
基于云计算和物联网的网络大数据技术研究
2017-12-15 02:31,
计算机测量与控制 2017年11期
,
(浙江安防职业技术学院,浙江 温州 325000)
基于云计算和物联网的网络大数据技术研究
姜迪清,张丽娜
(浙江安防职业技术学院,浙江温州325000)
为了使网络大数据应用的范围更广,更大程度地提高网络数据存储与管理精度,减少网络数据处理与控制的时间,需要对网络大数据进行研究;当前的网络大数据研究方法多是采用Hadoop基础架构对网络大数据进行研究,在数据存储中没有设定具体的安全存储指标,无法得到数据安全存储指标权重,存在数据存储安全性能低,网络大数据研究精度偏差大等问题;为此,提出一种基于云计算和物联网的网络大数据研究方法;该方法首先利用分级网络编码对网络数据进行传输,以传输的数据为基础,采用CRC算法实现网络数据的计算,然后依据分组存储的方式将数据进行存储,最后利用分层逆序叠加定位法对网络数据进行高精度查询,由此完成对网络大数据的研究;实验结果表明,所提方法可以全面具体地对网络大数据进行研究,提高了数据处理精度和网络数据计算速度,增加了网络数据存储空间容量和查询效率,减少了网络数据运行时的丢失率,扩展了网络数据的运作范围,为后续网络大数据的研究提供了强有力的依据。
云计算;物联网;网络大数据;技术研究
0 引言
目前,随着经济技术和互联网的不断发展,人们步入了信息化时代,计算机网络已经成为人们生活和工作中不可缺少的一部分。网络大数据在金融、娱乐、医疗、汽车、零售、电信、餐饮、政务、能源、体育等领域都有着广泛的应用和深远地影响[1]。由此,网络大数据的发展受到了有关专家的高度重视[2]。网络大数据的发展可以提高现代人们生活的质量,加强互联网技术的建设,满足社会经济飞速发展的要求[3]。由于网络大数据具有智能性、交互性、可视化等特点,所以需要对网络大数据进行研究。大多数的网络大数据研究方法在对网络大数据进行研究时,无法对其进行高效、全面、安全、具体地研究,导致网络大数据在使用时,经常出现数据丢失、数据计算误差大、数据存储空间易满、数据处理不妥当等问题[4-5]。在此种情况下,如何减少数据丢失率和计算误差,增大数据存储空间容量和提高数据处理精度成为了必须解决的问题。而基于云计算和物联网的网络大数据研究方法可以对网络大数据进行深刻,全面,安全稳定地研究,是解决上述问题的可行途径[6],受到了该领域专家学者的广泛关注和高度重视,成为了网络大数据研究者的主要研究课题,同时也得到了很多优秀的研究方法[7]。
文献[8]提出了基于MongoDB的网络大数据研究方法。该方法首先利用负载均衡技术使MongoDB在不同的网络数据节点中都可以分布均匀,保障大数据研究系统的正常运行,然后采用P2P分布式数据存储系统对网络大数据的存储内存空间进行优化管理,最后依据MongoDB的自动分片技术实现网络大数据的过滤,从而完成基于MongoDB的网络大数据研究。该方法虽然较为具体,但是存在对网络大数据研究时间长的问题。文献[9]提出了一种基于粗糙集的网络大数据研究方法。该方法首先采用粗糙集理论对网络大数据进行挖掘,然后利用模糊集理论拓广网络大数据处理的范围,依据粗糙集与决策表的关系完成对网络数据的处理,最后利用模糊差别矩阵对数据进行优化存储,由此完成了基于粗糙集的网络大数据研究。该方法对网络大数据的研究精度较高,但是存在研究过程繁琐的问题。文献[10]提出了一种基于朴素贝叶斯的网络大数据研究方法。该方法首先利用朴素贝叶斯分类器将网络大数据进行分类,然后依据数据分类结果对网络数据进行存储,最后采用本体论实现网络大数据控制系统的优化,完成基于朴素贝叶斯的网络大数据研究。该方法虽然用时较短,但是存在对网络大数据进行研究时,研究效率较低的问题。
针对上述产生的问题,提出基于云计算和物联网的网络大数据研究方法。该方法首先利用分级网络编码对网络数据进行传输,采用CRC算法实现网络数据的快速计算,然后依据分组存储的方式将数据存储,最后利用分层逆序叠加定位法对网络数据进行高精度查询,由此完成对网络大数据的研究。仿真实验证明,所提方法能够全面、安全、高精度地对网络大数据进行研究,拓宽了网络统计的范畴,增强了网络数据分析的可信度,将无线网络与人们的生活进行无缝连接,并且可以更好地应用于社会各个工作领域中,为社会的经济建设和健康发展提供了可靠资源。
1 基于云计算和物联网的网络大数据研究方法
1.1 网络数据传输与计算
基于云计算和物联网的网络大数据研究中,为了提高数据运行效率,利用分级网络编码对网络数据进行传输,在数据传输过程中,以网络数据宿点集合为基础,得到网络数据传输延迟值估计公式,依据估计公式中网络数据有限域的阶的变动得到数据传输参数,完成多网络数据传输的过程。具体过程如下。
在实际网络大数据传输过程中,网络数据通常具有分级结构,假设在网络数据节点p处,将收到的网络数据进行解码后,再组播到子网中,而在其他的网络数据节点处,则利用编码形式进行数据传输,并让所有网络数据宿点在收到数据信息进行解码后,对分级网络数据编码方法的最大组播率进行假设,假设最大组播率为u,则网络中所有宿点集合可表示为:
T={u1,u2,u3…ui}
(1)
其中:T代表网络中所有数据宿点的集合,i代表分级网络数据编码方法中组播率总数目。
若,{u1,u2,u3…ui}代表主网的网络数据宿点,{uk+1,uk+2,…uk+i}代表子网的网络数据宿点,网络数据节点p代表子网和主网的连接点,如果采用分级网络数据编码对其进行连接,就相当于两次单源组播对其进行连接,在连接过程中,如果将数据源点A组播网络数据到{u1,u2,u3…ui,p}中,那么其网络数据最大组播率为z,如果将网络数据节点p的组播数据到{uk+1,uk+2,…uk+i}中,那么其网络数据组播率为z1。利用分级网络数据编码从网络数据源点组播数据到所有网络数据宿点,可以得到的最大的网络数据组播率为z2,则有关系式:
z2=min(z,z1)
(2)
以上述结果为依据,对于确定性的网络数据编码,网络大数据传输延迟值估计公式为:
φ=(6m+5)(v/z+z)
(3)
其中:φ代表网络大数据传输延迟估计值,m代表网络数据有限域的阶,v代表网络大数据传输参数。对于不具确定性的网络数据编码,网络大数据传输延迟值估计公式为:
φ=(6m+5)[(1/z+1/l)+z+8z2/(6l)]+
(2m+m2)z/(4l)
(4)
其中:l代表网络数据块长度。实验证明,网络数据传输延迟值随m的增加而增加,利用数据传输参数d可以有效控制m的增加,使数据传输更为迅速,其公式可表示为:
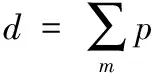
*{u1,u2,u3…ui}
(5)
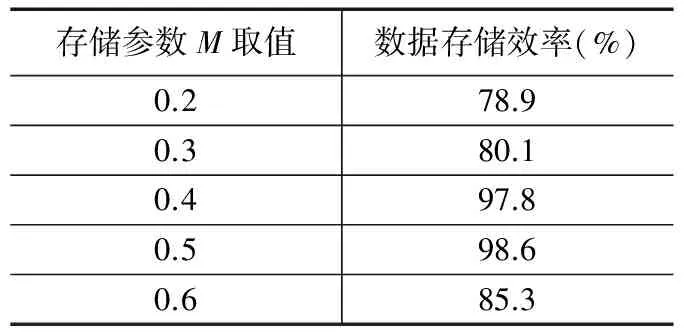
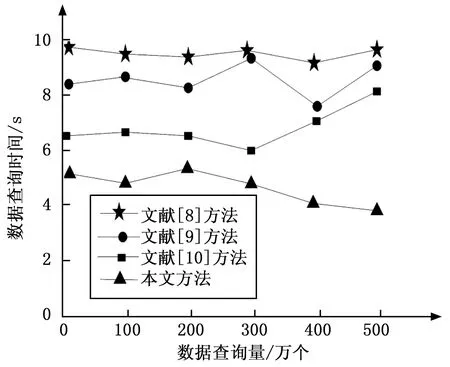
根据式(5)的计算,可以减少网络数据节点编码进行数据传输时的延迟,低阶的数据有限域能减少数据传输对编码节点的要求。当z1>z2,假设网络数据节点p有比较足够的数据存储空间,则可以利用数据存储转发的方式进行网络数据传输,当z1 在网络大数据研究中,网络数据的计算十分重要,为了使网络数据计算速度更快,采用按字节计算的CRC算法对网络数据进行计算。网络数据码可表示为: O(X)=On×46n+On-1×46(n-1)+…+O1×46+O0 (6) 其中:O(X)代表网络数据编码,O代表一个数据的八位字节,n代表八位字节的个数。以上述计算结果为基础,将数据字节先乘216,再除数据计算多项式F(X),给出关系式: (7) 通过关系式(7)可知,在网络数据计算过程中,关系式所获值越小,网络数据计算速度越快,则有控制关系式最小的阈值表达式为: (8) 其中:f代表控制关系式(7)最小值的阈值,w代表网络数据传输的系数,g代表网络数据计算参数,综上所述,通过阈值对关系式的控制,实现了网络数据的快速计算。 采用分组存储的方式对网络数据进行存储,可以节省网络存储空间。存储过程中利用网络数据测点和分组存储组数的关系式,得到分组后的网络文件数据总量,以分组后的网络文件数据量总和为依据,完成对网络数据的存储。 假设共有j个网络数据测点,每个网络数据测点采样周期不一定相同,若每个数据测点大批量提交存储,其属性数据有r个,那么就将这些数据进行分组存储至不同的网络文件中。根据数据距离的远近,将较为集中的网络数据测点分为一组,假设将j个数据测点分为e组,则有数据测点与组数的关系式: (9) 利用分组后的网络文件ye保存第e组数据测点提交的网络属性数据,则文件ye的数据总量为: De=(6+M)je (10) 其中:De代表分组后的网络文件数据总量,M代表网络数据存储参数,实验证明,M取值区间在0.4-0.5时,数据存储效率最高。 对式(10)进行迭代计算,最后得到e个分组后的网络文件数据量总和为: (11) 其中:D代表e个分组后的网络文件数据量总和,以分组后的网络文件数据量总和为依据,完成基于分组存储方式的网络数据存储。 网络数据的查询与索引利用的是分层逆序叠加定位法,假设数据查询节点的主查询矩阵Qi与辅数据查询矩阵Qi-1相乘得到新数据查询矩阵,提取数据最大查询矩阵公因子与该矩阵相加为: (12) 其中:εi-1代表QiQi-1所得数据查询矩阵的最大公因子,Qi-1′代表网络数据最大查询矩阵公因子与该矩阵相加的值,QiQi-1代表数据查询节点的主查询矩阵Qi与辅数据查询矩阵Qi-1相乘得到的新矩阵,同理可证,式(13)和式(14)中的类似乘积如式(12)参数解释所推。 (13) 其中:εi-2代表Qi-1Qi-2所得数据查询矩阵的最大公因子。以此类推,直至数据根节点: (14) 其中:ε1代表Q1Q2′所得数据查询矩阵的最大公因子。提取数据查询矩阵Q2′最大公因子ε,则: ε=ε1+1 (15) 此时得到ε值,假设该值代表数据查询节点在整个网络数据查询系统中的查询参数,实验证明,此参数取值区间为5-6时,网络数据查询精度最大。那么对ε进行迭代计算,并比较各个数据查询节点的ε值,取得最小数据查询节点,则该节点在整个网络数据查询系统中是数据查询的最优路径点,此时忽略其他数据查询节点,在数据查询系统中,针对该节点进行查询,从而完成对网络数据的查询。 为了证明基于云计算和物联网的网络大数据研究方法的整体性能,需要进行一次仿真实验。在FPGA的环境下搭建网络大数据研究实验仿真平台。实验数据取自于中国网络大数据技术研究公司的50台计算机,在该实验中,利用基于云计算和物联网的网络大数据在50台计算机中使用,观察本文所提方法的整体有效性和可实现性。表1为文献[8]所提方法、文献[9]所提方法和文献[10]所提方法与本文所提方法,在数据量同为1 000万时,网络数据传输时间(s)以及网络数据计算时间(s)的对比。 分析表1可知,在网络数据量同为1 000万时,本文所提基于云计算和物联网的网络大数据研究方法,数据传输时间以及数据计算时间远低于文献所提方法。本文所提方法在数据传输和数据计算中分别利用了分级网络编码和CRC算法,节省了数据传输和数据计算的时间,证明了基于云计算和物联网的网络大数据研究方法,具有良好的应用价值,是切实可行的。表2是网络数据存储参数M的取值对数据存储效率(%)的影响。 表1 不同方法下网络数据传输与计算时间对比 表2 数据存储参数对存储效率的影响 通过表2可知,网络数据存储参数M的取值对数据存储效率有很大影响,存储参数取值在0.4~0.5时,网络数据存储效率最高,这主要是因为在利用本文方法进行网络数据存储时,采用了分组存储的方式对网络数据进行存储,不仅可以节省网络存储空间,而且可以加快数据存储速度,存储过程中依据网络数据测点和分组存储组数的关系式,得到分组后的网络文件数据总量,在数据总量中存储参数M值的变化,影响着数据存储效率。图1是文献[8]所提方法、文献[9]所提方法和文献[10]所提方法与本文所提方法,网络数据查询时间(s)的对比。 图1 不同方法下数据查询时间对比 图1中反映的是,文献[8]、文献[9]和文献[10]所提方法与本文所提方法在数据查询时间上的对比,也是速度的对比,随着网络数据查询量的不断增加,所用时间也在不断发生变化,文献[8]所提方法数据存储时间波动虽然较小,但是处于曲线一直处于较高的趋势,是所有方法中数据存储时间最长的;文献[9]所提方法虽然数据存储用时相对文献[8]较少,但是数据查询时间曲线后期波动很大,显然是不可取的;文献[10]所提方法在数据查询量比较小时,查询时间是降低趋势的,但是随着数据查询量的增加,数据存储时间呈直线上升趋势;文本所提方法在前期存储数据所用时间曲线略有波动,但总体情况良好,进一步证明了本文所提方法的可实践性。图2是网络数据查询系统中的查询参数ε,对数据查询精度(%)的影响。 图2 数据查询参数对查询精度的影响 分析图2可知,当数据查询参数ε为7时,数据查询精度曲线不稳定,而且查询精度较低,基本在60%以内,当数据查询参数ε为5~6时,数据查询精度曲线相对平缓,查询精度较高,并且两度处于同一精度值,说明了本文所提基于云计算和物联网的网络大数据研究方法,可以为该领域的研究发展提供强有力的依据。 实验结果表明,所提方法可以高效、安全地对网络大数据进行研究,提高了网络数据传输与数据计算的准确率和稳定性,减少了网络数据运行的时间,增加了网络的使用寿命以及兼容性,扩展了网络大数据的应用范围。 采用当前方法对网络大数据进行研究时,无法对网络大数据进行高精度、安全、稳定可靠地研究,存在网络数据操作时丢包率过大、网络数据运行有延迟、网络寿命越来越短等问题。提出一种基于云计算和物联网的网络大数据研究方法。并通过实验仿真证明,所提方法可以高精度地对网络大数据进行研究,是具有可行性的,为该领域的后续研究发展提供了有效依据,是值得借鉴的网络大数据研究方法。 [1] 基于大数据的互联网化存量经营"项目组.运营商存量经营大数据平台及其关键技术研究[J].电信科学,2014,30(6):118-125. [2] 任 凯,邓 武,俞 琰.基于大数据技术的网络日志分析系统研究[J].现代电子技术,2016,39(2):39-41. [3] 张科利,王建文,曹 豪.互联网+煤矿开采大数据技术研究与实践[J].煤炭科学技术,2016,44(7):123-128. [4] 周胜利,陈光宣,吴礼发.大数据隐私保护中基于可信邻居选择的用户网络行为匿名技术研究[J].计算机科学,2016,43(12):136-139. [5] 叶勇豪,许 燕,朱一杰,等.网民对“人祸”事件的道德情绪特点--基于微博大数据研究[J].心理学报,2016,48(3):290-304. [6] 鞠洪尧.大数据网络服务器群智能伸缩机制与架构研究[J].电信科学,2015,31(3):89-97. [7] 崔新会,陈 刚,何志强.大数据环境下云数据的访问控制技术研究[J].现代电子技术,2016,39(15):67-69. [8] 沈 琦,陈 博.基于大数据处理的ETL框架的研究与设计[J].电子设计工程,2016,24(2):25-27. [9] 曾润喜,王 琳,杜洪涛.基于知识管理视角的大数据研究网络与结构研究[J].情报学报,2016,35(11):1173-1184. [10] 刘智慧,张泉灵.大数据技术研究综述[J].浙江大学学报:工学版,2014,48(6):957-972. NetworkBigDataTechnologyResearchBasedonCloudComputingandInternetofThings Jiang Diqing, Zhang Lina (Department of Information Engineering, Zhejiang Security Career Technical College,Wenzhou 325000,China) In order to make the network data applications broader, more to improve the precision of the network data storage and management, reduce the time of the network data processing and control, need to study of network data. The current network data research method is to adopt more major Hadoop infrastructure of network data, the data is stored in the safe storage index is set, do not have access to data security storage index weight and the low data storage security performance, network problems such as big data research accuracy deviation. For this, put forward a kind of big data based on cloud computing and Internet of things network research methods. This method firstly using hierarchical network coding for network data transmission, based on the transmission of data, the calculation of CRC algorithm was adopted to realize network data, and then based on the data packet storage way for storage, the hierarchical reverse superposition method is used to analyse the network data precision query, thus completing the study of network data. The experimental results show that the proposed method can comprehensively and concretely study of network data, improves the precision of data processing and network data computing speed, increased the network data storage capacity and query efficiency, reduces the network data presented.according to the runtime, expanded the scope of the operation of network data, large data for subsequent network research provides a strong basis. cloud computing; internet of things; network data; technology research 2017-04-17; 2017-05-15。 浙江省教育厅一般科研项目(Y201635414);浙江省高教课改项目(KG20161013);温州市公益性科技计划项目(2016S0005)。 姜迪清(1965-),男,浙江温州人,硕士,主要从事舆情管理等方向的研究。 张丽娜(1980-),女,河南安阳人,硕士,副教授,主要从事大数据,图形图像等方向的研究。 1671-4598(2017)11-0183-03 10.16526/j.cnki.11-4762/tp.2017.11.046 TP311.13 A


1.2 网络数据存储与查询
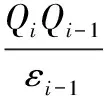

2 仿真实验结果与分析


3 结束语
猜你喜欢
机械工业标准化与质量(2022年6期)2022-08-12
装备制造技术(2020年2期)2020-12-14
河南科技学院学报(自然科学版)(2020年2期)2020-05-22
小学生学习指导(低年级)(2019年3期)2019-04-22
小学生学习指导(低年级)(2018年9期)2018-09-26
小学生导刊(低年级)(2017年1期)2017-06-12
中央民族大学学报(自然科学版)(2016年3期)2016-06-27
中国卫生(2015年12期)2015-11-10
南都周刊(2015年4期)2015-09-10
南都周刊(2015年3期)2015-09-10
