
基于全卷积深度学习模型的可抓取物品识别
2018-03-15 01:25皮思远肖南峰
重庆理工大学学报(自然科学) 2018年2期
皮思远,唐 洪,肖南峰
(华南理工大学 计算机科学与工程学院, 广州 510006)
随着工业4.0的发展,越来越多的工业机器人(包含末端执行器)正在替代工人进行各类生产作业,并且有效降低了生产成本[1]。目前的工业机器人大多是通过示教编程来完成一些特定的生产任务,但在实际应用中,通常需要工业机器人完成抓、握、捏、夹、推、拉、插、按、剪、切、敲、打、撕、贴、牵、拽、磨、削、刨、搓等20种生产操作。对于这些生产操作,现在通用的示教编程方法是令工业机器人在固定的轨迹空间中作业,通过工业机器人及其作业目标对象之间在时间上操作配合来完成上述生产操作。故现行的示教编程方法只适用于那些环境不确定性较低的作业任务。
工业机器人在上述20种实际应用中,核心问题是识别作业目标对象。比如,工业机器人抓取操作过程包括抓取检测、轨迹规划、抓取执行3个部分[2]。抓取检测是识别作业场景中的物品或物品上的某些可抓取区域,而传统的应用通过确保物品出现在预设位置或通过简单的基于预设特征的视觉系统解决该问题。轨迹规划即给出工业机器人从当前位置运动到目标位置的无障碍轨迹点。抓取执行是通过开环或闭环控制工业机器人执行轨迹规划结果运动到目标位置。抓取检测的本质是要对目标物品进行识别和定位,目前的主流方法是通过图像传感器或深度传感器采集场景信息,利用特征算子如HOG、SIFT或粒子滤波[3-6],结合提取的不同特征与不同分类器算法等进行目标物品识别或目标分类,例如支持向量机[2]、条件随机场和人工神经网络等分类器算法[7]。这些算法通过提取过分割区域获得特征向量并综合区域内部的局部联系给出分类结果。但同一分割区域存在不同类像素的干扰影响,且未完全考虑全局结构信息,因此很有必要利用全局信息来综合考虑改善传统方法。
目前,深度学习方法是机器学习中最重要的分支,表示为深度结构及复杂的多层次学习算法。研究和实践表明:深度学习算法凭借多层结构能够分布式学习样本数据中的特征,在隐含层节点之间通过连接提取特征[8]。在某些关键任务如图像识别、自然语言处理中获得倍数关系于传统机器学习算法的表现[9]。2012年Alex教授在ImageNet大规模视觉识别比赛(ILSVRC)中提出的AlexNet卷积深度学习模型在Top-5(最高5类概率)错误率表现为15.3%,将图像分类水平提升到了一个新高度[10]。而其后的VGG、Inception、ResNet深度学习模型取得了90%以上的准确率,甚至超出人类专家的分类水平[11-13]。其中,基于VGG泛化出许多其他的结构,如R-CNN、Faster-RCNN等用于目标检测[14-15]。Yolo[16]深度学习模型通过其网络结构直接检测物品,去掉了中间处理过程,大大加快了目标检测速度。深度学习方法中的卷积深度学习模型对分类问题可以取得优秀的效果,但并不适合像素级的识别分割任务,因为最后全连接层的输出维度固定会导致前端卷积层输入纬度固定,输入维度也被固定导致其不适合输入图片尺度变化。
在光学图像语义分割问题中,有关学者提出了以全卷积深度学习(fully convolutional network,FCN)为代表的一类像素级识别分类学习模型,Long等[17]将其应用于图像语义分割任务。全卷积神经网络模型不同于以往的深度学习模型,它将后端全连接层去除,利用卷积神经网络获取的特征进行反卷积与反池化操作,以恢复出物品在像素级别的检测结果。因为卷积操作并不限定输入图像的尺寸大小,从而消除了网络输出大小的限制,使得网络够适应各种大小尺寸的图像,不需要对图像进行尺寸规范处理,并避免了使用像素块需要重复存储和计算卷积的问题。由于全卷积神经网络输出尺寸可与输入尺寸相同,因此适合于像素级的机器学习任务,如语义分割、图像降噪等。
在上述基础上,本文提出了一种改进型的基于全卷积深度学习模型的可抓取物品识别的机器学习算法,可在像素级层面上识别可抓取物品,分割可抓取物品与背景元素。相对于全卷积神经网络,改进的方法提升了算法的识别准确性。可抓取物品识别与语义分割任务的区别在于语义分割需区别场景中各种物品,对其进行分类与确定位置,而可抓取物品识别只聚焦在工业机器人需要操作的目标对象在机器人视野中的位置,以配合工业机器人进行的后续操作。改进的算法不仅可用于可抓取物体识别,也可用于其他相关前景分割、物体定位问题。
1 全卷积深度学习模型
1.1 卷积深度学习模型
卷积深度学习模型是深度学习模型中效果突出的一类学习模型,卷积神经网络学习模型通过将网络层之间的全连接替换为卷积进行操作。例如,二维图像卷积运算可表示为
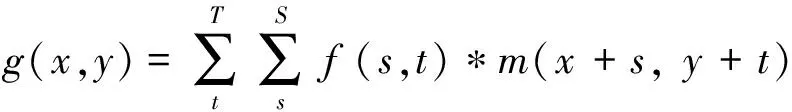
(1)
式中:g表示二维卷积运算某一点的结果;f表示卷积核函数;m表示二维矩阵中以(x,y)左上角顶点的长S、宽T的区域。假设卷积神经网络中某一层以k通道的图像zi作为输入,输出为zi+1,该层共c个卷积核,用⨁表示二维矩阵与卷积核的运算,则卷积层运算可表示为
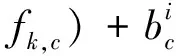
(2)
式(1)和式(2)表明实际卷积层通过卷积运算实现了权值共用,从而减少了大量中间权值参数的数量。并且卷积神经网络通过在卷积运算后进行接池化操作(pooling)进一步地实现特征提取,即把二维卷积运算后提取的特征划分到大小为m×n的不相交区域,然后对这些区域某一统计特征采样,如平均值、最大值来获取池化后的卷积特征。池化操作可以进一步降低网络参数量,避免陷入过拟合状况。卷积网络结构如图1所示,一般经过多层卷积层提取特征后,后端通过全连接层将卷积结果输出为预测向量。
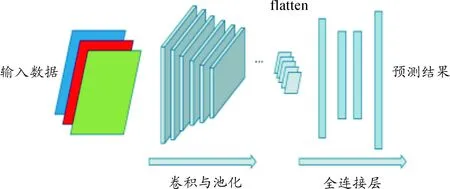
图1 卷积深度神经网络结构
1.2 全卷积深度学习模型
卷积操作可看作提取输入不同的特征图[18],而Zeiler等研究中提出的反卷积概念则与卷积层操作目的相反,其通过卷积运算从卷积提取的特征图中重构原始图像,如式(3)所示。
⨁fk,c
(3)
式(3)表明:反卷积可从将提取的k个特征图z恢复原始图像,通过学习过程调整卷积核参数。 Long等在研究中提出的全卷积深度学习模型去除VGG-16卷积神经网络模型中最后的全连接层,将其通过反卷积操作(deconvtion)将VGG-16网络的中间卷积层输出的特征图像恢复为二维语义分割图像[17]。Long的研究实验中还利用了VGG-16的中间卷积层结果分别给出了3种模型FCN-8x、FCN-16x、FCN- 32x,在pascal voc上超出了传统的方法。全卷积模型结构如图2所示。
本文针对全卷积深度学习模型的识别准确率进行改进,基于VGG16构建了13层全卷积深度学习模型,这13层网络结构的各层如表1所示,其中每层包含若干次卷积操作,具体网络结构模型如图3所示。经过5层卷积层,每层卷积层后接池化层,再接2层卷积层,继而经过5层反卷积层与反池化层输出物品识别结果图像。由表1可知:前6层卷积层与后6层反卷积层操作一一对应,第7层为中间过渡层,衔接卷积层与反卷积层,其中:convk-y,k表示卷积核大小为k×k;y表示使用的卷积核个数。
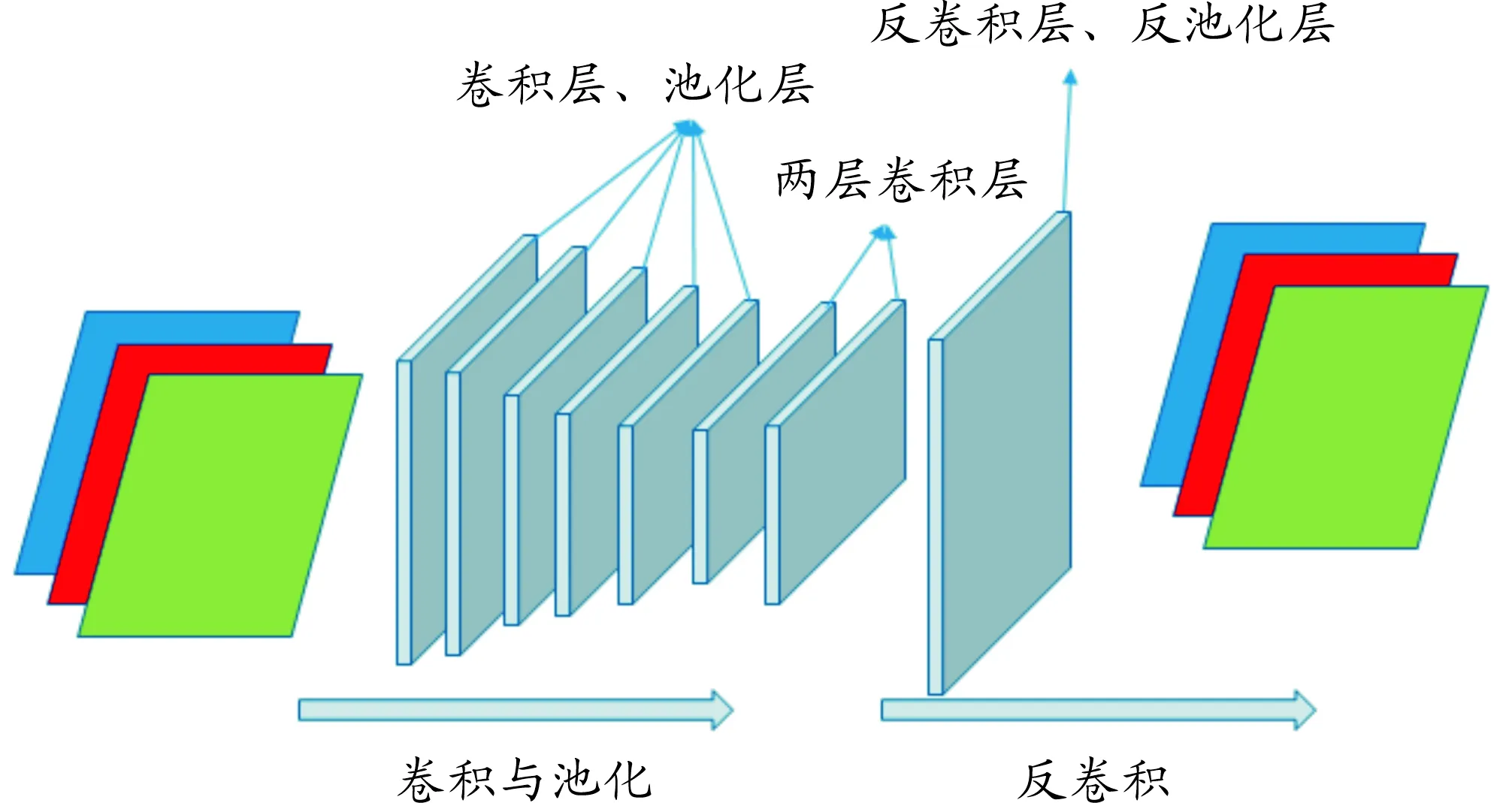
图2 一般全卷积深度神经网络结构

图3 13层全卷积深度神经网络结构

表1 全卷积深度学习模型结构配置
2 深度学习模型训练方法
由于深度学习模型随着层数加深使得模型变得难以训练,所以Hinton教授等[7,19]于1988年提出反向传播算法训练神经网络。但由于实际问题多是非凸性优化问题,随着网络层数加深容易陷入局部最优情况或出现过拟合情况,但基于动量的训练算法能够缓解这一情况[20]。为此,本研究中应用的反池化操作将对应最大池化采样结果复原到原矩阵对应位置,并对余下位置进行线性插值填充。传统的多层神经网络由于采用Sigmoid函数而导致反向传播时梯度发生弥散。Sigmoid激活函数及其导数表示为式(4)和式(5),式(6)为深度学习模型中权值更新方式。
(4)
f′(x)=f(x)(1-f(x))
(5)
wt=wt-ηL(Zn,wt)
(6)
式(6)中:L′(Z,wt)表示误差函数对wt求导;wt表示第t层深度学习模型的权值;Z为深度学习模型每一层输出;Zn为深度学习模型最终输出。根据反向传播方程链式法则,结合式(3),误差函数L对中间层权值求导表示为式(7)和式(8)。
L′(Z,wt)=L′(zn,zn-1)f′(zn-1,wt)
(7)
f′(zn-1,wt)=f′(zn-2)(1-f′(zn-2)wn-1…f′(zt-1,wt)
(8)
当Sigmoid激活函数在趋近0或1时,梯度趋向于0,导致多层神经网络前段神经单元得不到反馈激励,即导致梯度弥散现象。限制性线性单元(rectified linear units,Relu)[21]是一种新的激活函数,表示为
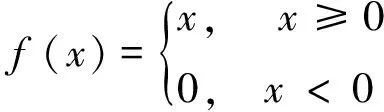
(9)
Relu激活函数的梯度恒定(0或1),当x=0,定义其梯度为0,这一特性使其避免深度学习模型反向多层传播导致梯度发生弥散现象,能使深度学习模型更快收敛,且Relu函数的一端为0,可以得到单侧抑制,这与生物学神经元研究符合,并能使传递数据变得稀疏。
本研究提出的全卷积深度学习模型使用Relu函数作为网络层中的激活函数。另在本文第3节的实验中使用滑动平均权值更新方式,权值更新方式为
wt=awt+(1-α)(wt-ηL′(zn,wt))
(10)
与普通的权值更新方式相比,通过增加超参数α能够控制权值变化速度,提高模型健壮性。并且通过对网络输出结果进行聚类分析,以最多分类像素点代表的物体表示前景物体,可得到最终识别结果。
3 试验结果及分析
3.1 实验数据与步骤
本文实验所使用的测试数据为康奈尔抓取数据集(cornell grasping dataset,CGD),该数据集包含了281种生活中常见的物品,例如杯子、剃须刀、剪刀等,如图4所示。数据集总共为1 034张图像,每张图像大小为640像素×480像素。由于原始图像不包含物品标注信息。故需要对数据进行预处理,数据集中提供背景图像信息。直接去除背景会导致存有阴影,因此需要手动对图像进行精细处理,将图片变换为以某一颜色指代物品与黑色指代背景的分割图像,数据集处理流程如图5所示,其中图像与背景相减结果对应图6(a);去除孤立像素,并手动去除阴影区域的结果对应图6(b);分配图像中物品特定颜色结果对应图6(c)。数据预处理后,利用数据增强方法,以图像为中心顺时针旋转5°,15°与-5°,-15°增加4倍数据,并通过以图片中心截取边界20像素与40像素,最后将样本增大至8 272份样例。

图4 康奈尔抓取数据集中的样例
本文研究的实验基于Tensorflow框架,采用Linux系统作为运行平台,在配置为intel I7 CPU,Nvidia Gtx1080 GPU,32 G内存的硬件平台上进行试验。预先使用Imagenet数据集对以前7层卷积层与3层全连接层组成的卷积神经网络进行预训练,学习大量物品的真实特征。之后将网络后端的全连接层改为本模型中的5层反卷积层,以及本实验提出的改进型全卷积深度学习模型,在康奈尔抓取数据集进行参数调整(fine-tuning)。
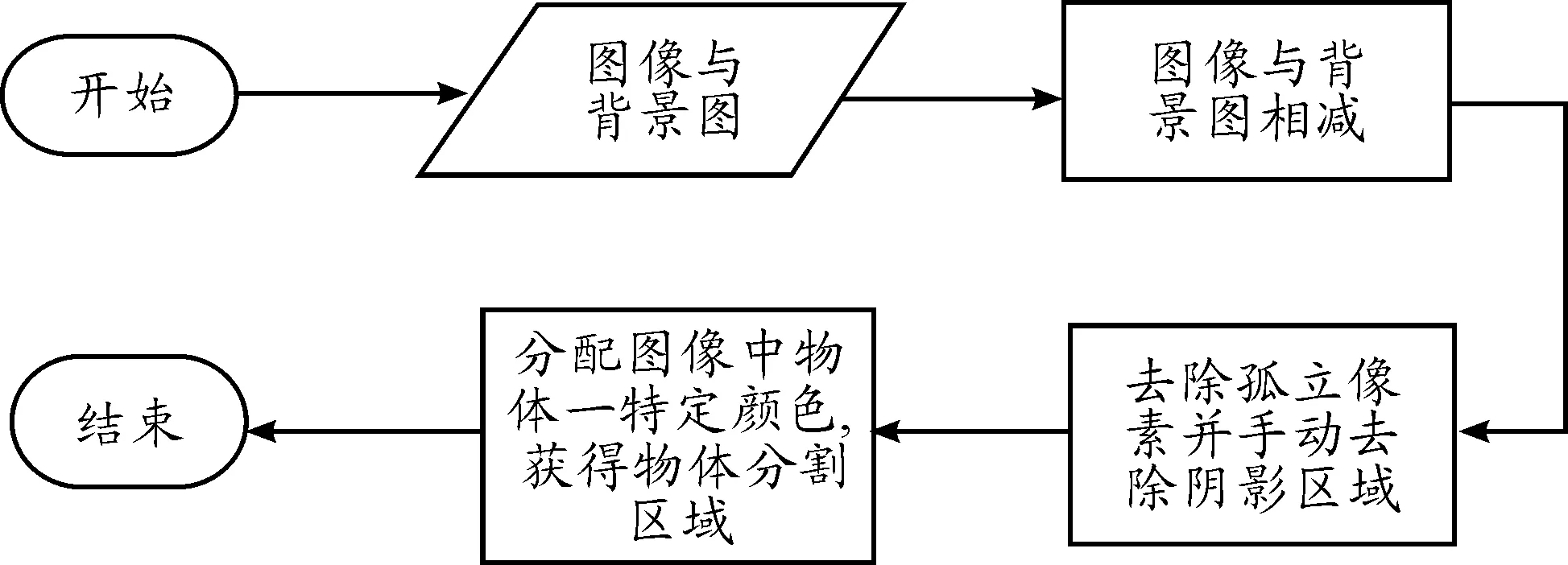
图5 数据集处理流程

图6 物品分割处理结果
3.2 结果分析
首先进行FCN-8x、FCN-16x、FCN-32x在预处理后的数据集上实验。针对3种全卷积深度学习模型分别训练选择最佳的结果,与本文提出的全卷积物品识别深度学习模型算法进行对比实验,结果如表2所示。本文研究利用的评判标准为像素分类的准确率,表示为
(11)
式中:ti表示为i类像素总数量;ni表示为分类为i类的i类像素数量。最终各模型的预测像素类别准确率如表3所示。由于每个测试用例包含单一的物体,因此前景准确率、背景准确率的计算方法都为式(11),而总准确率表示为
(12)
式中:f表示前景物物品像素;b表示背景像素。实验结果表明:相对于FCN-8X只利用一次反卷积层,增加反池化层与反卷积层能够使物品识别的准确率进一步提升,由于背景像素占图片比例较大,可以看出背景区域的错误率较低,而由于物品形状各异,识别属于物品的像素比较困难。由表3所示的实验结果可知:本文提出的模型相对FCN-8x的整体效果由71.2%上升到77.4%,提升了6.2%,且实验结果也表明局部区域更加贴合数据样本。
表2 模型预测结果
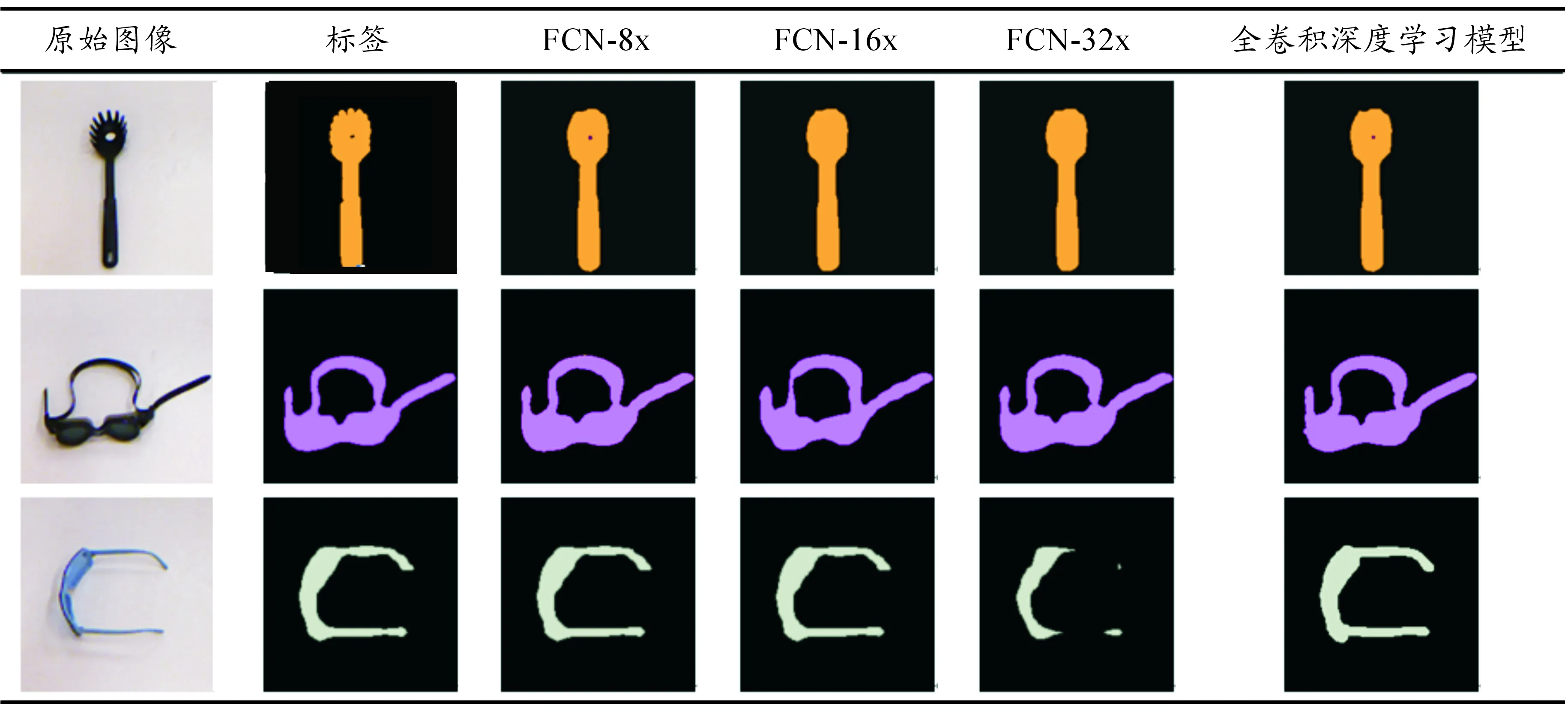
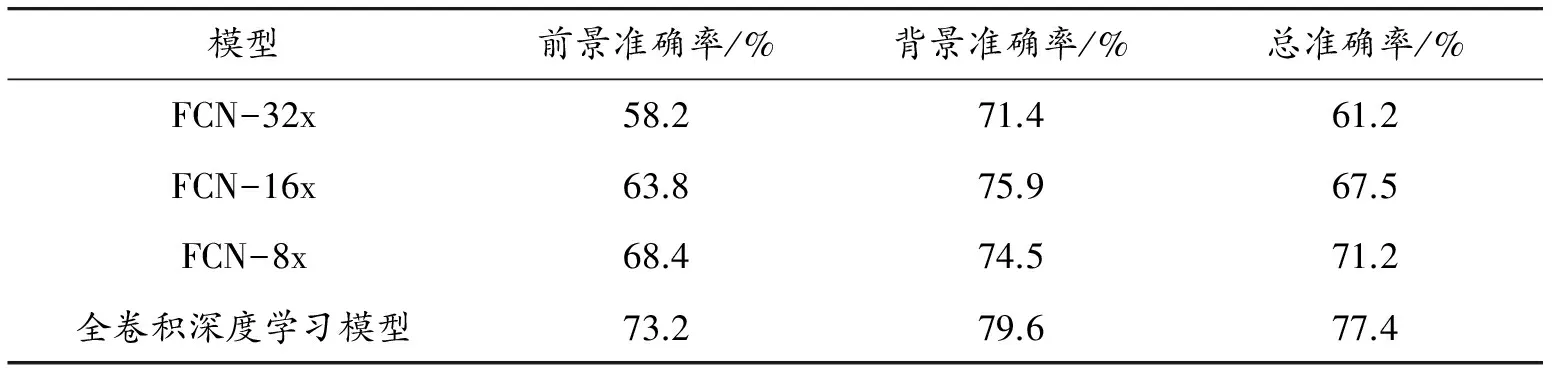
表3 模型准确率表现
4 结束语
本文引入和改进了全卷积深度学习模型用于解决可抓取物品的识别问题,对于已有的FCN-8x、FCN-16x、FCN32x进行试验,并考虑其不足,提出了改进的全卷积深度学习模型用于可抓取物品识别,应用插值方式进行反池化操作,可以有效地改进像素级的物品识别准确率,将分类结果提升了3.8%,图像细节信息得到改善。此方法不仅适用于可抓取物品识别领域,而且还可应用于其他像素级物品检测问题。本文的后续工作将在不断提高识别准确率的基础上进一步提高时间效率。
[1] 王田苗,陶永.我国工业机器人技术现状与产业化发展战略[J].机械工程学报,2014,50(9):1-13.
[2] SAXENA A,DRIEMEYER J,KEARNSs J,et al.Learning to grasp novel objects using vision[M]//Experimental Robotics.[S.l.]:Springer Berlin Heidelberg,2008:33-42.
[3] 战强,吴佳.未知环境下移动机器人单目视觉导航算法[J].北京航空航天大学学报,2008,34(6):613-617.
[4] 张雪华,刘华平,孙富春,等.采用 Kinect 的移动机器人目标跟踪[J].智能系统学报,2014,(1):34-39.
[5] 王修岩,程婷婷.基于单目视觉的工业机器人目标识别技术研究[J].机械设计与制造,2011,(4):155-157.
[6] 胡仕玲,顾爽,陈启军.基于HOG的物品分类方法[C]//中国智能机器人学术研讨会论文集.深圳:北京大学深圳研究生院,2011.
[7] ROSENBLATT F.The perceptron,a perceiving and recognizing automaton project para[M].New York:Cornell Aeronautical Laboratory,1957.
[8] BENGIO Y.Learning deep architectures for ai.foundations and trends R in machine learning [J].Cited on,2009,2(1):1-127.
[9] LECUN Y,BENGIO Y,HINTON G.Deep learning[J].Nature,2015,521(7553):436-444.
[10] KRIZHEVSKY A,SUTSKEVER I,HINTON G E.ImageNet classification with deep convolutional neural networks[C]//International Conference on Neural Information Processing Systems.USA:[s.n.],2012:1097-1105.
[11] SIMONYAN K,ZISSERMAN A.Very Deep Convolutional Networks for Large-Scale Image Recognition[J].Computer Science,2014(4):1409-1556.
[12] SZEGEDY C,LIU W,JIA Y,et al.Going deeper with convolutions[C]//Computer Vision and Pattern Recognition.[S.l.]:IEEE,2015:1-9.
[13] He K,Zhang X,Ren S,et al.Deep residual learning for image recognition[C]//Proceedings of the IEEE conference on computer vision and pattern recognition.[S.l.]:IEEE,2016:770-778.
[14] GIRSHICK R,DONAHUE J,DARRELL T,et al.Rich feature hierarchies for accurate object detection and semantic segmentation[C]//Proceedings of the IEEE conference on computer vision and pattern recognition.USA:IEEE,2014:580-587.
[15] REN S,HE K,GIRSHICK R,et al.Faster R-CNN:Towards real-time object detection with region proposal networks[J].IEEE Transactions on Pattern Analysis & Machine Intelligence,2017,39(6):1137-1149.
[16] REDMON J,FARHADI A.YOLO9000:better,faster,stronger[Z].2016.
[17] LONG J,SHELHAMER E,DARRELL T.Fully convolutional networks for semantic segmentation [J].IEEE Transactions on Pattern Analysis & Machine Intelligence,2017,39(4):640-651.
[18] LECUN Y,BOTTOU L,BENGIO Y,et al.Gradient-based learning applied to document recognition[J].Proceedings of the IEEE,1998,86(11):2278-2324.
[19] RUMELHART D E,HINTON G E,WILLIAMS R J.Learning internal representations by error propagation[J].Readings in Cognitive Science,1988,1:399-421.
[20] SUTSKEVER I,MARTENS J,DAHL G,et al.On the importance of initialization and momentum in deep learning[C]//International Conference on International Conference on Machine Learning.2013:1139-1147.
[21] GLOROT X,BORDES A,BENGIO Y.Deep sparse rectifier neural networks[C]//Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics.USA:[s.n.],2011:315-323.
猜你喜欢
小学生学习指导(低年级)(2022年5期)2022-05-31
小哥白尼(军事科学)(2022年2期)2022-05-25
北京航空航天大学学报(2021年9期)2021-11-02
疯狂英语·初中天地(2021年11期)2021-02-16
电子制作(2019年13期)2020-01-14
红领巾·萌芽(2019年8期)2019-08-27
电子制作(2019年11期)2019-07-04
少年漫画(艺术创想)(2019年2期)2019-06-06
北京航空航天大学学报(2018年1期)2018-04-20
中国与非洲(法文版)(2017年10期)2017-11-23
