
基于案例推理的高血压辅助诊疗方法研究
2017-12-20 01:16:09蒋乔薇王新宴张莎莎
转化医学杂志 2017年6期
王 蕾,蒋乔薇,王新宴,张莎莎,王 枞
基于案例推理的高血压辅助诊疗方法研究
王 蕾,蒋乔薇,王新宴,张莎莎,王 枞
针对高血压临床诊疗过程中的案例数据进行处理与分析,提出基于案例推理的高血压辅助诊疗方法。对高血压复杂的案例数据进行整理分析,提取案例中的关键症状作为特征属性构成案例模版,对高血压案例的症状进行创新特征表达,并提出一种快速案例推理的检索方法。根据病理原理以及数据分析提出采用内省学习方法,不断学习案例症状属性的权重,实现更高效、更准确的案例匹配。辅助诊疗方法提高了案例推理的准确率与高效性,有助于提高高血压辅助诊疗的自动化水平。
案例推理;高血压;辅助诊疗;案例检索;多属性决策
高血压是我国常见的慢性病之一,1991年我国约有9 000万高血压患者,目前我国高血压患者人数已经高达3.3亿,患病人群多为40~50岁,近年来更有年轻化趋势[1]。高血压极易发展为心脑血管疾病,引起卒中、心肌梗死或肾功能不全等严重并发症,危害人类健康。
案例推理是一种很重要的类比推理方法,案例推理的基本思想是利用已有的解决类似问题的经验案例进行推理求解新问题,即目标案例[2]。案例推理发展于1980年,是应用于人工智能领域中一种较新的问题求解和机器学习方法。目前案例推理系统已经广泛应用于机械行业、工业设计、天气预报等诸多领域,且得到越来越多的关注[3]。在医疗领域中由于医疗数据的复杂性和特殊性,案例推理的应用尚没有达到理想的效果,已经研发出的案例推理系统大多应用于中医诊断,尚缺少在临床方面案例推理的应用。同时,在案例推理系统中,案例检索是非常重要的,检索策略的合理性与否直接影响整个辅助诊疗系统的实现效果。其中,以相似度为基础的最近邻策略得到广泛关注,很多文献都讨论了属性间权重分配问题,比如遗传算法[4]、信息熵等[5-7]。即使当前医疗技术处于不断发展之中,某些参数的属性权重可能需要改变[8],但在使用这些算法时一旦系统确定了权重便不能再轻易调整。于是,将权重优化内省学习方法引入案例推理系统中,通过检查系统自身的属性权重逻辑来改进权重带来的问题,实现系统自我学习、权重修正策略,便可以提高系统的检索准确率。本研究根据高血压的目标案例与案例库中的案例检索对比分析,以发现案例之间的相似度,达到临床辅助诊疗的效果。
1 高血压案例推理流程
在案例推理系统中,当遇到新的案例时,在案例库中检索最接近的案例,并推荐医生采用源案例的解决方法来处理目标案例,达到辅助诊疗的目的。如果案例库中检索不到相类似的案例,则人工提出解决方法,并将该案例和新的处理方法存储到知识库中,从而完成学习过程。案例推理系统的设计包含案例表示、案例检索、案例重用、案例修正和案例保存5个部分。系统运行的模型见图1。
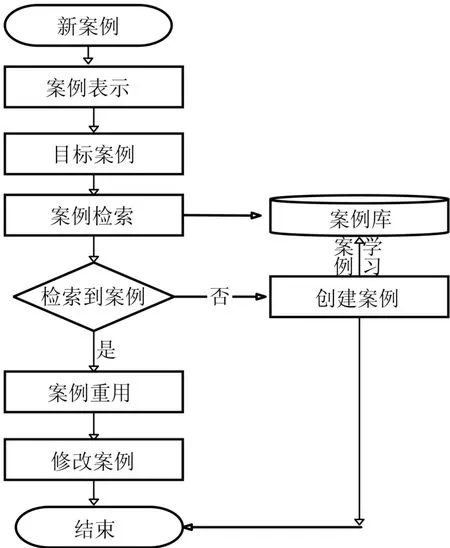
图1 高血压案例推理模型
2 高血压案例特征向量表示及辅助诊疗案例库设计
2.1 案例症状特征向量表示 高血压患者的病例症状数据类型可以分为确定数值型、二元变量型数值、模糊多概念型数值以及区间型数值4类。
2.1.1 确定数值型 所记录的症状属性信息值是连续型的、离散的,取其实际值作为特征值,表达:

其中,a为常数,但在计算确定数值型相似度时,取值范围大的属性对相似度的影响肯定高于取值范围小的属性,为了解决该问题,即要对各个属性的数值大小进行规格化统一。规格化的做法即是将案例中的各个属性值按照比例映射到统一的区间,这样就可以平衡案例中不同属性数值大小范围的影响。映射公式:
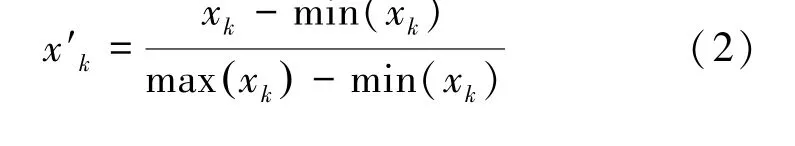
其中,max(xk)和min(xk)表示对某属性中所有特征描述的第k个属性的最大值与最小值。在高血压案例推理系统中,有关血压检查的很多数据都属于确定数值型,如患者年龄、血常规检查、血糖检查等。
2.1.2 二元变量型数值 即症状描述可以用明确的“是”“不是”或者“有”“没有”来表示结果。其参数化定义为:

高血压案例症状描述中很多属性具有2种变量值,类似布尔值,如患者的性别、尿蛋白检查结果用“+”“-”表示等情况,同样可以认为是二元变量型数据。
2.1.3 模糊多概念型数值 模糊多概念是指该症状描述没有确定的数量等级,而是用一系列定性的描述来表示其结果。例如在高血压案例描述中,患者的脑血管病史可能会有脑出血、缺血性卒中、短暂性脑缺血发作等多种结果。采用抽象化模糊集和归一化模糊集方式来确定模糊多概念属性的特征值。
2.1.3.1 抽象化模糊集 将相应的症状描述属性首先转化为特征值集合描述{0,1,2,3,4}等这样按顺序对应的数字集合,0代表该症状正常,1等其他数字代表病情的严重程度逐步加重。
2.1.3.2 归一化模糊集 经过第一步抽象模糊转化将症状属性描述的字符转化为有一定顺序规律的模糊集,对于模糊集可以将其通过某种方法映射为值域在[0,1]上的一个映射。定义为:

其中,x为描述原症状的取值,n为描述原症状个数,xk为经过关系映射后得到的表征该症状的新的取值。经过映射之后,原模糊多属性元素均在区间[0,1]上,并且当该症状描述为多个属性时,症状描述采用相加计算得到症状表征描述。
2.1.4 区间型数值 某些症状的描述结果通常由一段区间变量表示,高血压案例中一般没有这类区间型数据,所以暂不考虑。
2.2 高血压辅助诊疗案例库设计 案例库用于存储案例源,高血压症状属性数据较多,选择其中权重较大的17个代表症状属性为例进行分析。各个特征属性的表达方式以及取值范围如:①高血压等级,分别为正常、1级、2级、3级;②性别,男性(1)、女性(0);③年龄,数值型;④吸烟,是(1)、否(0);⑤尿蛋白,有+(1)、没有-(0);⑥腹型肥胖,有(1)、没有(0);⑦血常规血红蛋白,数值型;⑧血常规白细胞计数,数值型;⑨早发心血管病家族史,有(1)、无(0);⑩尿糖,检查结果一共有5种,包括不变(-)、微量(+)、少量(++)、中量(+++)、大量(++++);⑪血清铁,数值型;⑫血清铁蛋白,数值型;⑬脑血管病史,没有该疾病史、脑出血与缺血性卒中、短暂性脑缺血发作;⑭心脏疾病,没有该疾病史、心肌梗死史、心绞痛、冠状动脉血运重建史、慢性心力衰竭;⑮肾功能受损,有(1)、没有(0);⑯糖尿病肾病,有(1)、没有(0);⑰空腹血糖,数值型。
高血压诊断性评估分类包括3个方面:①确定患者血压水平以及其他心血管危险因素;②判断患高血压的病因,明确有无继发性高血压;③寻找靶器官损害以及相关临床情况[9]。
3 高血压案例检索
在案例推理系统中,案例检索的方法直接关系到整个高血压辅助诊疗系统的性能,因此案例检索的匹配率是辅助诊疗系统的关键问题。案例检索的目的是为了快速有效地从案例库中找到与新的问题描述最相似的案例[10]。在案例检索算法中,使用最广泛的是以相似度为基础的最近邻检索方法,但此种计算方法对于案例库中相关性不大的数据比较敏感。高血压辅助诊疗系统中要考虑的因素众多,指标权重不同,在案例检索过程中,不同的属性权重会直接影响案例之间的相似度计算结果,进而影响辅助诊疗系统的评判结果。
3.1 症状的特征向量局部相似度计算 根据上述高血压案例结构定义的症状特征描述数据类型的不同,分别定义不同数据类型的局部相似度计算公式,从而避免数据类型不同不具备可比性的问题。例如,案例库中存在2个案例分别定义为X=[x1,x2,…xk,…,xn]和Y=[y1,y2,…yk,…,yn]。
3.1.1 确定数值型相似度计算 数值型的相似度计算公式:
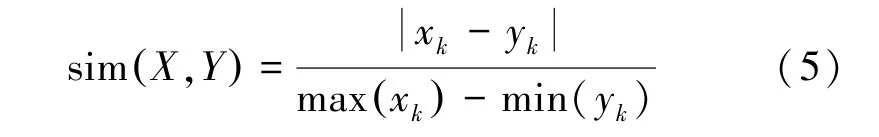
3.1.2 二元变量型相似度计算
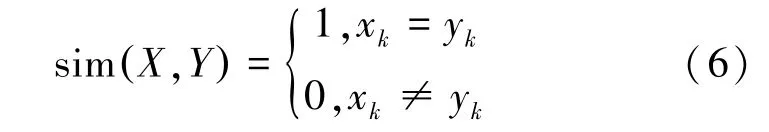
3.1.3 模糊多概念型相似度计算 对于模糊多概念型数据类型,由上文可知,对于模糊集在[0,1]上的隶属度,可以用它们自身的隶属度之差来表示2个案例之间模糊多概念型相似程度[11],因此可以定义:
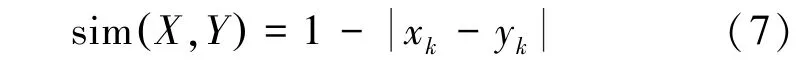
3.2 高血压症状特征向量全局案例相似度计算若案例库中存在2个案例X、Y则可根据上文所述将每个案例的记录属性值根据数据类型的不同选择相似度函数计算案例的局部属性相似度,然后根据最近邻算法欧氏距离[12]的相似度定义计算全局案例相似度:

3.3 权重的内省学习 在上述公式中对每个指标采用的是相同权重匹配案例库中的案例,而权重分配的不同会得到不同的相似度计算结果,进而影响案例匹配的准确性。权重的调整方式是内省学习中比较关键的方法,最基本的方法是加减或乘除一个固定量。根据2个案例相同属性的描述,将案例分为症状匹配属性和症状不匹配属性。
设有2个案例X=[x1,x2,…xk,…,xn]和Y=[y1,y2,…yk,…,yn],若满足则称案例X,Y的第k个症状属性匹配,否则称为症状不匹配属性。其中δmatch为判断属性是否匹配的阈值,表示2个案例同一属性的接近程度[13-14]。
权重学习策略基于内省学习原理:
(1)当多条案例与目标案例匹配成功时,症状匹配属性的权重增加,以此增加案例X,Y匹配的相似度。
(2)当多条案例与目标案例匹配成功时,不匹配属性的权重减少,以此增加案例X,Y的匹配相似度。
权重增加:
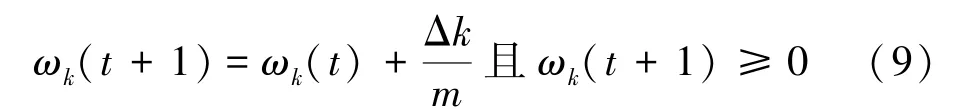
权重减少:
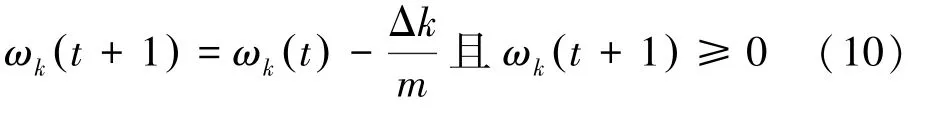
其中,ωk(t)是第k个属性第t次迭代的权重;ωk(t+1)是第k个属性第t+1次迭代的过程权重决定权重的变化量,m是案例中属性的个数。当一条案例所有的权重都被调整之后,为保证所有属性的权重之和为1,则需要进行归一化操作:
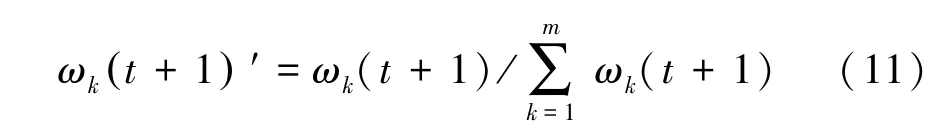
其中,ωk(t+1)′是第k个属性第t+1次迭代的最终权重。权重迭代计算时,要确定权重是有界的,即权重过程是收敛的[15]。
3.4 案例保存 案例保存是整个案例推理系统的学习过程之一,保障了系统的自学能力,使得系统可以逐步提高推理能力。如果目标案例在案例库中没有相似度很高的源案例,或者源案例的解决方案不适合目标案例,则需要将目标案例和相应的解决方案添加到案例库中,这即是案例学习过程。
4 高血压辅助诊疗方法研究验证实验
4.1 实验数据 实验数据来自高血压医享网(www.yx129.com/index.php)积累病例,整理选取其中300条高血压病例,部分案例数据见表1,选取100条不同高血压病情严重程度(低危、中危、高危、很高危)的案例记录作为训练集,分为4组,其他200条案例作为测试集。根据医生以及系统累积经验,暂将内省学习权重调整值设定为0.15/17,17为案例中属性个数,每个匹配属性的阈值δmatch取为0.1。分为4组对比实验。
(1)不使用内省学习方法的辅助诊疗系统计算方法。在案例不断测试添加的过程中,系统案例属性要素的权重不会改变。
(2)使用内省学习方法的辅助诊疗系统计算方法。在案例计算的不断对比学习过程中,案例属性不断改变。
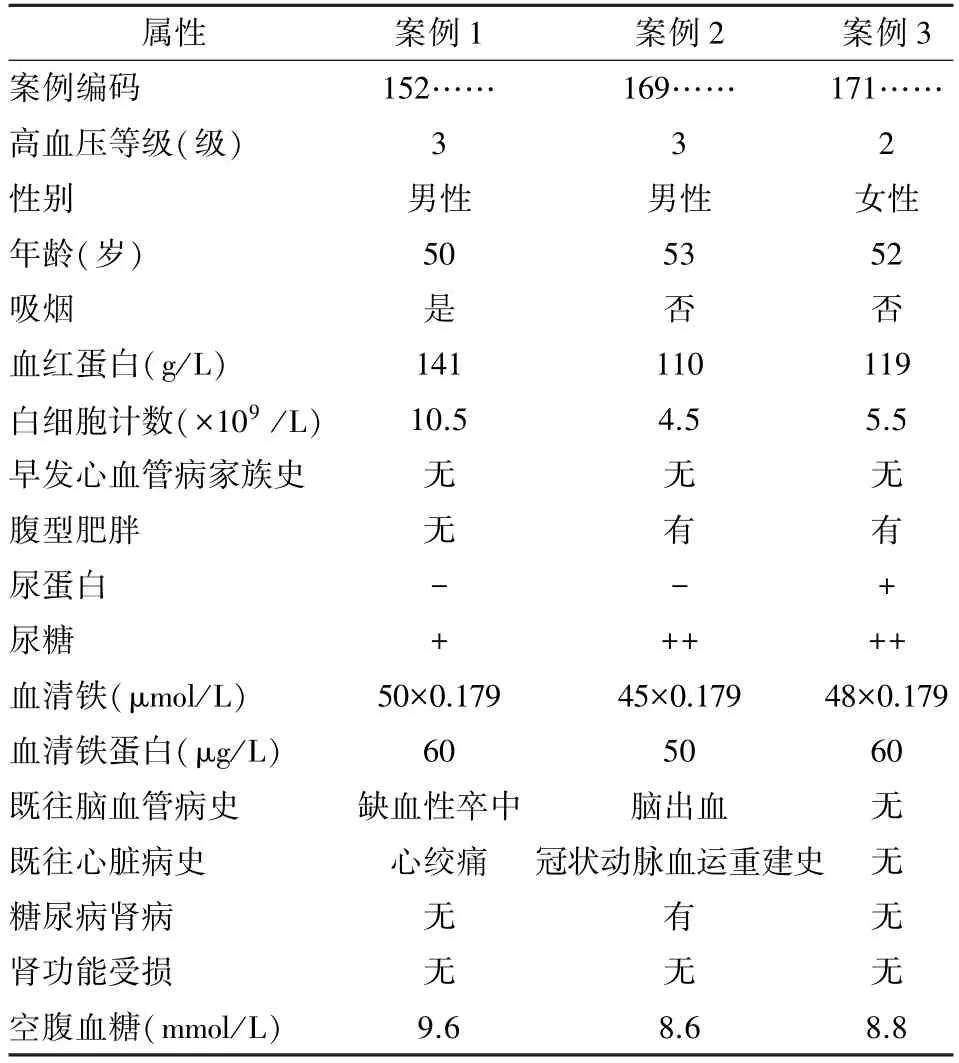
表1 部分高血压案例实例数据集
4.2 实例计算过程分析 通过实际数据展示3个不同案例之间相似度计算过程。
其中假设初始权重相同,因此案例相似度计算过程有以下几种。
(1)将案例中的数据按照不同的数据类型计算公式分别计算出案例1、案例2及案例3的症状特征向量:
案例1=[0.25,1,50,1,141,10.5×109,0,0,1,0.8,50×0.179,60,0.5,0.6,0,0,9.6]
案例2=[0.25,1,53,0,110,4.5×109,0,1,1,0.6,45×0.179,50,0.75,0.4,1,0,8.6]
案例3=[0.5,0,52,0,119,5.5×109,0,1,1,0.6,48×0.179,60,0,0,0,0,8.8]
(2)将3个案例的特征向量分别根据数据类型按照公式分别计算出属性相似度。
案例1与案例2每一项的相似度初步计算结果为[1,1,1,0,1,1,1,0,1,0.8,1,1,0.75,0.8,0,1,1]。
案例1与案例3每一项的相似度初步计算结果为[0.75,0,2/3,0,22/31,5/6,1,0,0,0.8,0.4,0,0.5,0.4,1,1,0.8]。
案例2与案例3每一项相似度初步计算结果为[0.75,0,1/3,1,9/31,1/6,1,1,0,1,0.6,1,0.75,0.6,0,1,0.2]。
(3)根据公式(8)计算全局案例相似度为:
sim(案例1,案例2)=0.86916
sim(案例1,案例3)=0.6442
sim(案例2,案例3)=0.69061
此计算过程每个属性的权重是相同的。
(4)根据内省学习方法,每次从案例库中查找相似案例,案例每个属性的权重都会进行相应的改变,例如迭代3次后根据属性的变化,重新计算权重之后案例相似度为:
sim(案例1,案例2)=0.83627
sim(案例1,案例3)=0.66523
sim(案例2,案例3)=0.69672
4组对比实验,每组共为25个案例测试集,每组的测试集分别对应由高到低的高血压病情严重程度,测试结果见表2。
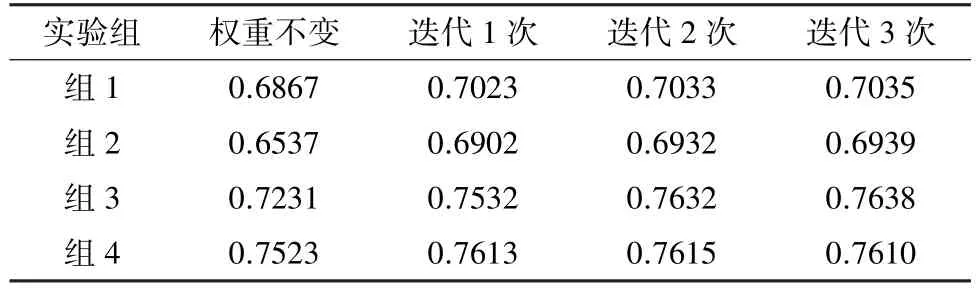
表2 内省学习方法测试结果
根据计算结果比较,加上专业医生的查看结果判定内省学习方法确实提高了案例相似度计算的匹配率,不同病情严重程度的高血压案例匹配率都有所提高,匹配的准确度也有所提高,并且迭代次数越多准确率越高。
为提高辅助诊疗的自动化水平,本研究提出了基于案例推理的高血压专科辅助诊疗方法。首先,针对高血压的病例数据进行分析与整理,提取病例中关键症状信息构建案例模版并将案例症状属性数据结构化展示,依据高血压专科案例的属性与案例库构成分级、分层结构;然后,采用内省学习方法使得权重每次检索之后都能自动调整,提高案例检索结果的准确度;最后,根据临床上的实际案例数据进行案例之间的相似度计算,结果表明确实提高了案例检索的准确率。
本研究构建的高血压专科辅助诊疗系统可以起到很好的辅助决策作用,具有很好的临床应用前景。在以后的研究中将进一步完善症状描述属性选择的相关问题,拟将高血压所有临床症状进行记录并可由医生选择任意相关症状进行案例对比,并逐渐确定症状权重迭代学习的稳定性,进而使辅助诊疗方法更加具有实用性。
[1]杨秉辉.惊悉我国高血压病人3.3亿[J].食品与生活,2013(8):52.
[2]Allsopp DJ,Harrison A,Sheppard C.A database architecture for reusable common KADS agent specification components[J].Knowl-Based Syst,2002,15(5/6):275-283.
[3]Bichindaritz I,Montani S,Portinale L.Special issue on casebased reasoning in the health sciences[J].Appl Intell,2008,28(3):207-209.
[4]Ahn H,Kim KJ,Han I.Global optimization of feature weights and the number of neighbors that combine in a casebased reasoning system[J].Expert Syst,2006,23(5):290-301.
[5]Wang H,Xu A,Ai L,et al.An integrated CBR model for predicting endpoint temperature of molten steel in AOD[J].ISIJ Int,2012,52(1):80-86.
[6]Zhou YN,Zhu YA.Algorithm for adjusting weights of decision-makers in multi-attribute group decision-making based on grey system theory[J].Control and Decision,2012,27(7):1113-1116.
[7]Huang MJ,Chen MY,Lee SC.Integrating data mining with case-based reasoning for chronic diseases prognosis and diagnosis[J].Expert Syst Appl,2007,32(3):856-867.
[8]Mabotuwana T,Warren J,Kennelly J.A computational framework to identify patients with poor adherence to blood pressure lowering medication[J].Int J Med Inform,2009,78(11):745-756.
[9]刘力生.中国高血压防治指南2010[J].中华心血管病杂志,2011,39(7):701-708.
[10]Bichindaritz I.Prototypical case mining from biomedical literature for bootstrapping a case base[J].Appl Intell,2008,28(3):222-237.
[11]Herrera F,Martinez L.An approach for combining linguistic and numerical information based on the 2-tuple fuzzy linguistic representation model in decision-making[J].Int J Uncertain Fuzz,2000,8(5):539-562.
[12]Aamodt A,Plaza E.Case-based reasoning:foundational issues,methodological variations,and system approaches[J].Ai Commun,1994,7(1):39-59.
[13]Zhao K,Yu X.A case based reasoning approach on supplier selection in petroleum enterprises[J].Expert Syst Appl,2011,38(6):6839-6847.
[14]García J,Cano JR,García S.A nearest hyperrectangle monotonic learning method[M].Switzerland:Springer International Publishing,2016.
[15]张春晓,严爱军,王普.案例推理分类器属性权重的内省学习调整方法[J].计算机应用,2014,34(8):2273-2278.
Computer-aided diagnosis method for hypertension treatment with case-based reasoning
WANG Lei1,2,JIANG Qiaowei1,2,WANG Xinyan3,ZHANG Shasha1,2,WANG Cong1,2
(1.School of Software,Beijing University of Posts and Telecommunications,Beijing 100876,China;2.Key Laboratory of Trustworthy Distributed Computing and Service,Ministry of Education,Beijing University of Posts and Telecommunications,Beijing 100876,China;3.Department of Special Diagnosis,Air Force General Hospital,Beijing 100142,China)
In this paper,through analyzing the treatment process data during the hypertension clinical diagnosis,the computer-aided diagnosis method is proposed for hypertension diagnosis with case-based reasoning.Based on the analysing for the complicated case data of the hypertension,the key information and the key symptom attribute information of the case were extracted to construct the case template.Based on the innovative expression for the symptoms of hypertension cases,a rapid retrieval method with case-based was proposed.According to the theory of pathology and data analysis,an introspective learning method was proposed,which is used to study the weights of case symptom attributes and to achieve a more efficient and accurate case matching process.The method can improve the accuracy and efficiency of case-based reasoning,and it also proves that the method is feasible and accurate,which can help to improve the level of the automation on diagnosis and treatment of hypertension.
Case-based reasoning;Hypertension;Computer aided diagnosis;Case retrieval;Multi-attribute decision
R447;R544.1
A
2095-3097(2017)06-0328-05
10.3969/j.issn.2095-3097.2017.06.003
科技部科技基础性工作专项(2015FY111700-06)
100876北京,北京邮电大学软件学院(王 蕾,蒋乔薇,张莎莎,王 枞),可信分布式计算与服务教育部重点实验室(王 蕾,蒋乔薇,张莎莎,王 枞);100142北京,空军总医院特诊科(王新宴)
2017-06-18 本文编辑:张在文)
猜你喜欢
绵阳师范学院学报(2023年10期)2023-11-01 00:43:30
中国毕业后医学教育(2022年4期)2022-11-29 03:50:54
水上消防(2021年4期)2021-11-05 08:51:50
北京教育·普教版(2021年6期)2021-08-23 08:57:35
内蒙古教育(2021年2期)2021-02-12 01:15:38
意林图解作文(小学版)(2019年6期)2019-07-16 08:35:46
韩国语教学与研究(2017年1期)2017-11-12 05:07:14
中国音乐教育(2017年4期)2017-05-20 09:21:04
西藏研究(2016年1期)2016-06-22 11:09:36
专利代理(2016年1期)2016-05-17 06:14:36
