
基于信号序列的在线签名认证方法及应用
2018-03-19 05:58张梓轩贺也平
计算机工程与设计 2018年3期
张梓轩,贺也平
(1.中国科学院 软件研究所,北京 100080;2.中国科学院大学 计算机与控制学院,北京 100049)
0 引 言
在线签名是生物特征信息的一种,随着人工智能的发展得到了越来越多的关注,并逐渐应用到身份认证上。然而目前基于在线签名的身份认证方法的性能和应用场景仍有待突破。本文主要针对该问题进行研究。
1 相关研究
在线签名认证系统中,用户首先需要提供若干自己的签名作为参考签名集(reference signature,RS),这个阶段称为注册阶段。这里假设该用户为A。在认证阶段,当一个用户声称自己是A时,则需要提供一份签名,称为待测签名,用于对该用户进行身份认证。系统将该签名与用户A的参考签名集进行比对,从该待测签名中提取特征,生成特征向量,然后通过一定的决策机制来判定该签名是真实签名还是伪造签名,以此判断该用户身份是否是A。
触屏设备可以实时获取签名者签名时任意时刻(T)笔尖的X轴坐标值(X),Y轴坐标值(Y),压力值(P)。除此之外,还可以使用特殊的设备采集书写时笔的运动方向、倾斜角度、签名时手腕转动的信息[1]。本研究的目的是提出一种有效的通过智能手机、平板等一般设备进行认证的算法。因此本文中提到的原始签名信息由T,X,Y,P四维信号组成。除此之外,由原始的签名信息可以计算出签名时任意时刻的X轴速度(VX),Y轴速度(VY)。因此最终的签名信息由{T,X,Y,VX,VY,P}6种信号组成。这些信号均为有时间顺序的一维向量。
每个人在签名时都有自己的特点,认证技术的核心是提取出签名者签名的特点,并且利用这些特征将真实签名和伪造签名区分开。所以特征提取的好坏直接影响认证效果。在线签名认证技术,根据特征提取方法的不同,分为两大类:基于特征参数的方法[2-6]和基于函数的方法[7,8]。基于特征的方法是计算出签名的描述性特点,如平均速度,签名时长等,用这些特征来代表签名。王容霞[2]提取了127个参数特征集,例如平均速度、签名时间等,然后利用PCA技术对特征集进行降维。还有一些研究通过对签名样本进行数学变换,将得到的系数作为特征[3,4,6]。这种数学变换的结果可以生成固定数量的特征,因此易于比较。Rashidi等[3]使用离散余弦变换技术将原始签名信号生成的系数作为特征,在实验的时候控制特征系数的数量,达到最好的效果。Fayyaz等[4]使用自编码器从签名信息学习到特征,也取得了一定的效果。基于特征的方法优点是计算量一般较小,并且在远程认证的场景下由于不需要传递原始的签名样本信息,因此相较于基于函数的方法更加安全[5]。其难点在于从签名中提取出有效的用于认证的描述性特征。
基于函数的方法将完整的信号序列看作时间的函数,并且直接利用信号序列将待测签名与参考签名集进行匹配认证。基于函数的方法由于保留了书写过程中完整信息,所以一般比基于特征参数的方法得到更好的效果。但是这种方法面临的挑战是由于签名者每次签名时的持续时间不定,信号长度也就不同,因此造成信号在时间轴上的非线性扭曲现象。Gruber等[8]提出了一种计算两个签名的最长公共子序列的算法,并将此算法作为SVM模型的核函数来解决这个问题,取得了一定的效果。邱益鸣等[9]提出了一种曲线相似度计算模型,依照参考签名曲线的有效点数,对待测签名进行重采样,采用分段匹配的方式计算相似度。一些研究使用动态时间规整来解决这个问题[7]。动态时间规整方法的目的在于找到两个有时序的序列的最佳匹配,因此可以计算两条信号序列的相似度。在Kholmatov A,Yanikoglu B的文献[7]中,使用基于动态时间规整的方法来计算签名之间的相似度。该论文首先从参考签名集中选出模板签名,在测试阶段时,计算测试签名到模板签名的距离、到参考签名集距离的最大值和最小值,以这3个值为作为签名的特征进行身份认证。然而,该方法在计算签名之间的相似度时并没有考虑不同信号可能具有不同的权重的问题。
为了对认证系统进行性能评价,一般有两个指标:误纳率(false accept rate,FAR)和误拒率(false reject rate,FRR)。因为这两个指标具有负相关,因此可以使用等误率(equal error rate,EER)从整体上评价该系统,等误率是指误纳率和误拒率相等时的值。等误率越小说明该系统性能越高。
2 系统介绍
目前大多数在线签名认证的研究都是基于传统的电子手写板设备采集的签名,如著名的公开数据集SUSIG[10],很少有基于移动设备的研究。然而传统的手写板上采集的签名与移动设备上采集的签名是不同的。一方面,移动设备由于有限的运算和内存资源使得信号采集的方式与传统的手写板不同。SUSIG数据集使用100 Hz频率的手写板采集签名,而在Android系统上,并没有特定的采集频率,而是当手指等触摸屏幕后,驱动层将触摸坐标及时间传给进程进行处理。另一方面,传统的电子手写板配有专用的手写笔,而在移动设备上,人们一般使用手指,因此移动设备上采集的信号比传统手写板较为不精确。图1为在Android系统上采集的手写签名样本图。

图1 Android设备手写签名样本
正如图2描述的,本文提出的认证系统由两个阶段组成:训练阶段和测试阶段。
训练阶段的主要目的是为了对测试使用的分类器进行训练。在训练阶段,系统首先从训练签名数据库中获取训练签名和该签名所对应身份ID及该签名的标签。签名的标签是指该签名是真实签名还是伪造签名,因而标签的取值为0或1。然后系统从参考签名数据库中获取该ID身份对应的参考签名集,并从参考签名集中选择模板签名。其次系统将利用参考签名集和模板签名从该训练签名中提取特征,生成特征向量。之后系统利用该签名的特征向量和标签对分类器进行训练。

图2 在线签名认证系统流程
在测试阶段,系统的输入为测试签名及该签名所声称的身份ID。系统将从参考签名数据库中查找该身份ID对应的参考签名集。然后同样经过模板选择,特征提取过程生成特征向量。此时,已经训练好的分类器对该特征向量进行决策,判断该签名是真实的签名还是伪造的签名。
本节的其余部分将对本系统的各个模块和算法进行说明分析。
2.1 签名预处理
签名信息的预处理主要是为特征提取时提供比较准确的信息,消除数据采集过程中因为环境和设备产生的各种干扰和失真。关于签名预处理的使用,不同研究者持有不同的态度。一方面,数据预处理可以提高真实签名的一致性,降低错误拒绝率。另一方面,数据预处理的同时对伪造签名也有同样的效果,减少了伪造签名与真实签名的差异,可能会增加错误接受率[2]。
在本文中,经过实验验证,一定程度的预处理可以提高认证效果。本文使用的预处理技术包括大小归一化和位置归一化。
2.1.1 大小归一化
大小归一化将签名数据的坐标值归一化到统一的区间内,其公式如下
(1)
(2)
其中,x(t),y(t)分别代表t时刻的X坐标和Y坐标,kX,kY是常数,代表X轴和Y轴归一化后的坐标最大值。xmax,xmin,ymax,ymin分别代表横、纵坐标的最大值和最小值。经过大小归一化,签名数据的X轴坐标被归一化到范围[0,kX],Y轴坐标被归一化到范围[0,kY],从而消除了因签名大小不同和位置变化引起的干扰。
2.1.2 位置归一化
位置归一化使用坐标平移的方法完成,归一化后的签名将以原点作为签名的中心,其公式如下

(3)

(4)
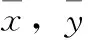
2.2 相似度计算
签名信息由{T,X,Y,P,VX,VY}信号组成。图3显示同一用户的不同签名样本的X轴信号对比。从图中可以看出,对于同一用户的真实签名来说,签名样本各个不同,但是其信号具有一定相似性,只不过由于书写快慢的缘故,造成序列在时间上扭曲的现象。而对于伪造签名来说,模仿者的模仿手法和水平决定了该签名信号与真实签名信号的差距一般会与真实签名的差距较大。因此,将计算签名之间相似度的问题转换为计算信号序列之间的相似度问题是可行的。

图3 真实签名和伪造签名X信号对比
本文使用动态时间规整算法计算信号序列之间的相似度。动态时间规整方法试图寻找两个序列的最佳匹配使得两个序列的距离最小,可以用来计算两个信号序列的相似度。算法的递推公式[7]如式(5),式(6)所示
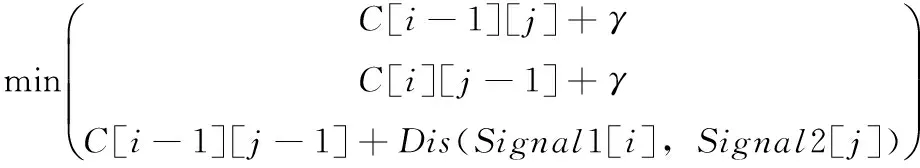
(5)

(6)
Signal1和Signal2表示两个信号序列,分别有N和M个采集点。Signal1[i]表示序列Signal1的第i个值,Signal2[j]表示序列Signal2的第j个值。C是一个矩阵,由该算法求得。C[i][j]表示由Signal1的前i个采集点组成的序列与Signal2的前j个采集点组成的序列的相似度得分,因此C[N][M]即为序列Signal1和Signal2的相似度得分。参数γ是个常量系数,用来惩罚在匹配过程中遇到的多余的点。函数Dis()表示两个点之间的差异值,函数中使用一个常量阈值θ,用于当两个信号正常匹配时,忽略或减少信号之间该处匹配时不明显的差异。
在后续的章节里,我们使用函数DTW(Signal1,Signal2)表示序列Signal1和序列Signal2之间的相似度,在上面的例子里,DTW(Signal1,Signal2)=C[N][M]。
2.3 选择模板签名
模板签名被认为是在参考签名集中最能代表该签名人签名特征的样本。假设签名S1和签名S2,其中,S1=(S1X,S1Y,S1P,S1VX,S1VY),S2=(S2X,S2Y,S2P,S2VX,S2VY)。L为信号数量,在这里L等于5。S1k,S2k分别表示签名S1和S2的第k个信号,DTW(S1k,S2k)代表签名S1和签名S2的第k个信号之间的相似度,那么签名S1和签名S2之间的相似度得分可以表示为
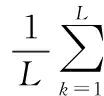
(7)
如此,每个参考签名都可以计算得出与其它参考签名的距离,与文献[7]类似,本文选取具有最小平均距离的签名为模板签名。
2.4 特征提取
在线签名认证中,用户会在认证之前输入几份真实签名,称为参考签名集。待测签名的特征可用该签名与参考签名之间的相似度信息来表示。因此,提取有效而准确的待测签名与参考签名相似度成为认证技术的关键。如图3所示,真实签名的相同信号之间的具有较强的相似性,而伪造签名与真实签名之间的差距较大。在书写的过程中,不同的信号序列之间具有一定的独立性,因此与其如文献[7]里将签名的不同信号特征进行融合,不如从信号的粒度提取特征,可以提取出更多有效的特征。
假设用户A的参考签名集为RS,已求得模板签名为TS,需要对签名S提取特征。以X信号为例,SX表示签名S的X信号,TSX表示模板签名的信号,RSi,X表示参考签名集中第i个签名的X信号。首先计算SX与TSX的距离得到X信号的模板距离tempDisX。然后计算SX与各参考签名的X信号RSi,X的距离的平均值得到avgDisX,最小值minDisX和中位值medDisX。这4个值作为X信号贡献的特征。以此类推,对所有的信号进行同样的操作,得到的结果组合成特征向量。
但是由于不同的签名样本笔画数量不同造成信号点的采集量不同,如果单纯使用DTW方法会造成笔画少的签名的距离得分比会比笔画多的签名距离得分要小,因此需要有一种归一化的方法去规避这个问题。为了解决这个问题,需要对参考签名使用相同的计算步骤,计算归一化基准值,其公式如下
(8)
(9)
(10)
(11)
在这里我们用函数count(RS)来计算参考签名的数量,在后面的算法中函数count()表示同样的意义。其中tempDisi,X,avgDisi,X,minDisi,X,medDisi,X分别表示参考签名RSi在X信号量上与模板签名的距离、与其它参考签名距离的平均值、最小值和中位值。对所有的信号进行同样的操作,得出的所有值组成基准值向量(BaseValues)。由于基准值的计算基于真实签名,因此如果待测签名S是真实签名,那么计算出的特征值应该接近于基准值;如果S是伪造签名,那么计算的特征值与基准值应该差异较大,因此归一化操作只需要将该原始特征值与对应的基准值求比值,即为最终的特征值。特征提取的过程见算法1。其中函数minimum(),mean(),median()的功能是求得所传入参数的最小值,平均值和中位值,函数top(V)代表向量V的长度属性。
算法1:签名S提取特征V
Input:签名S,模板签名TS,参考签名集RS,信号集SignalList,基准值BaseValues
Ouput:特征向量V
(1)functionExtract(S,TS,RS,SignalList,BaseValues)
(2)V←[]
(3)forsignalkinSignalListdo:
(4) Push(V,DTW(Sk,TSk))
(5)Distance←[]
(6)fori←0 tocount(RS)do
(7) Push(Distance,DTW(Sk,RS[i]k))
(8)endfor
(9) Push(V,minimum(Distance))
(10) Push(V,mean(Distance))
(11) Push(V,median(Distance))
(12)endfor
(13) Normalization(V,BaseValues)
(14)returnV
(15)endfunction
(16)functionPush(V,x)
(17)top(V)←top(V)+1
(18)V[top(V)]←x
(19)endfunction
(20)functionNormalization(V,BaseValues)
(21)fori←0 tocount(V)do
(22)V[i]←(V[i]/BaseValues[i])
(23)endfor
(24)endfunction
2.5 模型训练与测试
为了找到最佳分类模型,本文实验了3种分类器:PCA进行降维再使用阈值分类器、随机森林模型、神经网络模型。在训练阶段,系统对训练签名提取特征,完成原始签名信息到特征向量的转换。该特征向量与该签名的标签一起,作为分类器模型的输入,训练该模型。一旦模型训练完成,新用户注册时则不需要再对模型进行训练,因此该模型可以处理没有遇到过的新签名样本。在测试过程中,系统使用与训练阶段同样的步骤提取待测签名的特征向量,已训练好的分类器将根据其特征向量判定该签名是真实签名还是伪造签名。
3 实验与结果
3.1 数据集
签名数据一般可以分为真实签名、熟练伪造、随机伪造3种。真实签名是指签名者按照自己的真实想法,正确的意愿写下的签名信息,该签名信息不一定是自己的姓名,可以是任何文字。因此,即使知道该签名者身份,也不一定知道该签名的文字内容。熟练伪造是指伪造者知道该真实签名的字形和书写过程中的动态特性的情况下并经过练习来模仿真实签名。随机签名是指伪造者对真实签名的内容毫不知情而随意书写的其它签名。
本文提出的方法在SUSIG数据集和自采数据集上进行评价。SUSIG数据集包含熟练伪造的签名,这些签名是由签名者观察原签名是怎样书写之后并加以练习之后写出的。SUSIG数据集包含两部分:由内置LCD显示器并提供视觉反馈的Visual子数据集以及Blind子数据集。Visual子数据集包含由100个人提供的共计2000份真实签名和1000份伪造签名。然而,我们只获取到了其中的94人共计2820份签名样本数据。SUSIG数据集还提供10人的验证集进行训练,其中每人有10份真实签名样本和10份伪造签名样本。本文将使用Visual子数据集的Base Protocol[10]来进行评价。
在专用手写板上采集的签名和在移动设备上采集的签名是不同的,为了验证本文的方法在移动设备上的效果,我们使用Nexus 7,Android系统,采集了50人的签名样本。其中,每人25份真实签名样本和20份伪造签名样本,共计2250份样本。每个人的伪造签名样本均由不少于4个人进行伪造。当伪造者进行伪造时,我们提供伪造者真实签名样本的图像,并允许伪造者根据图像进行模仿。图4为真实签名和伪造签名的对比图。本数据集提供的信号包括时间戳、X轴坐标、Y轴坐标和压力值。

图4 真实签名、伪造签名对比
SUSIG数据集和自采集数据集的总结见表1。
至于参考签名集的选择,有两种方式。一些论文从真实签名里随机选取k个作为参考签名集,并运行多次来计算最终的结果。这种方式更好的规避真实签名的差别。另一些文献[5]选择采集最早的k个签名作为参考签名集。由于在线签名系统应用总是首先采集参考签名再采集待测签名。因此,本文选择第二种方式,也就是说,在真实签名集中,系统将选择签名的前5个签名作为参考签名集,剩下的真实签名用来计算误拒率。
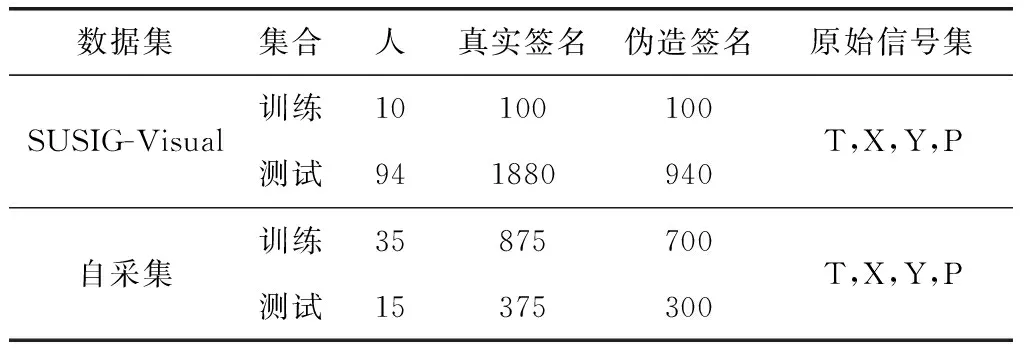
表1 SUSIG数据集和自采数据集总结
3.2 SUSIG数据集结果
图5显示了当选择不同的阈值时,误拒率和误纳率对应变化的曲线。其中,使用PCA模型将提取出的特征降成一维后,选取不同的阈值可以得到不同的误纳率和误拒率,取得的EER为2.48%,比文献[10]降低了25%,说明与其将信号进行融合,从信号的粒度可以保留更多有效的特征,效果也更好。另外,如果采用随机森林模型作为分类器的话,可以将等误率进一步降低到2.26%。从图5中,也可以看出PCA的错误率曲线比随机森林较为平稳,然而随机森林模型的EER结果更佳,这是由于模型本身的特性决定的。而神经网路的分类效果则比较差,在各参数都默认的情况下,取得了9.3%的EER。

图5 错误率曲线
表2列出了使用SUSIG 数据集的不同方法的结果比较。从中可以看出,一般基于函数的方法效果要优于基于特征的方法。在EER这个指标下,而本文比文献[10]效果最终提升了31%。
另外,我们还分别对各个信号的认证表现进行了研究,表3中列出了不同信号的EER,其中可以发现信号X,Y的EER比较高,说明X,Y信号在使用本算法时的效果并不好,因此X,Y并没有出现在我们最好的结果的信号集里。SUSIG数据集中的伪造签名均为熟练伪造,在签名采集时提供伪造者真实签名的图像,并允许练习和反馈,因此伪造签名样本在形状上与真实签名差距不大。然而,对于动态信息,如签名时间、签名速度,伪造者则很难模仿,因此这个结果也就不难以理解了。从这里我们可以得出结论,对于熟练伪造的签名样本来说,动态信息要比静态信息重要的多。在我们的实验中{VX,VY,P}的信号组合取得了最佳的效果。

表2 不同方法SUSIG数据集结果比较

表3 不同信号结果对比
3.3 自采数据集结果
为了验证本算法是否适用于Android设备上的手写签名,我们使用上述自采数据集进行实验。其过程与SUSIG数据集上的过程一样。其中,最佳结果中FRR为3.7%,FAR为5.5%。说明了本算法在Android设备上采集的签名也是有效的。不过与SUSIG数据集上不同的是,取得最佳效果的信号集不同。如表4中列出的结果,不同的信号集合取得了不同的效果,其中取得最佳效果的信号集组合包括了X和Y信号。这是由于我们收集的伪造签名,均由实验室的同学老师们模仿的,对一些比较难模仿的签名,普通模仿者很难在字形上与真实签名模仿的很相像,因此对于签名的坐标信息对于认证效果也有帮助。

表4 自采数据集采用不同信号集合结果比较
4 基于在线签名的Android系统解锁应用
目前Android系统的解锁功能,大多数使用传统的基于口令的方式,这种方式的缺点比较明显。如果攻击者看见了用户输入的口令,并且通过某种方式窃取到了用户的手机,那么攻击者很容易获取到手机里的信息。除此之外,一些高端手机机型集成了指纹识别的功能,通过指纹对个人身份进行验证,对屏幕进行解锁。这种解锁方式的优点是对攻击者有较强的防御功能,其缺点是提高了手机的成本。
为了解决上述问题,我们将本文提出的算法集成到Android系统上,实现了基于在线签名的Android系统解锁功能。利用自采数据集,我们将离线训练好的随机森林模型进行持久化操作,并将持久化后的文件打包进Android在线签名认证应用中。当用户选择使用手写签名进行解锁后,应用程序要求用户输入5份真实签名作为参考签名集。此时,应用程序首先会对参考签名集进行处理,然后对持久化后的模型进行反序列化,加载到内存中,最后开启手写签名解锁功能。这几步操作之后,当用户尝试进入Android系统,系统会要求用户输入一份签名样本,输入完毕后,系统会调用认证模块对该签名进行认证。如果认证成功,则进入系统,否则不能进入系统。为了使得系统重启后,在线签名解锁功能仍然正常工作,我们使用SQLite数据库存储用户输入的参考签名集。系统重启后,应用将自动从数据库中读取参考签名集信息,并且加载到内存中,用于认证使用。
由于Android系统解锁应用使用的签名数据与自采数据集中的数据均由智能手机采集,因此签名样本属于同一类型,因此在认证准确率上与自采数据集基本一致。我们仅使用真实签名来验证解锁效果,利用解锁速度、真实签名准确率两个指标对应用进行评价。我们选用了与签名采集设备Nexus 7不同的小米4手机作为测试机。小米4手机具有5英寸的屏幕,符合当前主流手机的屏幕大小。其搭载四核2.5 GHZ骁龙801处理器,内置3 GB内存,其内置基于Android6.0.1优化的MIUI8.1稳定版系统。如表5 所示,我们收集了8个人共68份真实签名样本,在平均采集点数172个、签名时间4.8 s的情况下,平均认证时间为0.77 s,认证速度令人满意。另外其准确率为97.1%,与在Nexus 7上采集的数据实现效果基本一致,说明本算法训练好的模型可以满足不同机型的要求。

表5 真实签名解锁结果
在实际使用时,基于在线签名的解锁应用可作为补充功能。安装了本应用后,用户可自由选择使用本解锁方式或其它系统支持的解锁方式,只需要在系统设置处进行选择,因此具有较强的易用性。手写签名是长期养成的行为习惯,一般不容易忘记,因此并没有对多次认证失败进行特殊处理。在进行实验验证的时候我们发现,具有独特性的签名一般不容易伪造,而规规矩矩的签名则容易被模仿,因此基于在线签名的Android系统解锁应用比较适合写字具有特点的用户。
5 结束语
我们提出了一种基于在线签名信号序列的特征提取方法,从信号的粒度,提取多维度特征,组成特征向量,用于身份认证。该方法使用动态时间规整算法计算不同签名的相同信号序列之间的相似度。在认证之前,用户输入若干份真实签名样本作为参考签名,系统将该参考签名集进行持久化存储,并根据参考签名集计算特征向量基准值。在认证阶段,用户需要输入一份签名样本,系统对该签名样本提取特征,之后利用基准值进行归一化,得到最终的特征向量。经过实验验证,随机森林模型的认证效果最佳。我们在SUSIG数据库上对该算法进行测试,取得了2.26%的EER,比与本方法类似的论文提高了31%,充分说明了新的特征提取方式的有效性以及随机森林分类器的优越性。另外,为了验证本算法是否适用于Android系统上采集的签名样本,我们使用Nexus 7采集了50个人共2250份签名样本,并在自采数据集上进行了测试,取得了3.7%的FRR和5.5%的FAR。本方法已经成功应用于Android系统的解锁功能上,其解锁速度令人满意。
[1]Alsulaiman F A,Sakr N,Saddik AE,et al.Identity verification based on handwritten signatures with haptic information using genetic programming[J].ACM Transactions on Multimedia Computing Communications Applications,2013,9(2):533-538.
[2]WANG Rongxia.On-line handwriting signature verification based on SVM[D].Wuhan:Wuhan University of Technology,2013(in Chinese).[王容霞.基于SVM的在线手写签名认证研究[D].武汉:武汉理工大学,2013.]
[3]Rashidi S,Fallah A,Towhidkhah F.Feature extraction based DCT on dynamic signature verification[J].Scientia Iranica,2012,19(6):1810-1819.
[4]Fayyaz M,Saffar M H,Sabokrou M,et al.Online signature verification based on feature representation[C]//International Symposium on Artificial Intelligence and Signal Processing,2015:211-216.
[5]Sae-Bae N,Memon N.Online signature verification on mobile devices[J].IEEE Transactions on Information Forensics & Security,2014,9(6):933-947.
[6]Liu Yishu,Yang Zhihua,Yang Lihua.Online signature verification based on DCT and sparse representation[J].IEEE Transactions on Cybernetics,2015,45(11):2498-2511.
[7]Kholmatov Alisher,Berrin Yanikoglu.Identity authentication using improved online signature verification method[J].Pattern Recognition letters,2005,26(15):2400-2408.
[8]Gruber C,Gruter T,Krinninger S,et al.Online signature verification with support vector machines based on LCSS kernel functions[J].IEEE Transactions on Systems,Man,and Cybernetics,Part B:Cybernetics,2010,40(4):1088-1100.
[9]QIU Yiming,HU Huacheng,ZHENG Jianbin,et al.On-line handwriting signature verification based on curve similarity[J].System Engineering and Electronics,2014,36(5):1016-1020(in Chinese).[邱益鸣,胡华成,郑建彬,等.基于曲线相似的在线签名认证方法[J].系统工程与电子技术,2014,36(5):1016-1020.]
[10]Kholmatov,Alisher,Berrin Yanikoglu.SUSIG:An on-line signature database,associated protocols and benchmark results[J].Pattern Analysis and Applications,2009,12(3):227-236.
猜你喜欢
建材发展导向(2022年23期)2022-12-22
九江职业技术学院学报(2022年1期)2022-12-02
建材发展导向(2022年12期)2022-08-19
保定学院学报(2022年2期)2022-04-07
中学生数理化·高一版(2021年2期)2021-03-19
知识经济·中国直销(2018年8期)2018-08-23
许昌学院学报(2018年4期)2018-05-02
中华建设(2017年1期)2017-06-07
数学学习与研究(2017年3期)2017-03-09
中国老区建设(2016年1期)2016-02-28
