
深度PCANet模型的人脸美丽预测
2018-03-07 03:06甘俊英姜开永曾军英何国辉谭海英
信号处理 2018年12期
甘俊英 姜开永 曾军英 何国辉 谭海英
(五邑大学信息工程学院,广东江门 529020)
1 引言
人脸美丽预测是智能信息处理领域的一个重要研究方向,与人脸识别、人脸表情识别一样,都是利用人脸特征进行判别的一种技术。在机器学习领域,早期的人脸美学研究注重对感性认识的验证,如“近古典规则”、“黄金比例”和“三庭五眼”等,将人脸美总结为简单的几何关系,这种方法往往过于简单,而且缺乏严格的科学检验。目前,人脸美学研究从模式分析角度,采用数据驱动的统计学分析,挖掘表征人脸美丽特征,用于人脸美丽预测,如几何特征和表观特征等。其中,表观特征减少了主观干预,受到更多关注。
几何特征和纹理特征属于浅层特征,在人脸美丽预测中取得了大量的研究成果[1-7]。但是,由于人脸结构的复杂性,仍然丢失了许多有用的美丽特征,比如肌肉纹理、器官形状和皮肤颜色等。与之前手工设计的特征提取算法相比,深度学习能够提取抽象性、层次性的表观特征,具有更强的表达能力。2010年,Gray等[8]开发了一套基于深度卷积神经网络(Deep Convolution Neural Network, DCNN)的女性人脸美丽预测系统,以像素点作为系统输入,在没有人工干预的情况下实现了特征的全自动化提取。Xie等[9]在其开发的SCUT-FBP人脸美丽数据库上,设计了一个多层DCNN,与人工标定值相比,取得了0.8187的相关系数。Gan等[10]采用局部二值模式(Local Binary Pattern,LBP)、Gabor和像素特征训练卷积深度信念网络(Convolutional Deep Belief Network,CDBN),在支持向量机(Support Vector Machine,SVM)分类和回归中取得了较好效果。Xu等[11]设计了3个深度不等的卷积神经网络(Convolution Neural Network, CNN),采用SCUT-FBP人脸美丽数据库进行级联微调实验,在纹理图像上取得0.82的相关系数,在RGB彩色图像双级联上取得0.88的相关系数。因此,深度学习在人脸美丽预测中具有广泛的应用价值。
采用多尺度预处理,生成图像金字塔,能够获得相同结构、不同尺度和清晰度的图像集,有效表征人脸图像美的空间层次结构。同时,由于人脸美丽标签来自大量参评人员主观评分的平均值,在进行人脸美丽评价时,人脸图像的尺度大小、清晰度,成为人脸美丽主观评价的影响因素,会对参评人员的评分造成影响。因此,本文通过对人脸图像多尺度预处理,分解成不同尺度图像,再提取特征,进行训练和预测。例如,2010年,Gray等[8]构建了一个浅层CNN模型用于人脸美丽回归预测,在HSV颜色空间上对非受限人脸图像进行多尺度变换后,送入网络进行训练,最终取得0.458的预测相关系数,高于单尺度图像0.417的预测相关系数。2016年,Gan等[16]使用Multi-scale K-means方法在自建的人脸美丽数据库上,结合SVM分类器,在男性人脸美丽分类和女性人脸美丽分类中分别取得57.49%和55.07%的分类正确率,分别高于单尺度k-means男性人脸美丽分类和女性人脸美丽分类55.36%和52.54%的分类正确率。
DCNN[9,12]是一种有监督网络,在人脸识别和图像识别中被广泛应用,具有良好的分类判别性能。但是,DCNN存在结构复杂、可调参数多、缺乏完善的选取准则和需要大量有标签数据集进行拟合等问题;尤其在小规模数据库上训练时,容易出现过拟合,训练难度大。因此,本文采用一种简化的深度主元分析网络(Principal Component Analysis Network,PCANet)[13]提取特征;该网络不仅具有DCNN的卷积功能和层次堆叠结构,而且还具有结构简单、系统资源开销小和对实验样本数量要求小的特点,能有效解决DCNN存在的问题;同时,采用线性支持向量机(Support Vector Machine, SVM)回归器[10]和随机森林(Random Forest, RF)回归器[14],能够快速实现回归预测。为了提高回归预测效果,本文提出了深度PCANet的人脸美丽预测模型,可提取不同尺度图像的结构性全局特征,再用该特征训练线性回归器,最后进行模型性能评估。基于SCUT-FBP人脸美丽数据库的实验结果表明,深度PCANet模型具有较好的回归性能。
2 基于深度PCANet的人脸美丽预测模型
深度PCANet通过主元分析处理,提取图像块的最大主元分量作为深度PCANet卷积滤波器的参数,再通过卷积滤波提取图像深层次的结构性特征。深度PCANet提取的图像全局特征,经哈希编码和直方图处理后,转变成高维空间的向量特征,从而通过特征映射将图像转换到高维空间。为了获得更加完备和稳健的人脸美丽特征集合,本文将深度PCANet模型用于人脸美丽预测;并对图像采用多尺度预处理,得到不同尺度的人脸图像。如图1所示,包括多尺度图像预处理层、深度PCANet和回归器。

图1 深度PCANet模型框图
2.1 多尺度图像预处理
图1中,多尺度图像预处理主要是对获取图像进行对齐、尺度归一化和下采样等尺度化处理,分别获得尺度为90×90、60×60、30×30的图像集,如图2所示。
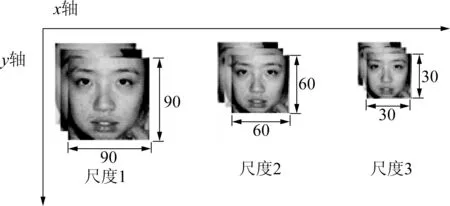
图2 多尺度训练集
2.2 深度PCANet
深度PCANet[13]是Chan等提出的一种简化的无监督深度卷积神经网络特征提取方法,整体采用层次堆叠结构,能够进行多层次级联,通过主元分析获取深度网络卷积滤波器参数,可提取更深层次更抽象的图像特征。与DCNN相比,深度PCANet通过无监督预训练提取卷积滤波器参数,无需调参优化,模型结构简单且运行速度更快。
深度PCANet通常由输入层、主元分析层、特征输出层和训练分类器四个部分构成,如图3所示。其中,主元分析层由多级PCA层构成,用于提取模型的滤波器参数,通常使用2级PCA层;特征输出层由哈希编码和块直方图变换构成,用于特征图变换和输出特征;训练分类器使用线性回归器,用于评估模型性能。下面以图3为例,详细介绍其处理过程。
2.2.1 PCA层
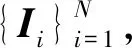
(1)
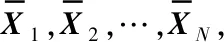
(2)
通过寻找标准正交矩阵来最小化重构误差,即
(3)
其中,V表示标准正交矩阵。再求解主元成分,即
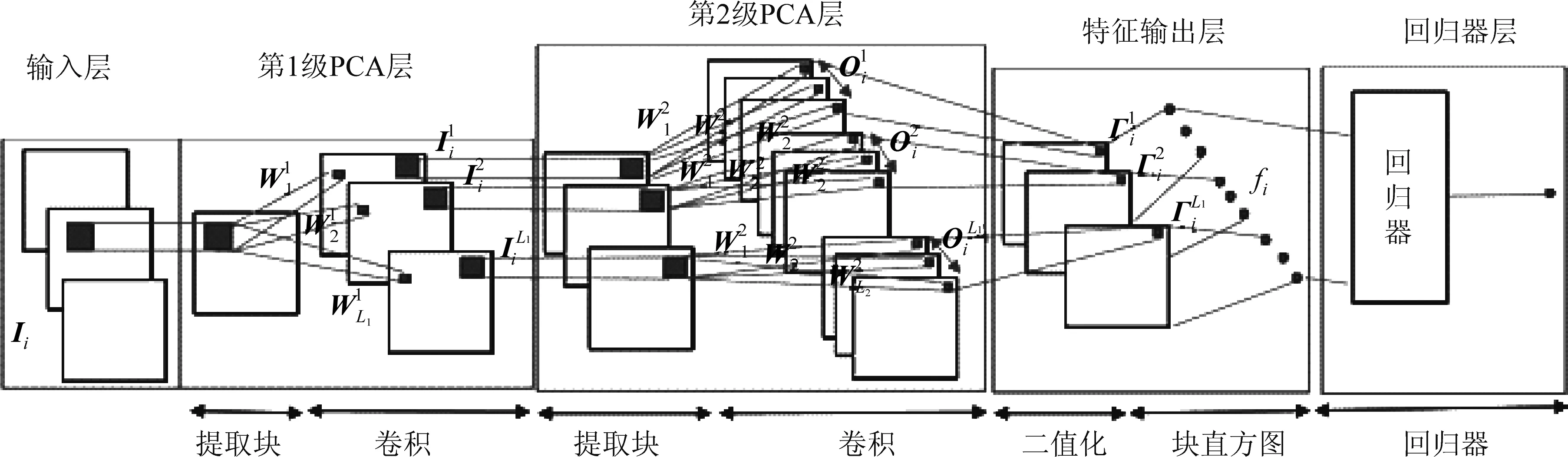
图3 深度PCANet模型
(4)
其中,matk1k2(•)函数是k1k2维向量到k1×k2矩阵的映射,q1(XXT)函数表示协方差矩阵的第l个主特征向量。卷积滤波后,共有N×L1个映射输出,即
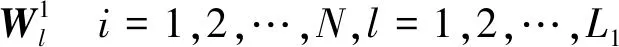
(5)

第2级PCA以第1级PCA的映射输出作为输入,进行卷积映射,即
(6)
其中,i=1,2,…,N,l=1,2,…,L1。每一个训练样本经2级PCA处理后均会产生L1L2个输出特征矩阵。
2.2.2 哈希和直方图处理
对第2级PCA输出的特征图像进行二值化,得到只包括1和0的数值,即
(7)
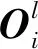
*W2γ)l=1,2,…,L1
(8)
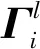
(9)
2.2.3 回归算法
深度PCANet提取的图像块直方图特征高达上百万维,使用加权主元分析(Weighted Principal Component Analysis,WPCA)进行降维后,特征维数降低到几万维。由于特征维数很高,以此训练的分类器模型在高维空间能够实现线性可分。
线性SVM分类器和随机森林分类器均属于高维数据分类模型。其中,线性SVM分类器在样本数量有限且特征维数很高的情况下,与LibSVM非线性分类器相比,具有更高的分类效率和准确率。实验证实了线性SVM分类器在模型训练上用时更短、正确率更高。随机森林分类器是用随机方式建立起的、包含多个决策树的分类器,在高维数据训练时,训练速度快且不易出现过拟合,对数据噪声和错误具有鲁棒性。本文采用以上两种线性分类器的回归方法进行人脸美丽预测实验,并使用皮尔逊相关系数(Pearson Correlation Coefficient)评价预测效果。
3 实验结果和分析
3.1 SCUT-FBP数据库
SCUT-FBP人脸美丽数据库是Xie等[9]创建的用于人脸美丽预测的亚洲年青女性人脸美丽数据库,包含500幅中性表情和少量遮挡的正面人脸图像,如图4所示。
SCUT-FBP人脸美丽数据库的标签分布符合高斯分布,如图5所示。人脸图像分布不均衡,极丑和极美的图像数量较少,大多为平均水平,如图6所示。
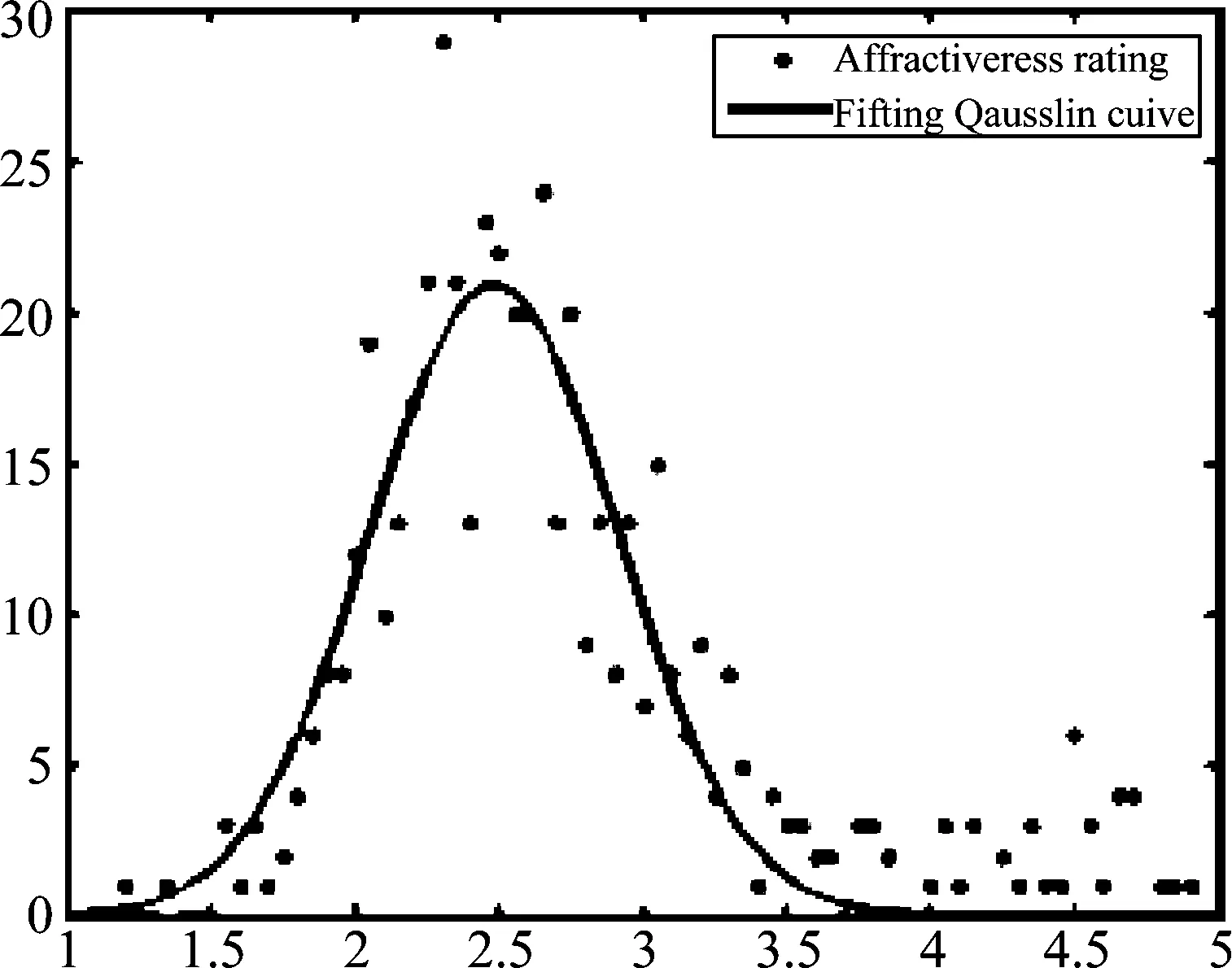
图5 SCUT-FBP标签分布图
3.2 图像预处理
为了提高深度PCANet模型的训练效果和泛化能力,本文进行人脸检测和关键特征点检测[15],如图7所示。以两眼中心关键点连线与水平线的夹角,
计算人脸水平偏转角度,进行图像水平对齐;再以两眼中心和嘴巴中心相隔48个像素进行尺度归一化,对尺度归一化后的图像进行裁剪和灰度变换,最终得到尺度为90×90的图像,如图8所示。
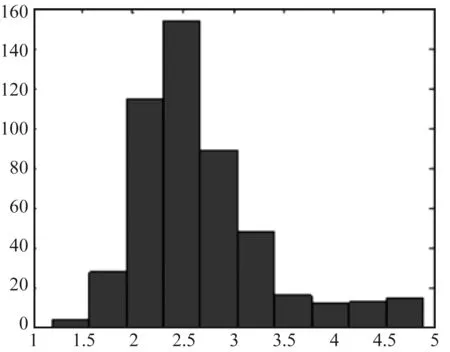
图6 SCUT-FBP标签分布直方图
3.3 结果与分析
本文采用随机划分图像和平均划分图像两种方式,对SCUT-FBP人脸美丽数据库进行划分,并完成人脸美丽预测实验。

图7 人脸检测和关键点检测

图8 图像预处理后的彩色图像(上)、灰度图像(下)
3.3.1 基于随机划分图像的实验结果
实验时,随机打乱SCUT-FBP人脸美丽数据库中的图像顺序,并平均分成5等份,然后进行5折交叉验证实验,用于实验的各尺度模型名称如表1所示。其中,图像尺度表示深度PCANet输入图像集的大小;DPCA模型表示未对特征进行开平方增强处理的深度PCANet;DPCAS模型表示对特征进行开平方增强处理的深度PCANet。例如,DPCA90模型,未对提取的深度PCANet特征进行开平方处理,而是直接送入线性回归器进行模型训练和预测;DPCA90S模型,对提取的深度PCANet特征进行了开平方处理,然后再送入线性回归器进行训练和预测。表2是深度PCANet模型的参数设置。其中,深度PCANet模型包括2级PCA滤波器,第1级有12个滤波器,第2级有8个滤波器。

表1 深度PCANet模型名称 Tab.1 Names of deep PCANet model
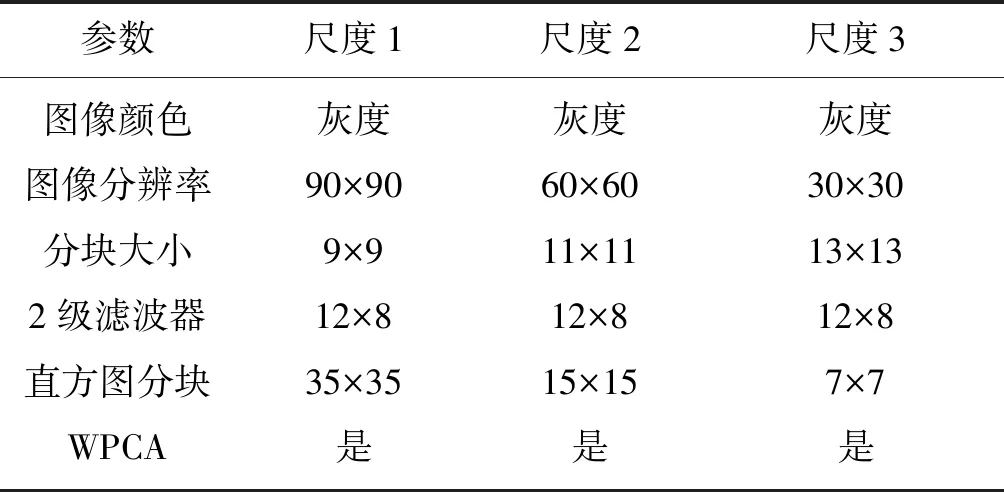
表2 深度PCANet模型参数
在3个尺度90×90、60×60、30×30上训练深度PCANet,并评估模型的回归预测性能。其中,60×60、30×30的训练集由尺度为90×90的训练集降采样获得。训练结束后,提取3个尺度深度PCANet的滤波器参数,并进行可视化,如图9所示。其中,第一行是尺度为90×90图像集对应的深度PCANet的2级滤波器参数可视化图,从左侧起,前12个是第1级滤波器参数的可视化图,后8个是第2级滤波器参数的可视化图;第二行和第三行分别是尺度为60×60、30×30图像集所对应的深度PCANet的2级滤波器参数可视化图。
由表3可知,进行线性SVM回归训练和预测时,模型DPCA90、DPCA60和DPCA30取得的相关系数分别为0.8403、0.8146、0.7440;使用特征增强方法后,模型DPCA90S、DPCA60S和DPCA30S取得的相关系数分别为0.8558、0.8164、0.7718。DPCAS模型的相关系数明显大于DPCA模型的平均相关系数,说明使用特征增强方法能有效提升回归性能,而且DPCA90S取得了最好的回归性能,表明选择合适的图像尺度可提高人脸美丽评价结果。
表4是深度PCANet模型在提取特征、训练和测试线性SVM与随机森林回归器上的时间。其中,第一行是PCANet模型训练和提取400幅训练集图像特征的总时间。在深度PCANet模型上,400幅训练集图像的特征提取时间最长为207.47 s,单幅图像的特征提取时间平均为0.52 s;400幅训练集图像的特征提取时间最短为61.12 s,单幅图像的特征提取时间平均为0.15 s。第二行、第三行分别是线性SVM回归器的训练时间和测试时间。其中,线性SVM回归器最长训练时间为2.24 s,最短训练时间为0.63 s;最长测试时间为0.55 s,最短测试时间为0.16 s。第四行、第五行分别是随机森林回归器的训练时间和测试时间。其中,随机森林回归器最长训练时间为2000.60 s,最短训练时间为1388.50 s;最长测试时间为37.44 s,最短测试时间为25.71 s。显然,线性SVM回归器比随机森林回归器的运行速度更快。尽管DCNN可以通过增加网络深度,提升特征提取能力,改善回归性能,但是网络训练时间很长,一般需要几个小时或者几天,而本文提出的深度PCANet模型,使用SVM回归器从训练到测试总耗时不超过10分钟,而使用随机森林回归器总耗时不到1小时。因此,与现有算法相比,本文所构建的深度PCANet模型具有网络训练时间短和图像特征提取速度快的特点,而且线性SVM回归器比随机森林回归器的训练时间更短,运行效率更高。

图9 3个尺度的滤波器可视化图
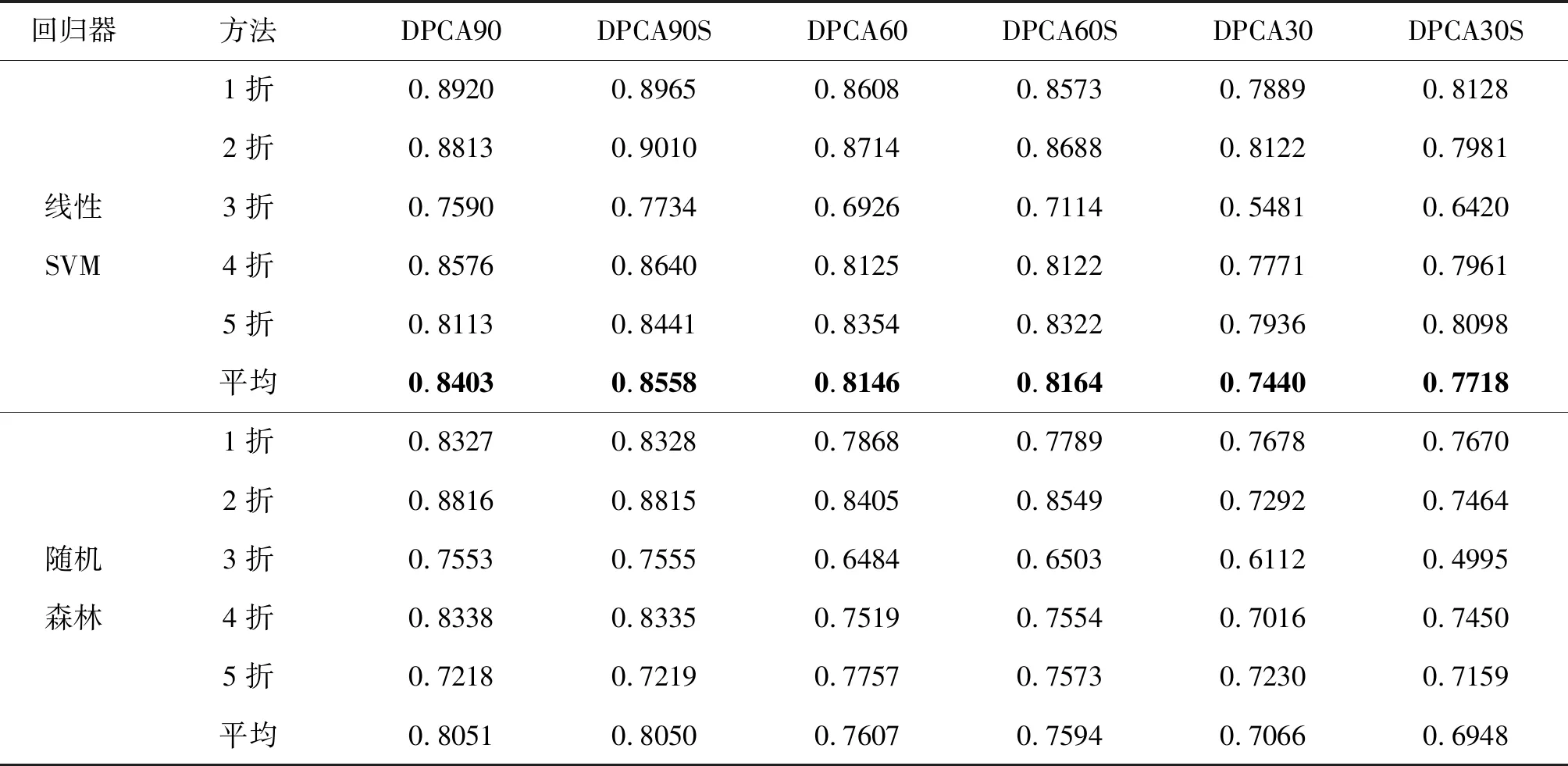
回归器方法DPCA90DPCA90SDPCA60DPCA60SDPCA30DPCA30S线性SVM1折2折3折4折5折平均0.89200.88130.75900.85760.81130.84030.89650.90100.77340.86400.84410.85580.86080.87140.69260.81250.83540.81460.85730.86880.71140.81220.83220.81640.78890.81220.54810.77710.79360.74400.81280.79810.64200.79610.80980.7718随机森林1折2折3折4折5折平均0.83270.88160.75530.83380.72180.80510.83280.88150.75550.83350.72190.80500.78680.84050.64840.75190.77570.76070.77890.85490.65030.75540.75730.75940.76780.72920.61120.70160.72300.70660.76700.74640.49950.74500.71590.6948
3.3.2 基于平均划分图像的实验结果
根据表5,改变SCUT-FBP训练集和测试集的划分方式,将数据集分成9段,分别对每一段进行5折交叉分割,最后合并成5折交叉的训练集和测试集。表5中,第一行表示图像标签(Label)的9个划分区间,第二行表示每个区间内分割到的图像数量,9个区间内的图像数量总和为500。
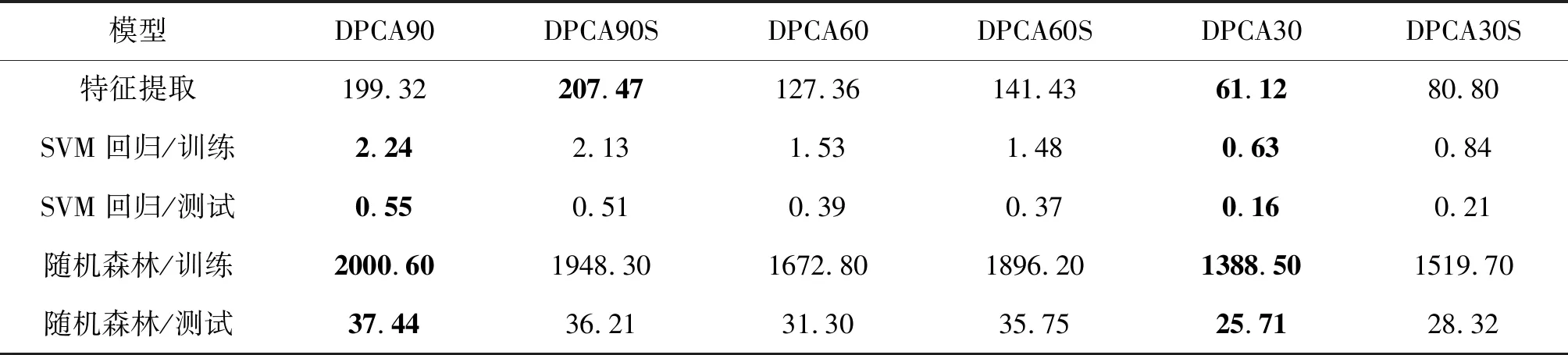
表4 不同尺度图像模型运行时间

表5 标签分割
模型名称和模型参数设置与3.3.1节相同。划分出训练集和测试集后,再次进行实验。由表6可知,进行线性SVM回归时,模型DPCA90、DPCA60和DPCA30取得的最高相关系数为0.8419,平均相关系数为0.8016;模型DPCA90S、DPCA60S和DPCA30S取得的最高相关系数为0.8548,平均相关系数为0.8078;使用随机森林回归时,最高相关系数为0.7831,低于线性SVM回归器的平均值0.8078。因此,深度PCANet模型在回归预测上,线性SVM回归器比随机森林回归器的预测性能好,且再次证明使用特征增强方法的DPCAS模型预测性能比不使用增强方法的DPCA模型好,而模型DPCA90S取得了最好的回归性能,再次说明选择合适的图像尺度可提高人脸美丽评价结果。表7是模型提取特征、训练和测试线性回归器所消耗的时间。从表7与表4可知,无论是采用平均划分图像还是采用随机划分图像,深度PCANet模型具有网络训练时间短和图像特征提取速度快的特点。
3.4 回归测试效果对比
由3.3节的实验可知,在数据库规模比较小的情况下,深度PCANet仍具有较好的特征提取和泛化能力。由图6可知,SCUT-FBP人脸美丽数据库中极丑和极美的人脸图像数量较少,在3.3.1节的5折交叉验证实验中,极端美丽程度的人脸图像分配到训练集中的数量不固定,但结果显示,在深度PCANet回归预测上分别取得了最高的相关系数,进一步表明,深度PCANet对训练集中数量少的类别也具有较好的学习能力。
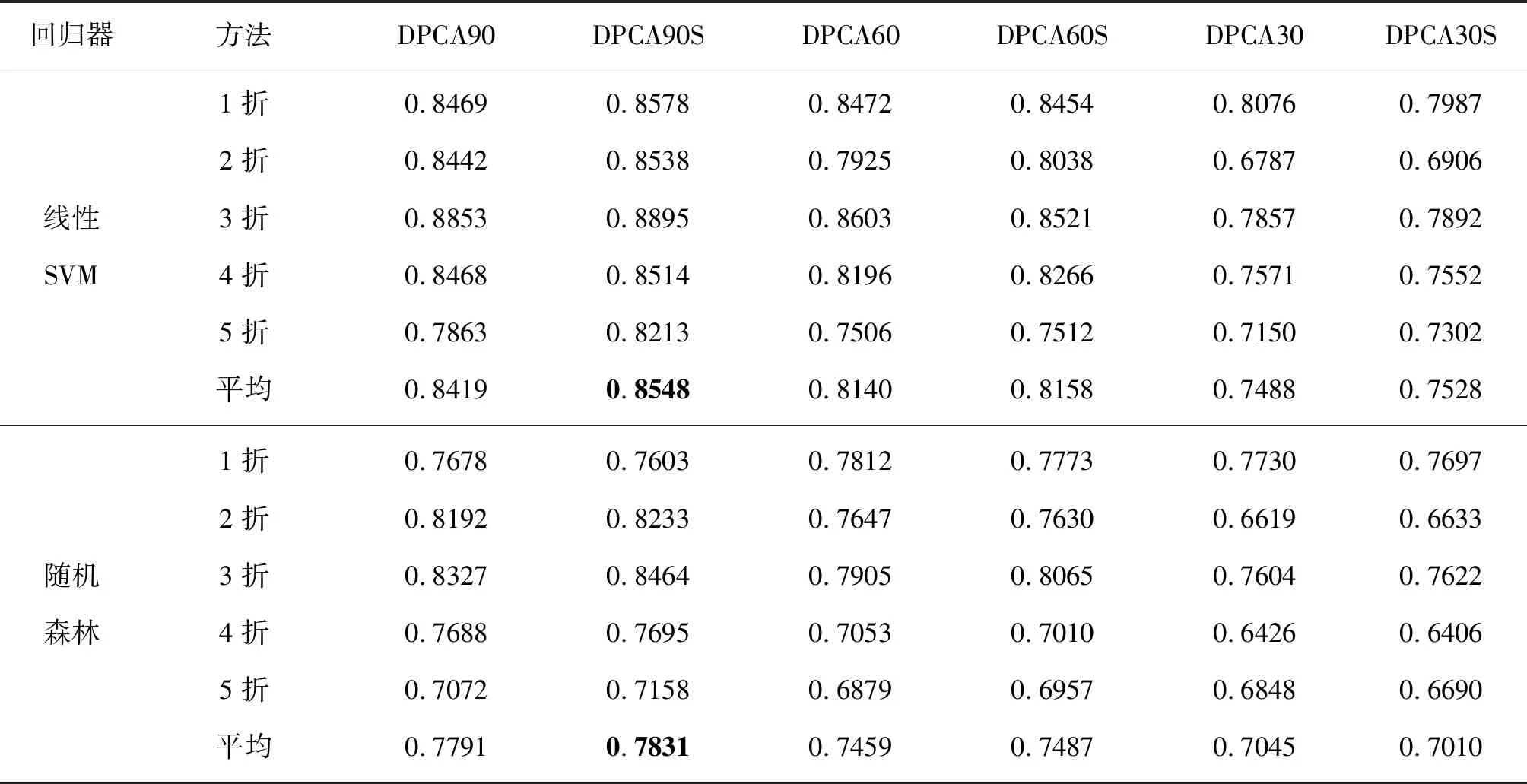
表6 回归预测结果
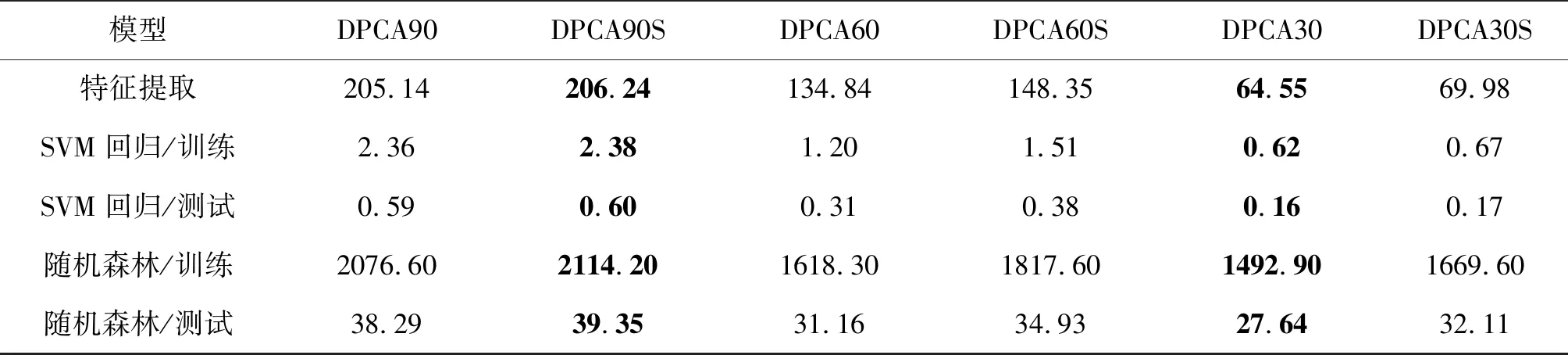
表7 不同尺度图像模型运行时间
由表8可知,深度PCANet模型在测试性能上优于传统的浅层特征提取网络和CNN网络,取得的最大相关系数为0.8558,高于深度卷积神经网络GoogLeNet[17]、VGG-19[18]和ResNet-101[18],说明网络不是越深效果越好。本文提出的深度PCANet具有一定的优越性;虽然未达到深度卷积神经网络CNN-3的相关系数0.88[11],但是,使用深度卷积神经网络预训练时间长,且文献[11]所提方法需要多次级联微调,参数优化比较复杂。本文所构建的模型采用无监督方式进行预训练,无需调参优化,网络结构更简单和运行速度更快。
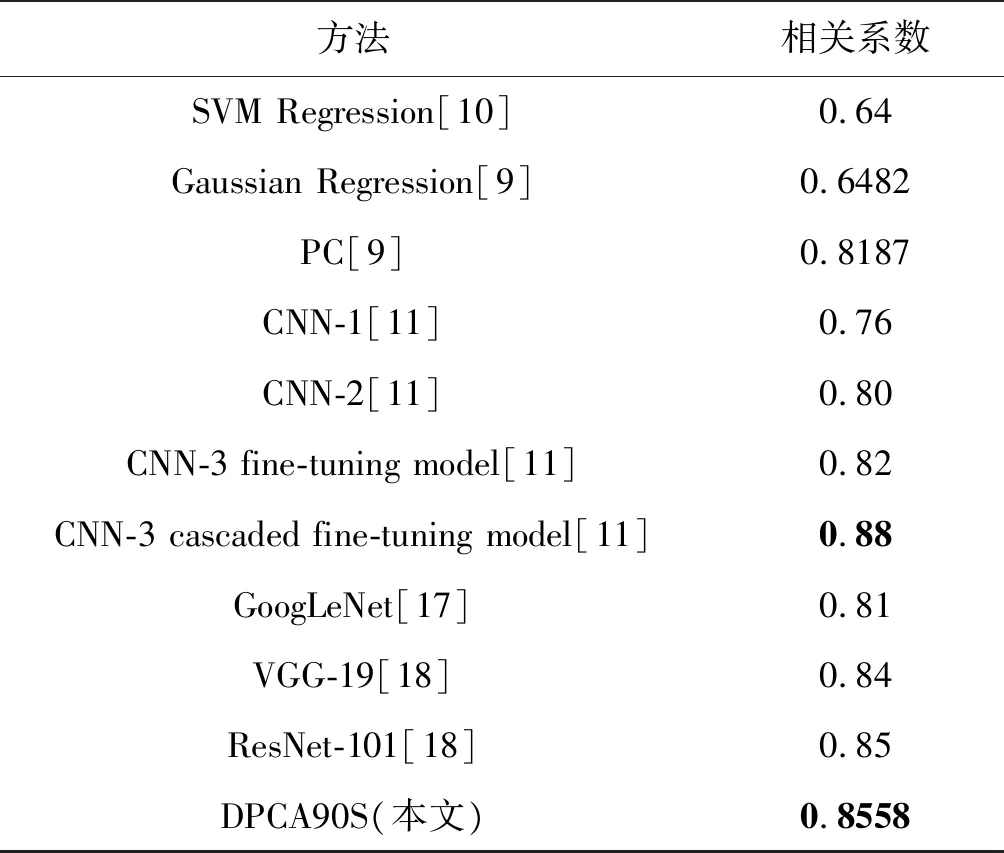
表8 不同算法在SCUT-FBP数据库上的实验结果
4 结论
本文构建了深度PCANet的人脸美丽预测模型,该模型能学习到图像的结构性特征,使其更稳健和更具表征能力。基于SCUT-FBP人脸美丽数据库的实验结果表明,深度PCANet模型不仅具有深度卷积神经网络卷积和层次堆叠的结构,而且还具有模型结构简单、运行速度快、特征提取时间短等特点,对深度学习在人脸美丽预测中的应用具有参考价值。同时,图像尺度为90×90的预测结果优于尺度为60×60、30×30的预测结果,对特征进行增强后的回归性能优于特征增强前的回归性能,说明选择合适的图像尺度与采用特征增强方法可提高人脸美丽评价结果。如何改进所构建的深度PCANet模型,提高其回归预测性能,值得进一步深入研究。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
动漫星空(2018年9期)2018-10-26
北京航空航天大学学报(2018年1期)2018-04-20
太空探索(2016年5期)2016-07-12
时代英语·高三(2014年5期)2014-08-26
