
基于遗传算法的组卷技术研究与改进
2017-12-28 01:11王文星赵新慧
辽宁石油化工大学学报 2017年6期
王文星, 赵新慧
(辽宁石油化工大学 计算机与通信工程学院, 辽宁 抚顺 113001)
基于遗传算法的组卷技术研究与改进
王文星, 赵新慧
(辽宁石油化工大学 计算机与通信工程学院, 辽宁 抚顺 113001)
优化了自动组卷的约束条件,并针对知识点的考核层次问题进行了算法改进。在初始化种群时使用知识点权重分级表,按知识点权重顺序来选取试题生成初始种群中的染色体,使种群从最初时起就满足对知识点的考核层次要求,并在遗传算子的设计中保持了种群知识点的稳定性。结果表明,改进算法在保证知识点覆盖率的同时,能提高重要知识点的覆盖率。
自动组卷; 遗传算法; 知识点权重; 考核层次
计算机自动组卷技术减轻了试卷命题人负担,并且提高了试卷的质量和科学性。目前计算机自动组卷方法有随机抽题法[1]、回溯法[2]和遗传算法[3-4]等。随机抽题法简单,但具有很大的随意性和不确定性[5];回溯法适用于状态类型和试题量比较小的情况;遗传算法模拟生物进化过程搜索最优解,适用于处理传统搜索方法难以解决的非线性、多约束的复杂问题[5],在自动组卷方面应用广泛。经验表明,约束条件越多,自动组卷的效率就越低[6]。自动组卷遗传算法研究主要关注点在约束条件优化上[7-8],或只考虑知识点的均匀分布但未考虑知识点的考核层次[1,9]。文献[10]要求人为指定知识点分配的分值,文献[11]指定不同考核层次占用的分值,增加了人工干预并且带有人为主观性。文献[12]使用了知识点分级带权重选取策略解决知识点的考核层次问题,不过选取结果过于均匀,重点不够突出,而且计算方法和知识点数量有关。本文优化了自动组卷约束条件,并针对知识点的考核层次问题对遗传算法进行改进。
1 试卷的数学模型
1.1 试题属性定义
组卷要考虑的因素有试卷难度、试卷区分度、题型、试题曝光度、知识点覆盖率和考核层次等。同时,对试卷还有一些特别的要求,如试卷中不能出现与上次试卷相同的试题,如果有A、B卷的话,也不能有重复试题。组卷涉及的条件很多,有些条件需严格满足要求,有些条件特殊情况才会用到。为提高组卷成功率及速度,可对这些条件进行取舍或优化。一般的考试,在组卷时考试题型、各题型试题分和试题数量是可以确定的。用题量来控制卷面分和答题时间,就可以不用考虑总分约束和时间约束问题。最终优化的试题属性如下。
(1)编号:唯一标识一道试题。
(2)知识点:试题考核的知识点。
(3)难度:代表一道试题的难易程度,划分为5个等级(易、较易、中等、较难和难,对应数字为1、2、3、4、5)。
(4)区分度:对考生水平区分程度的指标,并不是与难度成正比。
(5)曝光度:试题被选中的次数。
(6)分值:试题的分值。
(7)最后使用时间:试题最后一次被选中的时间。
1.2 试卷的数学模型
将1份试卷映射为1个矩阵,组成试卷的每个试题映射为1个行向量。设每份试卷有n道试题,每题有如上定义的7个属性,那么一张试卷就可以表示为矩阵S:
目标矩阵S需要满足以下约束条件:
1.3 组卷的目标函数
矩阵S需要满足用户对试卷的要求。在定制试卷时,用户提供期望的题型、各题型试题的分数、各题型的题量、试卷难度及区分度。用fi表示属性与属性期望值之间的误差,为反映各属性的不同重要程度,目标函数f取各误差的加权和:
(1)

由式(1)可知,为了得到最优解,f的值越小越好。
2 组卷遗传算法改进
2.1 染色体编码
染色体编码是由问题空间向遗传算法空间的映射。在组卷题量大时二进制编码染色体长度过长,从而降低组卷效率,因此使用染色体分段实数编码。1份试卷对应1个染色体,试题号作为染色体中基因的值,试卷中每道题的题号对应1个基因,染色体中基因按题型分段。
设试卷共有n道试题,k种题型,按题型将n道试题分成k段,每段代表1种题型。若第r(r=1,2,…,k)类题型包含的试题数目为ri,则染色体为:
sn1(1)sn2(2)…sn1(r1)sn2(1)sn2(2)…
sn2(r2)…snk(1)snk(2) …snk(rk)
(2)
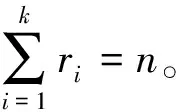
2.2 适应度函数
试卷中各种题型的数量、分值和考核知识点是在初始化种群时处理,设置适应度函数需要处理的约束包括试题难度、试题区分度和试题曝光度。所以,适应度函数直接由目标函数转化得到。
2.3 初始化种群
根据用户设定的各种题型的数量、分值和考核知识点生成初始种群。另外,引入知识点权重表,在保证知识点覆盖率的同时,加强对重要知识点的考核。
2.3.1 知识点权重分级表的创建 在教学大纲中都会规定每个知识点的考核要求,如“了解、理解、掌握和熟练掌握”。在考核时应该优先考核“熟练掌握”和“掌握”的知识点。在自动组卷时,应该能优先选择重要的知识点,不用每次组卷时人工指定。为此,需要创建一个知识点权重表,在选择试题时,优先选择知识点权重大的试题,这样就可以加强对重要知识点的考核。
为了避免出现由于知识点密度大而导致的题目相似度高的情况,实现组卷时知识点考核的均匀分布,对各章的知识点进行分级组织。首先按大类划分若干一级知识点,然后在一级知识点下再划分若干二级知识点。在选择知识点时,先选择一级再选择二级。二级知识点的权重直接按大纲要求指定,假设考核层次为“了解、理解、掌握和熟练掌握”,则相应权重可设置为1、2、3、4。一级知识点权重由其包含的二级知识点权重生成,原则上一级知识点权重要能体现其二级知识点的最高权重;一级知识点权重要与其二级知识点的数量有关。因此,本文定义一级知识点权重计算公式为:
(3)
式中,xi为第i个知识点的权重;ki为加权系数(放大权重值差距)。
根据式(3)可创建课程的知识点权重分级表,对一级知识点和二级知识点按权重分别降序排序。
2.3.2 初始化种群算法 根据用户指定的题型、题数和题分,使用知识点权重分级表,按知识点权重顺序来生成初始种群,算法如下:
步骤1 根据题型k和试题数n生成试卷染色体结构(k段共n个基因);
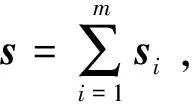
步骤3 为了避免因知识点序列固定而导致高分值试题考核知识点可预测,对试卷知识点表中前t(t为高分值试题数量)个知识点进行混排;
步骤4 依次从试卷知识点表中取出知识点,按照染色体中基因题分降序顺序,为染色体中基因分配取出的知识点;
步骤5 根据染色体基因所分配的知识点和题型信息,为染色体中所有基因随机选择一道符合知识点和题型要求并满足最后使用时间限制要求的试题;
步骤6 重复步骤4和步骤5,直到生成指定数量的试卷染色体种群。
2.4 遗传算子的设计
2.4.1 选择算子 为提高种群进化的效率,采用将前10%的优良个体直接选择进入下一代,剩余个体采用轮盘赌的选择策略。
2.4.2 交叉算子 采用分段单点交叉方法:种群中的染色体任意两两配对;给每对染色体生成1个[0,N-2]的随机数r,将r后的两道题互换,得到下一代。交叉后生成的子代有可能会出现重复的题号问题,解决方法是将重复的题号换成具有相同知识点并且在该段中没有出现过的题号。
2.4.3 变异算子 采用分段变异操作,即各题型在各自分段内进行变异,基本步骤为:对种群中的每个个体生成1个长度为n的随机数列R={r1,r2,…,rn},其中ri为随机产生的[0,1]的实数。对每个个体的第i个基因位置上的基因,如果ri≥Pm(Pm为变异阈值),保持该基因不变,否则进行变异操作,选择1个本段中没有的题号并和原试题具有相同知识点和题型的试题替换原试题。
2.4.4 终止条件 遗传算法需要多次迭代,其解尽可能接近最优解,终止条件为产生适应度达到指定要求的个体或达到指定的迭代次数。满足条件之一算法终止。
3 算法测试
为了验证改进算法,进行如下测试:
(1)测试条件。题库中共有5类题型:程序题、简答题、多选题、单选题和判断题,共1 200道试题,包括21个一级知识点和65个二级知识点。“了解、理解、掌握和熟练掌握”各权重的二级知识点总数为17、22、13、13。
(2)参数设置。试卷总分100分,试卷难度0.3,试卷区分度0.5,试卷曝光度取题库中所有试题的曝光度平均值,试卷中5类题型数量分别为3、5、10、20、10,分数比例分别为3∶2∶2∶2∶1,一级知识点权重计算公式中取ki= (xi+1)/2,初始种群规模50,种群数量24,最大迭代次数100,变异概率0.005,适应度函数中ω1=0.5、ω2=0.3、ω3=0.2。测试结果如表1所示。

表1 算法测试结果
注:各权重知识点的包含比例为试卷包含的各权重知识点数量与各权重知识点总数之比。
从表1可以看出,本文算法可以在保证知识点覆盖面的同时,提高重要知识点的覆盖率。各权重知识点的选取比例比较合理,权重高的知识点比权重低的知识点的覆盖率更高。
此外,通过设置不同题型和试题数量,进行多次测试。当试卷题量减少时,权重低的知识点的覆盖率减少的更快,而权重高的知识点覆盖率减少的相对缓慢,保证了试卷对重要知识点的考核力度。
4 结 论
自动组卷技术是计算机辅助教学中的一项重要技术。其中知识点考核不但要求覆盖率大而且要优先考核重要的知识点。对自动组卷约束条件进行优化,在知识点的考核层次问题上进行了算法改进。结果表明,改进算法在保证知识点覆盖率的同时,提高了对重要知识点的覆盖率。
[1] 金汉均,郑世珏,吴明武.分段随机抽取选法在智能组卷中的研究与应用[J].计算机应用研究,2003,20(9):102-103.
[2] Chen L H,Mei Y D,Dong Y J,et al.Improved genetic algorithmand its application in optimal dispatch of eas-cade reservoirs[J].Journal of Hydraulic Engineering,2008,38(5):550-556.
[3] 黄宝玲.自适应遗传算法在智能组卷中的应用[J].计算机工程,2011,37(14):161-163.
[4] 梁亚澜,聂长海.覆盖表生成的遗传算法配置参数优化[J].计算机学报,2012,35(7):1522-1538.
[5] 朱婧,戴青云,王美林,等. 自适应遗传算法在工程训练在线考试中的应用[J]. 计算机工程与应用,2013,49(14):227-230.
[6] Wang L, Tang D. An improved adaptive genetic algorithm based on hormone modulation mechanism for job-shop scheduling problem[J]. Expert Systems with Applications,2011,38(6):7243-7250.
[7] 陈国彬,张广泉. 基于改进遗传算法的快速自动组卷算法研究[J]. 计算机应用研究,2015,32(10):2996-2998.
[8] 张琨,杨会菊,宋继红,等. 基于遗传算法的自动组卷系统的设计与实现[J]. 计算机工程与科学,2012,34(5):178-183.
[9] 鲁萍,王玉英. 多约束分级寻优结合预测计算的智能组卷策略[J]. 计算机应用,2013,33(2):342-345.
[10] 贺荣,陈爽. 在线组卷策略的研究与设计[J]. 计算机工程与设计,2011,32(6):2183-2186.
[11] 任剑,卞灿,全惠云.基于层次分析方法与人工鱼群算法的智能组卷[J].计算机应用研究,2010,27(4):1293-1296.
[12] 鲁萍,何宏璧,王玉英. 智能组卷中分级带权重知识点选取策略[J].计算机应用与软件,2014,31(3):67-69.
Research and Improvement of Test Paper ConstructionTechnology Based on Genetic Algorithm
Wang Wenxing, Zhao Xinhui
(SchoolofComputerandCommunicationEngineering,LiaoningShihuaUniversity,FushunLiaoning113001,China)
The constraints of automatic test paper are optimized, and the algorithm is improved according to the examination hierarchy of knowledge points . The knowledge points weight grading table is used when initializing the population , and the chromosomes in the initial population are selected according to the knowledge weight order so that the population can meet the requirement of the assessment level of the knowledge points from the initial time. In the design of the genetic operators maintains the stability of the population of knowledge point .The results show that the improved algorithm can improve the coverage rate of important knowledge points while guaranteeing the coverage of knowledge points.
Automatic test paper generation; Genetic algorithms; Knowledge point weight; Assessment level
2017-06-09
2017-07-04
2016年国家级大学生创新创业训练计划项目(201610148052)。
王文星(1995-),男,本科生,软件工程专业,从事软件工程方面研究;E-mail:864862094@qq.com。
赵新慧(1973-),男,硕士,副教授,从事软件工程、智能信息处理等方面研究;E-mail:zhaoxinhui2002@163.com。
1672-6952(2017)06-0056-04
投稿网址:http://journal.lnpu.edu.cn
TP311.52
A
10.3969/j.issn.1672-6952.2017.06.012
(编辑 陈 雷)
猜你喜欢
中学生数理化(高中版.高二数学)(2022年5期)2022-06-01
中学生数理化(高中版.高二数学)(2021年5期)2021-07-21
科学之谜(2019年3期)2019-03-28
科学之谜(2018年8期)2018-09-29
中学生数理化·七年级数学人教版(2017年5期)2017-11-09
中央民族大学学报(自然科学版)(2017年1期)2017-06-11
中学生数理化·高一版(2017年2期)2017-04-25
恋爱婚姻家庭·养生版(2016年9期)2016-09-07
现代计算机(2016年34期)2016-02-28
智能系统学报(2015年4期)2015-12-27
