
基于深度学习的视频近似拷贝检索
2018-02-27 03:06冯兆华朱允斌李卫强
计算机应用与软件 2018年1期
冯兆华 朱允斌 李卫强
1(复旦大学计算机科学技术学院 上海 201203) 2(上海视频技术与系统工程研究中心 上海 201203) 3(上海下一代广播电视网应用实验室有限公司 上海 200032)
0 引 言
随着科技的发展,视频数据总量飞速增长,人们希望能有类似以图搜图这种基于内容的搜索系统出现。
近年来,机器学习领域取得了许多令人瞩目的成就,其中深度卷积神经网络已经被广泛应用在图像分类、图像识别和图像检索等领域[1],将其应用在视频检索领域是很自然的想法。视频近似拷贝检测的第一步便是提取视频采样帧的特征,而深度卷积神经网络恰好能做到这一点。之后需要为提取出的特征值建立索引以加快搜索速度,这一点可以利用k-d树实现。
1 相关工作
从已有的图像拷贝检测以及视频近似拷贝检索的算法[2,8,11-12]来看,视频近似拷贝检测方法大都可分为三个主要步骤:提取采样帧的特征值、为视频库内视频的采样帧建立索引,以及检索和计算相似度。
在提取特征步骤,传统方法的做法是手动提取特征。例如,文献[2]以像素灰度的序数为依据,将画面分块汇总序数信息后作为特征值。这种特征值体积较小,且对亮度变化的处理能力强。但由于这种方法加入了图像的空间信息,使其对于裁剪、遮挡、水印等变化十分敏感,对这类近似拷贝的检测能力不足。
近年来,受到文献[3]等图像领域工作的启发,一些学者尝试利用深度学习进行视频近似拷贝检索,如文献[11-12]等。虽然这些工作使用的网络结构各不相同,但这类方法的总体思路都是将深度卷积神经网络中所有卷积层的状态汇总为一个向量,并使用主元分析等方法对其进行降维,以此作为视频帧特征值,进一步将帧特征汇总为视频特征。这类方法的缺点在于,需要汇总计算所有卷积层的状态,并进行额外的降维操作才能得到帧特征值。此外,为了进行后续的索引操作,还需要进一步由帧特征得到视频特征。
在建立索引步骤中,通过进行相似检索来从视频库中选出与查询视频相似的视频。现有算法包括大致可分为最近邻搜索、二分图匹配算法、使用树结构以及哈希结构等[7],目的都是为了提高搜索速度[6]。
2 系统实现
本系统可以划分为使用深度卷积神经网络提取采样帧的特征值、为视频库内视频的采样帧建立索引,以及检索并计算相似度三个部分。其中,提取特征和建立索引两个步骤是离线进行的,检索步骤为在线过程。
系统的设计目标是针对一个给定的输入视频,在离线视频库内找出与输入视频相似的视频并输出。系统应在保证高效的同时达到较高的精确度。
不同于现有基于深度学习的方法,本方法在特征提取与建立索引步骤加以创新。在特征提取阶段,本方法在网络中加入一个新的隐藏层,以隐藏层的状态作为帧特征值。这种做法能够在保证特征质量的前提下免于计算所有卷积层的状态,同时不需要进行额外的降维操作,大大加快了特征提取的速度。在建立索引阶段,本文使用了一种基于帧特征建立索引的方法,并提出了对应的置信度和视频相似度计算方法,从而在保证索引效果的前提下避免了计算视频特征值。
2.1 视频近似拷贝检索系统框架
本系统实现分为离线索引和在线检索两部分,在离线索引阶段,算法使用深度卷积神经网络提取出数据库中视频的采样帧的特征值,之后并采用k-d树为它们建立索引。在检索阶段,算法会采用同样的方法提取出输入查询视频的采样帧特征值,并用近似最近邻搜索的方法在索引库中找出与其相似的候选视频。在最后的相似度投票阶段,算法会计算出候所有选视频与查询视频的相似度,并按照相似度给出近似拷贝检索的结果。
具体实践时,针对一个输入视频,我们采用1秒取1帧的固定间隔进行视频采样,得到一组连续的采样帧。我们将这些采样帧作为原始输入视频的代表,并在其基础上进行特征提取、建立索引等操作。
2.2 深度卷积神经网络模型
利用深度卷积神经网络(CNN)提取视频帧特征想法的产生是受到图像检索领域的启发。最近的研究表明[3],深度卷积神经网络可以大幅提高多种视觉任务的效率,如物体检测、图像分类和分割等,这都是得益于深度卷积神经网络对丰富的图像中层表示强大的学习能力。为了降低CNN特征的维度,我们向典型的CNN模型中添加一个新的隐藏层,从中能够提取出特征向量作为图像中层特征[1,9]。在具体实现时,本算法使用文献[13]提出的预训练CNN模型,这种模型是基于大规模图片数据库ImageNet中的超过1 200 000张图片训练得到的,并将这些图片归为1 000个对象类。著名的CNN代码库Caffe中已经包含了这套模型,可以方便地使用。图1为网络框架图。
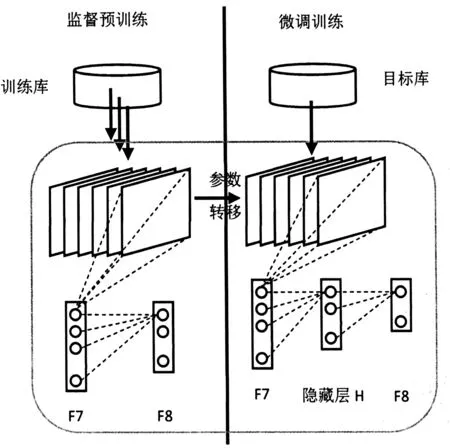
图1 深度卷积神经网络框架
2.3 特征提取
为了使用CNN提取视频帧特征,具体的做法是在CNN的F7和F8之间加入一个128节点的隐藏层H,其中的神经元状态用Sigmoid函数近似至{0, 1}。
深度卷积神经网络内的初始权值设定为从ImageNet数据库训练得来的权值,隐藏层H和最终层F8的权值被随机初始化,之后在目标库上进行微调训练。随着微调训练的进行,这些随机值逐渐变得更加适应监督深度学习[10],从而能够提取出视频帧特征。
训练完成后,将视频采样帧输入网络,隐藏层H的神经元状态就是我们需要的128维特征值。
2.4 使用k-d树为视频帧建立索引
k-d树是一种多维二叉查找树,主要用于存储关联性搜索所需的信息[4]。以往的视频近似拷贝检索算法很多都使用了LSH等哈希方法来建立索引,目的是为了快速剔除大量不相关的视频。但这类哈希方法只统计了视频是否加入候选,没有其他额外信息。与此相对地,利用k-d树进行最近邻搜索虽然速度稍慢,但可以在产生候选的同时附加一些额外的相似度信息,后续步骤可以以此为参考。
在建立索引时,只需将视频库内视频的采样帧特征值逐一加入k-d树即可。在执行近似检索时,利用所建立的k-d树对查询视频的每一帧特征执行一次最近邻(KNN)搜索,找出与其距离最近(换句话说,最为相似)的3个视频库中的视频帧并记录这三个视频帧所属的视频编号,将其交给后续的相似度计算步骤。
假设视频库中共有编号为0~m-1的m个视频,输入视频由n个采样帧f1,f2,…,fn表示,k-d树返回的f1,f2,…,fn的最近邻所属的视频编号分别为V11,V12,V13,V21,V22,…,Vn3∈[0,m-1]。本算法用p0,p1,…,pm-1来统计视频库中的m个视频作为最近邻搜索结果的次数,换句话说,p0,p1,…,pm-1初始值为0,之后遍历所有的Vij,其中的每一个都会使对应的pvij增加1。
最终,p0,p1,…,pm-1中存放了视频库中的m个视频作为最近邻搜索结果的次数,也即这些视频中的帧与查询视频中的帧相似的个数。不难想象,这些数字体现了其对应视频与输入视频的相似程度,数值越大,说明其对应视频与输入视频之间相似帧的数量越多,两个视频之间的相似程度也就越大。然而,这终究只是根据特征值进行近似最近邻搜索的结果,并不能完全准确地代表候选视频与输入视频之间的相似度,可以将其理解为候选视频与输入视频相似的可能性。为此,定义候选视频的置信度如下:
(1)
式中:1为输入视频的总长度。本算法将C0,C1,…,Cm按照降序进行排序,并选取其中数值最大的5个视频作为候选视频。
2.5 计算视频相似度
给定一个查询视频,前面的索引步骤筛选出了一些候选视频,成功地将近似视频的范围缩小至候选范围内。虽然这些候选视频与询问视频相似的概率很高,但并不是已经确定了它们和询问视频互为近似拷贝,因此需要进一步的检测以确定最终的近似拷贝检索结果。本算法采用的方法是逐对比较两个视频的特征值,用欧氏距离衡量两个特征值之间的距离,得到所有特征值之间的距离信息后以此计算候选视频与查询视频之间的相似度。
为了衡量候选视频与输入视频的相似度,对于由采样帧x1,x2,…,xm代表的视频Sx(x1,x2,…,xm)和由采样帧y1,y2,…,ym代表的视频Sy(y1,y2,…,yn),定义采样帧xi与yj之间的距离f(i,j)为:
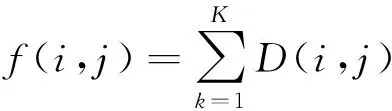
(2)
式中:D(i,j)为xi与yj之间的欧氏距离,H(xi,k)为xi的特征值的第k位:
(3)
从而,Sx与Sy的相似度定义为:
(4)
式中:d为查询视频与候选视频的视频长度差,k为参数。最终的WS值域在0到1之间。
最终,将所有候选的相似度由大到小排序,并选取其中与查询视频相似度大于特定阈值的候选作为最终的近似拷贝检索结果输出。在实际使用中,需要根据数据集情况、用户需求等因素调整、选取合理的阈值。
3 实验与评估
3.1 数据集
为验证算法的效果,我们使用TRECVID[5]中的IACC.1.tv10.training视频集作为数据集进行实验,其中包括大约3 200部公开的网络视频。我们从中选取1 000部互不重复的长度在3.6分钟左右的视频,总长度为3 616分钟,总大小约为14.3 GB。
3.2 实验方法
本次实验首先以选出的1 000部视频作为离线视频库,按照第二节所述的方法为其提取特征并建立索引。之后,从中随机选取100部视频,对它们进行亮度改变、加入字幕、裁切、缩放、旋转(90度和180度)、加入水印、抽帧(10帧),以及打乱时序操作,加上原始的100部视频,以此作为10组查询视频。
将10组查询视频输入系统进行视频近似拷贝检索,在0~1.5之间选取16组不同的置信度阈值T进行实验,得出候选后分别计算它们与查询视频的相似度,并选取相似度最高的视频作为系统输出。
本次实验运行在Ubuntu系统服务器上,CPU为i7-5960X 3.00 GHz,GPU为(4x) NVIDIA GeForce GTX TITAN X,内存总大小为125 GB。
最终运行效率方面,为1 000部总长度3 616分钟的视频建立索引总计耗时129分钟,耗时仅为视频总长度的3.57%;执行全部100次查询(总长度为361分钟)总计耗时13分钟,仅为查询视频长度的3.6%。索引文件大小为55.16 MB,仅为视频总大小的0.38%。
3.3 实验结果
实验结果表明,由于选取了特定的特征提取和建立索引方法,本系统对字幕、裁切、缩放、水印、抽帧及打乱时序这六类近似拷贝有较好的识别能力,而对亮度变化和旋转产生的近似拷贝不能很好地处理。实验的平均准确率与召回率如图2所示。
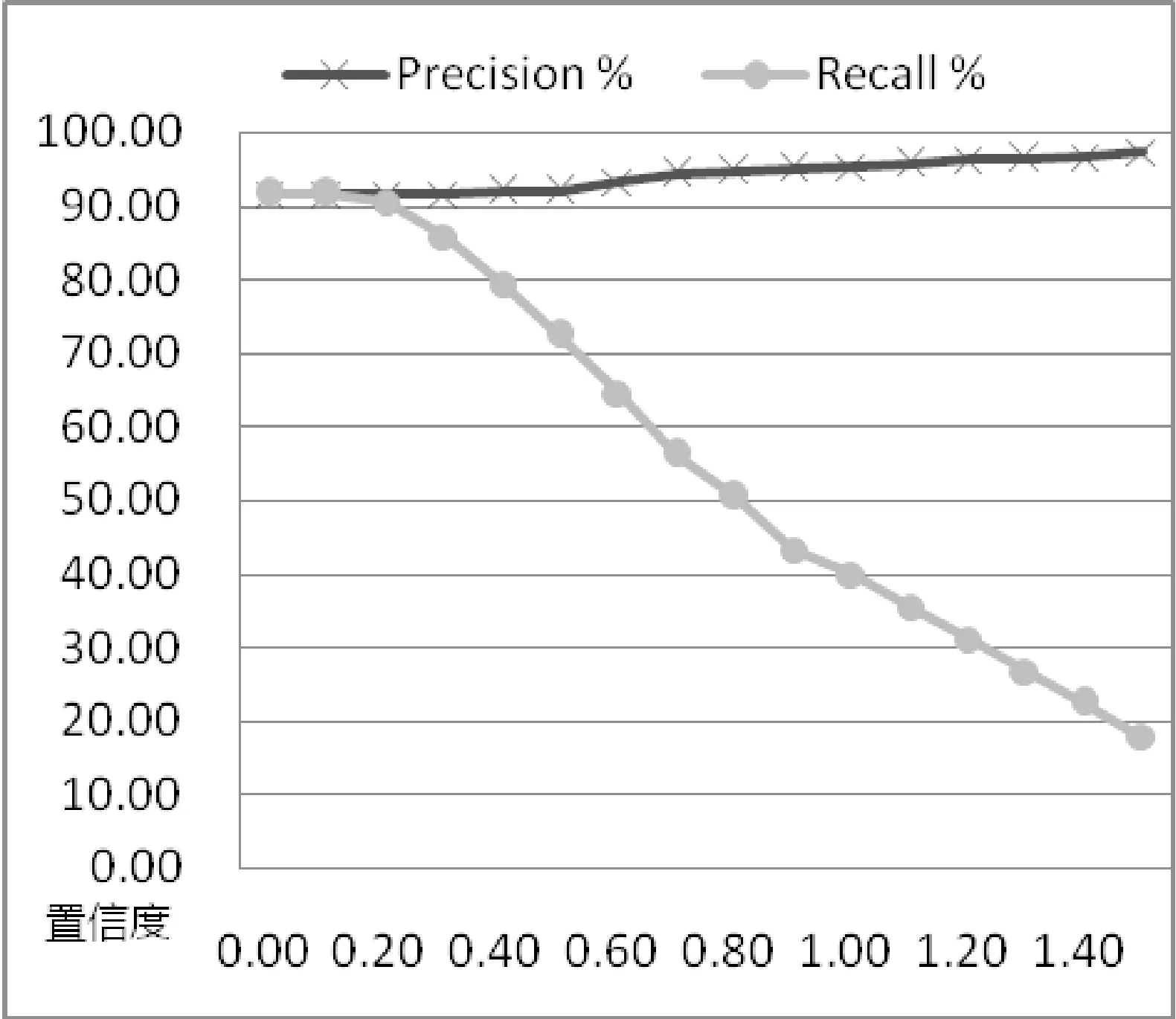
图2 算法的平均Precision-Recall
为了横向对比本算法的效果,本次实验在相同的数据集上运行了文献[11]中提出的方法,两次实验均选用最佳参数设置,实验结果如图3所示。
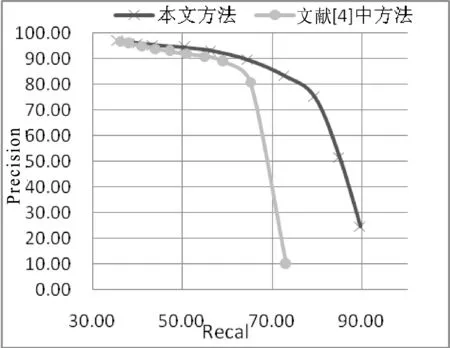
图3 两种算法的P-R对比
以上实验结果表明,本算法能够有效完成视频近似拷贝检索任务。这是由于本算法使用了合理的特征提取方法,通过在网络中加入隐藏层,算法得以快速提取出包含足够信息的特征值,避免了对网络卷积层的大量计算。之后通过k-d树为帧特征建立索引,算法得以快速找出与查询视频相似的视频。
此外,为了对比本算法与传统算法的效果,本次实验在相同的数据集上运行了文献[2]中提出的传统方法,实验结果如图4所示。
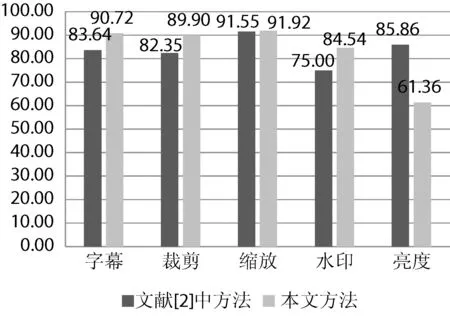
图4 五种情况的Precision对比(%)
从图中可以看出,本算法的综合表现优于文献[2]中的方法,仅对亮度变化等的处理能力不如文献[2]。如第一节所述,文献[2]的局限性在于它使用的是一种基于像素序数和空间信息的特征,使其能够较好地处理亮度变化,而对于水印、裁剪等局部空间变化的处理能力较差。
4 结 语
本文针对视频近似拷贝检测进行研究,使用深度学习方法提取特征,k-d树建立索引,计算输入视频和候选视频的相似度,得到按相似度排序的视频序列。
本文在公用数据集上对系统进行了一些实验与测试,并与已有方法进行了对比,验证了系统是有效且快速的,在视频近似拷贝检测领域具有实践和推广价值。
[1] Lin K,Yang H F,Hsiao J H,et al.Deep learning of binary hash codes for fast image retrieval[C]//Proceeding of The IEEE Conference on Computer Vision and Pattern Recognition (CVPR),2015:27-35.
[2] Paisitkriangkrai S,Mei T,Zhang J,et al.Clip-based hierarchical representation of near-duplicate video detection[J].International Journal of Computer Mathematics,2011,88(18):3817-3833.
[3] Ciresan D,Meier U,Schmidhuber J.Multi-column deep neural networks for image classification[C]//Proceeding of The IEEE Conference on Computer Vision and Pattern Recognition (CVPR),2012:3642-3649.
[4] Friedman J H,Bentley J L,Finkel R A.An algorithm for finding best matches in logarithmic expected time[J].ACM Transactions on Mathematical Software,1977,3(3):209-226.
[5] Over P,Awad G,Michel M,et al.Trecvid—An overview of the goals, tasks, data, evaluation mechanisms and metrics[C]//Proceeding of TRECVid,2014:1-52.
[6] Benevenuto F,Duarte F,Rodrigues T,et al.Understanding video interactions in Youtube[C]//Proceeding of the 16th ACM international conference on Multimedia,2008:761-764.
[7] Beygelzimer A,Kakade S,Langford J.Cover trees for nearest neighbor[C]//Proceeding of the 23th international conference on Machine learning (ICML),2006:97-104.
[8] Wan J,Wang D,Hoi S C H,et al.Deep learning for content-based image retrieval:A comprehensive study[C]//Proceeding of the 22nd ACM international conference on Multimedia,2014:157-166.
[9] Oquab M,Bottou L,Laptev I,et al.Learning and transferring mid-level image representations using convolutional neural networks[C]//Proceeding of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR),2014:1717-1724.
[10] Babenko A,Slesarev A,Chigorin A,et al.Neural codes for image retrieval[C]//European Conference on Computer Vision(ECCV),2014:584-599.
[11] Wang L,Bao Y,Li H J,et al.Compact CNN Based Video Representation for Efficient Video Copy Detection[C]//Proceeding of International Conference on Multimedia Modeling,2017:576-587.
[12] Kordopatis-Zilos G,Papadopoulos S,Patras L,et al.Near-Duplicate Video Retrieval by Aggregating Intermediate CNN Layers[C]//Proceeding of International Conference on Multimedia Modeling,2017:251-263.
[13] Krizhevsky A,Sutskever I,Hinton G.ImageNet classification with deep convolutional neural networks[C]//Proceeding of Neural Information Processing System 25,2012:1106-1114.
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23
烟台大学学报(自然科学与工程版)(2021年1期)2021-03-19
烟台大学学报(自然科学与工程版)(2020年1期)2020-02-08
科学与财富(2019年27期)2019-10-25
数码世界(2019年9期)2019-09-07
电子制作(2019年14期)2019-08-20
今日中国·中文版(2017年8期)2017-09-03
今日中国·中文版(2017年8期)2017-08-14
课程教育研究·新教师教学(2016年18期)2017-04-12
癌变·畸变·突变(2015年4期)2015-02-27
