
基于卷积神经网络和语义信息的场景分类
2018-02-05 09:16张晓明尹鸿峰
软件 2018年1期
张晓明,尹鸿峰
(1. 北京交通大学 计算机与信息技术学院,北京 100044;2. 北京交通大学海滨学院 计算机科学系,河北 黄骅 061199)
0 引言
作为机器视觉最常见的图像识别任务之一,场景图像的分类旨在通过提取并分析图像中的特征,将内容相似的图像归为同一类别。场景识别的意义,一方面是帮助计算机对画面的场景有一个总体的认识,增加先验知识,从而指导目标检测和识别[1];另一方面,目前更多应用的是基于内容的图像索引和检索[2],而互联网上的媒体内容每天都在快速不断地大量增多,亟需高效的自动方法来对这些内容进行存储、分类以及搜索。因此,场景分类成为了对海量的视觉内容进行组织、选择及索引的关键技术。
室内场景通常具有复杂的结构以及种类繁多的人工制品,容易使得场景类内差异比较大而类间相似性更高;此外,容易受到光照变化、视角变化和尺度变化以及遮挡问题的影响。因此,有关室内场景问题的处理相对进展较慢,且更具挑战性。而语义信息在克服上述问题方面具有很好的效果。实际上,场景与其中出现的目标,目标与目标共存等都不是互相独立、毫无关联的。因此语义理解是解决场景理解问题的重要组成部分,能利用场景及目标间的语义信息可以有效提高分类效果。
近年来,卷积神经网络深度学习模型在计算机视觉领域得到了广泛的应用。其中 Lecun网络[3]、Alex网络[4]、Google网络[5]、视觉几何组网络[6]、残差网络[7]是目前最知名的图像分类深度学习网络模型。然而这些深度模型有些对场景分类的效果并不好,尤其是复杂的室内场景。构建深度卷积网络模型,为提高分类效果通常做法是增加模型的深度或者宽度(层核或神经元数),如AlexNet有5个卷积层,VGGNet增加到了16层,GoogLeNet继续加深到21层,而ResNet则达到了151层且还在增加。除了增加计算成本之外,还需要海量训练数据。因此,如何在有限的数据集上,有效利用一定层数的卷积神经网络取得良好的场景分类效果是本文的研究重点。
本文面向复杂的室内场景,提出一种同时利用神经网络与语义信息来进行场景分类的方法,并在室内场景数据集上进行了实验对比,结果表明本文方法在训练数据集有限的情况下仍能取得很好的效果。
1 相关工作
传统场景分类方法,如 SPM[8]考虑空间信息,将图像分成若干块(sub-regions),分别统计每一子块的特征,最后将所有块的特征拼接起来,形成完整的特征来进行场景分类。该方法没有考虑图像中目标的完整性,对旋转等的鲁棒性也不高,而且利用的是人工SIFT特征。
而随着硬件水平的提高以及研究的深入,尤其从2012年AlexNet(Krizhevsky et al., 2012)赢得ILSVRC(ImageNet Large Scale Visual Recognition Challenge)比赛后,深度学习在计算机视觉领域展现出了巨大优势,应用也越来越广泛,已经成为计算机视觉的不二选择。在之后的几年中,VGGNet,GoogleNet,ResNet等一系列CNN网络在图像处理方面都取得了巨大成功。目前场景分类中最成功的CNN网络就是 Place-CNN[9],他是利用 Alexnet的结构,在由476个场景组成的共2500万张图像上进行训练得到的,取得了不错的分类效果。而他们都需要大量的图像作为基础,因为场景分布样式的千变万化。
Place-CNN中也指出CNN在进行场景分类时导致效果差的一个重要原因就是相比于目标图像来说,以场景为中心的图像更多样化,这也就意味着需要更多的训练样本,才能有更好的普适性。而一个场景中往往出现的目标物体是固定的,多个目标之间也会有固定的位置及依存关系。研究表明语义信息是解决计算机视觉问题的重要线索之一[10,11]。在进行场景分类识别时,利用场景和目标间的关系可以有效克服上述问题,避免场景多样化,用更少的训练数据得到良好的实验效果[12-15]。Object Bank[16]是预先训练好大量的目标检测器,然后将图像中检测到的目标作为特征来预测场景类别。但是没有明确的指出场景和他的目标组成间的关系以及目标间的几何关系。SDPM[17]与之类似,是利用DPM[18]获取目标信息进行场景分类。SS-CNN[19]结合深度信息,利用场景-目标间的共存关系训练了卷积神经网络,在SUN RGB-D数据集上取得了很好的效果。DeepContext[20]是利用3D语义信息,通过选定特定神经元,然后定义这些神经元之间的关系作为语义信息,训练 3D神经网络,来进行场景分类。3D ConvNets也需要预先训练场景模版,方法取得了很好的效果,但是却没有利用图像的颜色等2D信息。
因此,本文在利用卷积神经网络CNN利用颜色信息进行场景分类的基础上,利用目标与场景间的语义信息对分类结果进行修正。
2 相关模型和算法
2.1 卷积神经网络结构
以RGB三通道图像作为输入,本文分别用softmax和SVM作为分类器来进行了训练,以softmax为例,网络结构如图1所示。
为了减少计算量,避免训练集少造成过拟合,本文并没有用过深的网络,使用的是一个7层的卷积神经网络,前4层是卷积层,后3层为全连接层,其中最后一层采用softmax进行分类。
激活函数采用激活函数ReLU(Rectified linear units),实现起来非常简单,加速了计算的过程;且可以加速收敛,解决了饱和问题,大大地缓解了梯度消散的现象。
数据量比较小会导致模型过拟合,为防止模型过拟合,使得训练误差很小而测试误差特别大,我们通过对图像进行裁剪、翻转变换组合数据增强来增加输入数据的量;采用 Deopout[21]进行正则化,即在训练期间,对全连接的神经网络进行子采样。
网络会输出一个场景分类结果,但本文利用其各场景置信度,作为语义模型的输入,对分类结果重新进行评估,整体过程如图2所示。
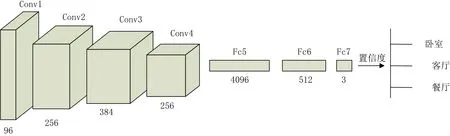
图1 卷积神经网络结构Fig.1 Examples of the network architecture
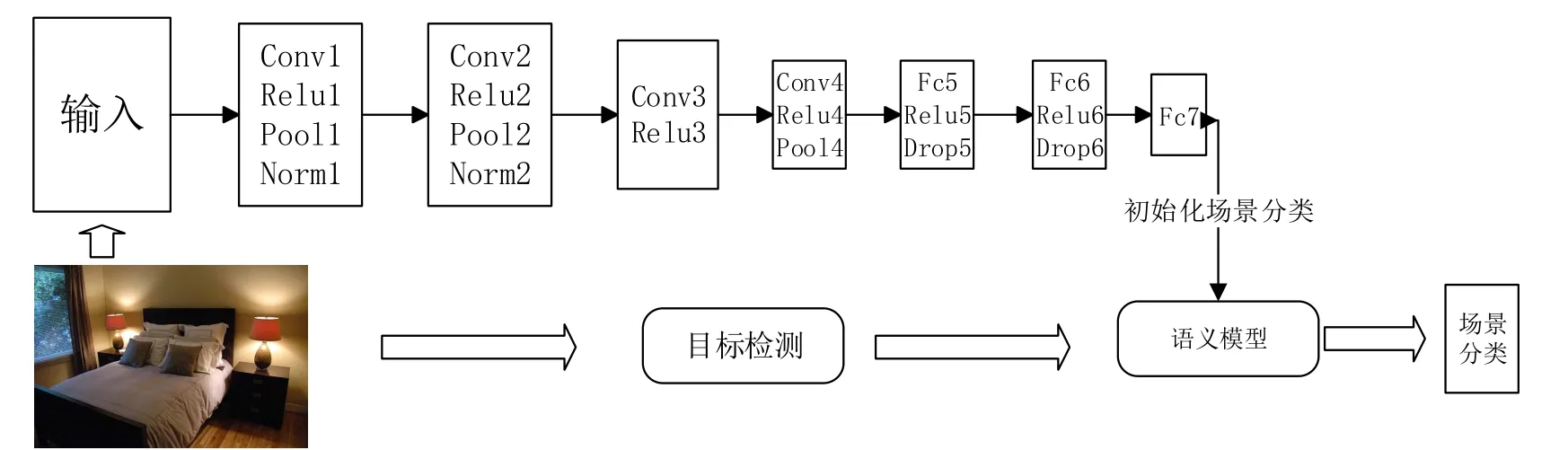
图2 整体分类流程Fig.2 Overview of the whole process
2.2 联合模型
本文利用颜色特征与语义信息相结合进行场景分类,共分两个阶段。整个系统分类过程如图2所示。首先利用卷积神经网络提取颜色特征对图像进行初始分类;然后,利用图像语义信息,对分类结果进行修正。
第一阶段:初始分类阶段。利用卷积神经网络进行图像分类,要先将图像转化为可用的lmdb数据格式,因为数据有过大的均值可能导致参数的梯度过大,影响后续的处理,因此还要数据零均值化。零均值化并没有消除像素之间的相对差异,人们对图像信息的摄取通常来自于像素之间的相对色差,而不是像素值的高低。计算过程如公式(1)所示。

其中,i,jX 表示第i行j列的像素值,一列共有n个值,即每个像素值为该数据值减去该列均值。
这里,我们不直接用网络分类结果,而是取网络中间结果各场景置信度作为第二阶段输入。同时,图像作为输入使用经典 DPM 算法进行目标检测得到目标检测结果,同样作为第二阶段输入。
第二阶段:修正阶段。我们定义场景与目标间的关系如公式(2)所示。

其中,O代表目标物体,OD代表检测到的目标集合,S表示场景类别,()Ψ·表示场景类型与目标间的语义上下文特征,根据二者共存的可能性来定义。

1. for i = 1 to SNum //SNum是场景分类的数目。2. for i = 1 to ONum //SNum是中目标数目。3. CalculateCo-occurence();//计算每个目标与场景间同时出现的几率。4. SumOccurence(); //计算所有目标出现在场景中的几率作为场景置信度。5. CompareOccurence();//比较每个场景的置信度//返回一个场景分类结果
上述算法描述了第二阶段伪代码。在完成 2.1所述卷积神经网络分类获得初始分类结果,及目标检测过程后,利用场景-目标间的语义关系对场景分类结果进行修正,得到最终场景分类结果。
3 实验
3.1 实验环境及数据集
实验使用 caffe深度学习框架,cuda 8.0,在NVIDIA GTX1080 GPU及64G CPU上运行。
为了测试本文方法的效果,我们在RGB数据集上做了大量实验,评估其场景分类效果。实验中我们采用文献[22]中数据集,含963张图片,包括卧室、餐厅、客厅三个场景各300多张。其中540张图片作为训练样本,用来训练网络模型,423图片用作测试,做了大量对比实验。
3.2 场景分类结果比较及分析
在实验过程中,由于数据集比较小,在训练卷积神经网络时我们采用全数据集(Full Batch Learning)的形式,即batch_size在GPU内存及计算能力允许的情况下尽可能设得大,因为 batch的选择,首先决定的是下降的方向。而选择全数据集,有以下几点优点:首先,由全数据集确定的方向能够更好地代表样本总体,从而更准确地朝向极值所在的方向,在一定范围内,一般来说Batch_Size越大,其确定的下降方向越准,引起训练震荡越小;其次,由于不同权重的梯度值差别巨大,因此选取一个全局的学习率很困难。并且,内存利用率提高了,大矩阵乘法的并行化效率提高。跑完一次全数据集所需的迭代次数减少,对于相同数据量的处理速度进一步加快。
Full Batch Learning 可以使用Rprop只基于梯度符号并且针对性单独更新各权值。但是受到内存限制,不能无限制增大,而且对于大的数据集也不可行,因为随着数据集的海量增长和内存的限制,一次性载入所有数据是不可能的。本文设置不同的batch_size进行实验,如图 3所示,(a)(b)(c)分别为batch_size等于16,128,622时,训练过程中损失值loss与准确率accuracy随迭代次数的变化。
由图3可以看出,随着batch_size的增大,收敛更快,loss下降更快,准确率提高更快,且准确率更高。其中,(a)在迭代2000次左右达到平稳,准确率只有74%,而(c)在迭代不到1000次即达到平稳,准确率可达80%,达到时间以及收敛精度上的最优。
我们分别训练了 softmax,linear SVM和 RBF Kernel SVM作为分类器。作为对比,我们用比较经典的算法SPM,SDPM和Object bank进行了实验。分别利用Alexnet和Place-CNN的网络结构进行训练和测试(两个网络均为迭代 4万次所得模型),Alexnet和 3DGPs[23]作为评价基准,与我们的实验对比结果如表1所示。实验结果表明本文方法在场景分类效果上优于现有的场景分类算法。比较方法的简介如下:
Object Bank. 将目标物体作为特征,它计算图像对不同目标特征的响应值,然后训练SVM分类器根据响应值对场景类型进行分类。我们总共考虑 6中典型目标。
SPM. SPM 提取经典的图像场景描述符 SIFT(Scale Invariant Feature Transform)特征,训练线性SVM作为分类器。
SDPM. 与Object Bank相类似,SDPM使用基于部件的可变形模型(DPM)学习场景的结构特征,并为每类场景训练LSVM模型。
Alexnet. 作为Place-CNN和我们的网络的结构基础,Alexnet作为评价的标准。利用随机初始化的权重,直接训练网络的softmax作为分类器。
Place-CNN. 与Alexnet一样,我们使用随机初始化权重的Place-CNN网络结构来进行场景分类。
3DGPs. 该方法研究3D几何模型,用于获取场景中一些常见的 3D空间配置,如经常一起出现的对象以及它们间的位置关系。通过迭代训练得到10个3DGP模型训练线性SVM作为分类器。
由表1可知,在训练数据少的情况下,深度神经网络的场景分类效果并不是很好,甚至比不上传统分类方法。Alexnet和Place-CNN都是随机初始化参数,直接训练 softmax作为分类器,而后者的分类效果明显不如前者。因为Place-CNN的网络结构更适合进行特征提取,而不是直接用作分类,因此可以利用Place-CNN网络结构提取特征,训练SVM作为分类器,分类效果会更好。而本文方法实验效果明显优于其他方法,由于利用神经网络提取颜色特征结合语义特征,并且SVM适用于少样本训练,本文中 SVM 作为分类器比 softmax直接分类效果好,其中以RBF Kernel SVM作为分类器效果最好。
4 结论
本文利用神经网络提取颜色特征,结合目标与场景间的语义信息,在利用较少的样本训练模型的基础上,在场景分类实验中取得了很好的效果。本文方法既可以减少搜集及标记大量图像样本所需的人力、物力、财力,一定程度避免人工标记的错误,也可以避免过深的网络所需的大量内存及计算问题。但仍存在一些问题,需要继续研究。首先,需要训练更多场景模型,才能推广到更多场景的分类中。并且,可以通过利用场景几何信息或者提高目标检测结果准确度来提高结果准确性。
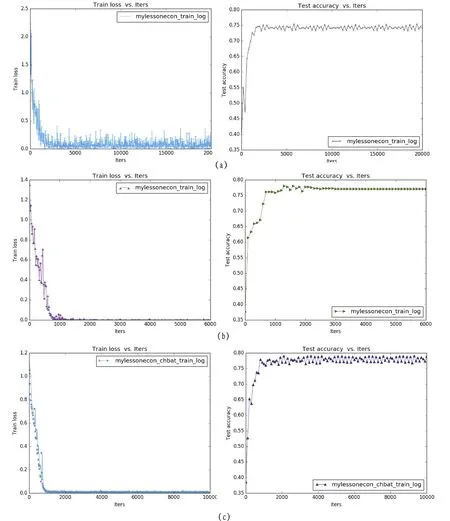
图3 batchsize分别为16,128,622时的loss-iter曲线以及accuracy-iter曲线Fig.3 Loss-iteration curves, accuracy-iteration curves and loss-second curves when batch size is 16, 128, 622
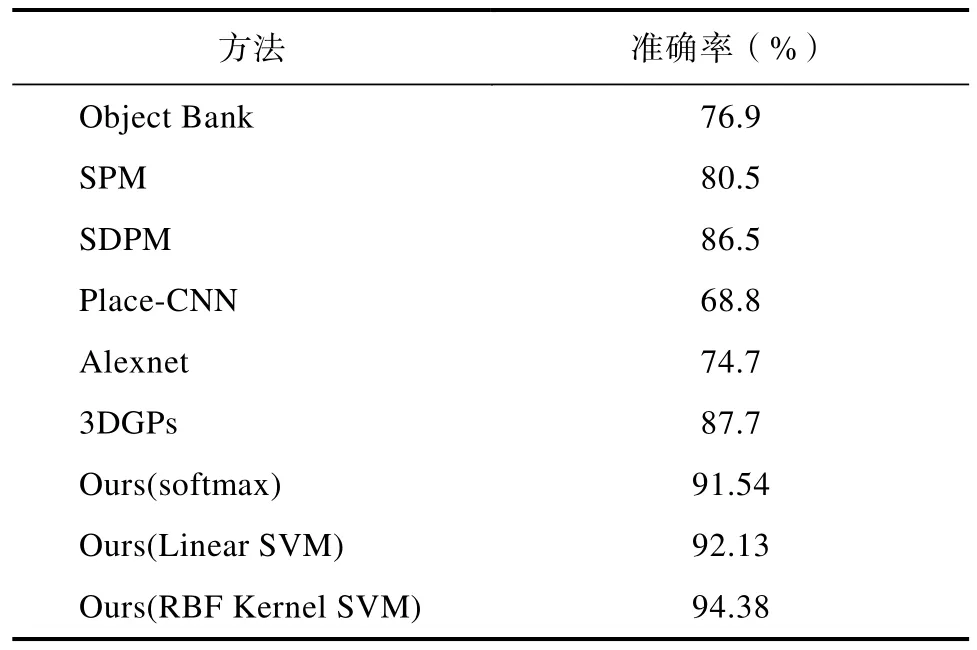
表1 场景分类精确度Tab.1 Scene classification comparison
[1] TORRALBA A, MURPHY K P, FREEMAN W T, et al.Context-based vision system for place and object recognition[C].Computer Vision, Proceedings. Ninth IEEE International Conference on. IEEE, 2003: 273-280.
[2] VAILAYA A, FIGUEIREDO M A T, JAIN A K, et al. Image classification for content-based indexing[J]. Image Processing,IEEE Transactions on, 2001, 10(1): 117-130.
[3] LECUN Y, BOTTOU L, BENGIO Y, and HAFFNER P.Gradient-based learning applied to document recognition.Proceedings of the IEEE, 86(11): 2278–2324, 1998.
[4] KRIZHEVSKY A, SUTSKEVER I, and HINTON G E. Ima-genet classification with deep convolutional neural networks.In In Advances in Neural Information Processing Systems,2012.
[5] SZEGEDY C, Liu W, Jia Y, Sermanet P, Reed S, Anguelov D, Erhan D, Vanhoucke V, Rabinovich A. Going deeper with convolutions. In IEEE, pages 1-9, 2015.
[6] SIMONYAN K and ZISSERMAN A. Very deep convolutional networks for large-scale image recognition. Preprint arXiv:1409. 1556, 2014.
[7] HE K, ZHANG X, REN S, SUN J. Deep Residual Learning for Image Recognition, 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), vol. 00, no., pp.770-778, 2016, doi:10.1109/CVPR.2016.90.
[8] LAZEBNIK S, SCHMID C, and PONCE J. Beyond bags of features: Spatial pyramid matching for recognizing natural scene categories. In CVPR, 2006. 1, 2, 3, 6
[9] ZHOU B, LAPEDRIZA A, XIAO J, TORRALBA A, and OLIVA A. Learning deep features for scene recognition using places database, Advances in Neural Information Processing Systems, pp. 487–495, 2014.
[10] CHANG A X, FUNKHOUSER T, GUIBAS L, HANRAHAN P, HUANG Q, LI Z, SAVARESE S, SAVVA M, SONG S,SU H, XIAO J, YI L, and YU F. Shapenet: An information-rich 3d model repository. In arXiv, 2015. 5
[11] CHOI M J, LIM J J, TORRALBA A, and WILLSKY A S.Exploiting hierarchical context on a large database of object categories. In CVPR, 2010. 2
[12] YAO J, FIDLER S, and URTASUN R. Describing the scene as a whole: Joint object detection, scene classification and semantic segmentation, Computer Vision and Pattern Recognition(CVPR), 2012 IEEE Conference on, pp. 702–709, IEEE,2012.
[13] LIN D, FIDLER S, and URTASUN R. Holistic scene understanding for 3d object detection with rgbd cameras, Computer Vision (ICCV), 2013 IEEE International Conference on, pp.1417–1424, IEEE, 2013.
[14] LUO R, PIAO S, and MIN H. Simultaneous place and object recognition with mobile robot using pose encoded contextual information. Robotics and Automation (ICRA), 2011 IEEE International Conference on, pp. 2792–2797, IEEE, 2011.
[15] ROGERS J G, CHRISTENSEN H, et al. A conditional random field model for place and object classification.Robotics and Automation (ICRA), 2012 IEEE International Conference on, pp. 1766–1772, IEEE, 2012.
[16] LI L J, SU H, XING E P, and LI F F. Object bank: A high-level image representation for scene classification &semantic feature sparsification. In NIPS, December 2010. 2,6, 7
[17] PANDEY M, LAZEBNIK S. Scene recognition and weakly supervised object localization with deformable part-based models. Computer Vision, IEEE International Conference on,vol. 00, no., pp. 1307-1314, 2011, doi:10.1109/ICCV.2011.6126383.
[18] FELZENSZWALB P, GIRSHICK R, ALLESTER D M, and RAMANAN D. Object detection with discriminatively trained part based models. PAMI, 32(9), Sept. 2010. 1, 2, 3, 5,6, 7.
[19] LIAO Y, KODAGODA S, WANG Y, SHI L and LIU Y.Understand Scene Categories by Objects: {A} Semantic Regularized Scene Classifier Using Convolutional Neural Networks .arXiv preprint arXiv: 1509. 06470.
[20] ZHANG Y, BAI M, KOHLI P, IZADI S, XIAO J. DeepContext:Context-Encoding Neural Pathways for 3D Holistic Scene Understanding.In arXiv: 1603. 04922 [cs.CV].
[21] SRIVASTAVA N, HINTON G, KRIZHEVSKY A, SUTSKEVER I and SALAKHUTDINOV R. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. Journal of Machine Learning Research., pp. 1929-1958, 2014.
[22] CHOI W, CHAO Y, PANTOFARU C, SAVARESE S. Understanding indoor scenes using 3D geometric phrases. In CVPR(2013).
[23] CHOI W, et al. Indoor Scene Understanding with Geometric and Semantic Contexts. International Journal of Computer Vision112.2(2015):204-220.
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
开放教育研究(2020年2期)2020-03-31
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
电子测试(2018年1期)2018-04-18
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
现代语文(2016年21期)2016-05-25
大连民族大学学报(2015年2期)2015-02-27
电测与仪表(2014年15期)2014-04-04
