
基于数据匿名化的隐私保护研究
2018-01-16 02:42孔志伟魏为民
上海电力大学学报 2017年6期
孔志伟, 魏为民, 杨 朔, 酆 华, 赵 琰
(上海电力学院 计算机科学与技术学院, 上海 200090)
随着网络的发展,各种数据的爆炸性增长给人们带来了诸多信息,但与此同时也产生了许多安全隐患.其中,数据发布作为一项将数据库中的数据直接展示给公众的技术,文献[1]至文献[3]指出,经过简单处理的源数据仍有可能暴露数据所有者的隐私,可能对个人或公司造成严重损失.例如企业公布的员工工资信息,即使将员工姓名删除后发布,攻击者通过对比数据等方式仍然可能获得员工的姓名,从而得到隐私数据.匿名数据发布就是针对这一问题而提出的解决方法之一.
匿名数据发布是一种基于限制发布的隐私保护技术,其目的在于平衡数据的安全性和有效性之间的关系,使得发布的数据既不失可用性,又能保证隐私性.目前,匿名数据发布的主要研究方向分为数据匿名化模型和算法两个方面.
1 数据匿名化模型
本文均以关系型数据表为例来介绍相关研究,在待发布数据表T中,每一行代表一个个体,每一列代表个体的属性.如在常见的医疗数据表中,每一行代表一个患者,每一列代表患者的相关属性,如表1所示.

表1 医疗数据
个体属性大致分为3类:显示标识符(ExplicitIdentifier,ID),能唯一地确定一个个体的属性,如姓名、身份证号;准标识符(Quasi-Identifier,QI),联合起来能唯一确定一个个体的最小属性集合,如邮编、生日、性别等联合起来就可能是准标识符;敏感属性(Sensitive Attributes,SA),包含隐私的数据,但是无法唯一确定一个个体,如薪水、患病信息.
1.1 传统的匿名模型
传统的匿名模型一般指的是在匿名模型刚提出时的一种不针对特定环境、特定应用的匿名模型.其特点是相对简单,能够在一般情况下保证数据的安全性和有效性.
SWEENEY L在2002年的一篇文章中提出了k-anonymity隐私保护模型[4].在数据表T中,每条记录的准标识符至少与其他k-1条记录相同,即k条记录之间无法相互区别,则称这k条记录属于一个匿名组.
表2是将表1进行匿名化后的结果.由表2可以看出,任意一条记录都无法与另一条区分,即满足2-anonymity模型.
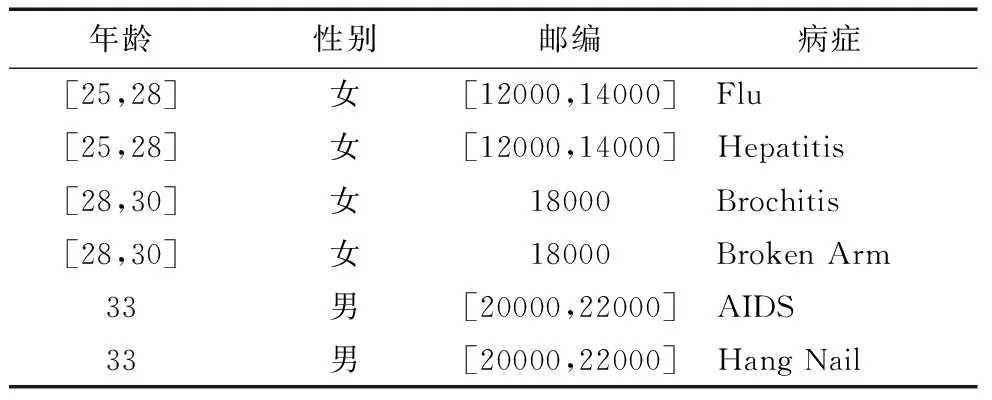
表2 医疗数据2-匿名
然而k-anonymity无法抵御Homo-geneity Attack(同质攻击)和Background Knowledge Attack(背景知识攻击),这是由于该模型对敏感属性没有约束[5].(α,k)-anonymity模型[6]在此基础上进行了改进,在满足k-anonymity的前提下保证了每个匿名组中出现的敏感属性的百分比不高于α.l-diversity保证了每个匿名组的敏感属性具有至少l个不同值,这样可以使得攻击者最多以1/l的概率确认某个样本的敏感信息.t-closeness模型[7]是在l-diversity的基础上考虑了敏感属性的分布问题,它要求所有匿名组的敏感属性分布应尽量接近该属性的全局分布.
1.2 面向特定环境的匿名模型
面向特定环境的匿名模型的基本思想与传统匿名模型无异,只是关注的重点不同.常见的有针对多敏感属性、属性权重以及个性化敏感属性的匿名模型等.
1.2.1 针对多敏感属性的匿名模型
一般的数据表结构往往只有一个敏感属性,因此传统的匿名模型并没有考虑多个敏感属性的问题.然而在实际情况中却常出现多敏感属性的数据表.针对这种数据表,文献[8]提出了一种基于多维桶分组技术的模型,该模型能够在一定程度上保护多敏感属性数据的安全发布.文献[9]建立了差异化多敏感属性lq-diversity模型,其定义如下:对于含q个敏感属性的数据表T中的匿名组而言,如果任意匿名组中所有敏感属性的每一维敏感属性值都满足l-diversity 性质,那么就称该数据表满足lq-diversity模型.
1.2.2 考虑属性权重匿名模型
在发布的数据表中,准标识符中的不同属性通常具有不同的重要程度,然而这一点在传统的匿名模型中却没有体现出来.文献[10]通过对属性赋予不同的权重,优化了在特定情况下不同属性的泛化程度,从而在一定程度上解决了该问题.
1.2.3 个性化匿名模型
并非所有的敏感属性都需要被保护,同样的,相同的敏感属性在不同的数据拥有者看来其重要程度也不相同,如一个人对患感冒和绝症的反应截然不同;城市居民和农村居民对工资的关注度不同.(α,l)多样化k-匿名模型提出了敏感属性分级的概念,实现了敏感属性的个性化保护问题[11].
数据匿名化模型是实现数据匿名化的第一步,其数据样式各异,发布环境也不尽相同.传统的匿名模型易于实现,但抗攻击性较差;面向特定环境的匿名模型种类繁多,且具有较强的针对性,但过分依赖于特点数据表的特征,适用性较低.
2 数据匿名化算法
数据匿名化算法是实现数据匿名化模型的过程,目前提出的算法有泛化、抑制、聚类、微聚类、分解、置换[12],其中比较热门的算法是泛化和聚类.
2.1 采用泛化的算法
泛化就是指将具体属性值用不具体的值来表示,如将原本显示为“回族”的属性用“少数名族”来代替.通过泛化可以使发布的数据具有一定的保密性和真实性,很好地实现了隐私保护的效果.
早期的泛化算法有MinGen算法、Datafly算法以及μ-Argus算法[13],然而这些算法的效率并不高.广泛使用的Incognito算法[14]通过首先构建包含所有全域泛化方案的泛化图,再自底而上对初始数据泛化,逐步裁剪优化泛化图,直到满足k-anonymity原则.该算法的实现步骤如下.
输入:原始表T,准标识符Q,一组多维表(一维是Q中的每个准标识符)
输出:一组全域泛化k-anonymity的表T
C1={在Q中的属性的域泛化层次结构的节点}
E1={在Q中的属性的域泛化层次结构的边界}
q=一个空q//q表示数列
fori=1 tondo
//Ci和Ei定义一个泛化图
Si=Ci
将{r}插入到q中,将q按照权重排列 //r表示所有属于Ci且不在属于Ei边界内的节点
Whileq非空 do
n=从q中删除第一个 //n表示节点
ifn没有标记 then
ifn是根 then
frequencySet= 相对于使用T的节点属性的计算频率集
else
frequencySet= 相对于使用父类频率集的节点属性的计算频率集
else if
使用frequencySet相对于节点属性检查k-anonymity
if T相对于节点属性是k-anonymity then
标记所有n的引导泛化
else
从Si中删除n
在q中插入n的引导泛化,使得q按权重排列
end if
end if
end while
Ci+1,Ei+1=泛化图(Si,Ei)
end for
returnSn中属性的投影到T和多维表中
泛化算法容易出现过度泛化现象,即泛化后属性值的有效性很低,或变成无用属性.为此,文献[15]提出了泛化约束的匿名算法,可以在一定程度上优化泛化操作.
2.2 采用聚类的算法
基于泛化的匿名算法有一个明显的缺点,那就是数据可用性较低,基于聚类的匿名算法可以在一定程度上解决这一问题.聚类是近年来提出的新技术,核心思想是根据数据的特点,将其分到不同的簇中[16].同一个簇中的数据相似,不同簇的数据有较大差距.
文献[17]提出了两种聚类算法,分别是r-gather和r-cellular.这两种算法的相似之处是发布每个聚类的中心、半径和相关属性,区别是r-gather只发布一个最大的半径,而r-cellular则发布每个聚类的半径.FUNG B C M等人提出了一种针对聚类分析的启发式数据隐藏发布方法[18].杨高明等人设计了聚类与概化/隐匿相结合的(α,k) -匿名聚类算法[19].其中,针对单敏感值表的具体算法步骤如下.
输入:数据表TD,匿名约束k,指定的敏感值s及其频率约束α

(1)C=φ;
(2) 计算数据表TD的相异矩阵Matrix(TD);
(3) 任选一点ti作为簇Ci的中心点;
(4) 选择距离ti最近的k-1 个数据点加入Ci,调整簇Ci的质心;
(5)TD=TD-Ci;C=C+Ci;
(6) 在剩余数据集TD中选择一点作为簇Cj的质心;
(7) 若 |TD| >k,转到步骤 4,否则放弃步骤(6);
(8) 对每个包含敏感值s的簇,计算s的频度,并把簇按照s的频度由大到小排序;
(9) 选择s频度最大的簇Ck,寻找簇Ck内距离质心最远且使簇Ck不满足(α,k) -匿名约束的l(l (10) 循环执行步骤(9),直到所有簇内的频 度小于α; (11) 将未分配的剩余簇加入距离他们较近的簇,且使加入后敏感值的频率不大于α. 除此之外,姜火文等人考虑现有的匿名方案缺少分类考察准标识符属性概化,提出了一种贪心聚类匿名方法[20].柴瑞敏等人针对k匿名算法的不足,提出了(k,L)匿名聚类算法,该算法在实现隐私保护的同时,减少了数据信息的损失,缩短了运行时间[21].唐印浒等人提出了变长聚类V-MDAV算法,在选择聚类种子时应加入种子记录的权重值,进而提出了W-V-MDAV算法,又将W-V-MDAV算法与k-means算法结合,大大降低了处理大数据集时的时间开销[22]. 采用泛化和聚类的数据匿名化算法比较如表3所示. 表3 两类数据匿名化算法比较 从表3可以看出,对于一般轻量级的数据匿名化而言,可采用泛化相关算法;对于想体现数据之间关联性的数据匿名化而言,可使用聚类相关算法. 随着越来越多的人对匿名数据发布技术的关注,该技术的研究热度也在逐渐提高[26-27].就目前而言,该技术的发展趋势如下. (1) 基于动态数据的匿名发布 目前社会中存在的许多数据,如个人医疗信息,都是随着时间的变化而变动的.相关研究表明,传统的应用于静态数据表的匿名算法在动态数据结构中已然失效[28],因此亟需基于动态数据的匿名发布算法. (2) 基于分布式数据的匿名发布 随着大数据时代的到来,数据的存储结构也在发生着变化,从结构化到非结构化,从集中式到分布式.因此,传统的匿名模型和算法在新的数据存储结构中可能不再适用[29-30]. (3) 基于位置服务的匿名发布 随着车载网络、车辆导航等一系列功能的实现,基于位置服务的匿名发布功能变得越来越重要,如轨迹隐私保护[31-33].一方面,用户要向服务商提供位置信息以便获取需要的导航信息;另一方面,用户不想暴露自身的位置隐私,以免遭到攻击者的攻击. (4) 基于社会网络的匿名发布 在社会网络中,每个个体用节点表示,而节点与节点之间的任何关联都可能称为隐私,同时,节点自身的位置以及社会网络图的结构都可能导致隐私的泄露[34-35].在如今网络连接世界的社会中,人们在网络上的相互联系也是一个社会网络,从日常的购买记录、浏览信息中不难分析出个人的隐私.因此,社会网络中的数据发布也成为研究的热点. 近些年,基于匿名的数据发布技术已经开始应用于无线传感器网络等领域,是一项前景广阔的技术.本文从匿名数据发布模型和算法出发,介绍了近些年的一些研究成果,客观分析了已有的技术,并对今后该领域的研究前景提出了展望. [1] NARAYANAN A,SHMATIKOV V.Robust de-anonymization of large sparse datasets[C]//Proceedings of the 2008 IEEE Symposium on Security and Privacy,2008:111-125. [2] SRIVATSA M,HICKS M.Deanonymizing mobility traces:using social network as a side-channel[C]//ACM Conference on Computer and Communications Security,2012:628-637. [3] BLOND S L,ZHANG C,LEGOUT A,etal.I know where you are and what you are sharing:exploiting P2P communications to invade users′ privacy[C]//Proceedings of the 2011 ACM SIGCOMM Conference on Internet Measurement Conference,2011:45-60. [4] SWEENEY L.K-anonymity:a model for protecting privacy[J].International Journal on Uncertainty,Fuzziness and Knowledge-Based Systems,2002,10(5):1-14. [5] MACHANAVAJJHALA A,KIFER D,GEHRKE J.L-diversity:privacy beyondk-anonymity[J].Acm Transactions on Knowledge Discovery from Data,2006,1(1):3. [6] RAYMOND CHI-WING W,LI J,ADA WAI-CHEE F,etal.(α,k) -Anonymity:an enhanced k-anonymity model for privacy-preserving data publishing[C]//Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,2006:754-759. [7] LI N,LI T.T-closeness:privacy beyondk-anonymity andl-diversity[C]//Proceeding s of the 23rd International Conference on Data Engineering,2007:106-115. [8] 杨晓春,王雅哲,王斌,等.数据发布中面向多敏感属性的隐私保护方法[J].计算机学报,2008(4):574-587. [9] 左苏楠,卞艺杰,吴慧.差异化多敏感属性Lq-Diversity模型和算法[J].计算机系统应用,2016,25(2):173-179. [10] 徐勇,秦小麟,杨一涛,等.一种考虑属性权重的隐私保护数据发布方法[J].计算机研究与发展,2012,49(5):913-924. [11] 阚莹莹,曹天杰.一种增强的隐私保护K-匿名模型——(α,L)多样化K-匿名[J].计算机工程与应用,2010,46(21):148-151. [12] 刘湘雯,王良民.数据发布匿名技术进展[J].江苏大学学报(自然科学版),2016,37(5):562-571. [13] SWEENEY L.Achievingk-anonymity privacy protection using generalization and suppression[J].International Journal on Uncertainty,Fuzziness and Knowledge-Based Systems,2002,10(5):571-588. [14] LEFEVRE K,DEWITT D J,RAMAKRISHNAN R.Incognito:efficient full-domainK-anonymity[C]//ACM SIGMOD International Conference on Management of Data,2005:49-60. [15] 朱卫红,潘巨龙,时磊.一种泛化约束的(K,L)-匿名算法[J].中国计量学院学报,2016,27(1):80-85. [16] 倪巍伟,陈耿,崇志宏,等.面向聚类的数据隐藏发布研究[J].计算机研究与发展,2012,49(5):1 095-1 104. [17] AGGARWAL G,FEDER T,KENTHAPADI K,etal.Achieving anonymity via clustering[C]//ACM Sigmod-Sigact-Sigart Symposium on Principles of Database Systems,2006:153-162. [18] FUNG B C M,WANG K,WANG L,etal.A framework for privacy-preserving cluster analysis[C]//IEEE International Conference on Intelligence and Security Informatics,2008:46-51. [19] 杨高明,杨静,张健沛.聚类的(α,k)-匿名数据发布[J].电子学报,2011,39(8):1 941-1 946. [20] 姜火文,曾国荪,马海英.面向表数据发布隐私保护的贪心聚类匿名方法[J].软件学报,2017,28(2):341-351. [21] 柴瑞敏,冯慧慧.基于聚类的高效(K,L)-匿名隐私保护[J].计算机工程,2015,41(1):139-142. [22] 唐印浒,钟诚.基于变长聚类的多敏感属性概率k-匿名算法[J].计算机工程与设计,2014(8):2 660-2 665. [23] 陈伟鹤,丁蕾蕾.匿名最短路径的top-k路径贪心泛化算法[J].计算机工程,2016,42(1):116-120. [24] 吴响,臧昊,俞啸.基于抽样路径的K-匿名隐私保护算法[J].电子技术应用,2016,42(12):115-118. [25] 王智慧,许俭,汪卫,等.一种基于聚类的数据匿名方法[J].软件学报,2010,21(4):680-693. [26] 周水庚,李丰,陶宇飞,等.面向数据库应用的隐私保护研究综述[J].计算机学报,2009,32(5):847-861. [27] 刘喻,吕大鹏,冯建华,等.数据发布中的匿名化技术研究综述[J].计算机应用,2007,27(10):2 361-2 364. [28] 张飞.基于动态数据集的匿名化隐私保护技术研究[D].重庆:重庆交通大学,2013. [29] 方炜炜,周长胜,贾艳萍,等.基于SMC的分布式隐私保护数据发布研究[J].系统工程与电子技术,2012,34(11):2 390-2 395. [30] 宋玉.基于分布式数据库数据隐私安全的K-匿名模型研究和改进[D].昆明:云南大学,2011. [31] 霍峥,孟小峰.轨迹隐私保护技术研究[J].计算机学报,2011,34(10):1 820-1 830. [32] 潘晓,肖珍,孟小峰.位置隐私研究综述[J].计算机科学与探索,2007,1(3):268-281. [33] 赵婧,张渊,李兴华,等.基于轨迹频率抑制的轨迹隐私保护方法[J].计算机学报,2014,37(10):2 096-2 106. [34] 刘向宇,王斌,杨晓春.社会网络数据发布隐私保护技术综述[J].软件学报,2014,25(3):576-590. [35] 罗亦军,刘强,王宇.社会网络的隐私保护研究综述[J].计算机应用研究,2010,27(10):3 601-3 604.
3 数据匿名化的发展趋势
4 结 语
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
计算机应用(2022年8期)2022-08-24
党员生活·下(2020年3期)2020-04-20
党员生活(2020年2期)2020-04-17
计算机系统应用(2020年8期)2020-03-22
泰山学院学报(2019年6期)2020-01-14
铁道通信信号(2018年10期)2018-12-06
图书馆建设(2015年11期)2015-08-24
天津商务职业学院学报(2015年2期)2015-02-28
天津商务职业学院学报(2015年1期)2015-02-28
