
基于I-Vector的多核学习SVM的说话人确认系统
2017-12-01 06:51龚铖,琚炜
网络安全与数据管理 2017年22期
龚 铖,琚 炜
(中国科学技术大学 信息科学技术学院,安徽 合肥 230026)
基于I-Vector的多核学习SVM的说话人确认系统
龚 铖,琚 炜
(中国科学技术大学 信息科学技术学院,安徽 合肥230026)
自I-Vector(身份认证矢量)被提出以来,基于I-Vector的说话人确认系统迅速取代了基于GMM超矢量的系统并开始流行。I-Vector-SVM系统作为其中之一,在通常训练样本较少的说话人确认领域有着独特的优势,但其性能受核函数影响较大。因此,基于多核学习(MultipleKernelLearning,MKL)思想,构建了基于I-Vector的多核学习SVM说话人确认系统,并与I-Vector-SVM基线系统进行了性能比较。基于NIST语料库的实验表明,基于I-Vector的多核学习说话人确认系统相对于基线系统可取得一定的性能提升。
说话人确认;多核学习SVM;I-Vector
0 引言
说话人确认是说话人识别的一个重要的研究方向,已经在相当广泛的领域内发挥出重要的作用。近年来,基于由传统高斯混合模型-通用背景模型(GMM-UBM)发展而来的全局差异空间(Total Variability space,TV)的I-Vector说话人确认系统逐渐成为研究的主流方向。相比传统的高达数千维的GMM-UBM超矢量,I-Vector是从说话人声道特征中提取的一种低维的特征矢量,可直接作为说话人的身份矢量,具有良好的区分性。因此,对I-Vector直接进行余弦评分,以及在I-Vector基础上使用传统的建模分类技术,如SVM,DNN等,构成了目前流行的说话人确认技术。
自文献[1]首次提出SVM以来,其迅速成为模式识别领域的一大重要工具,也在说话人识别领域得到了广泛的应用。文献[2]使用SVM对说话人的GMM-UBM超矢量进行分类,取得了良好的分类效果。随着I-Vector的提出,在文献[3]中,DEHAK N等首次利用SVM对说话人的I-Vector建模,构建了区分性模型,性能相对前者有了较大提升。文献[4]在此基础上,分析了多种不同的核函数对I-Vector-SVM说话人识别系统性能的影响,也揭示了单核函数SVM性能的不稳定。
随着技术进步,单核函数SVM由于性能受核函数影响较大,基于多核学习思想(Multiple Kernel Learning)的多核函数SVM逐渐得到重视和研究。BACH F R等人在文献[5]中首次提出了多核学习SVM(Multiple Kernel Learning-SVM,MKL-SVM)的概念,即将单核核函数用一组使用权值控制的核函数代替。MKL-SVM需要同时优化两类参数、核函数的权值和每个分SVM的参数,因此,其优化问题远比单核SVM复杂。在提出MKL-SVM概念的同时,BACH F R等人建议利用混合范数取代通常SVM的l2范数,提出将MKL-SVM的权值优化问题转化为一个与SVM优化类似的问题。在此基础上,文献[6]进一步提出了SILP算法,该算法反复迭代优化一个单核SVM,并将权值的优化问题转化为一个线性的随着迭代而改变的问题。总结前两者的经验,文献[7]提出了Simple-MKL算法,该算法由于收敛速度快,得到了广泛应用。文献[8]将MKL-SVM应用在说话人GMM-UBM超矢量上,取得了良好的分类性能和鲁棒性。
基于此研究现状,本文首先针对I-Vector-SVM基线系统进行了深入研究,通过实验研究对比了常见核函数的性能,在此基础上,适当挑选一组核函数建立多核I-Vector-SVM说话人确认系统,提升了说话人确认系统的整体性能。
1 身份认证矢量I-Vector
1.1GMM-UBM系统
高斯混合模型-通用背景模型(GMM-UBM模型)建模的基本思想是: 首先利用大量说话人的语音数据通过期望最大化 (Expectation Maximum, EM) 算法训练得到一个冒用者模型,即所谓的通用背景模型 (Universal-Background Model, UBM)。为了能够充分表示冒认说话人特征分布,一般UBM 的混合度都非常高。该 UBM 提供了一个统一的参考坐标空间, 然后将说话人的语音训练数据在该 UBM 上面进行最大后验概率 (Maximum A Posterior, MAP) 自适应, 得到了代表该说话人的高斯混合概率密度函数, 并将所有高斯模型的均值向量拼接成一个高维的均值超矢量作为说话人的身份向量。近年来,以GMM-UBM模型为基础的说话人建模技术取得了非常大的成功, 使得说话人识别系统的系统性能有了显著提升[9-10]。
1.2I-Vector的提取
在上述GMM-UBM超矢量的基础上,利用因子分析的算法从中估计出全局差异矩阵(Total Variability Matrix),并将高维的GMM-UBM超矢量在该矩阵中进行投影,最终得到投影后的低维矢量I-Vector[3]。
M=m+Tw
(1)
其中,M表示高斯混合模型的均值超矢量,m表示一个与该说话人和信道参数均无关的矢量, 通常用通用背景模型均值超矢量来替代,T即全局差异矩阵。
一般地,在得到I-Vector之后还会进行一些信道补偿工作,常见技术有类内协方差规整(Within-Class Covariance Normalization, WCCN)[11]等。
2 基于I-Vector的说话人确认系统
2.1余弦评分
获得说话人的I-Vector模型矢量后,可以直接使用余弦评分(CDS),即将说话人的模型矢量和待测试的模型矢量进行余弦距离打分,该分类器将说话人矢量ωtar和测试矢量ωtest的余弦距离分数直接作为判决分数,并与阈值θ进行比较,如式(2)所示:
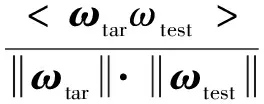
(2)
该评分方式通过归一化矢量的模去除了矢量幅度的影响,计算简单快捷,分类效果较好。
2.2I-Vector-SVM系统
支持向量机(SVM)是建立在统计学习理论和结果风险最小化理论基础上的有监督分类器,在解决非线性、高维度、小样本分类问题中表现出独特优势,特别适用于训练数据较少的说话人识别领域。文献[3]首次将SVM应用于说话人识别,提出了流行相当长时间的GMM- SVM说话人识别系统。自文献[2]提出I-Vector以来,I-Vector-SVM系统迅速替代了原有的GMM-SVM系统,成为当前流行的说话人识别研究方向之一。
SVM的训练过程即是在给定训练样本集X={(x1,y1), (x2,y2),…,(xn,yn)}的情况下,通过序列最小优化(Sequential Minimal Optimization, SMO)算法找出区分正样本点和负样本点的最优超平面。
在SVM的对偶问题(Dual Problem)里,目标函数和分类决策函数都只涉及实例点与实例点的内积,所以不需要显式地指定非线性变化,而是利用核函数巧妙地替换其中的内积,此过程被称为核技巧(Kernel Trick)。因此,SVM通过将低维的通常不可分的数据集映射到高维空间,不仅使得原本不可分的数据变得可分,而且由于在优化过程中只需计算一次每对数据的核函数内积,无需再进行显性的映射,因此其计算量较小。因此,SVM得到了非常广泛的运用。
一般地,满足Mercer定理的函数可以用作核函数,核函数种类众多,在第4节会具体介绍。单核SVM的判别函数如式(3)所示:
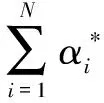
(3)
2.3其他判决模型
除了SVM,其他较为流行的后端判决模型还有人工神经网络(Artificial Neural Network,ANN)[12],把特征提取和模型训练结合到同一单个网络,通过其自适应、自学习和自组织能力,使得特征和模型都能够不断优化,从而达到最优。
3 多核学习SVM(MKL-SVM)
3.1MKL-SVM的结构
MKL-SVM的本质即使用一组核函数来代替单个核函数,因此,新的核函数以及判决函数如式(4)、式(5)所示:
(4)

(5)
其中,dm为核函数的权值,M为核函数的数量。
3.2MKL-SVM的优化
不同于单核SVM,MKL-SVM的优化问题由两部分组成:优化每个SVM的参数αi和每个核函数的权值dm。该问题实际上是一个凸的非光滑的问题。优化该问题的方案很多,BACH F R等人首先提出使用l1-l2混合范数取代通常SVM的l2范数,这样MKL-SVM的权值矢量优化问题就转化成为一个常见的SVM优化问题,可以使用一个类似于SMO的快速下降算法解决。
SONNENBURG S[13]等人认为该问题等同于一个半正定线性方案(Semi-Infinite Linear Program, SILP),该算法反复迭代优化一个单核SVM,并将权值的优化问题转化为一个线性的随着迭代而改变的问题。该算法的优点是SVM损失函数降低速度非常快,因此相较于BACH F R等人提出的方案有了性能上的进一步提升。
本文拟采用Simple-MKL方法来解决MKL-SVM的优化问题。Simple-MKL方法类似于SILP,区别在于其在初始问题(Primal Problem)上使用梯度下降算法(Reduced Gradient Algorithm)而非依赖于判决超平面的参数,使得方案更具效率。
具体地,MKL-SVM的优化问题为:
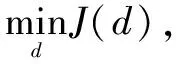
(6)
目标函数:
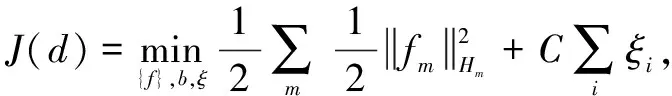
(7)
显然,该优化问题是典型的SVM优化问题,式(7)的Lagrange形式为:
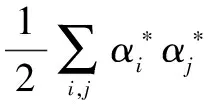
(8)
将其对dm求偏导,得到:

(9)
利用式(9)求出权值矢量d*的下降方向D(具体步骤见文献[7],此处不再赘述),使用d*=d*+γD更新d*,在式(10)的条件满足时,停止迭代并输出当前的d*。
(10)
Simple-MKL在此基础上进一步优化了算法,在每次权值更新时将下降方向最大的权值直接取0并重新规整权值总和为1,训练完SVM后计算目标函数,若目标函数较原来有下降即将该权值直接设为0,将原来的N核-MKL变为N-1核-MKL,再重复上一过程。此方法大大提高了计算效率。
4 实验结果与优化
4.1系统的性能评价
本文采用NIST等错误率(Equal Error Rate, EER)作为说话人确认的评价指标。在说话人确认领域有两种错误率,分别为错误接受率(FA)和错误拒绝率(FR),其分别表示冒认说话人被接受的概率和待确认说话人被拒绝的概率,两者均随着预设阈值的改变而反向改变。因此,当阈值取得一定值时,二者恰好相等,此时的FA或FR被称为等错误率,即EER。
4.2基于单核I-Vector-SVM的说话人确认系统的性能
实验所用数据均来自NIST04-08语料库中的电话语音, 辅助系统UBM混合度为128, I-Vector的维数为200维。测试语音随机选择了100个话者,每个人18~59条10 s语音,经VAD处理后为7~9 s。对于每个说话人,随机抽取16条I-Vector(8条目标说话人,8条冒认说话人)用以训练SVM,剩余的目标说话人的I-Vector用来做目标说话人测试,排除训练冒认说话人的I-Vector用来做冒认说话人测试。实验平台利用Libsvm[14]开源工具包构建,单核SVM参数寻优采用交叉验证法,N=10,实验测试了一系列参数的单核SVM的性能。
测试用的核函数采用了以下的常见核函数:
余弦核:
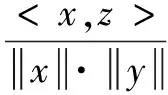
(11)
RBF核:
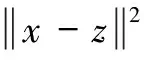
(12)
多项式核:
K(x,z)=(αxTz+β)P
(13)
线性核:
K(x,y)=〈x,z〉+c
(14)
Multiquadric核:
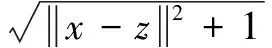
(15)
Sigmoid核:
K(x,z)=tanh(α〈x,z〉+β)
(16)
实验结果如表1~表4所示。
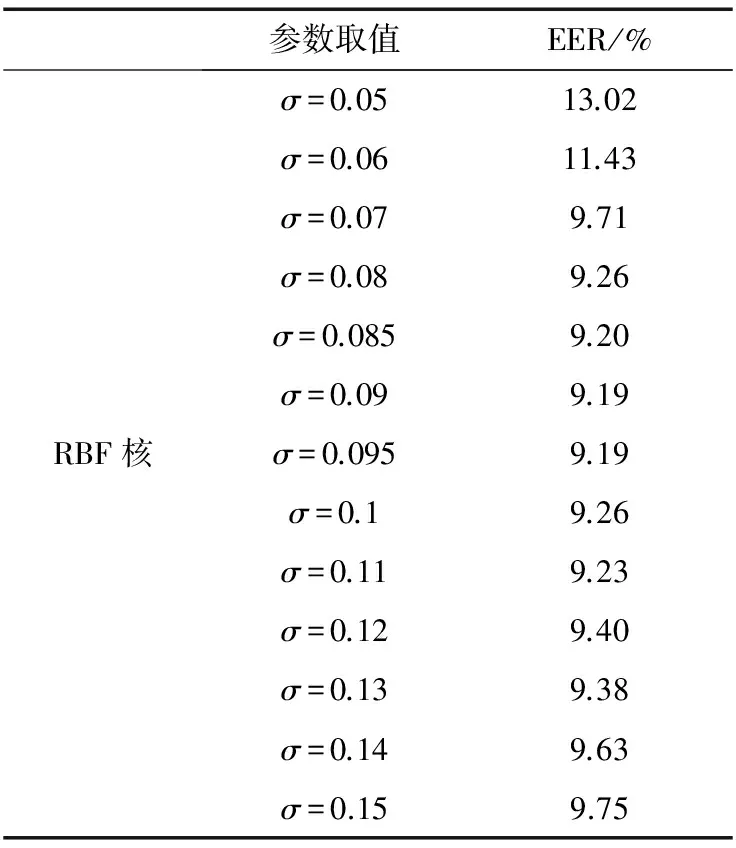
表1 不同参数RBF核函数下I-Vector-SVM说话人确认系统的性能

表2 不同参数多项式核函数下I-Vector-SVM说话人确认系统的性能

表3 不同参数Sigmoid核函数下I-Vector-SVM说话人确认系统的性能

表4 线性核、余弦核和Multiquadric核I-Vector-SVM说话人确认系统的性能
4.3基于多核I-Vector-SVM说话人确认系统的性能
训练和测试数据同单核SVM、MKL-SVM的下降方向步进γ=0.001,停止条件阈值ε=0.001,最高迭代次数为5 000次,其他数据同单核SVM。核函数采取了表1中表现相对优秀的核函数,分别测试了2~6个核函数融合下的系统性能,单核SVM的核函数为α=1,β=1,p=2的多项式核。实验结果如表5所示。
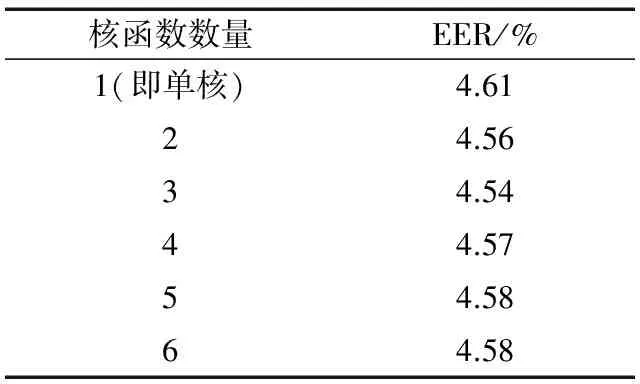
表5 不同核函数数量下单核SVM与MKL-SVM说话人确认系统的性能
由表5可以看出,较单核I-Vector-SVM系统,MKL-SVM系统的性能有一定提升,但提升十分微小,为1.52%左右。这与很多文献结论相一致。而由于I-Vector本身已经具有相当的区分性,因此MKL-SVM系统对基线系统的提升也非常有限。
5 结论
本文总结性地研究了基于I-Vector的SVM多核学习说话人确认系统的性能,并选择适当的一组核函数对基于I-Vector的多核学习SVM的说话人确认系统的性能进行了探索性的研究。基于NIST语料库的实验结果表明,基于I-Vector的多核学习SVM说话人确认系统的性能优于目前的单核SVM说话人确认系统,最大提升幅度可达1.52%。由于I-Vector本身已经具有相当的区分性,数据内生性的联系已经趋于一致,因此进一步从该模型中挖掘信息需要更多工作。
[1] CORTES C, VAPNIK V. Support-vector networks[J]. Machine Learning, 1995, 20(3): 273-297.
[2] CAMPBELL W M, STURIM D E, RENOLDS D A. Support vector machines using gmm supervectors for speaker verification[J]. IEEE Signal Processing Letters, 2006,13(5): 308-311.
[3] DEHAK N, KENNY P, DEHAK R, et al. Front-end factor analysis for speaker verification[C]. IEEE Transactions on Audio, Speech, and Language Processing, 2011, 19(4): 788-798.
[4] 栗志意,张卫强,何亮,等. 基于核函数的IVEC-SVM说话人识别系统研究[J]. 自动化学报,2014,40(4): 780-784.
[5] BACH F R, LANCKRIET G R G, JORDAN M I. Multiple kernel learning, conic duality, and the SMO algorithm[C]. Proceedings of the twenty-first international conference on Machine learning. ACM, 2004: 775-782.
[6] LANCKRIET G R G, CRISTIANINI N, BARTLETT P, et al. Learning the kernel matrix with semi-definite Programming[C]. Nineteenth International Conference on Machine Learning, Morgan Kaufmann Publishers Inc, 2002: 323-330.
[7] RAKOTOMAMONJY A, BACH F R, CANU S, et al. Simplemkl[J]. Journal of Machine Learning Research, 2008, 9(3):2491-2521.
[8] LONGWORTH C, GALES M J F. Multiple kernel learning for speaker verification[C]. IEEE International Conference on Acoustics, Speech and Signal Processing. IEEE, 2008:1581-1584.
[9] REYNOLDS D A, QUATIERI T F, DUNN R B. Speaker verification using adapted gaussian mixture models[J]. Digital Signal Processing, 2000, 10(1-3):19-41.
[10] KINNUNEN T, Li Haizhou. An overview of text-inde-pendent speaker recognition: from features to supervectors[J]. Speech Communication, 2010, 52(1):12- 40.
[11] HATCH A O, KAJAREKAR S S, STOLCKE A. Within-class covariance normalization for SVM-based speaker recognition[C].Interspeech 2006-ICSLP, Ninth International Conference on Spoken Language Processing, Pittsburgh, Pa, USA, 2006:1471-1474.
[12] FARRELL K R,MAMMONE R J,ASSALEH K T.Speaker recognition using neural networks and conventional classifiers[J]. IEEE Transactions on Speech amp; Audio Processing, 1994, 2(1):194-205.
[13] SONNENBURG S, RTSCH G, SCHFER C, et al. Large scale multiple kernel learning[J]. Journal of Machine Learning Research, 2006, 7(2006):1531-1565.
[14] CHANG C C, LIN C J. LIBSVM: a library for support vector machines[J]. ACM Transactions on Intelligent Systems amp; Technology, 2011, 2(3):27.
2017-04-19)
龚铖(1989-),通信作者,男,硕士研究生,主要研究方向:说话人识别。E-mail:grank@mail.ustc.edu.cn。
琚炜(1991-),男,硕士研究生,主要研究方向:语音信号处理。
Speaker verification system of multiple-kernel-learning SVM based on I-Vector
Gong Cheng, Ju Wei
(School of Information Science and Technology, University of Science and Technology of China, Hefei 230026, China)
As the concept ‘I-Vector’ was put forward, the text-independent speaker verification systems based on GMM super vector was replaced by the same systems based on I-Vector. As one of the systems, I-Vector-SVM system has a potential advantage when facing a small amount of training data. But its performance is influenced by its kernel too much. Under this situation, this paper builds a MKL-SVM speaker verification system based on I-Vector inspired by the concept ‘multiple kernel learning’, and compares it with the I-Vector-SVM baseline system. The experiment result based on NIST database showed, this system has an advantage in performance comparing with the baseline system.
speaker certification; multiple-kernel-learning-SVM; I-Vector
TP181
A
10.19358/j.issn.1674- 7720.2017.22.005
龚铖,琚炜.基于I-Vector的多核学习SVM的说话人确认系统J.微型机与应用,2017,36(22):15-18,22.
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21
北京航空航天大学学报(2021年9期)2021-11-02
中学生数理化·高一版(2021年11期)2021-09-05
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01
中国食用菌(2019年7期)2019-08-13
食用菌(2019年2期)2019-04-23
自动化学报(2017年7期)2017-04-18
现代电子技术(2016年15期)2016-12-01
现代防御技术(2016年1期)2016-06-01
新高考·高一物理(2016年1期)2016-03-05
