
云计算平台状态监控技术研究与应用
2018-02-05 09:16李红辉关婷婷杨芳南
软件 2018年1期
李红辉,关婷婷,杨芳南
(北京交通大学 计算机与信息技术学院,北京 100044)
0 引言
云计算平台由于其计算能力及存储能力受到越来越多企业的应用[1-3],特别是应用到动车组全生命周期数据[3-4]处理上。这些应用对于数据的稳定性和实时性提出了很高的要求,这就需要云计算平台在提供服务支撑的同时能够拥有较好的稳定性。因此平台的状态监控与故障告警成为了许多系统管理员着重关注的问题。
目前广泛被应用的监控方法依赖于开源工具,如Ganglia、Nagios[5-6]等,多为直接采用工具默认支持的监控指标[7-9],对关联的各项指标进行直接显示,没有根据各项指标数据进行计算,监控指标多而杂,这会造成指标多而不直观的问题。本文研究反映平台性能的指标及其计算方法,提出云计算平台状态监控指标体系,提出利用触发器的方法存储历史数据,利用Ganglia扩展指标能力和Icinga告警机制实现指标获取和状态监控及异常告警,最后采用Echarts工具进行历史数据和变化趋势的可视化展示。
1 平台监控软件结构
节点的性能与存活状态直接影响着计算平台的服务支持,如若不提供平台的状态监控与故障告警,当发生故障或作业卡顿时,平台管理员不能及时发现并定位故障原因,对于恢复平台计算能力提出了很大的挑战。目前成熟的监控工具 Ganglia对集群节点性能做了监控,但是繁多的监控指标让用户眼花缭乱;Nagios、Icinga等是一个核心框架[10],所有的监控任务需要依赖插件完成,工具自身与平台的耦合度较低。
为了更好的实现云计算平台的监控,满足平台对于硬件性能和集群运行状态的监控需求,提出了云计算平台监控工具软件结构模型,如图1所示。该模型包含数据采集、数据处理、数据存储、数据分析、异常告警和可视化显示等模块。首先实现监控指标采集,并对指标进行数据清洗与处理,按照提出的指标体系进行精简。接下来将获取到的指标进行存储,以便之后进行可视化展示,存储方式包括数据文件、数据库等。然后根据指标值对平台进行状态分析,当指标数据出现异常时,进行故障告警。最后对当前计算平台的正常运行状态、异常状态、告警对象及历史变化趋势进行可视化展示。
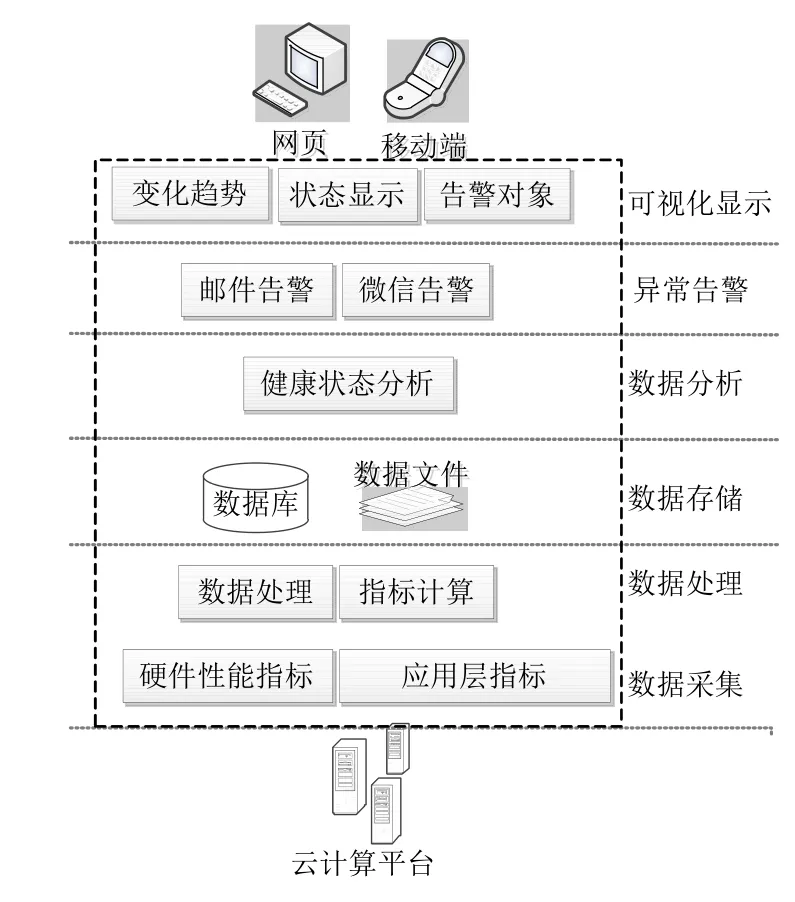
图1 云计算平台监控软件结构模型Fig.1 Model of monitor software structure of cloud computing platform
2 监控指标体系及计算方法
传统的监控工具硬件性能监控指标较多,不直观,如Ganglia,共有几十项硬性指标[5]。通过研究发现,平台硬性指标实际上主要关注CPU利用率、负载、磁盘I/O、内存使用率等四个重要指标。CPU的过度利用会导致作业运行的缓慢,大量的时间被消耗在上下文的切换上,作业计算能力被减弱;CPU负载表示正在使用和等待使用CPU的任务数,如果CPU负载过高任务等待时间就会过长;磁盘过载,IO等待时间过长,任务执行速度变慢;如果某个进程占用内存过大,就会影响整个系统性能。我们通过对这四个指标进行分析,找出相关指标并计算这四项指标值,直观显示的同时又减少了展示的监控指标数量,达到一目了然的效果。
CPU的利用率就是非空闲进程占用时间的比例,计算CPU的利用率可以通过以下方法计算。取两个时间点 t1、t2,分别获取 user(运行用户空间进程时间占比)、nice(运行调整优先级的用户进程时间占比)、system(运行内核时间占比)、idle(CPU空闲时间占比)、iowait(CPU等待I/O请求时间占比)、hardirq(处理硬件中断时间占比)、softirq(处理软件中断时间占比),则 CPU在此时间段内总的使用时间Tsum为:
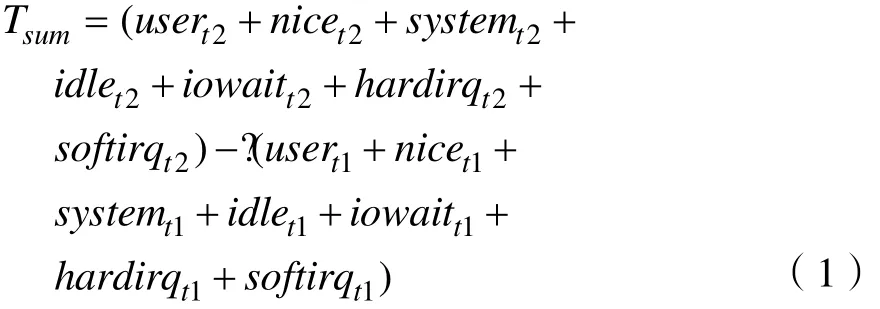
CPU此段时间内的空闲使用时间Tfree为:

所以,CPU在此段即时利用率Usagecpu为:

经过实验,t1和t2的时间间隔取3s时,刷新时间与top指令基本保持一致。
CPU负载不仅与平均负载(load averages)有关,还与CPU处理器数量有关。平均负载有三个表现值,load_one(平均每分钟负载)、load_five(平均每5分钟负载)、load_fifteen(平均每15分钟负载)。根据总结使用者经验,取load_five值较好。
内存使用率是物理已用内存占总的内存百分比,用 phyfree表示物理已用内存,内存使用率Usagemem计算如下:
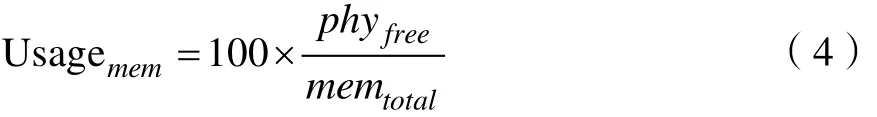
磁盘I/O瓶颈可通过磁盘读写速率体现。取t1、t2两个时间点的读操作的次数(rd_ios)、读取的扇区数量(rd_sectors)、写操作的次数(wr_ios)、写入的扇区数量(wr_sectors),t1、t2时间间隔为1s,则每秒完成的读I/O设备次数r/s为:
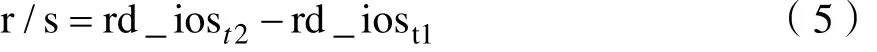
每秒完成的写I/O设备次数w/s为:
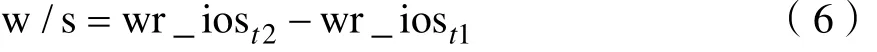
每秒读扇区数rsec/s为:
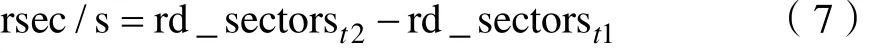
每秒写扇区数wsec/s为:
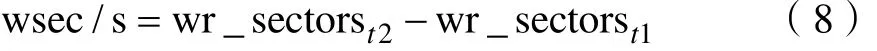
3 状态监控与故障告警系统实现
在第1节提出的监控软件模型和第2节的硬件监控指标基础上,提出一个云计算平台的监控系统实现方案,如图2所示。首先系统数据采集模块从云计算平台采集指标数据,交给数据处理插件进行数据处理及指标数值计算,并将计算结果上报。数据分析插件接到上报的指标数据,根据各指标的阈值区间判断此刻指标数值是否正常,将状态交给告警处理模块。告警处理模块对状态进行相应的告警处理并将数值存储数据库。最后前端实现数据可视化,给出实时数据状态展示和历史数据变化趋势展示。方案实现利用了 Ganglia的指标上报机制,用Pyhton语言自定义插件,实现 Ganglia指标扩展,实现指标数据的采集与处理;利用Icinga框架的故障告警能力,设计插件,将由 Ganglia上报的指标数值与阈值进行比对,判断指标是否存在异常,并给出异常告警;利用Icinga数据更新流程,设置触发器实现历史数据存储,实现历史变化趋势展示。
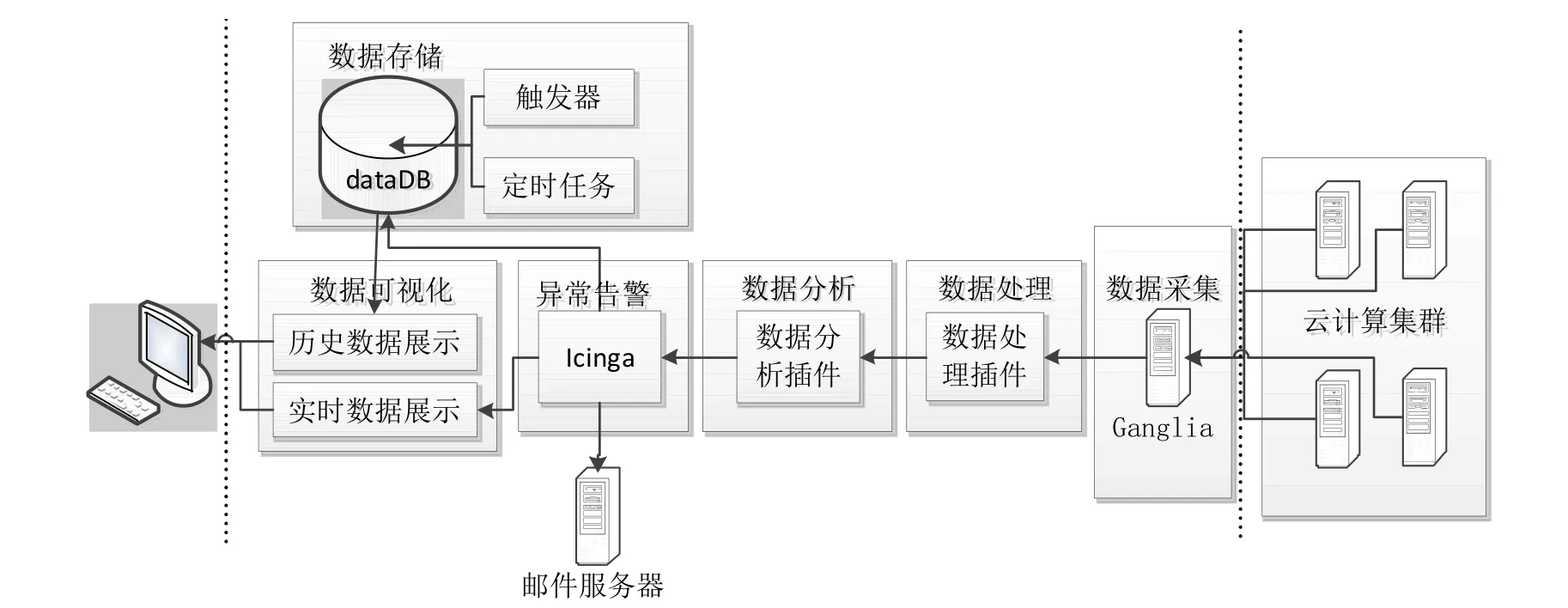
图2 监控系统实现方案Fig.2 Experiment scheme of monitoring system
3.1 数据采集与处理
采集性能指标需要读取系统文件,并实现指标数据的计算、主动上报和收集。本文数据采集分别从平台系统文件 meminfo、cpuinfo、stat、diskstat中定时读取系统硬件性能指标原始数据,按照前述的计算方法进行目标指标数据计算。为了很好地实现数据的上报和收集,这里与 Ganglia结合,利用Ganglia指标扩展能力[11],设计数据处理插件。插件由Python语言实现,在插件中分别实现指标信息的定义与初始化、指标清除、指标计算与处理,对应的三个函数分别为metric_init()、metric_cleanup()、metric_handler()。
3.2 数据存储
传统的监控工具对监控指标数据采用文件的形式存储,这种数据储存形式不方便数据的使用和展示。为了更好的实现可视化,需要改进存储方式。本文提出将监控指标数据存储到MariaDB表中,此处应用到触发器事件和定时任务。在数据库中建立指标数据历史存储表,存储内容及类型如表1所示。其中监控节点代表此条记录是平台中哪个节点,性能值包括此时的状态值和两个阈值,阈值记录方便之后的趋势展示标记,不用再遍历配置文件,状态分为三种,正常、告警、严重告警。结合Icinga中数据更新操作流程,当数据库表中更新状态数据时,触发器事件完成此次数据更新时触发一次插入数据库表操作,保存监控指标的历史数据。由于监控的实时性,更新速度很快,产生大量历史数据,可通过定时任务删除历史数据,如,定时任务每天执行一次,删除一个月前的数据,保留近1个月历史数据。

表1 指标数据历史存储表结构设计Tab.1 Table structure of metrics history datas
3.3 数据分析与故障告警
数据分析是指分析指标数据是否正常,故障告警是指当指标数据异常时给出告警提示。在数据分析中可以为每个指标设置两个阈值,分为代表亚健康状态和故障状态。根据实验经验,CPU利用率在0-75%之间任务运行一般正常,如果长时间处于90%以上,任务运行通常变慢。因此,CPU利用率两个阈值可设置为75%,90%。就单核处理器来说,CPU负载通常维持在0.70比较好,当达到1.0的时候说明CPU满载,当超过1.0时任务队列就会出现等待,因此,多核CPU负载的两个阈值可设置为0.70*CPU内核数,1.0*CPU内核数。为了满足不同配置服务器,阈值不能是固定值,应采用百分比机制,这样即使集群内节点硬件配置不同,监控配置阈值依然不用做修改。所以CPU负载做归一化处理,在计算CPU负载时将load_five值除以CPU内核数量。因此, CPU负载的阈值可以设置为0.7,1.0。磁盘IO瓶颈与磁盘的种类有关,不同的磁盘读写速率极限不同,7200转台式机硬盘大致在130-190MB区间,因此可以将磁盘读速率的两个阈值设置为100M/s、130M/s,写速率的两个阈值为50M/s、65M/s。根据实验经验,内存使用率低于88%时,系统一般不会出现卡顿,当内存使用率超过90%时,系统卡顿现象一般较为严重,因此,内存使用率阈值设置为88%,90%。CPU利用率、CPU负载、磁盘I/O、内存使用率四个指标的阈值设置汇总如表2所示。
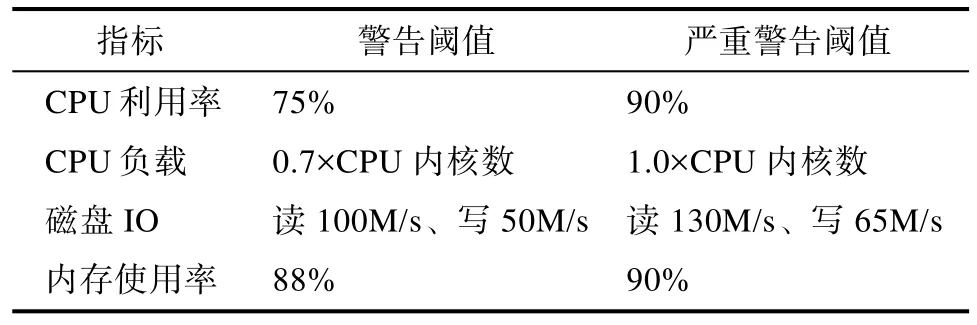
表2 故障告警阈值设置Tab.2 Thresholds settings of fault alarm
故障告警结合Icinga软件,自定义监控插件,并设置监控指标阈值。当指标数据超出阈值时,要给相关管理员发告警通知。告警类型分为警告和严重告警,通知方式采用邮件告警方式。
3.4 可视化
可视化分为两部分,实时指标数据展示和历史数据趋势展示。用户通过监控软件展示界面查看监控指标的状态及数据,发现故障,进行平台修复。历史数据趋势变化可以帮助系统运维管理人员了解指标变化趋势,帮助定位故障发生原因。可视化实现结合Icinga显示和开源工具Echarts,后端数据处理采用PHP语言。先编写PHP脚本将历史数据表中的数据进行处理,以Ajax异步方式传给Echarts[12]。Echarts为x轴、y轴赋值,并渲染画布进行趋势展示。
3.5 实验结果
针对本文提出的监控系统实现方案,本次实验搭建一个6个节点的云计算平台,包括1个主节点,5个从节点,每个节点预装了 centos7、jdk1.7、hadoop2.6环境。监控系统软件部署在另外一台服务器上,运行环境为 centos7、jdk1.7,并安装支持软件 ganglia3.7.2、python2.7、icinga1.12.2。
当监控指标出现异常时,监控系统向配置文件中的联系人发送邮件告警,同时数据异常指标的颜色和状态在可视化界面发生相应变化,如图3所示。图3表示CPU利用率在22:09分时发生严重告警,CPU利用率达到92%。系统运维人员可以选择指标进行变化趋势查看,默认为近1小时内数据,如图4所示,图中横坐标为时间,纵坐标表示CPU利用率,在近1小时内最大值为94%,最小值为13%,平均利用率为55.1%。
从实验结果来看,文中提出的监控软件设计方案实现了云计算平台状态监控及故障实时告警。
4 结论

图3 实时状态展示Fig.3 Real-time status display
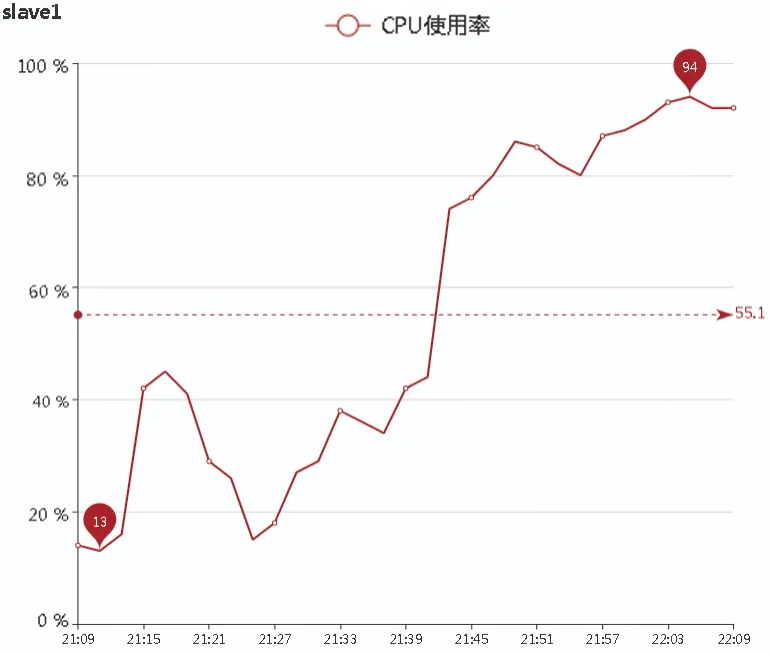
图4 历史状态趋势展示Fig.4 Historical states trend display
本文提出云计算平台监控模型,提出了性能监控指标体系及其计算方法,通过与 Ganglia扩展监控对象的方式自定义插件脚本,实现指标的采集及计算,依托Icinga更新状态数据流程,提出触发器保存历史监控指标数据,并建立定时任务对历史数据进行处理,减少磁盘存储和查询压力,利用 Icinga告警机制,自定义插件脚本,研究各监控指标的阈值设置,实现故障告警,前端可视化采用当前比较流行的开源技术Echarts搭配PHP脚本语言,图表直观人性化。本文提出的监控系统很好的实现了性能监控、故障告警、前端可视化展示,完成了云计算平台对监控软件的需求。之后的研究方向为研究反映云计算平台故障预测技术。
[1] 王有元, 蔡亚楠, 王灿等. 基于云平台的变电站设备智能诊断系统[J]. 高电压技术, 2015, 41(12): 3895-3901. DOI:10. 13336/j. 1003-6520. hve. 2015. 12. 003.WANG Y Y, CAI Y N, WANG C, et all. Intelligent Diagnosis System for Substation Equipment Based on Cloud Platform[J]. High Voltage Engineering, 2015, 41(12): 3895-3901.DOI: 10. 13336/j. 1003-6520. hve. 2015. 12. 003. (in Chinese)
[2] 陈韶男. 基于云计算的企业车辆监控管理平台的设计[J].软件, 2014, 35(8): 104-109. DOI: 10. 3969/j. issn. 1003-6970. 2014. 08. 023.CHEN S N. Design of Monitoring and Management Platform for Vehicles based on Cloud Computing[J]. computer engineering & Software, 2014, 35(8): 104-109. DOI:10.3969/j.issn. 1003-6970. 2014. 08. 023. (in Chinese)
[3] 李燕, 张惟皎, 贾志凯. 动车组全生命周期数据可视化研究[J]. 铁路计算机应用, 2013, 22(01): 58-62.LI Y, ZHANG W J, JIA Z K. Research on data visualization of EMUs whole life-cycle[J]. Railway Computer Application,2013, 22(01): 58-62. (in Chinese)
[4] 张春, 袁天宁. 针对动车组全生命周期集成管理的多源异构数据融合框架设计[J]. 计算机与现代化, 2017, (10):36-41.ZHANG C, YUAN T N. Design of Multi-source and Heterogeneous Data Fusion Framework for Integrated Lifecycle Management of EMU[J]. Computer and Modernization, 2017,(10): 36-41. (in Chinese)
[5] 梅西. Ganglia系统监控[M]. 机械工业出版社, 2013.Matt Massie. Monitoring with Ganglia[M]. China Mechine Press, 2013.
[6] 吴怡风, 归强, 罗明宇等. 集群计算机监控技术研究[J].计算机与现代化, 2013, (11): 218-222.WU Y F, GUI Q, LUO M Y, et all. Monitoring Technology of computer in cluster[J]. Computer and Modernization, 2013,(11): 218-222. (in Chinese)
[7] 张小银, 陈国胜. 基于Ganglia和Nagios的云计算平台智能监控系统[J]. 安徽理工大学学报(自科版), 2016, 36(4):69-74.ZHANG X Y, CHEN G S. Intelligent Monitoring System on Cloud Computing Platform Based on Ganglia and Nagios[J].Journal of Anhui University of Science and Technology(Natural Science), 2016, 36(4): 69-74. (in Chinese)
[8] 朱娜娜. Hadoop平台的集群故障监控的研究与实现[J]. 软件, 2013, 34(12): 73-77.ZHU N N. The Research and Implement of Fault Monitoring on Hadoop Platform[J]. computer engineering & Software,2013, 34(12): 73-77. (in Chinese)
[9] 钱涛, 李建元. 基于Nagios的Hadoop集群性能监控[J]. 杭州电子科技大学学报(自然科学版), 2015, 35(03): 64-67.QIAN T, LI J Y. Hadoop Cluster Performance Monitoring Based on Nagios[J]. Journal of Hangzhou Dianzi University,2015, 35(03): 64-67. (in Chinese)
[10] V Mehta. Icinga network monitoring[M]. UK: Packt Publishing Ltd, 2013: 5-6.
[11] Ng Zhi An. Gmond Python metric modules[EB/OL].(2014-06-28). [2017-11-22]. https://github.com/ganglia/monitorcore/wiki/Ganglia-GMond-Python-Modules.
[12] 冀潇, 李杨. 采用ECharts可视化技术实现的数据体系监控系统[J]. 计算机系统应用, 2017, 26(6): 72-76.JI X, LI Y. Realization of Data Hierarchy Monitoring System by Using ECharts Visualization[J]. Computer Systems &Applications, 2017, 26(6): 72-76. (in Chinese)
猜你喜欢
世界科学技术-中医药现代化(2022年3期)2022-08-22
云南化工(2021年8期)2021-12-21
高技术通讯(2021年5期)2021-07-16
海洋信息技术与应用(2020年1期)2020-06-11
电子制作(2019年22期)2020-01-14
当代陕西(2019年13期)2019-08-20
传媒评论(2019年4期)2019-07-13
黑龙江工程学院学报(2015年5期)2015-12-04
智能建筑电气技术(2015年1期)2015-03-01
测绘科学与工程(2014年5期)2014-02-27
