
基于RNTN和CBOW的商品评论情感分类
2018-03-19 05:58彭三春张云华
计算机工程与设计 2018年3期
彭三春,张云华
(浙江理工大学 信息学院,浙江 杭州 310018)
0 引 言
构建商品评论情感分类模型[1-4],是自然语言处理的范畴,在很长的一段时间里,基于统计模型的解决方法是自然语言处理的主要方法,在该基础上,人工神经网络也随之应运而生。而且相较于浅层模型,采用深度学习的人工神经网络模型表示的效果更好,需要的参数较少,模型结构层次较多,而且多层人工神经网络模型因其很强的特征学习能力得到的特征数据更加精准,从而效率更高[5,6]。使用深度学习技术处理中文自然语言问题的相关研究工作目前还处于起步阶段,这是因为中文和英文之间存在着本质的区别:中文的基本意义单元是汉字,而英文则是单词。中文汉字的意义比英文单词的意义更多更丰富,字与字之间的结合关系也比英文单词的组合更加复杂。中英文之间的这种区别可能导致在英文环境下具有良好效果的神经网络模型到中文环境下却完全不适用[7-9]。本文依据深度学习原理,在现有文本情感分类方法的基础上,提出了基于RNTN和CBOW的文本情感分类模型框架及模型。以网络爬虫系统爬取的真实数据作为实验数据,并与机器学习方法中表现最好的SVM模型以及深度学习表现好的RNN模型进行比较,取得了比较好的结果。
1 商品评论情感分类模型框架
商品评论情感分类模型主要由3部分组成,分别为评论文本数据准备、词向量表示和情感分类3部分,其研究框架如图1所示。

图1 商品评论情感分类模型框架
1.1 评论文本数据准备阶段
该阶段的主要工作是通过网络爬虫系统在淘宝网爬取关于小米手机的50 000条评论,并且根据评论正负差异情况选取实际实验数据。
1.2 词向量表示阶段
该阶段的主要工作是文本表示。而文本表示的基础是从文本数据中提取出能表示该文本的特征,而文本的特征必须能够对文本进行充分表示,反映文本在特征空间中的分布以及明显的统计规律,在保证正确率的同时还要尽可能减小文本映射到特征空间时计算的复杂度[10]。
词向量被誉为是一项利器,在许多NLP任务中,词向量已经完全地取代了传统的分布特征,比如布朗聚类和LSA特征。它的优势在于不需要人工标注语料,直接使用未标注的文本训练集作为输入。输出的词向量可以用于下游的业务处理[11]。本文基于CBOW模型,使用优化的CBOW模型训练词向量,在保证词向量语义信息不损失的前提下,更高效地获得分布式词向量。CBOW模型是以哈夫曼树作为基础,抛弃了计算繁琐的非线性隐藏层,同时所有词语共享隐藏层,它支持向语言模型中添加额外信息模型如图2所示。
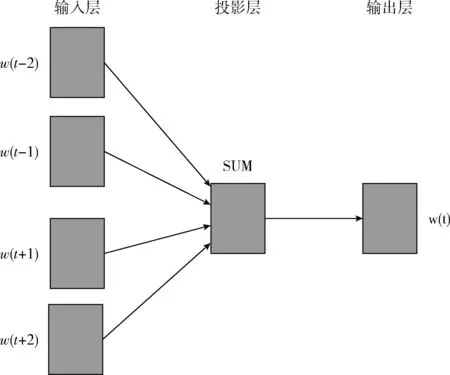
图2 CBOW模型
哈夫曼树中非叶节点存储的中间向量的初始化值是零向量,而叶节点对应的单词的词向量是随机初始化的,从输入层到投影层,CBOW是对上下文向量w(t)的线性求和,而从投影层到输出层,借助之前构造的哈夫曼树,从根节点开始,投影层的值需要沿着哈夫曼树不断的进行逻辑分类,并且不断的修正各中间向量和词向量[12,13]。学习CBOW模型的参数,传统的模型使用的是softmax,但softmax计算复杂度高,尤其语料词汇量大的时候。所以本文用的Negative Sampling来近似计算,目的是提高训练速度并改善词向量的质量。Negative Sampling不再使用复杂的哈夫曼树,而是采用随机负采样的方法,增大正样本的概率同时降低负样本的概率。
在CBOW模型中,已知词w的上下文Context(w),需要预测w,因此对于给定的Context(w),词w就是一个正样本,其它词就是负样本,对于一个给定的样本(Context(w),w),我们希望将其最大化,即
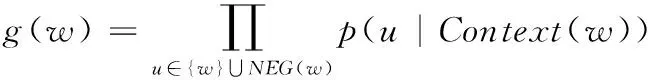
(1)
其中,NEG(w)表示负样本集,正样本标签为1,负样本标签为0,其概率计算如下
(2)
或者写成整体表达式
(3)
优化目标是最大化g(w),即增大正样本的概率同时降低负样本的概率。对于一个给定的语料库C,函数G就是整体优化的目标,为了计算方便,对G取对数,最终目标函数如下

(4)
利用随机梯度上升对上式进行求解即可,这里直接给出梯度计算结果

(5)
故参数θu更新后的公式如下

(6)
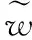

(7)
1.3 情感分类阶段
该阶段的主要工作是根据已知文本评论数据集构造出一个文本分类模型(或称文本分类器)。目前常用的文本分类模型有很多种,如K紧邻算法(KNN)、朴素贝叶新算法、决策树算法、支持向量机算法、粗糙集算法、人工神经网络算法(ANN)等[14]。本文将基于递归神经张量网络,调查了近年来这些问题的相关研究,分析了现有方法的特点,优化了模型训练过程。而且新加入的词矩阵使得该模型不仅可以充分的表达嵌入词含义,还能学习一个单词是如何“修饰”其它单词。在本文的情感分析中,最终的分类结果将不仅仅表达正向和负向,而是细化为5类,分别为强烈的负向情感、负向情感、中性、正向情感、强烈的正向情感。
2 基于递归神经网络的商品评论情感分类模型
2.1 一个单层的递归神经张量网络
为了加强词的表示形式,除了词向量外,往其中加入一个矩阵,新加入的矩阵与词向量构成矩阵-向量形式。基于这种形式,将两个单词作为递归神经网络(RNN)的输入,分别表示为a和b,其对应的词矩阵表示为A与B,接下来将向量Ab与Ba进行连接得到f(Ba,Ab),将f(Ba,Ab)作为新的输入向量x。其模型如图3所示。

图3 矩阵-向量递归神经网络模型
但是通过观测模型的误差,发现矩阵-向量递归神经网络模型(MV-RNN)对于中文的某些特定的关系,依然不能表达,而且会出现3类错误,第一类错误是否定正向的,即评论中的一些正向积极的情感会因其中的一个否定词而变成负向的,比如评论中有“不是很好”,表示的是负向情感,但是MV-RNN模型并不能理解“不”可以翻转整个句子的情感;第二类错误是否定负向的,比如评论中有“不是不好”,MV-RNN模型不能领略到“不”可以减轻负向的情绪;第三类错误是前两类错误的结合。因此,为了能够充分表达这些特定的关系,急需一个更具表现力的合成算法。而递归神经张量网络模型(RNTN)新加入一个词矩阵的概念,可以很好的解决前面3种问题,而且由该方法表示的单词向量可以显示句法和语义信息。其预处理过程是以向量∈R2d的形式连接起来,在通过一个二次型处理之后,将其变为非线性,从而得到两个词向量或短语向量,如
h(1)=tanh(xTVx+Wx)
(8)
其中,V是3阶张量V∈R2d*d*d,二次型xTV[i]x,i∈[1,2,…d],张量输出向量∈Rd,Wx是词向量,tanh是一个非线性函数的变换。通过这个二次型可以得出一个结论,模型并不需要保持和学习词矩阵,但是乘法类型的词向量的直接相互作用是我们需要的,而且这里的单词不是向量表示,也不是简单的矩阵-向量形式,而是引入一个词矩阵的概念,则递归神经张量网络模型如图4所示。

图4 递归神经张量网络模型
上面模型可以表示为
(9)
图4所示的是一个单层的递归神经张量网络,每个虚线框代表d个片层(V[1∶d])中的一片,并且能够计算子节点对父节点的影响,其中,W是之前模型定义好的参数,f可以选取tanh()等激活函数。使用复合函数来计算两个词向量(叶节点b,c)合成的新向量(父节点)。张量h可以直接和词向量相关联。更直观地,我们可以把张量h里面的“片”结构看成是捕捉词向量特征的。当张量增加到第二层的时候,RNTN模型就可以很好地使词向量复合函数变得更加有效简单。那么如何训练RNTN模型。正如前文所说,通过对每一个节点的特征向量进行训练,得到其softmax的分类结果,通过这种方法来预测一个给定的值或者一个目标向量t。我们假设这个目标向量t符合0-1编码。如果这是一个有C个不同的级别的目标向量t,那么t就是一个长度为C的向量,其中,对应级别的标注是1,其它级别通通被标注为0。
2.2 递归神经张量网络的训练
递归神经张量网络模型克服了RAE模型中贪心算法带来的巨大运算量问题,树的每个节点都可以由向量来表示[15]。模型使用字向量作为特征输入,预测5种情感类别的分布,其分类函数使用softmax函数,表示形式为
ya=softmax(Ws,a)
(10)
其中,Ws∈R|V|*d是情感分类矩阵,因为本文最终分成5类则Ws∈R5*d,a表示分类器所在的词语。模型训练的主要目标是为了最小化每一个节点的测试分类yi∈Rc*l和目标分类ti∈Rc*l的交叉熵。定义RNTN模型的参数为θ=(V,W,Ws,L,LM),λ为规范化的先验分布参数。L为单词的向量集,LM为单词的矩阵集。在一个评论文本中,交叉熵就是一个RNTN模型参数θ的函数,如下式
(11)
为使上式达到最小,首先需要求解RNTN模型的参数θ,由于softmax分类中的权重微分表达式具有一般性,而且可以简单的通过各节点的误差之和得到,所以定义xi∈Rd*l作为节点i的一个向量,忽略权重Ws的标准积分表达式,定义δi,s作为节点i的softmax误差
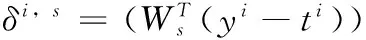
(12)
在这里,⊗是哈达玛算子,f′是f的导数,在这里,使用f=tanh来计算f(xi)。剩下的微分可以仅仅通过对自上而下的树形结构的计算得到,参数V,W的完整微分形式,是叶子结点的V,W的总和。通过反馈计算得到一般性的派生参量W,针对每一片k=1……d的微分表达形式为
(13)
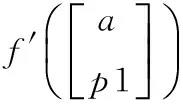
(14)
其中
(15)
p2的两个子节点会把向量S中的半个向量添加到它们各自的softmax误差中来计算δ
δp1,com=δp1,s+δp2,down[d+1∶2d]
(16)
这里的δp2,down[d+1∶2d]表示p1是p2的右子节点,因此用右半部分计算softmax误差,则最后的词向量微分形式应该是δp2,down[1∶d],在一个二叉树中,第V[k]部分的全微分表达式就是各节点的总和
(17)
同理,以上面同样的方式计算W,在上面的处理过程中,充分利用了张量分解的强大优势,使得计算过程得到了简化,从而加快了计算速度。
3 基于RNTN和CBOW的情感分类模型
在递归神经张量网络的基础上,本文将RNTN模型与CBOW模型结合,从而针对性地优化RNTN模型在情感分类任务上的性能,在CBOW模型训练好的词向量的基础上,添加一个矩阵,构成词矩阵,通过这么做,新的模型在改善了词向量的质量的基础上,即能表达嵌入词的含义,还能学习一个单词如何“修饰”其它单词,词向量的加法组合运算能够很好地反映词与词的共同属性,加快了训练速度,在后序的实验结果中取得了比较好的结果。
4 模型的实例计算
4.1 实验环境
本文的实验环境配置见表1。

表1 实验环境配置
4.2 实验语料
本文的实验语料是通过网络爬虫系统在淘宝网爬取关于小米手机的50 000条评论,但是由于爬取的商品评论中正负类差异很大比例为10∶1,属于严重不平衡语料,同时也存在很多的超短评论,可能导致最终的分类结果与真实结果出现偏差。因此为了保证分类的正确性,选取了其中的10 000条,正负性评论分别为5000条,将其中的6000条评论用于训练,剩下的4000条评论用于测试。作为参照实验,在相同的数据上,本文选取递归神经网络模型RNN以及传统的机器学习中最好的方法支持向量机SVM方法。
4.3 评价标准
常用的文本情感分类性能评测指标包括准确率、召回率和F值(F-Measure),为了测试基于RNTN和CBOW的分类方法与其它分类方法的效率对比,本文选取了F1值,F1值为正确率和召回率的调和平均数[16]。
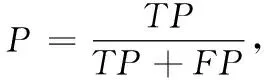
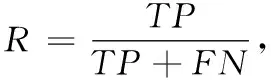
其中,TP为正确被分类的评论条数,TP+FP实际分类的评论总数。TP+FN为应该被分类的评论数[17]。

4.4 实验结果与分析
将实验数据按照本文模型以及参照模型进行训练,实验结果见表2。所有实验结果都经过交叉验证,正确率很高,具有较高的可信度。
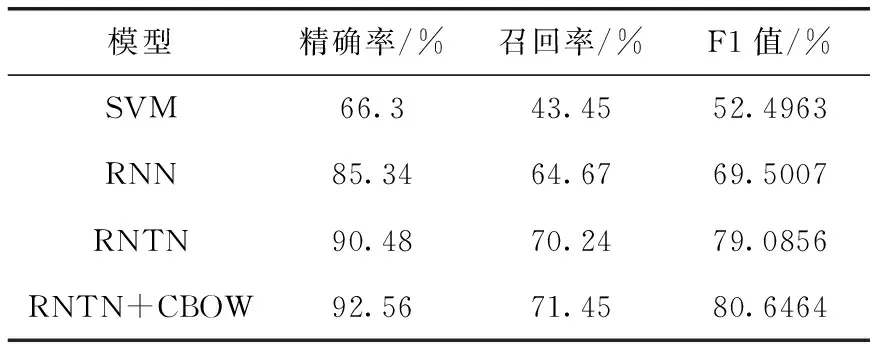
表2 实验结果
相比于传统的机器学习方法,RNTN模型在情感分类任务上已经获得了出色的性能提升。RNTN模型仅靠模型自身的特征提取能力其精确率就达到90.48%,与现在表现最好的SVM模型相比提高了24%,与现有深度学习模型RNN相比提高了5%。这也同时验证了递归神经张量网络结构在噪声数据环境下的健壮性。RNTN模型加上优化的CBOW模型将分类正确率由90.48%提升到92.56%,一方面CBOW模型在保证词向量语义信息不损失的前提下,更高效地获得分布式词向量,能够在更抽象的层面上描述原始输入数据的特征分布情况,另一方面,将CBOW模型的输出加上一个词矩阵作为RNTN模型的输入特征并在迭代训练过程中不断更新参数,这相当于在一定先验知识的基础上,在训练过程中可以引导模型按照更好的方向收敛到最优解。从而提高模型训练的速度和准确率。
5 结束语
互联网的迅猛发展,网上购物己经成为许多人购物时的首选,商品评论对于买卖双方来说都是非常有价值的信息。但是互联网的信息数量巨大,通常产品评论的数据量超出了人工分析所能接受的范围。虽然用户可以直观地理解每一条其他用户评论的内容,但用户不可能浏览全部评论并做出完善的综合分析[18,19]。本文在分析中文情感表达特点和文本语义的基础上,提出了基于RNTN和CBOW的商品评论情感分类模型,对互联网上的小米手机评论进行情感分类。实验结果显示,与传统机器学习方法SVM以及现有的深度学习方法RNN相比,本文提出的情感分析方法在情感分类的精确率上有明显的提高。由于用深度学习方法对文本进行情感分析,不需要建立情感词典,因此该模型可以用于不同领域中的情感分类,在后继的研究中,将会在继续提高情感分类准确率的同时研究将模型运用于不同领域的情感分类。
[1]Minkov E,Cohen W W.Graph based similarity measures for synonym extraction from parsed text[C]//Workshop Proceedings of TextGraphs-7 on Graph-based Methods for Natural Language Processing.Jeju:The Association for Computational Linguistics,2012:20-24.
[2]Huang T H K,Yu H C,Chen H H.Modeling pollyanna phenomena in Chinese sentiment analysis[C]//Proc 24th International Conf Mumbai:Demo,2012:231-238.
[3]Chen K,Luo P,Wang H.An influence framework on product word-of-mouth (WoM) measurement[J].Information & Management,2017,54(2):228-240.
[4]Bazinet A L,Cummings M P.A comparative evaluation of sequence classification programs[J].BMC bioinformatics,2012,13(1):92.
[5]Kim Y.Convolutional neural networks for sentence classification[C]//Proceedings of the Conference on Empirical Met-hods in Natural Language Processing.Doha:Association for Computational Linguistics,2014.
[6]Ghiassi M,Skinner J,Zimbra D.Twitter brand sentiment analysis:A hybrid system using n-gram analysis and dynamic artificial neural network[J].Expert Systems with Applications,2013,40(16):6266-6282.
[7]Dong L,Wei F,Tan C,et al.Adaptive recursive neural network for target-dependent twitter sentiment classification[C]//Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics.USA:The Association for Computational Linguistics,2014:49-54.
[8]Severyn A,Moschitti A.Twitter sentiment analysis with deep convolutional neural networks[C]//Proceedings of the 38th International ACM SIGIR Conference on Research and Development in Information Retrieval.Santiago:ACM,2015:959-962.
[9]Mudinas A,Zhang D,Levene M.Combining lexicon and learning based approaches for concept-level sentiment analysis[C]//Proceedings of the First International Workshop on Issues of Sentiment Discovery and Opinion Mining.Beijing:ACM,2012:5.
[10]ZHOU Jiayi.Research on the classification of semantic relations in English based on tensor recurrent neural networks[J].Modern Computer:Universal Edition,2015(4):43-47(in Chinese).[周佳逸.基于张量递归神经网络的英文语义关系分类方法研究[J].现代计算机:普及版,2015(4):43-47.]
[11]Vinodhini G,Chandrasekaran R M.A comparative performance evaluation of neural network based approach for sentiment classification of online reviews[J].Journal of King Saud University-Computer and Information Sciences,2016,28(1):2-12.
[12]Minkov E,Cohen W W.Learning graph walk based similarity measures for parsed text[J].Natural Language Engineering,2014,20(3):361-397.
[13]Zhao Y,Qin B,Liu T.Creating a fine-grained corpus for Chinese sentiment analysis[J].Intelligent Systems IEEE,2015,30(1):36-43.
[14]Qian X,Liu Y.Joint Chinese word segmentation,POS tagging and parsing[C]//Proceedings of the Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning.Jeju:Association for Computational Linguistics,2012:501-511.
[15]Wang Y,Li Z,Liu J,et al.Word vector modeling for sentiment analysis of product reviews[M]//Natural Language Processing and Chinese Computing.Berlin Heidelberg:Springer International Publishing,2014:168-180.
[16]Chen H,Jin H,Yuan P,et al.Sentiment classification for Chinese product reviews based on semantic relevance of phrase[M]//Web Technologies and Applications.Germany:Springer International Publishing,2015:340-351.
[17]Wu X,Lu H T,Zhuo S J.Sentiment analysis for Chinese text based on emotion degree lexicon and cognitive theories[J].Journal of Shanghai Jiaotong University(Science),2015,20(1):1-6.
[18]Du H,Xu X,Cheng X,et al.Aspect-specific sentimental word embedding for sentiment analysis of online reviews[C]//International Conference Companion on World Wide Web.Canada:International World Wide Web Conferences Steering Committee,2016:29-30.
[19]Cambria E,Hussain A,Durrani T,et al.Towards a Chinese common and common sense knowledge base for sentiment analysis[C]//Engineering and Other Applications of Applied Intelligent Systems.Dalian:Springer International Publi-shing,2012:437-446.
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
数学物理学报(2021年1期)2021-03-29
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
五邑大学学报(自然科学版)(2020年4期)2020-12-09
阅读(快乐英语高年级)(2020年8期)2020-01-08
智慧少年·故事叮当(2018年11期)2018-05-14
意林(绘英语)(2017年5期)2017-05-15
山西大同大学学报(自然科学版)(2016年2期)2016-12-12
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
