
基于流体系架构的分组密码处理器设计
2017-12-16 05:19李功丽戴紫彬徐进辉王寿成朱玉飞
计算机研究与发展 2017年12期
李功丽 戴紫彬 徐进辉 王寿成 朱玉飞 冯 晓
1(解放军信息工程大学 郑州 450001) 2(河南师范大学计算机与信息工程学院 河南新乡 453002)
基于流体系架构的分组密码处理器设计
李功丽1,2戴紫彬1徐进辉1王寿成1朱玉飞1冯 晓1
1(解放军信息工程大学 郑州 450001)2(河南师范大学计算机与信息工程学院 河南新乡 453002)
(lig1522@163.com)
为提升密码处理器性能,构建了密码处理器性能模型.基于该模型,提出多级资源共享、绑定前/后异或操作、最大化算法并行度等处理器性能提升技术,并根据性能提升技术确定了功能单元的种类和数量.然而功能单元不仅数量较多,而且在操作位宽和操作延迟方面均有较大差异,如何有效组织这些功能单元成为了一个关键问题.利用流体系结构可以高效集成大量功能单元的特点,设计并实现了基于流体系结构的可重构分组密码处理器原型,并通过把功能单元划分为基本处理单元,bank间共享单元和簇间共享单元3个层次来解决功能单元处理位宽和操作延迟的差异.在65 nm CMOS工艺下对处理器原型进行综合,并在该结构上映射了典型的分组密码算法.实验结果证明:该处理器以较小的面积获得了较高的性能,对典型分组密码算法的处理速度,不仅超越了国际上的密码专用指令处理器,而且高于国内可重构阵列结构密码处理器.
分组密码;流处理器;性能模型;可重构;密码处理器
最近几十年,信息安全已经逐步深入到政治、经济、军事以及人们日常生活的方方面面,并在上述领域发挥着越来越重要的作用.分组密码是保证信息安全的有效措施.随着信息安全需求的与日俱增,对分组密码处理的要求也越来越高,吞吐率一直是密码处理中首要考虑的性能指标.而随着密码应用场景的多样化和复杂化,还要求密码系统能够灵活适应不同算法,以应对不断发展的攻击手段和密码系统升级压力,所以密码系统的灵活性也变得越来越重要.上述这些要求都给密码处理器的设计提出了新的挑战.
可重构分组密码处理器面向分组密码处理进行优化,运算单元可重构使密码处理具有了较高的灵活性[1].同时,通过重复设置大量的功能单元来提高性能,但是功能单元种类的选择和功能单元数量的确定缺乏有效的理论分析作为基础,所以在性能提升的同时,往往导致面积和功耗的急剧增加,这使得开发出来的密码处理器因为面积和功耗的问题,在实际应用时受到诸多限制.本文以Amdahl定律[2]为基础,结合分组密码处理的特点,首先构建了密码处理性能模型,然后通过该性能模型确定功能单元种类及数量,从而在有效提升密码处理性能的同时,有效控制处理器的面积.
1 相关研究
国内外针对可重构分组密码处理器的实现技术展开了一系列研究,主要可归纳为可重构分组密码专用指令处理器结构和可重构分组密码阵列处理器结构.
可重构分组密码专用指令处理器的指令及运算单元面向密码应用进行优化,运算单元可重构,具有数据处理位宽大、处理并行性高、控制简单、开发便捷等优点.孟涛和戴紫彬[3]提出的可重构分簇分组式分组密码处理架构(reconfigurable clustered block cipher processor, RCBCP),可灵活地重构为4个32 b,2个64 b和1个128 b的数据通路,设计并实现了5级流水线以及运算单元内流水结构.Gaspar等人[4]提出的密码处理器HCrypt设计了分离的数据/密钥路径,集成了独立的加密模块和解密模块.Li等人[5]基于VLIW指令结构开发了4路32 b并行结构来提高可重构密码处理器的性能.相比于其他实现模式,专用指令处理器结构工作频率较低、密码处理性能有待进一步提升.
阵列结构可重构分组密码处理系统设计了面向分组密码的可重构运算单元,大幅提升了密码处理的性能.杨晓辉等人[6]提出的可重构分组密码处理模型(reconfigurable cipher processing architecture, RCPA),采用粗粒度可重构密码单元,能够在横向和纵向上开发分组密码并行特征.陈韬等人[7]提出了一种基于流处理架构的可重构分组密码阵列结构(stream based reconfigurable clustered block cipher processing array, S -RCCPA),通过设计基于Crossbar的分级互连网络连接多个粗粒度可重构的功能单元,构造了分簇式的密码处理阵列.Sayilar和Chiou[8]提出的可重构密码处理结构Cryptoraptor,通过集成80个基本重构单元实现了较高的性能.阵列结构的单元一般为同构结构,为确保处理单元能够广泛支持分组密码操作,处理单元设计比较复杂,面积和功耗较大,存在资源利用率低、用户开发困难等问题.
流处理器[9-10]作为近年来兴起的一种高性能处理器,主要针对计算密集型应用,通过集成大量的功能单元提供丰富的计算能力,从而获得了较高的性能.如Imagine流处理器在250 MHz下的峰值性能达到10GFLOPS,而Merrimac在1 GHz下的峰值性能达到128GFLOPS,且在实际应用中达到了117.3GFLOPS.流处理器以其对计算密集型应用所显示出的强大性能优势而成为了当前高性能计算领域的研究热点.
分组密码处理具有典型的计算密集性特征[11],是适合于流体系结构的应用.所以本文首先基于Amdahl定律构建了密码处理器的性能模型,然后在该模型的指导下,确定了密码处理单元的种类和数量,并基于流体系结构有效组织功能单元,设计了面向分组密码的可重构密码流处理器原型,最后通过综合实验验证了该原型的性能及面积优势.
2 基于Amdahl定律的密码处理性能模型
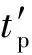
(1)
从式(1)可以得出,当I≥i时,无论I如何增加,都无法再进一步减少执行时间.即通过设置更多的硬件资源所能提高的并行度受限于算法本身的并行性.
令tpi对应的指令条数为Npi,则并行加速后所需指令条数为
(2)
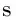
(3)
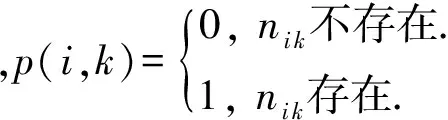
串行部分减少的指令条数为
).
(4)
通过对并行性部分的并行加速和串行部分的合并加速后,处理器完成密码运算所需时间为
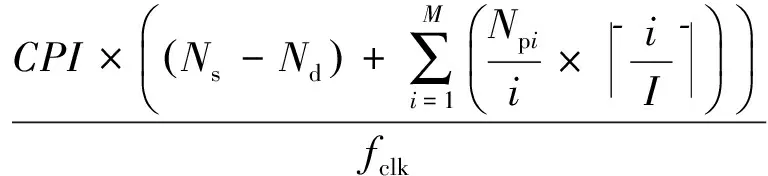
(5)
其中,CPI为执行一条指令的平均时钟周期数,fclk为系统主频(单位为MHz).此时,假设待处理的数据长度为L(单位为b),则吞吐率P为
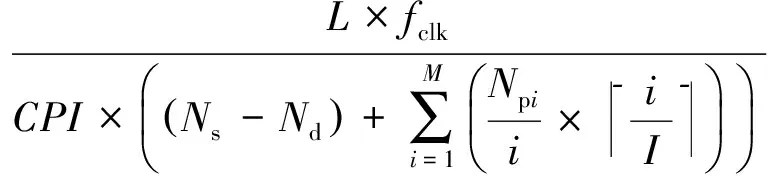
(6)
从式(6)可知,为了提高系统的吞吐率P,可通过提高系统频率fclk、减少指令的平均执行周期CPI、增加合并的串行指令数目Nd以及提供足够的并行处理资源I这4种途径提升密码处理器性能.
3 密码处理性能提升策略
下面将结合分组密码结构特征及基本单元的运算特征,分别针对fclk,CPI,Nd,I这4个参数来讨论密码处理器性能提升策略.
3.1 fclk与CPI——多级资源共享机制
根据前面的分析可知,提高系统频率fclk能够显著提升密码处理器性能,而频率取决于系统的关键路径.
首先选取国际上典型的分组密码算法作为样本进行研究.算法包括数据加密标准DES、高级加密标准AES,ISO/IEC分组密码标准(Camellia,MISTY1,CAST-128,TDEA,SEED)、欧洲NESSIE计划的分组密码、日本CRYPYTEC计划的分组密码、韩国标准ARIA以及行业标准IDEA,SMS4,CLEFIA,FOX,Skipjack等算法.选取的算法均有比较广泛的应用,结构也具有一定的代表性,基本可以代表当前分组密码的设计特点.
通过对所选21种算法的分解发现,首先分组密码算法整体结构主要有FEISTEL,SP,L-M等,基于相同或相似结构的分组密码具有相似的运算单元,涉及的操作类型有较大的交集,可归纳为S盒替代、移位、有限域乘法、模乘、模加/减、比特置换和基本逻辑等;其次操作的数据位宽集中于2类:
1) 32 b以内小位宽操作,特点是位宽小、并行度高;
2) 128 b以上大位宽操作,多是异或、置换和移位操作.
为了确定系统的关键路径,对上述算法集合中使用的运算进行统计,并采用65 nm CMOS工艺标准单元库,对8 b,16 b,32 b,64 b,128 b等不同操作位宽的基本密码运算单元进行逻辑综合,结果如表1所示.
由综合结果可知,不同运算单元的延时差异较大,运算单元的选取将会直接影响系统频率.
同时,影响系统性能的另一个因子——指令的平均执行周期CPI:
(7)
其中,CPIi,pi分别为第i类指令的执行周期数和使用频率.由式(7)可知,指令的使用频率对系统CPI有较大影响.假设系统使用频率最高的是指令i,当pj≪pi时,即使CPIj为多个时钟周期,对CPI的影响也十分有限,所以选择功能单元的目标是尽量减少使用频率高的指令的执行周期,从而降低CPI.
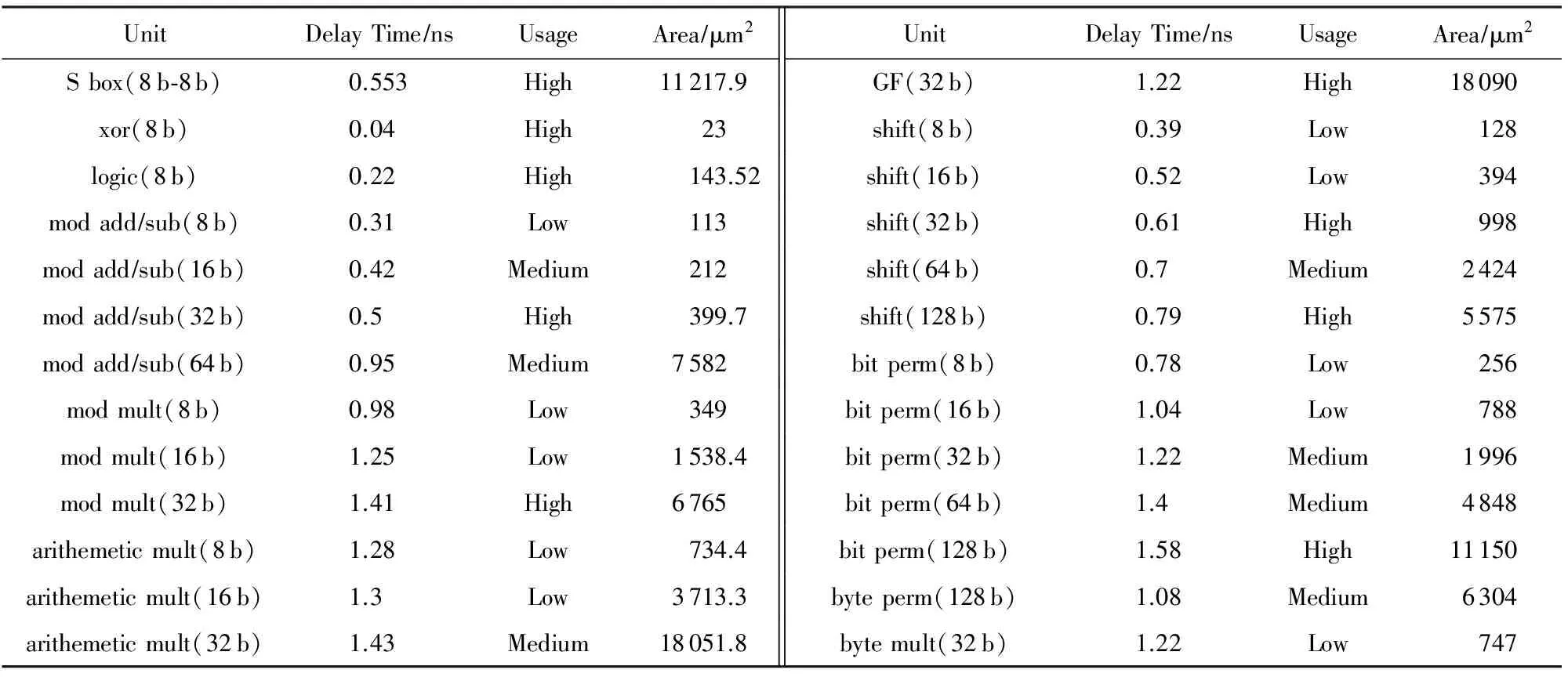
Table 1 Synthesization Results of Cryptographic Units (Frequency & Area)表1 密码运算单元综合结果(频率及面积)
根据上述分析,为使用频率高的指令设置专用的功能单元,使指令可以在1周期或2周期内完成,而对于使用频率较低的指令,综合考虑其重构代价和组合延时由这些基本单元重构或组合实现.
通过表1可知,使用频率高的8 b-8 b的S盒、8 b逻辑操作、32 b模加/减等延时都低于1 ns,不会影响处理器关键路径.而使用频率高的32 b有限域乘法、32 b模乘、128 b置换等单元的延时较大.集成这些大延时的单元会使系统频率降为原来的1/2或1/3,若不集成这些单元,一旦算法中包括这类操作,往往需要几个甚至十几个操作才能组合完成,从而使算法性能急剧变差.所以综合考虑系统频率及CPI,根据单元延时设置这些大延时的单元为2周期或是3周期,从而避免大延时的单元降低系统频率.
进一步考虑不同位宽单元的重构开销,确定构成系统的运算单元包括8 b-8 b的S盒、8 b逻辑单元和模加/减单元,32 b的模乘单元和有限域乘法单元以及128 b的移位和比特置换单元.8 b的模加/减单元虽然使用频率不高,但是通过设置进位链[12]可以并行实现16 b或32 b的模加/减操作,所以把8 b的模加/减单元作为基本运算单元.因为选择的运算单元位宽变化较大,所以如何有效地组织这些单元,既能使各个单元有效配合,高效实现密码算法,又能使单元之间的数据通路易于实现,是下一步要解决的关键问题.
首先选择8 b-8 b的S盒替代、逻辑运算和模加/减构成一个可重构密码处理bank(reconfigurable cipher processing bank, RCPB)作为系统的基本运算核心,RCPB的基本数据位宽为8 b.因为密码操作中,以8 b和32 b操作居多,所以把4个RCPB组成一个可重构密码簇(reconfigurable cipher processing cluster, RCPC).同一个簇中各RCPB的功能单元不是独立的,它们可以重构或组合实现16 b或32 b的操作.
有限域乘法和模乘单元均为32 b,组成bank间共享单元(inter-bank-shared unit, BSU),一个BSU对应4个RCPB.128 b的移位和置换组成簇间共享单元(inter-cluster-shared unit, CSU),每个CSU对应4个簇,可以同时与4个簇进行数据交互.
通过把使用频率高的指令用专用单元实现,使指令可以在1周期或2周期完成,从而有效降低CPI;把延时较长的指令设置为多周期,可以避免大延时单元降低系统频率;然后根据单元的位宽和重构效率等,把8 b位宽的运算单元组织成基本运算核心,大位宽的单元由多个基本核心共享.这种小位宽的运算核心加大位宽的共享资源,既能够让多个小位宽单元并行执行,又可以减少大位宽运算单元的数量,从而在提升处理器性能的同时,提高资源利用率并减少处理器面积.
3.2 Nd——绑定前/后异或
异或操作是分组密码中使用频率最高的运算,而且异或操作的延时和面积都非常小,通过将异或操作与其他密码操作组合实现复合操作,可以有效减少算法所需指令条数.以SMS4算法为例,在无绑定操作情况下,轮函数需使用13条指令,在支持指令绑定前/后异或的情况下,轮函数仅需使用7条指令,从而使指令条数减少了46.15%.通过对算法集合中的运算进行分析统计,异或运算绑定使用频率如表2所示:

Table 2 Usage of Binding Xor Operation表2 绑定异或操作使用频率
绑定有2种实现方式:
1) 利用执行过程中流水线的译码和写回段延时较小,把异或操作绑定在寄存器取数和写回段,这种方法不会影响系统的工作频率,但是会产生严重的数据相关问题,特别是无法实现数据旁路,而在密码运算中有大量的中间运算结果需要旁路,所以使用该方法会造成严重的流水线停顿;
2) 直接把密码操作与异或绑定,但是这可能会影响系统的关键路径,从而影响频率.通过分析异或操作与其他操作的使用频率及延时,选择使用频率高且对关键路径不影响或是影响较小的操作进行绑定.根据表2的统计结果,确定绑定异或的功能单元有S盒前后绑定、逻辑后绑定、模加后绑定、移位后绑定.
上述4个操作绑定后,延时均未超过关键路径.绑定异或操作前后,算法轮函数所需要的指令条数如表3所示:
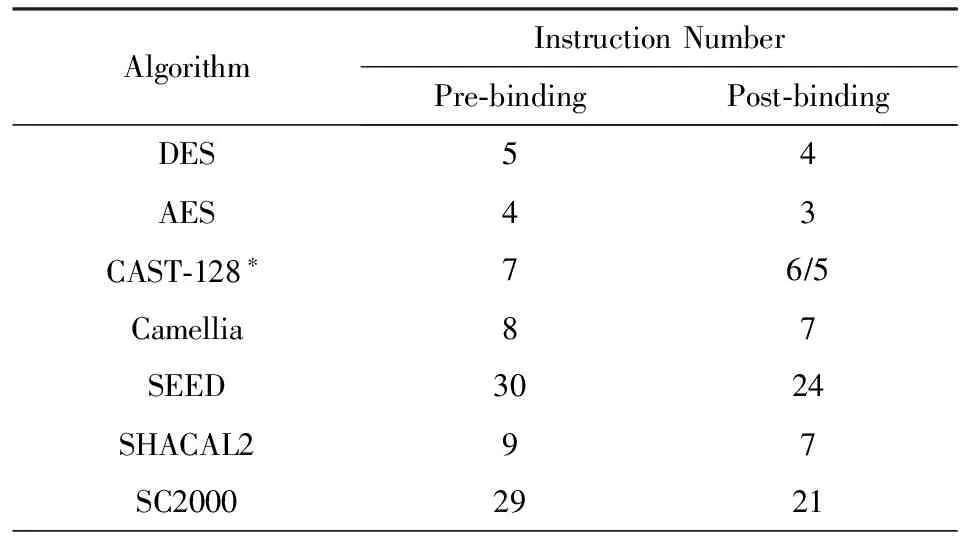
Table 3 Number of Round Function Instruction Pre-bindingand Post-binding
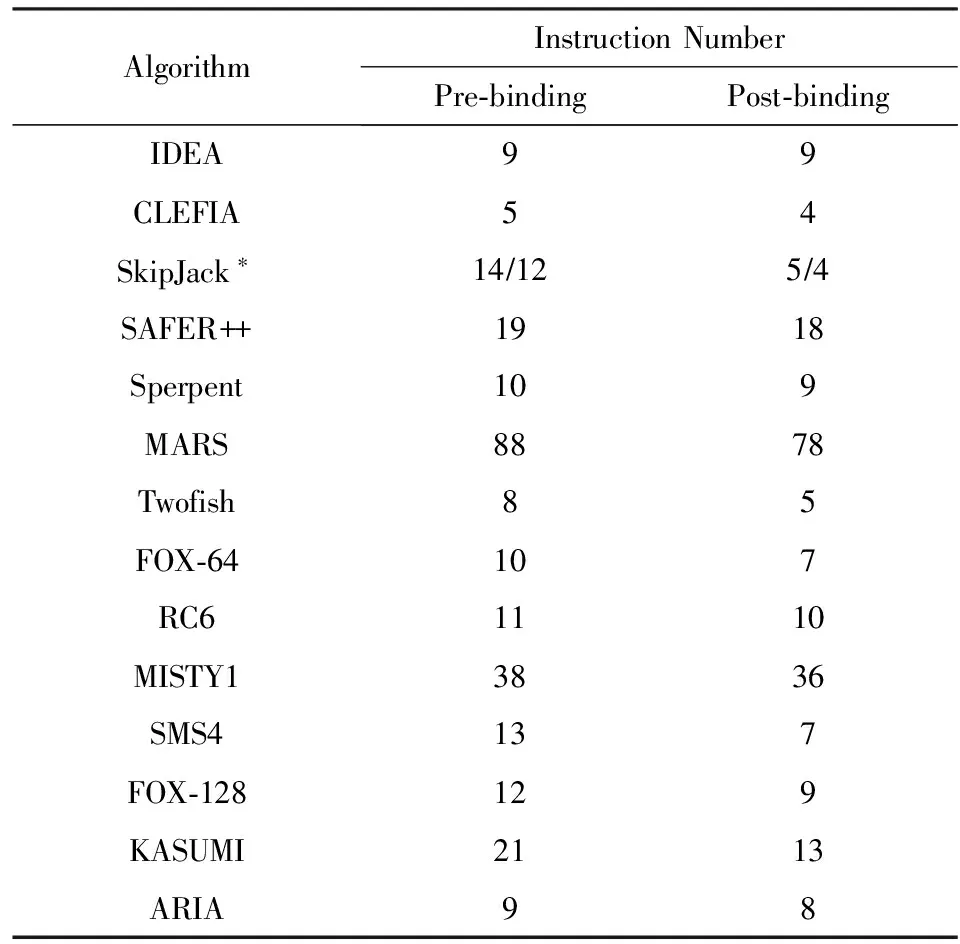
Continued(Table 3)
Note:* has more than one round functions
在绑定异或操作后,95%以上的密码算法轮函数所需要的指令条数均有所减少,平均减少了19.3%.但是也有算法在绑定后,指令条数并未减少,如IDEA.这是因为IDEA算法中的异或操作出现在延时较大的模乘操作之后,为了不影响关键路径,未对模乘操作绑定异或.
3.3 I——算法并行度分析
通过多路并行执行能够提升密码算法实现性能.但是对于密码算法来说,可实现的最大并行度受限于算法本身的并行性.基于3.1节所确定的运算单元,对算法集合中各算法的分组内最大并行度i进行分析,结果如表4所示:

Table 4 Max Parallelism in Block表4 分组内最大并行度
以AES算法为例,16个RCPB可以实现AES分组内最大并行.同时,在ECB模式下,这16个RCPB还可以实现多个分组的纵向流水执行.因为有限域乘法均需要2个周期,成为了流水线的瓶颈,所以把有限域乘法单元设置为2段流水,从而使AES算法在ECB模式下可以流水执行4个分组.
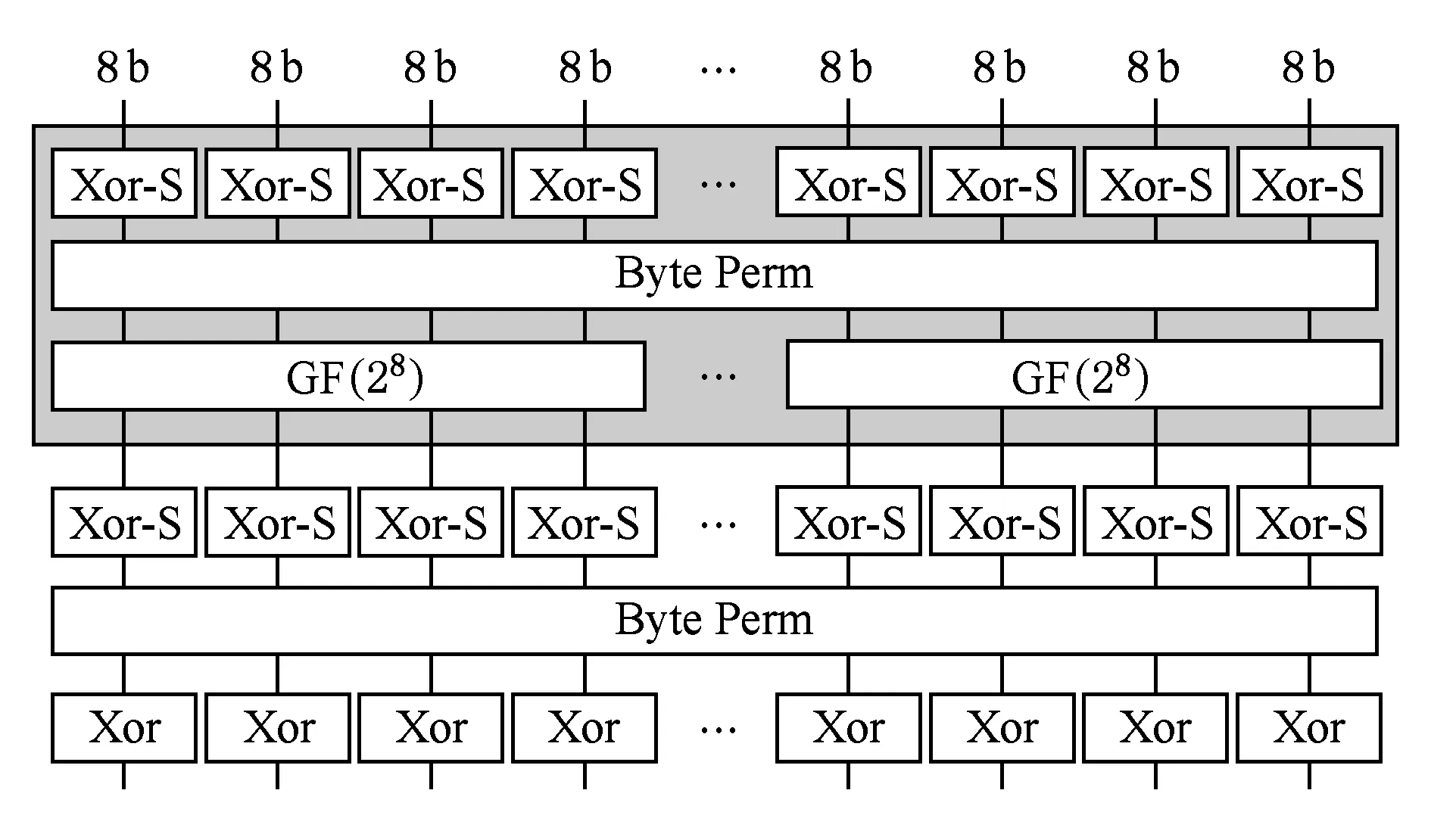
Fig. 1 AES mapping result图1 AES算法映射图
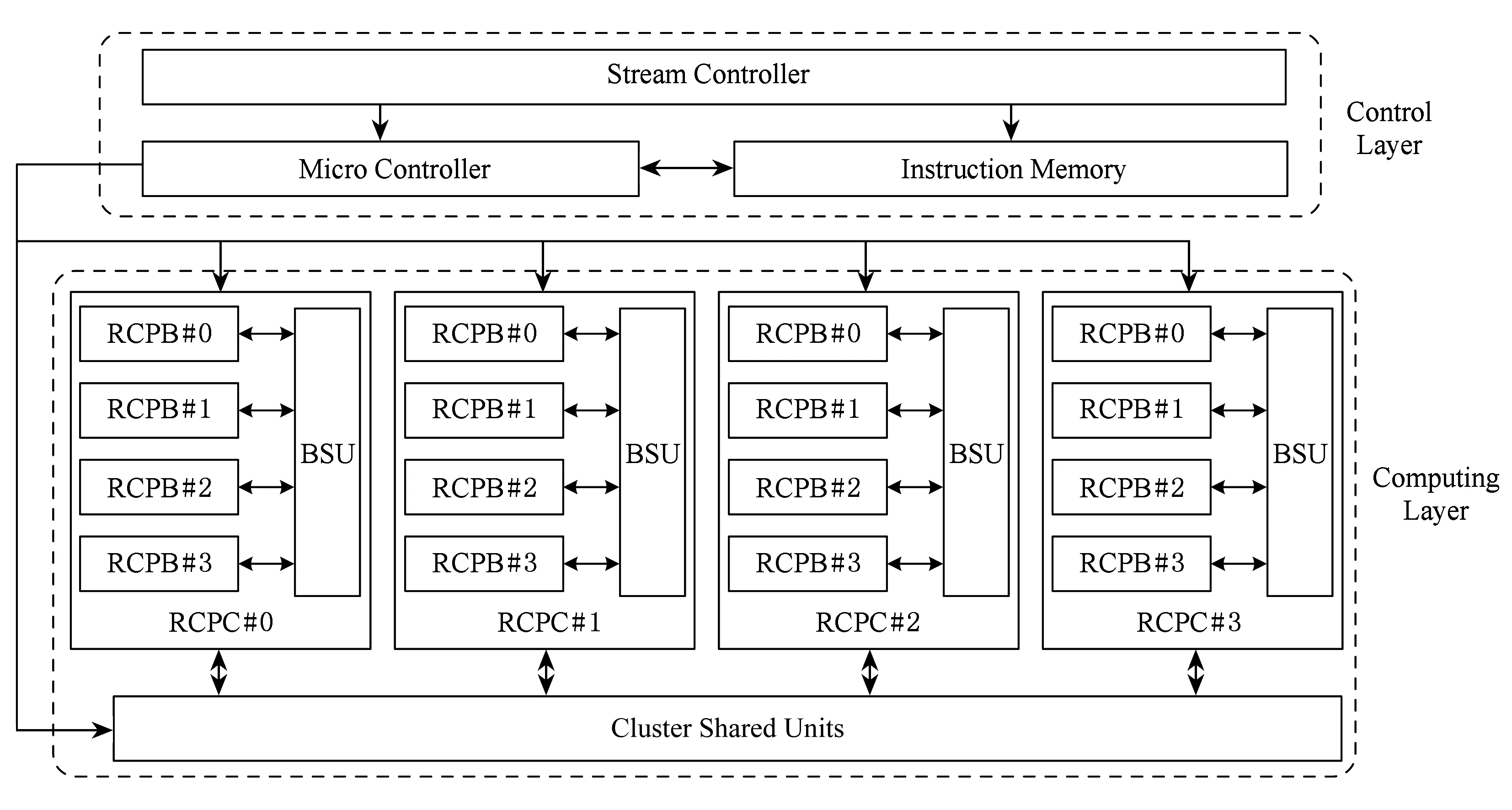
Fig. 3 General architecture of RCSP图3 RCSP结构图
而对于并行度小于16的密码算法,在ECB模式下或是CBC模式下通过交错技术[13],可以在多个RCPB上运行不同的分组,实现多个分组的横向并行.例如SMS4算法,执行1个128 b的分组需要4个RCPB,16个8 b的数据在4个RCPB上的映射结果如图2所示.如果使用全部16个RCPB,可以实现4个分组的并行执行.
多个RCPB既可以通过流水线技术实现多个分组的纵向并行,同时对于并行度小于16的算法,还可以实现多个分组的横向并行.2个维度上的并行性开发可以大大提高密码处理器的吞吐率以及资源利用率.
4 可重构分组密码流处理器原型
为了提高系统的时钟频率和减少指令的平均执行周期,选择使用频率高的功能单元构成系统的运算部件,并根据其位宽分别组成基本运算核心RCPB和多级共享单元BSU及CSU;为了减少算法的指令条数,在不影响关键路径的前提下绑定异或操作;通过对典型算法的并行性分析发现,设置16个RCPB时,可以最大限度地实现密码算法的分组内并行.基于上述分析,以流处理器框架为基础,设计了可重构密码流处理器(reconfigurable cipher stream processor, RCSP),结构如图3所示.
整个RCSP的结构分为控制层和运算层2个部分.控制层由流控制器和微控制器两级控制组成.当需要执行密码算法时,首先由流控制器加载算法指令和数据到RCSP中,指令存储在指令存储器中,指令存储器的容量为512×128 b,数据通过IO接口送入到与每个功能单元直接相连的局部寄存器(local register file, LRF)中.指令执行时由微控制器读取指令和译码,并把指令信息广播到对应的功能单元.同时,微控制器还负责执行循环跳转等控制指令.RCSP采用VLIW指令结构,所以它的控制部分相对简单,从而可以把更多的片上面积用于运算部件.
RCSP的运算层由基本运算核心RCPB,bank间共享单元BSU和簇间共享单元CSU组成.处于不同层次中的功能单元之间的连接方式如图4所示,其中白色表示的是RCPB内部的功能单元,浅灰色表示的是BSU单元,深灰色表示的是CSU单元.
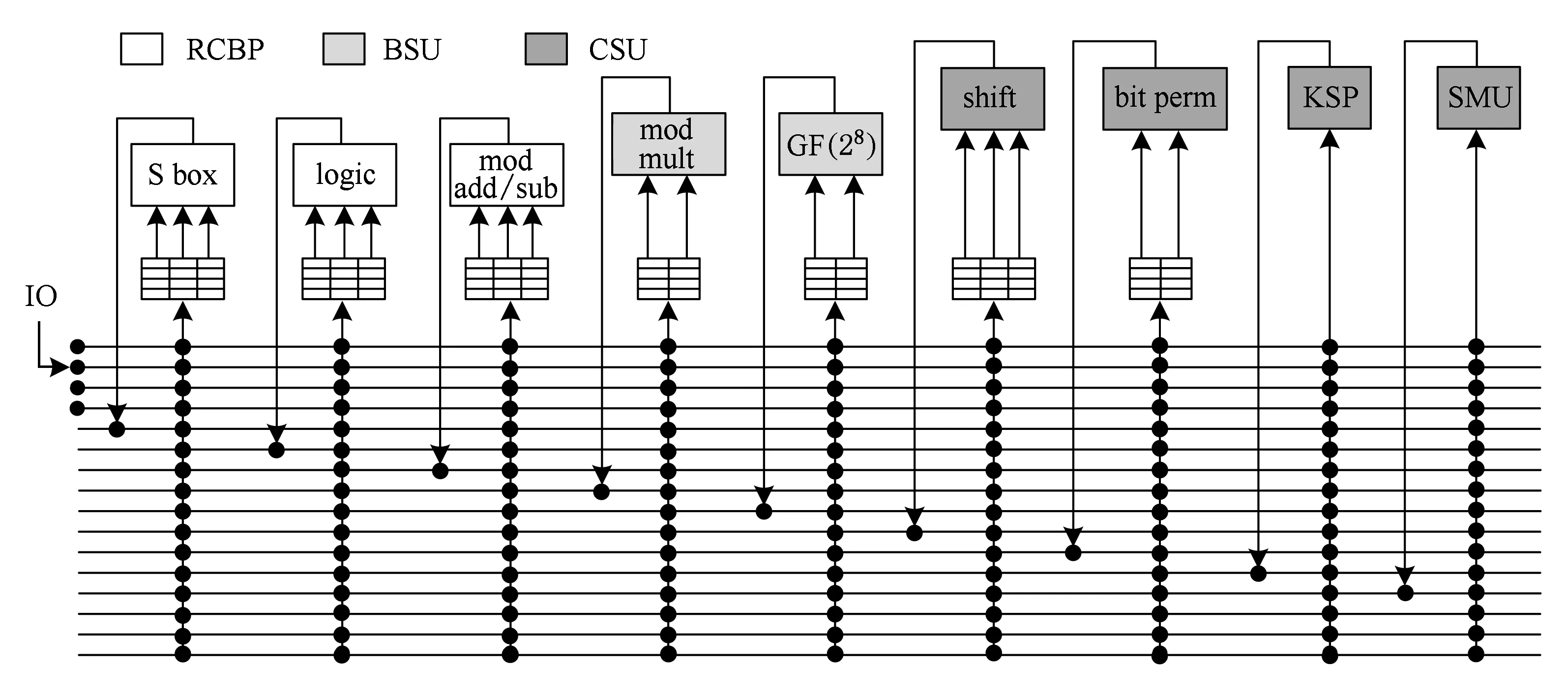
Fig. 4 Architecture of operation layer图4 运算层结构图
为了实现各个功能单元之间的快速数据交换,通过交叉互联开关把各个功能单元连接起来.每个功能单元在一个RCPB中都对应一个8 b位宽的结果输出总线和若干个输入寄存器.输入寄存器中包括了绑定操作时前/后绑定的操作数.
从逻辑结构上看,因为BSU和CSU中的共享单元在每个RCPB内通过交叉互连网络与RCPB内的功能单元连接,相当于共享单元在每个RCPB中均有一个8 b位宽的功能单元,是独立属于每个RCPB的,即每个RCPB中均有7个8 b位宽的功能单元,它们之间的数据交换通过交叉互连网络在单周期内实现.RCPB与共享单元这种逻辑结构上相互独立的设计,可以使密码算法映射变得简单.
因为密码算法有大量的中间运算结果,需要频繁进行中间结果的写回与读取操作,所以中间结果的写回与读取时间对系统的执行速度有较大影响.设置与每个功能单元直接相连的LRF保存中间结果,每次运算单元所需要的操作数都是直接从与它对应的LRF中取出,当操作完成,结果通过交叉互连网络写入下一个要使用该结果的功能单元所对应的LRF中.同时,LRF支持写穿透[9].中间结果保存到寄存器的同时传送给需要该结果的功能单元,避免因为数据写后读相关造成的流水线停顿.因为功能单元都是从自己对应的LRF中取操作数,相比于集中式的寄存器,这种分布式的结构可以有效减少操作延迟和寄存器面积.
密钥寄存器(key scratch pad, KSP)设置为32×128 b,在每个bank中对应的位宽是8 b,即每个bank一次可以向KSP中读/写一个8 b的数据.
每个RCPB中都有一个共享存储单元(shared memory unit, SMU),各个bank的SMU通过字节置换单元连接,实现单周期内多个RCPB之间的数据交换.
5 实验及性能对比
使用Verilog语言对RCSP进行描述后,通过65 nm CMOS工艺标准单元库及相应负载模型对设计的处理器原型进行逻辑综合,综合结果如表5所示.其中Slack为正值表示实际延迟时间满足约束条件,且其值越大表示实际时钟频率可以综合得更高;而Slack为负值表示实际延迟时间超过了约束条件,DC综合工具已经无法再继续优化.根据综合结果,RCSP时钟频率最高可达826 MHz,为保证工作稳定性,将RCSP工作频率确定为800 MHz.后文讨论均为RCSP在800 MHz工作频率下的运算性能.
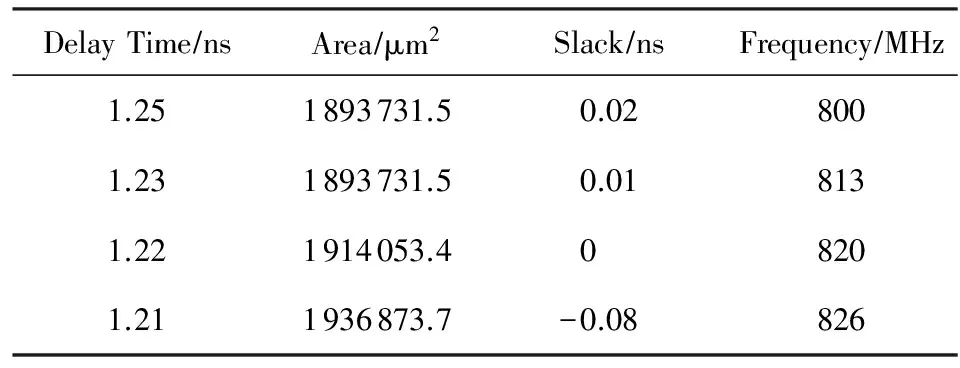
Table 5 Result Based on ASIC Implementation表5 基于ASIC实现的结果
对选取的算法集合进行适配,结果表明RCSP可以高效处理SP结构、Feistel结构、LM结构的分组密码算法.由于目前密码处理器文献中,一般仅列出AES,DES,IDEA的实现结果,考虑到MISTY结构算法具有一定代表性,增加了MISTY结构的代表算法KUSAMI.RCSP与其他密码处理器性能对比情况如表6所示.其中,Cryptonite[14]、CCProc[15]、RCBCP[3]、文献[5]和MCCP[16]为可重构密码专用指令处理器;Celator[17],RCPA[6],S-RCCPA[7],Cryptorapto[8],RCPC[18]为阵列结构可重构密码处理器.
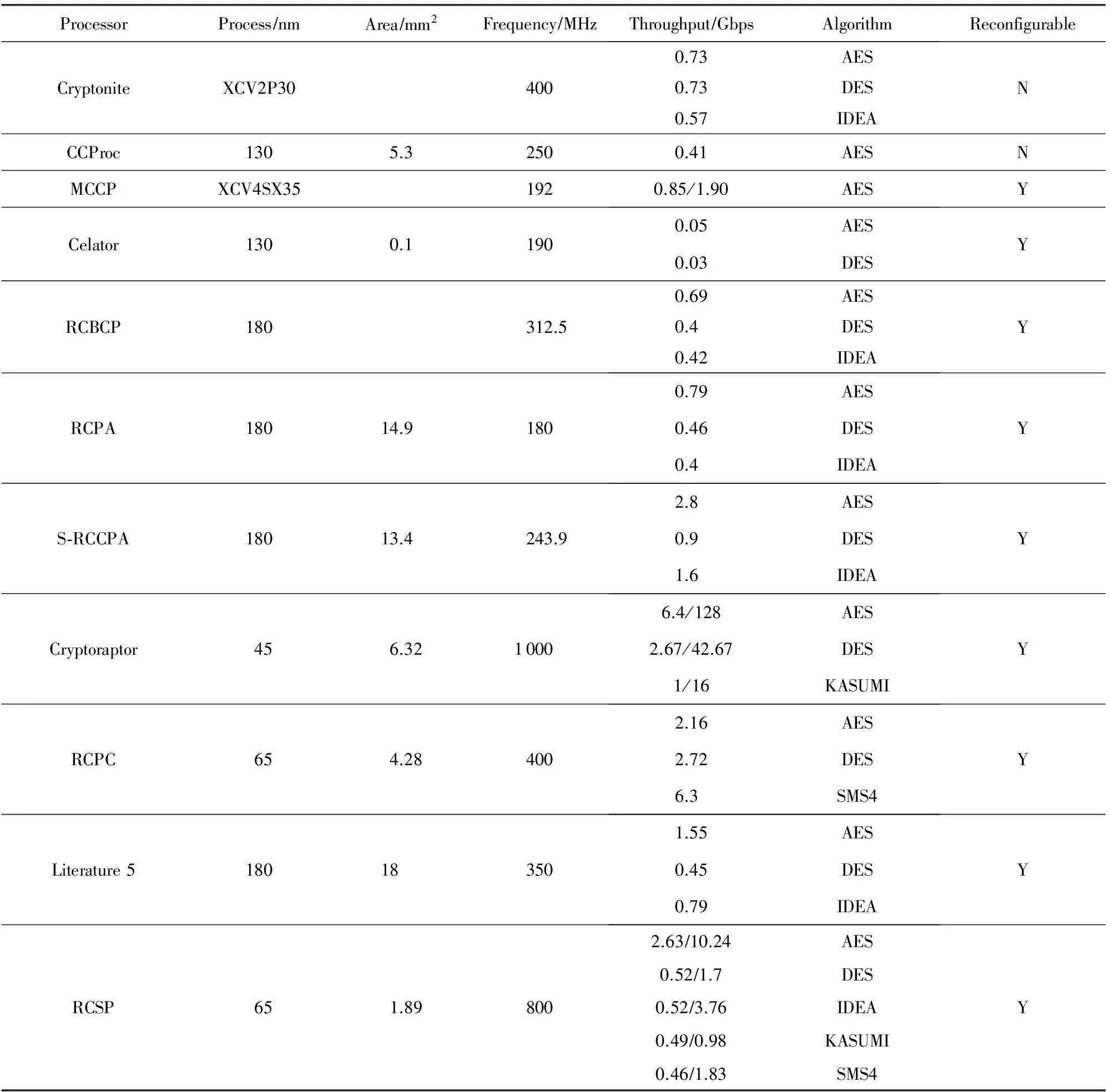
Table 6 Performance Comparison with Other Cryptographic Processors表6 不同密码处理器性能对比
根据综合结果,RCSP以较小的面积代价获得了较高的性能.RCSP对AES的实现性能在CBC和ECB模式下分别达到了2.63 Gbps和10.24 Gbps.而对于DES和IDEA,在CBC模式下吞吐率均为0.52 Gbps,在ECB模式下,通过纵向流水和横向并行,吞吐率分别达到了1.7 Gbps和3.76 Gbps.通过性能对比发现,RCSP对密码算法的实现性能明显高于其他专用指令处理器,大大提升了可重构密码处理器的实现性能.
与阵列结构的可重构密码处理器比较,RCSP实现性能仍高于Celator,RCPA,S-RCCPA处理架构.由此可见,通过设置8 b的基本处理单元和多级共享单元、绑定前/后异或以及多维度开发并行化等性能提升策略,可重构分组密码流处理器RCSP获得了与当前阵列结构可重构密码处理器相当的密码处理性能.
考虑到资源消耗及单元使用频率,RCSP中未设计大位宽查找表单元,对于9-9的S盒操作需使用多条指令组合实现.由于KASUMI结构使用了大量的9-9的S盒,RCSP对KASUMI算法实现性能较低.Cryptoraptor设计了10-32的查找表,对AES,DES,KASUMI的实现性能均高于RCSP,但Cryptoraptor结构未设计乘法单元,对使用范围较广的IDEA算法支持效果差,Cryptoraptor作者在性能对比中回避了IDEA算法,因此无法作出比较,同时Cryptoraptor资源消耗大约是RCSP的5倍(考虑到工艺差距),且Cryptoraptor是阵列结构,应用开发难度较大.
6 结束语
设计高效、灵活的可重构密码处理器是信息安全领域的热点研究课题.密码专用指令处理器具有配置信息少、灵活便捷的优点,但处理性能不高,成为限制其进一步发展的主要因素.
针对上述问题,根据分组密码算法特征,以提高分组密码处理器性能为目标,构建了分组密码处理器性能模型,并基于该模型研究密码处理器性能提升技术.提出了通过提升系统工作频率和减少指令平均周期的多级资源共享技术、提升单周期密码操作数目的绑定前/后异或技术、开发分组密码并行特征的并行处理技术.利用流处理器可以集成大量功能单元、控制结构简单的特点,在性能提升技术的指导下,设计并实现了面向分组密码的可重构密码流处理器原型RCSP.在65 nm CMOS工艺下完成了RCSP的逻辑综合,通过典型分组密码算法的映射结果表明,RCSP的密码实现性能均高于其他专用指令处理器,而且高于Celator,RCPA,S-RCCPA等阵列结构可重构密码处理结构,具有很好的应用场景.
由于缺少大位宽S盒运算单元,RCSP对MSITY,KUSAMI等算法的实现性能较低,为提升密码算法实现性能,下一步可考虑集成9-9的查找表.
[1]Compton K, Hauck S. Reconfigurable computing: A survey of systems and software[J]. ACM Computing Surveys, 2002, 34(2): 171-210
[2] Chen Shuming, Chen Shenggang, Yin Yaming. Revisiting Amdahl’s law in the hierarchical chip multicore processors[J]. Journal of Computer Research and Development, 2012, 49(1): 83-92 (in Chinese)(陈书明, 陈胜刚, 尹亚明. Amdahl定律在层次化片上多核处理器中的扩展[J]. 计算机研究与发展, 2012, 49(1): 83-92)
[3] Meng Tao, Dai Zibin. Reconfigurable clustered architecture of block cipher processor[J]. Journal of Electronics & Information Technology, 2009, 31(2): 453-456 (in Chinese)(孟涛, 戴紫彬. 分组密码处理器的可重构分簇式架构[J]. 电子与信息学报, 2009, 31(2): 453-456)
[4] Gaspar L, Fisher V, Bernard F, et al. HCrypt: A novel concept of crypto-processor with secured key management[C] //Proc of Int Conf on Reconfigurable Computing and FPGAs(RECONFIG 2010). Piscataway, NJ: IEEE, 2010: 280-285
[5] Li Wei, Zeng Xiaoyang, Nan Longmei, et al. A reconfigurable block cryptographic processor based on VLIW architecture[J]. China Communications, 2016, 13(1): 91-99
[6] Yang Xiaohui, Dai Zibin, Zhang Yongfu. Research and design of reconfigurable computing targeted at block cipher processing[J]. Journal of Computer Research and Development, 2009, 46(6): 962-967 (in Chinese)(杨晓辉, 戴紫彬, 张永福. 可重构分组密码处理结构模型研究与设计[J]. 计算机研究与发展, 2009, 46(6): 962-967)
[7] Chen Tao, Luo Xingguo, Li Xiaonan, et al. An architecture of stream based reconfigurable clustered block cipher processing array[J]. Journal of Electronics & Information Technology, 2014, 36(12): 3027-3034 (in Chinese) (陈韬, 罗兴国, 李校南, 等. 一种基于流处理框架的可重构分簇式分组密码处理结构模型[J]. 电子与信息学报, 2014, 36(12): 3027-3034)
[8] Sayilar G, Chiou D. Cryptoraptor: High throughput reconfigurable cryptographic processor[C] //Proc of IEEE/ACM Int Conf on Computer-Aided Design (ICCAD 2014). Piscataway, NJ: IEEE, 2014: 155-161
[9] Rixner M. Stream Processor Architecture[M]. Amsterdam, Netherlands: Kluwer Academic Publishers, 2001
[10] Zhang Chunyuan, Wen Mei, Wu Nan, et al. Research and Design of Stream Processor[M]. Beijing: Publishing House of Electronics Industry, 2009 (in Chinese)(张春元, 文梅, 伍楠, 等. 流处理器研究与设计[M]. 北京: 电子工业出版社, 2009)
[11] Wang Yuliang. Research and design on coarse-grain reconfigurable architecture for cryptographic algorithms[D]. Zhengzhou: PLA Information Engineering University (in Chinese)(王玉良. 面向密码算法的粗粒度可重构结构研究与设计[D]. 郑州: 解放军信息工程大学, 2010)
[12] Jarvinen K, Dimitrov V, Azarderakhsh R. A generalization of addition chains and fast inversions in binary fields[J]. IEEE Trans on Computers, 2015, 64(9): 2421-2432
[13] Desai A, Ankalgi K, Yamanur H, et al. Parallelization of AES algorithm for disk encryption using CBC and ICBC modes[C] //Proc of the 4th Int Conf on Computer Communication and Networking Technology. Piscataway, NJ: IEEE, 2013: 1-7
[14] Buchty R. Cryptonite —a programmable crypto processor architecture for high-bandwidth applications[D]. München, Bavaria, Germany: Technische University München, 2002
[15] Theodoropoulos D, Papaefstathiou I, Pnevmatikatos D N. CCproc: An efficient cryptographic coprocessor[C] //Proc of the 16th IFIP/IEEE Int Conf on Very Large Scale Integration (VLSI’08). Berlin: Springer, 2008: 160-163
[16] Bossuet L, Grand M, Gaspar L, et al. Architectures of flexible symmetric key crypto engines-a survey: From hardware coprocessor to multi-crypto-processor system on chip[J]. ACM Computing Surveys, 2013, 45(4): 115-123
[17] Fronte D, Perez A, Payrat E. Celator: A multi-algorithm cryptographic co-processor[C] //Proc of Int Conf on Reconfigurable Computing and FPGAs (RECONFIG’08). Piscataway, NJ: IEEE, 2008: 438-443
[18] Wang Bo, Liu Leibo. A flexible and energy-efficient reconfigurable architecture for symmetric chipper processing [C] //Proc of IEEE Int Symp on Circuits and Systems (ISCAS 2015). Piscataway, NJ: IEEE, 2015: 1182-1185
DesignofBlockCipherProcessorBasedonStreamArchitecture
Li Gongli1,2, Dai Zibin1, Xu Jinhui1, Wang Shoucheng1, Zhu Yufei1, and Feng Xiao1
1(PLAInformationEngineeringUniversity,Zhengzhou450001)2(CollegeofComputer&InformationEngineering,HenanNormalUniversity,Xinxiang,Henan453002)
To improve the performance of cipher processor, the performance model of cipher processor is proposed. And based on this model, three ways for enhancing cipher processor’s performance are presented, which are sharing multi-level resources, binding operations of pre-xor or post-xor and maximizing parallelism of block cipher algorithms. According to these improvement methods, the type and amount of cryptographic function units are determined. However, the function units are not only numerous but also different in operation data width and latency, so how to organize these function units efficiently becomes a key problem. The stream processor architecture can integrate a large number of function units to obtain high performance. Then, we design and implement a reconfigurable block cipher processor prototype which is based on stream processor architecture, and in order to organize the numerous function units effectively, the function units are divided into basic units, inter-bank-shared units and inter-cluster-shared units respectively according to their processing width. The prototype is synthesized in 65nm CMOS process and several typical block cipher algorithms are mapped on it. The evaluation results show that the processor prototype is area-efficient and its performance is not only beyond that of international application specific instruction cipher processors, but also higher than that of the domestic reconfigurable array processors.
block cipher; stream processor; performance model; reconfigurable; cipher processor
2016-08-31;
2016-12-09
国家自然科学基金项目(61404175)
This work was supported by the National Natural Science Foundation of China (61404175).
TP309.7

LiGongli, born in 1981. PhD candidate of the PLA Information Engineering University. Her main research interests include crypto-graphic arithmetic, computer architecture and high-performance cryptographic processor.

DaiZibin, born in 1966. Professor and PhD supervisor in the PLA Information Engineering University. His main research interests include cryptographic arithmetic, VLSI design of crypto-ICs, and SoC platform for security applications.

XuJinhui, born in 1978. PhD. His main research interests include reconfigurable computing, information security and SoC system design.

WangShoucheng, born in 1992. Master. His main research interests include reconfigurable computing and SoC system design.

ZhuYufei, born in 1990. Master. His main research interests include VLSI designs for security applications.

FengXiao, born in 1987. PhD. Her main research interests include high performance multi-core processor, design of SoC platform for security applications.
猜你喜欢
保健医苑(2022年4期)2022-05-05
当代陕西(2022年4期)2022-04-19
摄影世界(2022年1期)2022-01-21
数码世界(2020年12期)2021-01-20
中国生殖健康(2020年7期)2020-12-10
学校教育研究(2020年11期)2020-06-08
学与玩(2018年5期)2019-01-21
商周刊(2017年6期)2017-08-22
语文世界(小学版)(2016年9期)2016-09-14
微型小说选刊(2015年5期)2015-06-05
