
基于混合模型的图书馆服务机器人语音指令解析系统
2017-12-26 10:56:02张丽芬郭新灵
电子器件 2017年6期
张丽芬,李 平,郭新灵
(1.内蒙古化工职业学院图书馆,呼和浩特 010010;2.黄淮学院信息工程学院,河南 驻马店 463000)
基于混合模型的图书馆服务机器人语音指令解析系统
张丽芬1*,李 平2,郭新灵1
(1.内蒙古化工职业学院图书馆,呼和浩特 010010;2.黄淮学院信息工程学院,河南 驻马店 463000)
基于智慧图书馆技术的现状,对图书管理服务机器人的人机交互问题进行了研究,提出了一种基于混合模型的机器人语音指令深层信息解析系统。首先,对图书馆机器人的研究现状及其存在的语义解析问题进行了分析;然后提出了基于概率和神经网络的混合模型,基于此模型对语音指令进行深度的信息识别;最后在该系统上进行了深层信息解析的仿真实验,并与几种经典方法进行了比较。结果表明,该方法能够更加准确的提取表层信息和深层信息。
语音解析;混合模型;深度信息提取;概率模型;神经网络模型
随着人类社会的不断发展,未来城市的面积和人口承载量将越来越大。为了实现城市的可持续发展,发展建设智慧城市已成为当今世界城市发展的历史潮流。智慧城市代表城市的信息化和智能化,作为城市公共事业的重要部分,智慧图书馆的发展成为当下智能化研究的一个重要方向,图书馆服务机器人的应用也在快速拓展。2013年,美国北卡罗莱纳州立大学亨特图书馆引进机器人存取服务,读者在检索系统中选择图书,工作人员将图书名称输入电脑,机器人即可自动找到该图书[1]。2014年,澳大利亚悉尼科技大学的机器人管理员不仅能整理馆内超过30万本的藏书,而且能将读者在计算机上选好的书在最短时间内送到他面前。2016年,浙江图书馆引入机器人管理员,它能够语音识别读者说出的图书名称,并指示出图书所在的位置,实现自主智能的借还书服务。
人工智能和计算机技术的进步使图书馆机器人能够代替人工提供更多的服务,但现阶段,机器人需要人工的协助才能完成相应的任务,如需要人工输入计算机、语言、手势等。其中,基于语言的人机交互是智能机器人应用中最理想的交互方式[2]。为了使机器人能够理解人类的语言,语音处理主要包括两个关键步骤:语音识别和语义解析。语音识别是将人的语音转化为语言文本,语义解析是对语音识别出的文本进行分析,推断说话人所要表达的语意。其中语音识别技术已经比较成熟,现在也有了许多商业化产品,例如科大讯飞的“讯飞语音输入”,语音识别率高达95%;而语义解析技术还处在发展当中,是现阶段语言处理中的研究热点。
语音识别领域的模型主要可分为3类:(1)隐马尔科夫模型HMM(Hidden Markov Model)[3-4]:该模型具有时序建模能力,语音识别结果良好,但模型中状态输出独立性假设为高斯混合模型;(2)神经网络模型NNM(Neural Networks Model)[5]:该模型具有自组织性、自适应和连续学习能力,但仅限于小词汇和语音识别;(3)混合模型:Geoffrey[6]提出将深度神经网络模型和隐马尔科夫模型相结合,应用于大词汇量的语句识别中,识别精度提高,且识别的错误率降低了30%。
语义解析的方法一般包括两种[7]:(1)基于规则的方法:该方法实现相对较容易,准确度高,但是不具有适应性,当场景变换时需要制定新的规则。骆家伟[8]等人研究智能家庭服务机器人语音系统,通过提取用户话语中的关键词进行匹配,实现简单的聊天和指令功能。李新德等[9]采用了基于组块的路径分析方法,实现了针对语言描述路径的机器人室内导航。(2)基于统计的方法:包括基于距离和相似度的算法、基于概率论的算法、基于机器学习的算法,该方法使用灵活,场景的变化时可以快速移植[10]。Pulasinghe[11]等人提出了一种基于模糊神经网络的理解算法,实现了对用户模糊语义的理解。两种方法都依赖于文本数据,通过挖掘相关知识,进行语义理解。不同的地方是基于规则的方法挖掘的是关联规则,而基于统计的方法挖掘的是是统计特征。
基于以上分析,语音处理中的模型专注于语音表层信息的识别,缺乏深层信息识别相关内容。为进一步提高图书馆服务机器人语音指令的理解能力,本文提出了一种新的基于概率模型和双受限波尔兹曼机神经网络混合模型的机器人语音指令深层信息解析系统,并通过仿真实验验证了方法的正确性。
1 图书馆服务语音指令分类
图书馆环境中,服务机器人所接收到的语音指令一般可由服务对象、操作对象、位置对象和指令对象4种实体组成。
(1)服务对象:图书管理环境中,服务对象即为指令的发起对象,该对象是指令的发出者也是被服务的主体,通常为使用图书管理系统的人。例如:“给我拿一本《图书馆战略管理》”中的“我”。
(2)操作对象:操作对象是指在指令序列中被机器人作用的实体,图书馆中通常为书籍。例如:“给我还一本《图书价格管理制度研究》”中的书籍《图书价格管理制度研究》。
(3)位置对象:位置对象是指由服务对象指定的用来表示操作对象位置信息的对象。例如:“帮我将《图书价格管理制度研究》放在2号阅览室”中的“2号阅览室”。
(4)指令对象:指令对象是指由服务对象发出的动作指令。例如“开门”中的“开”、“拿书”中的“拿”等,该类对象往往是一条指令的必备成份。
由以上4种实体对象,可以组合出多种语音指令。为了研究的方便,将所有的简洁有效的语音指令分为3类。
(1)A类指令
A类指令结构为机器人―服务对象―操作对象类的语音指令。例如“给我拿一本《图书馆战略管理》”,意指机器人为我借一本书籍《图书馆战略管理》,这类指令也可以有其他表达方式,如“拿一本《图书馆战略管理》给我”或者“帮我借一本《图书馆战略管理》”。
(2)B类指令
B类指令是机器人―操作对象―位置对象类的语音指令。例如“将《图书价格管理制度研究》放在2号阅览室”,意指机器人将《图书价格管理制度研究》这本书放在2号阅览室,这类指令也可以有其他描述方式,如“拿一本《图书价格管理制度研究》到2号阅览室”或者“在2号阅览室放一本《图书价格管理制度研究》”。
(3)C类指令
C类指令是机器人―操作对象类的语音指令,该类指令的句型简短、目标明确、表达方式固定。例如“找到《图书馆信息资源建设与管理研究》”。
以上为图书馆服务机器人所接收到的常用语音指令类型,使用中可能会有交叉或者混合的指令类型。在实际的运行过程中,可以直接从语音识别的文本中理解指令的表层含义,但在执行的过程中仍需要对语音指令的深层信息进行解析,才能正确的操作命令。例如“帮我拿一本《图书馆信息资源建设与管理研究》”,通过表层信息可以提取出关键词“我”,“一本”,“《图书馆信息资源建设与管理研究》”。为了执行操作,需要在执行命令时,理解指令的深层信息,首先需要执行的动作是“借”而不是“还”;其次需要定服务对象的位置,这样才能完成服务命令;最后,还需要由图书的名称进行深层次的解析,定位操作对象的位置,这样才能规划运动的合理轨迹。因此,在图书馆服务机器人中研究新的有效的语音指令深层信息解析系统与方法非常必要。
2 基于混合模型的系统架构
人机交互中的语言理解的本质上就是将人的语言转化为机器可以理解的语言,基本框架如图1所示,包括输入层、分析层和输出层3个部分。
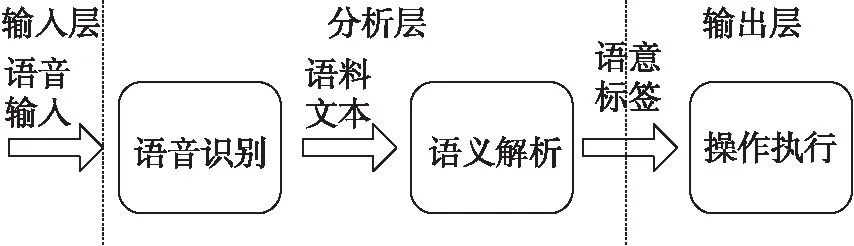
图1 语言语义理解框架
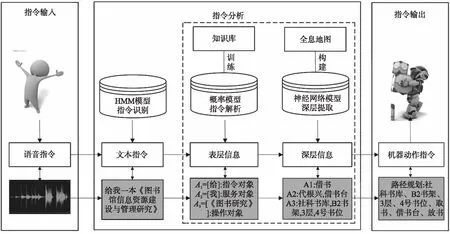
图2 深层信息解析系统结构
基于这一流程,本文提出一种基于混合模型的深层信息解析系统。系统包括以下流程:首先,人通过语音发出输入指令,结果显示为语音信号;其次,该语音信号作为指令分析模块的输入,基于隐马尔科夫模型,将其转化为文本信息;然后该文本信息作为语义解析模块的输入,基于概率模型的指令解析模块将各个词汇进行对象标注;进而由双受限波尔兹曼机神经网络模型[12-13]对服务对象、操作对象、指令对象和位置对象进行深层信息的提取和分析;最终由提取获得深层信息,构建处机器人动作指令的流程,规划出合理的操作顺序,输出指令。
以A类指令为例,操作员发出语音指令“给我一本《图书馆信息资源建设与管理研究》”。该指令首先储存为语音信号,基于隐马尔科夫模型,转化为文本指令,显示为文本信息{“给我一本《图书馆信息资源建设与管理研究》”}。文本信息进人语义解析模块,基于概率模型,解析出各个词与有效信息的映射关系,标注为{“[给]:指令对象”,“[我]:服务对象”,“[《图书馆信息资源建设与管理研究》]:操作对象”}。然后,将3种对象实体基于双受限波尔兹曼机神经网络模型进行深层信息提取,注释为{“指令对象:借书”,“服务对象:代根兴,借书台”,“操作对象:《图书馆信息资源建设与管理研究》,社科书库,B2书架,3层,4号书位”}。最后,由以上提取获得信息,对机器人的路径进行规划,{借书台―社科书库―B2书架―3层―4号书位―取书―借书台―放书}。至此,从语音指令输入,经过解析,输出给机器人一个完整的机器指令。
3 指令解析的数学表达
图2给出了深层信息解析系统的整体结构,在隐马尔科夫模型基础上获得文本信息进入指令解析模块。如图2中虚线框所示,指令解析模块分为两个部分,一部分为表层信息的获取,一部分为深层信息的提取。
3.1 表层信息提取
基于概率模型的语义提取方法有很多种,本文选取最大熵模型[14]。最大熵模型的核心思想是,对随机变量的概率分布进行预测时,除已知条件外,不对未知情况做任何假设,此时概率分布的信息熵最大。
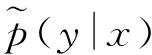
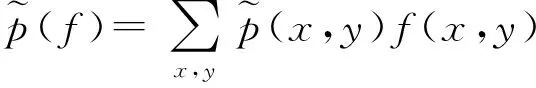
(1)
f(x,y)相对于模型条件概率分布p(y|x)的期望值为
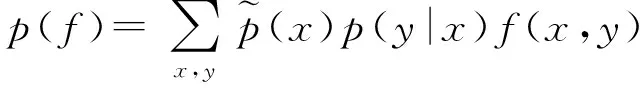
(2)
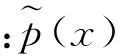
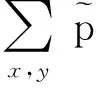
(3)
因此,在满足约束的集合内,最大熵模型的求解公式为:
p*=argmaxH(p)
(4)

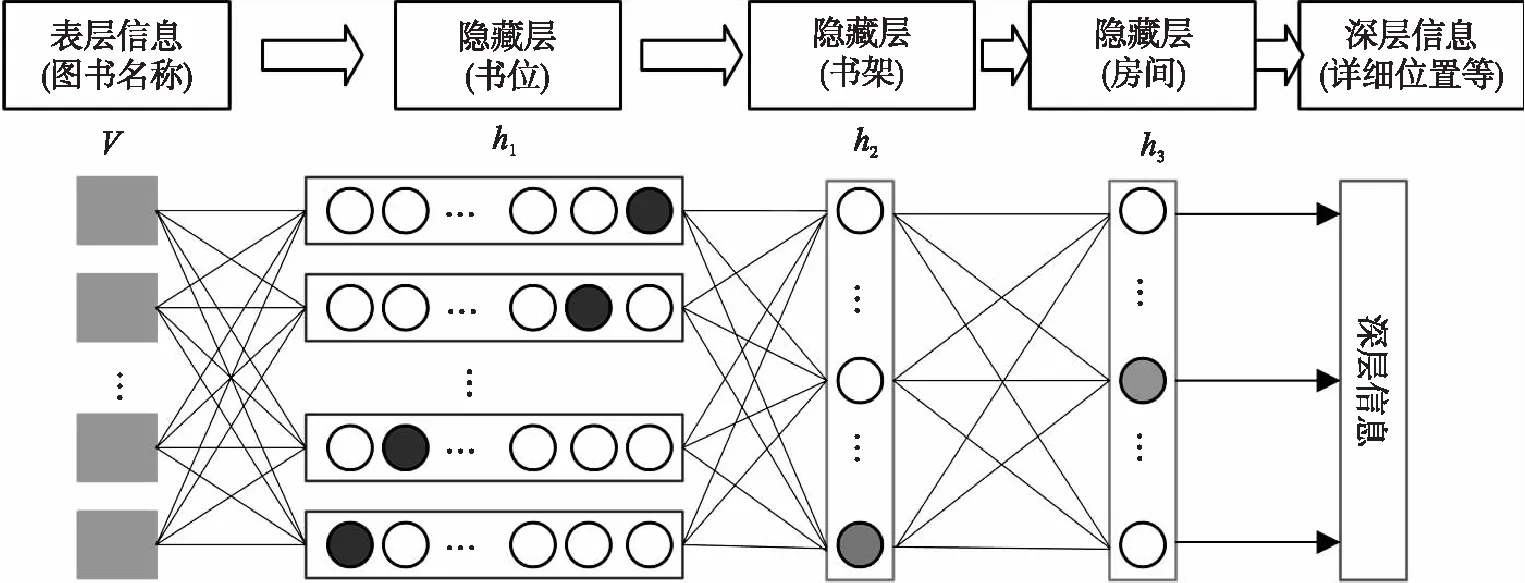
图4 基于多层受限波尔兹曼机神经网络模型的深层信息提取
利用所建立的最大熵模型求解语义标注问题。如图3所示,输入某一文本特征向量,利用式的最大熵模型,得到输出语义标注向量y1y2…ym,以及对应的概率向量p1>p2>…>pm,概率最大的语义标注即为最佳语义,从而完成文本信息的表层信息提取。

图3 基于最大熵算法的表层信息提取
3.2 深层信息提取
表层信息的获得是机器人能够了解语音指令中的各个实体对象,如操作对象和指令对象。但机器人在执行操作时,需要进一步了解在语音指令中包含的隐藏信息或者默认信息,因此需要进一步对各个实体对象进行深层信息挖掘。本文采用Geoffrey多层深度神经网络模型进行深层信息的提取。对于不同的实体对象,可能由不同层次的隐藏信息,因此神经网络模型的层次也不同,以图书馆服务中常用的A类指令中的操作对象为例,在了解书籍的名称之后,还需进一步对书籍的位置等隐藏信息进行深度解析。图4表示了基于多层受限波尔兹曼机神经网络模型,对操作对象进行深层信息提取的过程。该神经网络模型可表示为
Y=(v,h1,h2,h3;θ)
(5)
式中:V表示可见层;h1为第1个隐藏层(书位);h2为第2个隐藏层(书架);h3为第3个隐藏层(房间),θ是神经网络Y的参数。由已知的可见层中的参数Vi作为
输入条件,根据神经网络模型确定在第1个隐藏层h1j的信息:
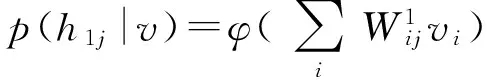
(6)
然后,将获得第1层隐藏信息h1j作为输入条件,识别第2层隐藏书架中的信息;同理,依次即可获得第3层房间的信息:
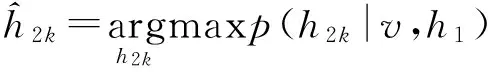
(7)
至此,通过多层受限波尔兹曼机神经网络模型,该操作对象所隐藏的深层信息都被挖掘出来,从而为机器人的动作指令规划提供完整的信息。其他实体对象的深层信息可通过相同的方法进行解析,但在实现的过程中根据对象的不同,其隐藏信息的层次有所区别。
4 实验结果与分析
以上几节对本文提出的基于混合模型的语音指令深层信息解析系统的结构和原理进行了详尽的介绍,在此基础上,采用仿真实验的方法对提出的模型和算法进行验证和分析。
4.1 基于数据的模型训练
首先在自然条件下采集图书馆环境下的语音库,作为知识库进行模型训练。选取4个学生的语音进行采集,其中两男两女。语音库包括3种不同结构的指令,实验中A类64条,B类48条,C类16条,每人共128条,四人共计512条语音。表1列出了语音类型中的训练示例,其中包括6个房间层,6个书架层,6个书位层和若干个操作对象。
模型训练之前,需要对生成的语音指令中的各个实体对象进行手动标注。将各条指令拆分为由服务对象、操作对象、指令对象和位置对象组成的指令。为了增加模型的准确度,验证模型训练所需的语音指令的个数,可将所有的512条命令随机的重复,以增加语音指令的数量。具体的操作为,将语音指令重复整数倍,再从其中随机抽选出若干指令。这种操作的优点为避免完全倍数重复条令带来的偶然性对模型训练的影响。
表2显示了十次实验之后模型训练的准确率变化和耗费时间的情况。从表中可以看出,当语音指令的个数较小时,随着指令数量的增加,模型的准确率和消耗的时间也明显增加;但是当指令的数量增加到4 096之后,模型的准确率的增加会显著的较小,甚至出现负增长,消耗的时间的增长也变慢。由此,得出以下两个结论:(1)训练模型的样本个数并不是越多越好,需要通过实验验证最优个数;(2)模型训练消耗时间的增长会随着样本个数的增加而逐渐减小,直至平稳。为此,本文在模型训练中选择4 096个样本,即原始样本的8倍,此时训练的时间为22.4s。
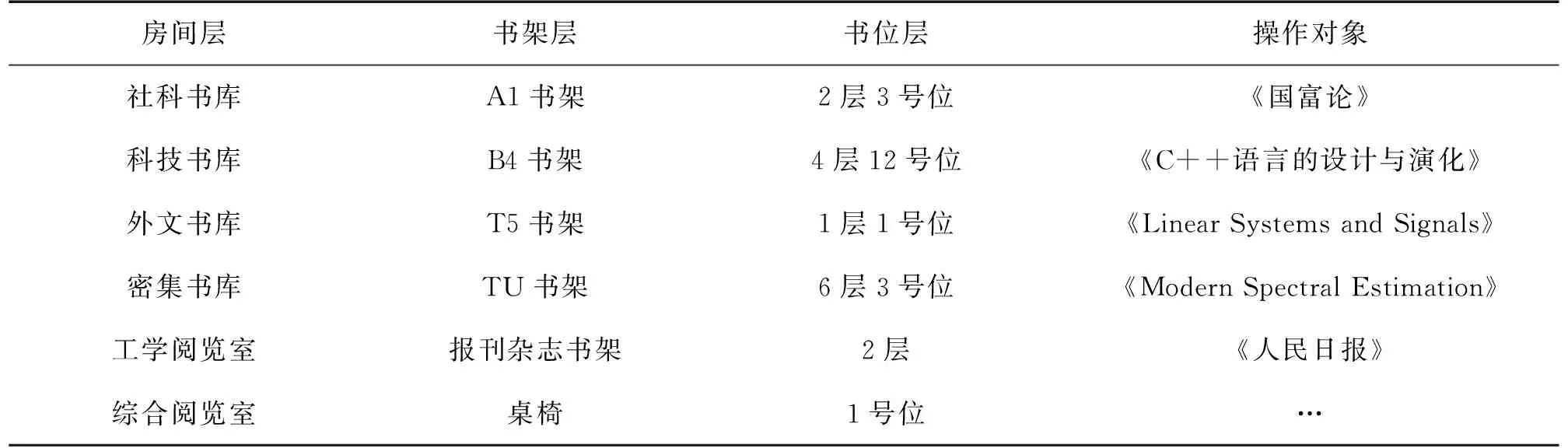
表1 语音训练示例

表2 模型训练的收敛性和复杂度[15]
4.2 语音信息的解析
在完成模型的训练之后,对实际的语音条令进行信息解析,其过程可以分为表层信息的提取和深层信息的提取。
图5给出了本文提出的混合模型与Kate等[16]提出的的KRISP模型和Mooney等[17]提出的规则模型对表层信息提取的准确率的对比。与其他两种模型相比,本文提出的混合模型信息提取系统识别表层信息的准曲率要高,十次实验中识别结果的准曲率都在90%左右;单独从混合模型来看,表层信息识别过程的稳定性非常好,十次实验准曲率幅值的跳动都不大。因此,可以得出从表层信息的识别结果来看,本文的基于混合模型的系统的结果要更好。

图5 表层信息提取的识别准确率对比
在表层信息结果的提取的基础上,进一步对深层信息提取的结果进行分析。图6给出了本文提出的方法对3类不同指令中深层信息提取的结果。总体来看,3种类型指令深层信息的识别准确率在75%左右,准确率的幅值在65%到85%之间,识别的结果较为稳定。与表层信息相比,解析信息的准确度有所降低。但从图7中,本文方法与传统方法的识别结果来看,基于混合模型的语音指令解析系统能够识别出传统系统无法提取的深层信息,有着明显的优势。基于深层信息识别准确率在75%左右,该方法有进一步研究提升的空间。
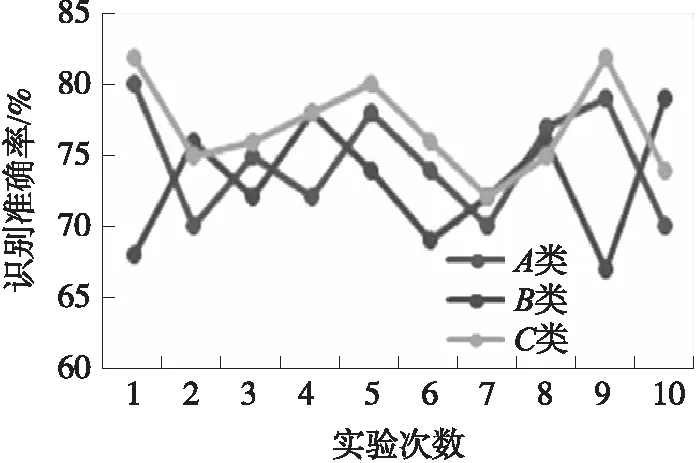
图6 针对操作对象的深层信息提取的识别准确率
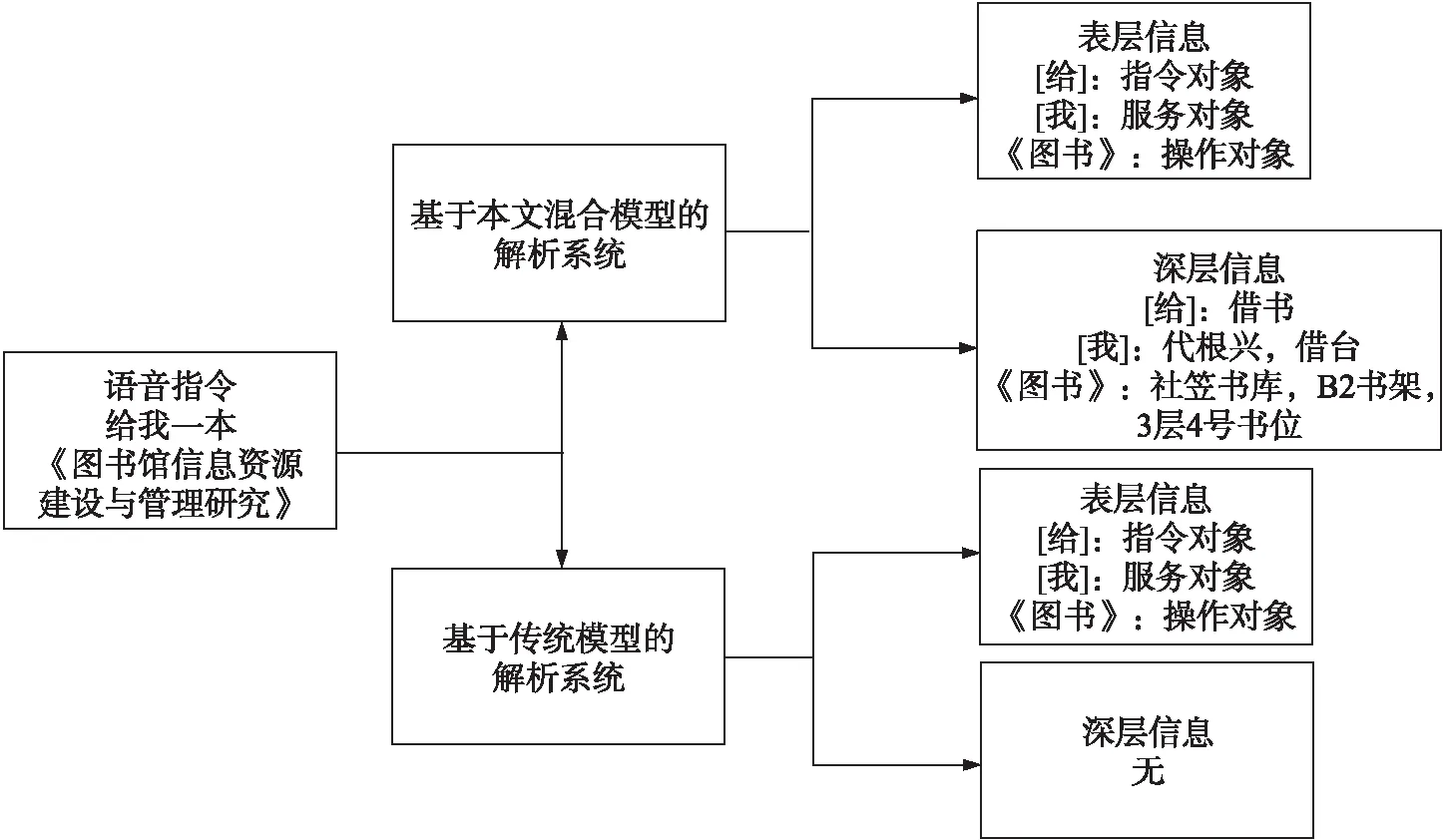
图7 深层信息提取的对比
5 结论
通过对传统的语义解析方法的研究和图书馆语言指令特点的分析,本文提出了一种新的基于混合模型的图书馆服务机器人语音指令深层信息解析系统,系统将基于最大熵的概率模型和基于多层受限波尔兹曼机神经网络模型相结合,实现了对语音指令中深层语义信息的识别和提取,与传统方法相比,能够使机器人更好的理解和实现语音指令。针对本文的研究结果,一方面,作者会进一步对系统本身的解析方法进行改进,以提高深层信息识别的准确性;另一方面,作者将致力于软硬件结合的实现,将所提出的方法在真实的图书馆机器人上得到应用。
[1] Wang M,Chen Y. The Research of Community Library Service for Youth Groups in USA[J]. Research on Library Science,2015.
[2] Jurafsky D,Martin J H. Speech and Language Processing[M]. Pearson,2014,24-29.
[3] Prestat E,David M M,Hultman J,et al. FOAM(Functional Ontology Assignments for Metagenomes):a Hidden Markov Model(HMM)Database with Environmental Focus[J]. Nucleic Acids Research,2014,42(19):e145-e145.
[4] 荆雷,马文君,常丹华. 基于动态时间规整的手势加速度信号识别[J]. 传感技术学报,2012,25(1):72-76.
[5] 陈华华,杜歆,顾伟康. 基于神经网络和遗传算法的机器人动态避障路径规划[J]. 传感技术学报,2004,17(4):551-555.
[6] Dahl G E,Yu D,Deng L,et al. Context-Dependent Pre-Trained Deep Neural Networks for Large-Vocabulary Speech Recognition[J]. IEEE Transactions on Audio,Speech,and Language Processing,2012,20(1):30-42.
[7] MacCartney B,Manning C D. Natural Logic and Natural Language Inference[M]//Computing Meaning. Springer Netherlands,2014:129-147.
[8] 骆家伟,牟琳,靳泰戈. 智能家庭服务机器人语音系统实现[J]. 计算机应用,2013(s2):322-325.
[9] 李新德,张秀龙,戴先中. 一种基于受限自然语言处理的移动机器人视觉导航方法[J]. 机器人,2012,33(6):742-749.
[10] Shimada K,Iwashiata K,Endo T. A Case Study of Comprehension of Several Methods for Corpus-Based Speech Intention Understanding[C]//Proceeding of PACLING 2007. 2007:255-262.
[11] Pulasinghe K,Watanabe K,Izumi K,et al. Modular Fuzzy-Neuro Controller Driven by Spoken Language Commands[J]. IEEE Transactions on Systems,Man,and Cybernetics,Part B:Cybernetics. 2004,34(1):293-302.
[12] Geoffrey E,Simon O. A Fast Learning Algorithm for Deep Belief Nets. Neural Computation,2006,18(7):1527-1554.
[13] Mohamed A,George E. Acoustic Modeling Using Deep Belief Networks. IEEE Transactions on Audio,Speech,and Language Processing,2014,20(1):14-22.
[14] 戴波,盛沙,唐建,等. 改进的Burg最大熵法在管道检测中的应用[J]. 传感技术学报,2007,20(6):1416-1419.
[15] 肖雪. 基于最大熵模型的中文文本层次分类方法[J]. 计算机与网络,2015(9):36-38.
[16] Kate R J. Learning for Semantic Parsing with Kernels under Various Forms of Supervision[M]. The University of Texas at Austin,2007.
[17] Mooney R J. Learning for Semantic Parsing[C]//International Conference on Intelligent Text Processing and Computational Linguistics. Springer Berlin Heidelberg,2007:311-324.
AParsingSystemBasedonHybridModelforLibraryServiceRobot’sVoiceCommand
ZHANGLifen1*,LIPing2,GUOXinling1
(1.Inner Mongolia Vocational College of Chemical Engineering Library,Hohhot 010010,China;2.School of Information Engineering Huanghuai University,Zhumadian He’nan 463000,China)
Based on the present situation of the wisdom library technology,the human-computer interaction issues of the library service robots was studied,and a hybrid model was proposed on the basis of the parsing system for voice command depth information parsing. First,the situation of library service robots and the problem in semantic analysis methods were analysed. Then,a hybrid model based on the probability and neural network was proposed,and deep information were identified from the voice command. Finally,experiments based on the simulation were verified using the comparision with other classical methods. The results show that the proposed sysetm can extract surface and deep information more accurately.
voice parsing;deep information;hybrid model;library robot;information extraction
10.3969/j.issn.1005-9490.2017.06.047
2016-02-03修改日期2017-05-10
TP242
A
1005-9490(2017)06-1575-07

张丽芬(1980-),女,内蒙古呼和浩特人,汉族,本科,高级讲师,研究方向为计算机、信息技术;

李平(1976-),女,河南驻马店市人,汉族,硕士,讲师。研究方向为信息处理与现代电子系统;

郭新灵(1980-),男,内蒙古呼和浩特市人,汉族,本科,高级工程师,从事电子政务云规划与设计。
猜你喜欢
科普童话·神秘大侦探(2023年1期)2023-05-30 12:48:10
电子技术与软件工程(2021年14期)2021-09-23 01:53:24
电脑报(2020年38期)2020-10-14 22:27:04
水利规划与设计(2020年1期)2020-05-25 08:01:34
物联网技术(2019年5期)2019-07-29 00:56:35
测控技术(2018年5期)2018-12-09 09:04:26
电子测试(2018年18期)2018-11-14 02:30:34
铁道通信信号(2018年1期)2018-06-06 02:27:37
中国卫生(2015年1期)2015-11-16 01:05:58
浙江伦理学论坛(2014年0期)2014-03-01 02:48:48
