
越南语分词词典半监督集成构建算法
2018-03-07 09:22刘伍颖
郑州大学学报(理学版) 2018年1期
刘伍颖, 王 琳
(1.广东外语外贸大学 语言工程与计算实验室 广东 广州 510420;2.上海外国语大学 贤达经济人文学院 上海 200083)
0 引言
越南语是一种以音节为基础的非通用语言,其文本在词与词之间并没有任何显式的形式分隔符.因此,越南语分词在很多自然语言处理应用中显得格外重要[1].用于越南语分词的机读词典在存储内容方面仅仅需要保留多音节词,而这种基础资源在一定程度上决定着分词算法的性能.
计算技术的飞速发展带来了语言信息的爆炸式增长,各种语言中的新词汇不断涌现.但人工词典编纂是一种代价高昂的工作,而且人工编纂的时效性也极大限制了分词算法的提高.幸运的是,语言信息爆炸所产生的大规模越南语文本文档为越南语多音节词动态提取提供了一种新机遇[2].已有研究表明,一些基于分词词典的越南语分词算法可以达到较高的性能[3],通过个性化定制一个单独的子词典能够使大词典在分词中发挥大性能[4].本文主要研究越南语分词词典构建问题,并提出一种新的半监督集成构建方法,该方法能够结合人工干预,从大规模未标注越南语语料中提取多音节单词.
1 半监督集成构建算法
1.1 框架
半监督学习能够充分发挥大规模未标注语料的优势[5],又能够大大降低人工标注的需求[6-7].集成学习能够组合多个单独的学习器以获得更优的结果[8].因此,综合这两种机器学习方法的优势,提出一种新的半监督集成构建(semi-supervised ensemble construction, SEC)框架,如图1所示.该框架输入大规模未标注越南语语料,根据预设阈值和人工干预最终生成3个单独词典DIC1、DIC2、DIC3和1个集成词典DICE,并以此支撑词典分词算法的运行.此外,3个单词提取器人工检测后的正确单词形成一种动态反馈.当框架输入是在线实时数据流时,通过设置一定长度的时间窗口,动态反馈能够阻止以前提取并正确识别的单词,使得框架能够循环迭代并增量学习.
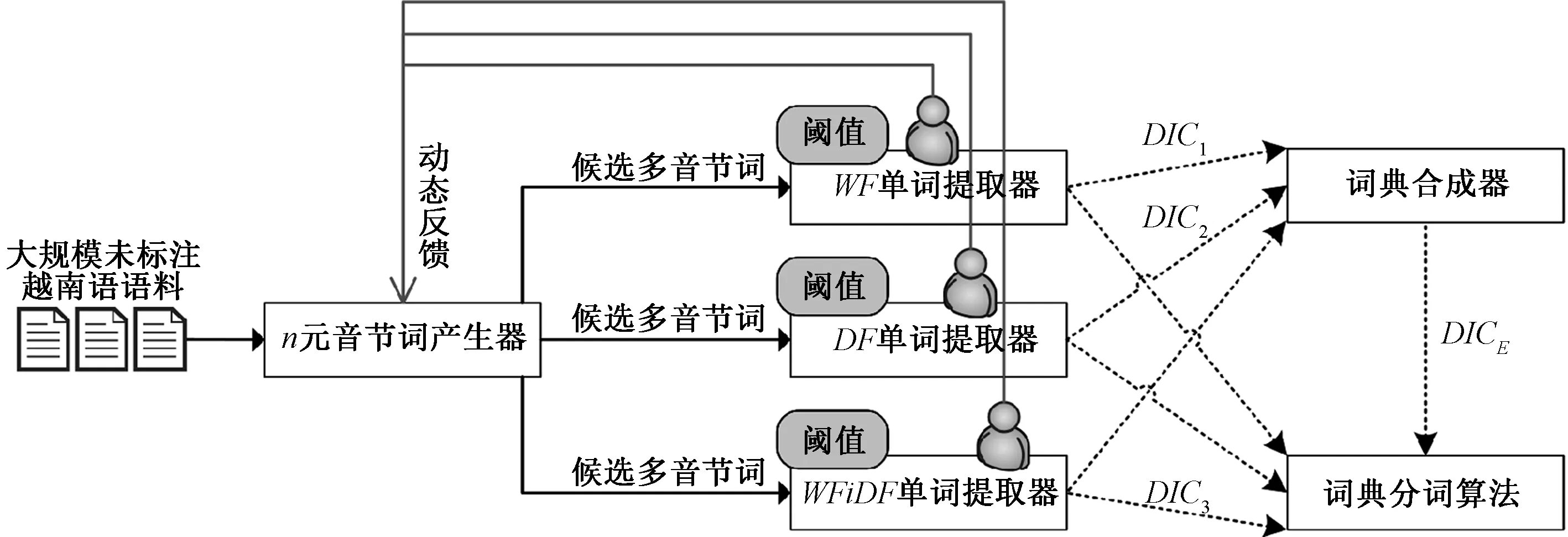
图1 半监督集成构建框架Fig.1 Semi-supervised ensemble construction framework
在图1所示的SEC框架中,n元音节词产生器是一个重要部件,它负责生成尽可能多的候选多音节词.并且这一生成过程只需要n元音节词模型,而不需要额外的人工干预.接着,每个单词提取器根据统计特征值进行候选多音节词排序,通过对比预设的百分比阈值提取排在前面的多音节词,并提交给越南语专家进行检测并修正.专家检测修正的结果形成分词词典,并以动态反馈的形式发给n元音节词产生器.最后,词典合成器充分利用不同单词提取器的优势,合并这几个提取出的分词词典形成一个集成词典,这些单独的分词词典和集成词典可以被用于基于词典的分词器.
n元音节词模型蕴含丰富的有用特征[9],并且n值决定候选多音节词的总数.采用4种交叠n元音节词模型(2元模型、3元模型、4元模型、5元模型)来表示越南语多音节词,并通过统计数据进行进一步分析.利用Wiki Dump工具从互联网下载了越南语Wikipedia语料(viwiki-20170101-pages-articles.xml.bz2),再通过Wikipedia Extractor软件抽取获得1 152 603篇越南语纯文本文档.根据上述4种n元音节词模型,从这些越南语文本文档中提取出10 849 903个候选多音节词,并为每个候选多音节词统计词频和出现文档频率.绘制词频-词秩和文档频率-词秩图,结果如图2所示.针对两幅图中的数据分别拟合出趋势线,结果表明,词频分布和文档频率分布都近似遵循幂律,而泛在的幂律分布给去除低频词提供了一个机会[10].
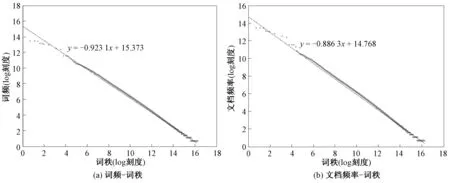
图2 词频-词秩和文档频率-词秩Fig.2 Word frequency versus rank and document frequency versus rank
1.2 算法
一个越南语单词可以由单个音节构成,也可以由空格连接起来的多个音节构成.在越南语文本中,空格是一种重载符,既可以表示单词内部的连接符,又可以表示单词之间的分隔符.因此,越南语多音节词提取任务可以定义为连续多音节的共现规律发现.如果几个音节倾向于高频共现,可以预判它们是一个多音节词.基于幂律分布支撑,可以通过统计候选多音节词的词频(WF)和出现文档频率(DF)两种简单特征,并根据预设的百分比阈值提取出一些高频共现多音节词,而这些高频词和高文档频率词往往是通用词汇.此外,词频除以文档频率(WFiDF)也是一种广泛用于自然语言处理的重要特征.通过统计WFiDF特征,往往能够提取专业词汇.
在SEC框架下所提出的越南语分词词典半监督集成构建算法如表1所示.首先,循环调用ngram()方法生成候选多音节词(CMW).在这个过程中需要对越南语文本进行切片预处理,片段是由标点符号、阿拉伯数字、外来词分割开的越南语音节段.接着,分别调用3个单词提取器(WFextractor,DFextractor,WFiDFextractor).其中每个提取器运行3个方法:rank()方法根据统计特征值排序候选多音节词;truncate()方法根据预设阈值(T)截断低频词;sendfeedback()方法回传动态反馈.当然,每个提取器生成的词典还需要进行人工检测.最后,词典合成器运行merge()方法,将上述3个词典(DIC1、DIC2、DIC3)去重合并成集成词典(DICE).3个单词提取器运行的并行性能够进一步提高算法的时空高效性.
表1越南语分词词典半监督集成构建算法
Tab.1SEC algorithm of Vietnamese word-segmentation dictionary

2 实验部分
2.1 语料与评价
实验中大规模未标注越南语语料就是1.1节所述的越南语Wikipedia语料,包括1 152 603篇越南语纯文本文档.在实验前实现了表1的算法,能够从未标注语料中提取3个单独词典和1个集成词典.以下将通过直接实验和间接实验来评价越南语分词词典半监督集成构建算法的效力.在直接实验中,利用一个人工构建的包含159 214个越南语多音节词的大词典来模拟人工检测,以此计算每个词典的准确率.评价指标是在阈值T上的准确率(P@T).在间接实验中,针对每个构建出的词典,分别运行两个基于词典的分词算法MM(maximum matching)和RMM(reverse maximum matching).
分词算法运行使用公开的标准数据集(corpus for Vietnamese word-segmentation, CVWS),该数据集包括305篇多领域越南语新闻文本,共7 807个已标注词边界的句子.使用国际bakeoff[11]评价标准和相关评价方法,用准确率(P)、召回率(R)、F1值和错误率(ER)评价分词算法的性能.P、R、F1的值域为[0, 1],1为最优,ER的值域也为[0, 1],但0为最优.以上5项评价指标的计算公式为
P@T=V/W,(1)
P=C/(C+M),(2)
R=C/N,(3)
F1=2PR/(P+R),(4)
ER=M/N,(5)
式中:W表示自动提取器提取的多音节词数;V表示自动提取词典和人工构建词典共同包含的多音节词数;N表示人工分词语料的总词数;C表示自动分词结果中正确切分的词数;M表示自动分词结果中错误切分的词数.
2.2 结果与讨论
在直接实验中阈值分别被设置为20%、40%、60%、80%,由此产生的多音节词数和准确率结果如表2所示.例如,根据词频排序10 849 903个候选多音节词,采用20%阈值能够提取前1 270个词,这其中有37.72%的词命中人工构建的大词典.表2还显示了4个词典具有类似的结果趋势.尽管准确率不是特别高,但未命中的词中间还有很多是算法发现的新词.此外,准确率不高的原因是大规模未标注越南语语料和人工构建的大词典之间相互独立.

表2 不同阈值下的词数和准确率Tab.2 Word number and precision at different thresholds
在间接实验中先分别在3个单独词典下运行MM算法,实验结果如表3所示,3个单独词典中DIC3性能最优.例如DIC3词典下最优的P值(0.682 8)、R值(0.753 8)、F1值(0.691 0)、ER值(0.314 0)分别是当阈值为40%、20%、40%、60%时达到的.结果表明,WFiDF特征比单独的WF特征或DF特征更加有效.
表4展示了在3个单独词典下运行RMM算法的实验结果,和MM算法的实验结果具有相同的趋势,4项评价指标的最优值也是DIC3词典的.

表3 MM算法在3个单独词典下的实验结果Tab.3 Experimental results of MM algorithm in three individual dictionaries
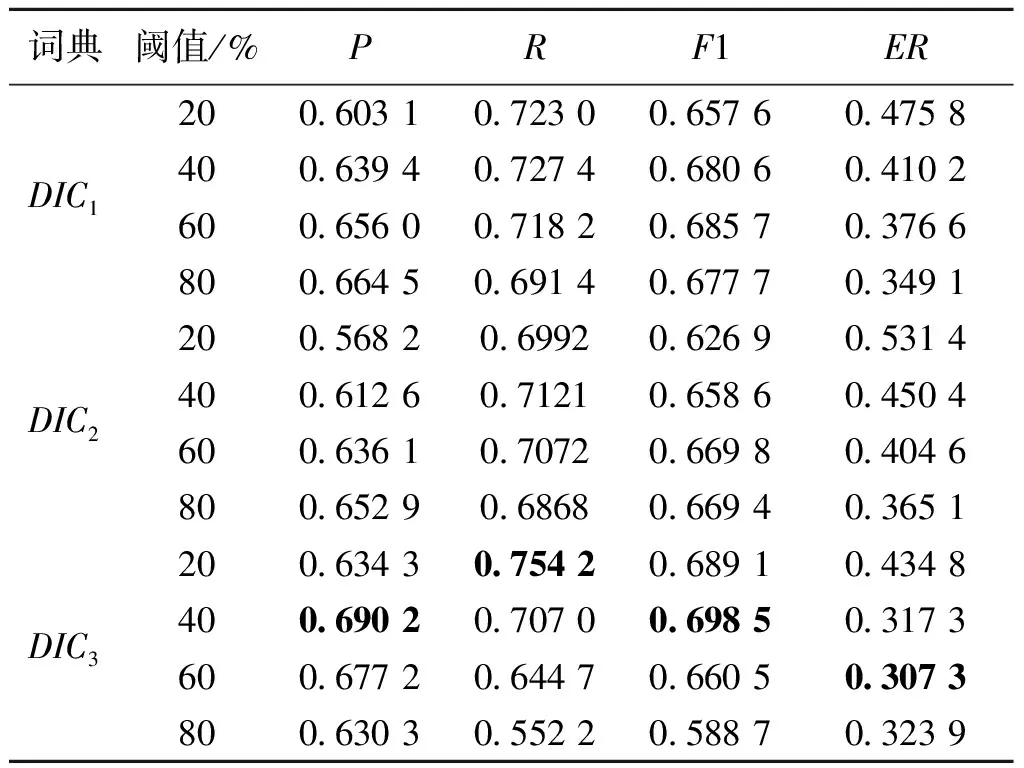
表4 RMM算法在3个单独词典下的实验结果Tab.4 Experimental results of RMM algorithm in three individual dictionaries
图3展示了集成词典下MM算法的实验结果,结果表明,阈值既非越大越好,又非越小越好,一个合适的阈值(40%)能够使集成词典下MM算法达到最优性能.尽管性能提升不太显著,但最优的F1值(0.706 3)还是超越了其他3个单独的词典,这也验证了越南语分词词典半监督集成构建算法在统计、计算、表示方面的优越性[12].图4展示了集成词典下RMM算法的实验结果,和MM算法的实验结果具有相同的趋势.但RMM算法4项评价指标的最优值均超过了MM算法.例如,MM算法的最优F1值为0.706 3,而RMM算法的最优F1值为0.713 3,这之间的差距主要是和越南语的语序有关.
通过对上述实验结果的分析,发现词频和文档频率这两种简单特征的统计能够有助于高效提取通用的越南语多音节词.正因为如此,所以仅仅4 847词的RMM算法能够达到0.685 7的F1值.尽管WFiDF特征的统计有助于提取专业词汇,但不幸的是CVWS数据集与越南语Wikipedia语料也没有很强的相关性,所以仍然有大量的“长尾”词被预设阈值剔除了.如果还想进一步提高分词词典的准确率,算法中的人工干预过程ManualFilter.check()至关重要.
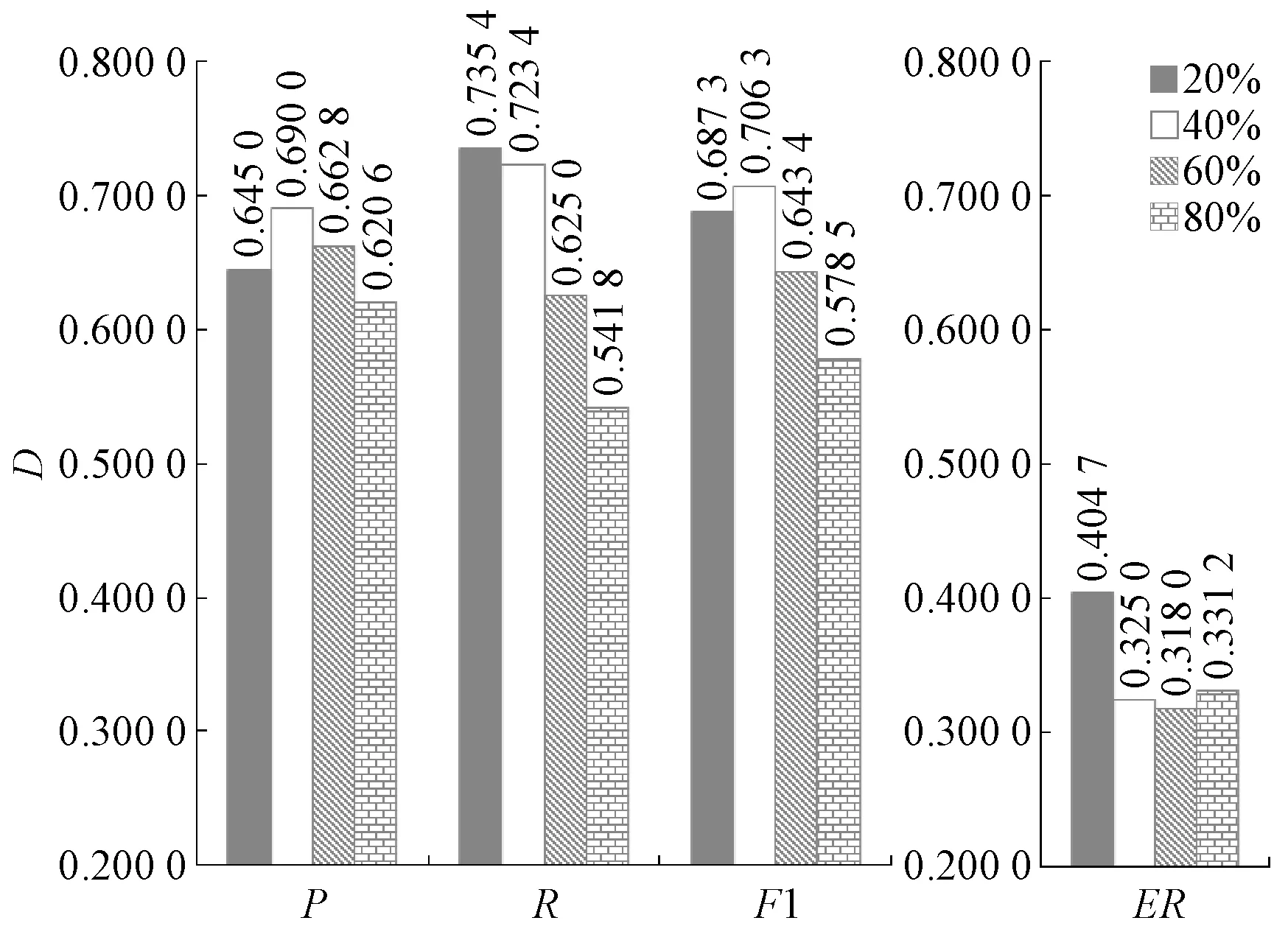
图3 MM算法在集成词典下的实验结果Fig.3 Experimental result of MM algorithm in ensemble dictionary
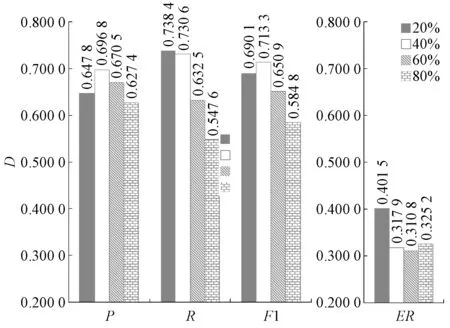
图4 RMM算法在集成词典下的实验结果Fig.4 Experimental result of RMM algorithm in ensemble dictionary
为了展示词典的具体细节,给出了部分分词词典数据.表5是阈值为40%时按照字母序显示的集成词典命中的前100个多音节词.该词典总共包含590 481个词,而如此之多的单词的确出乎人们的意料.经过辨认不难发现越南语复合韵母的新旧拼写形式差异也增加了单词规模.例如表5中biên hoà和biên hòa就是这种原因的等义异形词,它们都表示“边和”这个越南地名.因此,可以通过编列复合韵母新旧拼写规则来进一步提高越南语分词词典的效率.
表5分词词典数据样例
Tab.5Data sample of word-segmentation dictionary

3 结论
研究了如何从大规模越南语文本文档中半监督构建分词词典,所提出的半监督集成构建算法充分利用了越南语连续多音节的高频共现.研究结果表明,采用动态提取词典的MM和RMM算法能够取得理想的结果.进一步的研究将关注其他知识对多音节词提取的影响,例如停用词、句法规则、语义上下文等.此外,为了进行越南语到汉语的有效处理,汉越词提取也是值得深入研究的有趣问题.同时希望将上述研究成果迁移到其他合适的亚洲语言,例如泰国语、日本语、汉语等.
[1] DINH Q T, LE H P, NGUYEN T M H, et al. Word segmentation of Vietnamese texts: a comparison of approaches [C] // Proceedings of the 6th International Conference on Language Resources and Evaluation. Marrakech, 2008: 1933-1936.
[2] TRUNG H L, ANH V L, DANG V H, et al. Recognizing and tagging Vietnamese words based on statistics and word order patterns [C] // Proceedings of the Advanced Methods for Computational Collective Intelligence. Berlin, 2013: 3-12.
[3] LIU W Y, LIN L. Probabilistic ensemble learning for Vietnamese word segmentation [C] // Proceedings of the 37th International ACM SIGIR Conference on Research and Development in Information Retrieval. Gold Coast, 2014: 931-934.
[4] LIU W Y, WANG L. How does dictionary size influence performance of Vietnamese word segmentation?[C] // Proceedings of the 10th International Conference on Language Resources and Evaluation. Portoro, 2016: 1079-1083.
[5] 王红蔚, 席红旗, 孔波. 一种新的半监督支持向量机[J]. 郑州大学学报(理学版), 2012, 44(3): 66-68.
[6] VLACHOS A. Evaluating unsupervised learning for natural language processing tasks [C] // Proceedings of the 1st Workshop on Unsupervised Learning in NLP. Edinburgh, 2011: 35-42.
[7] 姚冬冬, 袁方, 王煜, 等. 基于半监督DPMM的新闻话题检测[J]. 郑州大学学报(理学版), 2016, 48(3): 63-68.
[8] LIU W Y, WANG T. Online active multi-field learning for efficient email spam filtering [J]. Knowledge and information systems, 2012, 33(1): 117-136.
[9] KANARIS I, KANARIS K, HOUVARDAS I, et al. Words versus character n-grams for anti-spam filtering [J]. International journal on artificial intelligence tools, 2007, 16(6): 1047-1067.
[10] LIU W Y, WANG L, YI M Z. Power law for text categorization [C] // Proceedings of the 12th National Conference on Computational Linguistics. Suzhou, 2013: 131-143.
[11] SPROAT R, EMERSON T. The first international Chinese word segmentation bakeoff [C] // Proceedings of the 2nd SIGHAN Workshop on Chinese Language Processing. Sapporo, 2003: 133-143.
[12] DIETTERICH T G. Ensemble methods in machine learning [C] // Proceedings of the 1st International Workshop on Multiple Classifier Systems. Cagliari, 2000: 1-15.
猜你喜欢
环球时报(2022-09-15)2022-09-15
内江科技(2021年8期)2021-09-13
校园英语·月末(2021年13期)2021-03-15
计算机应用与软件(2019年12期)2019-12-12
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
亚太教育(2018年5期)2018-12-01
长江丛刊(2018年15期)2018-11-15
读者·校园版(2015年7期)2015-05-14
科技视界(2014年33期)2014-08-15
