
Inconsistency between univariate and multiple logistic regressions
2017-11-29 03:16HongyueWANGJingPENGBokaiWANGXiangLUJuliaZHENGKejiaWANGXinTUChangyongFENG2
上海精神医学 2017年2期
Hongyue WANG Jing PENG Bokai WANG Xiang LU Julia Z. ZHENG, Kejia WANG Xin M. TU,Changyong FENG2,*
•Biostatistics in psychiatry (38)•
Inconsistency between univariate and multiple logistic regressions
Hongyue WANG1,Jing PENG1, Bokai WANG1, Xiang LU1, Julia Z. ZHENG3, Kejia WANG1, Xin M. TU4,Changyong FENG1,2,*
Conditional expectation; model selection; logistic regression[Shanghai Arch Psychiatry. 2017;29(2): 124-128.
http://dx.doi.org/10.11919/j.issn.1002-0829.217031]
1. Introduction
Many medical studies have binary primary outcomes.For example, to study the treatment effect of a new intervention on patients with severe anxiety disorders,patients are randomized to the new intervention or treatment as usual (control) groups. The outcome is significant clinical improvement (yes or no) within a period such as 12 months. For this kind of outcome,we use 1 (0) to denote the occurrence or success (no occurrence or failure) of the outcome of interest such as significant (no significant) clinical improvements.The treatment effects can be measured by the difference or ratio of success rates in the two groups.Pearson’s chi-square test (or Fisher’s exact test) can be easily used if the treatment effect of the treatment method is better than the current method.
It is not uncommon that treatment effect is confounded by differences between treatment groups such as age, medication use and comorbid conditions.If such confounding covariates are categorical, such as gender and smoking status, contingency table methods can be easily used to study treatment differences. For continuous covariates such as age,although still possible to apply such methods by categorizing them into categorical variables, results depend on how continuous variables are categorized such as the number of end cut-points for categories.
The multiple logistic regression[1]provides a more objective approach for studying effects of covariates on the binary outcome. It addresses both categorical and continuous covariates, without imposing any subjective element to categorize a continuous covariate. Coefficients of continuous as well as noncontinuous covariates, which are readily obtained using well-established estimation procedures such as the maximum likelihood, have clear interpretation.Also, its ability to model relationships for case-control studies has made logistic regression one of the favorite statistical models in epidemiologic studies.[2]
Model selection offers advantages of increasing power for detecting as well as improving interpretation of effects of covariates on the binary outcome, especially when there are numerous covariates to consider. Here is how model selection was carried out in multiple logistic regression in a paper recently published in JAMA surgery[3]:
‘Associations between preoperative factors and adenocarcinoma or HGD were determined with univariate binary logistic regression analysis. Variables with statistically significant association on univariate analysis were included in a multivariable binary logistic regression model.’
Such a univariate analysis screening (UAS) method to select covariates for multiple logistic regression has been widely used in research studies published in top medical journals[4-6]since it seems very intuitive, reasonable,and easy to understand. In this paper we take a closer look at this popular approach and show that the UAS is quite flawed, as it may miss important covariates in the multiple logistic regression and lead to extremely biased estimates and wrong conclusions. The paper is organized as follows. In Section 2 we give a brief overview of the logistic regression model. In Section 3 we study the relationship between the univariate regression analysis,the basis for selecting covariates for further consideration in multiple logistic regression, and the multiple logistic regression model. In Section 4 we use the theoretical findings derived, along with simulation studies, to show the flaws of the UAS. In Section 5, we give our concluding remarks.
2. Logistic regression model
We use Y=1 or 0 to denote ‘success’ or ‘failure’ of the outcome. Here ‘success’ and ‘failure’ only indicate two opposite statuses and should not be interpreted literally. For example, if we are interested in the relation between the exposure of high density of radiation and cancer, we can use Y=1 to denote that the subject develops cancer after the exposure. Aside from the outcome, we also observe some factors(covariates) which may have significant effects on the outcome, denoting them by X1, X2, ..., Xp. The relation between the outcome and the covariates is characterized by the conditional probability distribution of Y given X1, X2, ... Xp. In multiple logistic regression, the conditional distribution is assumed to be of the following form
where β1β2... βp≠ 0. This is the model on which our following discussions will be based. The covariates may include both continuous and categorial variables. A more familiar equivalent form of (1) is
where the left hand side is called the conditional logodds.
Given a random sample, the parameters(β0, β1, … ,βp) in (1) can be easily estimated by maximum likelihood estimation (MLE) method, see for example.[7,8]
3. Univariate regression model
Suppose we are interested in the marginal relation between the outcome and a single factor X1, i.e. we need to find.
From the property of conditional expectation[9]we know that
If the joint distribution of X1, X2,…,Xpis unknown,generally it is impossible to find the analytical form of (2). In this section we consider the univariate regression model with following some specific distributions.
3.1 Univariate regression with categorical covariate
First assume X1is a 0-1 valued covariate. For example,in the randomized clinical trial, we can use X1as the group indicator (=1 for the treatment group and for the control group). It is easy to prove that there exist unique constants α0and α1such that
where both α0and α1are functions of β0, β1, … ,βp.Usually the form of these functions are complex as they depend on the joint distribution of X1, X2,…,Xp.There is no obvious qualitative relation between α1in(3) and β1in (1).
Equation (3) indicates the marginal relation between Y and X1still satisfies the logistic regression model, and
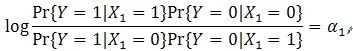
which means that α1in (2) is the log odds ratio.Furthermore, if X1is independent of (X1, X2, ..., Xp), we can prove that (i) α1>0 if and only if β1>0, (ii) α1<0 if and only if β1<0, and (iii) α1=0 if and only if β1=0.The independent assumption is true for completely randomized clinical trials. However, it seldom holds in practice, especially in observational studies.
Now assume X1is a covariate with k-categories,denoted by 1, ... k. Let Zj=1{X1=j}. We can also prove that there exist constant α0, α1, … ,α(k-1)such that
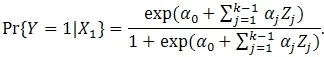
All those parameters have similar interpretation as in the binary case.
This section shows that for categorical covariate,the univariate regression still has the form of logistic regression. However, the interpretation of the parameter is different from that in multiple logistic regression.
3.2 Univariate regression with cont i nuous covariate
Assume X1is a continuous covariate, for example, the age of the patient. We want to know if Pr{Y=1|X1}can be written in the (3) if (1) is the true multiple logistic regression model. Before answering this question, let’s us take a look a the following example.Example 1. Suppose there are only two covariates in the multiple logistic regression model (1), where X1is a continuous covariate with range R, X2is 0-1 valued random variable with Pr{X2=1}=1/2, and X1and X2are independent.We further assume β0=β1=β2=1 in (1). Then
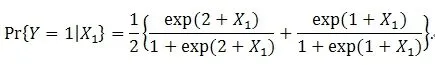
If (3) is true, then we should have
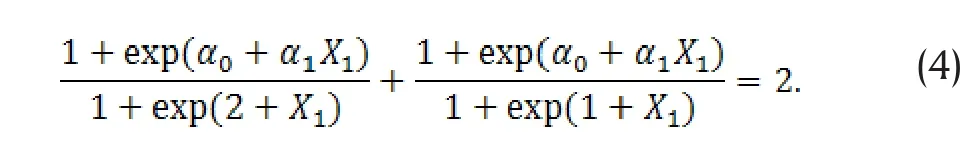
Let X1→∞ in (4) we have α1=1. Let X1=0 in (4) we have
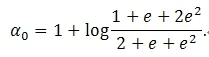
However, if X1=1 in (4), then
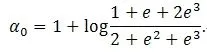
Since these two solutions of α0do not match, model (3)does not hold.
This example shows that, for continuous covariate X1, the regression of Y on X1does not in general satisfy the univariate logistic regression model even if X1is an essential component in the multiple logistic regression. Hence, the univariate logistic regression model should not be used to estimate the marginal relation between the outcome and a continuous covariate.
4. Inconsistency between univariate and mul ti ple logis ti c regressions
In Section 3 we show that in multiple logistic regression,the univariate regression of the outcome on each individual covariate may not satisfy the logistic regression any more. This fact has serious implications for model selection and interpretation of results in data analysis. In this section, we demonstrate this important issue using simulation studies.
4.1 Signi fi cant e ff ect in mul ti ple but not in univariate logis ti c regression
In this section we show an example where a continuous covariate is a necessary part in the multiple logistic, but the univariate regression indicates that the covariate has no effects in the univariate regression. The following preliminary result will be used in our discussion.
Lemma 1.Suppose c is a positive constant and the random variable X has standard normal distribution. Then E[X/(1+cexp(θX))]=0 if and only if θ=0.
The proof of this result is available from authors upon request.
Example 2.Let X2and X3be independent random variables with standard normal distributions, and X1=X2+2X3. Consider the following multiple logistic regression model
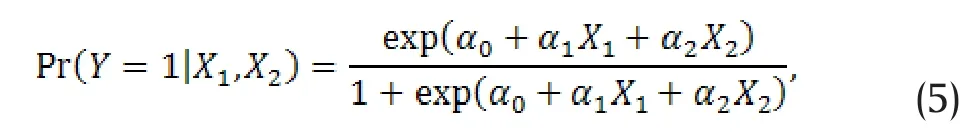
where α1=-α2/5,α2≠0. Using the result in Lemma 1 we can prove that if

then θ1=0.
What does this result mean within the current context? Although X1and X2both are in the multiple logistic regression, if their coefficients satisfy the condition (5), the regression of Y on X1is no longer a univariate logistic regression. Moreover, if (Yi1, Xi1,Xi2),i=1,…,n is a random sample from (5), X1and X2will become increasingly significant in the multiple logistic regression, but X1will remain nonsignificant regardless of sample size, as illustrated by the following simulation results.
The data was generated according (5) with α0=1,α1=-3/5,α2=3. Shown in Table 1 are the estimates and standard deviations of the coefficient of X1in both univariate and multiple logistic regression after 10,000 Monte Carlo (MC) replicates. The parameters were estimated by MLE. For a wide range of sample sizes, the maximum likelihood estimator of the coefficient of X1in the multiple logistic regression was very close to the true value, and the standard errors decreased with the sample size, as expected.However, the estimated coefficient in the univariate analysis was consistently close to 0 in all cases.
Table 1 also reports the chance that p-value is>0.2 (or >0.1) in the univariate logistic regression.It shows that although X1is a necessary part of the multiple logistic regression, X1will most likely be excluded from the multiple logistic regression, if the cutoff of the p-value is set at 0.2 (or 0.1).
Reported in Table 2 are the estimates of the coefficient of X2in the logistic regression if X1is mistakenly excluded due to UAS method. The true coefficient of X3is 3 in the multiple logistic regression, but the estimated coefficient of X2became extremely biased if X1was excluded.
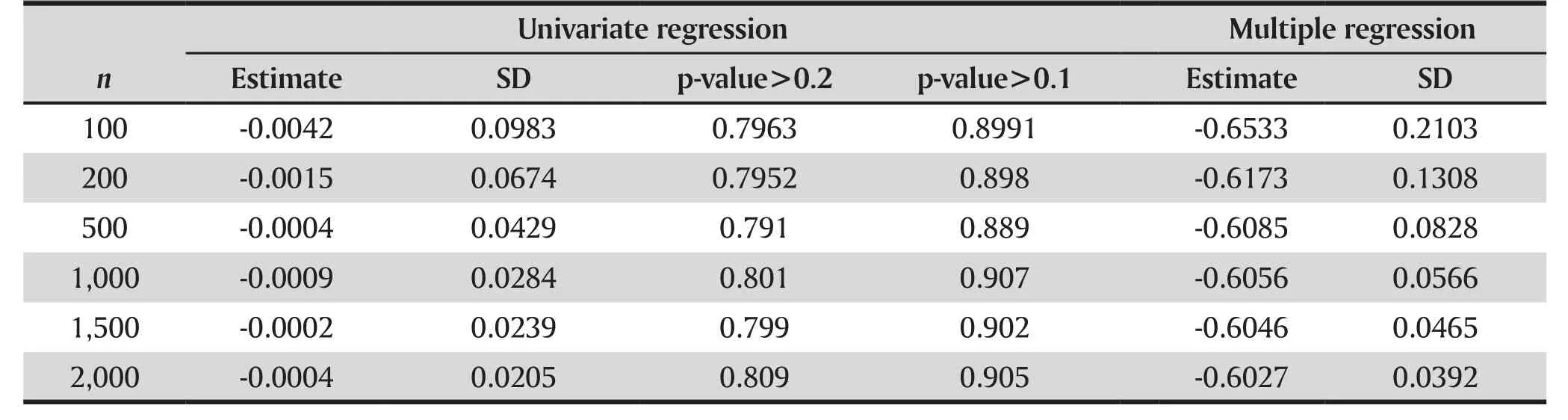
Table 1. Estimate of regression coefficient of X1 in Example 2
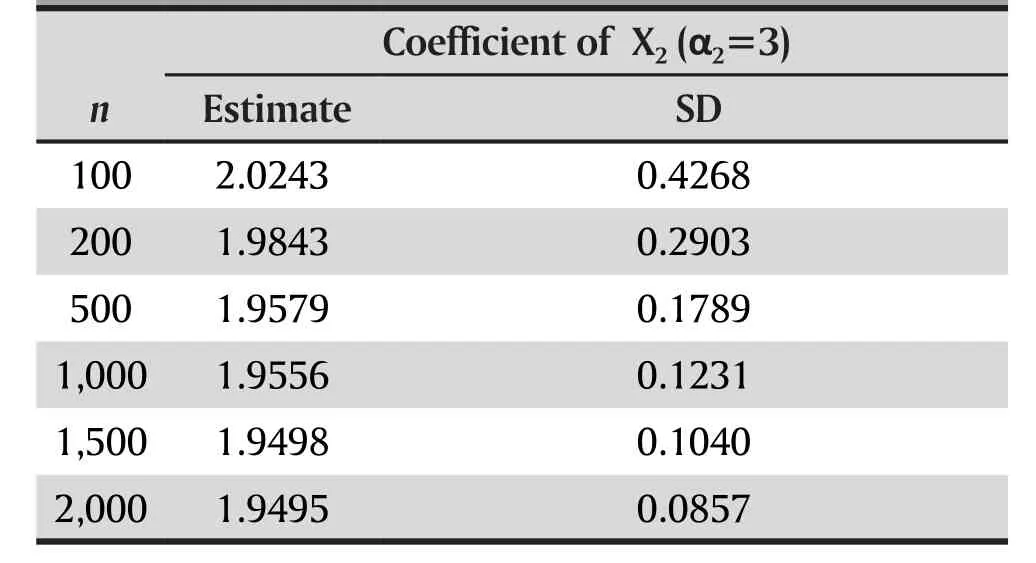
Table 2. Estimates of coefficients of X2 in logisticregression with X1 being removed inExample 2
Taken together, the results show that the UAS not only most likely misses some important covariates in the multiple logistic regression, but also leads to severely biased estimates of effects of other covariates on the response.
4.2 Signi fi cant e ff ect in univariate but not in mul ti ple regression
In this section we show a case where a continuous covariate has significant effect in the univariate regression, but is not significant if it is included in the multiple regression.
Example 3. Suppose X1, X2, X4and ε are independent standard normal random variables, and X3=X1+X4. Consider the following multiple logistic regression model
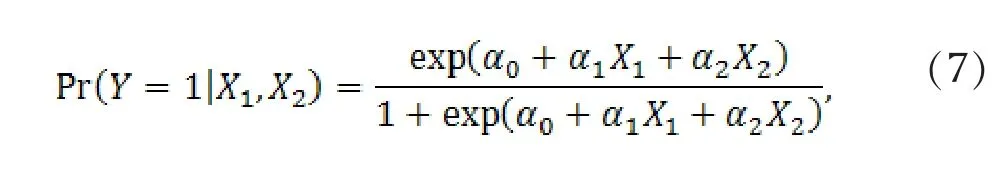
where α1α2≠0.
In the simulation study, the data was generated according model (7) with α0=0,α1=2,α2=1. Shown in Table 3 are the estimates of the coefficient of X3in both univariate and multiple linear regression (with X1,X2and X3as covariates) after 10000 replicates. For all sample sizes, X3shows very significant effect on Yin the univariate regression, but no significant effect in the multiple logistic regression.
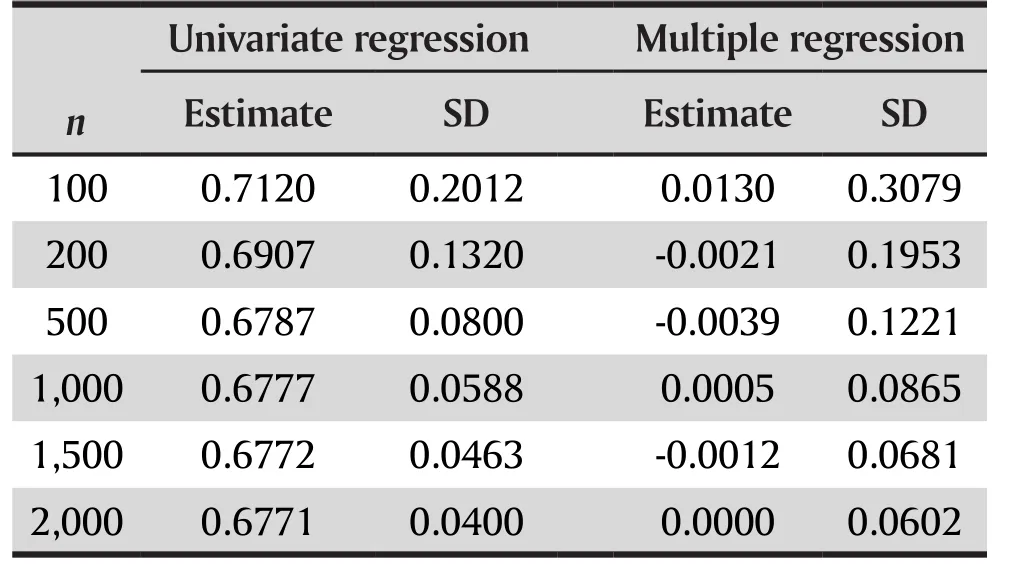
Table 3. Estimate of the regression coefficient of X3
5. Discussion
Although the logistic regression is a very powerful analytical method for binary outcome, the results from the univariate and multiple logistic regressions tend to be conflicting. A covariate may show very significant effect in the univariate analysis but has no role in the multiple logistic regression model. On the other hand, a covariate may be an essential part of the multiple logistic regression but shows no significant effect on the outcome in the univariate regression.The UAS method uses the univariate analysis as an initial step to select covariates for further consideration in the multiple regression. This method may mistakenly exclude important covariates in the multiple logistic regression and lead to extremely biased estimates of the effects of other covariates in the multiple model. Hence the UAS is not a valid method in model selection. It should be removed from the tool kits of biomedical researchers and even some PhD statisticians. Formal model selection methods based on solid theory, such as Akaike’s information criterion (AIC) and Schwarz’ Bayesian information criterion (BIC) discussed in[10]should be implemented in all regression analyses.
Funding
None
Conflict of interest statement
The authors report no conflict of interest related to this manuscript.
Authors’ contribution
Hongyue Wang, Bokai Wang, Xiang Lu, Xin M. Tu and Changyong Feng: theoretical derivation and revision Julia Zheng, Jing Peng, and Kejia Wang: Simulation studies and manuscript drafting
1. Cox DR. The regression analysis of binary sequences (with discussion). J Roy Stat Soc B. 1958;20: 215–242
2. Prentice RL, Pyke R. Logistic disease incidence models and case-control studies. Biometrica. 1979;63: 403–411. doi:http://dx.doi.org/10.1093/biomet/66.3.403
3. Postlewait LM, Ethun CG, McInnis MR, Merchant N, Parikh A, Idrees K, et al. Association of preoperative risk factors with malignancy in pancreatic mucinous cystic neoplasms:A multicenter study. JAMA Surg. 2017;152(1): 19-25. doi:http://dx.doi.org/10.1001/jamasurg.2016.3598
4. Karcutskie CA, Meizoso JP, Ray JJ, Horkan D, Ruiz XD,Schulman CI, et al. Association of mechanism of injury with risk for venous thromboembolism after trauma. JAMA Surg. 2017;152(1): 35-40. doi: http://dx.doi.org/10.1001/jamasurg.2016.3116
5. Templin C, Ghadri JR, Diekmann J, Napp LC, Bataiosu DR, Jaguszewski M, et al. Clinical features and outcomes of takotsubo (stress) cardiomyopathy. N Engl J Med.2015;373(10): 929-38. doi: http://dx.doi.org/10.1056/NEJMoa1406761
6. Nor AM, Davis J, Sen B, Shipsey D, Louw SJ, Dyker AG. The Recognition of Stroke in the Emergency Room (ROSIER)scale: Development and validation of a stroke recognition instrument. Lancet Neurol. 2005;4(11): 727-734. doi: http://dx.doi.org/10.1016/S1474-4422(05)70201-5
7. McCullagh P, Nelder JA. Generalized Linear Models (2nd ed).New Yrok: Chapman & Hall; 1989
8. Agresti A. Categorical Data Analysis (3rd ed). Hoboken, NJ:Wiley; 2010
9. Durrett R. Probability: Theory and Examples (4th ed). New York: Cambridge University Press; 2010
10. Claeskens G, Hjort NL. Model Selection and Model Averaging.New York: Cambridge University Press; 2008
单因素与多因素逻辑回归的不一致性
WANG H, PENG J, WANG B, LU X, ZHENG J, WANG K, TU X, FENG C
条件期望;模型选择;逻辑回归
Summary:Logistic regression is a popular statistical method in studying the effects of covariates on binary outcomes. It has been widely used in both clinical trials and observational studies. However, the results from the univariate regression and from the multiple logistic regression tend to be conflicting. A covariate may show very strong effect on the outcome in the multiple regression but not in the univariate regression, and vice versa. These facts have not been well appreciated in biomedical research. Misuse of logistic regression is very prevalent in medical publications. In this paper, we study the inconsistency between the univariate and multiple logistic regressions and give advice in the model section in multiple logistic regression analysis.
1Department of Biostatistics and Computational Biology, University of Rochester, Rochester, NY, USA
2Department of Anesthesiology, University of Rochester, Rochester, NY, USA
3Department of Microbiology and Immunology, McGill University, Montreal, QC, Canada
4Department of Family Medicine and Public Health, University of California San Diego, La Jolla, CA, USA
*correspondence: Dr. Changyong Feng. Department of Biostatistics and Computational Biology, University of Rochester, 601 Elmwood Ave., Box 630,Rochester, NY, 14642, USA. E-mail: Changyong_feng@urmc.rochester.edu
概述:逻辑回归是研究协变量对二元结果影响的一种常用的统计方法。它已被广泛应用于临床试验和观察性研究。然而,单因素回归得到的结果和多元逻辑回归得到的结果往往是相互矛盾的。在多元回归中可能对结果会显示出非常强烈的影响的一个协变量在单因素回归中可能不会,反之亦然。这些事实在生物医学研究中并没有引起足够的重视。误用逻辑回归在医学出版物中非常普遍。在本文中,我们研究了单因素和多因素逻辑回归分析的不一致性,并在多元逻辑回归分析的模型部分中给出建议。

Hongyue Wang obtained her BS in Scientific English from the University of Science and Technology of China(USTC) in 1995, and PhD in Statistics from the University of Rochester in 2007. She is a Research Associate Professor in the Department of Biostatistics and Computational Biology at the University of Rochester Medical Center. Her research interests include longitudinal data analysis, missing data, survival data analysis,and design and analysis of clinical trials. She has extensive and successful collaboration with investigators from various areas, including Infectious Disease, Nephrology, Neonatology, Cardiology, Neurodevelopmental and Behavioral Science, Radiation Oncology, Pediatric Surgery, and Dentistry. She has published more than 80 statistical methodology and collaborative research papers in peer-reviewed journals.
猜你喜欢
科学与社会(2022年4期)2023-01-17
科学与社会(2021年4期)2022-01-19
基层中医药(2020年5期)2020-09-11
图书馆建设(2018年5期)2018-07-10
中国气象科学研究院年报(2017年0期)2017-07-19
照明工程学报(2016年3期)2016-06-01
中国学术期刊文摘(2016年8期)2016-02-13
中国学术期刊文摘(2016年8期)2016-02-13
中国气象科学研究院年报(2015年0期)2015-06-08
中国合理用药探索(2012年2期)2012-03-20

- 上海精神医学的其它文章
- Efficacy towards negative symptoms and safety of repetitive transcranial magnetic stimulation treatment for patients with schizophrenia: a systematic review
- Factors related to acute anxiety and depression in inpatients with accidental orthopedic injuries
- Placement instability among young people removed from their original family and the likely mental health implications
- A study of the characteristics of alexithymia and emotion regulation in patients with depression
- Efficacy and metabolic influence on blood-glucose and serum lipid of ziprasidone in the treatment of elderly patients with first-episode schizophrenia
- The current situations and needs of mental health in China