
互补学习:一种面向图像应用和噪声标注的深度神经网络训练方法
2017-12-16 05:17周彧聪
计算机研究与发展 2017年12期
周彧聪 刘 轶 王 锐
(北京航空航天大学中德联合软件研究所 北京 100191)
互补学习:一种面向图像应用和噪声标注的深度神经网络训练方法
周彧聪 刘 轶 王 锐
(北京航空航天大学中德联合软件研究所 北京 100191)
(zjoe546@foxmail.com)
近几年来,深度神经网络在图像识别、语音识别、自然语言处理等众多领域取得了突破性的进展.互联网以及移动设备的快速发展极大地推进了图像应用的普及,也为深度神经网络的训练积累了大量数据.其中,大规模人工标注的数据是成功训练深度神经网络的关键.但随着数据规模的快速增长,人工标注图像的成本也越来越高,同时不可避免地产生标注错误,从而影响神经网络的训练.为此,提出了一种称为互补学习的方法,面向图像应用中深度神经网络的训练,将简单样本挖掘和迁移学习的思想相结合,利用少量人工标注的干净数据和大量带有噪声标注的数据,同时训练一主一辅2个深度神经网络模型,在训练过程中采用互补的策略分别选择部分样本进行学习,同时将辅模型的知识迁移给主模型,从而减少噪声标注对训练的影响.实验表明:提出的方法能有效地利用带有噪声标注的数据训练深度神经网络,并对比其他方法有一定的优越性,有较强的应用价值.
深度神经网络;图像应用;噪声标注;简单样本挖掘;迁移学习
近年来,深度神经网络在图像识别、语音识别、自然语言处理等众多领域的应用取得了突破性的进展.其中,大规模标注数据(如ImageNet[1])在物体识别[2]、物体检测[3]及深度神经网络结构[4]等应用中发挥着重要作用.而在图像应用中,模型的性能很大程度上取决于标注数据的数量和质量.在实际的研究与应用中,一般采用2种典型的方法来获取和标注大规模图像数据:大量的人工参与或是利用互联网搜索引擎在获取数据的同时将搜索关键字作为标注[5].对于人工参与的标注工作而言,当需求的数据量增长到一定规模时,人工标注的时间成本和人力成本都将难以承受.另外一种构建大规模图像标注的方法是利用互联网搜索引擎获取图像数据,同时将搜索关键字作为数据的标注.这种方法可以较为容易地获得大量的标注数据,但也不可避免地引入了大量噪声.直接使用带有大量噪声的数据进行训练则会对深度神经网络的性能产生较大的负面影响[6].
相比于直接使用噪声数据训练,我们注意到有2种方法可以更好地利用噪声数据.
1) 利用简单样本挖掘的思想,在训练模型的过程中把模型对于标注类别预测的置信度近似地看作该样本标注正确的概率,并让模型只学习当前预测置信度较高的样本.该方法的思想在于利用噪声数据训练得到的模型仍具有一定的判别能力,使得模型预测的置信度也一定程度上反映了样本标注正确的可能性.通过选择高置信度的样本,可以从噪声数据中以较高的可能挑选正确的样本进行训练,从而使模型不断提升.该方法可以看作是在线难样本挖掘(online hard example mining)[7]的反面,即在线简单样本挖掘.然而这种方法也有很强的局限性,主要体现在:①高置信度样本的阈值难以选择,并且训练效果对阈值比较敏感;②选择样本的过程取决于模型本身,两者高度相关,因此比较容易陷入较差的局部最优解中.
2) 需要一部分经过人工标注的干净数据.虽然大规模干净标注数据需要消耗大量的人力和时间成本,少量的干净标注数据则是相对容易获得.在这种场景下,知识提取方法[8]基于迁移学习[9]的思想,先用少量干净数据训练一个辅助模型,再在噪声数据上用辅助模型生成软目标供主模型学习.这种方法可以一定程度上利用噪声数据,但其效果很大程度上取决于干净数据的数量.在干净数据较少的情况下,辅助模型提供的信息十分有限,同时也存在过拟合的风险.
基于这2种方法的特点和存在的问题,本文提出了一种称为互补学习的深度神经网络训练方法.该方法同时训练2个模型,称为主模型和辅助模型.辅助模型和主模型分别采取保守的学习策略和激进的学习策略进行训练.保守的学习策略会尽可能选择置信度高的数据进行训练,其目的是在尽量保持辅助模型干净的同时提升其精度;而激进的学习策略则会让主模型学习置信度更低的样本,从而在大规模的训练数据中尽可能地学习到有价值的难样本.为了避免训练样本的选择完全依赖于单个模型,该方法综合考虑2个模型预测的置信度来选择样本,2个模型互为对方提供辅助信息,从而降低了样本的选择和单个模型的相关性.更进一步地,该方法利用迁移学习的思想,让主模型学习辅助模型生成软目标(soft targets),利用相对干净的辅助模型去纠正主模型学习到的噪声.与现有方法相比,本文提出的基于互补学习的训练方法能更有效地利用噪声数据训练深度神经网络.在人工生成的噪声数据和真实噪声数据上进行的多组实验表明:本文的方法能更好地适应不同的噪声数据,并获得更高的精度,因此有较强的应用价值.
1 相关工作
本文提出了一种利用大量噪声数据和少量干净数据训练深度神经网络的方法,目的是有效利用相对容易获得的大量噪声数据训练深度神经网络,并减少标注噪声对训练的影响.本文主要在单标签图片分类任务中讨论该方法的原理和应用.文献[10]比较全面地介绍了标注噪声和噪声鲁棒算法,而我们下面主要介绍比较相关的文献和方法.
从噪声数据中学习是机器学习的一个重要研究领域.利用噪声数据进行学习的方法通常可以分为两大类:
1) 尝试直接从噪声标注中进行学习.例如文献[11]提出了一种自我引导(bootstrapping)的方法,根据模型当前的预测结果动态修改标注,从而减轻噪声标注的影响;文献[12]提出了一种重要性重加权的方法,利用预训练的分类器估计噪声水平,以此减少随机噪声的影响,该方法扩展了传统重加权方法[13]中无偏损失函数的思想;文献[14]提出了一种“噪声层”的方法,在交叉熵损失函数上增加一个全连接层用来“吸收”噪声标注;文献[15]中提出了一种简单的标签平滑化的方法,将标注均匀地重分布在所有类别中,从而避免过于信任数据标注,减少噪声的影响;文献[16]提出了一种损失函数修正的方法,该方法结合并扩展了噪声层和文献[17]中提出的噪声估计方法,一定程度上减弱了需要已知噪声分布的条件.这些方法由于缺少外部的辅助信息,有较大的风险拟合到噪声数据,或者需要对噪声结构做比较强的假设,比如噪声层和损失函数修正方法均假设噪声仅依赖于类别而与图片无关,并且标注在类别之间存在一定的概率出错,而现实场景中的噪声数据通常有更复杂的结构.
2) 通过引入少量的干净标注数据来弥补上述方法的不足,这些方法一般被称为半监督方法.典型的半监督方法例如标签传播方法[18-19]将少量干净数据的标注逐渐传播到大量噪声数据中.然而这种方法需要样本数量平方级别的复杂度,所以难以扩展到大规模数据上.受噪声层启发,文献[5]提出了一种基于概率图模型建模噪声的方法.该方法扩展了噪声层中噪声只依赖于类别的假设,让噪声分布也依赖于图片本身,并利用少量的干净数据帮助建模噪声.类似的方法[20]也提出依赖于图片的噪声模型,不同的是这种方法关注多标签分类任务,利用经过人工矫正的标注学习噪声标注到正确标注的映射.在多标签分类任务中,标签之间通常存在一定的内在联系,同时多个标签全是错误标注的概率较低,因此该方法可以利用这种特性来矫正噪声标注.而在单标签分类任务中标签只有一个,提供的信息远少于多标签任务,因此矫正难度比较大.文献[8]提出了一种基于“知识提取”的方法来利用噪声数据进行学习.和bootstrapping、标签平滑化等方法类似,该方法也是通过修改标注来减少噪声的影响.不同的是,该方法先用干净数据训练了一个辅助模型,并利用辅助模型的预测结果修正噪声标注.该方法证明了通过精细的设置修正参数,其受噪声影响的风险要小于bootstrapping和标签平滑化方法.但该方法的辅助模型仅利用了干净数据进行训练,当干净数据较少时,辅助模型能提供的信息十分有限.
本文提出的方法也利用了少量干净数据的标注.与概率图模型和损失函数修正等方法不同的是,该方法不去直接建模噪声.这种选择的原因在于,建模噪声依赖于对噪声分布进行假设并需要足够数量的干净数据.一方面真实场景中的噪声来源比较复杂,假设通常不能完全成立;另一方面获取干净标注数据的成本较高,通常难以获得大量的干净标注.我们的方法从另一个角度出发,结合了简单样本挖掘和迁移学习的思想.与现有方法不同的是,我们的方法利用了“互补”的概念,采用不同的策略同时训练2个模型.这种设计一方面解决了简单样本挖掘方法容易陷入局部最优解的问题,另一方面也改进了知识提取方法中辅助模型受限于少量干净数据的缺陷.
2 基于互补学习的训练方法
噪声数据常见于图片分类任务中,许多现有方法都是在该场景下进行研究,我们也在图片分类任务中分析和测试所提出的方法.
我们提出的基于互补学习的训练方法结合了2种思想:简单样本挖掘和迁移学习.本节我们先形式化设定问题,之后分别介绍这2种思想在噪声数据上的应用并分析其存在的问题,最后介绍我们的方法并分析其相比于前面2种方法的优势.
2.1 问题设定
考虑一个单标签图片分类问题,C={1,2,3,…,c}共c类.训练数据D由2部分构成,D=Dclean∪Dnoise,其中:
Dnoise={(x1,y1),(x2,y2),…,(xN,yN)},
Dclean= {(xN+1,yN+1),(xN+2,yN+2),…,
(xN+M,yN+M)},
Dnoise,Dclean分别为噪声数据和人工标注的干净数据,M≪N.xi是一张图片,yi∈C是xi的类别标签,令:
(1)
称Hi为yi的独热码(one-hot code).
利用深度神经网络解决单标签图片分类任务的典型方法如下:
选定某个深度神经网络结构F,权重为θ,F的输入为图片xi,输出为向量si∈Rc.则:
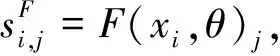
(2)
其中,CE为交叉熵,B为一个样本批,Loss(B)为该样本批的交叉熵损失函数.利用随机梯度下降方法来优化该损失函数,最终得到训练好的模型(F,θ).
该过程是利用深度神经网络来拟合样本xi属于yi类别的概率分布.如果用上述方法直接学习噪声数据,则模型可能会拟合到噪声数据上,从而降低模型的性能.
2.2 在线简单样本挖掘
在介绍简单样本挖掘之前,我们先介绍与之相对的方法:难样本挖掘.难样本挖掘由Felzenszwalb 等人[21]提出,主要应用于优化支持向量机(support vector machine, SVM).其主要思想是维护一个数据集的子集,称为工作集,并交替进行2个步骤:
1) 在当前工作集上训练SVM直到收敛;
2) 根据当前的SVM模型更新工作集.
更新工作集的方法一般是根据当前模型去掉一些简单样本并加入一些困难样本,在这个过程中当前模型是固定的.Shrivastava等人[7]提出了一种称为在线难样本挖掘的方法,可以直接应用于训练深度神经网络常用的随机梯度下降方法中.其思想是在训练过程中,以当前批次中每个样本的损失值作为样本难易程度的标准,并选择一部分损失值较大(难样本)的样本进行反向传播.由于每次都选择比较难的样本进行学习,这种方法可以提高模型精度,并且加快收敛速度.
然而在线难样本挖掘实际上要求数据标注是干净的,该方法不能在噪声数据上得到有效的应用.其原因在于噪声数据与干净数据分布相差较大,如果模型当前主要拟合了干净数据,则噪声样本的损失值会相对较大,从而被选择为难样本,而干净样本则被视为简单样本.因此反向传播的过程中梯度大部分来自于噪声样本,从而让模型去拟合噪声数据.反之如果当前模型主要拟合了噪声数据,则经过难样本挖掘反而会让模型去拟合干净数据.由此模型拟合的分布会在干净数据和噪声数据之间震荡,造成训练过程的不稳定,降低模型的性能.
根据类似的思想,我们针对噪声数据提出在线简单样本挖掘(online easy example mining)方法.将式(2)修改为
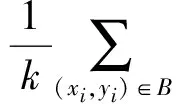
(3)
其中,1[条件]为示性函数.对于每个批次的样本,我们将当前模型预测的置信度Pi,yi作为样本xi的难易程度,置信度越高认为该样本越简单,并选择最简单的K个样本进行学习.K一般可以根据噪声数据的噪声比例进行选取,一种方法是:
K=Ceil(|B|×(1-Pnoise))
(4)
即每个批次样本中干净数据数量的期望.噪声比例Pnoise通常可以利用采样的方式进行估计.
与在线难样本挖掘不同的是,简单样本挖掘在噪声数据上有较好的鲁棒性,并能一定程度上帮助模型的训练.原因在于,在模型已经一定程度上拟合了干净数据的情况下,置信度高的样本有较大可能是干净数据,因此选择简单样本学习会进一步使模型拟合干净数据,从而帮助模型训练.
这种方法的缺点在于:其样本选择的过程无法很好地区分噪声和困难的干净样本,因此可能会使模型拟合在较小的一部分数据上,导致模型过拟合.另一方面,由于样本选择过程完全依赖于模型自身,该方法很容易使模型陷入局部最优解中,不能充分利用噪声数据.
2.3 基于迁移学习的方法
迁移学习以多种形式出现在机器学习领域.一种形式是“微调”,即先在一个较大且与目标任务有一定相关性的数据集上训练一个深度神经网络,之后再在目标数据集上进行微调.这种方法被认为可以将大数据集中的“知识”迁移到目标任务中,增强特征的泛化能力并减少过拟合的可能.这种方法通常可以有效地提高目标任务的精度,例如R-CNN[3]中利用ImageNet图片分类任务上预训练的模型在目标检测数据集上进行微调,得到了非常好的效果.类似的做法目前已经成为惯例,也在各种图片相关的任务中得到了广泛的应用.
迁移学习的另一种形式是Hinton等人[9]提出的“知识提取”,其做法是把一个模型的预测结果作为目标,称为软目标(soft targets),让另一个模型学习.这种方法的典型应用是用一个较小的模型去学习一个或多个较大模型整合的软目标,从而让一个小模型获得与一个或多个大模型接近的精度.
上述迁移学习的2种形式在噪声数据的训练方法中均有体现.根据文献[20],先在噪声数据上训练,再在干净数据上微调是一种常见做法.知识提取(distillation)[8]方法提出利用迁移学习的思想,先用干净数据训练一个模型FA,再用FA在噪声数据上生成软目标,让模型FB进行学习,即:
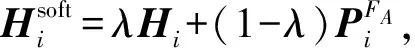
(5)
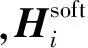
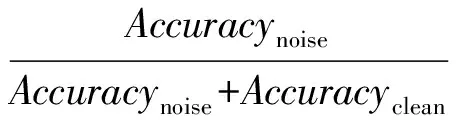
(6)
这2种方法均能一定程度上降低噪声数据对训练的影响,但也存在缺陷:2种方法都非常依赖干净数据的数量.当只有少量干净数据时,无论微调还是知识提取方法,都有较大过拟合的风险.
2.4 结合简单样本挖掘和迁移学习:互补学习
2.2节和2.3节介绍的2种方法均可以一定程度上减少噪声的影响,但也存在各自的缺陷.在简单样本挖掘中,简单样本的选择完全依赖于模型自身,容易使模型陷入较差的局部最优解;而迁移学习的有效性取决于干净数据的数量,干净数据较少时容易过拟合.基于对这2种方法的分析,我们提出一种称为互补学习的方法,结合两者的优点并改进两者的不足.下面介绍基于互补学习的训练方法,如图1所示:

Fig. 1 The overall framework of complementary learning图1 基于互补学习的训练方法
选择2个深度神经网络结构记为F1和F2(可以是相同的结构),F1作为辅助模型,F2作为主模型.对F1和F2采用不同的策略在D上进行联合训练,具体训练过程如下:
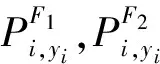
(7)
为F1和F2对样本(xi,yi)的平均置信度.
训练F1网络的损失函数为
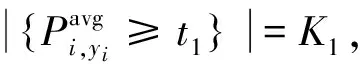
(8)
训练F2网络的损失函数为
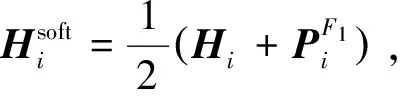
(9)
使用随机梯度下降方法同时训练2个网络直到收敛.
图1展示了上述过程:一组图片分别经过深度神经网络F1和F2,得到2个网络对每个样本预测的置信度PF1,PF2,并计算平均置信度Pavg.2个网络根据Pavg分别选取置信度最高的K1和K2个样本进行学习,对F2来说,其学习目标是由PF1和原始噪声标注H生成的软目标.除此之外,2个网络都额外对一小部分干净样本直接进行学习,但为了清晰地展示我们方法的核心,这部分没有在图1中画出.
为了让模型在训练的开始就具有互补的特性,可以让F1和F2先分别在Dclean和Dnoise上进行预训练,之后再进行上述训练过程.
下面我们对上述方法进行详细说明.首先训练F1,F2的损失函数中均包含了对干净样本的损失(即L1,L2的后半部分),这部分损失是为了防止2个网络在训练的过程中偏离到噪声数据上.这部分损失只起到辅助的作用,同时考虑到干净样本数量较少,采样时m应小于n,减少过拟合的可能.
1) 选择的标准是2个网络的平均置信度,而不是各自的置信度.这个设计主要是为了改进简单样本挖掘的缺陷:样本选择完全依赖于模型自身.由于使用了平均置信度,在样本选择的过程中2个模型互为对方提供了额外的辅助信息,减少了样本选择过程和单个模型的相关性.
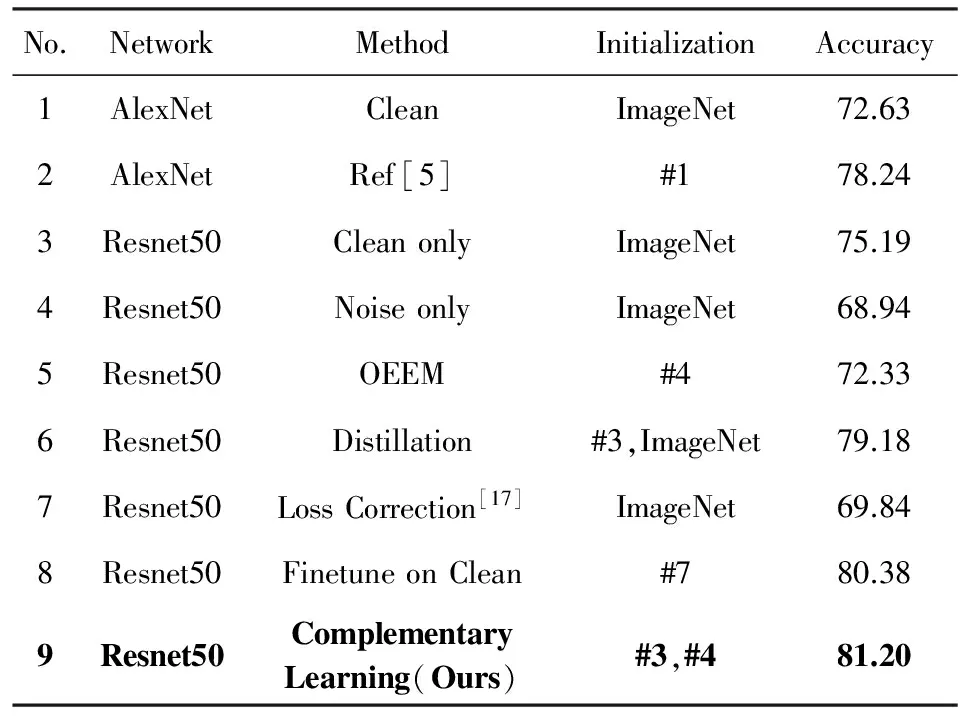
2) 两个损失函数中的样本选择阈值不同.这个设计体现了不同的训练策略,其中K1 这2种不同训练策略使得2个网络表现出一定的互补性质,从而可以互相提升. 我们的方法引入了2个超参数K1,K2来控制样本选择的策略,这里给出一种设置该参数的方法.考虑实际应用场景中,一般可以通过采样的方式比较准确地估算数据的噪声比例Pnoise,那么在噪声数据中采样一个批次样本的过程服从n次实验的二项分布,n为每批样本的数量,令: (10) 其中,binocdf(k,n,1-Pnoise)表示对于某个成功概率为1-Pnoise的实验进行n次实验中有小于等于k次成功的概率,则式(10)表示在噪声数据中采样n个样本,有99%以上的概率至少包含K1个干净样本.这种设置方法遵循了保守的样本选择策略.对于K2,我们将其设置为每个批次中干净样本数量的期望,即: K2=Ceil(n×(1-Pnoise)), (11) 这种设置方法更激进,因为有较大概率引入噪声样本. 我们提出的基于互补学习的训练方法可以总结为3点: 1) 同时训练辅助模型F1和主模型F2,训练时采样一部分噪声数据和一部分干净样本构成每个批次; 2) 利用2个模型的平均置信度进行样本选择,F1采用保守的选择策略,F2采用激进的选择策略; 3) 让F2学习F1生成的软目标,将F1的知识迁移给F2. 另外,虽然在训练过程中需要同时训练F1和F2两个模型,但辅助模型的知识已经通过迁移学习传递给了主模型,所以测试阶段仅需要用主模型进行预测. 我们在Tensorflow[22]中实现了本文所提出的训练方法,并在一台配置双路E5-2680v3处理器和2块Nvidia Titan X GPU的服务器上进行了实验测试.我们参照文献[17]在Cifar10, Cifar100[23]上用人工生成噪声的方式测试所提出的方法,并和其他方法进行对比.另外,我们还在真实噪声数据集Clothing1M[5]上进行了实验测试. 进行对比的4种方法分别是:在线简单样本挖掘(online easy example mining, OEEM)、知识提取(distillation)、损失修正(loss correction)以及我们提出的互补学习(complementary learning).作为基准的还有用干净数据训练(clean only)和用噪声数据训练(noise only). 1) 数据准备.Cifar10和Cifar100各包含50 000张训练图片和10 000张测试图片,在训练集中保留5 000张图片作为验证集,并对剩余45 000张图片人工加入噪声.我们仿照文献[16]在容易混淆的类别之间人工生成噪声.对于属于类别的图片,设其被错误标注为类别j的概率为Ti,j.对于每个类别i,我们给其设置一个相似类j,令Ti,j=Pnoise,Ti,j=1-Pnoise,其中,Pnoise称为噪声水平.Cifar10包含10个类别,设置的相似类别对包括:卡车→轿车、鸟→飞机、鹿→马、猫↔狗.Cifar100包含100个类别,分为20个父类,每个父类包含5个子类.对于每个父类,令其中每个子类和下一个子类构成一个相似对.例如,果蔬父类包含苹果、蘑菇、橘子、梨和甜椒,则相似对为:苹果→蘑菇、蘑菇→橘子、橘子→梨、梨→甜椒、甜椒→苹果.分别令Pnoise为0.2,0.3,0.4生成噪声数据后,再从中随机挑选5 000张去除噪声作为干净数据集. 2) 网络结构.我们选择文献[4]中提出的Resnet20和Resnet32分别在Cifar10和Cifar100上进行实验. 3) 参数设置.所有实验均采用动量值为0.9的随机梯度下降方法进行训练,权重衰减系数为0.000 5.每轮迭代采样的批大小为128,在Comple-mentary Learning方法中额外采样批大小为40的干净数据.训练初始学习率为0.1,进行160个纪元(epoch),学习率分别在80,120个纪元时降低10倍.图片采用标准的归一化方式,即减去图片像素均值并除以图片像素标准差.采用常规的数据增强方法:在32×32的原图四周填充4个像素至36×36,并随机裁剪32×32的区域,再进行随机水平翻转. 本节对OEEM方法和互补学习方法的参数设置策略进行实验和分析. 3.2.1 OEEM方法参数设置实验 对于OEEM方法,根据式(4),其超参数K取决于批大小(实验中为128)和噪声比例.对于Cifar10来说,10个类别中由5个类可能出错(见3.1节),因此当噪声水平为0.2,0.3,0.4时,实际噪声比例为0.1,0.15,0.2,对应的K取值为116,109,103;对于Cifar100来说,100个类别全部可能出错(见3.1),因此实际噪声比例和噪声水平相同,当噪声水平为0.2,0.3,0.4时,对应的K取值为103,90,77;对于Clothing1M,根据原文估计其噪声比例约为0.385,对应的K=79. 为了分析式(4)中提出的参数设置策略,我们在上述K取值的附近采样了一些值进行实验,观察不同K取值下的实验结果. 图2~图4分别展示了OEEM方法在Cifar10,Cifar100和Clothing1M上的结果随K取值的变化.横轴表示K取值与基准值(根据式(4)计算的值)的差,纵轴为测试准确率,各条曲线分别对应了不同的噪声水平和网络结构.可以看到,在大多数情况下,在K取基准值-8时准确率最高,K取基准值次之.这说明式(4)的设置方法有较好的通用性,在不同数据集、噪声水平和网络结构下都获得了较好的准确率,但根据实验发现略小于基准值通常能获得更好的效果. Fig. 2 Accuracy of OEEM method at different hyper parameters on Cifar10图2 Cifar10上OEEM方法参数设置对结果的影响 Fig. 3 Accuracy of OEEM method at different hyper parameters on Cifar100图3 Cifar100上OEEM方法参数设置对结果的影响 Fig. 4 Accuracy of OEEM method at different hyper parameters on Clothing1M图4 Clothing1M上OEEM方法参数设置对结果的影响 3.2.2 互补学习方法参数设置实验 对于互补学习方法,根据式(10)(11),K1,K2两个超参数取决于批大小和噪声比例.和OEEM方法类似,对于Cifar10,当噪声水平为0.2,0.3,0.4时,对应的K1,K2取值为(102,116),(92,109),(84,103);对于Cifar100,对应的K1,K2取值为(84,103),(70,90),(56,77);对于Clothing1M,对应的K1,K2取值为(65,79).我们在这些取值附近进行采样,观察不同K1,K2取值对结果的影响.Cifar10和Cifar100上的实验在Renset32网络结构上进行,Clothing1M的实验在Res50上进行. 图5、图6分别展示了互补学习方法在Cifar10,Cifar100和Clothing1M上的结果随K1,K2取值的变化.纵轴表示K1取值与基准值(根据式(10)计算的值)的差,横轴表示K2取值与基准值(根据式(11)计算的值)的差,用颜色表示准确率的变化,颜色越亮表示准确率越高.可以看到在不同的数据集和噪声水平下,当K1,K2在基准值附近时准确率相对较高,远离基准值时准确率相对较低.这说明式(10)(11)提出的参数设置策略有较好的有效性和通用性. Fig. 5 Accuracy of complementary learning method at different hyper parameters on Cifar10/Cifar100图5 Cifar10/100上互补学习方法参数设置对结果的影响 Fig. 6 Accuracy of complementary learning method at different hyper parameters on Clothing1M图6 Clothing1M上互补学习方法参数设置对结果的影响 根据3.2节的分析,对于OEEM方法,我们根据式(4)设置其超参数K;对于我们提出的互补学习方法,根据式(10)(11)设置超参数K1,K2.对于另外2种方法Distillation和Loss Correction,遵循原文中的方式设置其超参数:根据式(6)设置Distillation方法的超参数λ;遵循原文中的方法对Loss Correction中的混淆矩阵进行估计. 3.3.1 Cifar数据集上的实验和分析 实验结果如表1所示.每一列中精度最高的2种方法用加粗表示.可以看到在不同的数据集,网络结构和噪声水平下,我们的方法均达到了对比的方法中最高的准确率.通过实验结果我们可以发现4点结论: 1) OEEM方法在不同数据集,网络结构和噪声水平下均优于直接使用噪声数据进行训练,但提升较小.原因可能在于该方法没有引入任何额外的信息,只能通过自身网络减少一部分噪声的影响. 2) Distillation方法在低噪声水平时反而会降低准确率,但在较高噪声水平时提升比较明显.例如在Resnet20,Cifar10的实验中,随着噪声水平的提高,Distillation方法相对于Noise Only提高的准确率分别为-1.83,0.6,3.0;在Resnet20,Cifar100的实验中则更明显,提高的准确率分别为-0.51,2.13,8.67.根据原文中的分析,该方法对参数λ的设置比较敏感,而其给出的方法式(6)启发式地根据模型在干净数据和噪声数据上的准确率进行设置,可能并不是最优的.可以发现在不同噪声水平时,根据式(6)求得的λ比较接近,例如在Resnet20,Cifar10的实验中λ分别为0.52,0.52,0.51,而该值对于噪声水平较低的情况可能过低,使得方法过分相信Clean Only的结果,反而没有充分利用噪声水平较低的大量数据,从而降低了模型的性能;而当噪声水平较高时,λ的值比较合适,从而明显提高了性能. 3) Loss Correction方法对性能的提升相对前2种方法更稳定,在Cifar10上提升明显,但在Cifar100上仅有微弱的提升.例如在Resnet20实验中,Cifar10上分别提升了1.83,1.81,4.96,而Cifar100上只提升了0.57,1.05,1.78.这个现象和原文中一致,其原因在于该方法的提升依赖于准确估计混淆矩阵T,而对Cifar100的估计效果较差.Cifar100的类别数是Cifar10的10倍,因此需要估计的混淆矩阵参数量是Cifar10的100倍,而2个数据集的图片数量相同,造成估计Cifar100的混淆矩阵更困难. 4) 我们的方法在不同数据集、网络结构和噪声水平下,准确率均高于其他3种方法.Complementary Learning在结合了OEEM和Distillation方法优势的同时改进了2种方法的缺点,相比于2种方法均有明显的提升.可以看到在所有Cifar10的实验中,Complementary Learning比OEEM和Distillation方法最少提升了0.83,最多提升了2.02;在Cifar100的实验中最少提升了1.43,最多提升了7.36.Complementary Learning方法在Cifar10上效果与Loss Correction方法接近,但在Cifar100上明显效果更好. 通过上述实验结果,可以发现我们提出的Complementary Learning方法有2点优势: 1) 与OEEM方法相比,我们的方法在样本选择过程中利用2个模型互相提供辅助信息,从而降低了样本选择与单个模型的相关性,降低了模型陷入局部最优解的可能.与Distillation方法相比,我们的方法中辅助模型不断通过保守的策略选择样本进行学习,在尽量保持自身干净的同时不断提升,从而能给主模型提供更多信息. 2) 与Loss Correction方法相比,我们的方法不依赖于对噪声分布的假设,例如不需要估计混淆矩阵(也不假设噪声数据可以通过混淆矩阵建模),因此可以更好地适应复杂的噪声数据.在Cifar100上的实验验证了这一点. Table 1 Accuracy of Different Methods on Cifar10 and Cifar100表1 Cifar10和Cifar100上不同方法的结果 Note: The top 2 accuracies of each row is shown in bold. 3.3.2 真实噪声数据Clothing1M实验 我们在真实噪声数据Clothing1M数据集上验证Complementary Learning方法.Clothing1M有14类,包含近1 000 000张带噪声的训练图片、50 000张人工标注过的干净数据和14 000张验证集、10 000张测试集.原文中利用期望最大化算法同时训练了2个AlexNet[2],并额外利用干净数据进行了bootstrapping过程.Loss Correction方法也在该数据集上进行了测试,使用了Resnet50网络结构.我们同样选择Resnet50网络并采用相同的数据增强方法. 我们用Resnet50分别在干净数据和噪声数据上训练得到2个网络F1,F2,并用这2个网络作为初始化进行互补学习,实验结果如表2所示: Table 2 Accuracy of Different Methods on Clothing1M表2 Clothing1M上不同方法的结果 OEEM方法和Distillation方法均比仅在噪声数据上训练有所提升,其中利用了干净数据的Distillation方法提升更显著.Loss Correction方法#7相对于在噪声数据上训练的#4仅提升了0.9,之后又以#7作为初始化在干净数据上微调达到了80.38.而我们的Complementary Learning方法则利用#3,#4作为初始化,直接达到了81.20,不需要额外的微调过程. 在如今的图像应用中,数据规模不断增大,标注成本不断提高,如何有效利用大量容易获得的噪声数据是十分有价值的问题.对此本文提出了一种称为互补学习的方法,结合简单样本挖掘与迁移学习的思想,用不同的策略同时训练2个网络,让2个网络在保持互补特性的情况下互相提升,从而充分利用噪声数据进行训练.在人工生成的噪声数据(Cifar10,Cifar100)和大规模真实噪声数据(Clothing1M)上的实验表明该方法可以较好地适应不同的数据和噪声规模,并能显著提升模型在噪声数据上的准确率,与现有方法相比有一定优势,有较强的应用价值. [1]Deng Jia, Dong Wei, Socher R, et al. Imagenet: A large-scale hierarchical image database[C] //Proc of the 22nd IEEE Conf on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2009: 248-255 [2] Krizhevsky A, Sutskever I, Hinton G E. Imagenet classification with deep convolutional neural networks[G] //Advances in Neural Information Processing Systems 25 (NIPS 2012). La Jolla, CA: The NIPS Foundation, 2012: 1097-1105 [3] Girshick R, Donahue J, Darrell T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C] //Proc of the 27th IEEE Conf on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2014: 580-587 [4] He Kaiming, Zhang Xiangyu, Ren Shaoqing, et al. Deep residual learning for image recognition[C] //Proc of the 29th IEEE Conf on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2016: 770-778 [5] Xiao Tong, Xia Tian, Yang Yi, et al. Learning from massive noisy labeled data for image classification[C] //Proc of the IEEE Conf on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2015: 2691-2699 [6] Nettleton D F, Orriols-Puig A, Fornells A. A study of the effect of different types of noise on the precision of supervised learning techniques[J]. Artificial Intelligence Review, 2010, 33(4): 275-306 [7] Shrivastava A, Gupta A, Girshick R. Training region-based object detectors with online hard example mining[C] //Proc of the 29th IEEE Conf on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2016: 761-769 [8] Li Yucheng, Yang Jianchao, Song Yale, et al. Learning from noisy labels with distillation[OL]. [2017-11-08]. https://arxiv.org/abs/1703.02391 [9] Hinton G, Vinyals O, Dean J. Distilling the knowledge in a neural network[OL]. [2017-11-08]. https://arxiv.org/abs/1503.02531 [10] Frénay B, Verleysen M. Classification in the presence of label noise: A survey[J]. IEEE Trans on Neural Networks and Learning Systems, 2014, 25(5): 845-869 [11] Reed S, Lee H, Anguelov D, et al. Training deep neural networks on noisy labels with bootstrapping[OL]. [2017-11-08]. https://arxiv.org/abs/1412.6596 [12] Liu Tongliang, Tao Dacheng. Classification with noisy labels by importance reweighting[J]. IEEE Trans on Pattern Analysis and Machine Intelligence, 2016, 38(3): 447-461 [13] Natarajan N, Dhillon I S, Ravikumar P K, et al. Learning with noisy labels[G] //Advances in Neural Information Processing Systems 26 (NIPS 2013). La Jolla, CA: The NIPS Foundation, 2013: 1196-1204 [14] Sukhbaatar S, Fergus R. Training Convolutional Networks with Noisy Labels[OL]. [2017-11-08]. https://arxiv.org/abs/1406.2080 [15] Szegedy C, Vanhoucke V, Ioffe S, et al. Rethinking the inception architecture for computer vision[C] //Proc of the 29th IEEE Conf on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2016: 2818-2826 [16] Patrini G, Rozza A, Menon A K, et al. Making deep neural networks robust to label noise: A loss correction approach[C] //Proc of the 30th IEEE Conf on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2017: 1944-1952 [17] Menon A, Rooyen B V, Ong C S, et al. Learning from corrupted binary labels via class-probability estimation[C] //Proc of the 32nd Int Conf on Machine Learning. New York: ACM, 2015: 125-134 [18] Zhu Xiaojin, Ghahramani Z. Learning from labeled and unlabeled data with label propagation, CMU-CS-03-175[R]. Pittsburgh, PA: Carnegie Mellon University, 2002 [19] She Qiaoqiao, Yu Yang, Jiang Yuan, et al. Large-scale image annotation via random forest based label propagation[J]. Journal of Computer Research and Development, 2012, 49(11): 2289-2295 (in Chinese)(佘俏俏, 俞扬, 姜远, 等. 一种基于标记传播的大规模图像分类方法[J]. 计算机研究与发展, 2012, 49(11): 2289-2295) [20] Veit A, Alldrin N, Chechik G, et al. Learning from noisy large-scale datasets with minimal supervision[C] //Proc of the 30th IEEE Conf on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2017: 839-847 [21] Felzenszwalb P F, Girshick R B, McAllester D, et al. Object detection with discriminatively trained part-based models[J]. IEEE Trans on Pattern Analysis and Machine Intelligence, 2010, 32(9): 1627-1645 [22] Abadi M, Barham P, Chen Jianmin, et al. TensorFlow: A system for large-scale machine learning[C] //Proc of the USENIX Symp on Operating Systems Design and Imple-mentation. Berkeley, CA: USENIX Association, 2016, 16: 265-283 [23] Krizhevsky A, Hinton G. Learning multiple layers of features from tiny images[D]. Toronto, Canada: Department of Computer Science, University of Toronto, 2009 TrainingDeepNeuralNetworksforImageApplicationswithNoisyLabelsbyComplementaryLearning Zhou Yucong, Liu Yi, and Wang Rui (Sino-GermanJointSoftwareInstitute,BeihangUniversity,Beijing100191) In recent years, deep neural networks (DNNs) have made great progress in many fields such as image recognition, speech recognition and natural language processing, etc. The rapid development of the Internet and mobile devices promotes the popularity of image applications and provides a large amount of data to be used for training DNNs. Also, the manually annotated data is the key of training DNNs. However, with the rapid growth of data scale, the cost of manual annotation is getting higher and the quality is hard to be guaranteed, which will damage the performance of DNNs. Combining the idea of easy example mining and transfer learning, we propose a method called complementary learning to train DNNs on large-scale noisy labels for image applications. With a small number of clean labels and a large number of noisy labels, we jointly train two DNNs with complementary strategies and meanwhile transfer the knowledge from the auxiliary model to the main model. Through experiments we show that this method can efficiently train DNNs on noisy labels. Compared with current approaches, this method can handle more complicated noise labels, which demonstrates its value for image applications. deep neural networks (DNNs); image applications; noisy labels; easy example mining; transfer learning 2017-09-01; 2017-10-17 国家重点研发计划项目(2016YFB0200100);国家自然科学基金项目(61732002) This work was supported by the National Key Research and Development Program of China (2016YFB0200100) and the National Natural Science Foundation of China (61732002). TP1830 ZhouYucong, born in 1993. Master candidate. His main research interests include computer vision and machine learning. LiuYi, born in 1968. Professor of Beihang University since 2006, and associate professor of Xi’an Jiaotong University from 2001 to 2006. Received his PhD degree in computer science from Xi’an Jiaotong University. His main research interests include high-perfor-mance computing and computer architecture. WangRui, born in 1978. PhD, asistant professor in the School of Computer Science and Engineering, Beihang University. His main research interests include computer architecture and parallel programming.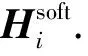
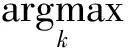
3 实 验
3.1 实验设置
3.2 OEEM和互补学习方法的参数设置策略
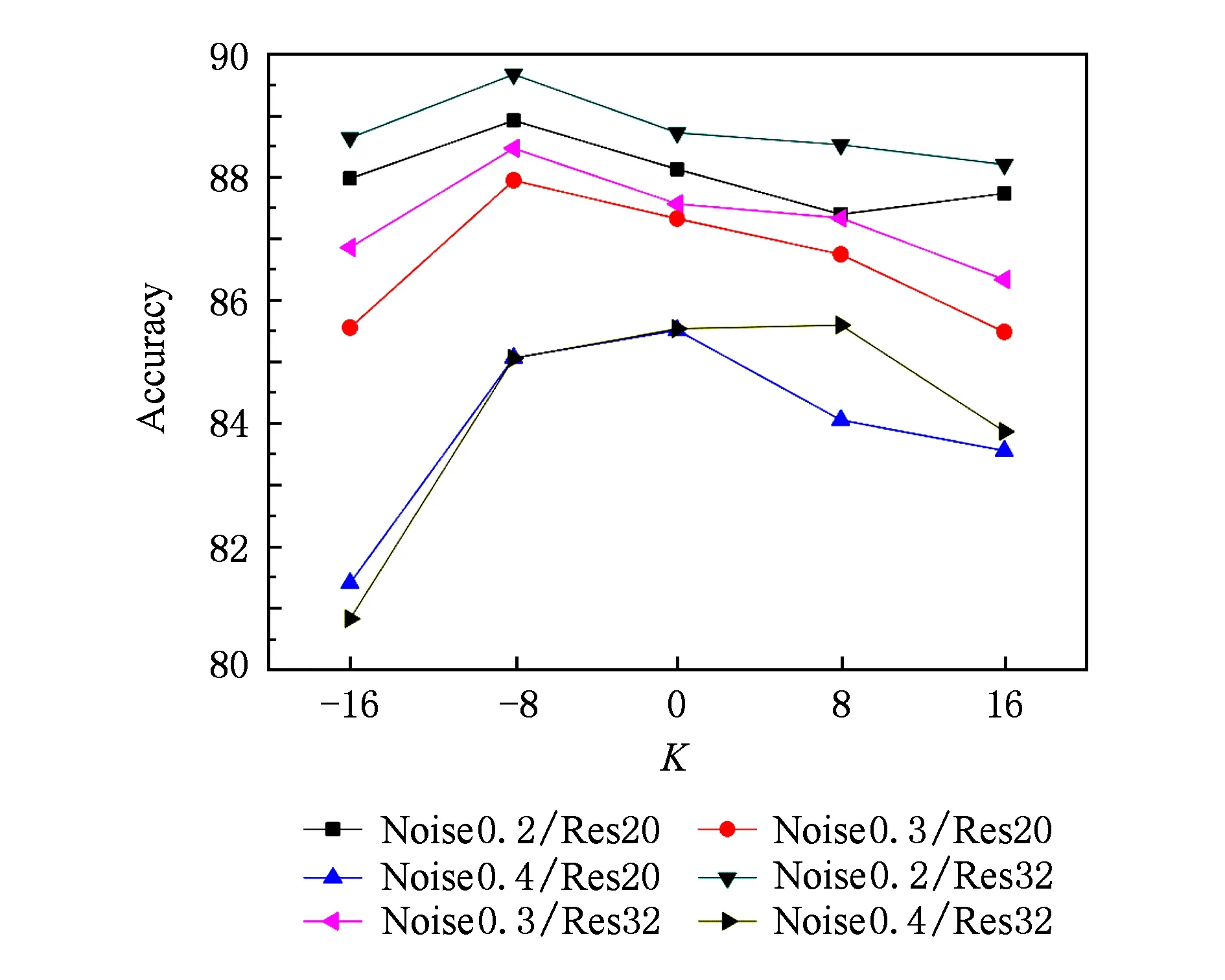
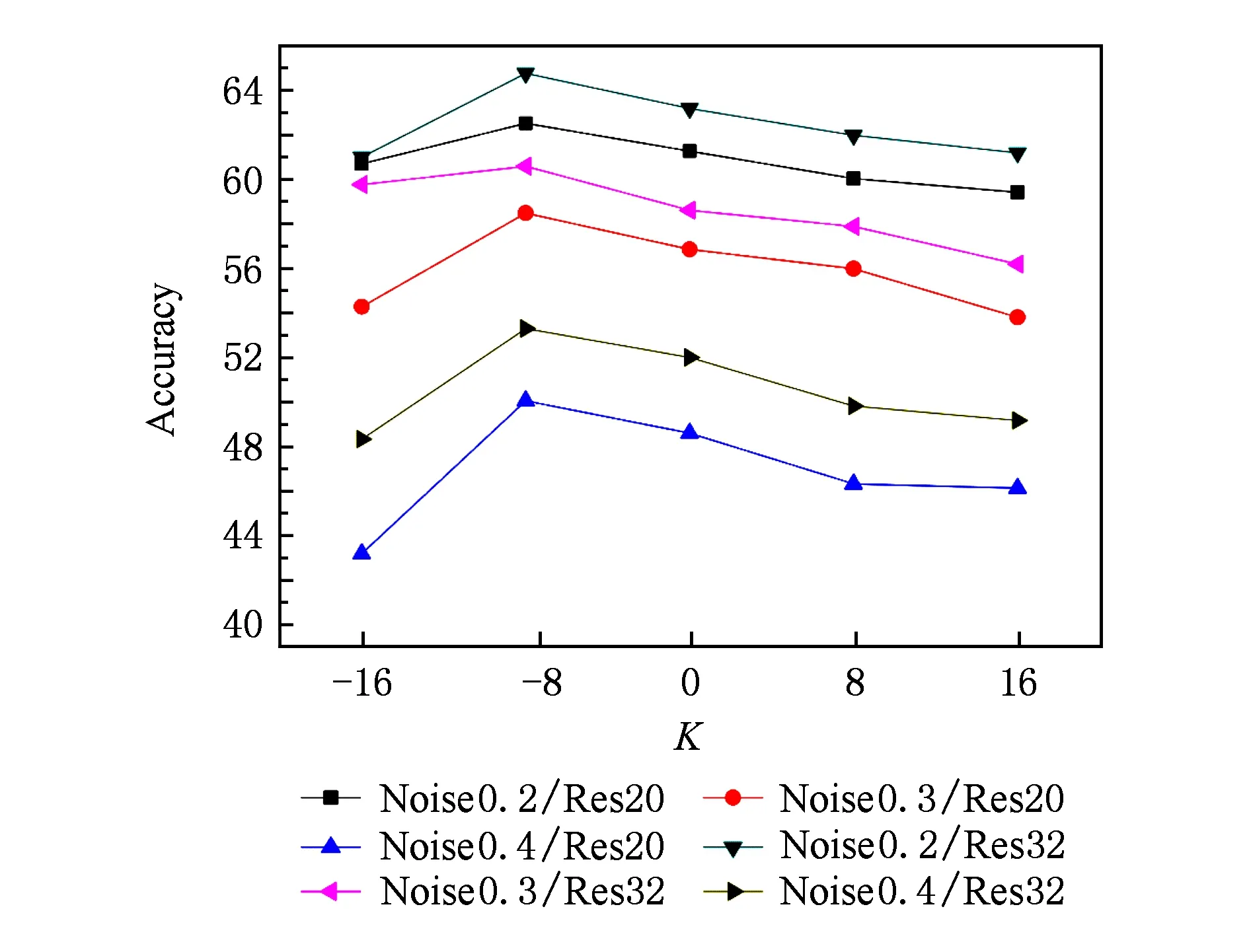
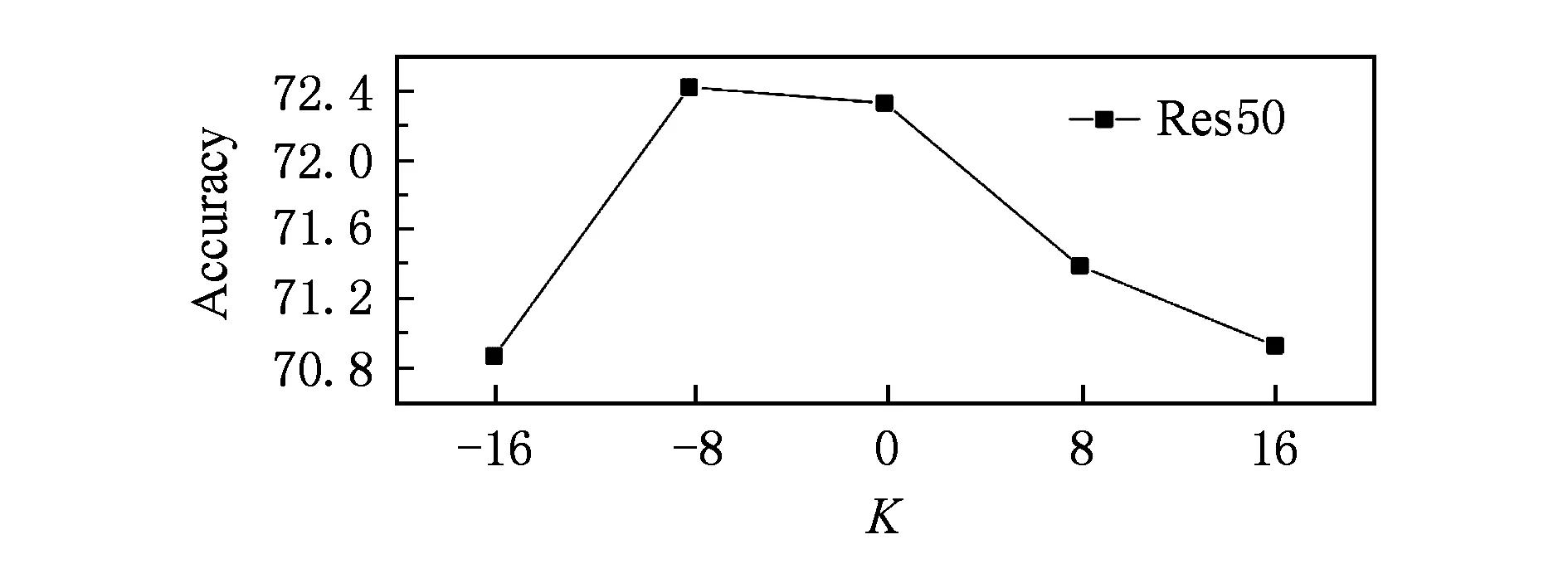
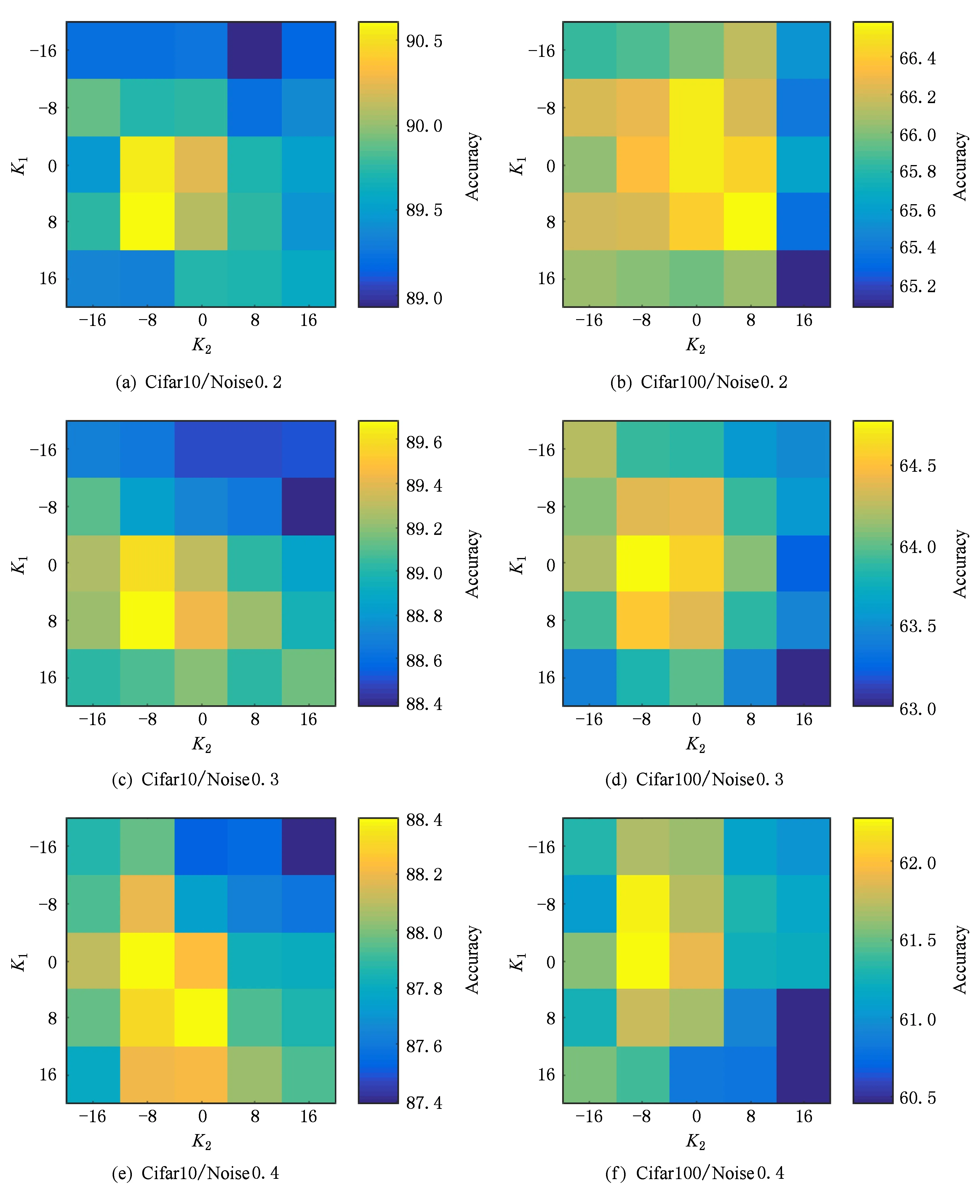
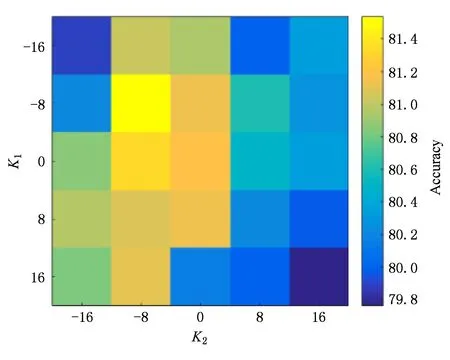
3.3 实验结果与分析
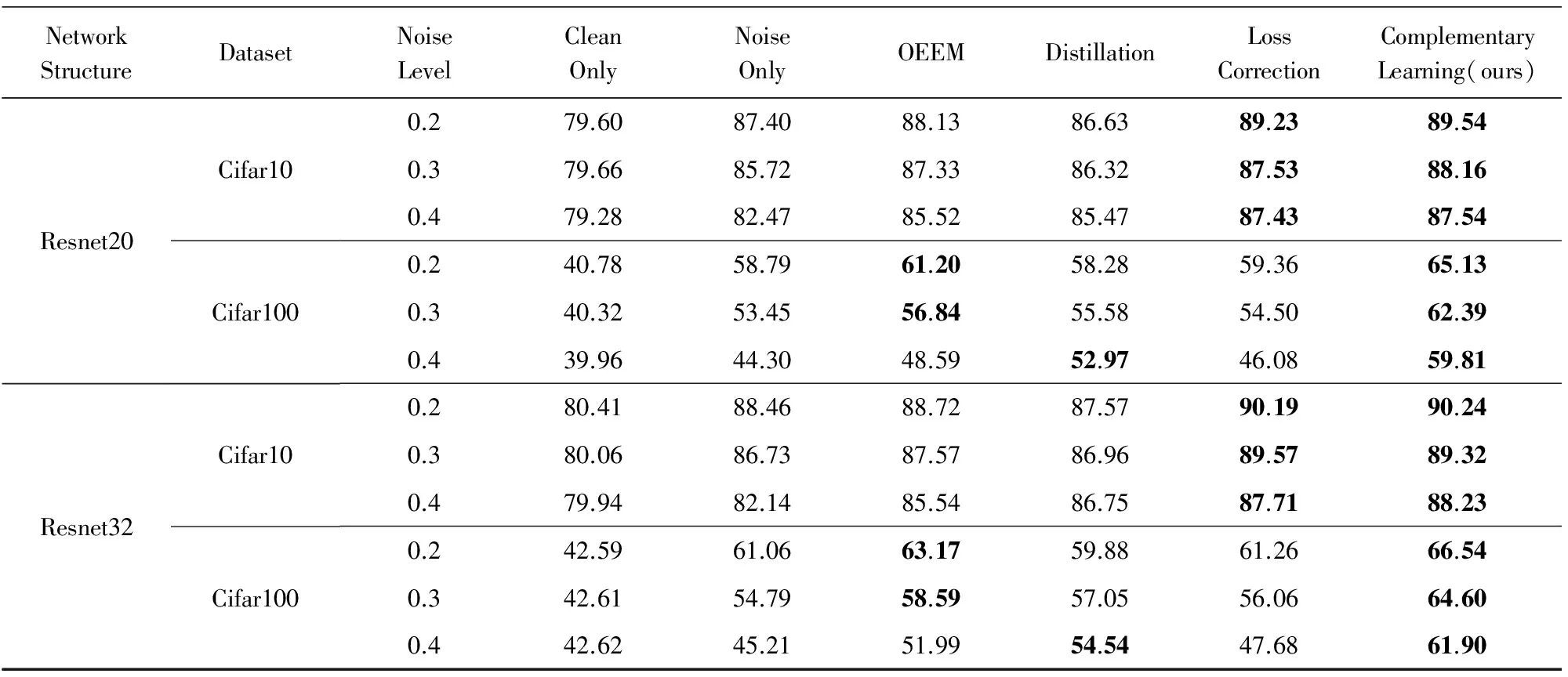
4 结 论



猜你喜欢
舰船科学技术(2022年21期)2022-12-12
电子技术与软件工程(2022年15期)2022-11-11
现代电力(2022年2期)2022-05-23
小型微型计算机系统(2022年4期)2022-05-09
电子制作(2019年19期)2019-11-23
劳动保护(2019年3期)2019-05-16
电子制作(2019年24期)2019-02-23
计算机应用(2018年5期)2018-07-25
北京航空航天大学学报(2017年12期)2017-04-23
中国科技纵横(2016年20期)2016-12-28
