
结合文本信息量和聚类的文本裁剪算法
2018-03-19 06:28:32邓珍荣朱益立
计算机工程与设计 2018年3期
谢 攀,邓珍荣,2,朱益立
(1.桂林电子科技大学 计算机与信息安全学院,广西 桂林 541004;2.桂林电子科技大学 广西可信软件重点实验室,广西 桂林 541004)
0 引 言
KNN方法是基于实例的学习,在分类过程中存在着耗时的缺陷[1-4],所以对训练数据集进行优化操作以减小计算量就显得很有意义。针对KNN文本分类的研究,很多学者也提出了自己的想法。周庆平等提出了一种基于聚类改进的KNN文本分类算法[5],对训练文聚类产生m个簇,利用每个簇的聚类中心构建新的训练样本空间与测试文本计算相似度,提高了时间效率,但是并没考虑文本的重要性程度;苟和平等提出一种基于密度的KNN分类器样本裁剪算法[6],该算法虽然能提高分类的准确率和时间效率,但是样本裁剪率过低;刘海峰等提出了一种基于位置的文本分类样本裁剪及加权方法[7],先通过聚类方法裁剪掉孤立点,再通过对样本加权,提高了分类的准确率,但时间效率并没有太大改进;谭学清等提出了一种基于类平均相似度的文本分类算法,在每个类中采用聚类中心作为待训练文本空间[8],提高了分类的时间效率和分类效果。
从目前的研究看,常用的解决办法是通过一定的方式筛选出具有类别代表性的训练文本,作为新的训练样本,或者通过聚类的思想找出每个类别的样本中心,然后在此基础上进行相似度计算[9-12]。
结合上述研究,本文提出一种算法。首先根据文本中的特征词及特征词出现的次数,利用本文提出的计算方法计算每条文本的权重,对每个类别中的文本重要性进行排序;再利用kmeans聚类算法将文本向量空间模型进行聚类,删除掉每个类别中的噪声样本;然后结合已经计算的样本的重要性序列,在每个类别中筛选出等量的文本,构建新的训练样本空间。后续的KNN操作,在新的训练样本空间上进行。
1 相关工作
1.1 文本预处理
文本预处理主要包括对文本正则化处理、中文分词、停用词操作。对于给定的文本,其中包含了许多特殊字符和无用的数字信息,需要通过正则化的方法去除掉这样的内容。文本操作的核心是对特征词的操作,因此必须把给定的文本序列划分成一个一个独立的词。经中文分词后,文本中存在着大量分类贡献性小的词,比如“的”、“好”等。这些词不仅占用内存,而且会影响特征词的选取,需要经过停用词操作。
1.2 特征提取
文本分类的首要问题是从高维特征中选择出具有代表性的特征,特征选择的好坏直接影响到后续的分类。高维度会导致许多问题,首先,会使得维度之间独立性变差,影响算法的分类准确性。其次,包含大量的噪声特征,存在大量类别区分度低的特征。最后,严重影响计算量及分类效率。信息增益[13]和卡方检验是目前认定较好的特征选择方法。信息增益是基于信息熵和条件熵的评估方法,是一种全局特征选取方法,同时考虑了特征词出现和特征词不出现的情况。IG计算公式为

(1)
1.3 向量空间模型
本文选择向量空间模型(VSM)[14]表示文本。在VSM模型中,每个文本被表示成向量形式d=(w1∶v1,w2∶v2,…,wn∶vn),d表示一个文本向量,wi(i=1,2,…,n)代表特征词,vi(i=1,2,…,n)为特征词在文本中的权重,n为文本集中的特征词个数。特征词权重计算公式为TFIDF。公式表述如下
Wij=tfij*idfj=tfij*log(N/nj)
(2)
1.4 KNN分类
KNN核心思想是:对一个测试样本,算出该样本与训练样本的相似度,考虑其中相似度最近的K个样本,根据多票表决制来判断待分类样本属于哪个类别。相似度计算公式为
(3)
2 结合文本信息量和kmeans的文本裁剪
KNN在文本分类问题上,存在明显缺点。当训练样本量大时,会花费大量时间在相似度计算上;当训练文本中存在着类别区分度低或噪声文本时,也会对分类造成干扰。针对KNN在文本分类上存在的问题,本文结合文本信息量和kmeans聚类对文本进行裁剪。然后在新的训练文本空间上进行KNN分类。
2.1 文本信息量的引入
文本的信息量是指一篇文本包含的类别信息,对于一篇文本D的信息量由它所包含的特征词来衡量,特征词及特征词的个数都将影响文本的信息量。特征词对于分类的信息量用IG(式(1))计算出,但是同一个特征词出现在不同类别中所携带的类别信息是不同的,引入了χ2来衡量特征词对类别相关性程度。对各类别中的文本计算信息量,并按照信息量权重的大小进行排序,得出每个类别中文本的重要性序列。
(1)χ2统计量
χ2统计方法衡量特征词与文档类别c之间的相关程度,特征词t对于类别c的χ2统计量计算公式为
(4)
在多分类中,分别计算特征词t对于每个类别的χ2(t,ci)值。其中特征与各类别卡方最大值表示为:χmax2(t)=max{χ2(t,ci)}。
(2)联合χ2和IG计算文本信息量
利用IG计算出特征词对于训练文本的全局信息量,χ2计算出特征词对于各类别的局部信息量。一个特征词包含的信息量IG表示,对于不同类别中出现的特征词,用χ2值来加权。则文本信息量可以如下表述:
设文本训练集D={d1,d2,…,dn},其中n代表训练文本的编号。训练文本的类别为C={c1,c2,…,ck},k代表类别编号。根据词袋模型统计每个特征词在每个类中出现的次数,结合信息增益公式挑选出特征词集合为T={t1,t2,…,tm},m代表特征词编号。特征词的信息增益集合IG={ig1,ig2,…,igm},每个特征词在一篇文本中出现的次数N={Nt1,Nt2,…,Ntm},根据卡方检验公式计算某个特征词的类别倾向性可以表示为:χ2(i,j)={χ2(i,1),χ2(i,2),…,χ2(i,k)}, 则每一条文本文本信息量的公式为
(5)
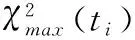
2.2 VSM模型的kmeans聚类
在文本数据中一些文本的类别具有模糊性,一方面一个文本可能本身具有多个类别属性,比如一个文本可能既包含体育的类别信息,又包含健康的类别信息;另一方面一些文本的书写不规范,包含的类别信息不明显。在TFIDF构建向量空间模型后,这样的文本常处于各个类别的交叉区域、或者错分到其它类别。这样的类别表现能力差的文本将成为噪声文本,对分类的准确性造成了负面的影响。
聚类把相似度高的样本归为一簇,簇内的相似度高,而簇间相似度低。经过聚类后,再在结合样本的类别标签,删除掉簇内干扰性样本,删减掉一些交叉类别样本,以获得表现能力更强的样本。
算法:训练样本空间kmeans聚类。
输入:经TFIDF构造的向量空间模型,聚类个数K。
输出:样本所在的簇及删减掉噪声样本的训练样本空间。
(1)对于训练样本集,随机选择K个向量作为质心,K为样本的类别个数。
(2)计算非质心文本与K个质心的相似度,并把它们加入相似度最近的质心所在的簇中。
(3)每个文本都已经属于其中的一个簇,然后根据每个质心所包含的文本的集合,重新计算得到新的质心。
(4)如果新计算的质心和上次质心之间的距离达到一个设置的阈值,算法终止,否则需要继续迭代步骤(2)至步骤(4)。
(5)结合文本原本的类别信息,删除掉每个簇中干扰性的文本,得到删减噪声样本的训练样本空间。
2.3 结合文本信息量和聚类的样本裁剪
算法的主要思想是通过计算文本的信息量,得到每个类别中文本的重要性序列。假设原始训练样本空间为W1(d),通过kmeans聚类,删减掉每个类别中的噪声文本,得到训练样本空间W2(d)。结合训练样本的重要性程度,在每个类别中筛选出等量的代表性训练样本,得到新的训练样本空间W3(d)。
假设文本训练集为S,S有K个类别C1,C2,…,Ck,S的总文本数为n。具体流程如下。
输入:训练文本集合D={d1,d2,…,dn}, 特征词集合T={t1,t2,…,tm}, 特征词的词袋模型。
(1)根据式(1)计算特征词的信息增益值,按信息增益值大小筛选特征词。
(2)根据式(4)计算特征词对于不同类别的相关性程度。
(3)结合式(5)计算每个文本所包含的信息量。并对每个类别中的文本按照信息量进行排序。
(4)根据kmeans聚类删除掉每个类别中的噪声训练样本,得到新的训练样本集合W2(d)。
(5)根据信息量有序训练样本集合W1(d)和训练样本集合W2(d),在每个类别中选择出L个训练样本,组建成新的训练样本空间W3(d),用作后续的操作。
3 改进KNN文本分类算法流程
经过改进后的KNN文本分类的流程如图1所示。
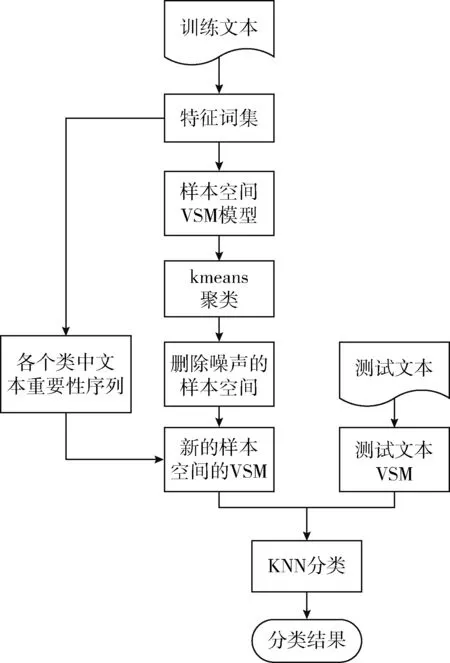
图1 样本裁剪KNN分类流程
步骤1 对文本训练集进行预处理操作、中文分词、停用词处理。
步骤2 构建词袋模型,采用式(1)计算特征词的信息增益值,选择出特征词集合。
步骤3 根据提取的特征词构建VSM,采用式(2)计算。
步骤4 利用选取的特征词及式(5)计算每个文本的信息量,并对每个类别中的文本包含的信息量进行排序,得出文本的重要性序列。
步骤5 对构建好的训练文本向量空间模型进行聚类操作,删除掉文本中的噪声样本。结合步骤4得出的重要性序列,在每个类别中筛选等量的样本。
步骤6 对测试文本进行步骤1和步骤3的操作。
步骤7 采用式(3)计算相似度,并选出K个相似度最近的样本。
步骤8 选出隶属度最大的类别C,并将待分类的文本归到该类别。
4 实验及分析
4.1 实验环境及实验数据集
实验设计如下:实验环境为Ubuntu 16.04 64位操作系统、处理器为Intel E3-1241、内存为8G,python2.7编程完成实验。本文所采用的实验数据集是搜狗实验室公开新闻语料库。从中选取了训练文本21 600篇,包括汽车、教育、财经、医疗、军事、体育6个类别,每个类别3600篇;选取了测试文本2400篇,每个类别400篇。分类效果的评估指标采用准确率、召回率、和F1值,时间采用秒来计时。
4.2 实验度量标准
准确率是指分类正确的条数与分类到该类别的条数的比值,数学公式表示为
(6)
召回率是指分类正确的条数与样本中该类别的条数的比值,数学公式表示为
(7)
F1值综合考虑准确率和召回率这两个因素,公式表示为
(8)
在针对多分类时,评估分类方法的整体性能可以用宏平均准确率、宏平均查全率、宏平均F1值只来评估。计算公式为
(9)
(10)
(11)
在多次实验对比中,当K值取30左右的时候分类效果最佳。
4.3 实验对比
比较不同特征数词目下,文本裁剪后的KNN分类、传统KNN分类及随机选取等量训练文本KNN的实验效果。比较选择特征词数为100、300、800、1000、1500、2000,2500,3000,3500,4000每个类裁剪后文本数为300时的宏平均准确率、宏平均召回率、宏平均F1值及相似度计算时间T。此时从21 600篇训练文本中筛选出了1800篇代表性样本。
由表1实验结果看出,通过文中提出的训练样本裁剪方法,在不同特征词数时都能大幅度的降低相似度计算的时间,时间降低10倍以上,而且各类评估指标并没有明显下降。实验添加了一组随机挑选等量训练文本的对比实验,虽然计算时间减少了,但分类结果会下降很多。实验在特征词数为3500左右时分类效果趋于最佳,随着特征词的增多,干扰的特征也会增加,时间复杂性变高,但分类的准确率趋于平稳。
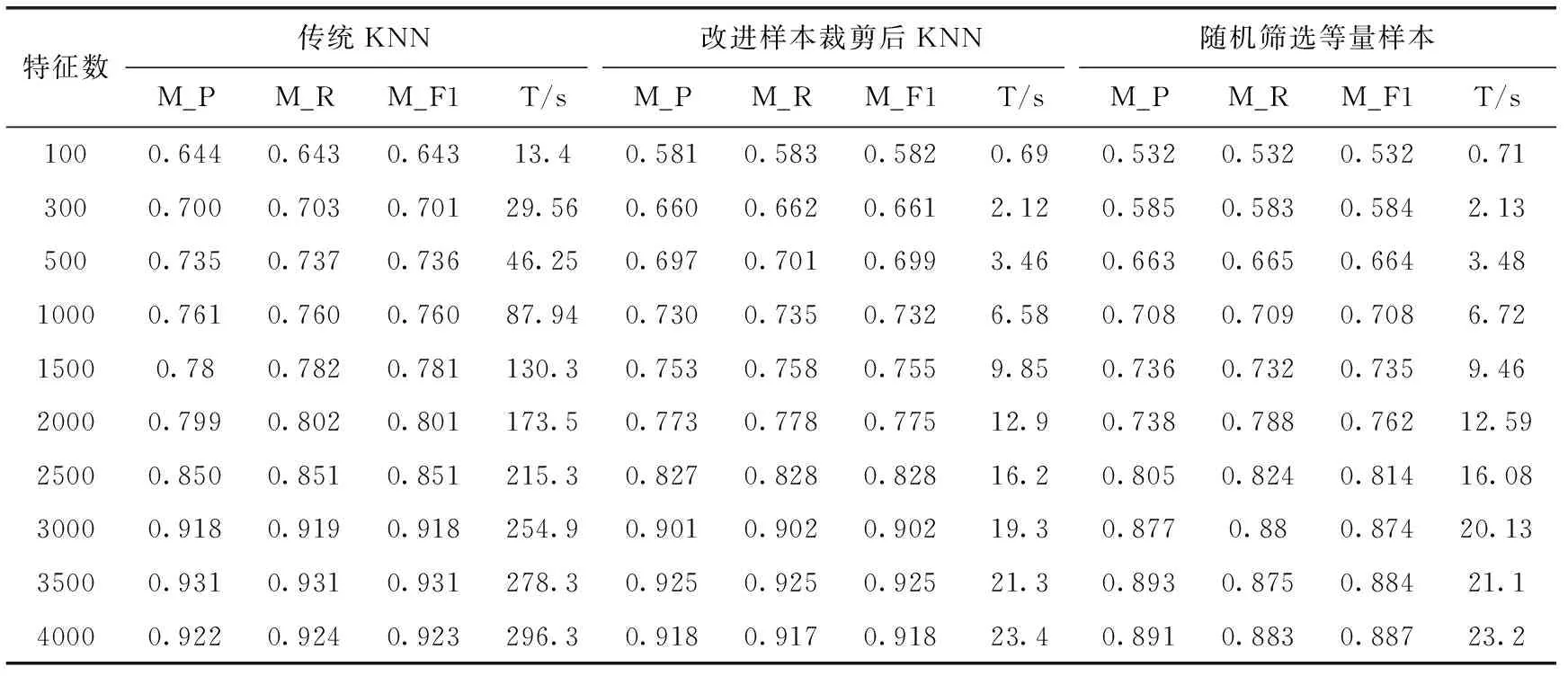
表1 裁剪文档为300不同特征数下实验结果
从每个类别中分别筛选10、50、100、150、200、300、400、600个训练样本,选择特征词数3000,文档裁剪的实验结果如图2和图3所示。

图2 不同裁剪数下实验结果

图3 不同裁剪度下运行时间
图2结果表明,当每个类样本保留200以上时,文本的分类准确率没有明显的下降。由图3结果表明,当每个类的样本保留的越多时,耗费的时间成倍增长。结合图2和图3的实验结果表明,当每个类别样本裁剪到200到300的时候分类的准确率在最高值附近,且计算相似度耗费的时间也可接受。
通过实验得出,训练文本中存在着分类无关样本或噪声样本时,对分类的时间效率和分类的准确性都存在着干扰,通过本文提出的样本裁剪方法不仅时间效率提高了,而且分类效果并没有下降,本算法在训练文本存在大量干扰样本时会表现出更强的鲁棒性。
5 结束语
本文对KNN文本分类进行了研究,鉴于KNN效率低的局限性,提出了结合文本信息量和聚类的文本裁剪算法。考虑到文本的信息量越大,则文本的重要性越高,赋予的权重也越大,越有可能被筛选为新的训练样本;同时考虑到训练样本空间中噪声文本会干扰文本的选择,结合聚类删除掉噪声的样本。实验结果表明,该样本裁剪算法可筛选出分类性能强的样本,减少计算开销,但不可避免地带来了样本信息的损失,如何既高效又实效地进行样本裁剪,是今后可研究的方向。
[1]Bijalwan V,Kumar V,Kumari P,et al.KNN based machine learning approach for text and document mining[J].International Journal of Database Theory and Application,2014,7(1):61-70.
[3]Jaderberg M,Simonyan K,Vedaldi A,et al.Reading text in the wild with convolutional neural networks[J].International Journal of Computer Vision,2016,116(1):1-20.
[4]Al-Salemi B,Ab Aziz M J,Noah S A.LDA-AdaBoost.MH:Accelerated AdaBoost.MH based on latent Dirichlet allocation for text categorization[J].Journal of Information Science,2015,41(1):27-40.
[5]ZHOU Qingping,TAN Changgeng,WANG Hongjun,et al.Improved KNN text classification algorithm based on clustering[J].Computer Application Research,2016,33(11):3374-3377(in Chinese).[周庆平,谭长庚,王宏君,等.基于聚类改进的KNN文本分类算法[J].计算机应用研究,2016,33(11):3374-3377.]
[6]GOU Heping,JING Yongxia,FENG Baiming,et al.Sample clipping algorithm based on density KNN classifier[J].Journal of Jiamusi University(Natural Science Edition),2013,31(2):242-244(in Chinese).[苟和平,景永霞,冯百明,等.基于密度的KNN分类器样本裁剪算法[J].佳木斯大学学报(自然科学版),2013,31(2):242-244.]
[7]LIU Haifeng,LIU Shousheng,SU Zhan.Sample clipping and weighting method for text categorization based on location[J].Computer Engineering and Applications,2015,51(2):131-135(in Chinese).[刘海峰,刘守生,苏展.基于位置的文本分类样本剪裁及加权方法[J].计算机工程与应用,2015,51(2):131-135.]
[8]TAN Xueqing,ZHOU Tong,LUO Lin.A text classification algorithm based on class average similarity[J].Modern Library and Information Technology,2014,30(9):66-73(in Chinese).[谭学清,周通,罗琳.一种基于类平均相似度的文本分类算法[J].现代图书情报技术,2014,30(9):66-73.]
[9]Bijalwan V,Kumar V,Kumari P,et al.KNN based machine learning approach for text and document mining[J].International Journal of Database Theory and Application,2014,7(1):61-70.
[10]Sharma M,Sarma K K.Dialectal Assamese vowel speech detection using acoustic phonetic features,KNN and RNN[C]//IEEE SPIN,2015:674-678.
[11]Liu H,Liu S S,Yao Z.An improved KNN text categorization algorithm based on the training samples distribution[J].Journal of The China Society for Scientific and Technical Information,2013,32(1):80-85.
[12]Dong T,Cheng W,Shang W.The research of kNN text categorization algorithm based on eager learning[C]//International Conference on Industrial Control and Electronics Engineering.IEEE,2012:1120-1123.
[13]Xu J,Jiang H.An improved information gain feature selection algorithm for SVM text classifier[C]//International Conference on Cyber-Enabled Distributed Computing and Knowledge Discovery,2015:273-276.
[14]Yu C Y,Shan J.Research on the web Chinese keywords extraction algorithm based on the improved TFIDF[J].Applied Mechanics & Materials,2015,727-728:915-919.
猜你喜欢
科技创新与应用(2020年6期)2020-02-29 10:39:27
西南交通大学学报(2018年5期)2018-11-08 10:59:16
计算机技术与发展(2018年8期)2018-08-21 02:08:14
中国机械工程(2017年22期)2017-12-02 01:52:34
北京理工大学学报(2016年6期)2016-11-22 11:17:22
电视技术(2016年9期)2016-10-17 09:13:41
系统工程与电子技术(2016年7期)2016-08-21 13:59:00
新闻传播(2016年11期)2016-07-10 12:04:01
计算机工程(2015年4期)2015-07-05 08:29:20
中文信息学报(2015年4期)2015-04-21 08:29:12
