
面向教务发布的隐私保护研究
2017-12-19 01:20:25王亚男
河北软件职业技术学院学报 2017年4期
王亚男,张 磊
(1.四平农业工程学校,吉林 四平 136100;2.佳木斯大学 信息电子技术学院,黑龙江 佳木斯 154007)
面向教务发布的隐私保护研究
王亚男1,张 磊2
(1.四平农业工程学校,吉林 四平 136100;2.佳木斯大学 信息电子技术学院,黑龙江 佳木斯 154007)
随着数据使用范围和应用领域的扩大,数据挖掘和数据分析技术得到了飞速发展。而教务系统的广泛应用,使得教务数据的发布面临泄露学生以及教务信息隐私的威胁,针对教务数据多以统计信息形式进行发布的特性,提出了基于ε-差分隐私的教务数据隐私保护方案。
教务数据;隐私保护;差分隐私
0 引言
教务数据具有较为广泛的公开使用范围和较为严格的私密性,当获得大量教务相关数据时,无论是恶意的攻击者还是非恶意的好奇者,都可以按照教务数据的自然或统计规律获得教务管理部门或学生所不愿公开的信息。如何将这些教务统计数据在保持最大可用性的情况下发布给教务数据使用者,同时最大限度地保护教务管理部门以及学生的隐私,成为了教务数据发布所面临的重要信息安全问题。本文利用ε-差分隐私的保护方法,将这种针对统计数据的当前最为有效的隐私保护方案与教务统计数据相结合,克服基于k-匿名方法在统计数据发布中可能存在的各种不足,为教务统计数据的发布提供了有效的隐私保护,同时为差分隐私保护提供了有益的应用方案。
1 ε-差分隐私
差分隐私是在2006年针对统计数据可能存在的隐私泄露问题,提出的最新型隐私定义[2]。与以往常用的k-匿名模型不同,在这种标准定义下,对任何数据集合进行处理产生的结果都不会因其记录中某条数据变化导致敏感性差异,进而决定了单条数据是否存在于该数据集合中,对整个统计分析的计算结果不会产生较大影响。也就是说,一个记录在整个数据集合中是否加入或者删除,不会对整个数据集合的统计分析结果产生影响,从而使得该数据集合产生的隐私泄露风险最小化,并在用户可以接受的范围内。因此,攻击者即使通过对该数据集进行多次结果比较,仍无法准确获得某个个体的隐私信息。
传统的k-匿名模型存在两个未能解决的缺陷:最大背景知识假设和缺乏严格定义的量化评估方法。差分隐私的提出很好地解决了这两个问题[1]。差分隐私的特点在于,该模型是建立在假设攻击者能够获得除所需要目标外所有可能获得的其他记录作为攻击可使用的背景知识,即最大可掌握背景知识的基础上。另外,该模型具有坚实的数学基础,并且对隐私进行了严格的定义和量化评价指标,针对不同参数设定下的数据集合处理结果提供了较好的比较和评价,并能证明隐私保护方案的优劣。因此,差分隐私理论迅速被业界认可,并逐渐成为隐私保护领域的一个研究热点。近几年来,差分隐私和其他领域研究的结合使得大量新成果不断涌现[3-5]。
ε-差分隐私保护的基本思想是在给定的两个数据集S和S’中,只存在至多一条相差记录,使得|S-S’|≤1,存在一种隐私保护算法f,可使在f作用下对数据集S和S’中的任意输出结果集合O存在:

其中,概率p表示由算法f导致的随机性控制;ε表示隐私预算,即隐私保护程度,该值越小则隐私保护程度越高。
2 教务数据发布的隐私保护方案
以教务数据发布中的学生成绩为例。假设攻击者通过查询获得5个人和4个人当前科目的总成绩,且相差的一个数据即为攻击者希望获知的某个学生的成绩隐私。利用两个统计数据量,攻击者可用两组数据差的方式获得该学生的成绩隐私。
假设存在如表1所示的学生成绩,进行统计插叙可获得M(S)=count(i)的成绩集合,若Jim不希望自己的成绩被别的用户通过统计查询的方式获取,而攻击者可通过 M(5)-M(4)=count(5)-count(4)的方式获取到该成绩。

表1 学生成绩
基于这种情况,本文利用ε差分隐私数据发布中较为常见的噪声机制保护成绩数据隐私,即在每个查询获得的成绩集合中添加满足拉普拉斯分布的随机噪声扰动。
设M是对数据进行的统计查询操作,则有f(S)=M(S)+Y,其中 Y~Lap(△/ε)为添加的随机噪声,该噪声的服从尺度参数为△/ε的拉普拉斯分布。此时,其概率密度函数p(x)可表示为:
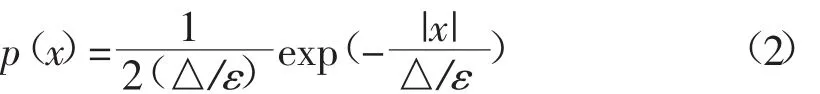
设b=△/ε可得由图1所示的不同拉普拉斯概率密度函数的图形,从中可以看出,当ε的取值越大时引入的噪声数据越大,越不利于发布后的数据使用,隐私需要对不同敏感度的教务数据采用不同的隐私保护预算,以实现教务数据隐私保护和可用性之间的平衡。
继续本文前面关于学生成绩的例子,由于f(S)=M(S)+Y,使得 f(5)=M(5)+Y,同时 f(4)=M(4)+Y,这样即使攻击者通过多次查询计算f(5)-f(4)所得到的统计结果差值都不是Jim的真实成绩,且该差值满足拉普拉斯分布中任意随机位置的变化噪声值。由此,发布后的用户成绩统计数据得到了隐私保护。
对于统计数据发布后的可用性,需要选择合适的ε取值,按照参考文献[5]所给出的方法,可以较为准确且便捷地获得对教务数据可用性和隐私性的平衡,本文不再叙述。

图1 拉普拉斯概率密度函数
3 结论
教务数据由于其特殊性,使得对该数据信息的发布需同时兼顾隐私性与可用性。本文通过使用当前较为流行的差分隐私保护方法,对发布的教务数据进行噪声扰动添加,在一定程度上保护了教务数据中的用户隐私,为教务数据的隐私保护提供了一个有益的发展方向。然而,教务数据中的隐私问题并不局限于统计信息的发布,今后的研究工作将在更为全面的教务数据隐私保护方面展开。
[1]熊平,朱天清,王晓峰.差分隐私保护及其应用[J].计算机学报,2014,37(1):101-122.
[2]Dwork C.Differential Privacy[C].Automata,Languages and Programming.Springer Berlin Heidelberg,2006:1-12.
[3]张啸剑,孟小峰.面向数据发布和分析的差分隐私保护[J].计算机学报,2014(4):927-949.
[4]欧阳佳,印鉴,刘少鹏.一种有效的差分隐私事务数据发布策略[C].中国计算机学会人工智能会议,2013.
[5]何贤芒,王晓阳,陈华辉,等.差分隐私保护参数ε的选取研究[J].通信学报,2015,36(12):124-130.
[6]Dwork C.Differential Privacy:A Survey of Results[C].Theory and ApplicationsofModelsofComputation.Springer Berlin Heidelberg,2008:1-19.
Research on Privacy Protection for Educational Data Publishing
With the rapid development of data publishing and data mining technology,educational data publishing may reveal the students and educational information privacy,in view of characteristics of educational data,as they are also in the form of statistical information,this paper puts forward the educational data privacy protection scheme based on ε-differential privacy.
educational data;privacy protection;differential privacy
TP391.7
A
1673-2022(2017)04-0017-02
2016-11-17
佳木斯大学教育科研课题(2016jw2003)
猜你喜欢
包装工程(2023年24期)2023-12-27 09:18:26
海洋信息技术与应用(2021年1期)2021-06-11 01:20:34
大学(2021年2期)2021-06-11 01:13:16
传播力研究(2019年8期)2019-03-20 10:58:14
信息记录材料(2016年4期)2016-03-11 15:23:04
现代计算机(2016年11期)2016-02-28 18:35:21
当代教育理论与实践(2015年9期)2015-12-16 16:26:04
河南科技(2015年7期)2015-03-11 16:23:13
中央民族大学学报(自然科学版)(2014年2期)2014-06-09 08:28:14
郑州大学学报(理学版)(2014年3期)2014-03-01 04:21:01
