
基于上下文关系和TextRank算法的关键词提取方法
2018-01-16 02:40杜海舟陈政波钟孔露
上海电力大学学报 2017年6期
杜海舟, 陈政波, 钟孔露
(1.上海电力学院, 上海 200090;2.浙江华云电力工程设计咨询有限公司, 浙江 杭州 310000)
随着社会信息化的快速推进,网络上的信息以爆炸式的趋势飞速增长.若没有强有力的工具支持,个人在面对海量甚至大数据级别的文本数据时,很难进行高效阅读并提取知识.同样对于决策者而言,没有准确的信息支持很难在短时间内做出正确的决策.因此,迫切需要一个能自动提取文本关键信息的方法且以用户可读的方式呈现出来.自然语言处理技术是目前解决海量文本数据问题的有效技术之一.而特征关键词提取方法正是其中最基础和最关键的技术,其提取效果对后续的自动摘要、标题提取、网页去重,以及文本情感趋势分析等起决定性作用.
本文提出一种基于上下文关系和加权TextRank算法的关键词提取方法.通过分析中文文本中的词语组合来反映核心主题的客观事实,基于关键词的上下文关系并利用TextRank算法来提取最能表达文本主题思想的关键词.实验结果表明,相对其他同类技术,该方法能得到更理想的效果.
1 文本关键词提取方法概述
关于文本关键词提取问题,国内外很多学者已经进行了研究,并取得了一定的成果.研究中使用的主流方法集中于以下3类:一是以TF-IDF(Term-Frequency Inverse Document Frequency)算法为代表的基于统计特征的关键词提取方法;二是以LDA为代表的基于主题模型的关键词提取方法;三是基于词图模型的关键词提取方法.
在基于统计特征方面以改进TF-IDF算法最为流行,该算法是一种用于信息检索和数据挖掘的常用加权技术.HOW B C等人[1]提出了类别描述符,以此来减弱类别数据集偏斜带来的影响;李运田等人[2]则利用N-gram方法来提取特征值,可以提高关键词提取的准确率,但是在时间上无法满足用户快速检索的要求;李镇君等人[3]利用IPM收集用户阅读中行为的相关信息,将Document Triage引入到TF-IDF算法中,在一定程度上提高了文本关键词提取的准确率.上述研究者提出的改进算法在一定程度上提高了文本特征提取的效果,但其也有一定的不足,如基于统计特征往往会出现低频词获得高权重及不同关键词间权重值区分度不够等问题,表明仅仅依靠词语的统计特征而不考虑词语的联系进行关键词提取是不全面的.
在基于主题模型的关键词提取方面,LDA模型最具有代表性.PASQUIER C[4]将体现文本主题且联系紧密的句子聚类后提取主题关键词,以达到文本特征提取的目的.刘俊等人[5]利用词和主题在主题模型中的分布情况,以及通过构建关键词抽取模型来进行文本特征的选取.但上述模型最大的缺点就是过分依赖于训练数据集,训练集的数量和质量都直接影响最后关键词提取的准确率,致使其在应用方面受到较大限制.
针对上述问题,目前更多学者倾向基于词图模型的TextRank关键词提取算法.李鹏等人[6]通过引入社会化标签(tag)这种新颖的信息源并提出一种具体的实现方法——Tag-TextRank算法.基于词图模型的算法在各个评价指标上都优于传统的基于统计特征的关键词提取.方康等人[7]提出基于隐马尔科夫模型的加权TextRank关键词抽取算法.实验结果表明,该算法在提取单文档中较少的关键词时准确率比较理想.但该模型以“词袋”来单独考虑文本中的某一个词语,直接忽略上下文词语对于关键词的辅助作用以及其自身所带的重要主题信息,导致其效果不甚理想.
2 基于上下文关系和TextRank的文本关键词提取方法
针对上述方法存在的诸多问题,在目前应用最为广泛的词图模型基础上,本文提出了一种基于上下文关系和TextRank 算法的中文文本关键词提取方法.该方法以词语上下文依赖关系为基础,通过TextRank算法的不断迭代计算,以提高获取文本关键词的准确率.
2.1 上下文词语信息量关系
关键词的上下文是依据一个固定长度的“窗口”来选定的,选定窗口是表示该关键词左右一定范围内的词语集合.当然窗口长度并不是越长越好,鲁松等人[8]对关键词窗口长度对应的信息量进行了研究和实验,得出的结果如图1所示.

图1 中文文本上下文位置与其信息量关系
在利用最小代价的前提下,如何获得文本关键词上下文中最大信息量是基于上下文关系的关键词提取算法中急需解决的问题.结合相关文献的结论以及信息熵知识可知,关键词旁不同位置上的词语信息量可用定量来表示:某位置上的信息量由系统熵与在该位置上时的条件系统熵的减少量决定.通过信息熵,文本中词语的信息量就可以用定量表示出来.以关键词w为信息源头的信息熵为:
(1)
式中:p(w)——关键词w的词频.
H(W|VP)是上下文位置P时的条件熵,其计算公式为:
(2)
式中:p(wc)——上下文词语wc的词频.
上下文位置P的信息量IP的计算式为:
IP=H(W)-H(W|VP)
(3)
H(W|wc)是在上下文词语wc已知情况下的条件熵,即:
log2p(w|wc)
(4)
由此可知,不同位置上词语的信息量可被定量表示,即不同位置上的词语对关键词的贡献量可以用信息量表示.
2.2 TextRank算法
MIHALCEA R等人[9]通过改进著名的网页排序算法PageRank,提出了用于文本关键词选择的TextRank算法.TextRank算法的核心思想是一个节点的重要程度取决于相邻指向节点的数量,即从文本中选取出若干关键词并建立词图模型,利用投票机制迭代计算出每个关键词的重要程度,从而进行排序选出最能表达文本主题的关键词.从TextRank的原理可知,该算法支持带权重的迭代计算,同时根据中文语言特性以及文本特征选择的规则分析可知,TextRank算法在迭代计算时,重要的关键词将获得更高的投票分值,不重要的词语则拥有较低的投票分值.
2.3 基于上下文关系的TextRank模型
基于上下文关系的TextRank算法最重要的两个部分是带有上下文信息的文本特征选取和带有权重迭代计算的TextRank.其主要步骤为:
(1) 将给定的文本进行切割得到句子集合,并对句子集合中的每个句子做预处理,包括分词、筛选停用词等;
(2) 利用传统的基于统计特征选择方法筛选出文本句子集合中每一个句子的初始关键词集合;
(3) 依次对初始集合中的关键词进行上下文依赖关系的定量分析并带入计算,选择与关键词依赖程度最大的词语加入集合中,形成修正关键词集合;
(4) 将修正关键词集合中所有带有权重值的关键词组建关键词图模型,不断迭代计算并得到最终的文本关键词.
具体流程如图2所示.
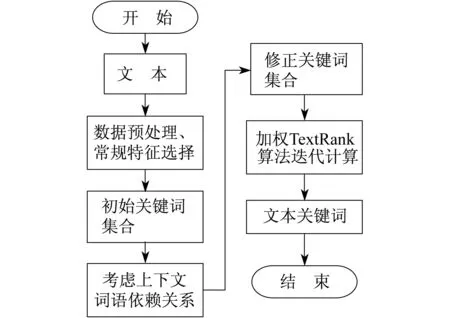
图2 考虑上下文依赖关系以及TextRank的文本特征选取整体流程
2.3.1 基于上下文依赖关系的关键词选取
本文利用互信息来衡量上下文中不同词对于关键词的依赖程度.依据式(1)至式(4)的核心思想,总结出互信息的计算公式为:
(5)
式中:wi——属于关键词k左右[a,b]之间的上下文词语;
P(wi|k)——在关键词k窗口范围内wi出现的概率;
P(k)——关键词k在文本中出现的概率.
通过计算,将互信息与阈值α进行比较,大于阈值的上下文被认为是对关键词贡献大的词语.
基于上下文依赖关系提取关键词的局部流程如图3所示.首先利用常见的特征选择方法选取权重较大的关键词作为初始关键词集合;其次对初始关键词集合当中的每一个词利用式(5)进行上下文依赖关系的定量分析,从而筛选出对关键词依赖度较大的上下文词,并将其加入到修正关键词集合中待进一步处理.

图3 基于上下文依赖关系提取关键词局部流程
2.3.2 加权TextRank词图模型
TextRank模型基于词图模型的文本特征选择,将特征选择转变为特征关键词重要性排序.将文档中的关键词及其关系组织成一张词图,并利用词图模型的迭代运算得出权重值最大的文本特征.根据上述分析可知,在构建词图模型时,基于上下文关系的加权TextRank算法应先从修正关键词集合中取出关键词以及各自对应的权重开始.
首先,构建初始图G=(V,E),由词语结点V以及其结点之间的边E组成,修正关键词集合中的关键词为词图的结点,每个词的权重系数为对应结点的权重.文献[10]提出利用滑动窗口来获得词与词之间的关系,文本参考该方法来实现关键词间的关系.本文使用较小的滑动窗口来进行词与词关系的提取.至此一个初步的加权TextRank初始模型就已建立.另外,基于TextRank的基本思想,利用投票机制来计算出每个关键词的重要程度进行排序,从而选出最能表达文本主题的词语.权重迭代计算式为:
S(Vi)=(1-d)+d×
(6)
式中:ln(Vi)——词图模型中表示指向词语结点Vi的结点集合;
(Vj)out——词语结点Vi指向其他结点的集合;
Wji——初始值为修正关键词集合中的权重;
d——阻尼系数,一般情况下取0.85.
文献[11]在PageRank算法中将阻尼系数定义为用户在到达某网页后继续往后浏览的概率值,同时该系数的存在也可避免在迭代运算过程遇到极端数据时而使迭代强行停止的情况.根据式(6)进行多次迭代运算直至达到所有的Wji都收敛为止,获得权重系数最大的Top-N词语即可作为文本的文本特征.
3 实验评估及结果分析
为能够验证基于上下文关系和TextRank算法的中文文本关键词提取方法的有效性,同时又不失样本的普遍性,本文选取电力领域新闻文本作为实验样本.电力领域具有完整的系统性、强烈的政策敏感性以及强大的社会发展导向性,所以以该领域的新闻文本作为实验语料库对于算法验证以及该技术的发展有着重要的意义.
本次实验的电力新闻文本语料库全部来自互联网,采用网络爬虫技术从北极星电力网采集6大类别的电力新闻,共10 500篇最新的电力新闻.其中,火力发电、风力发电、水力发电、核电以及智能电网5个类别的电力新闻文本各2 000篇,微电网这一类别由于数据有限,收集了500篇最新的新闻文本.与此同时,收录每篇电力新闻网页当中的关键词和网页的标题作为关键词标准来检验不同的算法.
本次实验的开发语言是JAVA,编译环境采用Eclipse Kepler Service Release 2,并利用中国科学院的中文分词软件来对数据进行预处理;所用硬件环境为Lenovo ThinkCentre M8400t-N000,其处理器为Intel(R) Core(TM) i7-3770,4 GB内存.
3.1 实验评价指标
在语料库中,实验的验证标准为每篇文章中的关键词,该关键词由网站上传新闻时一并提供,可以准确地提供该新闻的核心意思.关于评价标准,本文使用查准率、查全率以及F1值等方面来评价算法.衡量文本特征关键词的提取效果应从提取正确率和提取正确量两个方面加以考虑.查准率用于描述提取的正确关键词占提取总量的比重,查全率表明被提取出来的关键词占文本所有关键词的比例;F1值是查全率和查准率两个评价指标综合效果的体现.从电力领域的语料库中检索到的关键词可以大致分为A,B,C,D 4类,如表1所示.
查准率(Precision)和查全率(Recall)的计算公式分别为:
(7)
(8)
除了对文本特征进行两个指标的评价外,还将F1-measure值作为另一个评价标准,即结合查准率和查全率两者使用情况而进行的综合评价:
(9)

表1 语料库文本特征分类
3.2 实验与分析
本文经过网络爬虫、预处理、权重计算、特征选择以及精度计算等步骤,将基于上下文关系和TextRank算法选取的文本权重TOP-10的文本关键词与文章标准的关键词进行对比.同时,与传统的TF-IDF算法的结果进行比较,进一步验证本文算法的高效与精确性.
首先,利用传统的TF-IDF算法得到文本的初始关键词集合,然后根据上文描述的上下文关系对其进行修正,得到修正关键词集合,其中阈值α取0.01.依据文献[8]的结论可知,对于85%的信息量可以通过关键词左边8个位置以及右边9个位置的窗口来获取,故窗口取值为[-8,9].最后,利用加权的TextRank的词图模型对修正关键词集合进行多次迭代运算,最后选取权重TOP-10的文本特征词作为最终的文本特征.将选取结果与标准的关键词进行多指标的对比,其结果如表2所示.

表2 基于不同算法的电力领域新闻文本特征关键词选取实验结果 %
由表2可知,相较于传统的TF-IDF,基于上下文关系及TextRank算法在查准率、查全率和F1-measure值3个指标中都获得了较理想的结果.
为了进一步验证本文算法在电力行业各个子领域中的准确性,本文选取语料库中的6大类别新闻文本数据,分别用上述两种算法进行文本关键词提取.依据上文所述的评价标准,对相应权重结果进行查准率、查全率以及F1-measure的计算,结果如表3所示.
由表3可以看出,在电力行业各个不同子领域内,本文算法比传统算法都有明显提升.其中,本文算法比传统算法在查准率上平均高出近8%~9%,同时在各个子领域上也都有不同程度的提高.在查全率方面同样高于传统算法,其中火力发电和水利发电两个类别体现得尤为明显.由此也进一步证实了本文算法同样适合于各个子领域的文本关键词的提取,并且结果较传统算法更理想.
为了更直观地体现TF-IDF算法与基于上下文关系和TextRank的算法获得正确关键词的情况,又进行了两种算法在取不同数量的关键词下平均正确关键词数量的实验.实验对象为整个电力行业内的10 500篇电力新闻文本,其结果如图4所示.
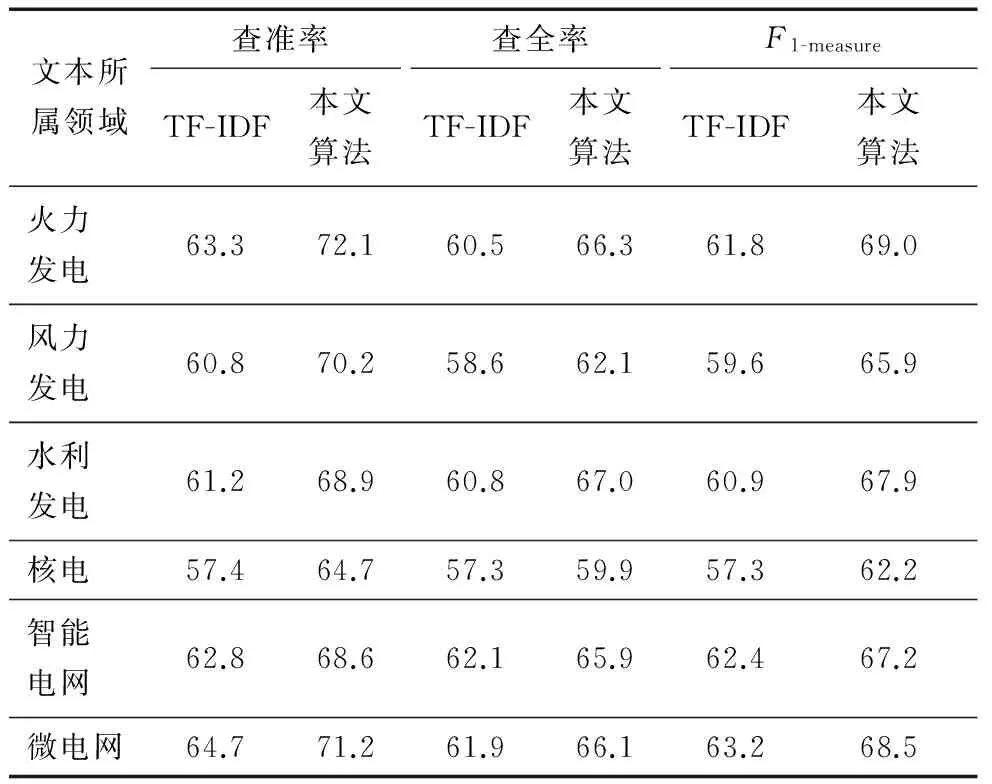
表3 TF-IDF和本文算法在电力行业不同子领域文本语料关键词提取实验结果 %
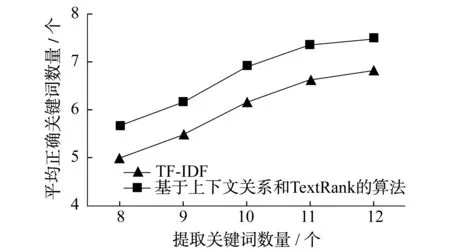
图4 TF-IDF算法与基于上下文关系和TextRank
综上所述,与传统的TF-IDF算法相比,基于上下文关系和TextRank算法在查准率、查全率和F1-measure,以及获取平均正确关键词数量方面都有大幅度的提升.
4 结 语
通过实验分析可知,相较于传统的TF-IDF算法,采用基于上下文关系以及TextRank算法在查准率、查全率和F1-measure方面有4%~7%的提升;在电力子领域的实验中,在查准率上提高了6%~8%,在查全率以及F1-measure方面提升了5%~7%.因此,本文提出的方法能有效提高文本关键词提取的准确率,可以为文本关键词提取技术提供一种新的思路.
[1] HOW B C,NARAYANAN K.An empirical study of feature selection for text categorization based on termweightage[C]//Proceeding of the 2004 IEEE /WIC/ACM International Conference on Web Intelligence.Washington DC:IEEE Computer Society,2004:599-602.
[2] 李运田,吴琼,郑献卫.改进的TF-IDF模型在特征抽取中的应用[J].工业控制计算机,2014(2):51-52.
[3] 李镇君,周竹荣.基于Document Triage的TF-IDF算法的改进[J].计算机应用,2015(12):3 506-3 510.
[4] PASQUIER C.Task 5:single document keyphrase extraction using sentence clustering and latent dirichlet allocation[C]//Proceedings of the 5th International Workshop on Semantic Evaluation.Stroudsburg,PA,USA:Association for Computational Linguistics,2010:154-157.
[5] 刘俊,邹东升,邢欣来,等.基于主题特征的关键词抽取[J].计算机应用研究,2012,29(11):4 224-4 227.
[6] 李鹏,王斌,石志伟,等.Tag-TextRank:一种基于Tag的网页关键词抽取方法[J].计算机研究与发展,2012(11):2 344-2 351.
[7] 方康,韩立新.基于HMM的加权Textrank单文档的关键词抽取算法[J].信息技术,2015(4):114-116.
[8] 鲁松,白硕.自然语言处理中词语上下文有效范围的定量描述[J].计算机学报,2001(7):742-747.
[9] MIHALCEA R,TARAU P.TextRank:bringing order into texts[C]//Proceedings of Conference on Empirical Methods in Natural Language Processing,Barcelona,Spain,2004:404-411.
[10] CORMODE G,GAROFALAKIS M.Sketching probabilistic data streams[C].Acm Sigmod International Conference on Management of Data,2007:281-292.
[11] PAGE L.The PageRank citation ranking:bringing order to the web[J].Stanford Digital Libraries Working Paper,1998,9(1):1-14.
猜你喜欢
当代陕西(2020年17期)2020-10-28
现代电子技术(2018年20期)2018-10-24
现代电子技术(2018年16期)2018-08-21
人大建设(2018年5期)2018-08-16
现代情报(2018年11期)2018-01-07
现代电子技术(2017年23期)2017-12-20
计算机应用(2016年10期)2017-05-12
应用科技(2015年5期)2015-12-09
河南科技(2014年15期)2014-02-27
中国管理信息化(2009年10期)2009-06-19
