
中文电子病历文本中的时间识别算法研究
2018-03-10 07:54:38孙健高大启刘珉高炬阮彤
山西大学学报(自然科学版) 2018年1期
孙健,高大启,刘珉,高炬,阮彤*
(1.华东理工大学 信息科学与工程学院,上海 200237;2.上海曙光医院,上海 200021)
0 引言
近年来,随着医疗信息化的不断推进,电子病历系统也随之出现[1]。电子病历(Electronic Medical Record,简称EMR)详实地记录了患者从入院到出院期间所有的诊断和治疗信息,具有供用户访问完整准确的数据和帮助医生临床诊断的能力。电子病历中包含大量实体,包括症状、疾病、检查、手术和用药等。其中,时间实体是描述患者信息的一个重要维度[2],反映了患者的病情发展情况,如“患者因2009年7月起无明显诱因下出现反复胃痛后于2010.3.8 15:00入院”、“患者因十二指肠癌术后6年零3月有余于2012-04-03 10:00:00由门诊拟十二指肠癌术后入院”等等。电子病历文本的用语较为自由,时间的表达也有多种形式,例如上述的2010.3.8 15:00可用以下形式表示:2010-3-8 15:00:00,2010/3/8下午3点,2010年3月8日15时等。另外,电子病历文本中时间识别存在这样的难题:由于基于事件的时间短语太长而不能准确定位其边界。基于事件的时间是指由表示事件的名词、动词,后面可跟介词或方位词,并且可有时间信息组合表示的时间短语,例如上述例子中的“十二指肠癌术后6年零3月有余”等。由于这类时间短语太长,在识别过程中无法将基于事件的时间中的事件完整无误地识别出来导致边界错误,且因短语表现形式灵活多变而无明显的语言学特征可利用,所以识别时存在较大障碍。
早在2007年,SemEval就已经将时间识别作为一个任务纳入评测[3]。在最近有关英文病历文本的时间表达式识别研究中,Clinical TempEval 2016对来自癌症患者的600份临床笔记和病理文本进行时间识别、医疗事件识别以及时间关系识别[4]。而关于中文电子病历文本中时间识别的研究比较稀少,学界较多关注于新闻报道中的时间识别[5-6]。
本文将电子病历文本中的时间分为两类:独立时间和基于事件的时间,并针对这两类时间分别提出了基于bootstrapping的识别算法和基于条件随机场(Conditional Radom Field,简称CRF)的识别算法。本文的贡献点如下:(1)基于bootstrapping算法识别独立时间,解决了正则表达式识别时间会覆盖不全的问题;(2)识别基于事件的时间时,引入中文症状知识库,很好地解决了基于事件的时间短语太长而不能准确定位其边界的问题。
时间信息能标识事件发生的时序性,故而时间识别是自然语言处理中的一个研究重点。时间表达式识别的常用方式有两种:一种是基于统计机器学习的方法;另一种是基于规则的方法,通过定义规则模板来实现时间抽取。由于时间表达式的结构通常较为规范,故近年来多采用基于规则的方法来抽取时间信息。
朱莎莎等[7]采用统计机器学习的方法识别时间短语,将时间短语分为日期型和事件型两种类型,提出基于条件随机场的时间短语识别方法。他们以词为基本处理单元生成一系列特征向量,然而如果前期分词有误的话(一般这种情况很难避免),就会导致错误的层层传导与放大,而难以保证识别的准确性。吴琼等[8]采用条件随机场识别时间单元而非时间表达式整体,提高了结果的准确性;制定规则确定时间表达式的边界补充时间单元,提高了结果的召回率。Strötgen等[9]提出了一个基于规则的时间标注系统HeidelTime,它的目标是将英文文档中的时间表达式抽取出来,并对该表达式分配正确的类型和标准化后的值。Hao等[10]利用启发式规则和模板学习来抽取英文电子病历中的时间表达式。他们观察时间表达的特征生成规则识别时间,然后,挖掘所有出现时间的模板并计算每个模板的置信度,以高置信度的模板来抽取新的时间表达式。Xu等[11]基于正则表达式识别中文电子病历中的日期型时间。然而,电子病历文本的用语较为自由,定义的规则很难覆盖到所有的时间信息。除了朱莎莎等[7]考虑了基于事件的时间表达,其他人都没有考虑基于事件的时间表达。而在电子病历文本中,基于事件的时间在临床时间推理中具有重要意义。
1 中文电子病历中时间表达类别
本研究通过对1 500份上海中医药大学附属曙光医院的电子病历进行分析,将文本中的时间表达分为两类:独立时间和基于事件的时间。
独立时间可分为简单时间和复合时间。基于TIMEX2标注规范[12],本文将简单时间又分为精确时间表达和模糊时间表达,如表1所示。其中,精确时间表达是指时间表达具有精确的时间点或时间段,模糊时间表达是指时间表达包含模糊修饰词且无法推算出精确的时间点或时间段。由于文本中时间信息的描述具有灵活性,几类简单时间可以进行组合构成复合时间表达,如“2015年8月18日下午5点”。

表1 简单时间表达类别
基于事件的时间是指由表示事件的名词、动词,后面可跟介词或方位词,并且可有时间信息组合表示的时间短语。在电子病历文本中,基于事件的时间是指以临床事件如入院、住院、出院、化疗、症状、疾病、手术等作为参考时间,如“入院第三天”、“肠癌术后第6年”等。
本文针对独立时间和基于事件的时间分别提出了基于bootstrapping的识别算法和基于条件随机场的识别算法。图1表示了本文方法的整个过程。

Fig.1 The overall workflow图1 总体流程图
2 独立时间表达的识别
如第1节所述,独立时间可分为简单时间和复合时间。观察电子病历文本发现,简单时间的格式具有一定的规律性;复合时间由两个或两个以上简单时间直接组合或通过空格、逗号进行组合。利用正则表达式识别独立时间时,如果医生书写不规范,例如出现多个空格、逗号或其他符号将导致正则表达式无法识别;或者,规则制定不全导致无法覆盖全部的时间。故而本文结合了正则表达式和bootstrapping算法识别电子病历文本中的独立时间。
2.1 基于正则表达式的种子抽取
首先为独立时间的识别去抽取种子。由于简单时间的格式具有规律性,通过观察简单时间的特征总结一系列规则构建正则表达式。表2给出了部分类型的简单时间的正则表达式。另外,收集了修饰模糊时间表达的模糊修饰词“近”、“前”、“后”、“约”等,共21个。电子病历文本中的复合时间由多个简单时间直接连接或通过空格、逗号进行连接,所以利用正则表达式对简单时间进行识别后,通过相邻原则进行复合时间的识别。本文将识别出的简单时间和复合时间作为种子。
2.2 基于bootstrapping算法的独立时间识别
为了学习模板来抽取独立时间,需要对电子病历文本中的时间进行标注。利用基于正则表达式抽取出的种子自动对文本进行标注,这种方法大大减少了人工标注耗费的时间和人力。具体来说,首先收集包含种子的句子,并将种子用特殊符号进行替换,然后从这些包含特殊符号的句子中学习出新的模板,最后使用学习出来的模板去抽取新的时间作为种子。这一过程是迭代进行的,直到没有新的时间被抽取出来时终止迭代。

表2 部分类型时间的正则表达式
2.2.1 模板学习
首先收集包含种子的句子,将句子中出现的种子用特殊符号“
2.2.2 模板打分

于
为了抽取出更多的时间,引入更少的噪声时间,需要对模板学习过程中产生的候选模板进行打分筛选,得到最有效的模板。根据公式(1)为候选模板集合中的每一个模板计算分数:
(1)
其中,Numrecognized(P)是利用模板P识别出来的独立时间个数,Numrecognized in seeds(P)是利用模板P识别出种子的个数。本文将模板分数阈值定为0.7。
2.2.3 独立时间识别
对于每个模板P,首先检索在病历文本中符合模板P的句子,并抽取“
3 基于事件的时间表达式识别
3.1 CRF模型
CRF模型是由Lafferty等人[13]于2001年提出的一种条件概率模型,它结合了隐马尔可夫模型(HMM)和最大熵马尔可夫模型(MEMM)的特点,通过全局归一化避免了标记偏置问题,从而在命名实体识别任务中取得很好的效果。CRF模型是一种符合马尔可夫随机场的无向图模型,基于观测序列X,计算目标标签序列Y的条件分布P(Y|X,λ)。目前常用的是线性CRF模型,其公式化为:
(2)
(3)
(4)
(5)

3.2 问题转化
利用CRF模型将识别基于事件的时间问题转化为序列标注问题。给定电子病历文本中的一个序列X=
常用的序列标注策略是以词为标注单元,以句子为标注序列。在中文文本中,词与词间没有天然的分隔符,当以词为标注单元时需要先利用分词工具进行分词。然而现有的分词工具通常面向一般文本,对电子病历这类专业性很强的文本分词效果并不好。如果分词错误的话,就不能保证训练集百分之百的准确,所以本文以字为标注单元。由于医生在记录电子病历时书写不规范,随意使用标点符号,所以本文以分句为标注序列(即以逗号、分号、句号对句子进行分割)。
3.3 特征选择
除了选择最基本的上下文特征、词性特征和位置特征作为三种最基本的特征[14],还额外增加了4种适用于识别电子病历文本中基于事件的时间的特征,如表3所示。采用Unigram,Bigram和Trigram这三种上下文特征,与上下文特征相对应,词性特征同样包含Unigram,Bigram和Trigram三组特征。对于词性特征,使用汉语言处理包HanLP[15]对病历文本进行分词和词性标注。由于本文以字为标注单元,故而当前字所在词的词性即是当前字的词性。HanLP认为被标记为t的词是时间词,然而,像“第三天”、“2016.11.23”和“6月23号”等很多时间词都不能被准确地识别出来。故而,本文将利用基于bootstrapping算法识别出来的独立时间赋予新的词性“tt”,并将识别出来的时间加入到用户自定义词典中,以确保分词的准确性。位置特征用Subi-Posi表示,其中,Subi是当前标注对象Xi所处分句的索引位置,Posi表示Xi在分句中的位置。

表3 基于事件的时间识别模型特征
3.3.1 词典特征
基于事件的时间是指由表示事件的名词、动词,后面可跟介词或方位词,并且可有时间信息组合表示的时间短语。在电子病历文本中,基于事件的时间是指以临床事件如入院、住院、出院、化疗、症状、疾病、手术等作为参考时间,如“入院第三天”、“肠癌术后第6年”等。
类似“入院第三天”、“化疗后第7天”等这些基于事件的时间中的事件较为简单,即为入院、化疗等这些关键词。而类似“十二指肠癌术后两年”、“乳腺癌术后4个月”、“反复腹胀腹痛后3年零2个月”等这些基于事件的时间中的事件较为复杂,在识别过程中会出现这样的难题:基于事件的时间短语太长而不能准确定位其边界的问题。观察电子病历文本发现,这类基于事件的时间中的事件类型是症状、疾病或手术。其中,手术都是以“术”字结尾,且“术”字前面都是某个疾病,例如上述的“十二指肠癌术”和“乳腺癌术”。故而,为了提高识别基于事件的时间的准确率和召回率,本文利用已经构建了的症状知识库[16]对电子病历文本中的症状和疾病进行识别。
isSYMPTOMorDISEASE判断当前标注序列中是否存在子字符串与症状知识库中的实体名完全相同,并得到其类型是症状还是疾病。本文为识别出来的症状赋予新的词性“symptom”,为疾病赋予新的词性“disease”,并加入到用户自定义词典中。hasOPERATION判断当前标注序列中是否包含字符串“手术之后”、“术之后”、“手术以后”、“术以后”、“术后”中的任意一个,当判断结果为“是”时,特征值为1,否则为0。
3.3.2 关键词特征
3.3.1节中提到了某些基于事件的时间中的事件较为简单,即为一些关键词。hasKEYWORDS判断当前标注序列中是否包含字符串“入院”、“住院”、“出院”、“化疗”、“检查”、“治疗”中的任意一个,当判断结果为“是”时,当前标注单元的关键字特征的特征值为1;否则为0。
3.3.3 时间触发词特征
利用时间触发词特征可以有效地判断当前标注序列是否可能包含基于事件的时间。本文收集了时间触发词例如“年、月、日、天、周”等等,总共11个。hasTIMETRIGGER判断当前标注序列中是否出现了时间触发词中的任意一个,当判断结果为“是”时,当前标注单元的时间触发词特征的特征值为1;否则为0。
3.3.4 数词特征
一般时间中大多包含数字。hasNUMERAL判断当前标注序列中是否包含数字0-9或“半一二三四五六七八九十”,当判断结果为“是”时,当前标注单元的数词特征的特征值为1;否则为0。
4 实验与分析
4.1 实验语料
对来自上海中医药大学附属曙光医院的1 500个患者的病历文本进行时间识别。其中,每个患者的病历文本包均含以下记录:首次病程记录,首次主治查房记录,首次主任查房记录,主任查房记录,主治查房记录,交班记录,住院记录,日常病程记录,出院小结。这些病历存在大量的冗余信息,通过观察发现,出院小结中的信息最为完整地概括了住院过程中患者的病情随时间的演变,包括入院情况、医生诊断情况、检查情况、治疗情况、出院情况以及转归情况。所以,基于出院小结,可以为每一个患者生成一个综合病历,总共1 500份。实验所用的数据都是这1 500份综合病历。
4.2 评测指标
通过准确率(Precision)、召回率(Recall)和F1值(F1-score)3个指标评测识别独立时间和基于事件的时间的性能。它们的计算方法分别为:
(6)
(7)
(8)
其中,Numrecognized是利用bootstrapping算法或CRF模型识别出来的时间总数;Numrecognized correct识别出来的时间中正确的个数,也就是Numrecognized中正确的个数;Numcorrect是测试语料中包含的时间总数。
4.3 实验结果和分析
4.3.1 独立时间表达式识别结果和分析
将1 500份综合病历文本分为两部分,1 000份作为训练集用来学习模板,500份作为测试集用来测试模板的效果。表4给出了利用正则表达式和本文方法识别独立时间的结果。

表4 不同方法对识别独立时间的结果影响
利用正则表达式识别独立时间时,如果医生在书写不规范,例如出现多个空格、逗号或其他符号将导致正则表达式无法识别;同时,相对时间和时间词收集不完全也会影响识别结果。而利用本文提出的方法能解决这个问题。
对基于bootstrapping算法的独立时间识别结果进行分析,发现错误类型主要包括以下两个方面:(1)模板导致抽取出错误的时间,例如:模板“患者于
4.3.2 基于事件的时间表达式识别结果和分析
依然将1 500份综合病历文本分为两部分,1 000份作为训练集,500份作为测试集,考虑不同的上下文窗口大小和不同的特征模板对CRF模型结果的影响,如表5所示。其中,基准模板就是上下文特征、词性特征和位置特征的组合。
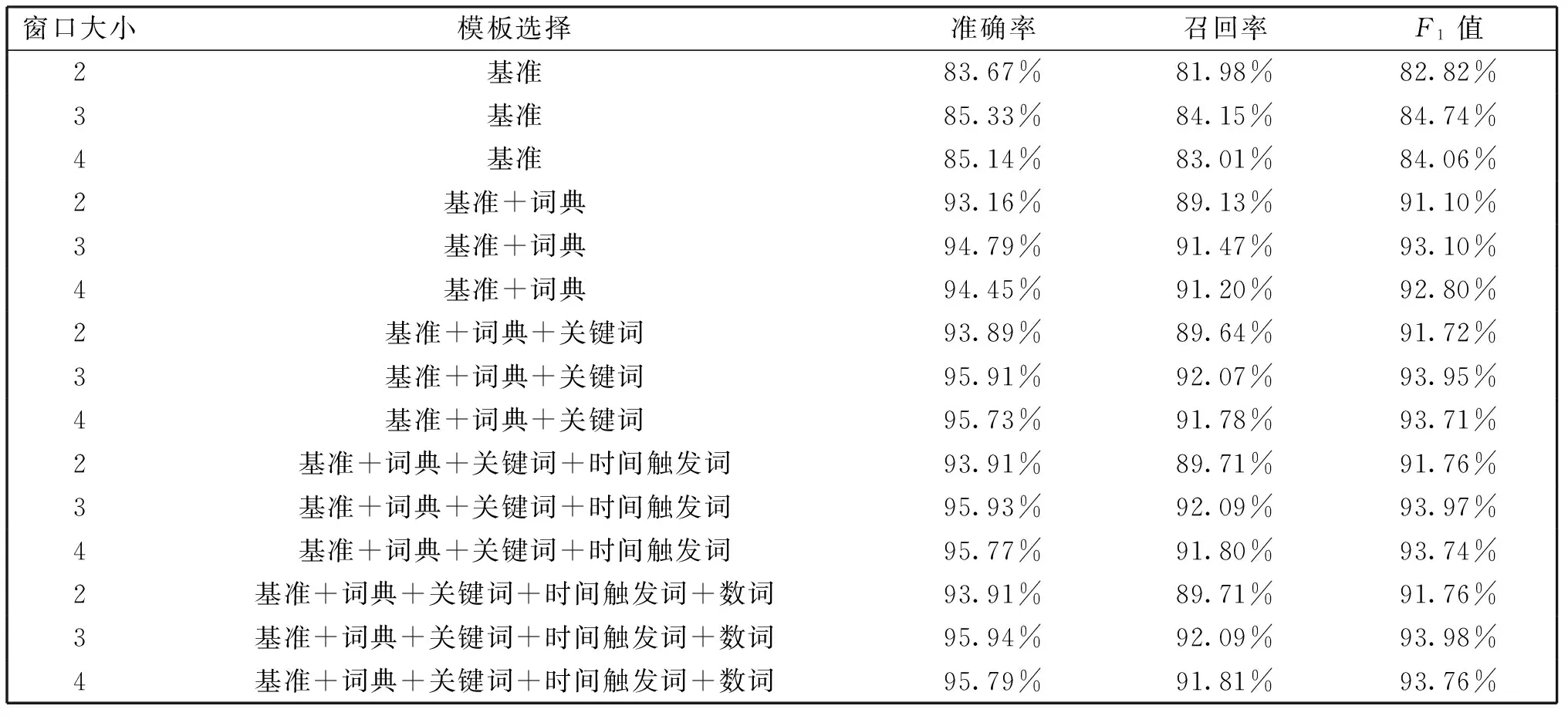
表5 不同窗口大小和特征模板对CRF识别结果影响
通过实验对比发现,在基准实验的基础上,加上词典特征后,CRF识别结果明显变好。这是由于引入中文症状知识库作为词典特征很好地解决了基于事件的时间短语太长而不能准确定位其边界的问题。而数词特征对CRF的识别结果影响最小。结果显示,当上下文窗口大小设为3,模板选择为上下文、词性、位置、词典、关键词、时间触发词和数词特征的组合时,CRF识别结果最高,其准确率、召回率、F1值分别为95.94%、92.09%和93.98%。
5 结论
将电子病历文本中的时间分为独立时间和基于事件的时间,提出了基于bootstrapping算法识别独立时间和基于条件随机场识别基于事件的时间的方法。基于bootstrapping算法识别独立时间,解决了正则表达式识别时间会覆盖不全的问题;利用CRF模型将基于事件的时间识别问题转化为序列标注问题,并引入症状知识库来解决基于事件的时间短语太长而不能准确定位其边界的问题。结果表明,这种方法在独立时间和基于事件的时间识别上的F1值分别达到了92.57%和93.98%。在未来的工作中,将继续识别电子病历文本中的时间关系,包括事件-事件和事件-时间的时间关系,这对于研究患者的病情发展和治疗效用至关重要。
[1] 马锡坤,杨国斌,于京杰.国内电子病历发展与应用现状分析[J].计算机应用与软件,2015,32(1):10-12.DOI:10.3969/j.issn.1000-386x.2015.01.003.
[2] 杨锦锋,于秋滨,关毅,等.电子病历命名实体识别和实体关系抽取研究综述[J].自动化学报,2014,40(8):1537-1562.DOI:10.3724/SP.J.1004.2014.01537.
[3] Liu Y K,Ray G.SemEval 2007 task 15:TempEval Temporal Relation Identification[C]∥International Workshop on Semantic Evaluations.Association for Computational Linguistics,2007:75-80.
[4] Bethard S,Savova G,Chen W T,etal.SemEval-2016 Task 12:Clinical TempEval[J].ProceedingsofSemEval,2016:1052-1062.DOI:10.18653/v1/S16-1165.
[5] 赵国荣.中文新闻语料中的时间短语识别方法研究[D].太原:山西大学,2006.
[6] 蔡华利,刘鲁,刘志明,等.突发事件Web新闻中时间信息分析及抽取[J].计算机工程与应用,2010,46(34):107-110.DOI:10.3778/j.issn.1002-8331.2010.34.033.
[7] 朱莎莎,刘宗田,付剑锋,等.基于条件随机场的中文时间短语识别[J].计算机工程,2011,37(15):164-167.DOI:10.3969/j.issn.1000-3428.2011.15.052.
[8] 吴琼,黄德根.基于条件随机场与时间词库的中文时间表达式识别[J].中文信息学报,2014,28(6):169-174.DOI:10.3969/j.issn.1003-0077.2014.06.024.
[9] Strötgen J,Gertz M.HeidelTime:High Quality Rule-based Extraction and Normalization of Temporal Expressions[C]∥International Workshop on Semantic Evaluation.2010:321-324.
[10] Hao T,Rusanov A,Weng C.Extracting and Normalizing Temporal Expressions in Clinical Data Requests from Researchers[J].LectureNotesinComputerScience,2013,8040:41-51.DOI:10.1007/978-3-642-39844-5-7.
[11] Xu D,Zhang M,Zhao T,etal.Data-Driven Information Extraction from Chinese Electronic Medical Records[J].PlosOne,2015,10(8):e0136270.DOI:10.1371/journal.pone.0136270.
[12] Ferro L,Gerber L,Mani I,etal.TIDES 2005 Standard for the Annotation of Temporal Expressions[S].2005.
[13] Lafferty J,McCallum A,Pereira F.Conditional Random Fields:Probabilistic Models for Segmenting and Labeling Sequence Data[C]∥Proceedings of the Eighteenth International Conference on Machine Learning,ICML,2001,1:282-289.
[14] Wang Y,Yu Z,Chen L,etal.Supervised Methods for Symptom Name Recognition in Free-text Clinical Records of Traditional Chinese Medicine:An Empirical Study[J].JournalofBiomedicalInformatics,2014,47:91-104.DOI:10.1016/j.jbi.2013.09.008.
[15] Hankcs.HanLP[CP].https:∥github.com/hankcs/HanLP,2014.
[16] Tong R,Wang M,Sun J,etal.An Automatic Approach for Constructing a Knowledge Base of Symptoms in Chinese[C]∥IEEE International Conference on Bioinformatics and Biomedicine.IEEE Computer Society,2016:1657-1662.DOI:10.1109/BIBM.2016.7822767.
猜你喜欢
趣味(语文)(2021年9期)2022-01-18 05:52:42
数学小灵通·3-4年级(2020年9期)2020-10-27 03:26:16
数学物理学报(2020年2期)2020-06-02 11:29:10
安顺学院学报(2020年1期)2020-04-05 10:57:20
现代计算机(2019年6期)2019-04-08 00:46:50
中国卫生(2016年10期)2016-11-13 01:07:44
中国卫生(2015年10期)2015-11-10 03:14:32
商(2012年11期)2012-07-09 19:07:55
