
科技情报大数据业务平台设计
2018-01-10 07:09:34吴素研吕志坚吴江瑞李文波
现代情报 2018年1期
吴素研 吕志坚 吴江瑞 李文波
(1.北京市科学技术情报研究所信息技术研究部,北京100044;2.河南工学院材料工程系,河南 新乡 100044;3.中国科学院软件研究所总体部,北京100081))
·业务研究·
科技情报大数据业务平台设计
吴素研1吕志坚1吴江瑞2李文波3
(1.北京市科学技术情报研究所信息技术研究部,北京100044;2.河南工学院材料工程系,河南 新乡 100044;3.中国科学院软件研究所总体部,北京100081))
[目的/意义]本文分析了目前大数据时代科技情报工作面临的问题和机遇,针对情报服务领域大数据服务模式进行了分析。[方法/过程]该论文结合信息技术领域的虚拟化技术、云平台技术、高性能技术和人工智能技术,设计了科技情报大数据业务平台架构,详细阐述了硬件层、虚拟层、支撑层和业务层主要功能和所需技术;并对大数据处理首要任务存储进行了探索,搭建了基于hadoop和hbase的大数据存储平台。[结果/结论]本文提出的大数据情报业务平台从整体架构进行了设计,并实现了存储模块,下一步实现分析和可视化部门,可以为情报的收集和处理提供大数据支撑服务。
科技情报;大数据;hadoop;hbase
传统的科技情报工作主要是从公开的、正规的纸质事实文献上,如科技论文、专利、标准、图书等获取信息,提炼出来的客观情报知识。信息技术和互联网的出现,使得科技情报来源的信息载体由纸质演变为数字化,情报信息的获取方式也从专门的机构变为可以随时随地访问的开放网络上。
目前,一方面,网络上的信息随着互联网技术的蓬勃发展,尤其以由用户主导而生成的内容互联网产品模式的Web2.0技术和以融合为主的第三代互联网技术的发展,让信息爆炸式地增长,人类社会也进入了大数据时代,目前都是从海量信息中发现有价值的东西。依据时代的发展,科技情报工作已由传统的以文献服务、知识服务为标志的情报1.0、2.0时代,进入了以智能服务为标志的情报3.0时代[1]。
另一方面,计算机硬件技术和软件技术也有了新的突破,硬件方面的DSP、GPU、高性能处理芯片,软件方面云计算、sdn等技术[2-4],软件方面的互联网的爬虫技术可以实现从网上自动采集信息,人工智能、机器学习、数据挖掘、自然语言处理技术也发展到相对成熟的阶段,这些技术可以实现文本的自动分类、聚类,可以从大量数据中学习有价值的知识,文本检索技术可以实现从海量数据中找出想要的数据,这些技术为快速处理海量数据提供了基础[5-7]。
有这两方面需求的驱动和技术的支撑,大数据技术应运而生,主要包括进行数据表示的知识表示技术、对数据进行表示的知识图谱技术、对数据进行挖掘发现的深度学习技术,这些技术是目前进行情报分析的基础,必须引入这些技术来完成对大规模信息的处理和分析,解决情报3.0时代所面临的问题。才能完成数字化、网络化的新时期的情报分析任务。
进行情报分析任务,首先面对的就是数据的高效存储,关系数据库在面对高并发,高负载的低效,以及不易进行升级和扩展,往往需要停机维护和数据迁移等缺点是不适宜应用在大数据业务平台上,搭建高效的存储平台是建立大数据业务的首要任务。因此本文首先分析了大数据时代情报业务模式,其次探索利用hadoop和hbase技术进行大数据存储平台的搭建。
1 大数据情报业务平台架构
大数据指的是数据量超过单个台式机存储能力数据,无法用传统的关系型数据库进行存储、单机数据分析统计工具无法处理的数据,这些数据需要存放在拥有数千万台机器的大规模并行系统上进行存储和分析。大数据情报业务平台,需要提供对情报信息的高可靠性、高性能、可伸缩分布式存储系统和实时的、多维的、智能的分析功能。
大数据情报业务员平台需要对硬件计算和存储资源的进行合理虚拟化以实现高效的调配,需要对虚拟的资源进行高效内存计算以达到高效计算,在此让利用深度学习工具加强平台智能化,最终通过大数据可视化实现结果的展示。它主要分为4层。分别是:硬件资源层,虚拟资源,支撑平台和情报业务服务。科技情报大数据平台架构如图1所示。
1)硬件资源层:大数据平台对硬件的需求主要是:可作为计算设备的主机、进行数据存储的磁盘和满足内部服务和对外服务的网络设备。大数据平台硬件的建设可以采取2个方案:①采用托管的方式,可以租用云计算平台。
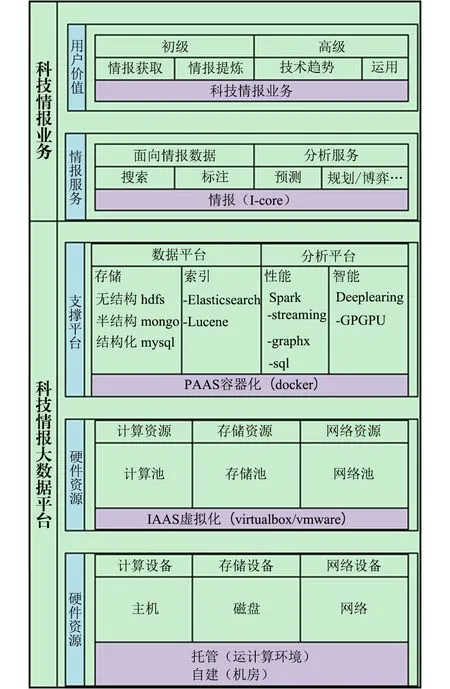
图1 科技情报大数据平台
②可以采用自建的方式。采购20台以上的服务器和磁盘阵列,搭建私有云平台即能满足基本情报服务。
2)虚拟资源层:此层对上是透明化底层物理硬件,对下是打破实体结构间的不可切割的障碍,使这些资源的不受现有资源的架设方式、地域或物理组态所限制,实现最大化的利用物理硬件。虚拟化技术分为商用软件和开源虚拟化技术两种。
3)支撑平台层:支撑平台主要完成数据的存储和处理,因此分为数据平台和处理平台。
情报的数据主要分为无结构的、半结构的和结构化的。对于结构化数据可以采用关系型数据库存储。对于半结构化的数据采用非关系型数据库存储。无结构化的数据可以采用文件系统存储。如果对数据要进行快速的查找和访问,还需要有索引的存储,对索引的处理也有很多成熟的开源技术,如sola、弹性搜索等。
情报大数据平台处理数据最大特点是数据量大,因此对数据处理性能要求要高。要达到这点首先处理的数据就要有原来的硬盘上改为在内存出处理,因此内存计算技术是大数据平台的基础。内存技术主要是对流处理、图、统计的处理,都已经有很多成熟的方法。情报大数据的处理除了速度,还需要智能。利用数据挖掘技术从海量信息中找出有价值的情报是大数据情报平台主要的作用之一。因此在对数据处理上,深度学习是很重要的。目前已经有很多深度学习的算法和工具,并在实际应用中获取过很多有价值的成果。比如,作者曾经利用Google开源的Deep Learning工具Word2vec训练出来的知识应用于对人大建议和政协提案进行模糊查找中和主题词的推荐中,得到了很好的效果。
4)情报业务层:这一层是大数据平台的业务层。情报主要是在对数据的处理过程中,获取价值,数据具有多样性,包括类型,文字的、图片的。结构化的,非结构化的,所属领域不同,如低碳、节能、农业、林业等。目前对数据处理的自动化技术也是发展得很好,如对文本处理的搜索、分类、聚类等。对图像的提取、检索等。因此根据情报所情报业务的需求和目前的计算机技术结合起来,建立能为情报服务的数据处理平台。这一层是可扩展、组件化的,可以根据需求不断进行技术的更新。目前根据最基本的需求,设计了几个模块。情报搜索,他和一般的搜索不一样,它具有行业性,搜索需要对具有新颖性的东西加以特别关注、还具有多样行。当然依托于大数据平台,提高性能更是必不可少的。知识库的构建:目前在自然语言处理比较火的概念之一。建立一个好知识库,可以对概念进行推理和延伸。可以让处理走向语义化。而知识库的建立是具有领域性的,可以针对情报所的特定服务建立该领域知识库。其次知识库需要建成能自我完善的,其众包技术能很好地起到这个效果。
基于大数据平台,提供的服务最终体现在用户价值上,从服务的层次上,分为初级和高级。初级可以面向大众免费提供,如进行情报的检索和情报数据的自动提炼上。而高级服务可以定制进行,为用户提供行业情报,对技术进行趋势估计等。
2 基于hadoop+hbase的大数据存储平台
关系型数据库适用于存储结构化数据,不适宜于高并发访问和大数据量的大数据平台。 Nosql(Not-Only-SQL)就是为半结构化数据存储而生的。Nosql数据库采用Key-Value的形式对数据进行存储,且结构不固定,也就是说一个表的任意一行的列的数量可以不相同。并且就算定义字段,在不使用的情况下,也并不会占用存储空间,这样在某种程度上来说也降低了一定的存储开销。同时还具有易扩展性和高可用性的特性,方便部署在廉价的PC服务器上集群用于处理大规模的海量数据。HBase是Hadoop平台下数据存储引擎,它能够为大数据提供实时的读/写操作。HBase具备开源、分布式、可扩展性以及面向列的存储特点,使得HBase可以部署在廉价的PC服务器集群上处理大规模的海量数据。HBase最早是由Google的Bigtable演变而来,他提供了2种存储方式:一种是使用操作系统的本地文件系统;另外一种则是在集群环境下使用Hadoop的HDFS,相对而言,使用HDFS将会使数据更加稳定。同时HBase存储的是松散型数据,也就是半结构化数据,那么注定HBase的存储维度是动态可变的。也就是说HBase表中的每一行可以包含不同数量的列,并且某一行的某一列还可以有多个版本的数据,这主要通过时间戳范围进行区分。HBase不仅可以向下提供运算,它还能够结合Hadoop的MapReduce向上提供运算,这些都是HBase所具备的特点[8]。根据上面大数据业务平台的架构,结合hadoop+hbase技术搭建了大数据存储的原型系统,具体方案如下文所述。
2.1 系统基础架构
在两台配置处理器:CPU四核,处理速度3.3GHz,内存16G,硬盘:1T的Window7的系统上分别安装Vitualbox,并在每个Vitualbox上安装5个Ubuntu系统,每个性能内存2G,存储200G。按照Hadoop集群的基本要求,其中一个是master结点,主要是用于运行hadoop程序中的namenode、secondorynamenode和jobtracker任务。另外9个结点均为slave结点,其中一个是用于冗余目的,如果没有冗余,就不能称之为hadoop了。slave结点主要将运行hadoop程序中的datanode和tasktracker任务。
在准备好这10个结点之后,需要分别将Linux系统的主机名重命名和配置IP地址(因为前面是复制和粘帖操作产生另外9个结点,此时这10个结点的主机名是一样的),依此对虚拟系统设置IP从10.10.1.60到10.10.1.69,修改各个虚拟机hostname文件,将节点机器名字依次设置为maste、slave1、slave2、slave3、slave4、slave5、slave6、slave7、slave8、slave9。之后修改各个机器的hosts文件。设置为:
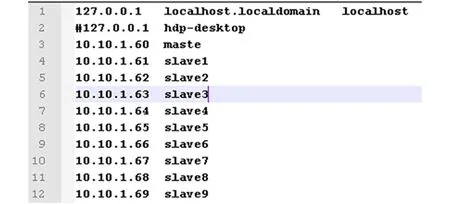
图2 hostname文件配置
2.2 系统配置
2.2.1 hadoop配置
1)设置Core-site.xml
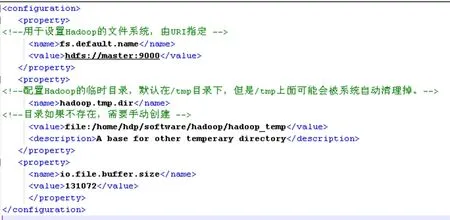
图3 Core-site.xml文件配置
2)设置hdfs-site.xml

图4 hdfs-site.xml文件配置
3)设置mapred-site.xml

图5 mapred-site.xml文件配置
4)设置yarn-site.xml
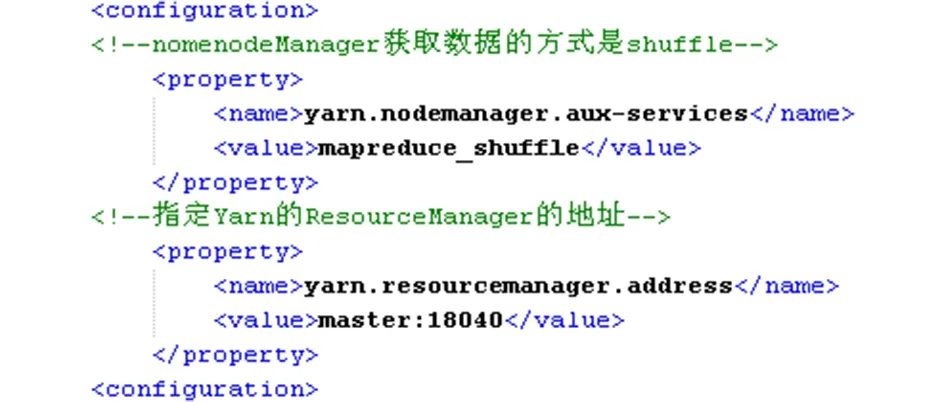
图6 yarn-site.xml文件配置
2.2.2 hbase集群配置
1) 配置hbase-site.xml

图7 hbase-site.xml文件配置
hbase.rootdir指定Hbase数据存储目录。hbase.cluster.distributed指定是否是完全分布式模式,单机模式和伪分布式模式需要将该值设为false,hbase.master指定Master的位置,hbase.zookeeper.quorum指定zooke的集群,多台机器以逗号分隔。
2)修改conf下的regionservers文件

图8 regionservers文件配置
3)修改Hadoop hdfs-site.xml下的一个属性值
维宁尔(veoneer)的前身是全球汽车安全领域的领导者瑞典奥托立夫(Autoliv)公司的电子事业部。维宁尔(中国)电子有限公司专注于汽车安全电子及自动驾驶等新兴市场业务,维宁尔的目标是成为高级驾驶辅助系统(ADAS)和自动驾驶系统的领先供应商。维宁尔(中国)电子有限公司积极顺应市场需求,着力研发相关产品,以期成为汽车安全电子产品市场的领导者。

图9 regionservers文件配置
该参数限制了datanode所允许同时执行的发送和接受任务的数量,缺省为256,hadoop-defaults.xml中通常不设置这个参数。这个限制缺省值实际使用情况下有些偏小,高负载情况下影响集群性能,需要根据实际集群条件设置一下。
2.2.3 hadoop和hbase启动和停止
启动顺序:先启动Hadoop-≫hbase。
进入hadoop文件夹下执行命令:./sbin/start-dfs.sh;./sbin/start-yarn.sh;分别启动hadoop的文件系统和任务调度系统。通过jps查看节点状态,在maste和slave上分别显示如下图所示,表示hadoop启动成功。
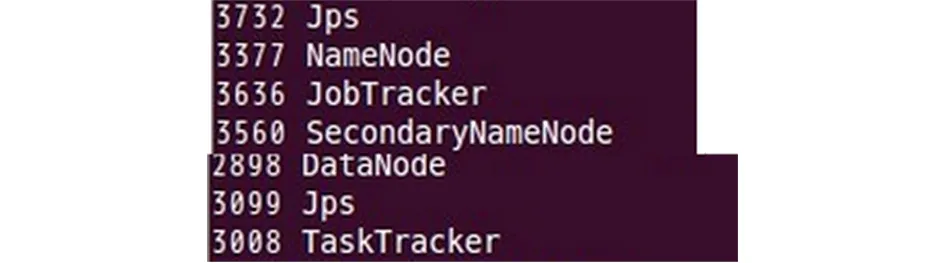
图10 hadoop启动任务
进入hbase文件夹下执行命令:./bin/start-hbase.sh,运行后通过jps查看节点状态,出现黄色框起来的任务表示启动成功。
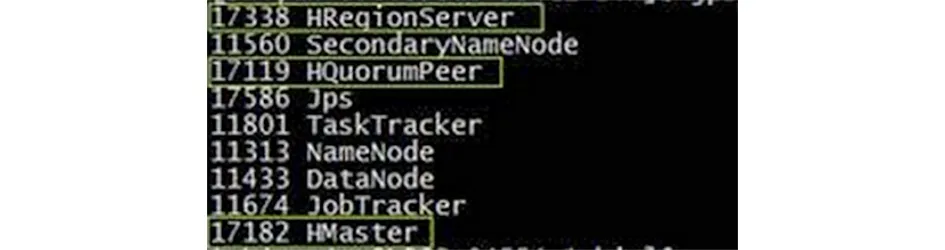
图11 hbase启动任务
停止顺序:hbase->hadoop,依次执行./bin/stop-hbase.sh;./sbin/stop-yarn.sh;./sbin/stop-dfs.sh;即可停止hbase和hadoop。
2.2.4 java代码实现hbase简单存储
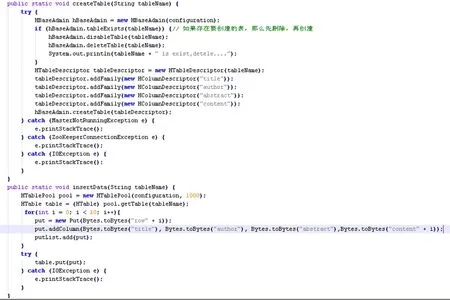
图12 hbase建库和插入数据代码
3 结 语
本文分析了目前大数据时代科技情报工作面临的问题和机遇,结合信息技术领域的虚拟化技术、云平台技术、高性能技术和人工智能技术,设计了科技情报大数据业务平台架构,并对大数据处理首要任务存储进行了探索,搭建了基于hadoop和hbase的大数据存储平台。下一步,将在此基础上,将人工智能技术嵌入到大数据平台上,实现情报的大数据挖掘,最终,嵌入大数据可视化技术,对情报结果进行展示。
[1]吴晨生,李辉,付宏,等.情报服务迈向3.0时代[J].情报理论与实践,2015,38(9):1-7.
[2]Bolz J,Farmer I,Grinspun E,et al.Sparse matrix solvers on the GPU[J].Acm Transactions on Graphics,2003,22(3).
[3]Hayes B.Cloud computing[J].Communications of the Acm,2008,51(7):9-11.
[4]Dixit A,Fang H,Mukherjee S,et al.Towards an elastic distributed SDN controller[M]// ACM SIGCOMM Computer Communication Review.ACM,2013:7-1
[5]Naimi A I,Westreich D J.Big Data:A Revolution That Will Transform How We Live,Work,and Think.[J].American Journal of Epidemiology,2014,17(9):181-183.
[6]Lecun Y,Bengio Y,Hinton G.Deep learning[J].Nature,2015,521(7553):436-444.
[7]吴信东.数据挖掘十大算法[M].李文波,吴素研,译.北京:清华大学出版社,2013.
[8]Mehul,Nalin,Vora.Hadoop-HBase for large-scale data[C]// International Conference on Computer Science and Network Technology.IEEE,2012:601-605.
BigDataPlatformforScienceandTechnologyIntelligence
Wu Suyan1Lyu Zhijian1Wu Jiangrui2Li Wenbo3
(1.Beijing Institute of Science and Technology Information,Beijing 100044,China;2.Henan Institute Technology,Xinxiang 453003,China;3.Institute of Software Chinese Academy of Science,Beijing 100081,China)
[Purpose/Signficance]This paper analyzed the current big data era of science and technology Intelligence work problems and opportunities.[Method/Process]Combined with information technology,virtualization technology,cloud platform technology,high performance technology and artificial intelligence technology,design science and technology information data service platform architecture,described the hardware layer,virtual layer,support layer and business layer and main function the required technology;and explored the primary task of big data storage,to build a large data storage platform based on Hadoop and hbase.[Resule/Conclusion]Big data business intelligence platform was proposed in this paper was designed from the overall architecture,and implemented the storage module,realized the analysed and visualization department next,could provide support services for large data collection and processing of information.
scientific and technical intelligence;big data;hadoop;hbase
10.3969/j.issn.1008-0821.2018.01.019
TP393
A
1008-0821(2018)01-0131-05
2017-08-04
北京市财政项目(项目编号PXM2017_178214_000005)、北京市科学技术情报研究所改革与发展专项(2017)。
吴素研(1977-),女,副研究员,博士,研究方向:科技情报、大数据。吕志坚(1975-),男,副研究员,博士,研究方向:科技情报、人工智能。吴江瑞(1968-),男,高级技师,研究方向:焊接。
孙国雷)
猜你喜欢
现代装饰(2022年5期)2022-10-13 08:49:18
现代装饰(2022年4期)2022-08-31 01:42:30
技术与市场(2022年7期)2022-07-16 06:04:42
现代装饰(2022年3期)2022-07-05 05:59:04
情报学报(2022年6期)2022-07-02 07:18:26
军民两用技术与产品(2022年5期)2022-06-28 02:15:12
现代装饰(2022年2期)2022-05-23 13:15:48
现代装饰(2022年1期)2022-04-19 13:47:44
安徽科技(2018年9期)2018-12-31 12:54:31
办公室业务(2017年20期)2017-11-25 03:07:10
