
跨语言的项目级代码混淆方法
2018-02-27 03:06张润洁吴毅坚赵文耘
计算机应用与软件 2018年1期
张润洁 吴毅坚 赵文耘
1(复旦大学软件学院 上海 201203) 2(复旦大学计算机科学技术学院 上海 201203) 3(上海市数据科学重点实验室 上海 200433)
0 引 言
代码混淆是一种在保证代码功能性不变的前提下将原有代码转化为在形式上难于阅读和理解的代码变换技术,能够提升软件逆向工程的难度[1]。随着代码混淆研究的发展,混淆技术在代码保护强度和保护代价方面做到了很好的平衡,被应用到了数字水印[2]、版权保护[3]等很多实用领域。代码混淆器的发展也日趋成熟,Java混淆器ProGuard[4]、JavaScript混淆器JavaScript Obfuscator[13]等在工业界得到广泛应用。
目前,随着软件项目复杂性的提高,一个项目通常由多种语言一起编写,且不同类型代码间通常具有关联关系。例如在基于Struts2的 Web项目中,action的名称在前台JavaScript代码、Struts配置代码和后台Java代码之间必须保持一致。然而,传统的混淆方法通常只针对局部混淆,当混淆了一个或者部分子系统的代码后,可能造成混淆后的代码元素不再相互关联,导致整个软件系统无法组装运行。因此,为实现全局混淆,需要对关联代码进行特殊处理。目前通常采取人工设置混淆配置项的方式,逐一标识关联性代码元素的混淆方式。混淆人员需要花费大量精力处理源代码细节,且繁琐的配置项极易引入错误,造成引用程序集失效的问题,导致混淆后的项目无法正常运行。
本文设计了跨语言的代码元素及其关联关系的描述规则,其中定义统一代码模型,抽取代码元素信息,实现对不同代码元素的统一化描述。并提出关联规则的概念,作为代码关联关系的统一描述规则,结合正则模式匹配技术,获取项目代码关联关系。在此基础上,提出跨语言的项目级代码混淆方法,实现对同一项目中不同类型代码的代码元素的统一化混淆以及代码关联性的自动化维护,保证混淆前后代码关联性的一致,提高了项目整体混淆效率和混淆程度。
1 跨语言的项目级代码混淆方法
1.1 研究动机
本文以业界常用的基于Struts2框架的Web项目为例,前后台代码与配置代码三者间存在一定的关联关系。例如在前台JS代码、Struts配置代码和后台Java代码中表示Action的名称的代码元素是相互关联保持一致的,如图1所示。
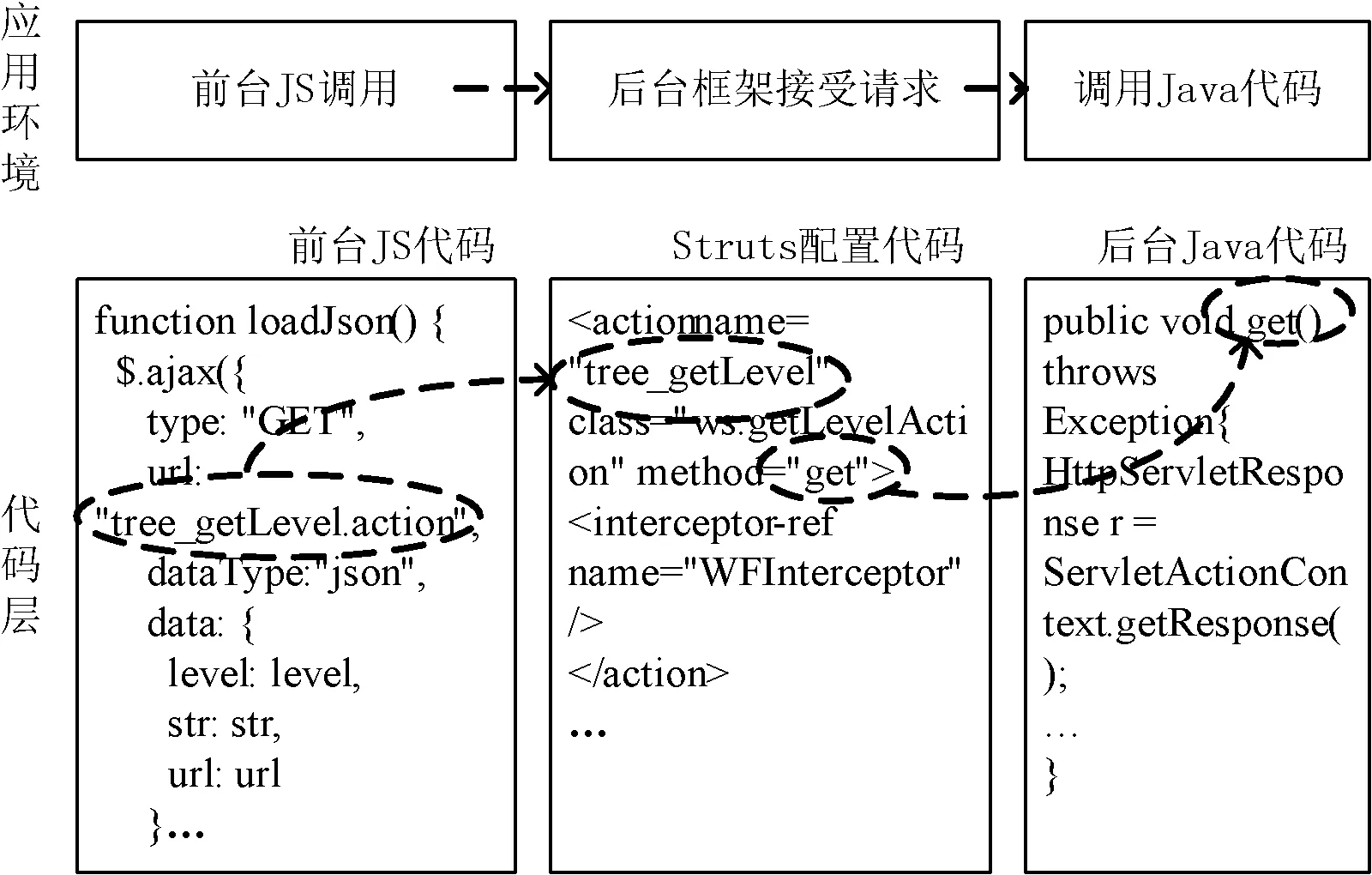
图1 Struts2项目代码元素关联性示例
现有混淆方法一般无法深度混淆前后台交互的Action名称。例如,当混淆方法对后台Java代码的方法名进行混淆后,仍然无法更改Struts2框架的配置文件中存在的方法名,此时前台发送的方法调用请求按照配置文件中的映射规则,在相应的Java文件中找不到相应的方法,从而产生错误。另外,由于前台代码中的字符串通常以明文形式存在,而Action是Struts2中是非常重要的组成部分,因此,为了更好地保护软件产品的利益,需要混淆能够反映代码的逻辑信息的Action名称,提升软件保护的门槛。
针对上述问题,我们提出了跨语言的项目级代码混淆方法,设计了代码元素及其关联关系的描述规则,对不同类型代码中的各类代码元素进行统一化的描述。通过获取项目代码关联关系,将相互关联并需要一起混淆的代码元素梳理在一起,解决了现有混淆方法易造成的混淆后代码关联性丢失问题。
1.2 跨语言的项目级代码混淆方法过程概述
跨语言的项目级代码混淆方法过程,如图2所示。
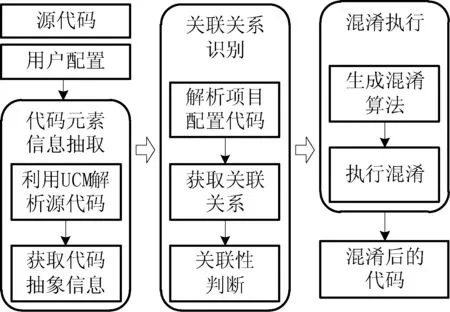
图2 跨语言的项目级代码混淆方法过程示意图
主要包括以下三个步骤:
(1) 代码元素信息抽取。以项目程序源代码和用户配置文件作为输入元素,用户配置文件信息指明源代码中待混淆代码元素的所属文件类型、代码文件范围、代码元素类型等信息。利用本文定义的描述不同类型代码中各类代码元素的统一代码模型UCM(Unified Code Model)在程序解析工具的支持下分析匹配源代码,将不同的代码元素转换成统一的程序抽象形式,为后续代码关联关系的获取以及混淆执行提供了统一形式的输入元素。
(2) 关联关系识别。本文定义了描述项目代码映射规则的关联规则CR(Connection Rule),利用正则匹配技术,使用关联规则作为匹配模式串对项目配置文件进行模式匹配,获取项目代码关联关系,依据项目关联关系判定代码元素的关联性,将相互关联的需要一起混淆的代码元素梳理在一起。
(3) 混淆执行。利用关联关系识别步骤中得到的项目关联关系列表,以保持混淆后代码关联性为前提生成混淆算法。依据代码元素的特征描述信息如代码文件类型、代码元素类型、代码元素名称等,调用相应的程序修改方法,执行混淆,最终得到混淆后的项目代码。
1.3 跨语言的项目级代码混淆方法设计与实现
1.3.1 统一代码模型
本文定义了描述不同类型代码中各类代码元素的统一代码模型(UCM),如图3所示。其中,Code Type表示代码元素类,用于定义不同类型的代码元素,由不少于一个的Code Element构成。Code Element代表一种名称确定的代码元素,并包含多个具体实例Instance。Instance对代码元素的名称、起始标志、结束标志以及源代码文件路径进行了明确的定义,用于描述每一个代码元素的具体存在信息。Code Pair表示关联代码元素对,用于定义一对相互关联的代码元素,每个Code Pair由两个Code Element构成。
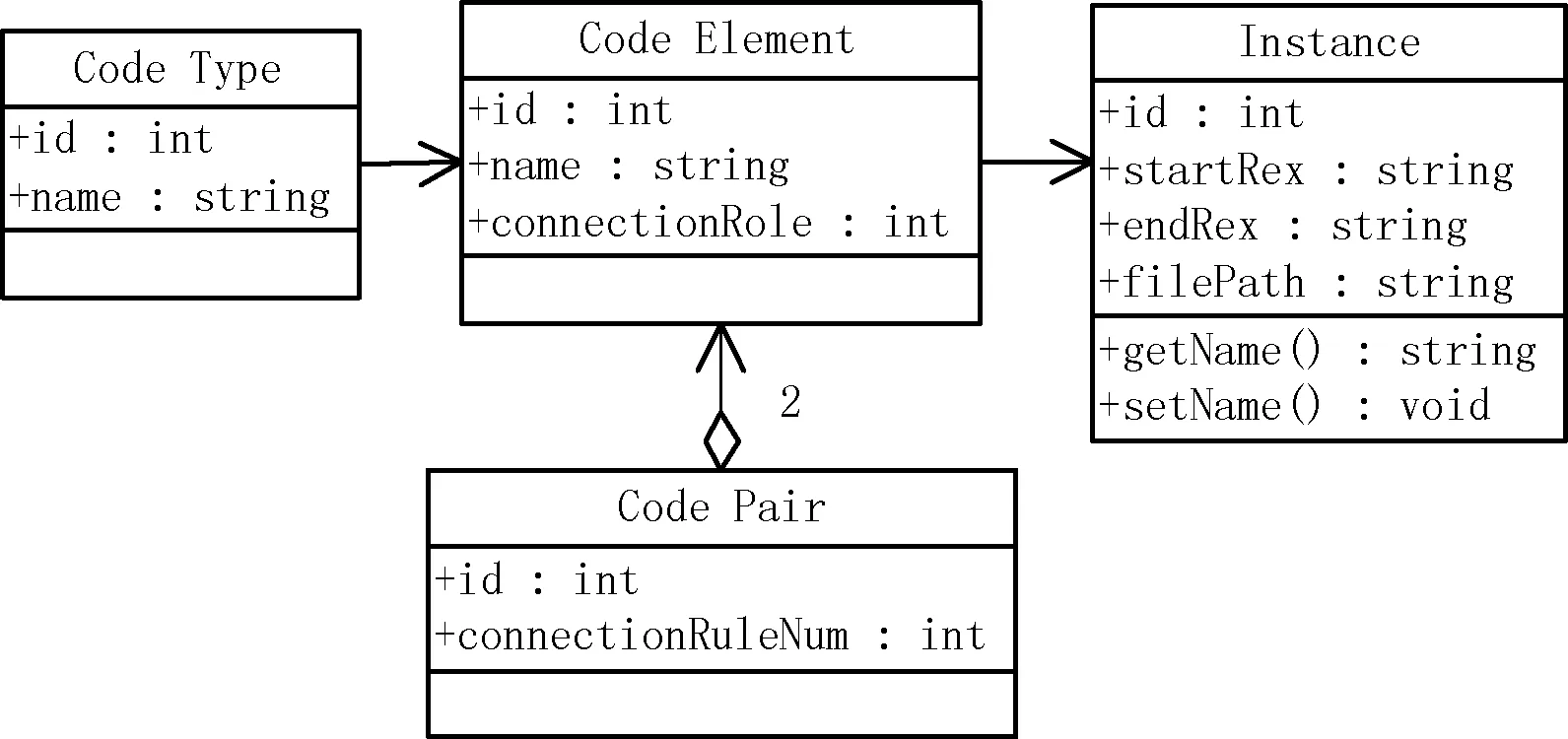
图3 统一代码模型
1.3.2 代码元素信息抽取
由于统一代码模型(UCM)中包含了准确描述每一个代码元素所必须的属性特征。本文利用统一代码模型对软件项目中具体的源代码进行分析以及匹配,从中抽取代码元素在源代码中具体的属性信息,从而将同一项目中多样化的代码元素转换为统一表示形式,为后续获取代码元素间的关联关系以及跨语言的混淆算法实施提供了统一的代码元素对象。例如,我们对基于Struts2框架的Web项目中JavaScript代码的Action名称,Class代码中的方法名以及struts.xml文件中的Action名称和方法名进行信息抽取,代码元素信息抽取结果如图4所示。另外,分析源代码的过程需要程序解析技术的支持,我们开发了相应的程序解析工具,目前支持Class、JavaScript以及XML、JSP、HTML等各类文本文件类型的源代码文件。
1.3.3 关联规则
关联规则(CR)是项目代码关联关系的统一描述规则,其完整文本模式描述称为Pattern,代表关联规则整体的文本模式,由多个子模式(Sub_pattern)组成。Sub_pattern代表子文本模式,Sub_pattern之间相互独立,独立用“#”表示,如图5所示。

图5 关联规则
CR的完整性定义为:CR={P,FQ,FS,FL,FT,FH,FR,BQ,BS,BL,BT,BH,BR},CR各组成元素的名称及定义如表1所示。前部元素与后部元素为关联关系所描述的两个关联代码对象,例如FS和BS分别为一条关联规则中前部元素全称与后部元素全称的文本模式描述。利用正则表达式[14]描述文本模式,CR各组成元素均为正则表达式集合,这源于对网络安全监测领域经常利用正则表达描述攻击特征[15]的借鉴。此外,以基于Struts2框架的Web项目为例,Struts2示例列给出符合框架代码映射规则的CR内容。
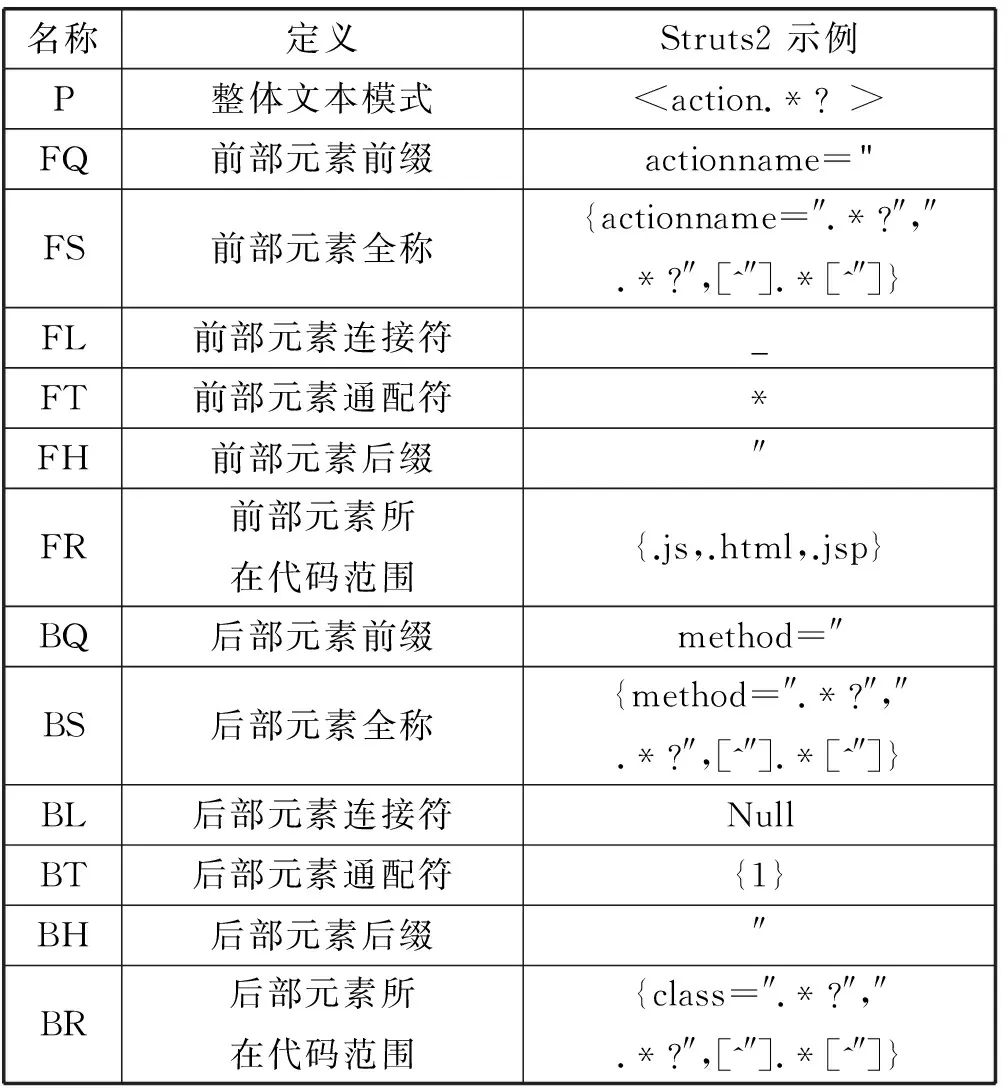
表1 关联规则组成元素
1.3.4 关联关系识别
本文利用正则匹配技术,使用关联规则作为模式串对项目配置文件进行过滤,匹配结果即为项目代码关联关系列表。当关联关系包含通配符时,需要进一步明确代码间的映射关系。我们利用包含通配符的关联关系构建模式串,正则匹配代码元素抽象信息,获取代码元素间明确的对应关系。例如,利用表1中Struts2示例内容解析项目配置文件struts.xml中图6所示代码片段,得到图6关联关系编号1,即代码类型为js、html或jsp且名称为“one_*”的前部元素与代码文件名为“action.getAction”的后部元素关联。完善后得到图6关联关系编号2,确定了名称“one_copy”的前部代码元素与名称为“copy”后部代码元素关联。

图6 关联关系获取示意图
最后,利用关联关系信息分别对前部和后部代码元素进行匹配,符合关联关系信息描述的代码元素即为关联性代码元素。在关联性代码元素中,前部元素与后部元素通过所匹配的关联关系条目编号关联在一起,并在后续的代码混淆过程中一起混淆,从而实现关联代码的混淆联动。
1.3.5 混淆执行
混淆算法依赖于完善后的关联关系列表,利用列表中关联关系条目的位置信息替换具有实际意义的明文信息,使得混淆后代码元素人眼难辨而机器可识。同时,依据项目关联规则对代码元素名称的特征描述,获取代码元素混淆后的名称格式,使用关联代码元素对具有的相同位置信息作为名称内容,生成混淆后的代码元素名称,保证混淆前后代码元素关联性一致。例如,图6关联关系编号2包含了前部元素“one_copy”与后部元素“copy”关联信息,使用该条关联信息在关联关系列表中的位置信息替换明文信息后,前部元素“one_copy”被混淆成“A00003_S00006”, 后部元素“copy”被混淆成“S0006”,其中数字3和数字6均与该关联信息条目在关联关系列表中的位置有关。
最后在明确了混淆算法的前提下,根据代码元素的具体属性特征,如所属文件类型、代码元素类型等,调用相应的程序修改方法,执行混淆。例如,利用UCM对图1示例中前台JS代码的Action名称元素,后台Java代码的方法名元素以及Struts配置代码元素进行信息抽取,经关联关系识别和混淆执行后,混淆结果如图7所示。其中前台JS代码的Action名称元素 “tree_getLevel”被混淆成“A00001”,后台Java代码方法名元素“get”被混淆成 “S00001”,通过混淆后的Struts配置代码保持了代码元素间的关联关系。
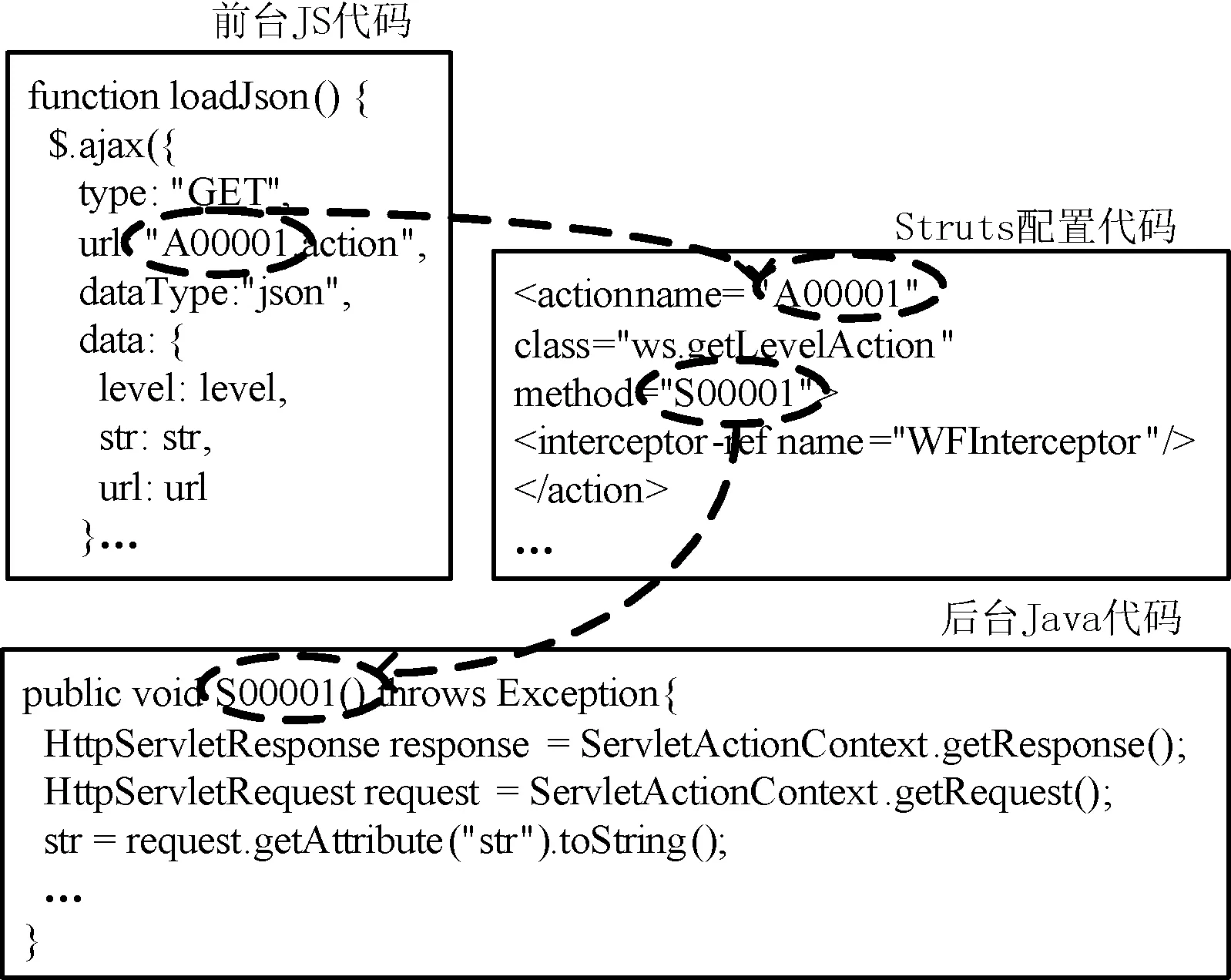
图7 混淆后Struts2项目代码元素关联关系示例
2 实 验
2.1 工具实现
基于本文方法,研发了跨语言的项目级代码混淆工具。混淆工具依据用户配置文件对项目中不同类型代码的代码元素建模,获取项目代码关联关系,生成混淆算法,完成关联性代码元素的统一混淆并在混淆过程中维护了代码关联关系,最终得到混淆后可正常运行的项目代码。
2.2 实验及评价
实验选取两个基于Struts2框架的实际Web项目源程序作为实验对象,分别对这两个项目进行混淆实验,实验设置信息如表2所示。实验中,混淆人员通过用户配置文件描述源代码具体信息,运行工具进行代码混淆。本文分别对各组实验的工具运行时间,混淆前后项目程序体积变化情况,被混淆代码元素的数量和名称变换情况进行了统计。从混淆方法的可行性及有效性两个方面分析实验结果,最后对本文混淆方法的局限性进行说明。
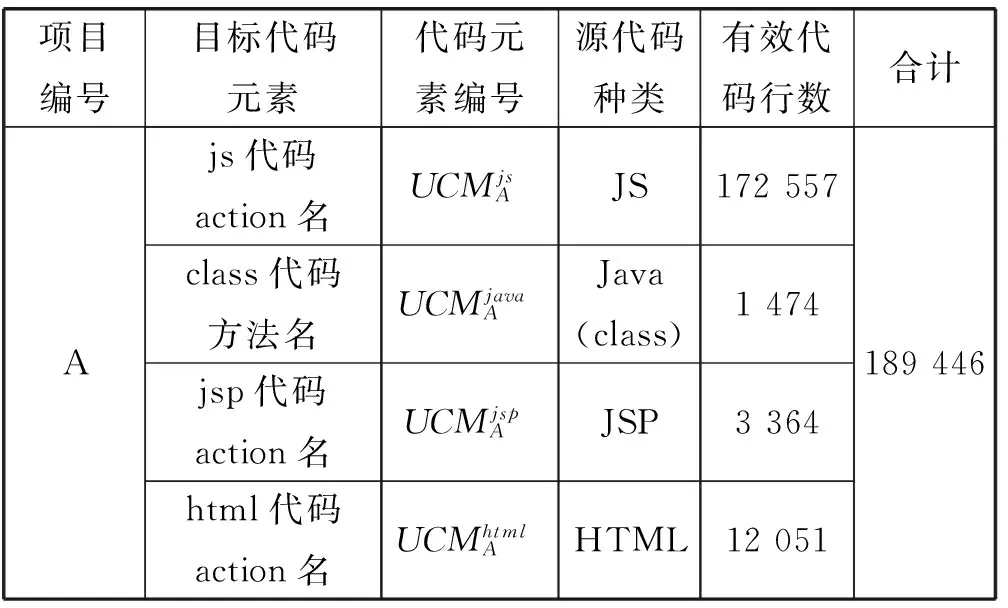
表2 实验设置信息
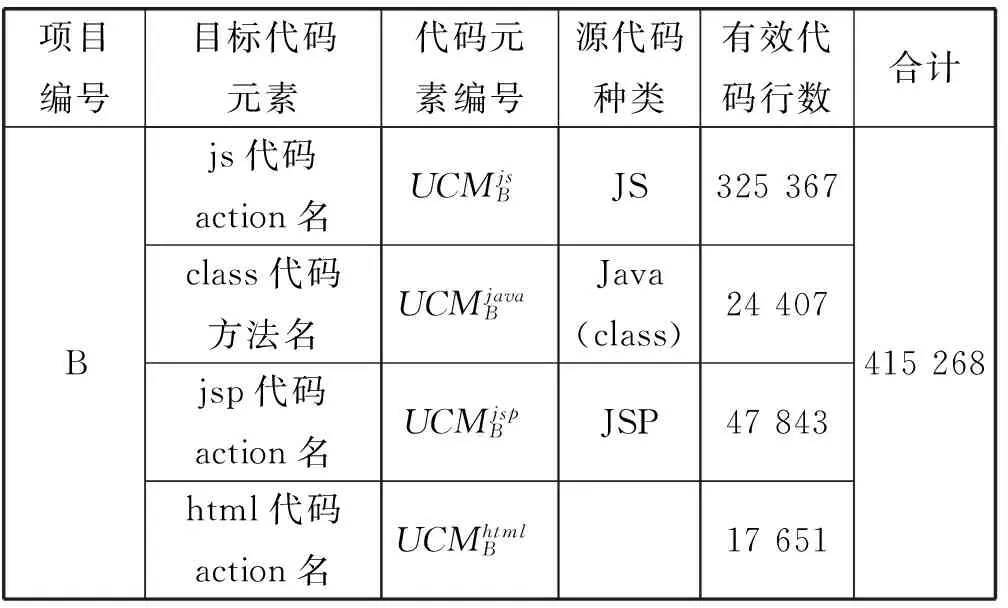
续表2
2.2.1 混淆方法的可行性评估
通过记录各组实验中工具的运行时间,结合实验对象的有效代码行数进行分析,如图8所示。项目A的混淆时间为76秒,项目B的混淆时间为95秒,项目代码有效行数越多,工具运行总时间越长,但随着代码行数的增长,工具单位时间处理的代码行数并未降低。这是因为混淆时间还与单位数量的代码行中所包含的关联代码元素数量有关。另外,混淆工具均在较短的有效时间内完成了项目混淆工作。
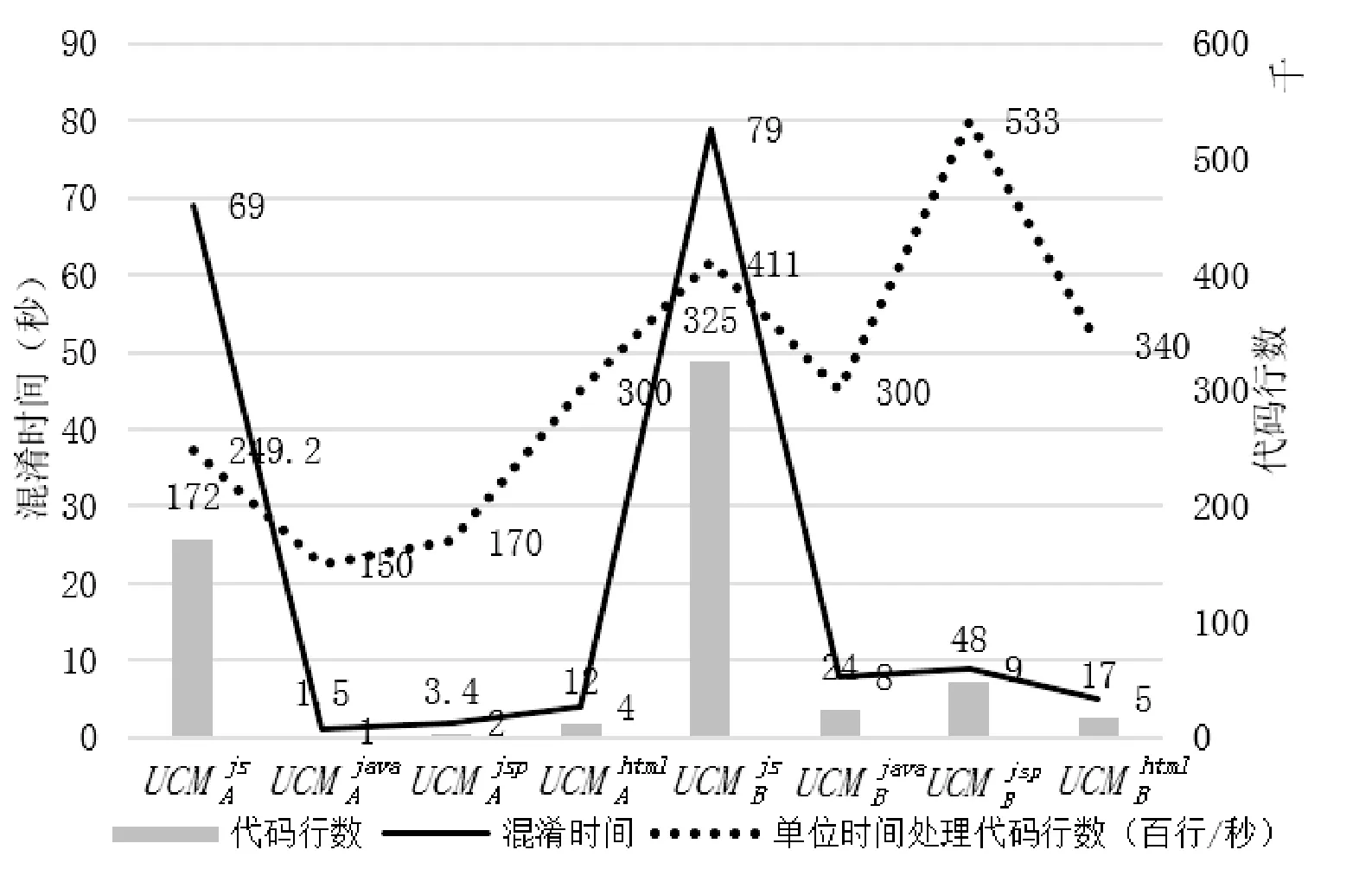
图8 有效代码行数与混淆时间
此外,两组实验最终均得到了可正常运行的混淆后项目程序,利用自动化测试工具UFT[5]进行功能测试,对比混淆前后项目功能测试结果,说明混淆后项目功能的正确性,并统计各功能模块覆盖的被混淆代码元素数量。以项目A为例,共混淆81个Action名称,功能测试中各测试用例的执行情况以及Action名称覆盖情况如表3所示。
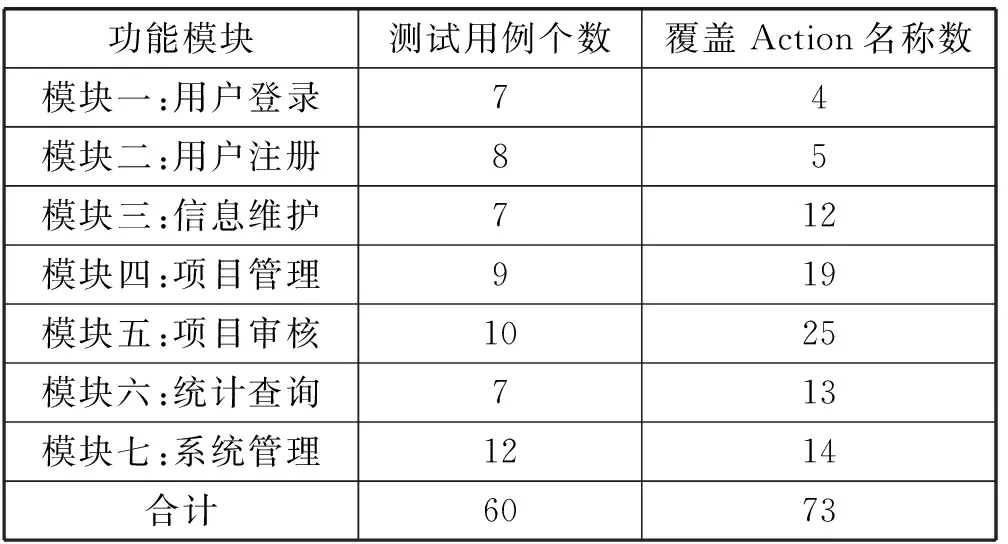
表3 测试用例执行结果及Action名称覆盖表
分析实验结果可知,60个测试用例均执行通过,说明混淆前后项目程序保持了功能性的一致,测试覆盖到的Action名称数量占混淆名称总量的90%以上,反映了混淆前后Action名称代码元素关联性的一致。综上所述,工具能在有效时间内混淆关联代码,并保证混淆后项目的正常运行,说明本文混淆方法以及混淆工具在实际的项目混淆中是具有可行性的。
2.2.2 混淆方法的有效性评估
混淆后项目A与项目B的程序体积增长率分别为2.90%及3.10%。由于本文混淆算法选取了较长的标识符替换代码元素原有名称,混淆后程序体积均有所增长。但整体来看,混淆后程序体积增长率均不大,这是由于本文混淆算法不会产生冗余代码,因此不会导致程序代码体积的大幅增加。
两组实验中发生混淆的代码元素种类及数量情况如图9所示。由图9可知,待混淆项目中关联性代码元素数量众多,且分布于不同类型的代码中,说明了混淆关联性代码元素对于提高项目混淆程度有所帮助,同时验证了所提方法具备了跨语言混淆的能力。
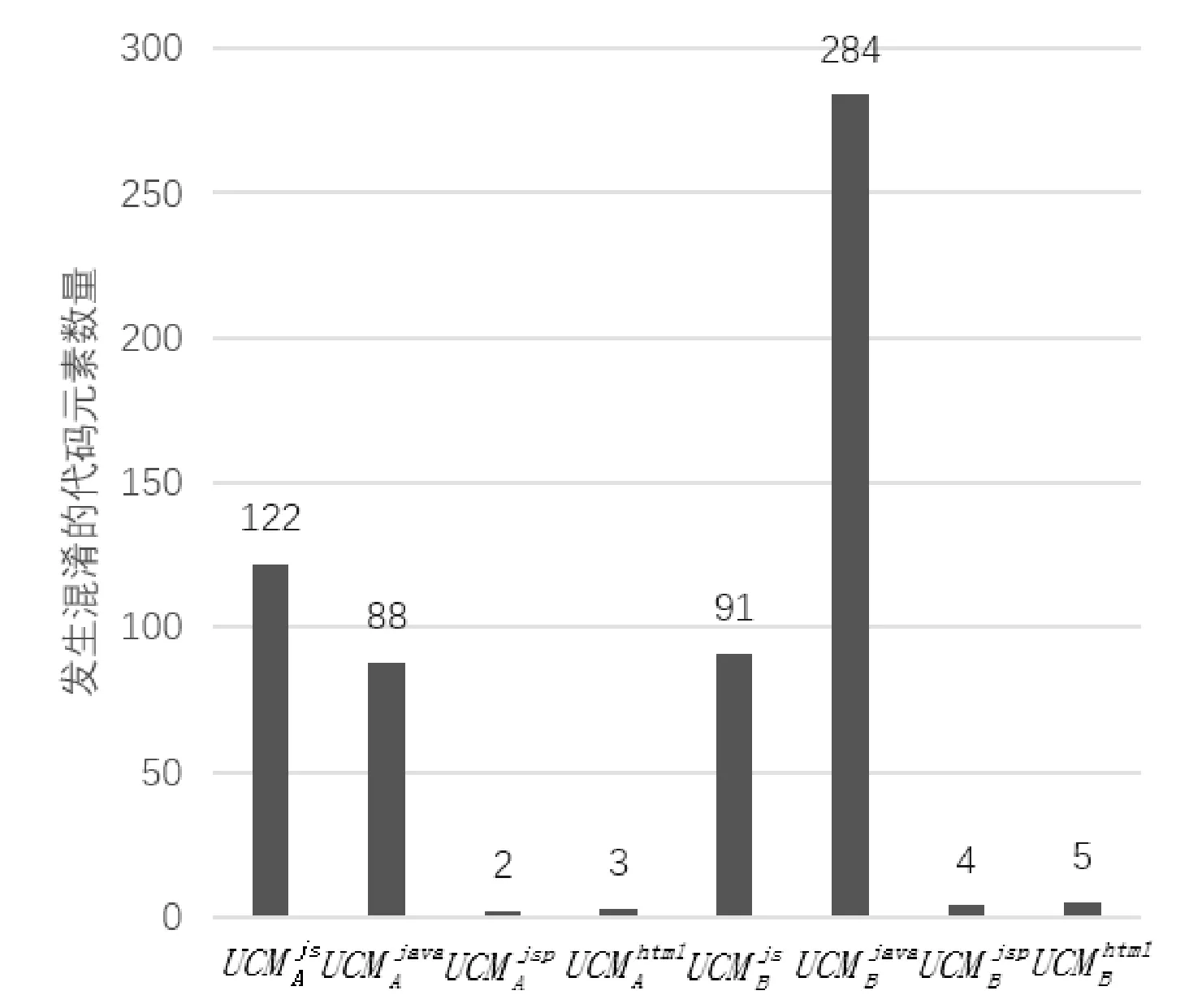
图9 混淆代码元素数量统计图
实验过程中,我们记录了混淆前后的Action的名称的变化情况。以项目A为例,从混淆结果中随机选取10条代码元素名称的变换信息,如表4所示。由混淆前后的Action名称对比情况可以看出,混淆前名称里诸如doQuery、bindSqlData这种有意义的名称,容易给用户造成联想,产生攻击尝试,本文混淆方法隐藏了代码元素名称所具有的意义,增加了人工阅读和理解代码的难度。
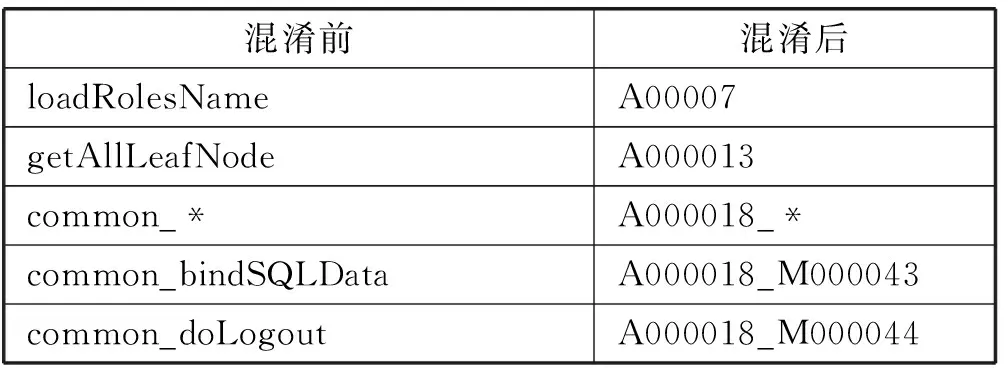
表4 以A项目为例混淆前后部分Action名称对比表
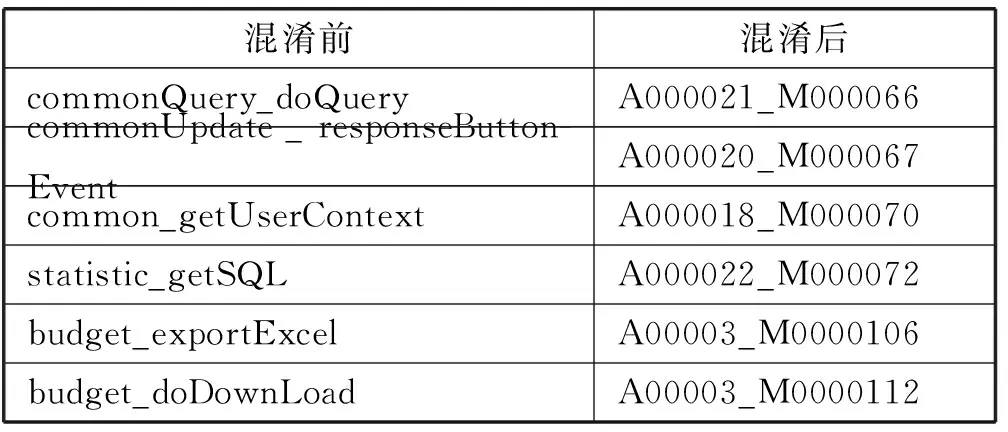
续表4
然而,本文方法具有一定的局限性,由于本文方法目前只考虑关联性代码元素的混淆,因此只能够处理关联代码的混淆联动问题,仍然需要依赖传统的混淆方法处理局部混淆。此外,本文混淆方法对于不依赖于变量名的逻辑分析工具仍然是没有作用的,只提升了人工分析的门槛。
3 相关工作
代码混淆技术作为一种软件安全保护技术而兴起,随Java语言的迅速发展而备受关注,近十几年来很多组织和研究人员致力于代码混淆技术在软件安全保护方面的研究。
Collberg等[1]最早对码混淆进行了准确定义,将混淆转换分为数据混淆、词法混淆、控制混淆,以及预防性混淆,并提出普适于高级语言的混淆算法,但未涉及实现细节。控制混淆方面的研究相对较多,平展控制流混淆算法[6]及不透明谓词混淆算法[7]是较为著名的研究成果。本文设计跨语言的代码混淆算法,结合布局混淆和数据混淆两方面的混淆变换技术,对不同类型代码元素进行统一化混淆。
Barak 等[8]给出了程序混淆的形式化定义,突破了此前代码混淆算法评估只能定性描述的局限。此后利用密码学等数学理论为重点的代码混淆技术成果不断涌现,例如通用混淆被证明是难以实现,而对某些具体函数类的混淆构造是可以有效实现的[9],以及利用密码学理论对反混淆的NP复杂度问题进行证明[10]。至今,软件工程学与密码学现在仍然是代码混淆技术的两个最主要的研究方向。
混淆模型方面,混淆新模型是程序混淆方面的一个重点研究方向,Barak等[8]指出虽然研究混淆的不同定义类型具有一定的实际应用意义。例如,对软件项目混淆时可以结合硬件的辅助,如公钥混淆[11]以及带硬件假设的安全混淆[12]。公钥混淆与一个公钥系统相结合,输出的结果是原函数的输出结果在此公钥系统下的加密密文。带硬件假设的安全混淆中将软件部分和一个硬件部分共同组成混淆函数,混淆的功能性由软件部分和硬件部分共同完成,而安全性只考虑软件部分的安全性。本文研究工作从混淆软件整体项目代码的角度出发,通过设计项目级代码混淆方法模型,实现项目关联代码的统一化混淆,从而提升项目整体的混淆强度。
代码混淆技术也带动了很多有效混淆工具的开发,对现实软件产品内部核心算法和知识产权进行保护。ProGuard[4]面向 Java类文件提供压缩和优化功能,利用布局混淆和数据混淆来实现混淆保护,通过删除或者重命名类、字段、方法与属性,最大程度地优化字节码文件。在JS语言方面,Javascript Obfuscator[13]通过布局混淆将对JS源代码转换成不可读的形式,并具有较强压缩能力。目前混淆工具的设计通常只针对特定编程语言类型的代码,本文基于所提方法研发跨语言的项目级代码混淆工具,能够实现跨语言的代码混淆以及关联代码元素关联性的维护,使得混淆后的项目程序能够正常运行,从而实现对现实软件产品全局业务逻辑代码的有效保护。
4 结 语
本文从提升软件项目整体混淆效果的角度出发,提出跨语言的项目级代码混淆方法。通过设计描述不同类型代码的各类代码元素的统一代码模型,以及定义关联规则对项目关联关系进行统一化描述,实现了项目关联关系的识别和自动化维护以及跨语言的代码混淆,提高了项目代码整体的混淆程度,提升了软件保护的门槛。基于所提方法,研发跨语言的项目级代码混淆工具,并在基于Struts2框架的真实源代码项目中进行了混淆实验,对所提方法及技术的可行性和有效性进行说明。
然而,本文方法目前局限于混淆项目关联代码,代码的局部逻辑混淆仍然依赖于传统的混淆方法。另外,所提方法中对于项目关联关系的获取仍需解析源代码文件,因此在实际应用中受到文件解析工具能力的限制。关联规则目前仅限于描述二元元素间的关联关系,如何进一步完善关联规则的统一化的定义,设计更为通用的描述规则以适应更多类型的项目是我们需要继续研究的问题。
[1] Collberg C,Thomborson C,Low D.A taxonomy of obfuscating transformations[R].Technical Report 148,University of Auckland,1997:325-350.
[2] Giacobazzi R.Hiding information in completeness holes:New perspectives in code obfuscation and watermarking[C]//Software Engineering and Formal Methods (SEFM),2008:7-18.
[3] Zhu W,Thomborson C.A provable scheme for homomorphic obfuscation in software security[C]//Communication,Network and Information Security (CNIS’05),2005:208-212.
[4] Proguard.ProGuard Java Optimizer and Obfuscator[EB/OL].2016-09-20.http://www.guardsquare.com/en/proguard.
[5] HPE UFT.The complete solution for automation of web,mobile,API,and packaged applications[EB/OL].2015-11.https://www.hpe.com/h20195/V2/GetPDF.aspx/4AA5-6938ENW.pdf.
[6] Chow S,Johnson H.An approach to the obfuscation of control flow of sequential computer programs[C]//Proceedings of the 4th International Conference on Information Security.Springer Verlag London,2001:144-155.
[7] Collberg C,Thomborson C,Low D.Manufacturing cheap,resilient,and stealthy opaque constructs[C]//Proceedings of the 25th ACM Sigplan-sigact Symposium on Principles of Programming Languages,1998:184-196.
[8] Barak B,Goldreich O,Impagliazzo R.On the impossibility of obfuscating programs[M].Journal of ACM,2001:1-18.
[9] Bitansky N,Canetti R,Paneth O,et al.More on the impossibility of virtual black-box obfuscation with auxiliary input[R].Cryptology ePrint Archive,Report 701,2013.
[10] Andrew W.Deobfuscation is in np[EB/OL].2002-08-21.http://www.cs.princeton.edu/~appel/papers/deobfus.pdf.
[11] Ostrovsky R,Skeith W E.Private searching on streaming data[M].Journal of Cryptology.Springer New York,2007,20(4):1432-1378.
[12] Goyal V,Ishai Y,Sahai A.Founding cryptography on tamper-proof hardware tokens[M]//Theory of Cryptography (TCC),Springer berlin heidelberg,2010:308-326.
[13] 宣以广,周华.基于字符熵的JavaScript代码混淆自动检测方法[J].计算机应用与软件,2015,32(1):309-312.
[14] 朱文琰,郑肖雄.基于正则表达式构建学习的网页信息抽取方法[J].计算机应用与软件,2017,34(2):14-19,79.
[15] 张树壮,罗浩,方滨兴,等.一种面向网络安全检测的高性能正则表达式匹配算法[J].计算机学报,2010,33(10):1976-1986.
猜你喜欢
小学教学参考(语文)(2022年3期)2022-05-26
电子产品世界(2022年2期)2022-03-22
老年医学研究(2021年5期)2022-01-19
现代信息科技(2021年21期)2021-05-07
云南医药(2020年5期)2020-10-27
农家书屋(2016年11期)2016-12-23
股市动态分析(2016年17期)2016-10-20
股市动态分析(2016年13期)2016-10-17
股市动态分析(2016年11期)2016-10-11
股市动态分析(2016年10期)2016-09-30
