
基于Fisher线性判别分析的情景感知推荐方法
2018-03-19 06:28:48杨茜
计算机工程与设计 2018年3期
杨 茜
(郑州大学 体育学院,河南 郑州 450044)
0 引 言
“信息过载”导致了互联网内容服务提供商难以为不同的用户推荐符合其偏好的资源。而随着搜索技术与检索技术的逐渐发展,能够在一定程度上缓解这些问题,由于不用的用户对于个性化的需求各不相同,导致其并不能有效帮助用户找到符合其兴趣的偏好资源。
在此需求背景下,许多的研究工作者对能够解决上述问题的推荐系统进行了深入的研究,并给出了有效的推荐系统实现策略[1-3]。其中应用范围最广、研究最深入的是协同过滤[2,3],而多数基于其的推荐预测系统,仅仅致力于通过相似度判别方法找出用户的k最近邻,通过对k最近邻行为的分析来找出当前用户可能的偏好资源。这种方法在面对冷启动[2]与数据稀疏性[3]问题时,对用户的区分度较低,很难找到真正相似的最近邻用户,在这种情况下得出的推荐结果的可靠性相对较低,很难得出高质量的推荐结果[4]。
并且,上述推荐系统仅关注于“用户-项目”间的二维关系模型,多以用户间的历史偏好数据为核心,通过度量用户偏好行为间的交互影响关系,建立用户的偏好预测模型。由于用户偏好的产生受多种内在与外界因素的影响,用户的职业、年龄、所处上下文环境等都会影响用户的偏好决策[5]。并且对于同一用户而言,当其所处的上下文环境发生变化,其偏好也会产生相应的波动[6],以位置上下文的影响为例,当位置属性为“家”时,用户会倾向于“电视节目”,当位置属性为“公共交通”时,则会更倾向于“音乐”、“新闻资讯”等。上述推荐系统由于无法辨别用户的位置等上下文环境差异,也就难以取得高质量的推荐效果。
随着“泛在计算”等新型运算模式的提出与发展,为主动发现并处理用户状态、所处位置等上下文信息提供支撑数学模型,那么融合各种上下文信息的情景感知推荐系统逐渐成为了新的发展方向。在这种情况下,受多视图学习相关理论启发,提出了一种基于线性判别分析的情景感知推荐方法,以期为相关情景感知推荐方法研究提供有益参考。
1 相关工作
情景感知推荐近年来的应用与发展越来越广泛与深入,主要的思路为将上下文信息融入偏好获取过程或对上下文信息进行建模分析,优化用户的偏好模型。例如,A.Karatzoglou等[7]提出了通过引入多种神经元来融合上下文信息,以改进协同过滤算法,提高了推荐准确度;Gantner Z等[8]采用因式分解模型对电影上下文信息进行建模分析,提高了电影推荐的准确度;涂丹丹等[9]提出了一种基于联合概率矩阵分级的情景感知广告推送方法,提高了广告推荐的精确度;郭晶晶等[10]基于物联网面向虚拟社区,提出了一种社会化网络环境下,用户群组间信任关系的推荐方法;顾梁等[11]面向播存网络环境采用协同过滤算法实现了UCL推荐策略,等。
这些方法多是基于上下文信息的建模来为用户生成推荐服务,也即是从单视图角度建立用户的偏好模型,难以全面的涵盖影响用户偏好的各种信息。并且这些方法多以提高推荐准确度为度量准则,未能兼顾多种度量标准,影响了推荐质量和推荐系统的大规模推广应用。
而多视图学习研究起源于Yarowsky[12],用多视图解决图像样本特征分类问题,其定义比较宽泛,一般只要满足“学习的数据可以用多视图描述”,目前是样本分类、模型优化与半监督学习等领域的热门研究方向,例如,将多视图学习用户复杂标签样本分类、手写数字识别等。在推荐领域,推荐的过程可以看作是样本分类的过程,即是以用户偏好为分类特征,相关的样本数据采用多视图来描述:可以从用户、项目、内容提供商等视图对相关数据进行描述,也即是推荐的产生可以转换为多视图优化问题。
受此启发,本文提出了一种基于线性判别分析的情景感知推荐方法。该方法不仅降低了时间开销,而且能够同时提高推荐准确度与多样性,即是说明了所提出方法能够兼顾多种度量准则。该方法的具体描述见下文。
2 基于多视图数据融合的情景感知推荐方法
2.1 多视图数据的获取
本文所采用的多视图数据主要包括用户视图下的偏好项目特征数据与项目视图下的项目吸引程度。其中,用户视图下的偏好项目特征数据表示基于用户的历史偏好行为,所建立起的描述其偏好项目特征的数据集合。其中用户的历史偏好信息多由评分矩阵表述(见表1),Pij指代用户Ui对于任意项目Ij的历史偏好值,偏好程度与Pij的值为正相关关系。

表1 用户历史偏好矩阵
度量用户间偏好相似程度的主流方法包括以下3种:余弦相似度[2]、修正的余弦相似度[3]、泊松相似度[7],3种度量策略的实现思路均为度量历史偏好行为偏差程度,并对其差异程度采用归一化的度量值表示。本文使用修正的余弦相似度方法作为偏好行为近似程度的度量策略,具体如下

(1)
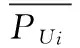
在通过上述方法获取偏好近邻的基础上,基于偏好近邻的历史偏好信息,建立用户偏好项目的属性特征描述,具体如下
(2)
(3)
其中,CUip指代用户Ui对于任意属性p的偏好特征,KNN(Ui)表示获取的用户Ui的最近邻用户集合,cUjp指代Ui的任一近邻用户Uj对于p的平均偏好度量值,Ip为Uj的历史偏好项目中,包含属性p的项目集合,PUjm表示Uj对于项目m(m∈Ip)的历史偏好值。
基于项目视图下的项目吸引力,指的是从项目视图下度量项目对于用户的吸引程度,能够反映出项目被推荐的概率。其值越大表明项目被推荐的概率也就越大,推荐系统整体的项目吸引力能够反映出用户推荐列表对于项目整体的覆盖程度。度量此值的目的在于减弱长尾效应[7],使每个项目能够推荐至偏好它的用户群组,而不是只推荐热门资源,避免冷门资源越来越冷门。项目吸引力采用A(m,Ui) 表示,具体度量方法如下
(4)

2.2 多视图数据融合
(5)
根据类间离散度与类内离散度定义,各类中的类内离散度矩阵可表示为
(6)
根据上述定义,总的类内离散度矩阵可由如下方式获取
Sk=Sk1+Sk2
(7)
类间离散度矩阵如下
St=(A1-A2)(A1-A2)T
(8)
其中,矩阵(A1-A2)(A1-A2)T是一种协方差矩阵,度量了所获取的偏好特征与总体样本数据间的约束程度,其对角线中的特征数据为偏好特征与样本总体间的样本方差,非对角线数据为样本总体的协方差。也即是Aj指代样本总体中各类特征数据间的离散冗余程度,St指代各类特征数据间的离散冗余程度。
根据分类准则,需通过降低分类后类间特征数据的近似程度,提高类内特征数据的近似程度。那么,推荐结果的产生也就转换成了找到使得Aj取得整体最小值,St取得整体最大值的分类准则。具体方法为将原两类样本数据转换为相应维度的特征向量,并以任一向量C为方向进行投影变换,如下
(9)
变换后的两类类样本均值为

(10)
变换后的类内离散度为
=CTSkjC,j=1,2
(11)
变换后的类间离散度为

=CT(A1-A2)(A1-A2)TC
=CTStC
(12)
对于转换之后的偏好项目集合的特征数据需求仍然是,降低分类后类间特征数据的近似程度,提高类内特征数据的近似程度。为此,采用Fisher判别准则进行样本数据优化,具体如下
(13)
具体方法为以其判别准则为优化目标,获得能够使JFisher最大的投影方向,具体如下
(14)
使用Lagrange乘子法作为求解方法,设CTSkC为非零常数b,则
L(C,δ)=CTStC-δ(CTSkC-b)
(15)
对C求偏导数可以得出
(16)
令偏导数为0,即是
StC′=δSkC′
(17)
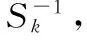
(18)
3 实验与结果分析
3.1 数据集
实验选取扩充后的BookCrossing数据集(数据集下载地址如下:http://www2.informatik.uni-freiburg.de/~cziegler/BX),并以此为基础加入一定的上下文生成规则,构建一个模拟真实数据集BookCrossing-MN。其中,核心数据集是从Book-Crossing图书社区上采集的真实数据。其中共包含278 858名读者对于271 379图书的借阅、评价等行为信息记录。BookCrossing-MN共包括如下几部分:
BC-MN-Users,读者的ID、位置、年龄;
BC-MN-Books,图书的标题、编号、所属领域、出版社、作者、页码;
BC-MN-Ratings,读者对相应图书的偏好值;
BC-MN-Contexts,包括时间、位置、状态信息等上下文信息。
3.2 算法度量准则
准确度是衡量推荐系统质量最直观与最常用的度量准则,能够直接反映出推荐结果是否符合其偏好模型。其中P@R依据推荐列表中的Top-R个相关项目,并将其与测试集中访问频次最高的Top-R个项目进行对比,其值与准确度为正相关关系

(19)
多样性是另一个度量推荐效果的度量准则,S(i,j)指代项目间的相似关系,|R|指代推荐列表的长度,那么多样性定义如下
(20)
3.3 实验及分析
实验一:参数最优取值实验
参数α为历史偏好行为次数与历史偏好值对于项目吸引力影响的修正参数,项目吸引力是从项目视图下度量项目价值。其中,历史偏好次数能够反映出项目的热门程度,历史偏好值反映的是相应项目符合用户偏好的程度。本次实验将项目吸引度最大的项目作为相应用户的推荐列表,并采用覆盖率作为度量准则。具体如下
(21)
其中,|I|指代推荐系统中所有的项目数量,R(Ui)指代Ui的推荐列表,分子指代系统中所有用户推荐列表的并集。
在本次实验中,数据集的处理采用ABO方法[14],本文在每个参数实验节点运算10次,并把其均值作为相应度量结果值。并将本文数据集划分为不同比例的训练集与测试集,经过反复对比实验,选取出有代表性的训练集比例,以及α取值(表2),对比结果如图1~图4所示。

表2 参数α代表性取值
由图1~图4可知:α取不同值的时候,训练集比例从小到大,算法的覆盖率并无统一规律,说明训练集比例对于覆盖率显著影响。另外,随着推荐列表长度的增加,覆盖率随之增加,说明提高推荐列表长度有助于获得更高的覆盖率。而其长度应依具体应用环境控制在合适的范围内。原因在于:一方面减少算法时间开销,另一方面由于数据集的稀疏性,增加推荐列表长度会导致算法涵盖不相关的偏好信息,影响推荐准确度。综合对比4个实验结果图,随着α的增加,本文方法的覆盖率呈现出先增后减的趋势,并在α=1.21时取得最优结果,因此在接下来的实验中,取α=1.21。

图1 20%数据为训练集的实验结果

图2 40%数据为训练集实验结果

图3 60%数据为训练集实验结果

图4 70%数据为训练集实验结果
实验二:算法对比实验
在获取最优参数的基础上,将本文算法与现有的算法进行实验分析对比。本文选取两个有代表性的方法RNCF[13]和GBCR[14]。其中RNCF是不考虑上下文信息的推荐方法,主要思路为通过建立归一化的评分体系,削弱用户评分尺度的影响,并在此基础上改进协同过滤算法。而协同过滤算法是最具代表性并且应用最广泛的推荐方法。GBCR是通过图模型对上下文信息建模,通过度量模型节点间相关关系生成偏好模型。GBCR是推荐系统最新的研究方向的代表性方法。由于RNCF不考虑上下文信息,所以只采用BC-MN-Ratings部分。
(1)准确性对比
准确度是目前度量推荐效果最常用的度量准则,它能够直观的反映出所推荐项目是否符合用户的偏好模型,其值越大表明推荐质量越高,本文选取具有代表意义的实验结果如图5和图6所示。
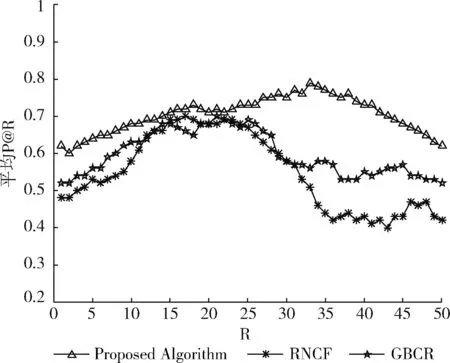
图5 40%数据为训练集实验结果

图6 60%数据为训练集实验结果
由图5,图6所示,在两组对比实验结果上,本文算法与GBCR能够相比于RNCF能够取得更好的推荐准确度,说明在建立用户偏好模型时,考虑相关的上下文信息能够提高推荐算法的推荐质量。而本文算法相比于GBCR与RNCF,准确度平均提升了13.54%、24.28%,说明采用多视图学习融合用户偏好的多视图数据能够取得更好的推荐准确度。
(2)多样性对比
多样性描述了推荐算法能否挖掘用户潜在偏好的重要度量标准。在几种不同比例训练集上进行实验测试,选取出有代表性的40%与60%的训练集比例进行对比实验,见表3。

表3 多样性对比实验结果
从表3可以看出,本文算法的多样性优于两种对比算法,相比于GBCR与RNCF多样性分别提升了26.42%与39.15%,也即是本文算法有更大的概率覆盖用户的潜在偏好。原因在于本文算法相比于两个对比算法,采用了多视图学习的方法融合了用户偏好的多维特征,某种程度上降低了用户历史偏好的影响,丰富了推荐列表的多样性。
(3)时间复杂度对比
环境为Intel(R)Core(TM)i3,主频2.1G随机HZ。选取50个用户为一组,计算3种算法的平均时间开销。实验结果见表4(时间单位为s)。
在表4中,第一列指代推荐列表长度,由表中数据可知,随着推荐列表的增加,3种算法的时间开销对随之增加,并且初始推荐的时间开销(推荐列表长度为10)较多,随着推荐列表长度的持续增加,时间开销的增加幅度逐渐减少。这是由于算法初次运行时会计算出相关的中间变量,所需的时间开销较多。3个算法中,RNCF的时间开销最少,这是由于它只采用了评分数据,没有采用上下文数据,减少了时间开销。而本文算法的时间开销比GBCR减少约7.74%,说明相比于现有的情景感知推荐方法,本文能够降低算法的时间开销。

表4 时间开销对比
4 结束语
情景感知推荐方法研究是目前人工智能研究热点之一,国内外各个研究机构、大学和互联网巨头公司等都投入了大量的人力和物力进行探索和研究。现有的情景感知推荐方法,多采用单视图数据建立用户的偏好模型,导致了推荐结果无法兼顾多种度量准则,影响了推荐质量。受多视图学习相关理论启发,提出了一种基于线性判别分析的情景感知推荐方法,与现有的方法比较,本文方法不仅降低了时间开销,而且准确度平均提高18.91%,多样性平均提高32.79%,即是说明了所提出方法能够兼顾多种度量准则,提高了推荐质量。
[1]SUN Guangfu,WU Le,LIU Qi,et al.Recommendations based on collaborative filtering by exploiting sequential beha-viors[J].Journal of Software,2013,24(11):2711-2733(in Chinese).[孙光福,吴乐,刘淇,等.基于时序行为的协同过滤推荐算法[J].软件学报,2013,24(11):2711-2733.]
[2]WANG Xingmao,ZHANG Xingming.Collaborative recommendation algorithm based on contributor factor[J].Application Research of Computer,2015,32(12):132-136(in Chinese).[王兴茂,张兴明.基于贡献因子的协同过滤推荐算法[J].计算机应用研究,2015,32(12):132-136.]
[3]WU Yueping,DU Yi.Collaboration filtering recommendation algorithm based on artificial fish swarm algorithm[J].Computer Engineering & Design,2012,33(5):1852-1856(in Chinese).[吴月萍,杜奕.基于人工鱼群算法的协同过滤推荐算法[J].计算机工程与设计,2012,33(5):1852-1856.]
[4]GAO Ming,JIN Cheqing,QIAN Weining,et al.Real-time and personalized recommendation on microblogging systems[J].Chinese Journal of Computers,2014,37(4):963-975(in Chinese).[高明,金澈清,钱卫宁,等.面向微博系统的实时个性化推荐[J].计算机学报,2014,37(4):963-975.]
[5]Wu H,Yue K,Liu X,et al.Context-aware recommendation via graph-based contextual modeling and postfiltering[J].International Journal of Distributed Sensor Networks,2015(3):1-10.
[6]Kim J,Lee D,Chung K Y.Item recommendation based on context-aware model for personalized u-healthcare service[J].Multimedia Tools and Applications,2013,71(2):855-872.
[7]Karatzoglou A,Amatriain X,Baltrunas L,et al.Multiverse recommendation:N-dimensional tensor factorization for context-aware collaborative filtering[C]//Proceedings of the Fourth ACM Conference on Recommender Systems.New York:ACM,2013:79-86.
[8]Gantner Z,Rendle S,ST L.Factorization models for context-/time-aware movie recommendations[C]//Processing of the Recsys Workshop on CAMRa.New York:ACM press,2014:14-19.
[9]TU Dandan,SHU Chengchun.Using unified probabilistic matrix factorization for contexual advertisement recommendation[J].Journal of Software,2013,24(3):454-464(in Chinese).[涂丹丹,舒承椿.基于联合概率矩阵分级的上下文广告推荐算法[J].软件学报,2013,24(3):454-464.]
[10]GUO Jingjing,MA Jianfeng.Trust recommendation algorithm for virtual community based interest of things[J].Journal of XiDian University,2015,42(2):52-57(in Chinese).[郭晶晶,马建峰.面向虚拟社区物联网的信任推荐算法[J].计算机研究与发展,2015,42(2):52-57.]
[11]GU Liang,YANG Peng,LUO Junzhou.A collaborative filtering recommedation method for UCL in broadcast-storage network[J].Journal of Computer Research and Development,2015,52(2):475-486(in Chinese).[顾梁,杨鹏,罗军舟.一种播存网络环境下的UCL协同过滤推荐方法[J].计算机研究与发展,2015,52(2):475-486.]
[12]Baltrunas L,Ricci F.Experimental evaluation of context-dependent collaborative filtering using item splitting[J].User Modeling and User-Adapted Interaction,2014,24(1):7-34.
[13]Kim S C,Sung K J,Park C S,et al.Improvement of colla-borative filtering using rating normalization[J].Multimedia Tools and Applications,2013,6(2):1-12.
[14]Wu H,Yue K,Liu X,et al.Context-aware recommendation via graph-based contextual modeling and postfiltering[J].International Journal of Distributed Sensor Networks,2015,21(3):1-10.
猜你喜欢
小学生学习指导(高年级)(2024年4期)2024-05-07 03:28:46
初中生学习指导·提升版(2023年11期)2023-12-16 12:44:18
科学咨询(2022年19期)2022-11-24 04:23:25
小学生学习指导(中年级)(2021年4期)2021-04-27 10:14:56
课堂内外(初中版)(2020年5期)2020-06-19 08:11:11
中学生数理化·中考版(2017年6期)2017-11-09 02:46:46
非公有制企业党建(2017年10期)2017-11-03 02:26:27
现代兵器(2017年4期)2017-06-02 15:59:24
现代兵器(2017年4期)2017-06-02 15:58:14
中学生数理化·八年级数学人教版(2015年12期)2015-05-30 10:48:04
