-28
