
面向电力领域的微博评论情感分析
2018-01-16 02:40雷景生
上海电力大学学报 2017年6期
宋 硕, 雷景生
(上海电力学院 计算机科学与技术学院, 上海 200090)
作为近几年新兴的网络社交媒体,微博凭借其便捷性、原创性和草根性的特点,得到了快速发展,成为了当今自媒体时代不可分割的一部分.在电力行业,为了及时获取用户对电力行业热门事件的态度并进行舆情分析,面向电力领域的微博评论情感分析具有重要意义.目前,在舆情方面的研究主要集中在商品评论[1]、电影评论[2]等非电力领域.而且相关情感词典[3]、情感计算[4]的研究也在不断深入,但针对电力领域微博评论的研究相对较少.有学者采用最大熵[5]、多项式贝叶斯分类模型[6]等方法对短文本情感进行分析,或基于话题聚类及情感强度对中文微博舆情进行分析[7],但这些方法都无法原封不动地照搬到电力领域.因此,本文面向电力领域微博,生成评论结构关系树,结合扩展情感词典和支持向量机方法对电力微博评论进行分析.
1 相关理论基础
1.1 电力微博评论
一般的微博评论都存在文本长度短小、语言随意等特点[8],这些特点在电力微博评论中也普遍存在,此外,电力微博评论还具有以下特点.
(1) 省略事件 电力微博中的评论主要是针对电力事件的评论,这些事件均存在于主帖或其他跟帖中,所以评论中对这些事件经常采用省略或指代的形式,甚至不被提及.
(2) 时效性短 微博话题的发展通常有初始、成长、繁荣(爆发)和递减4个阶段[9].电力领域话题通常时效性较短.
(3) 专业性强 电力微博的文本和评论中通常含有大量专业词汇,这些词汇通常是不包含情感因素的客观词汇,但传统情感分析中经常会误判这些词汇.例如,“阻抗”“阻值”“阻尼振荡”都是含有“阻”字的客观词汇,但传统方法均会将这些词拆分并将“阻”字归为消极词汇.
在评论关系上,假设Cx是某用户对电力微博文本T进行的评论,文本与评论的关系记作(T,Cx),则评论之间的关系有以下3种.
(1)Cy的评论针对对象为Cx,Cy是Cx的子评论,记作
(2)Cy的评论针对对象为T,Cy和Cx在显示上邻接,在内容上相互关联,记作[Cy,Cx].为明显表示出二者的邻接关系,以[Cx,Cx+1]代替.在实际应用中,这种关系往往存在于多个评论中,Cx之后的多个评论组成一个有效的文本(网络上称之为“盖楼”),此处将这种关系记作[Cx,Cx+1,Cx+2,…,Cx+L-1],其中L为楼层链的长度.如Cx为“深圳供电主网建设投资16.76亿元”,Cx+1为“16.76亿元用于40个重点项目建设”.
(3)Cy的评论针对对象为T,但二者并不存在[Cy,Cx]的关系,则认为二者包含间接关系,不进行考虑.
综上所述,电力领域微博评论的结构关系如图1所示.

图1 电力领域微博评论结构关系
1.2 文本情感分析
文本情感分析也称意见挖掘,它使用自然语言处理、文本挖掘和计算机方法来提取文本中的主观意见,旨在识别自然语言中所表达观点的极性和强度[10].按照颗粒度划分,其主要任务可分为词语级、短语级和篇章级情感分析[11].情感属性分为积极、消极、客观3类,积极的情感特征包括肯定、主动、踊跃、乐观,正面属性大于负面属性的情感也被归为积极一类;消极的情感特征包括否定、悲观、失望、消沉,负面属性大于正面属性的情感也被归为消极一类.
假设电力微博文本T包括n个主题,UT表示这n个主题的集合;评论Cx包括m个主题,Ux表示这m个主题的集合,Txy表示Ux中第y个主题,Pxy为Txy对应的情感倾向,ωxy为Txy对应的权重,则Cx的情感倾向为:
(1)
假设Cxs是Cx的子评论,Cxs包括k个主题,Uk表示这k个主题的集合;∃Tk∈Uk,当Tk∈Ux且Tk∉UT,则出现主题漂移.
1.3 文本情感分类
1.3.1 特征标注与特征选择
特征抽取的方法有很多,常用的有细粒度情感特征抽取方法[12]和标签特征提取算法[13].特征权重决定该特征在文本分类中的重要程度,目前大多采用统计量来赋予权重,常用的方法为布尔权重和TF-IDF,由于电力领域拥有较强的专业性,本文选择绝对词频来计算特征权重.
1.3.2 情感分类
常用的分类算法有很多,其中支持向量机(Support Vector Machine,SVM)[14]的最大特点是根据结构风险最小化准则,以最大化分类间隔构造最优分类超平面来提高学习机的泛化能力,它可以较好地解决电力评论高维数、非线性、专业性强等问题.对于情感分类问题,支持向量机算法可以根据电力评论区域中的电力专有词汇计算该区域的决策曲面,确定该区域中专业词汇的类别,因此支持向量机算法适用于电力领域.本文设计了“积极分类器”和“消级分类器”两个判别器,当两个分类器判定结果都为“否”,则将该特征归为“客观”;当两个分类器判定结果都为“是”,则在之后的扩展词典中作进一步处理.
2 情感分析流程
面向电力领域微博评论的情感分析流程如图2所示.
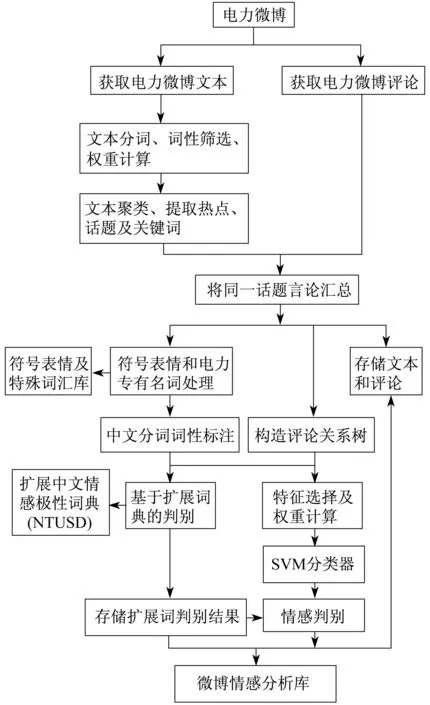
图2 电力领域微博评论情感分析流程
具体过程如下:利用url,从网络中利用网络爬虫技术抓取电力行业文本、评论等信息;文本分词、文本词语的词性筛选以及词语的权重计算;文本聚类,提取出热点话题及关键词;根据关键词将相同话题、相关评论转发、点赞等信息汇总;对汇总后的数据进行符号表情处理,构造如图1所示的结构关系树;使用扩展情感词典的方法动态扩展情感词典,使用支持向量机的方法设计情感极性分类器.
2.1 电力微博评论处理
2.1.1 符号表情处理
微博评论文本中的符号表情十分常见,当文本中出现超过阈值个数v的非中文符号时(电力领域文本阈值v=5),我们将这段文本定义为“符号表情”,此时根据“搜狗输入法”提供的符号表情库[15],将其导入“符号表情库”,在处理过程中将其处理为相应的中文含义.如“O(∩_∩)O”替换为“哈哈”,“(∘•ˇ^ˇ•∘)”替换为“不高兴”.如果文本中出现的符号表情并未在搜狗输入法提供的符号表情中出现,则选择相似度最高的符号表情进行替换.如“(╯‵□′)╯︵ ┻┻”和“(╯‵□′)╯︵ ┻━┻”的相似度为0.909,也可以替换为“掀桌”,并收录到符号表情库.符号表情近似度公式为:
(2)
式中:e1,e2——要比较的两个符号表情;
l1,l2——两个符号表情的字符长度;
D(e1,e2)——e1和e2之间的编辑距离.
2.1.2 编码切换
当出现繁体字、“火星文”等非简体编码时,本文使用EditPlus编辑器将其他编码统一转换为GB2312编码.
2.1.3 文本分词和词性筛选
本文使用NLPIR汉语分词系统(又名ICTCLAS2013)进行文本分词和词性筛选,NLPIR包括中文分词、词性标注、命名实体识别、用户词典等功能,支持多种编码[16].
2.2 评论关系树
2.2.1 评论关系
在
在[Cx,Cx+1,Cx+2,…,Cx+L-1]中,L个楼层共同倾向于一种观点,可以进行整体分析.如某微博观点是“电力行业将退出历史舞台”,1楼评论为“小编胡言乱语”,2楼评论为“小编信口雌黄”,3楼评论为“小编颠倒是非”,这3个观点作为整体在反对主题观点.判断评论间是否存在依存关系比较难,这里我们根据固定句式和正则表达式来判断,一般“盖楼”都有相同字数、相同韵律的固定句式,盖楼的评论多数为相互调侃、相互取乐.
2.2.2 生成评论关系树
评论关系树的根节点为微博新闻,按时间顺序将所有评论依次提取,先判断

图3 树的节点数据结构
图3中,Text为文本域;Parent为父节点;Child为子节点;Upstairs为[Cx,Cx+1,Cx+2,…,Cx+L-1]关系中的上一楼层(1楼Upstairs为空);Emotional为该节点的情感极性.
生成评论关系树算法为:
root←T;//评论关系树的根节点为微博新闻
root->text←T->text;
for(Cxin Uc)
currentNode←Cx;
currentNode->text←Cx->text;
if(< Cx,Cy> is existed)//父子关系存在
currentNode->parentld4←Cy;
Cy->childList.add(currentNode);
end if;
if([Cx-1,Cx] is existed)//楼层链关系存在
currentNode->prefLev←Cx-1;
end if;
if(currentNode->parentld is null)
currentNode->parentld←root;
root->childList.add(currentNode);
end if;
end for.
2.2.3 判别子评论关系
假设积极属性为P,消极为N,客观为O.在
Cx->T∈P,
Cxs->Cx∈P→Cxs->T∈P;
Cx->T∈P,
Cxs->Cx∈N→Cxs->T∈N;
Cx->T∈P,
Cxs->Cx∈O→Cxs->T∈P;
Cx->T∈O,
Cxs->Cx∈P|N|O→Cxs->T∈O;
Cx->T∈N,
Cxs->Cx∈P→Cxs->T∈N;
Cx->T∈N,
Cxs->Cx∈N→Cxs->T∈P;
Cx->T∈N,
Cxs->Cx∈O→Cxs->T∈N
(3)
式中:Cx->T——Cx基于T的情感倾向;
Cxs->Cx——Cxs基于Cx的情感倾向;
→——推导出的结果.
2.2.4 判别公式的影响
判别子评论关系的公式由Cx->T∈P|N|O,Cxs->Cx∈P|N|O和判别结果3部分构成.假设Cx->T∈P|N|O或Cxs->Cx∈P|N|O中存在错误,则推导结果也会出现错误.错误主要分为以下3类:Cxs->Cx所属情感倾向错误;Cx->T所属情感倾向错误;Cx->T,Cxs->Cx所属情感倾向均错误.其中,第3类发生的可能性极低,不进行考虑,前2类则可用公式表示为:
Cx->T∈S,
Cxs->Cx∉S→Cxs->T∉S;
Cx->T∉S,
Cxs->Cx∈S→Cxs->T∉S
(4)
式中:S——所属情感的正确情感倾向.
在第1类错误中,推导结果出现错误的情况为Cx->T∈P∧Cxs->Cx∈N,或者Cx->T∈N∧Cxs->Cx∈P.为了避免这种错误的发生,应该谨慎选择情感极性逆转的判别.
在第2类错误中,一旦Cx->T∉S,则所有情况都会发生错误.为了避免这种错误的发生,应该适当调节情感值判断的阈值下界v到上界v′来控制情感倾向错误划分,并将式(3)中的第4条优化为:
Cx->T∈O,Cxs->Cx∈P,
v≤Px≤v′→Cxs->T∈P;
Cx->T∈O,Cxs->Cx∈P,
-v′≤Px≤-v→Cxs->T∈P;
Cx->T∈O,other→Cxs->T∈O
(5)
这种方法可以在一定程度上弥补将Cx->T∈P或者Cx->T∈N错误判别为Cx->T∈O后造成的判别错误.
2.3 基于扩展情感词典的方法
由于电力微博评论目前并不普及,评论主要以数据稀疏的短文本为主,主题获取难度较其他领域来说更困难,因此考虑使用因子来代替主题,而因子就是情感极性的词汇.将因子代入式(1),则有:
(6)
式中:Wxy——Cx中的因子;
Pxy——Txy对应的情感倾向;
ωxy——Txy对应的权重.
此处采用的是词频计算的方法.
计算情感极性采用分段式函数,即:
(7)
这里采用NTUSD进行构建,该数据库是基于文本情感二元划分方法的一个中文词语数据库,它将词语分为积极属性词语和消极属性词语.在NTUSD的基础上,根据电力领域特性添加自定义极性词汇,扩展情感词典[17],电力领域的话题影响极大,自定义词汇效果十分明显.
根据Px的情感值来判断Cx的情感倾向,即:
(8)
2.4 基于支持向量机的方法
在电力评论中,含有情感极性的词汇一般为形容词和动词,通过文件频率方法判别出积极和消极词汇以及这些词汇附近的形容词,将所有的词通过人工识别的方法选定为特征项,作为向量空间的维,其权重为特征项的词频.
使用积极分类器和消级分类器两个判别器,将“积极”属性标记为正,“消极”属性标记为负,两个分类器把电力评论划分到决策平面的两侧.利用训练样本进行训练,采用式(8)对实验进行判别.
3 实验结果及分析
实验数据来源于新浪微博,利用网络爬虫技术抓取相关电力行业文本,按图2所示的电力领域微博评论情感分析流程进行处理.以“江西丰城发电厂坍塌事故”为例,实验提取“江西电厂事故”“江西电厂坍塌”等相同话题,时间截取范围为江西丰城发电厂坍塌事故发生后,并将得到的结果去重去空,最后得到该新闻超过90万微博用户的参与,评论超过9万条,截止2017年5月1日,总评论数为91 352条.
提取评论中出现的高频词汇,如表1所示.

表1 “江西丰城发电厂坍塌事故”高频词汇
选取高频词汇中含有情感倾向的词汇加入情感词典中,扩展NTUSD.由于这些评论受电力领域话题影响极大,目前也没有标准的语料库,于是随机选择1 500条评论,对其情感极性进行人工标注.
3.1 基于扩展情感词典的实验
根据实际应用经验取值,式(5)中,v=0.76,v′=0.79;在式(7)中,θ=1;在式(8)中,v=0.76.对1 500个数据进行基于扩展情感词典的实验,结果如表2所示.
表2中,A为包含评论关系的数据量;An为不包含评论关系的数据量;Aman为人工标注的数据;E为包含评论关系的数据实验结果与人工标注的差距;En为不包含评论关系的数据实验结果与人工标注的差距.E和En的计算公式为:
(9)
由表2可知,E和En的平均差距分别为0.070和0.329.
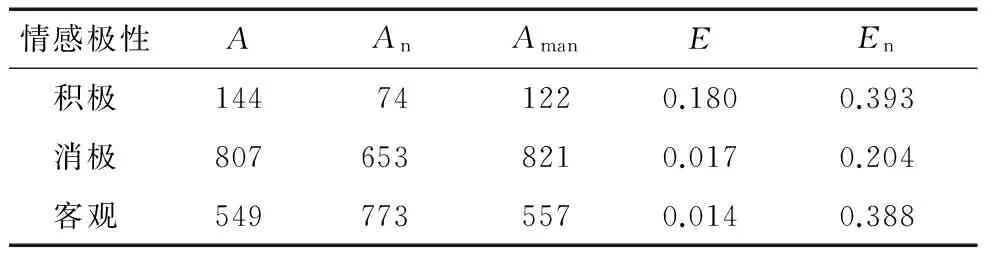
表2 基于扩展情感词典的实验结果
3.2 基于支持向量机的实验
从1 500个数据中随机抽取900个作为训练集,其余作为测试集.同样方法,在式(5)中,v=0.76,v′=0.79;在式(7)中,θ=1;在式(8)中,v=0.76.对训练集以外剩余的600个数据进行基于支持向量机的实验,结果如表3所示.

表3 基于支持向量机的实验结果
由表3可知,E和En的平均差距分别为0.112和0.182.
此外,根据实验可知,其他不考虑评论关系的算法在情感判定(参考参数是积极、消极、客观)方面与传统算法差别不大.
3.3 实验结果分析
(1) 根据E和En的数值比较可以得出,使用扩展情感词典和支持向量机这两种方法来进行电力微博情感极性分析,都可以提高分析的准确率.
(2) 基于扩展情感词典实验中的E小于基于支持向量机实验中的E,而基于扩展情感词典实验中的En大于基于支持向量机实验中的En,说明扩展情感词典的方法能更好地提高准确性.究其原因可能是:扩展情感词典的方法更适用于专业词汇出现较为频繁的电力领域;支持向量机方法本身已经足够准确,进步空间小;支持向量机方法实验数据基数小,容易造成实验结果不准确,偏差较大;基于支持向量机实验中的训练集是随机选取的,容易破坏评论间的结构关系.
(3) 从新闻报道中可以知道,民众对“江西丰城发电厂坍塌事故”的主流情绪是愤怒和悲伤.统计后发现,网民在微博评论中的情绪宣泄主要是针对电厂的管理层和相关社会机构负责人,认为管理层存在掩盖事实、推卸责任的行为,所以大部分评论是针对管理者的消极评价,仅有一小部分人相信管理者可以处理好善后工作.在微博中出现这种消极大于积极的网络舆情倾向与本试验结果一致.
4 结 语
本文面向电力领域微博情感分析,根据电力行业的特性,将评论进行预处理后,建立评论关系树,使用基于扩展情感词典的方法进行动态扩展,采用基于支持向量机的方法设计情感极性分类器,建立情感极性判别规则,来进行情感极性分析.实验结果表明,生成评论关系树后,扩展情感词典和支持向量机两种方法在电力领域的正确率均得到了明显的提升.
下一步的工作将着重于如何在电力领域微博评论中选取特征项以及怎样解决消除数据稀疏后产生的分析困难,并针对电力领域常见的歧义词汇在不同语义中进行消解处理.
[1] 李涵昱,钱力,周鹏飞.面向商品评论文本的情感分析与挖掘[J].情报科学,2017(1):51-55.
[2] ANAND D,NAOREM D.Semi-supervised aspect based sentiment analysis for movies using review filtering[J].Procedia Computer Science,2016,84:86-93.
[3] RAO Y H,LEI J S,LIU W Y,etal.Building emotional dictionary for sentiment analysis of online news[J].World Wide Web,2014,17(4):723-742.
[4] PERIKOS I,HATZILYGEROUDIS I.Recognizing emotions in text using ensemble of classifiers[J].Engineering Applications of Artificial Intelligence,2016,51(c):191-201.
[5] 黄文明,孙艳秋.基于最大熵的中文短文本情感分析[J].计算机工程与设计,2017(1):138-143.
[6] 刘正,黄震华.基于多项式贝叶斯分类模型的短文本多情感倾向分析及实现[J].现代计算机(专业版),2016(14):39-42.
[7] 吴青林,周天宏.基于话题聚类及情感强度的中文微博舆情分析[J].情报理论与实践,2016(1):109-112.
[8] 张剑峰,夏云庆,姚建民.微博文本处理研究综述[J].中文信息学报,2012(4):21-27.
[9] MA Y F,DENG Q,WANG X Z,etal.Keyword-based semantic analysis of microblog for public opinion study in online collective behaviors[M].Springer International Publishing,2014:38-46.
[10] 韩忠明,张玉沙,张慧,等.有效的中文微博短文本倾向性分类算法[J].计算机应用与软件,2012(10):89-93.
[11] 杜振雷.面向微博短文本的情感分析研究[D].北京:北京信息科技大学,2013.
[12] 贺飞艳,何炎祥,刘楠,等.面向微博短文本的细粒度情感特征抽取方法[J].北京大学学报(自然科学版),2014(1):48-54.
[13] XU J H,LIU J L,YIN J,etal.A multi-label feature extraction algorithm via maximizing feature variance and feature-label dependence simultaneously[J].Knowledge-Based Systems,2016(1):172-184.
[14] YU L C,LEE L H,YEH J F,etal.Near-synonym substitution using a discriminative vector space model[J].Knowledge-Based Systems,2016(5):74-84.
[15] 佚名.搜狗输入法表情符号词库[EB/OL].[2013-06-15].http://pinyin.sogou.com/dict/detail/index/36756.
[16] 佚名.NLPIR汉语分词系统(ICTClAS 2016)[EB/OL].[2017-03-14].http://ictclas.nlpir.org/.
[17] TAN C F.The Chinese microblog emotional tendency analysis based on sentiment dictionary[J].Applied Mechanics and Materials,2013,333-335:795-798.
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
中华胰腺病杂志(2021年1期)2021-02-26
山东医药(2020年34期)2020-12-09
文苑(2019年24期)2020-01-06
文苑(2019年24期)2020-01-06
中华胰腺病杂志(2019年4期)2019-08-29
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
中关村(2014年5期)2014-05-15
