
特征聚类在油田测试方案优化中的研究
2017-11-28 09:51:18李洪奇张艳丽杨景海朱丽萍赵艳红裴建亚
中成药 2017年11期
李洪奇 ,张艳丽 ,杨景海 ,朱丽萍 ,赵艳红 ,裴建亚
1.中国石油大学 地球物理与信息工程学院,北京 102249 2.中国石油大学 油气数据挖掘北京市重点实验室,北京 102249 3.大庆油田测试技术服务分公司,黑龙江 大庆 163000
特征聚类在油田测试方案优化中的研究
李洪奇1,2,张艳丽1,2,杨景海3,朱丽萍1,2,赵艳红1,2,裴建亚3
1.中国石油大学 地球物理与信息工程学院,北京 102249 2.中国石油大学 油气数据挖掘北京市重点实验室,北京 102249 3.大庆油田测试技术服务分公司,黑龙江 大庆 163000
针对油田注产剖面动态测试在选井上没有一个合适参考标准的问题,提出利用基于特征的聚类将油井按照生产状况进行先聚类再分类的方法。首先对油井生产时间序列数据选择处理,然后提取序列特征进行聚类,并把聚类结果划分等级,最后制定油田测试优化方案。实验结果表明,提取的时间序列特征能很好地表征油井生产波动情况,获得较好地分类效果,对指导油田测试有重要意义。
特征;聚类和分类;时间序列;油田测试优化
1 引言
目前我国的主要油田已经处于高含水开发后期,如何指导油田生产、稳定产量成为亟待解决的问题[1]。而随着油田建设已进入了信息化和数字化阶段,产生了大量按照时间顺序存储的生产相关数据信息(即时间序列数据),为数据挖掘提供了研究与分析的机会。如今,大数据分析技术已经在油田生产优化、油气藏干预与优化等领域有所应用,但在油田测试领域仍是空白。
注产剖面测试资料是分析储层吸水和产出状况[2]的重要依据,尤其对于高含水油井而言,测试资料对稳定生产意义重大。根据《油田开发管理纲要》(以下简称《纲要》)要求,应选取油井开井数10%~15%以上的井每年测产液剖面一次。但因缺乏科学合理的选择标准以及受到时间、人力等因素制约,实际测试比例非常低。以大庆油田为例,一年仅有5%左右的井参与了测试。那么,利用时间序列数据挖掘技术高效地将油井按照生产情况进行聚类,在有限的条件下选择出具代表性的井参与测试,最大化测试价值,将是数据挖掘技术在油田生产领域中应用的又一突破。
油井的产油量时间序列数据能够体现油井的生产状况,所以本文将其作为研究对象。但是时间序列数据具有动态变化和高维度的特性[3],直接在原始数据上聚类不仅会增加聚类复杂度,还会使得聚类结果受到时间因素影响。文献[4]从统计分布特征、非线性和傅里叶频谱转换等三个方面对时间序列数据提取全局特征建立特征向量进行聚类分析。文献[5]运用成分分析法提取时间序列特征后再聚类,提出了基于独立成分分析的单变量时间序列多路归一化割谱聚类方法。为将油井能按照生产状况进行归类,本文通过提取原始时间序列数据的基本统计特征、时域特征和混沌性特征[6]三类体现油井生产状态的特征来对实现时间序列数据的降维处理[7]。
在聚类方法上,文献[8]结合小波变换技术提出一种新的迭代式聚类算法,优化高维聚类对初始矩阵中心高敏感性的问题,提高了聚类效果。文献[9]在聚类过程中将CURE和减聚类方法相结合,以获得自适应的聚类个数和中心。考虑到油田既有测试比例的要求又有实际测试限制,所以本文利用基于遗传算法的K-Means组合层次聚类方法进行聚类分析,使得首次聚类结果能满足规定的比例要求,二次聚类得到的簇类谱系图能满足实际情况下测试比例的调整需求,最终给出优化方案。
2 相关技术和分析模型
时间序列数据挖掘用于聚类的主要研究技术有时间序列数据预处理、时间序列数据的表示、时间序列相似性度量和时间序列聚类[10]。
(1)时间序列数据预处理
在数据挖掘过程中,数据预处理极大影响着最后的挖掘效果。油田测试方案目的是挑选出生产波动状况大、存在异常的井作为重点测试井,所以选择油井日产油量时间序列,作为研究对象。另外,按照油田生产实际,剔除长期关井导致生产“平稳”的数据,以免干扰分析结果。
(2)时间序列数据的表示
油田开发是一个复杂的非线性动力学系统,油田产量变化受多种因素(如地质因素、流体性质、开采方式等)制约,这些因素导致油井生产时间序列表现形式既有确定性又有随机性[11-12],对这样的数据进行分析困难重重。根据小波分析理论,时间序列经过多次小波变换后,其趋势项、周期项和随机项就能从原序列中获得较好的分离,最终将非平稳的时间序列转换为平稳的时间序列,从而降低了数据分析的难度[13-14]。为了获得时间序列数据的总体趋势和变换后的平稳分量,本文采用wavedec函数对其进行多尺度分解。
(3)时间序列相似性度量
相似性度量是衡量对象之间关系的标准,也是时间序列数据聚类和分类的基础。相似性度量包含相似度和距离两个相对的概念,在一定环境下,两者是等价的。因为聚类对象是时间序列的特征集,而且特征项属于静态数据,所以通常基于特征的聚类方法采用的是欧式距离法[15]。
(4)时间序列聚类
基于划分的K-means聚类算法和层次聚类算法是最主要的两种聚类方法。其中,K-means属于快速聚类算法,它虽然需要预先指定聚类个数,但能处理大数据集,可以很好应对油田海量数据的现状。另外,针对K-means簇初始化问题,许多文献都已经提出了改进算法,这里采用基于遗传算法的K-means聚类算法,可以避免陷入局部最优[16]。层次聚类算法能把整个数据集的谱系关系展示出来,通用性强,但却不能很好地支持大数据集。所以,将这两种聚类算法进行组合,令均值聚类的输出作为层次聚类的输入,实现优势互补不失为一种很好的聚类方案。
综合时间序列数据挖掘流程和油田测试方案优化目标,获得一个比较完整的数据分析模型来实现油田测试方案优化,如图1所示。
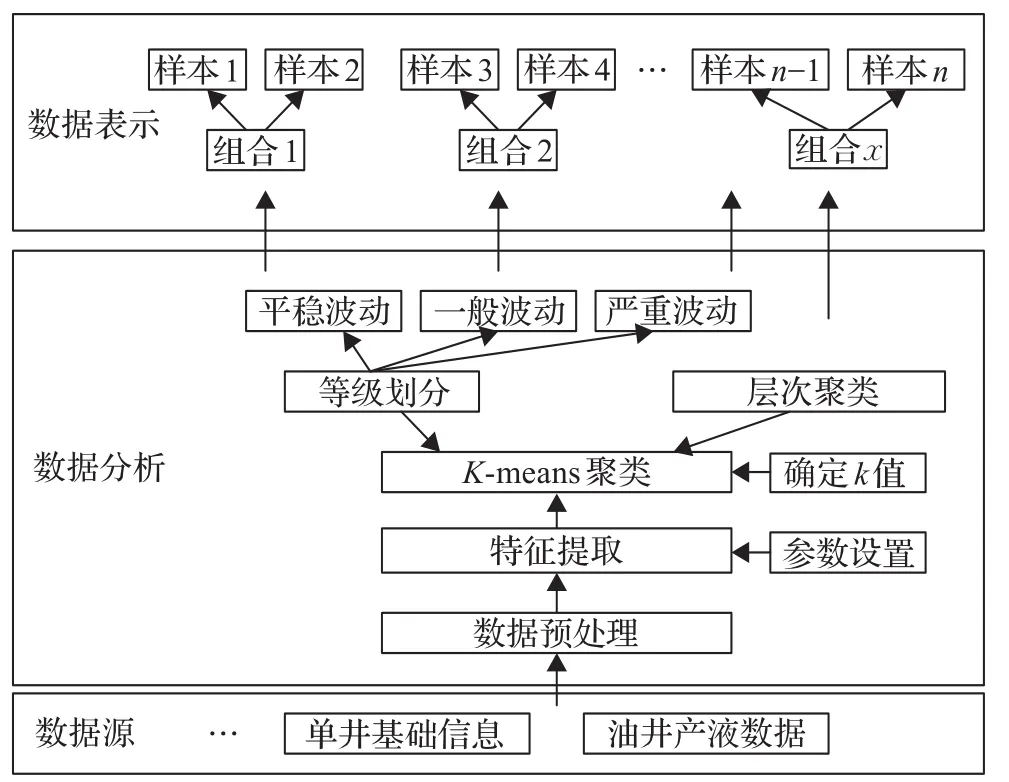
图1 油井生产时间序列分析模型
3 小波变换与特征集构建
3.1 小波变换原理
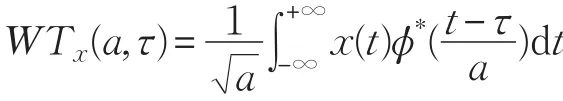
小波变换是把某一被称为基本小波的函数作位移τ后,在不同尺度a下,与待分析信号X(t)作内积,即:a>0,作用是对基本小波φ(t)函数作伸缩,τ可正可负,它们都是连续变量,则称为连续小波变换。在实际应用中,常常要把连续小波离散化,即对a和τ进行采样,离散小波变换一般仍然具备连续小波变换具有的性质。
3.2 wavedec函数用于时间序列分解
本文利用Matlab中的wavedec函数对时间序列数据X(t)进行N层分解,分解成包含低频分量的体现时间序列数据变换趋势的尺度信号和包含高频分量及噪声的细节信号。
以大庆油田某区块的一口井为例,四层分解结果如图2所示。x是原始数据,a4是数据的长期走势,即大尺度趋势成分,d1、d2、d3、d4分别是不同频率的小尺度成分。其中,d1、d2可以认为是随机项不予考虑,d3是分离掉趋势项的分量,d4是分离掉噪声后的分量。4个小尺度成分围绕0上下波动,说明时间序列的趋势项已经得到了很好的分离,非平稳时间序列已经转换为平稳时间序列。

图2 产油量时间序列4层分解结果图
3.3 时间序列特征集
从日产油量时间序列分解后的趋势分量和去噪分量中提取基本统计特征、分布特征、模型特征和混沌性特征描述时间序列的全局特征,可以不必考虑时间序列数据的长度和信息是否有丢失,如表1。但这些特征项的度量单位各不相同,组合特征集之前必须进行标准化处理,将有量纲的数转为无量纲的数,本文综合数据特点和计算效率等因素,采用最大-最小标准化处理,将所有数值变成绝对值在[0,1]之间的小数。

表1 油井生产时间序列特征项
4 油井生产实例分析
针对大庆油田某区块的油井日产油量数据,采用油井生产时间序列分析模型将所有的油井按照生产状况进行划分,并将划分结果结合实际生产数据进行分析评判。
4.1 油井生产实例研究对象
选择2014年1月1日至2015年1月1日的日产油量数据,该地区的油井总数为303,生产井(指在2014年一年内有过开井生产记录的井)数目301。
4.2 油井生产时间序列重新描述
根据第2章和第3章讲解的时间序列数据集处理和特征集的构建过程,将上述所有生产井的时间序列数据提取特征并归一化,部分结果如表2所示。
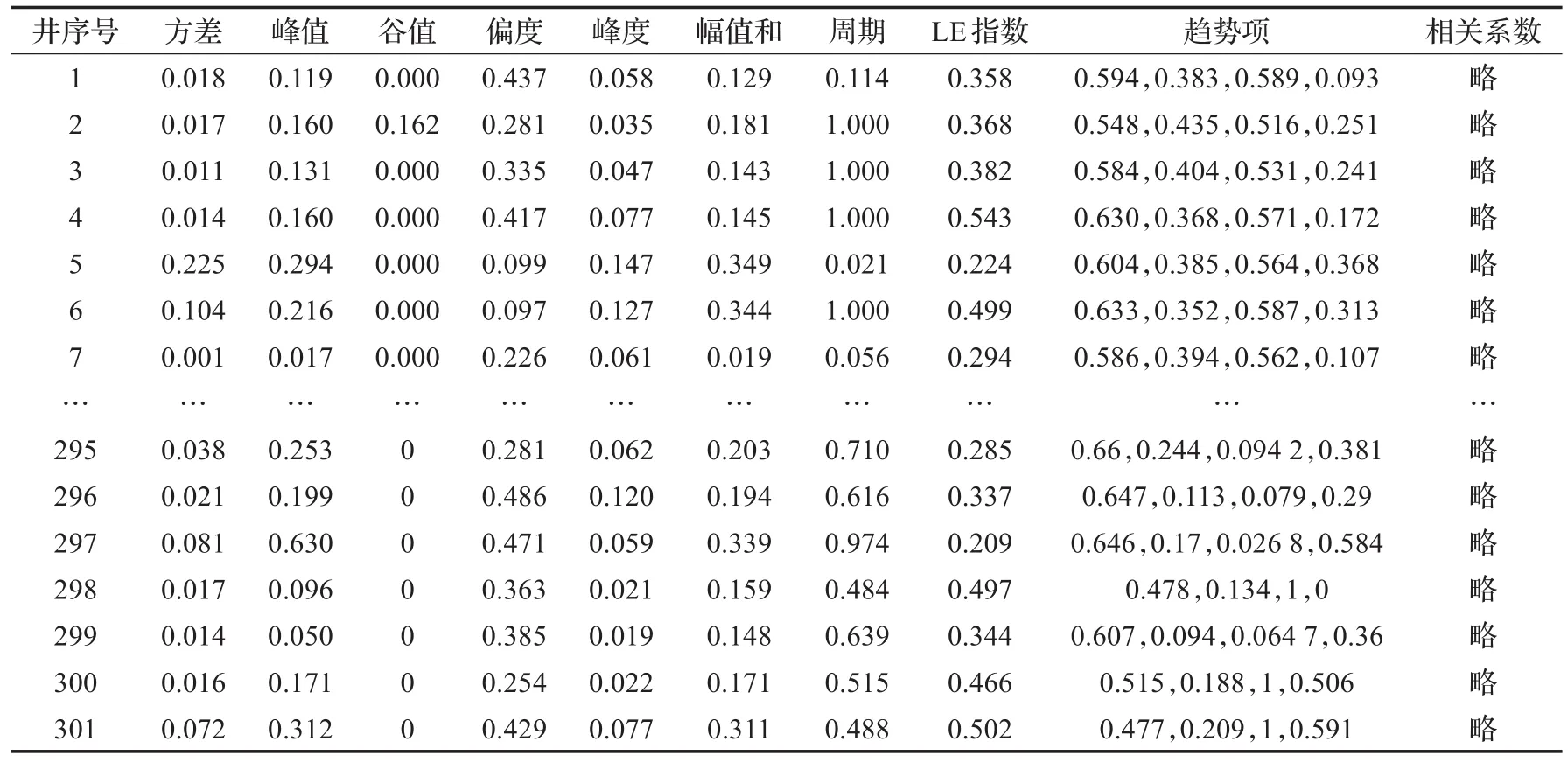
表2 油井生产时间序列特征归一化值(部分)
4.3 聚类实验及结果分析
根据《纲要》中对于每年测试油井个数10%~15%的比例要求,大约需要聚成30~45个类。因此本文取最大类,K=45。聚类结束后针对重点测试波动幅度大的井的要求,需把井划分成平稳生产、一般波动和严重波动3个等级,而方差是反映波动情况最直观的变量,故以方差为标准,将45个聚类中心按方差排序划分状态级别,如表3。
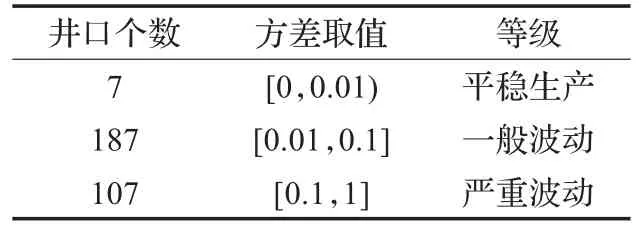
表3 状态分类
为验证划分结果的正确性,对井进行纵向比较。从三个等级中各自挑选一口井,作出它们的生产曲线图,如图3,可见将聚类结果的确可以划分波动等级,等级划分具有一定合理性。
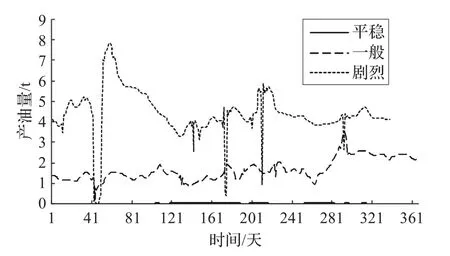
图3 三种波动级别对比图
接下来进行横向比较,三个等级中各自随机选择三口井作图4~6。可以看到,同一簇内的井产油量波动曲线近似,如图5中属于簇28的两条井生产曲线波动较一致,图4中属于簇33的两条井生产曲线波动较一致。同一等级内的井整体生产状况符合所在等级的划分标准,如属于平稳生产的图4波动范围在0~0.7,属于一般波动生产的图5波动范围在0~6,属于严重波动生产的图6波动范围在0~10。
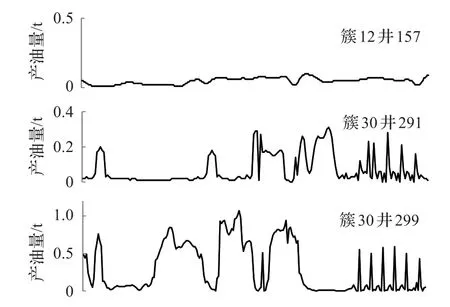
图4 平稳生产级别内部比对
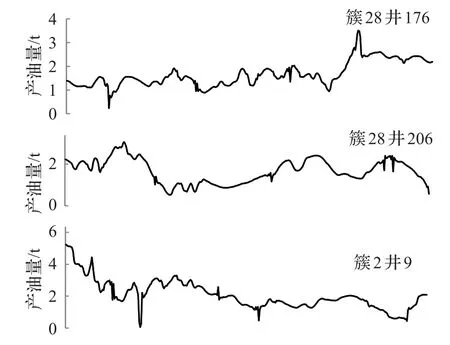
图5 一般波动级别内部比对
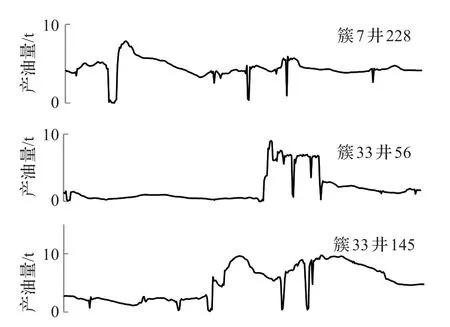
图6 严重波动级别内部比对
4.4 测试优化方案制定
经过均值聚类,已经满足了《纲要》规定的要求,只要从每个类别中选择一口井作为代表参与测试即可。但当测试条件不允许的时候,就需通过层次聚类调整测试比例。将上节聚类得到的45个簇的质心数据作为层次聚类的输入,得到质心之间的谱系图,如图7。
当油田受条件所限达不到规定的比例,可以通过这些井的谱系关系对参与测试的井进行约减。当油田更关注于波动严重的井的测试资料时,也可以根据谱系图适当提高严重波动等级内要测试的井的比例,降低平稳等级内要测试的井的比例。最终让测试选井变得富有针对性,实现测试方案的优化。
5 结束语
对实际生产的油井进行分析归类是一个有实际应用价值的研究。本文针对油井日产油量时间序列数据聚类做了一系列研究与实验,选择了适用于油井的时间序列特征项,并从K-means聚类和层次聚类两种聚类模型展开分析,结果表明利用特征项进行聚类能准确地获得较优的测试方案,实现了时间序列数据挖掘在油田生产测试方案上的新应用。下一步将从考虑影响油田生产的更多因素,即从多变量时间序列的方向展开研究。
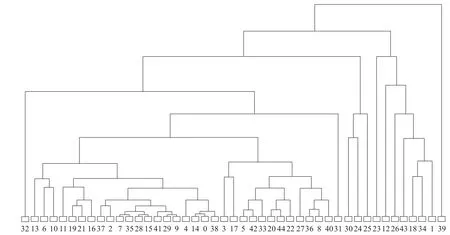
图7 层次聚类结果
[1]段泽英,蔡贤明,滕卫卫,等.大数据分析技术在油田生产中的研究与应用[J].中国管理信息化,2015(18):64-65.
[2]鲁柳利.油田区块监测指标与开发指标预测建模及应用研究[D].四川南充:西南石油大学,2013.
[3]韩娜.聚类算法在时间序列中的研究与应用[D].广州:广东工业大学,2011.
[4]孙旭.时间序列全局特征聚类分析方法及其应用[J].统计教育,2009(3):55-59.
[5]苏木亚.谱聚类方法研究及其在金融时间序列数据挖掘中的应用[D].辽宁大连:大连理工大学,2011.
[6]李天舒.混沌时间序列分析方法研究及其应用[D].哈尔滨:哈尔滨工程大学,2006.
[7]Krawczak M,Szkatuła G.An approach to dimensionality reduction in time series[J].Information Sciences,2014,260:15-36.
[8]韩忠明,陈妮,乐嘉锦,等.面向热点话题时间序列的有效聚类算法研究[J].计算机学报,2012,35(11):2337-2347.
[9]孙吉红.长时间序列聚类方法及其在股票价格中的应用研究[D].武汉:武汉大学,2011.
[10]Aghabozorgi S,Shirkhorshidi A S,Wah T Y.Time-series clustering-A decade review[J].Information Systems,2015,53:16-38.
[11]刘合,邹继刚,李天舒,等.基于小波信号分析的联合站沉降脱水系统黑箱建模[J].哈尔滨工程大学学报,2001,22(4):39-42.
[12]Wheelwright S,Makridakis S,Hyndman R J.Forecasting:methods and applications[M].[S.l.]:John Wileyamp;Sons,1998.
[13]Maheswaran R,Khosa R.Wavelet volterra coupled models for forecasting of nonlinear and non-stationary time series[J].Neurocomputing,2015,149:1074-1084.
[14]Amezquita-Sanchez J P,Adeli H.A new music-empirical wavelet transform methodology for time-frequency analysis of noisy nonlinear and non-stationary signals[J].Digital Signal Processing,2015,45:55-68.
[15]Hautamäki V,Nykänen P,Fränti P.Time-series clustering by approximate prototypes[C]//19th International Conference on Pattern Recognition,2008,ICPR 2008.IEEE,2008:1-4.
[16]Liao T W,Ting C F,Chang P C.An adaptive genetic clustering method for exploratory mining of feature vector and time series data[J].International Journal of Production Research,2006,44(14):2731-2748.
LI Hongqi1,2,ZHANG Yanli1,2,YANG Jinghai3,ZHU Liping1,2,ZHAO Yanhong1,2,PEI Jianya3
1.College of Geophysics and Information Engineering,China University of Petroleum,Beijing 102249,China 2.Beijing Key Lab of Data Mining for Petroleum Data,China University of Petroleum,Beijing 102249,China 3.Daqing Oilfield Testing Technology Services Branch Offices,Daqing,Heilongjiang 163000,China
Research on optimization of oilfield test scheme based on characteristic clustering.Computer Engineering and Applications,2017,53(21):214-218.
Note the oilfield production cross section in the dynamic test in the well election does not have a suitable reference standard issue,the paper proposes a well production division method in accordance with the feature-based clustering and the classification.First,the method selects and processes the well production time series data.And then the characteristic sets are extracted for clustering from time series data.In the end the clustering results develop the oilfield test optimization.Experimental result shows that the characteristics extracted from time series can be a good representation of the fluctuations in oil production,obtain better classification results and be important for guiding the oilfield test.
characteristics;clustering and classification;time series;the oilfield test optimization
A
TP301
10.3778/j.issn.1002-8331.1604-0408
李洪奇(1960—),男,博士,博士生导师,研究方向为数据挖掘、人工智能与应用、油气信息化管理技术;张艳丽(1991—),女,在读硕士,研究方向为软件工程、数据挖掘,E-mail:862390147@qq.com;杨景海(1964—),男,硕士研究生,从事测试资料解释处理;朱丽萍(1973—),女,副教授,研究方向为数据挖掘、虚拟现实、计算机网络;赵艳红(1986—),女,博士研究生,主要研究领域为软件工程、过程建模与本体应用;裴建亚(1976—),男,硕士,从事生产测井解释方法研究。
2016-04-29
2016-06-14
1002-8331(2017)21-0214-05
CNKI网络优先出版:2016-09-29,http://www.cnki.net/kcms/detail/11.2127.TP.20160929.1650.024.html
猜你喜欢
大众投资指南(2021年35期)2021-02-16 01:06:26
钻井液与完井液(2018年5期)2018-02-13 01:07:28
钻井液与完井液(2018年5期)2018-02-13 01:07:26
电子测试(2017年15期)2017-12-18 07:19:27
电力与能源(2017年6期)2017-05-14 06:19:37
智能系统学报(2015年4期)2015-12-27 09:38:39
信息通信技术(2015年6期)2015-12-26 01:16:46
电子设计工程(2015年6期)2015-02-27 12:04:53
华东师范大学学报(自然科学版)(2014年6期)2014-02-27 13:40:55
电子设计工程(2014年18期)2014-02-27 12:00:13
