
词和短语区分的频率因素计量考察
2018-01-17 02:08陈衡
现代语文 2018年7期
陈衡


摘要:词和短语的区分问题是汉语语言学研究的一个重点和难点,传统的“结构稳固、意义凝聚、音节长度适中”并不能很好地解决这一问题。近年来,从“频率”角度对这一问题展开的讨论增加,但主要限制在关于“词感”的讨论方面,还缺乏大规模数据统计的支持。“频率”是否真正适合作为区分词和短语的一个标准还没有定论。本文基于对近5亿字现代汉语语料2-gram串统计结果最高频1000个字符串的考察,得出:“频率”还不能直接作为界定词的标准,它在解决词和短语区分的模糊地带方面能否发挥较大作用还需进一步探讨。
关键词:词 短语 频率 二字词 二字短语
一、引言
在汉语语言学研究中,“词”是各类研究的重要基础,没有对词的定义和界定,基于其上的诸如词语研究、词类研究、构词研究、短语研究、词典编纂等都将无从谈起。词的定义与界定问题是现代汉语中一个非常重要的问题,也是一个难题。与英语中实行单词分写不同,汉语的字不实行分词连写,因此,汉语中“词”的定义与界定问题比英语中的复杂得多。
关于词该如何定义及界定的问题自中国现代语言学诞生时就已经开始探讨。邵敬敏(1990)总结认为,词的划界一是定义的需要,二是分词连写的需要。譬如,中文信息处理中的分词问题——尽管目前使用“分词单位”作为权宜之计,但以此制定出来的“分词词表”仍饱受诟病,原因之一还是对“词”的定义与界定没有很好的把握。
到目前为止,一般广为接受的关于“词”的定义应该是吕叔湘先生的“最小的自由活动的语言片段”(吕叔湘,1979)。但光从这一定义来看,处处都有着不确定性,什么是“最小的、自由的、语言片段”都不好把握,连吕叔湘自己都说“这仍不十分明确”,“最好是用具体事例来给词划界”。然而用具体事例来给词划界又陷入了这样一个逻辑怪圈:不知道“词”是什么,却需要对具体事例作出判断从而反过来说明什么是词。
传统研究中对于词的界定,一般认可以下三个标准:结构稳固、意义凝聚、音节适长。然而,细细考究起来,无论哪一个标准,都有无法解决的难题(黄月圆,1995)。近十多年来,随着数学统计方法在语言学中的运用,从“频率”的角度对这一问题展开的研究增多,如胡明扬(1999)、梁源(2000)、吳为善(2003)、丁喜霞(2006)、李宇明、李晋霞(2007)、刘云(2009)、李晋霞(2013)。这些研究增进了我们对频率之于词和短语区分影响上的认识,但缺憾是缺乏大规模数据统计的支持,因此“频率”是否真的适合作为区分词和短语的一个标准还需进一步探讨。
二、基于N-gram串频率的验证
N-gram串指语流中接连出现的n个音节(在文本上表现为字)。N-gram串一般以标点符号为天然的分界线。例如:“天放晴了,最容易忘记雨伞”中包含的2-gram应该是:天放、放晴、晴了、最容、容易、易忘、忘记、记雨、雨伞;包含的3-gram应该是:天放晴、放晴了、最容易、容易忘、易忘记、忘记雨、记雨伞。
(一)“频率”相关研究问题分析及本文验证思路
综合目前所见学术界关于“频率”与“词”关系的研究,一般认为:“词感”与“频率”呈现“共变”关系,即词的频率越高,词感越强。从“词感”这一术语的使用可见,不同的词给人的“成词的感觉”(即哪个更像词)是不一样的。目前关于频率的研究还存在以下问题:
第一,“词感”的使用尽管体现了“连续性”这一概念,但又增添了“主观性”这一变数,即“词感”体现的是人的感觉,这种感觉会因人而异,胡明杨(1999)对此有所论述。除此之外,汉语中的词语个数上万甚至十几万,通过“词感”调查来划分词语的“连续性”不可行,且符合一部分人的“词感”不一定符合另一部分人的“词感”。对此,我们用“成词性”这一较客观的术语来指称从“短语”到“词”的汉字字符串成词能力的强弱。它指的是“字符串”的成词性的强弱,因此在未界定单位性质前用这一术语可以避免指称上的混乱。
第二,以往的研究多为举例式的考察,未能将全部汉语词语作为考察的对象,因此还不可得知“频率”作为界定词语能否成为一条真正的可行的标准。为此,我们收集整理了一个字符数达1.08GB的超大规模语料库,未分词,通过软件统计出2-gram字符串的频率并排序。这样做的好处一是避免了分词造成的偏差;二是事先不考虑“词”概念的使用,将“词、短语、无效串”(即“字符串”构成)统一无差别排序,这样就避免了我们在未界定出“词”之前却先使用了“词”的逻辑悖论。
我们的基本思路是:以统计结果中最高频的1000个2-gram串为分析对象,对它们进行属性标注,分别为词、短语或无效串。词的判别以《现代汉语词典》(第6版)、《现代汉语规范词典》(第2版)和《汉语大词典》(1997)为依据;没有任何意义的为无效串,其余为短语。这里需要说明的是,我们之所以只考察2-gram串,是因为汉语中约70%的词是双音节词。(王惠,2009)
(二)基于2-gram串验证存在的问题分析
虽然我们基于2-gram串进行统计可以摆脱基于分词所带来的问题,但它也带来了另外的一些问题,不过这并不会对考察造成太大的影响。基于2-gram串的考察所带来的问题主要有以下几个方面:
第一,字串的“耦合性”。
由于N-gram串只是几个字符的简单共现,并不涉及是否有意义,或处于一个结构中,所以,具有“耦合性”。例如“中国人民爱好和平”中的“国人”单独来看是一个词,但在该句子中并不处于同一个结构层次中。
对于这个问题,就以下几点分析,不会对本文的考察产生较大影响。
首先,大规模语料的抵消作用。由于本文使用的语料规模高达1.08GB,有近5亿字数,因此可以在一定程度上较少偏差,尤其是在超高频字串与中低频字串之间,一般不会出现高频词实际频率低于中低频字串的情况。
其次,从逻辑上来讲,一个“词”的串频低,其实际词频必然更低,而高频“短语”不会出现误差。这样的对比是有意义的对比。
再次,以N-gram串作为考察对象还有一个非常重要的考量,就是要撇开语义直接考察简单的形式共现是否对字串成词性产生重要影响。例如,Bybee(2007)认为在很多情形下,高频共现已经超过了语义成为字串结合的重要影响因素。
第二,“词”和“短语”的区分问题。
尽管我们以三部权威词典作为判定依据,但还是遇到了一些困难。
首先,有的字串具有词和短语的双重属性,只有在具体的句子语境中我们才能确定它到底是一个词还是一个短语。例如“不是”,当作“错处、过失”讲时,是一个名词,如“出手打人就是你的不是了”中的“不是”;但当作“否定”义讲时,“不是”是一个状中短语,而不再是一个词了。
其次,加不加“儿”的问题。“儿”字是一个很特殊的成分,代表儿化,虽然在音节上它可以依附于前面的成分,但它毕竟也占一个字符,这样就在音节长度和字符串长度上产生了矛盾。比如,词典中“一会儿”是一个词,但“一会”就不大好处理。
对于第二个问题,由于本文的目的是考察“高频是否一定是词”,因此,对于“词”和“短语”的区分,我们本着它是“词”的原则,如果能得出相反的结论,更是对本文论证的加强。
第三,“短语”和“无效串”的区分问题
尽管看起来将“短语”和“无效串”区分开来不会有什么难点,但这是在句子中,在有语境的情况下。其实,单独从字符串的角度来看,还是有一些难于处理的情况,例如“也不、有一、在这、这一、的话、里的、面的”。以“的字短语”为例,本文是将所有“的字结构”看作短语的,但有些情况却不能很好地做出判定,像“里的、面的”。
对“短语”和“无效串”的区分中存在的问题,本文采取以下原则及策略:
1.有意义即为短语,无任何意义、断裂的结构为无效串。
2.以紫光系统词库(153956条,实际包括词和短语)作为验证短语的一个策略,出现在里面的一定为短语。
三、语料收集与统计说明
本文的统计语料皆來自互联网,共1.08G,高达486408743个汉字,接近5亿,都是手工采集并经处理的有效文本内容,存为TXT.文件。语料采集的时间为:2012年4月~11月。
语料内容包括四部分:中国现当代文学作品(包括现当代知名作家的全部代表性作品,及其他一些比较知名的文学作品)、新闻(包括人民日报、新华网、中国青年报等媒体的新闻报道)、政府公文(包括法律类、政策类等官方文件)、网络小说(包括“都市言情、军事、科幻灵异、玄幻修真、游戏竞技、耽美同人”等类型)。这四部分语料的规模分别为312M、94.3M、92.2M、609M,共1107.5M,比例约为3:1:
1:
5。
以上语料都是从网络下载的,语料文本中存在着广告等无效信息,与原文不相关的成分如序言、后记等我们一并删除。对这些无效信息的处理,我们采用人工和机器处理相结合的方法:有些有一定规则的重复出现的信息我们用机器删除,零碎的不成规则的全部手工删除。语料下载收集与预处理工作是同时进行的。
本文使用的预处理及统计工具是“汉字串N-gram统计检索软件Cici V1.0”,该软件基于Java语言开发,支持GB级别中文文本语料N-gram串统计与检索,支持长度为1-10之间的汉字串统计。Cici是一个自由、绿色软件,用户可通过互联网直接获取。
四、统计结果分析
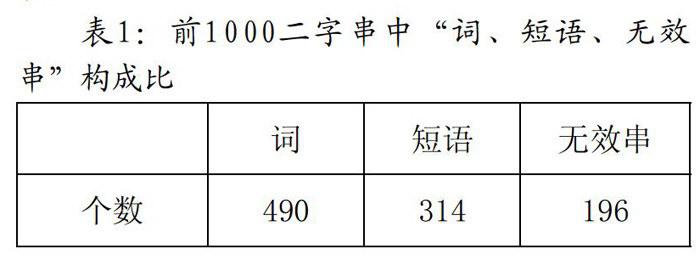
本文对1000个高频2-gram串的考察结果见表1。
从表1可以看出,在频率最高的前1000个二字串中,“词语”所占的比例最高,约占一半,短语次之,另外还有约五分之一比例的无效字符串。这至少说明以下几个问题:1.在汉语中频率非常高的二字串中,词语的比例很高,有很大可能性是词。2.尽管我们统计了一个超大规模的语料库,可以说分析了汉语中毗连频率最高的1000个二字串,但还是有一半的二字串不是词语,这说明,绝对的高频率毗连的二字串不一定是词,而且除了无效串,这里面还有很多是短语。3.想以高频率来抽取汉语中的词语的方法是不可行的,因为在我们抽取的超高频二字串中都有许多非词成分。
本文还发现,出现在超高频字串表中的无效串有以下特点:
第一,多和绝对高频的单字串在一起出现。
第二,很多无效串二字多处于跨层结构中,例如“况下”,多半情况下出现在“在……情况下”语境中。
第三,无效字串中不乏有短语化、词汇化倾向的例子,例如已有研究的“的话”(不过词典还未收录)——即处于跨层结构中;再如“的说”,其“成词性”要稍弱于“的话”。而“的话”的串频要远远高于“的说”,这说明,二字的高频共现,尤其是与虚词有关的高频共现确实容易诱发词汇化、语法化现象。
最高频1000个二字串中各属性字串构成比见表2。
由表2可知,(1)虽然我们选取的1000个二字串都是超高频二字串,但它们内部本身差异是很大的。譬如,频率最高的词与频率最低的词的频率之比约是20:1;频率最高的短语与频率最低的短语频率之比约是23:1;频率最高的无效串与频率最低的无效串频率之比约是15:1;频率最高的二字串与频率最低的二字串之比约是28:1。(2)在我们分成四块的考察中,每块里面都有一定比例的词语、短语以及无效串,而且它们的比例都是成“词>短语>无效串”的序列。(3)各块“词、短语、无效串”所占比例分别都与表1所统计比例类似,例如:排名251~500Z-字串部分词、短语、无效串所占比例分别为48.8%、32.8%、18.4%,与表1所示总体比例49%、31.4%、19.6%基本持平,但也表现出一定的差异,见图1。
基于数据分析,本章得出以下几个结论:
第一,不考虑其他因素,相邻共现字串的“高频率”不能作为其被判定为词的标准。通过上面对1000个超高频二字串属性的统计,可以看出,不论多么高的频率范围,总是会有一定比例的短语存在,而且其中最高频的“一个”都是短语,并没有因高频而“词化”。
第二,频率单独不能实现汉语短语到词的“连续统”划分。从1000字串分段分析中我们看到,词和短语是交叉分布的,而且每块各个比例都相当,因此,尽管从所有排序字串属性来说很可能高频词多,低频词少,但这同样还是不能掩盖词和短语交叉分布的事实。依据图1还可以发现,短语数并没有随排名降低而明显减少或增多,这说明短语分布的普遍性和均匀性以及汉字超强的组合能力。
第三,高频出现的字串属性“可能性”:词语字串>短语字串>无效字串。这一结论只具有统计学上的意义,是笼统的,不具有判定字串属性时的实际操作性,因为不论从“高频共现”(字串)的角度还是“高频出现”(有意义字串)的角度来说,它们既可以是词,也可以是短语,还有可能是无意义的字串。不论如何选取语料,这一事实不会改变。这意味着,在区分词和短语这一问题上,“频率”发挥的作用不会那么完全有效,需要进一步找出其适用范围,以及合适的统计方法。当然,对于不是以区分词和短语的研究来说,比如选取除词典以外的“分词单位”、计算机输入法词库的语言单位等,基于频率的选取是非常重要的一个来源。
第四,频率越高,字串的“有意义性”几率越很大。
在这里“有意义性”是指语言上是有意义的单位,具体指“词”和“短语”。只要是高频出现在一起的字串基本可以有一定的意义或高度熟悉感。
那么應该怎么来解释并非“频率越高,成词性越高”这一结论呢,本文认为原因如下:
第一,词语并不是人们表达的唯一常用单位,有很多短语也是人们经常使用的单位,但它们并未“词化”。
第二,词的产生过程并不与频率有必然的联系,人们构造新词只是使用上的需要,或者有可能只是部分领域使用的需要,因此不必然与高频率相联系。
第三,即使由所谓“高频共现”而产生的新词,也不与“笼统频率”存在必然联系,而只与“临界频率”有关,彭睿(2011)对此有详细论述。
五、结语
本文通过对近5亿字的现代汉语语料2-gram串的考察分析,得出了如下结论:“频率”不是“词”定义的应有之义,也不可直接作为界定词的标准;它在解决词和短语区分的模糊地带也不能广泛发挥作用;它在解决词和短语区分的模糊地带方面能否发挥重大作用还需进一步的分类探讨,这也是我们下一步将要进行的工作。
本文还存在一定的不足,后续研究中还可以从以下几个角度深入展开讨论:
第一,不同语料库的统计结果会有一些差异,因此有必要考察不同语体语料对词和短语区分可能产生的不同影响。
第二,对中、低频二字串部分加强定量考察,并与高频部分的统计结果作对照。
第三,对有意义耦合字串在文本中出现的真实频率进行统计,并考察其对区分词和短语产生的影响大小。
猜你喜欢
电脑爱好者(2021年12期)2021-06-22
中学课程辅导·高考版(2020年12期)2020-12-23
天天爱科学(2020年6期)2020-09-10
初中生学习指导·中考版(2020年5期)2020-09-10
疯狂英语·初中版(2019年11期)2019-01-02
中学生数理化·高一版(2017年2期)2017-04-25
哈尔滨理工大学学报(2016年2期)2016-09-12
海外英语(2013年3期)2013-08-27
海外英语(2013年1期)2013-08-27
海外英语(2013年6期)2013-08-27
