
基于稀疏学习与显著性的人脸识别方法研究
2018-03-02 09:23孔英会尹紫薇车辚辚
计算机工程 2018年2期
孔英会,尹紫薇,车辚辚
(华北电力大学 电子与通信工程系,河北 保定 071003)
0 概述
人脸识别作为身份识别的重要技术之一,已成为模式识别和计算机视觉领域研究的热点[1]。传统人脸识别算法在受约束简单环境下可得到非常好的识别效果,但在无约束复杂环境下的识别性能急剧下降。人脸识别包含人脸检测、预处理、关键特征提取及识别分类,其中特征提取是识别技术中的重要环节[2],提取在各影响因素下都具鲁棒性和代表性且易于分类识别的特征是人脸识别需要解决的关键问题。
由神经系统的研究可知,人类的视觉感知系统在执行视觉任务时仅有小部分的神经元细胞进入到工作激活状态。文献[3]提出稀疏编码方法对生物视觉系统进行模拟。类似于Gabor[4]滤波器,利用稀疏编码方法[5]得到的特征提取滤波器也是多尺度多方向的,但该滤波器不是人为设定参数,而是通过训练集图像学习得到的,并可自适应调整,提取人脸图像的空间结构信息,捕获图像中的高阶相关结构。同时由于稀疏编码自身的特点,可以克服传统人脸识别在不利环境(如表情变化、半遮挡、图像加噪等)中的影响,提取到的特征能更好地用于识别。局部二值模式(Local Binary Pattern,LBP)[6]提取人脸局部细节纹理特征,对较小姿态及光照改变具有较强的鲁棒性,因此,将稀疏编码提取到的特征融合后再进行LBP滤波可突出图像的纹理特性。
人脸图像的不同区域含有不同的信息量,在人脸识别中也具有不同的重要性。人眼在复杂环境下能快速捕获关键信息,这是依靠视觉选择注意机制[7]。文献[8]提出了显著图的概念,区别对待图像的不同区域,增强重要区域的作用,同时弱化其他区域的作用[9]。
本文模拟视觉选择机制,对经过LBP滤波的融合特征进一步构造显著图,突出重要特征对于人脸识别的贡献,从而在保留稀疏编码特征的图像空间变化表征能力基础上,增强其全局特征表征能力。
1 设计思想
本文方法的整体流程如图1所示,包括预处理、特征提取及融合、滤波、构造显著图与分类等部分,主要工作包括:1)依据多分辨率理论对输入人脸样本进行预处理;2)稀疏编码算法构造滤波器提取人脸特征;3)图像的LBP滤波;4)显著图的构造;5)分类识别。

图1 本文方法整体流程
2 稀疏编码特征提取与滤波
2.1 预处理
多分辨率理论与多分辨率下的信号表示和分析有关,图像金字塔是以多分辨率理论来解释图像的一种结构,在一种分辨率下不易被提取的特征在其他分辨率下可能较容易被提取[10]。本文将每张图片处理成多尺度来构造图像金字塔。首先将输入图片灰度化,大小统一处理成80×80像素,然后以1/21/2为系数对图片进行缩放构造多尺度图像金字塔。多尺度处理会直接使图片的数量加倍运算复杂度增大,因此,选择合适的尺度数也尤其重要。实验分析得到,在该尺寸下,将图像处理成5个尺度时识别率较高且实时性较好。
2.2 稀疏编码算法提取特征
2.2.1 稀疏编码

X=DA
(1)
自然图像X已确定,其字典D可通过求解以下最优化问题解决:
(2)
其中,λ是平衡稀疏度的参数。
采用K-SVD[12]方法求解式(2),具体过程如下:
1)初始化标准化D。
2)固定D,更新A。采用正交匹配追踪[13]算法求解优化问题,获得每个样本信号xi的稀疏表示向量ai。
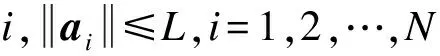
(3)
3)固定A,更新D。在更新字典同时更新每个基向量。设定移除第k个基向量后的误差矩阵为Ik:
(4)

4)在步骤2)~步骤3)间不断计算直到共同收敛得到图像稀疏表示A和字典D。
2.2.2 特征提取及融合
稀疏编码算法提取人脸特征的具体过程是首先对训练集人脸图像标准化并切割成大小一致的图像块,将图像块利用字典学习算法得到过完备字典D和稀疏表示A。在测试阶段利用训练出的字典D和稀疏编码算法得到测试集的稀疏表示A′(即稀疏编码特征)。训练原始图片对应生成的过完备字典如图2所示。

图2 原图片对应生成的过完备字典
过完备字典D可看作由多组基函数组成的特征提取滤波器。通过人脸图像学习得到的基函数既描述了人脸共有的空间结构又对空间频率具有选择性,但直接训练得到的数量非常庞大,若全用于特征提取运算复杂度会急剧增大。由于部分边缘结构信息就能表示人脸的整体类别特性,且光照改变对图片低频部分影响较大,因此舍弃具备低通特性选择具备带通特性的基函数。保留重构能量Ei最大的前K个基函数构造提取特征的滤波器D′。重构能量Ei的表达式为:
(5)
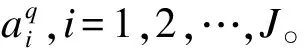
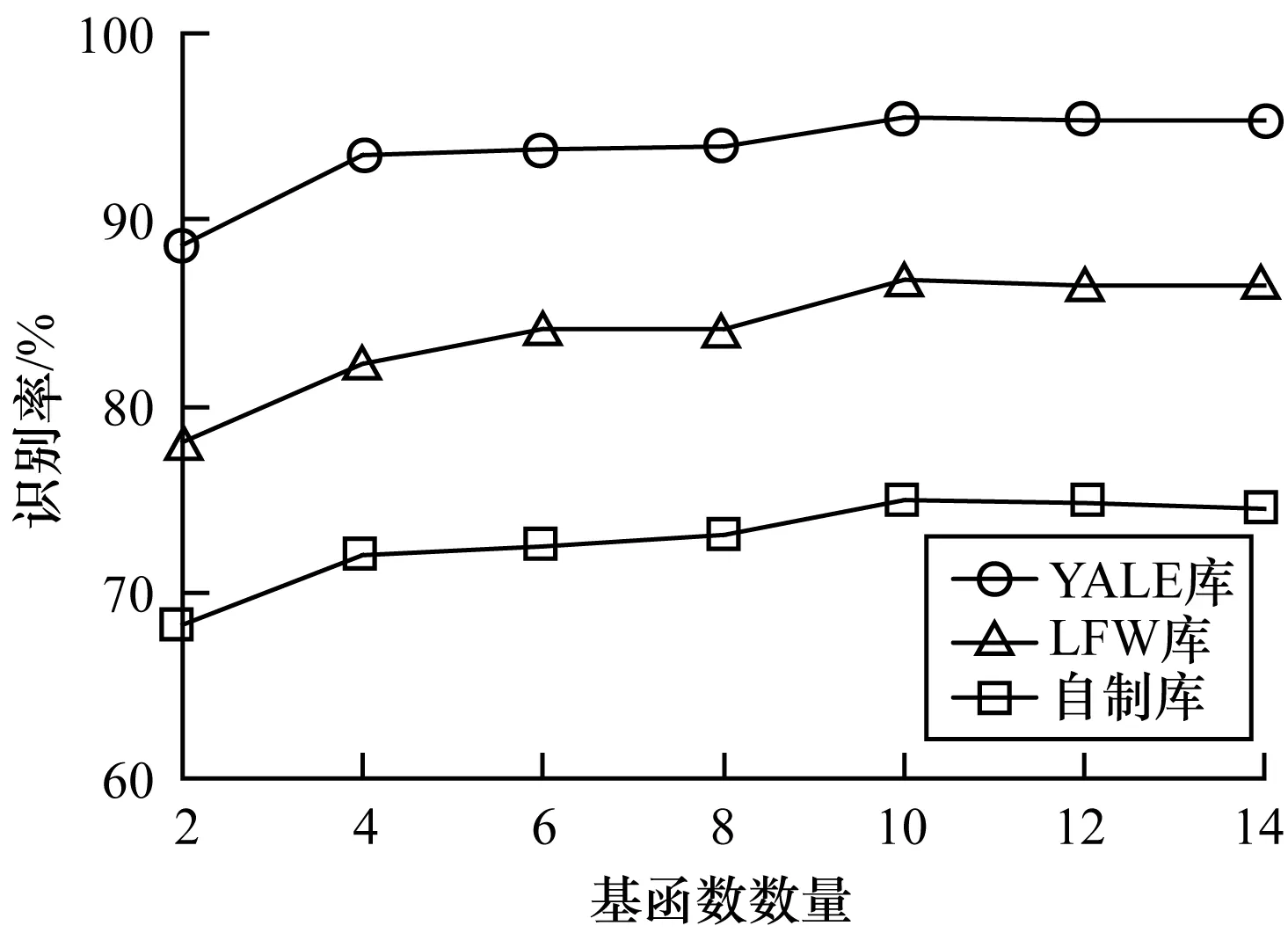
图3 不同基函数数量对应的识别率
由图3可以看出,在基函数数量为10时识别率达到最大,之后基本保持不变。但时间开销会随着基函数个数增多而增加。因此,本文选定基函数数量K=10,此时滤波器性能最优且时间开销小。本文方法得到的特征提取滤波器时频图如图4所示。
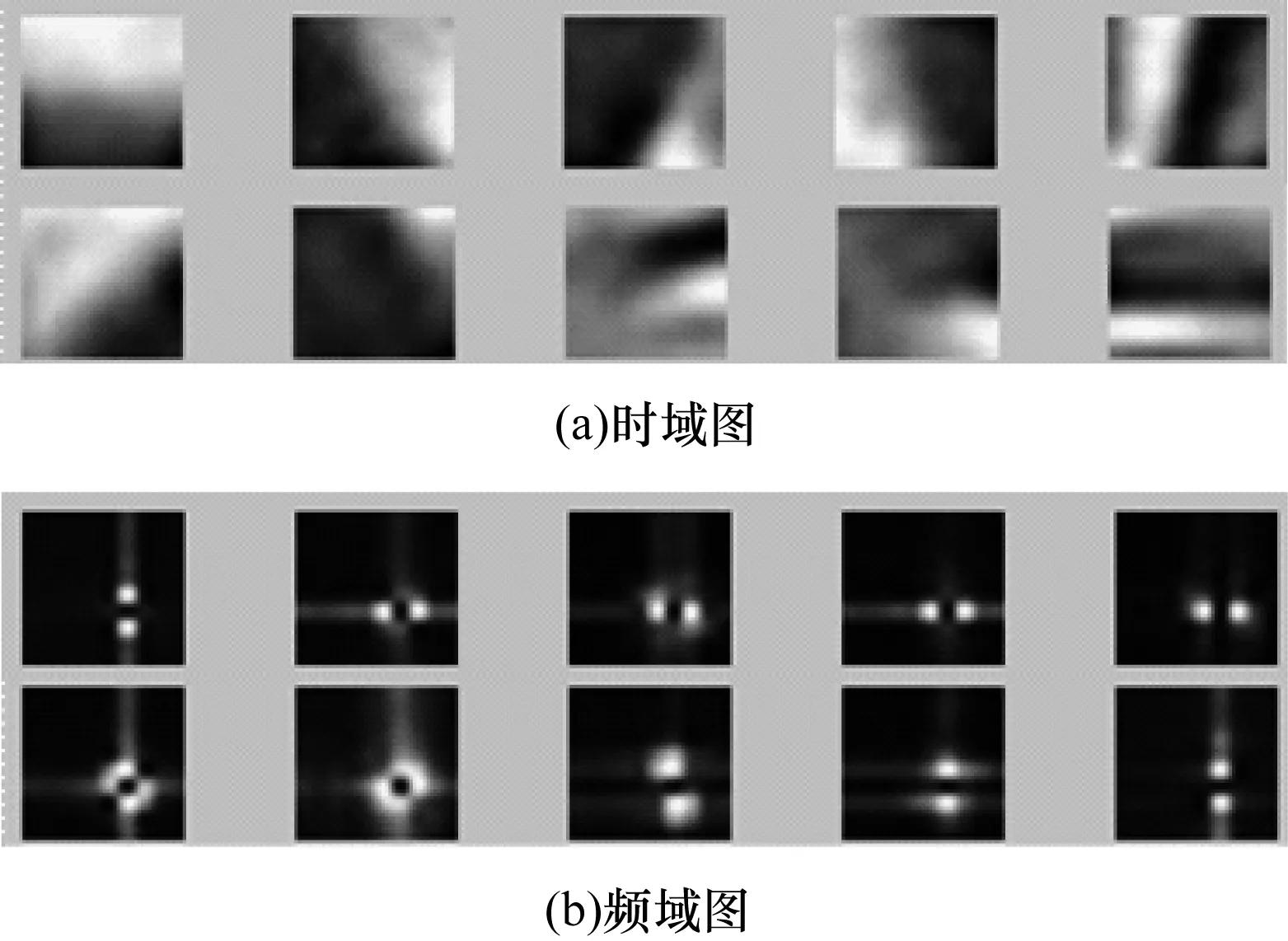
图4 滤波器时频图

(6)
稀疏学习得到特征及融合后的特征如图6所示。

图5 5尺度10方向图像特征

图6 融合后的特征
2.2.3 LBP滤波
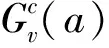
(7)
LBP滤波结果如图7所示。可以看出,图像经过LBP滤波后的细节纹理特征更加突出。

图7 LBP滤波结果
3 融合显著图构造
3.1 视觉显著理论
人的视觉感知系统存在2种注意机制:自顶向下和自底向上的注意选择。自顶向下的注意选择与人脑高级功能相关,而自底向上的注意选择直接依据接收到的数据信号。目前主要集中于自底向上的注意选择研究。显著图的构造有多种不同的方法,其中影响最大的为1998年Itti等人提出的视觉注意计算模型。但该模型只保留了最终由注意机制选出的部分显著区域,舍弃了相对不显著的人脸区域,因此,不能描述整体的人脸结构。而人脸的全局信息在人脸识别过程中是非常重要的,因此,该模型在人脸识别中是不适用的。本文方法构造的显著图只是对显著区域进行加强,对不显著区域特征进行减弱,没有丢弃任何区域,保留了人脸结构的整体性。
3.2 显著图构造
直方图统计可以很好地描述图像的整体特征,得到图像的联合分布,从而反映特征的重要程度。但是直接对整张图片进行直方图统计会使许多细节结构信息丢失,因此,将得到的融合图像进一步划分为多个大小一致且互不重叠的矩形子块分别进行直方图统计。划分的小块直方图更好地包括了周围的区域信息,不仅能体现细微的局部变化,还能保留整体的改变。实验证明,将每个融合图像划分为8×8时效果最好。具体公式为:

i=0,1,…,p-1;j=0,1,…,q-1
(8)
其中,Hi,j为每块的直方图统计结果,p=256,q=64。连接计算得到的图像小块直方图,反映了这一局部区域内整体灰度变化。由直方图统计结果得到图像每个尺度上所有特征的联合概率PL(x,y),进而得到香农自信息量QL(x,y)。
QL(x,y)=-lb(PL(x,y)),L=1,2,…,5
(9)
香农自信息量不仅反映图像信息量的分布,还反映图像的注意显著性分布。以此信息量得到的最终显著图与Itti显著图的比较如图8所示。其中:第1列为原图;第2列为Itti显著图;第3列位本文方法得到的显著图。Itti显著图中颜色越亮表示显著性越强,本文显著图中颜色越深表示该区域信息量越大。可以看出,Itti显著图是由颜色、亮度、方向等的对比度生成的,得到的显著区域可能会有较大偏差,对后续的识别结果造成影响。本文方法生成的显著图在人的眉毛、眼睛、鼻子、嘴巴以及脸颊轮廓处的颜色较深,表明这些区域对于人脸识别的贡献较大,与人自身感知一致,因此,本文方法生成的的显著图更有利于人脸识别。
图8 不同状态下生成的显著图比较
将最终得到的特征归一化处理得到人脸不变特征向量,再经过PCA降维处理送入分类器进行分类识别。
4 实验与结果分析
实验采用YALE、LFW标准人脸库。同时,为进一步验证本文方法适用于实际场景中,从视频中截取部分帧图像构成数据库来进行实验。
4.1 YALE和FERET人脸库实验
YALE人脸库有15个人,每人11幅图像。每人11幅图像。包含6种表情,3种不同程度的光照,并有是否佩戴眼镜的区别。YALE库中某一人的图像样本如图9(a)所示。将该数据库划分为不同情况下的子集进行实验,其中标准集作为训练集,光照集、表情集、遮挡集作为测试集,并任选每人3张图像构成训练集,其余每人8张用来测试构成综合集。
FERET人脸库包含1 199个人的14 051幅图像。对于同一人其图像主要包含光照、姿态、表情变化等,FERET库中某人的图像样本如图9(b)所示。随机抽出库中200个人的7张图片,将其分成标准集、光照集、表情集、姿态集和综合集来进行实验。
用6种不同方法对2个标准库进行实验,结果如表1和表2所示。可以看出,本文方法在各因素影响下较其他方法识别率都有较大提高,加入显著图后优势明显,且在YALE库中的识别率可达到100%,在FERET库中的识别率也达到99.2%。

表1 YALE库图片识别率比较 %
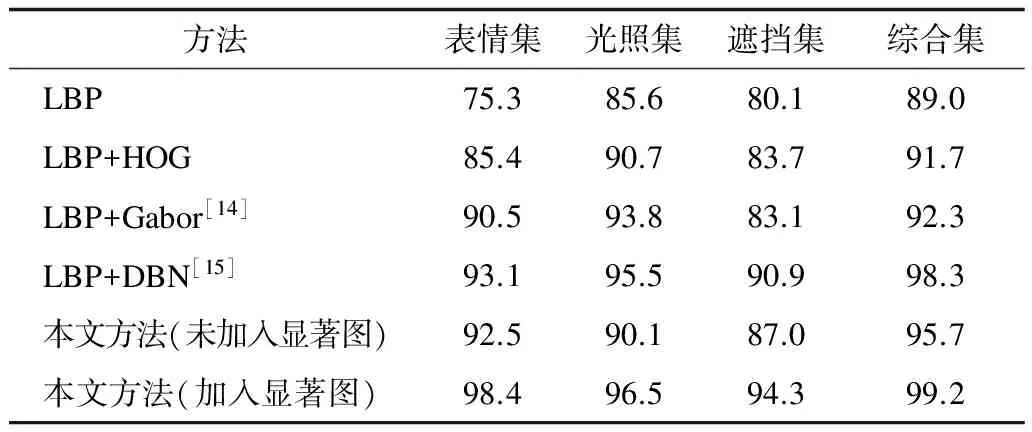
表2 FERET库图片识别率比较 %
4.2 LFW人脸库实验
LFW库中的图片比较接近于实际情况,包含5 749个人的13 233幅图片。LFW一般用于复杂环境下的人脸识别,该库可以表现实际环境中人脸图像的改变,如光照、表情、性别、姿态、遮挡、性别、背景等变化。图10为LFW库的人脸图片示例。

图10 LFW 库的人脸图片示例
将LFW库分别用6种方法进行实验,结果如表3所示。可以看出,加入显著图的方法下LFW库识别率可达到95.8%,相较其他5种方法(由上向下)识别率分别提高12.0%、5.5%、10.5%、10.8%及2.4%。

表3 LFW库识别率比较 %
4.3 自制视频帧人脸库实验
视频人脸识别是目前研究的热点及难点,视频的限制因素较多,如目标距离远分辨率低等,且视频中人的表情姿态改变更加复杂。本实验图片包含10个人,给每人录制一段视频,并截取每人任意15帧图像构成无约束图像库进行人脸识别,部分图像样本如图11所示。

图11 视频帧部分图片及对应处理后的图像
该库也使用上述6种方法进行实验,结果如表4所示。

表4 自制视频帧人脸库识别率 %
自制图片库由于拍摄手机像素较低且与人距离较远、姿态表情改变严重等因素,识别率较标准库有一定差距。从表4可以看出,本文方法在该库中也取得了很好效果,识别率达到85.0%。使用深度信念网络方法的识别率虽达到84.7%,但其消耗的总时间为1 811 s,而本文方法仅为33 s,时间开销更小。综合以上实验可得出,本文方法提取的特征在复杂环境下有着更好的鲁棒性、不变性和代表性,优于传统特征提取方法。
5 结束语
本文提出一种基于稀疏编码学习与显著性的人脸识别方法。首先利用稀疏编码学习得到的基函数构造滤波器,提取多尺度多方向人脸特征,该特征包含人脸的外观轮廓结构信息。然后利用LBP算子进行滤波保留图像的局部细节纹理特征。最后根据显著性理论对该特征构造显著图,增强其全局特征表征能力,突出重要区域对于人脸识别的贡献。实验结果表明,本文方法对于光照、遮挡、表情变化及姿态改变等影响因素都有较强的鲁棒性,适用于复杂环境下的人脸识别。
[1] 魏明俊,许道云,徐梦珂.基于均方差度量分块的自动加权稀疏表示算法[J].计算机工程,2017,43(5):174-178,184.
[2] LOWE D G.Distinctive Image Features from Scale-invariant Keypoints[J].International Journal of Computer Vision,2004,60(2):91-110.
[3] OLSHAUSEN B A,FIELD D J.Emergence of Simple-cell Receptive Field Properties by Learning a Sparse Code for Natural Images[J].Nature,1996,381(6853):607-609.
[4] 林克正.基于Gabor特征的全局加权稀疏表示[J].哈尔滨理工大学学报,2016,21(1):40-44.
[5] 杜 兴,龚卫国,张 睿.一种仿生的人脸不变特征提取方法[J].仪器仪表学报,2011,32(4):813-818.
[6] 孙 玉,刘贵全.基于HoG与LBP特征的人脸识别方法[J].计算机工程,2015,41(9):205-208.
[7] 孙晓帅,姚鸿勋.视觉注意与显著性计算综述[J].智能计算机与应用,2014(5):14-18.
[8] KOCH C,ULLMAN S.Shifts in Selective Visual Attention:Towards the Underlying Neural Circuitry[J].Human Neurobiology,1985,4(4):219-245.
[9] 张 焱,张志龙,沈振康,等.基于动态显著性特征的粒子滤波多目标跟踪算法[J].电子学报,2008,36(12):2306-2311.
[10] 赵仲秋,季海峰,高 隽.基于稀疏编码多尺度空间潜在语义分析的图像分类[J].计算机学报,2014,37(6):1251-1260.
[11] GUHA T,WARD R K.Learning Spare Representations for Human Action Recognition[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2012,34(8):1576-1588.
[12] RAJA H.Cloud K-SVD:A Collaborative Dictionary Learning Algorithm for Big,Distributed Data[J].IEEE Transactions on Signal Processing,2016,64(1):173-188.
[13] DETERME J F,LOUVEAUX J,JACQUES L,et al.Improving the Correlation Lower Bound for Simultaneous Orthogonal Matching Pursuit[J].IEEE Signal Processing Letters,2016,23(11):1642-1646.
[14] LIOR W,TAL H,YANIV T.Effective Unconstrained Face Recognition by Combining Multiple Descriptors and Learned Background Statistics[J].IEEE Pattern Analysis and Machine Intelligence,2011,33(10):1978-1990.
[15] 梁淑芬,刘银华,李立琛.基于LBP和深度学习的非限制条件下人脸识别算法[J].通信学报,2014,35(6):154-160.
猜你喜欢
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
电子制作(2019年15期)2019-08-27
中国听力语言康复科学杂志(2019年3期)2019-06-24
听力学及言语疾病杂志(2019年3期)2019-05-24
电子制作(2018年19期)2018-11-14
动漫星空(2018年9期)2018-10-26
中国交通信息化(2018年3期)2018-06-13
自动化学报(2017年11期)2017-04-04
中国交通信息化(2016年2期)2016-06-06
