
基于随机森林分类的HEVC帧内CU快速划分算法
2017-11-28 09:50:48毋笑蓉师智斌雷海卫
中成药 2017年11期
毋笑蓉,师智斌,雷海卫,杜 博
1.中北大学 计算机与控制工程学院,太原 030051 2.中北大学 仪器科学与动态测试教育部重点实验室,太原 030051
基于随机森林分类的HEVC帧内CU快速划分算法
毋笑蓉1,师智斌1,雷海卫2,杜 博1
1.中北大学 计算机与控制工程学院,太原 030051 2.中北大学 仪器科学与动态测试教育部重点实验室,太原 030051
针对HEVC帧内编码中递归式四叉树编码单元(Coding Unit,CU)划分引起的高计算复杂度问题,提出了基于随机森林分类(Random Forest Classifier,RFC)的CU快速划分算法。该算法包括模型离线训练和CU快速编码算法两部分。在模型离线训练中,将CU最佳划分结果(+1,-1)作为分类标签,将当前CU的对比度、逆差矩和熵信息作为特征属性,训练RFC模型。在编码时,提取当前CU的特征属性值,利用训练好的RFC模型快速预测当前CU的划分结果。实验结果表明,该算法与HEVC的标准算法相比,在保证编码质量的前提下,平均可以节约45.18%的编码时间。
随机森林;快速编码;离线训练;CU划分;HEVC
1 引言
近年来,高清、超高清视频应用逐渐走进人们的视野,各式各样的直播平台屡见不鲜,视频的高清化和应用场景的多样化对视频压缩技术提出了更高的要求。2013年,视频编码联合组(JCT-VC)制定了新一代视频编码标准——H.265/HEVC,与前代编码标准H.264/AVC相比,HEVC在同样的编码质量下能够节约50%的码率[1-2]。
HEVC实现高压缩率的关键技术之一是采用灵活的四叉树结构来组织编码单元CU、预测单元(Prediction Unit,PU)和变换单元(Transform Unit,TU),四叉树结构有多种划分层次,HEVC编码需要遍历所有的划分情况,并计算它们的率失真代价(Rate-Distortion Cost,RDCost),然后选择RDCost最低的划分作为最终编码方式,给编码器带来极高的计算复杂度,这也给实时性要求高的视频传输应用带来了很大的挑战。
目前,许多国内外学者针对以上问题提出了多种CU快速编码算法,这些算法主要分为两类:一类是基于图像的纹理特性或统计思想获得阈值来判断CU划分的深度级。文献[3]根据CU空间和相邻帧之间的纹理相关性,结合亮度直方图的密集度特征设置阈值,提高对CU划分深度的预测精度;文献[4]通过分析低量化参数(Quantization Parameter,QP)值时图像中不同CU尺寸的RDCost获取相应的终止阈值,提早结束CU递归划分。文献[5]利用贝叶斯方法统计不同层次下CU划分和不划分的RDCost,实现不同深度CU的早划分和早裁剪。这种通过对HEVC参考软件代码的优化方法可以使编码速度提升,但是实时应用的空间仍然有限。
另一类是采用机器学习的方法,在编码中将CU划分问题建模为分类问题,利用智能分类算法加快CU的预测划分。在HEVC编码方面,该方法的应用相对较少。文献[6]根据编码块的纹理特征,选择灰度差分统计熵和 SATD(Sum of Absolute Transformed Difference)的最小值为属性特征,利用决策树实现对CU的快速划分;文献[7]以互信息为标准统计编码块的特征,提出了基于贝叶斯分类的CU快速选择算法,以F-score方法统计CU的特征向量,提出了基于加权支持向量分类器的CU划分模型,快速决策当前CU的划分结果,降低HEVC的编码复杂度。
然而,在基于机器学习的算法中,单一的智能分类算法(决策树、贝叶斯和支持向量机)训练模型容易产生过拟合现象,预测准确率不是很高,最终影响视频播放的质量。因此,在集成学习的思想指导下,本文提出了基于随机森林分类的CU快速划分算法。本文算法包括两部分:模型离线训练和CU快速编码算法。在离线训练中,将CU的“划分(+1)”与“不划分(-1)”作为分类结果,选择能刻画CU的统计特征(对比度、逆差矩和熵)作为特征属性,构建RFC模型。在HEVC编码过程中,计算当前CU的特征属性值,导入线下训练好的RFC模型,预测当前CU的划分结果,在保证视频编码质量的同时,降低编码复杂度,推进编码标准的实时应用。
2 相关工作
2.1 HEVC帧内编码分析
HEVC编码时,每帧图像都被划分成一系列的编码树单元(Coding Tree Unit,CTU),编码时按照Z-Scan的方式,在CTU内部,采用基于四叉树的循环分层结构,CTU的划分示意图如图1所示。对于HEVC帧内编码,CTU(2N×2N,N∈{32,16,8,4})可以迭代地划分成四个CU,一直划分到最小编码单元(8×8),每一深度的CU又可以划分成2N×2N和N×N两种PU,每种PU进行35种帧内预测编码,并根据RDCost选择最佳PU模式。
判定一个CTU的最佳划分方式,一般需要进行1+4+42+43=85次RDCost计算,如图1中序号所示。
具体计算步骤如下:
(1)将CTU作为CU,计算其最小RDCost(最优PU模式时)。
(2)对当前CU进行四叉树划分,计算每个子CU的RDCost,并对该CU内所有子CU的最小RDCost求和,得到该CU的RDCost。
(3)每个子CU作为当前CU重复步骤(2)。
(4)重复步骤(3)直到最大编码深度。
(5)从最大编码深度,比较4个子CU与CU的RDCost,自底向上依次确定出当前CU的最佳划分方式。

图1 CTU四叉树递归划分结构示意图
由此可见,整个CTU的递归划分过程繁琐,计算量很大,研究CU快速划分算法具有重要的现实价值。
由以上分析可知,对CTU中的每个CU,都要考虑“划分(+1)”与“不划分(-1)”两类情况,由此想到,可以将CU的划分问题建模为一个二分类问题,选择适用的分类算法实现CU的快速划分预测。
分类算法众多,神经网络算法预测精确但是计算量大,决策树分类简单易实现却容易陷入局部最优,预测性能会随着数据量的增大而下降。这些单一的分类算法往往会产生过拟合现象,而随机森林[8](Random Forest,RF)可以避免这种现象,其实质是一个包含多个决策树的分类器,每棵树具有相同的分布,可以进行独立分类运算得到各自的分类结果,最终分类结果按决策树投票众数而定。随机森林作为一种新型集成分类器,具有用户设置参数少、人工干预少、分类精度高等优点,可以处理高维数据并快速得到分类结果,相对于其他传统分类方法具有良好的鲁棒性。
2.2 随机森林算法
随机森林算法是利用多棵树对样本进行学习训练并预测的一种组合分类器,森林中的每棵树是一个独立同分布的基本分类单元,随机森林是由两大随机化思想决定的,即1996年Breimans提出的Bagging思想[9]和1998年Ho提出的随机子空间(random subspace)思想[10]。
Bagging算法是基于自助聚集(Bootstrap aggregating)方法重采样产生多个训练集,即采用有放回的方式,从原始训练样本集中随机等量抽取样本,重复K次,生成K个新的训练样本集。随机子空间思想是在对每棵决策树的每个节点(非叶节点)进行分裂时,从所有特征属性集中随机等概率地抽取一个子属性集,然后从这个子属性集中选择一个最优属性来分裂节点。森林中的每棵决策树由随机抽取样本和随机抽取属性的方式建立,多棵树组合起来称为“随机森林”。
随机森林生成后,取一个新的样本进行测试,森林中的每棵树都会独立判定分类结果,最终决策取相同判定最多的分类类别,用公式表示如下:

公式(1)中,H(x)表示组合分类模型,hi(x)是单个分类树模型,Y表示输出变量,I(⋅)为示性函数(即当集合内有此数时,函数值为1,否则为0)[11]。
2.3 节点分裂算法
节点分裂是随机森林算法的核心步骤,在随机决策树的训练过程中,需要一次次地将训练数据集分裂成两个子数据集,每棵树的分支的生成,都是按照某种分裂规则选择属性。本文随机森林算法采用CART(Classification And Regression Tree)节点分裂算法,分裂规则是gini指标最小原则。gini值越小,说明划分的子集纯度越高。计算过程如下:
(1)计算样本的gini指标

其中,P(Ci)代表类别,Ci∈{+1,-1}在样本集S中出现的概率,l=2。
(2)计算每次划分的gini指标
S被分割成两个子集S1与S2,则此次划分的gini系数为:

3 基于随机森林分类的帧内CU快速划分算法
编码单元CU的划分问题可以建模为二分类问题,“+1”表示划分,“-1”表示不划分,利用图像纹理信息与CU划分的密切关系,选择图像的统计特征对比度、逆差矩和熵作为分类的特征属性,离线训练RFC模型。编码时,提取当前CU的特征值,输入到RFC模型中,得到当前CU的预测值,再根据该预测值决定当前CU的划分过程。
3.1 RFC模型建立
3.1.1 属性选择
在分类问题中,模型分类效果的优劣取决于属性特征的选取。本文选择表3中的测试序列“Traffic”、“ParkScene”、“RaceHorses”、“BasketballDrill”和“Johnny”进行HEVC编码。图2给出了“RaceHorses”第五帧的CU划分结果。从编码实例分析可知,编码块的某些统计特征与CU的划分尺寸有着密切的关系,灰度级共生矩阵可用来描述编码块的纹理特征信息,它可以反映出图像灰度关于方向、相邻间隔、变化幅度等综合信息,经统计,其中四个方向(0°、45°、90°、135°)上的特征量(对比度、逆差矩和熵)与编码单元CU的划分结果关系最密切。因此,本文选择编码单元在以上4个方向上的对比度、逆差矩和熵作为输入数据的特征属性变量,建立更加准确的分类器,进而提升编码器的编码性能。

图2 HEVC编码器的CU划分结果示意图
3.1.2 参数设置
CTU采用基于四叉树的分层递归划分方式,尺寸大小为8×8的CU不需要进行划分,根据CU的层次不同,需要建立3个分类器,即CU大小分别为64×64(CuDepth=0)、32×32(CuDepth=1)和16×16(CuDepth=2)的RFC模型。
随机森林算法中,训练样本集的大小会影响RFC模型的训练时间和分类性能。本文选用HEVC通用测试序列(表3)中不同分辨率、不同帧率的五个测试序列Traffic、ParkScene、RaceHorses、BasketballDrill和 Johnny作为训练序列,每个训练序列编码前50帧,提取不同CU深度的特征属性,其中前20帧作为训练样本集S,余下30帧作为测试集T。由于CU的划分层次不同,训练样本集 S分为三类:S0、S1和 S2,分别表示CuDepth=i的训练样本集(i=0,1,2),同样测试集T可以分为T0、T1和T2。
RFC模型训练中,决策树的数量(nTrees)和特征属性的随机选取个数(nFeatures)这两个参数对随机森林的分类精度都有极大的影响。目前对于随机森林参数的选择多采用经验值方式,经验值往往不够准确,为了在运行效率可接受的范围内选择出最佳的参数组合(nTrees,nFeatures),本文采用了基于网格搜索的参数寻优方法,以训练样本的分类准确率(Accuracy)为目标,通过大量实验分析,同时考虑RFC分类性能和训练模型的复杂度,最终选择(22,5)作为最佳参数组合值。
RFC模型建立的相关训练参数设置如表1所示。
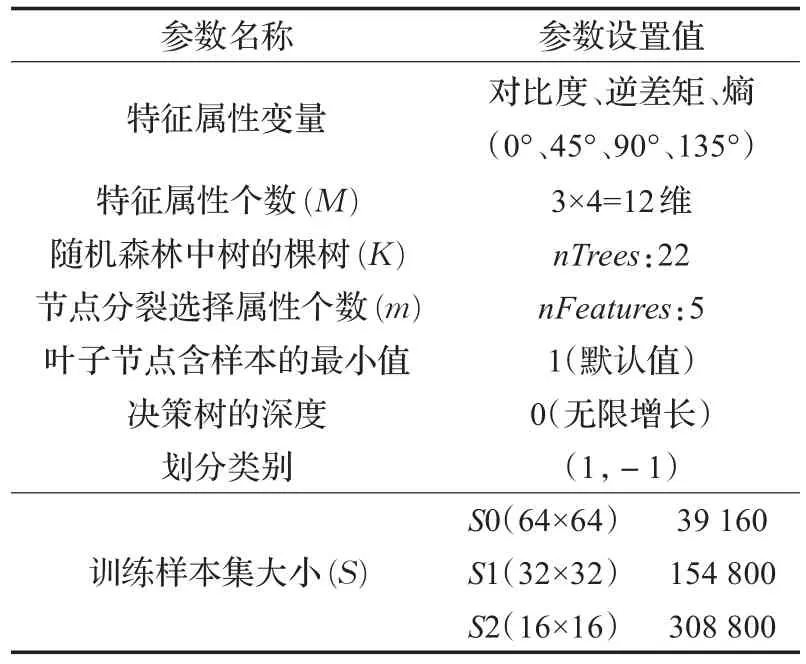
表1 训练参数设置
3.1.3 离线训练
根据表1设定参数,RFC模型进行离线训练,建立过程如图3所示。
具体步骤描述如下:
(1)给定训练样本集S和测试集T。
(2)利用Bootstrap法重采样数据样本集S,生成K个训练样本集{S*1,S*2,…,S*K},每次没有被抽到的样本组成K个袋外数据集;将生成的每个训练集S*i作为根节点,生成对应的决策树{T1,T2,…,TK}。
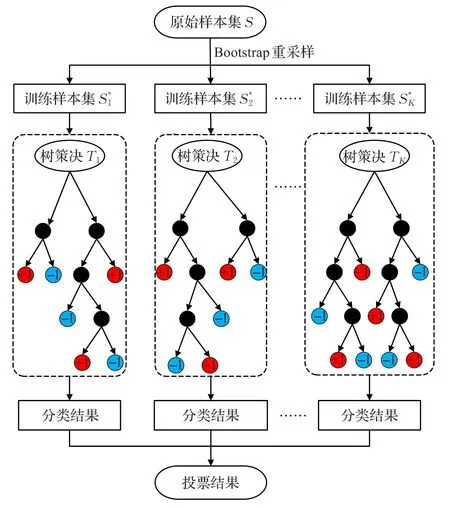
图3 随机森林分类模型的生成
(3)从根节点开始训练,在决策树的每个中间节点(非叶节点)上随机选择m个属性(m≪M,M为特征属性变量个数),遍历计算每个属性的gini指标系数,从中选择gini值最小的属性作为当前节点的最优分裂属性,以当前gini值为分裂阈值,划分为左右子树。
(4)重复步骤(3),训练K次,直到K棵决策树训练完成,每棵决策树都完整生长而不进行剪枝。
(5)将生成的多棵决策树组成随机森林,用随机森林分类器(RFC)对测试集T进行判别分类,分类结果采用投票方式,将K棵决策树输出最多的类别作为测试集T的所属类别。
3.1.4 训练测试评估
利用HM编码器对CU的划分结果,选择测试集T和10折交叉验证法(Cross Validation,CV)法来测试评估不同训练模型对CU的划分性能,实验过程中统计不同RFC模型的训练时间,所得RFC(0)、RFC(1)和RFC(2)的平均训练时间如表2所示,RFC(i)表示CUdepth=i时的RFC模型(i=0,1,2),RFC模型训练属于离线训练过程,训练好的模型被导入到HM编码器中用于CU的预测划分,因此,训练时间不计入序列的编码时间。表2还列出了训练好的模型在不同CU层次下预测的准确率。从表2可看出利用RFC模型预测CU划分的平均准确率为90.18%,综合考虑编码性能和编码复杂度,基于随机森林的分类模型适合编码单元CU的划分判定。

表2 不同RFC模型的训练时间和预测准确率
3.2 基于随机森林分类的CU快速划分算法
将CU的划分问题建模为分类问题,本文利用随机森林分类器预测CU的划分结果,其算法流程如图4所示,具体步骤描述如下。

图4 基于随机森林分类的CU划分算法流程图
步骤1对于一个CTU,从CuDepth=0开始编码。
步骤2计算当前CU的特征属性值。
步骤3加载训练好的RFC(i),对当前CU预测划分结果(i=0,1,2)。
步骤4如果判定当前CU划分,CuDepth加1,并将当前CU划分成4个Sub-CUs,然后返回步骤2继续执行;否则,编码当前层次下一个CU,返回步骤2执行。
步骤5结束当前CTU的编码,开始编码下一个CTU。
4 实验结果及分析
4.1 实验参数配置与算法性能评定
本文实验在配置为4.00 GHz,内存为8.00 GB计算机上的Visual Studio 2012环境上运行。
本文算法基于HEVC参考软件HM-16.0[12]实现。编码方案采用通用测试条件[13]中的全帧内编码模式,即All-Intra-Main(AI-Main)配置文件。量化参数QP分别选用22,27,32,37,测试序列选择表3中除用于训练序列(Traffic、ParkScene、RaceHorses、BasketballDrill和Johnny)之外的剩余序列,每个测试序列编码100帧。
实验中对本文算法的峰值信噪比变化量BDPSNR(dB)和码率变化率BDBR(%)[14]进行统计,分析了算法的率失真性能。为了衡量计算复杂度[15]的变化,实验统计了使用本文算法的编码时间变化率ΔT,计算方法如公式(4):

公式(4)中,timeHM16.0(Q Pi),timeproposed(Q Pi)分别表示HM16.0编码器和本文算法在不同QP值时的编码时间,ΔT为4个QP值下编码时间的均值。

表3 HEVC通用测试序列
4.2 算法性能比较分析
为了全面评估本文算法的性能,将本文算法与HM编码器和文献[6]算法进行了比较,实验结果如表4所示。
从表4中可以看出,与HM16.0编码器算法相比,本文算法平均减少45.18%的编码时间,同时保持了与HM16.0相近的率失真性能,BDBR平均增加了1.23%,BDPSNR平均降低了0.048 dB。此外,本文算法在编码时间和率失真性能方面都优于文献[6]中的方法。文献[6]中的算法是利用单一决策树实现对CU的预测划分,决策规则简单易实现,但是在训练模型尤其是遇到噪音数据时,很容易出现过拟合现象,降低分类精度。本文算法将多棵树集成森林,利用集成学习中的随机森林分类算法,多数投票实现对CU的预测划分,在提高预测精度的同时还降低了编码复杂度。

表4 本文算法和文献[6]算法在AI-Main环境下与HM性能比较

图5 不同算法在AI-Main编码配置环境下的率失真性能比较
图5 以视频序列“PeopleOnStreet”(2 560×1 600)和“BQMall”(832×480)为例,给出了HM16.0编码器、文献[6]算法和本文算法在AI-Main编码配置环境下的率失真性能比较。其中Y-PSNR为亮度Y峰值信噪比,Bitrate为每秒码流的大小。
从图5(a)、(b)两组实验可看出,与HM和文献[6]相比,PeopleOnStreet和BQMall序列在不同的码率下表现略有差异,但是本文算法的编码性能与HM相比没有显著的下降,而且比文献[6]的效果要好。在算法编码性能损失几乎可以忽略的情况下,比文献[6]算法还能减少约11.51%的时间。因此,本文提出的快速编码算法能够实现较好的编码器性能。
5 结束语
本文针对HEVC帧内编码过程中,编码单元CU划分过程计算复杂度高的问题,提出了基于机器学习随机森林分类的CU快速划分算法。该算法包括RFC模型训练和CU快速编码两部分。在离线训练时,根据视频内容与CU划分的密切关系,选择当前CU的统计特性(对比度、逆差矩和熵)作为模型训练的特征属性,以CU是否划分{1,-1}为分类结果,进行学习训练。在编码过程中,计算当前CU的特征属性值,利用离线训练好的RFC模型快速判断当前CU的划分结果,从而降低HEVC的编码复杂度。实验证明,在几乎相同的率失真性能情况下,本文算法比HEVC编码器提高了45.18%的编码速度,而且本文算法比文献[6]的快速算法,还能提高约11.51%的编码速度。下一步将继续研究帧间编码过程中CU划分与编码块的统计特性间的关系,最终选择更合适的编码方法,进一步加快HEVC的编码速度。
[1]万帅,杨付正.新一代高效视频编码H.265/HEVC:原理、标准与实现[M].北京:电子工业出版社,2014:12.
[2]Sullivan G J,Ohm J,Han W J,et al.Overview of the high efficiency video coding(HEVC) standard[J].IEEE Transactions on Circuitsamp;Systems for Video Technology,2012,22(12):1649-1668.
[3]金智鹏,代绍庆,王利华.HEVC帧内编码单元快速划分算法[J].南京邮电大学学报:自然科学版,2015,35(2):58-63.
[4]刘柱寨.新一代视频编码标准HEVC参考帧设置与块划分快速算法研究[D].广州:华南理工大学,2014.
[5]Cho S,Kim M.Fast CU splitting and pruning for suboptimal CU partitioning in HEVC intra coding[J].IEEE Transactions on Circuitsamp;Systems for Video Technology,2013,23(9):1555-1564.
[6]Zheng Xing,Zhao Yao,Bai Huihui,et al.Fast algorithm for intra prediction of HEVC using adaptive decision trees[J].Ksii Transactions on Internetamp;Information Systems,2016,10(7):3286-3300.
[7]沈晓琳.HEVC低复杂度编码优化算法研究[D].杭州:浙江大学,2013.
[8]Breiman L.Random forests[J].Machine Learning,2001,45(1):5-32.
[9]Breiman L.Bagging predictors[J].Machine Learning,1996,24(2):123-140.
[10]Ho T K.The random subspace method for constructing decision forests[J].IEEE Transactions on Pattern Analysisamp;Machine Intelligence,1998,20(8):832-844.
[11]方匡南,吴见彬,朱建平,等.随机森林方法研究综述[J].统计与信息论坛,2011,26(3):32-38.
[12]JCT-VC of ISO/IEC and ITU-T.HM reference software16.0[EB/OL].(2014).https://hevc.hhi.fraunhofer.de/trac/hevc/browser#tags/HM-16.0.
[13]Bossen F.Document JCTVC-L1100:Common test conditions and software reference configurations[C]//Proceedings of the 12th Meeting of Joint Collaborative Team on Video Coding(JCT-VC) of ITU-T SG16 WP3 and ISO/IEC JTC1/SC29/WG11,2013.
[14]Bøntegaard G.Document VCEG-M33:Calculation of average PSNR differences between RD-curves[C]//VCEG Meeting(ITU-T SG16 Q.6),2001.
[15]Bossen F,Bross B,Suhring K,et al.HEVC complexity and implementation analysis[J].IEEE Transactions on Circuitsamp;Systems for Video Technology,2012,22(12):1685-1696.
WU Xiaorong1,SHI Zhibin1,LEI Haiwei2,DU Bo1
1.School of Computer and Control Engineering,North University of China,Taiyuan 030051,China 2.Key Laboratory of Instrumentation Scienceamp;Dynamic Measurement,Ministry of Education,North University of China,Taiyuan 030051,China
Fast CU partition algorithm for HEVC intra-frame based on random forest classifier.Computer Engineering and Applications,2017,53(21):115-120.
To reduce the coding computational complexity of the quadtree structured Coding Unit(CU)partition process forintra-framein High Efficiency Video Coding(HEVC),a fast CU splitting algorithm based on Random Forest Classifier(RFC)is proposed.The algorithm includes two parts:model off-line training and CU fast coding algorithm.In the process of off-line training,a RFC model is constructed,where the optimal partition result of current CU is utilized as class label(+1,-1),and the contrast,the inverse different moment and the entropy information of current CU are treated as feature vectors.In the process of encoding,characteristic attribute values of current CU are extracted,then,a trained RFC model is used to predict the class label.The experimental results show that the proposed algorithm can save 45.18%coding time on average under the premise of guaranteeing the coding quality compared with HEVC standard algorithm.
random forest;fast encoding;offline training;CU partition;High Efficiency Video Coding(HEVC)
A
TN919.81
10.3778/j.issn.1002-8331.1704-0115
2015年度山西省高校科技创新项目(No.20151101)。
毋笑蓉(1992—),女,硕士研究生,主要研究领域为视频编码、智能分类算法,E-mail:1035737097@qq.com;师智斌(1971—),女,博士,副教授,主要研究领域为人工智能、数据挖掘、模式识别;雷海卫(1980—),男,博士研究生,讲师,主要研究领域为视频信号处理、3D视频编码;杜博(1990—),男,硕士研究生,主要研究领域为视频信号处理、3D视频编码。
2017-04-11
2017-06-19
1002-8331(2017)21-0115-06
猜你喜欢
防爆电机(2021年4期)2021-07-28 07:42:46
中国特种设备安全(2021年11期)2021-05-05 06:13:18
铁道通信信号(2020年6期)2020-09-21 09:23:34
成都信息工程大学学报(2019年3期)2019-09-25 08:31:20
中国惯性技术学报(2019年6期)2019-03-04 09:50:10
电子制作(2018年16期)2018-09-26 03:27:06
中成药(2018年2期)2018-05-09 07:20:09
中央民族大学学报(自然科学版)(2017年2期)2017-06-11 07:14:54
中央民族大学学报(自然科学版)(2016年4期)2016-06-27 08:06:04
火控雷达技术(2016年3期)2016-02-06 02:30:28
