
基于簇和阈值区间的高效关联规则隐藏算法
2017-12-16 05:18牛新征王崇屹叶志佳
计算机研究与发展 2017年12期
牛新征 王崇屹 叶志佳 佘 堃
1(电子科技大学计算机科学与工程学院 成都 611731) 2(电子科技大学信息与软件工程学院 成都 610054)
基于簇和阈值区间的高效关联规则隐藏算法
牛新征1王崇屹1叶志佳1佘 堃2
1(电子科技大学计算机科学与工程学院 成都 611731)2(电子科技大学信息与软件工程学院 成都 610054)
(xinzhengniu@uestc.edu.cn)
关联规则隐藏是隐私保护数据挖掘(privacy-preserving data mining, PPDM)的一种重要方法.针对当前的关联规则隐藏算法直接操作事务数据、I/O开销较大的缺陷,提出一种基于FP-tree快速关联规则隐藏的算法FP-DSRRC.算法首先对FP-tree的结构进行改进,增设事务编号索引并建立双向遍历结构,进而利用改进的FP-tree对事务信息进行快速处理,避免了遍历原始数据集产生的大量I/O时间;然后通过建立和维护事务索引表实现对敏感项的快速查找,并基于分簇策略对关联规则处理,以簇为单位进行敏感规则消除,同时采用规则支持度和置信度阈值区间的思想,减少了关联规则隐藏处理对原始数据集的影响;最后通过实验测试证明:相较于传统关联规则隐藏算法,FP-DSRRC算法在保证生成的数据集质量的同时,减少了50%~70%的算法执行时间,并在大规模真实数据集上有较好的可用性.
隐私保护;关联规则隐藏;频繁模式树; 敏感规则; 数据清洗
随着关联规则技术的逐渐成熟以及大数据云计算的不断发展,通过关联规则能挖掘出的信息越来越多,其中可能包含了用户的敏感数据和隐私信息[1].因此,Agrawal等人[2]在2000年提出的隐私保护数据挖掘(privacy-preserving data mining, PPDM)成为数据挖掘领域的研究重点,而关联规则隐藏作为解决数据挖掘中隐私问题的一项关键技术也引起了国内外学者的重视.
关联规则挖掘最初由Agrawal[3]在1993年提出,其目的是为了挖掘事务数据库中各项集存在的价值关联,为相关决策提供依据.对于一些包含敏感关联规则的数据,在发布数据前修改原始数据集,从而达到隐藏敏感规则的目的,这个过程就是关联规则隐藏.
1 相关工作
当前关联规则隐藏技术大致可分为6种[4]:基于启发式的方法(heuristic approach)、基于边界的方法(border approach)、基于重构的方法(reconstruction approach)、基于加密的方法(cryptographic approach)、精确方法(exact approach)和基于混合的方法(hybrid techniques approach).
启发式方法主要采用数据失真技术和数据阻塞技术,通过向原始事务数据库中添加噪声数据或将原敏感项集的某些属性删除,以达到降低敏感规则支持度或置信度的目的.在基于启发式的关联规则隐藏算法中,文献[5]提出基于频繁项集相交点阵(intersection lattice)的关联规则隐藏算法(heuristic for confidence and support reduction based on intersection lattice, HCSRIL),算法首先确定对原始数据库影响最小的敏感规则,并求解最小的待修改事务数,在消除敏感规则的同时保留频繁项集,通过以上步骤尽量降低修改敏感规则对原始数据库产生的影响;文献[6]提出一种基于数据失真技术的关联规则隐藏算法(cuckoo optimization algorithm for the sensitive association rules hiding, COA4ARH),该算法分别构造了3个适应度函数用于优化隐藏方案的选择,并利用迁移函数避免陷入局部最优.
在利用减少敏感规则右项支持度的启发式算法中,文献[7]提出了DSRRC(decrease support of R.H.S item of rule clusters)算法,算法首次利用分簇和划分敏感度的思想进行关联规则隐藏,尽可能地减少算法执行对原事务数据集产生的影响,但是DSRRC算法需要对数据集进行多次排序且不能消除有多个右项的关联规则,为了解决这个问题,文献[8]提出了2个新算法:ADSRRC(advanced DSRRC)算法和RRLR(remove and reinsert L.H.S. of rule)算法,克服了这些问题.ADSRRC也是基于相同右项对敏感规则分簇,通过计算事务数据的敏感度并将其降序排序,消除对算法执行结果的影响,而RRLR算法能处理具有多个右项的规则的能力;文献[9]提出的MDSRRC(modified DSRRC)算法通过每次删除敏感度最高的敏感项保证修改后的事务数据集的质量,启发式算法通常需要向原始数据库中添加噪声或删除某些属性,当敏感规则较多时对原始数据改动较大,同时在基于数据阻塞的方法中,由于项集的某些属性被删除,后续可能无法计算其支持度和置信度.
基于边界的方法以贪心方式选择对边界影响最小的数据清洗策略,文献[10]提出一种基于阻塞的关联规则隐藏算法(border rule based blocking algorithm, BRBA).该算法基于边界规则筛选合适的事务数据进行清洗,通过安全边界策略(safety margin)降低所有敏感规则的支持度或置信度,最小化敏感规则隐藏对其他非敏感规则的影响.
基于精确方法的思想是把数据清洗当成一种原子操作,这类算法可以使消除敏感规则后的数据库没有任何影响,但是需要多次选择、比较,相比启发式算法时间开销巨大.文献[11]提出的关联规则隐藏算法无需修改频繁项集支持度,而是提出一个代表规则(representative rule, RR)的概念.通过运用代表规则,算法无需访问主数据库就能推断出敏感规则,其基本思路是改变数据项所在的位置,而不是将其从事务数据库中删除.这种策略的优点在于算法不会对频繁项集的支持度和数据库规模产生影响,然而该算法无法保证敏感规则的置信度小于阈值.文献[12]将敏感规则消除问题抽象为多目标优化问题,并采用遗传进化理论进行优化求解.该算法在快速隐藏敏感规则的同时,对原事务数据库的修改幅度较小,然而该算法会对非敏感规则产生较大的丢失率,并且查找待删除项的过程复杂度较高.
基于重构的方法首先执行数据失真处理,然后重构数据分布.文献[13]提出一种基于重构的算法,首先通过频繁项集挖掘算法找到所有频繁项集及其对应的支持度,再将敏感规则从频繁项集中删除到支持度之下,然后利用这些不包含敏感规则的频繁项集去构建一棵FP-tree[14],这样关联规则隐藏的问题就转化成了反向频繁项集挖掘问题(inverse frequent set mining, IFM)[15],最后通过反向频繁项集挖掘算法生成不包含敏感规则的数据库.
基于数据加密的方法通过对敏感数据进行加密编码,文献[16]提出结合RSA公钥加密和伪随机数生成器技术,对隐私数据进行加密保护.但是对于规模较大的数据集,该算法计算过程较复杂,实用性较差.
基于混合的方法采用多种技术的融合进数据保护.文献[17]结合2种启发式算法,分别从降低敏感规则的支持度和置信度入手,兼顾2种算法的优势.但该算法仅仅是2种算法的简单叠加,未能针对不同数据特点自适应选择处理算法,并且该算法同样具有启发式算法对原始数据影响较大的缺陷.
通过对现有工作的分析可以看出,现有的关联规则隐藏技术主要存在3个问题:
1) 现有的关联规则隐藏技术往往直接对原事务数据集进行操作,当事务数据集规模较大时,对数据的遍历处理会导致严重的I/O开销,时间效率低下.
2) 现有的算法仅仅着眼于最大限度消除敏感规则,但缺乏对非敏感规则的保护,从而导致经过关联规则消除的数据集规则丢失率和数据损失度较高.
3) 通过人为向原事务数据集中增添项集或规则来隐藏敏感规则的方案,将破坏非敏感规则从而导致错误的挖掘结果.总之,当前的关联规则隐藏算法未能在敏感消除和数据质量之间做到很好的权衡.
关联规则隐藏的前提条件是进行频繁项集挖掘,找到所有关联规则,但是现有算法都割裂了关联规则隐藏和频繁项集挖掘之间的联系,多次遍历和修改原始数据集导致了大量的I/O时间.针对传统关联规则隐藏算法效率较低以及对原始数据集影响较大的缺陷,本文提出一种FP-DSRRC(FP-tree DSRRC)算法,利用一棵改进的FP-tree,使得频繁项集挖掘和关联规则隐藏2个过程都在FP-tree上进行操作,并结合基于启发式和基于边界的关联规则隐藏方法,使算法既快速又高效.
本文主要贡献有3个方面:
1) 改进经典的FP-tree结构,添加事务索引表将算法对FP-tree的修改映射到数据集中.同时算法直接在FP-tree上操作避免了遍历原始数据集产生的时间代价,通过FP-tree的头表信息、节点间域信息可以快速确定敏感事务编号,减少了查找开销.
2) 采用启发式方法,通过将敏感规则分簇,使得单次敏感项的删除影响到多个敏感规则,减少了对原数据集的修改.
3) 基于规则支持度和置信度阈值区间的思想,通过将敏感项按影响度大小排序,优先删除对原数据集影响较小的项,保证了数据集质量的同时显著提升算法效率.
2 问题描述
2.1 关联规则挖掘
关联规则挖掘的目的是从事务数据库DB中找出支持度和置信度阈值区间内的强关联规则[18].具体而言,支持度大于最小支持度阈值MST,并且置信度大于最小置信度阈值MCT的规则才被认为是强关联规则.
设I={i1,i2,…,in}是全部项的集合,其中ik(k=1,2,…,n)为不同的项,令事务数据库DB=(T1,T2,…,Tn),则Ti称为1条事务,其是由若干个项组成的项集.
定义1. 支持度.是项集X支持的事务T在事务数据库DB中出现的百分率,即:
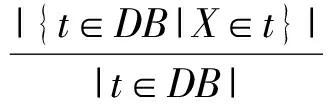
(1)
定义2. 关联规则.是指形如X→Y的蕴含式,X和Y分别是关联规则的先导(left-hand-side, L.H.S.)和后继(right-hand-side, R.H.S.),也叫左项集和右项集,且X∩Y≠∅.关联规则X→Y的支持度为项集X∪Y在DB出现的百分率,即:
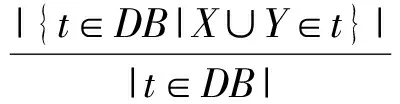
(2)
关联规则X→Y的置信度为项集X∪Y在项集X出现的百分率,即:
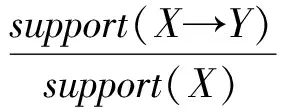
(3)
2.2 关联规则隐藏
定义3. 敏感规则SR.是不符合用户安全策略的关联规则集合,即需要隐藏的关联规则.
定义4. 关联规则隐藏.是指通过关联规则隐藏算法将原始数据库DB转换成1个新的事务数据库DB′,DB′中不包含给定的敏感规则SR.
关联规则隐藏算法通常应该满足3个条件:
1)DB′中不包含任何给定敏感规则SR;
2)DB′中应该包含所有DB原来的非敏感规则;
3)DB′中不包含任何人为产生的新规则.
寻找一种满足关联规则隐藏的全部条件的算法已经被证明是一种NP-hard问题.一般采用HF(hiding failure),MS(missing cost),AP(artificial patterns)这3个指标来衡量一个关联规则隐藏算法和关联规则算法对原数据集的影响.
1)HF表示敏感规则的隐藏失败率:

(4)
HF越低表明关联规则隐藏效果越好.
2)MC表示规则丢失率:

(5)
MC越低表明DB′的质量越高.
3)AP表示人为规则产生率:

(6)
AP越低表明DB′中人为产生的规则越少.
3 FP-DSRRC算法
FP-DSRRC算法的流程图如图1所示.算法首先将事务数据库DB的信息压缩到一棵改进的FP-tree上,并通过FP-Growth[14]算法挖掘出所有强关联规则.将强关联的敏感规则按敏感项分簇,以簇为单位消除所有敏感规则,当所有簇都消除完毕后,将FP-tree还原成一个不包含敏感规则的数据库DB′.
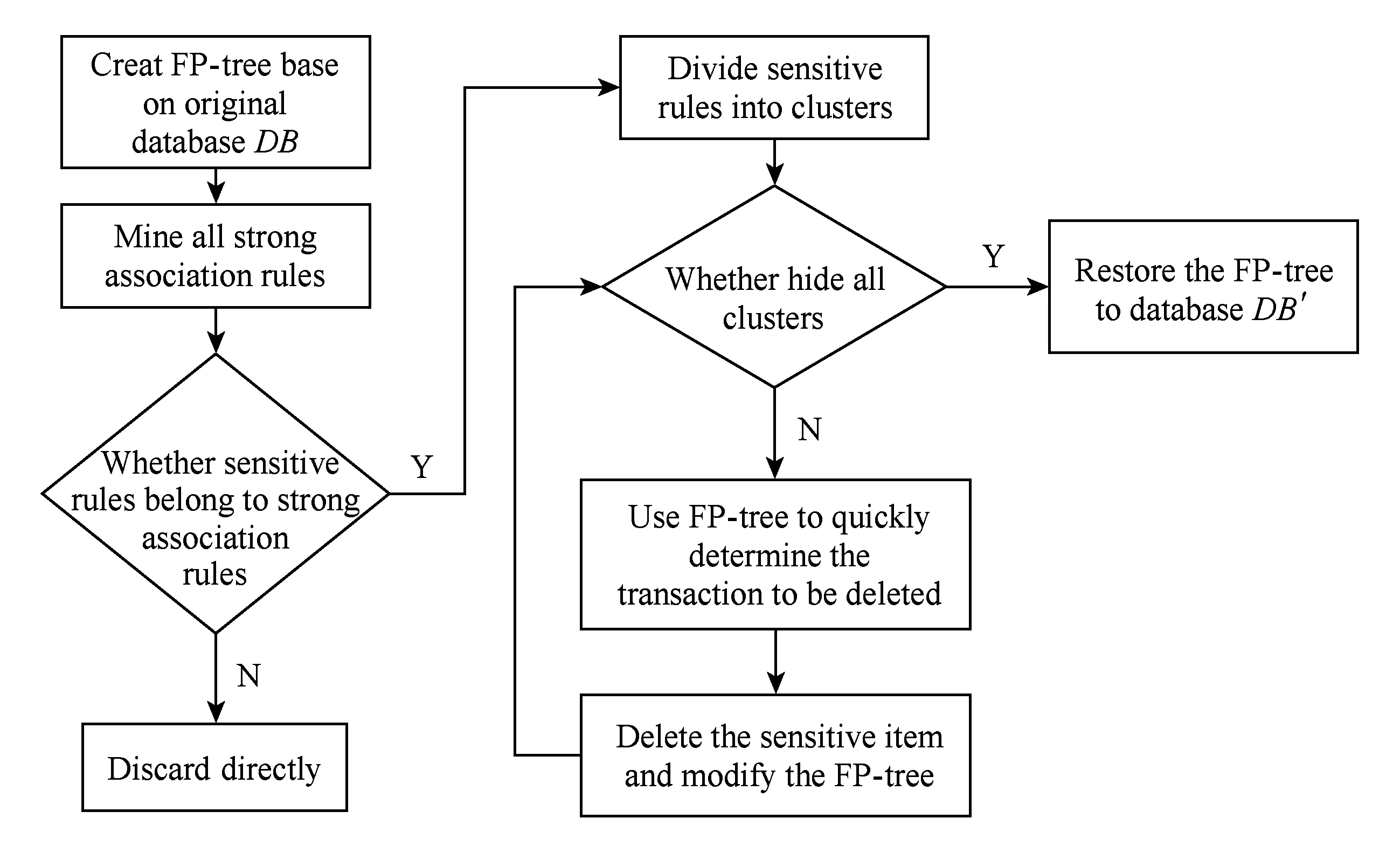
Fig. 1 FP-DSRRC algorithm process图1 FP-DSRRC算法流程
3.1 改进的FP-tree及其性质
相对于经典的FP-tree树[14],本文的FP-tree树添加了1个事务索引表用于标识每一条事务的编号,用于关联规则隐藏过程中事务的索引和新数据库的重构.这样通过FP-tree每个节点到根节点有唯一路径.并且相对于经典的FP-tree是从节点到根单向遍历的,本文的FP-tree建树时保留了节点的Child域,使得该FP-tree是双向可遍历的.改进的FP-tree具体构成如下:
1) 由1个树根Root及其频繁项子树、1个频繁项头表和1个事务索引表组成;
2) 频繁项子树的每一个项节点用Order,Count,Child,Parent,Sibling,Link六个域组成;
3) 频繁项头表由Count域和Link域构成;
4) 事务索引表中每个表项由Index域和Length域构成.
改进的FP-tree如图2所示,构成的事务数据为ABC,A,B三条数据.
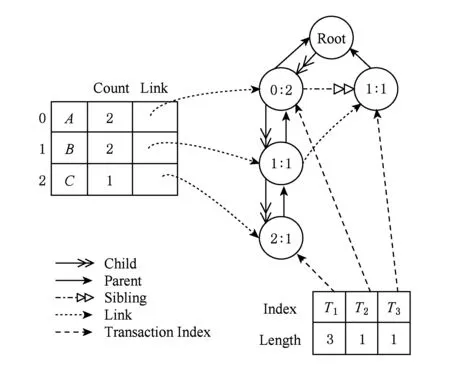
Fig. 2 Improved FP-tree图2 改进的FP-tree
构建FP-tree先从原始数据集DB中读取所有事务,按照频繁项的支持度递减排序并编号,生成1个项序转换表;然后再次读取DB,逐一将事务按照项序转换表排序后插入FP-tree中,并更新事务索引表.通过FP-Growth[14]算法可以挖掘出所有频繁项集并生成所有强关联规则,建树算法和挖掘频繁项集算法可以参考文献[19],本文的建树方式相对于文献[19]保留了Child域和Sibling域,并添加了1个事务索引表.
为了直观展示建树的过程,给出1组精简的数据集TestDB,设定MST=1/3,MCT=0.6.根据频繁项集进行项序转换,A,B,C,D,E的序号分别为3,0,1,2,4,其中序号表示项的支持度,序号越小,支持度越高.筛选后的事务项集表如表1所示:
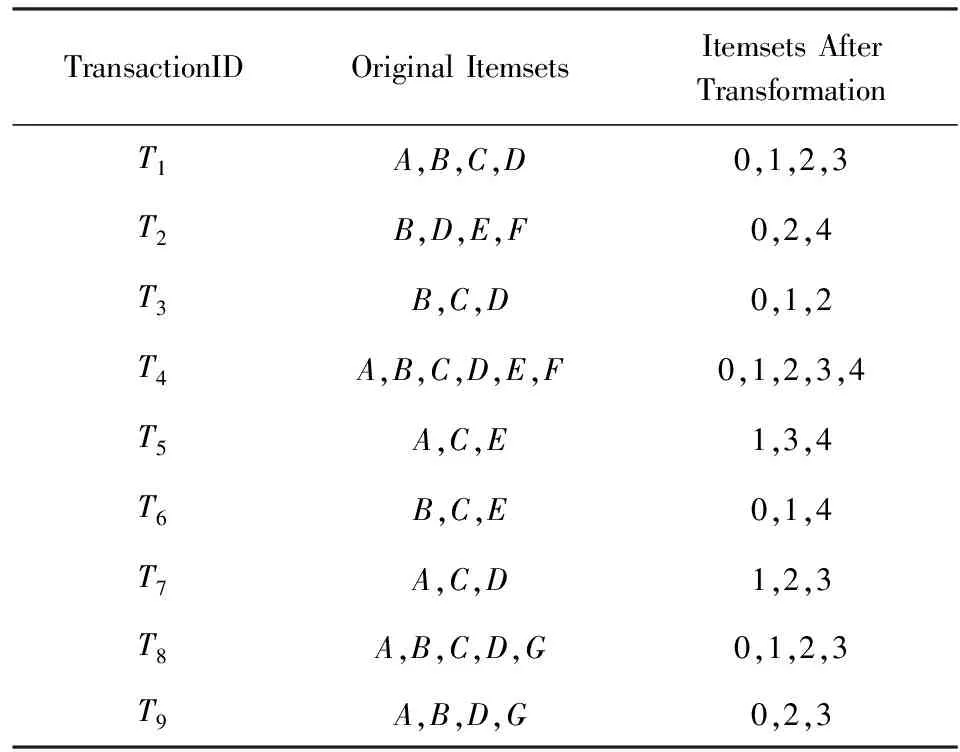
Table 1 Test Data and the Index after Transforming表1 测试数据集TestDB以及项序转换后的索引
建立FP-tree,为了保持图的简洁,未画出Child域和Sibling域,FP-tree建立后如图3所示.
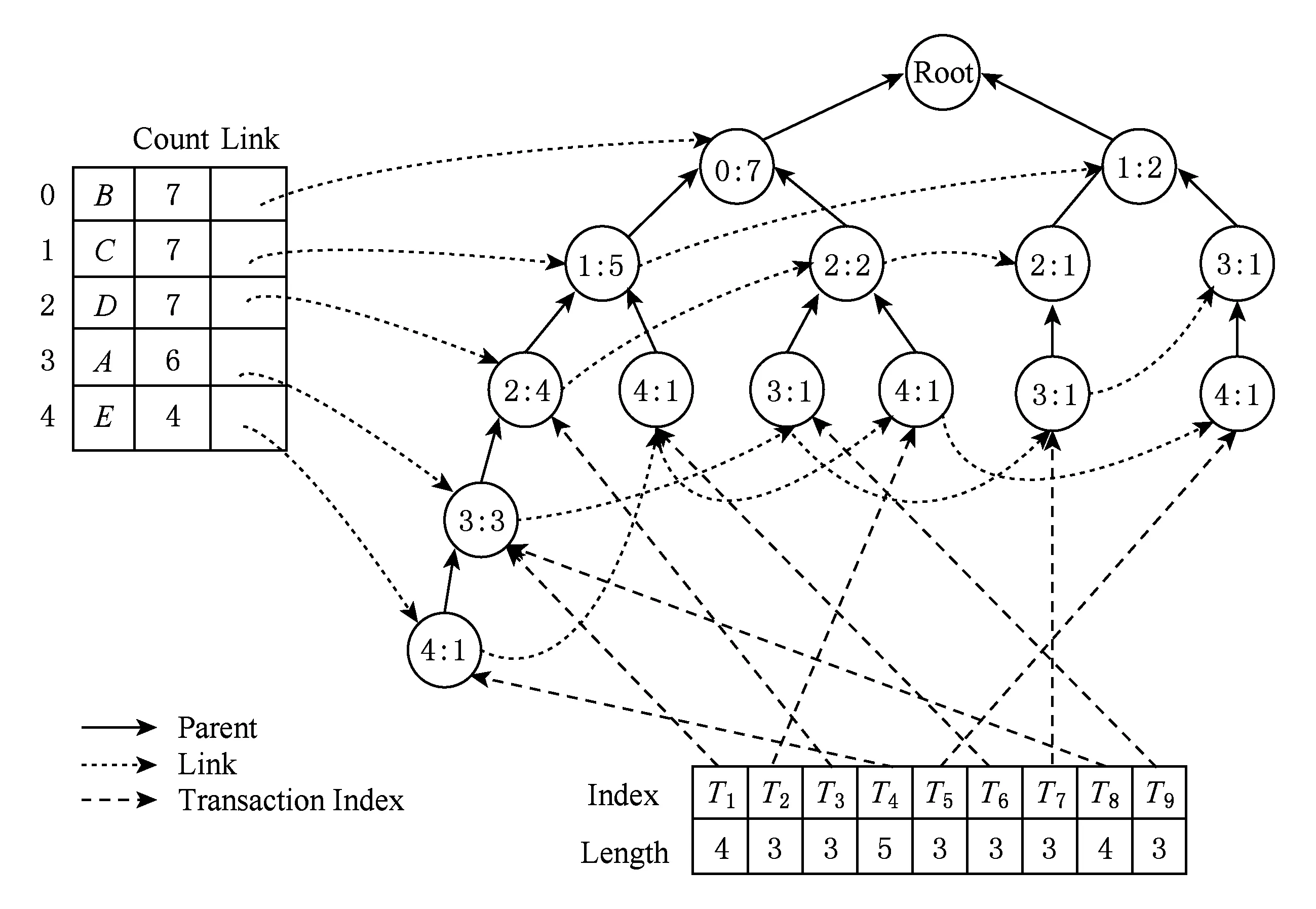
Fig. 3 Construct FP-tree图3 建立FP-tree
综上所述,改进的FP-tree有3个性质:
性质1. 对于形如X→Y的规则,根据项序转换表找出{X,Y}中项序最大的项a,通过对所有的节点a向上遍历可知当前路径是否支持该规则,然后根据事务索引表快速确定哪些事务支持该规则.
性质2. 由于FP-tree保留了Child和Sibling域,可双向遍历,FP-tree可以根据事务索引表取出某条事务,对该事务进行修改后插回FP-tree中,而不影响其他事务.
性质3. 通过遍历事务索引表并统计每个节点到根节点的唯一路径可以快速将FP-tree还原成事务数据库.
采用FP-Growth算法对图3中的FP-tree进行频繁项集挖掘,可以得到表2的结果,表现形式为(频繁项集:支持数).

Table 2 Frequents Itemsets of TestDB表2 TestDB的频繁项集表
3.2 敏感规则消除
为了尽可能减少对原事务数据库的修改,需要尽量减少敏感项的删除,因此本算法的核心思想是通过FP-tree快速定位待删除的事务,并尽量使单次删除可以同时作用于多个敏感规则.算法用敏感度来确定删除的顺序,设敏感规则SR包含敏感项si1,si2,…,sin,多个敏感规则可划分为簇SC={SR1,SR2,…,SRm}.则项敏感度isk定义为sik在敏感规则簇SC中出现的总次数:
(7)
其中,Num(i,k)表示敏感规则SRi中敏感项sik的数量.规则敏感度定义为规则中项敏感度之和:
(8)
类似地,簇敏感度定义为簇中规则的敏感度之和:
(9)
算法根据待隐藏的敏感规则的待删除项分簇.形如X→Y的敏感规则,当有多个右项时,选择具有最大项敏感度ismax的作为待删除项;若敏感度相同,则待删除项选取支持度最大的项.将具有相同待删除项的规则归为同一个簇,然后以簇为单位消除所有的敏感规则,最后重构1个新的事务数据库DB′.
对于表1中的TestDB数据集,假设敏感规则为SR={E→C,A→B,A→BD},则可以得到敏感项的敏感度为A:2,B:2,C:1,D:1,E:1,对于敏感规则A→BD,有2个后项B和D,选择敏感度高的项即项B作为删除项,因此敏感规则集可以分为2个簇,然后计算当前敏感度最高的簇中敏感规则的较小删除数,并通过FP-tree快速确定支持敏感规则的事务索引.
以敏感规则A→B为例,将其支持度降低到MST之下需要删除2个后项,将其置信度降低到MCT之下需要删除1个后项,所以敏感规则A→B的最小删除数为1.根据项序转换表,项A的序号比B大,所以通过频繁项头表的项A出发,经过的每一个节点A同时向根节点查找,如果路径经过节点B说明当前路径支持该敏感规则,即通过该节点A的事务都支持敏感规则A→B,得到事务T1,T4,T8,T9支持A→B.具体过程如图4所示.图4中带灰度的节点为路径支持敏感规则的敏感节点,而带灰度的事务索引为支持该敏感规则的敏感事务索引,敏感规则分簇后如表3所示:

Table 3 Divide Sensitive Rules into Clusters表3 敏感规则分簇
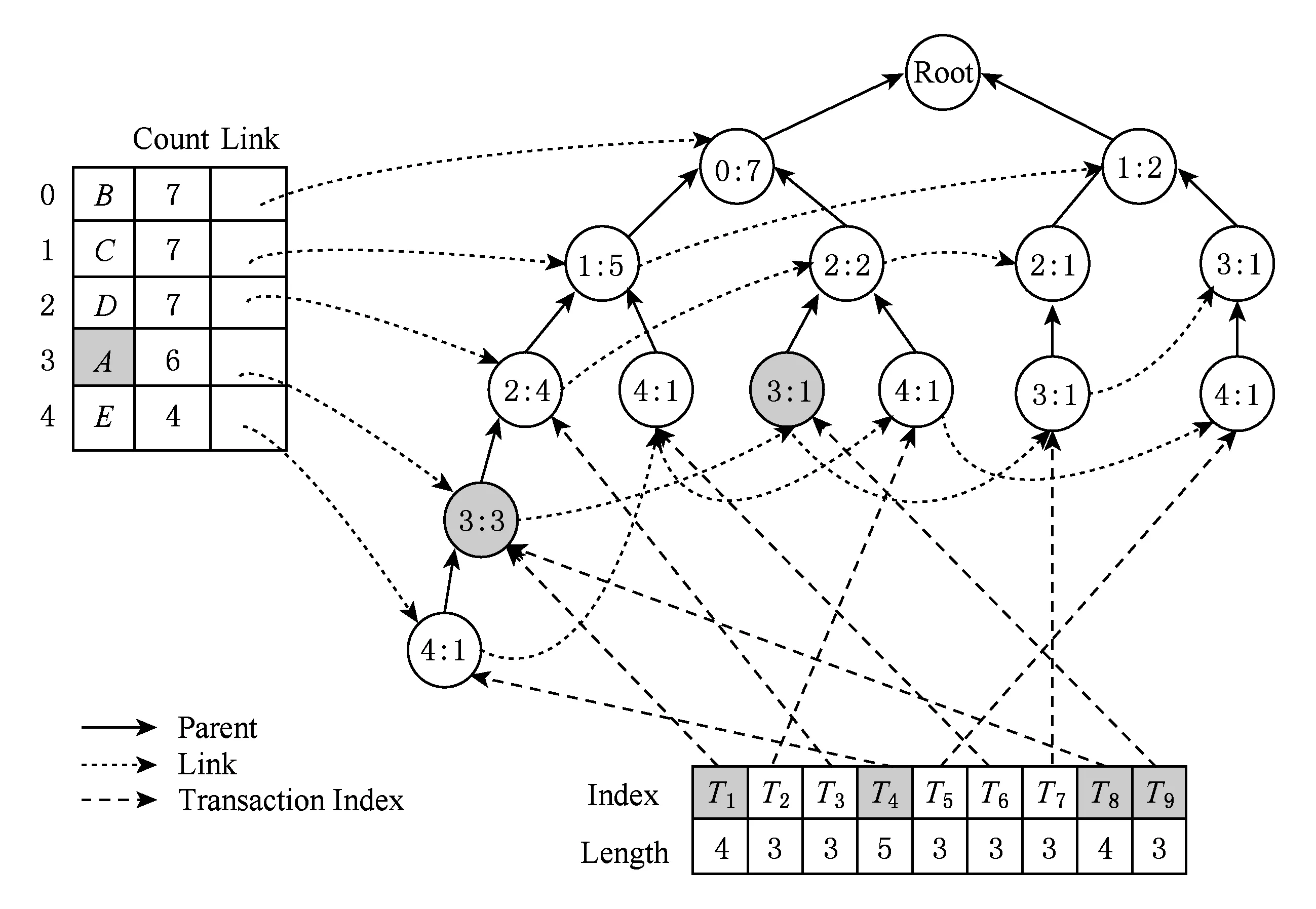
Fig. 4 Find transaction index which supports A→B图4 查找支持A→B的事务索引
对表3中选择敏感度最大的簇即Cluster1进行敏感规则隐藏,对敏感事务的支持规则数进行计数,得到T1:2,T8:2,T9:2,T4:1,选择长度最小的事务T9进行删除,删除节点后的FP-tree如图5所示,此时敏感规则A→B和A→BD的delete count都减1变成0,将A→B和A→BD从Cluster1删除,此时Cluster1所有敏感规则已经隐藏完毕,重新挖掘FP-tree中的频繁项,得到新的频繁项集后则处理其他的簇.
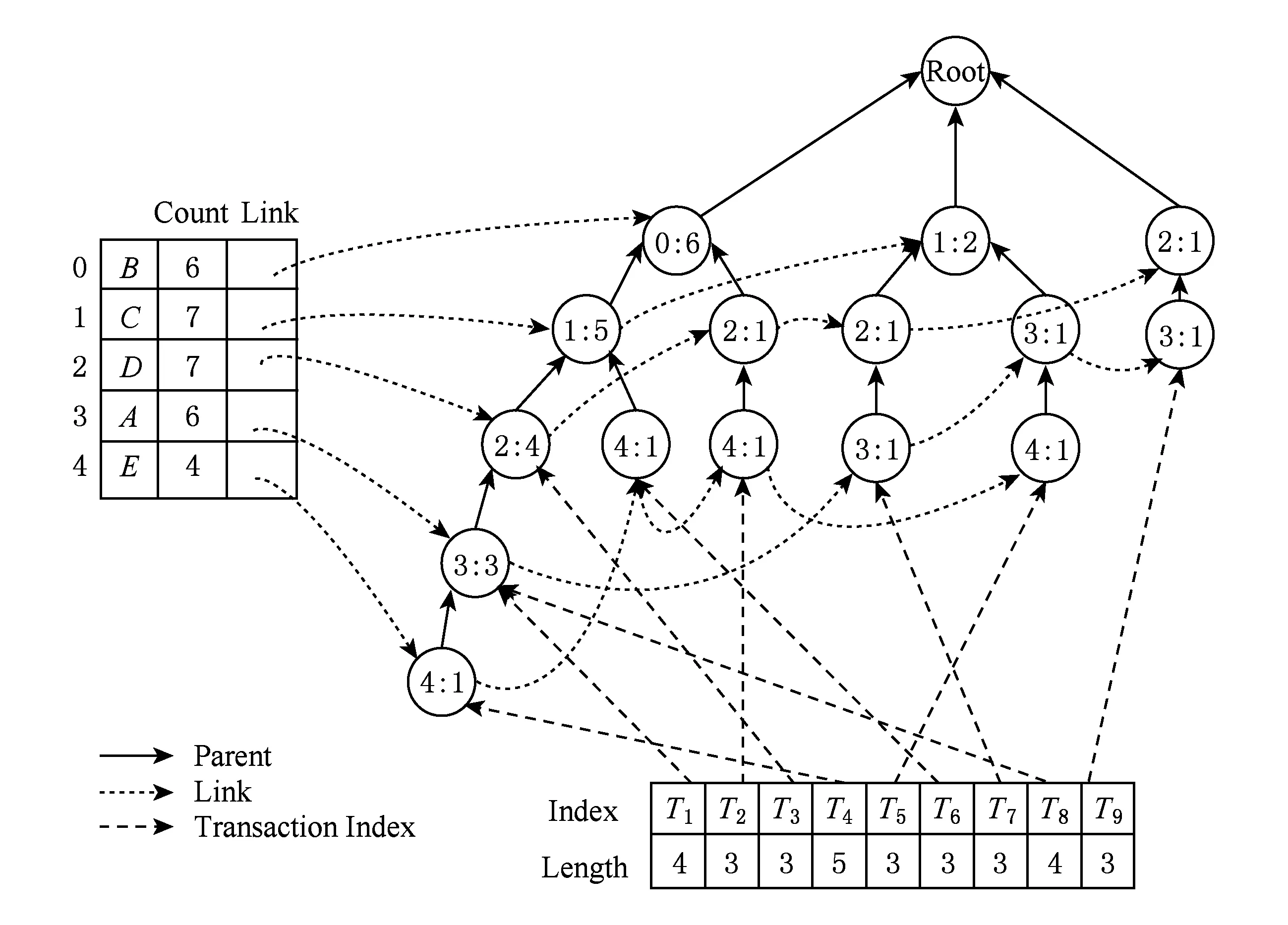
Fig. 5 FP-tree after deleting node B图5 删除节点B后的FP-tree
3.3 FP-DSRRC算法描述
FP-DSRRC算法的伪代码如算法1所示.
算法1. FP-DSRRC算法.
输入:原事务数据库DB、最小支持度阈值MST、最小置信度阈值MCT、敏感规则集SR;
输出:消除敏感规则的事务数据库DB′.
① 根据DB和MST建立FP-tree;
② 利用FP-Growth挖掘频繁项集,根据MCT计算强关联规则AR;
③ 根据定义5计算敏感度;
④ For eachsr∈SR
⑤ 根据定义6确定待删除项;
⑥ 将SR根据待删除项分簇得到Clusters;
⑦ End For
⑧ For eachc∈Clusters
⑨ 根据定义5计算簇敏感度;
⑩ End For
算法1中行①~③首先建立FP-tree,通过挖掘频繁项集得出强关联规则集合,进而计算其敏感度;随后,行④~确定各敏感规则1的待删除项,并根据待删除项分簇,同时将簇进行降序排序;算法行~,对所有划分出的簇按照簇敏感度进行关联规则消除,并维护事务索引表;最后,行当所有敏感簇处理完毕后,根据事务索引表生成消除敏感规则的事务数据库DB′.
4 实验及结果分析
4.1 TestDB数据集
对于2.1节表1中给出的精简数据集TestDB,利用FP-DSRRC算法处理后的结果如表4所示:
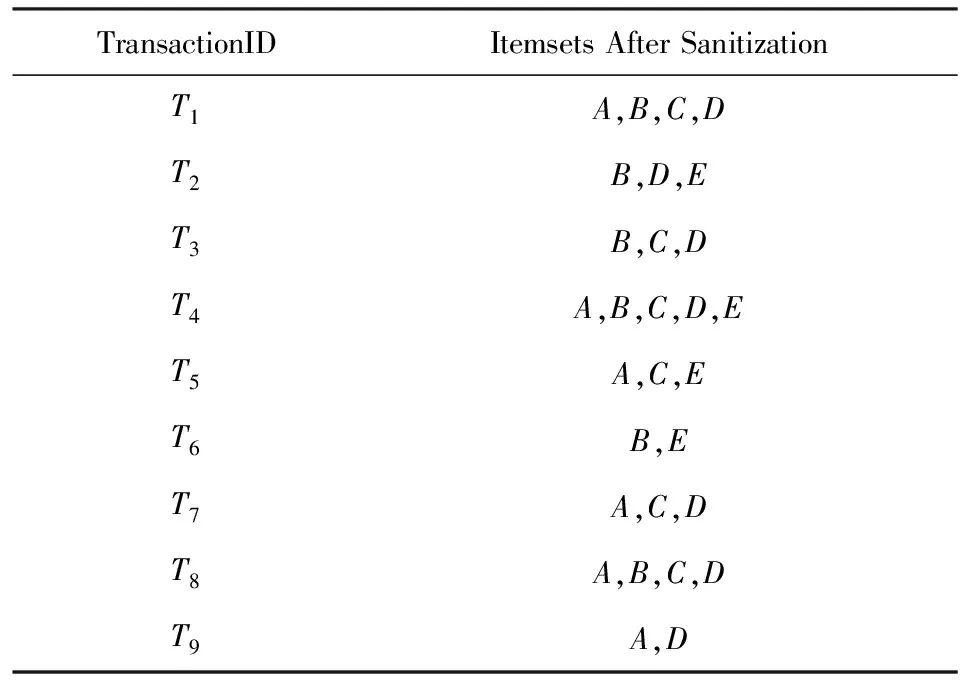
Table 4 New Dataset DB′ after Hiding Sensitive Rules表4 消除敏感规则后的DB′
由表1和表4中的数据,采用式(3)可分别求得敏感规则的置信度,则对于原始事务数据库DB中,E→C为0.75,A→B为0.67,A→BD为0.67;而经过FP-DSRRC算法处理后生成的事务数据库DB′中,E→C为0.50,A→B为0.50,A→BD为0.50,置信度均得以减少到MCT之下,消除了敏感规则的强关联性.
4.2 真实数据集
为了验证算法的高效性,实验将FP-DSRRC,DSRRC[7],ADSRRC[8],MDSRRC[9]在真实数据集下进行测试对比.实验环境在AMD A6-3420 1.5 GHz CPU和8 GB内存的计算机上,操作系统为Windows 10,开发语言Java.本实验采用的数据集是数据挖掘中的2个经典数据集Chess和Mushroom[20].其中,Chess数据集包含74个项,共3 196条事务记录,其平均长度为37,比较稠密;Mushroom数据集含有119个项,共8 124条记录,其平均长度为23,比较稀疏,数据集信息如表5所示.Chess数据集的MST和MCT分别设置为90%和80%,Mushroom数据集的MST和MCT分别设置为30%和60%,随机选择一定数量的规则作为敏感规则,对比不同算法之间的HF,MC,AP运行时间Runtime指标.
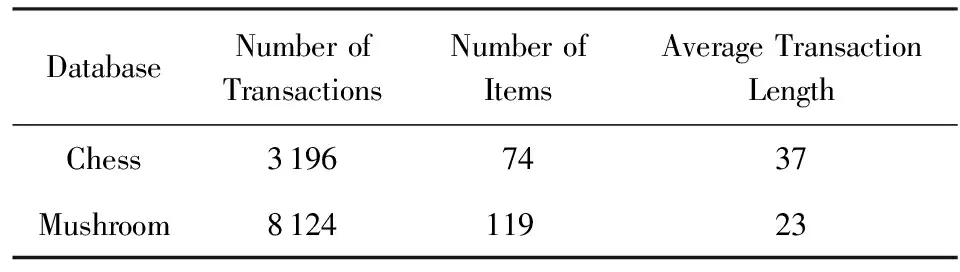
Table 5 Details of Chess and Mushroom表5 Chess和Mushroom数据集信息
4种算法都采用删除敏感项的方式来减小敏感规则的支持度或置信度,所以理论上敏感规则都可以被隐藏,在2个数据集上的实验也证明了这4种算法的隐藏失败率HF=0.
图6展示了4种算法在Chess和Mushroom数据集上消除敏感规则后的规则丢失率MC.由于Chess数据集较稠密而Mushroom数据集较稀疏,Chess数据集中频繁项的支持度也较大,所以当删除部分敏感项后,4种算法在Chess数据集比Mushroom数据集有更低的规则丢失率.
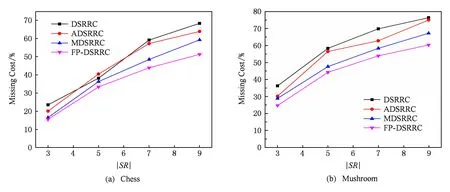
Fig. 6 Missing cost图6 规则丢失率
由于FP-DSRRC算法将敏感规则分簇后,按簇为单位消除敏感规则,每次选择删除的事务都尽可能支持多个敏感规则,从而使事务删除过程对原始数据集修改较小.从图6可以看出随着敏感规则数的增加,所删除的敏感项也越多,规则丢失率也随之增加,但FP-DSRRC在较稠密和较稀疏的数据集上的规则丢失率都低于其他算法.
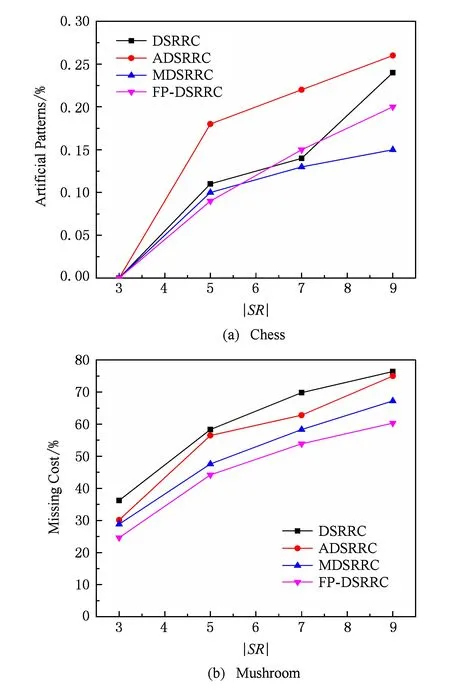
Fig. 7 Artificial patterns图7 规则产生率
图7展示了4种算法在Chess和Mushroom数据集上消除敏感规则后的人为规则产生率AF,4种算法均通过删除敏感项改变敏感项的支持度和与其关联的频繁项集支持度,所以都不产生太多的人为规则.从图7可以看出,随着越多的敏感项被删除,4种算法产生的人为规则都在增加,但总体都处于一个较低的水平.在AP这项指标上,FP-DSRRC算法与MDSRRC算法接近,优于DSRRC和ADSRRC算法.

Fig. 8 Runtime of hiding sensitive rules on Chess and Mushroom图8 Chess和Mushoom数据集上消除敏感规则的运行时间
图8展示了4种算法在Chess和Mushroom数据集上的运行时间Runtime,这也是FP-DSRRC算法相对于其他3种算法提升最显著的指标,由于FP-DSRRC算法自始至终都通过维护一棵FP-tree而避免了对原事务数据库的重复遍历,并且在每次消除簇后直接利用FP-Growth重新挖掘关联规则,减少了大量的I/O时间.当数据集较大时,FP-DSRRC算法的执行效率优势就越明显,因为数据集越大,遍历数据集所需要的I/O时间就越多,而FP-DSRRC算法只需要通过FP-tree的节点信息就能快速确定事务的索引及敏感度.从图8可以看出在2个数据集上FP-DSRRC的运行效率都高于其他3种算法,并且在更大的Mushroom数据集上优势越明显,而且随着敏感规则数的增加,FP-DSRRC的优势会越来越大.
4.3 大型数据集
为了验证算法的可用性,实验在2个较大的数据集Retail和BMS-Webview-2[20]上进行测试.Retail数据集由一个比利时零售超市匿名捐赠用于科研分析,数据集包含5 133个顾客对16 469种商品的88 163条购买记录.由于人们购买那些必备商品、常用商品的频率远远高于那些冷门商品,所以整个数据集呈现出稀疏、不均匀的特点.BMS-Webview-2数据集由是一个电子商务网站对点击流量的统计,包含77 512条记录,数据集的总项数较少,平均事务长度较短.Retail和BMS-Webview-2数据集的详细信息如表6所示:
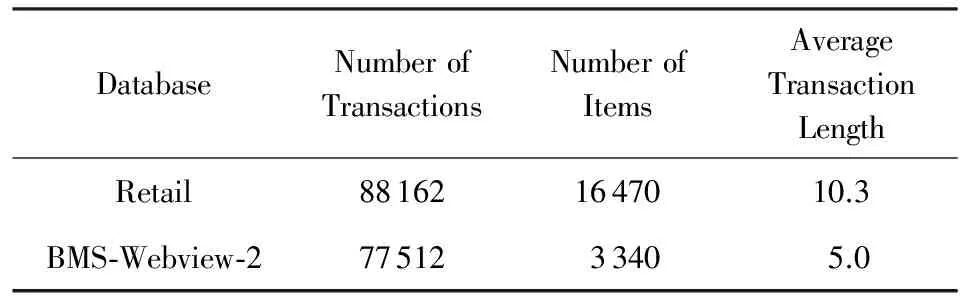
Table 6 Detail of Retail and BMS-Webview-2表6 Retail和BMS-Webview-2数据集挖掘结果
我们设置Retail数据集的MST=1%,MCT=20%;BMS-Webview-2数据集的MST=0.5%,MCT=10%,由于数据集较大,DSRRC算法、ADSRRC算法和MDSRRC算法需要频繁对原事务数据库进行I/O,时间上已经变的不可控,即这些算法已经不适用于这个大数据集,所以我们给出HCSRIL算法[5]、COA4ARH算法[6]和FP-DSRRC算法在2个数据集上的运行时间对比,实验依旧随机选取一定数量的强关联规则作为敏感规则.
图9展示了3种算法在2个数据集上的运行时间,随着敏感规则数的增加,算法的执行时间也随之增加.由于COA4ARH算法通过迭代选择最优敏感项消除策略,且一般需要迭代10次以上才能获得较好的效果,当数据集较大时单次迭代时间较长,故该算法运行时间最长;HCSRIL算法先评估所有敏感项对频繁项集的影响,然后逐条消除敏感规则,而FP-DSRRC算法通过分簇方式可同时对多条敏感规则进行消除,故其执行时间比HCSRIL算法短.由于BMS-Webview-2数据集的密度较低,数据项也较少,所以3种算法在BMS-Webview-2数据集下的运行时间比Retail数据集要长.
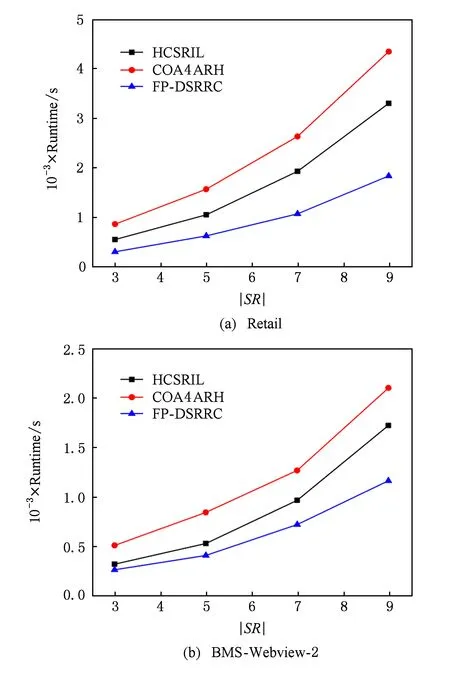
Fig. 9 Runtime of hiding sensitive rules on Retail and BMS-Webview-2图9 Retail和BMS-Webview-2数据集上消除敏感规则的运行时间
同时,我们通过Retail数据集和BMS-Webview-2数据集测试算法的内存开销,实验结果如图10所示.BMS-Webview-2数据集由于事务平均长度较小,项的总个数也较少,所以在相同事务数量的时候,算法执行的内存消耗较在Retail数据集时低.随着事务数量的增加,算法所需内存的增长率在不断变小,这是因为算法很好地利用了FP-tree本质上是一棵前缀树的性质,事务在插入FP-tree前进行了项序转换并按序号排序,所以越频繁的项总是在前面.随着FP-tree节点的不断增加,FP-tree会包含更多的频繁的项序,这时有相同前缀的事务就可以只修改节点的计数值而不是耗费内存去创建1个新的节点.总体来说,FP-DSRRC算法在面对这些较大的数据集上仍然有较好的可用性.
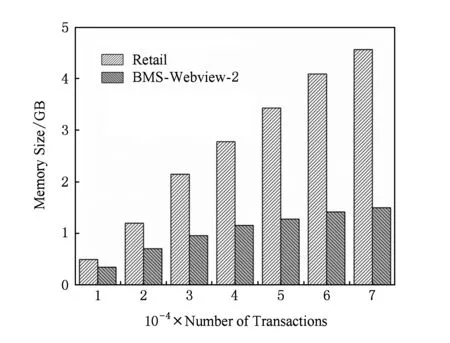
Fig. 10 Memory consumption in Retail图10 Retail数据集上的内存开销
5 结束语
通过FP-tree,将关联规则隐藏的2个步骤频繁项集挖掘和消除关联规则结合起来,提出了一种兼数据集质量和运行效率的算法FP-DSRRC,通过对敏感规则进行簇划分,以簇为单位进行敏感规则隐藏,并通过计算敏感规则的最小删除数和统计事务的敏感规则支持数保证了清理后数据集的质量,降低了关联规则隐藏对原事务数据库的影响,显著提升了算法运行效率.
[1]Chong Zhihong, Ni Weiwei, Liu Tengteng, et al. A privacy-preserving data publishing algorithm for clustering application[J]. Journal of Computer Research and Development, 2010, 47(12): 2083-2089 (in Chinese)(崇志宏, 倪巍伟, 刘腾腾, 等. 一种面向聚类的隐私保护数据发布方法[J]. 计算机研究与发展, 2010, 47(12): 2083-2089)
[2] Agrawal R, Srikant R. Privacy-preserving data mining[C] //Proc of the 2000 ACM SIGMOD Int Conf on Management of Data. New York: ACM, 2000: 439-450
[3] Agrawal R. Mining association rules between sets of items in large databases[C] //Proc of the 1993 ACM SIGMOD Int Conf on Management of Data. New York: ACM, 1993: 207-216
[4] Refaat M, Aboelseoud H, Shafee K, et al. Privacy preserving association rule hiding techniques: Current research challenges[J]. International Journal of Computer Applications, 2016, 136(6): 11-17
[5] Le H Q, Arch-Int S, Nguyen H X, et al. Association rule hiding in risk management for retail supply chain collaboration[J]. Computers in Industry, 2013, 64(7): 776-784
[6] Afshari M H, Dehkordi M N, Akbari M. Association rule hiding using cuckoo optimization algorithm[J]. Expert Systems with Applications, 2016, 64: 340-351
[7] Modi C N, Rao U P, Patel D R. Maintaining privacy and data quality in privacy preserving association rule mining[C] //Proc of the 2nd Int Conf on Computing Communication and Networking Technologies. Piscataway, NJ: IEEE, 2010: 1-6
[8] Shah K, Thakkar A, Ganatra A. Association rule hiding by heuristic approach to reduce side effects & hide multiple RHS items[J]. International Journal of Computer Applications, 2012, 45(1): 1-7
[9] Domadiya N H, Rao U P. Hiding sensitive association rules to maintain privacy and data quality in database[C] //Proc of the 3rd Int Advance Computing Conf (IACC). Piscataway, NJ: IEEE, 2013: 1306-1310
[10] Peng Cheng, Ivan L, Li Li, et al. BRBA: A blocking-based association rule hiding method[C] //Proc of the 13th AAAI Conf on Artificial Intelligence (AAAI’16). Berlin: Springer, 2016: 4200-4201
[11] Jain D, Khatri P, Soni R, et al. Hiding sensitive association rules without altering the support of sensitive items[C] //Proc of the 2nd Int Conf on Computer Science and Information Technology. Berlin: Springer, 2012: 500-509
[12] Cheng Peng, Pan Jeng-Shyang, Lin Chunwei. Use EMO to protect sensitive knowledge in association rule mining by removing items[C] // Proc of the 2014 IEEE Congress on Evolutionary Computation. Piscataway, NJ: IEEE, 2014: 65-66
[13] Guo Yuhong. Reconstruction-based association rule hiding[C] //Proc of ACM SIGMOD 2007. Berlin: Springer, 2007: 51-56
[14] Han Jiawei, Pei Jian, Yin Yiwen. Mining frequent patterns without candidate generation[C] //Proc of the 2000 ACM SIGMOD Int Conf on Management of Data. New York: ACM, 2000: 1-12
[15] Ainen T M. On inverse frequent set mining[C] //Proc of Workshop on Privacy Preserving Data Mining. Piscataway, NJ: IEEE, 2003: 18-23
[16] Gui Qiong, Cheng Xiaohui, Rao Jianhui. Privacy preserva-tion association rules mining algorithm based on RSA[J]. Computer Engineering, 2009, 35(17): 138-140 (in Chinese)(桂琼, 程小辉, 饶建辉. 基于RSA的隐私保护关联规则挖掘算法[J]. 计算机工程, 2009, 35(17): 138-140)
[17] Domadiya N H, Rao U P. A hybrid technique for hiding sensitive association rules and maintaining database quality[C] //Proc of the 1st Int Conf on Information and Communication Technology for Intelligent Systems. Berlin: Springer, 2016: 359-367
[18] Shen Yan, Song Shunlin, Zhu Yuquan. Mining algorithm of association rules based on disk table resident FP-TREE[J]. Journal of Computer Research and Development, 2012, 49(6): 1313-1322 (in Chinese)(申彦, 宋顺林, 朱玉全. 基于磁盘表存储FP-TREE的关联规则挖掘算法[J]. 计算机研究与发展, 2012, 49(6): 1313-1322)
[19] Niu Xinzheng, Yang Jian, She Kun. Algorithm of frequent itemsets mining based on array prefix-trees[J]. Journal of Chinese Computer Systems, 2014, 35(8): 1693-1698 (in Chinese)(牛新征, 杨健, 佘堃. 基于数组前缀树的频繁项集挖掘算法[J]. 小型微型计算机系统, 2014, 35(8): 1693-1698)
[20] Philippe F. SPMF: A Java open-source data mining library[DB/OL]. [2016-07-16]. http://www.philippe-fournier-viger.com/spmf/index.php?link=datasets.php
AnEfficientAssociationRuleHidingAlgorithmBasedonClusterandThresholdInterval
Niu Xinzheng1, Wang Chongyi1, Ye Zhijia1, and She Kun2
1(SchoolofComputerScienceandEngineering,UniversityofElectronicScienceandTechnologyofChina,Chengdu611731)2(SchoolofInformationandSoftwareEngineering,UniversityofElectronicScienceandTechnologyofChina,Chengdu610054)
Association rules hiding is a very important method of privacy-preserving data mining (PPDM). Because the current association rules hiding algorithm operates the transaction database directly, it leads to a lot of I/O overhead. To solve this problem, we put forward a quick association rules hiding algorithm based on FT-tree, called FP-DSRRC. Firstly, the algorithm improves the structure of FP-tree by adding an index to the transaction number and establishing the bidirectional traverse structure. Then FP-DSRRC uses the improved FP-tree to quickly handle transaction data set, avoiding a large number of I/O overhead caused by traversal the raw transaction data set. Furthermore, FP-DSRRC finds the sensitive items quickly by building and maintaining a transaction index table, and then handles the association rules based on the clustering strategy. We eliminate the sensitive rules by clusters, and reduce the negative influence caused by association rules hiding progress to the original data set by adopting the idea of rule support and confidence degree interval at the same time. Finally, the experiment shows that compared with traditional association rules hiding algorithm, the executive time of FP-DSRRC has been decreased by 50%~70% while guaranteeing the quality of general data, moreover, FP-DSRRC has better availability on a large-scale real data set.
privacy preservation; association rule hiding; FP-tree; sensitive rule; data sanitization
2016-08-16;
2017-01-06
国家自然科学基金项目(61300192);国家科技支撑计划基金项目(2013BAH33F02);中央高校基本科研业务费专项资金项目(ZYGX2014J052);四川省科技支撑计划基金项目(2015GZ0096);成都市科学技术局软科学研究项目(2015-RK00-00046-ZF);四川省公安厅科研项目(2015SCYYCX06);四川省自贡市公安局项目
This work was supported by the National Natural Science Foundation of China (61300192), the National Key Technology Research and Development Program of China (2013BAH33F02), the Fundamental Research Funds for the Central Universities (ZYGX2014J052), the Key Technology Research and Development Program of Sichuan Province (2015GZ0096), the Soft Science Research Project of Chengdu Science and Technology Bureau (2015-RK00-00046-ZF), Scientific Research Project of Sichuan Provincial Public Security Department (2015SCYYCX06), and the Project of Public Security Bureau of Zigong City, Sichuan Province.
TP301.6

NiuXinzheng, born in 1978. PhD, associate professor. Senior member of CCF. His main research interests include data mining and information security.

WangChongyi, born in 1995. Master candidate. His main research interests include social network and data mining.

YeZhijia, born in 1993. Master candidate. His main research interest include big data and social network.

SheKun, born in 1969. Professor and PhD supervisor of University of Electronic Science and Technology of China. His main research interests include information security and big data.
猜你喜欢
电子技术与软件工程(2022年15期)2022-11-11
小型微型计算机系统(2022年4期)2022-05-09
辽宁大学学报(自然科学版)(2022年1期)2022-04-26
中华骨与关节外科杂志(2021年8期)2021-11-30
西安邮电大学学报(2021年6期)2021-05-10
计算机与数字工程(2018年10期)2018-10-23
计算机应用(2018年5期)2018-07-25
计算机与数字工程(2017年2期)2017-03-02
中国科技纵横(2016年20期)2016-12-28
医学研究杂志(2015年9期)2015-07-01
