
多领域机器翻译中的非参贝叶斯短语归纳
2017-11-22 08:47刘宇鹏马春光朱晓宁乔秀明
哈尔滨工程大学学报 2017年10期
刘宇鹏,马春光,朱晓宁,乔秀明
(1.哈尔滨理工大学 软件学院,黑龙江 哈尔滨 150001; 2.哈尔滨工程大学 计算机科学与技术学院,黑龙江 哈尔滨 150001; 3.哈尔滨工业大学 计算机学院,黑龙江 哈尔滨 150001)
多领域机器翻译中的非参贝叶斯短语归纳
刘宇鹏1,2,马春光2,朱晓宁3,乔秀明3
(1.哈尔滨理工大学 软件学院,黑龙江 哈尔滨 150001; 2.哈尔滨工程大学 计算机科学与技术学院,黑龙江 哈尔滨 150001; 3.哈尔滨工业大学 计算机学院,黑龙江 哈尔滨 150001)
多领域机器翻译一直以来都是机器翻译领域研究的重点,而短语归纳是重中之重。传统加权的方法并没有考虑到整个归约过程,本文提出了一种使用层次化的Pitman Yor过程进行短语归约,同时把多通道引入到模型中,使得在短语归约的过程中平衡各领域的影响;从模型角度,本文的方法为生成式模型,模型更有表现力,且把对齐和短语抽取一起建模,克服了错误对齐对原有短语抽取性能的影响。从复杂度上来说,该模型独立于解码,更易于训练;从多领域融合来说,对短语归约过程中进行融合,更好地考虑到整个归约过程。在两种不同类型的语料上验证了机器翻译的性能,相对于传统的单领域启发式短语抽取和多领域加权,BLEU分数有所提高。
多领域机器翻译; 非参贝叶斯; 短语归纳; Pitman Yor过程; 生成式模型; 块采样; 中餐馆过程; BLEU分数
随着互联网技术的快速发展,信息增长的速度越来越快,更加凸显出了自然语言处理和机器翻译任务的重要性。领域自适应作为机器翻译任务的一个重要应用,一直吸引着很多研究者投入其中,关于这个方面的研讨会也是数不胜数。近几年来非参数贝叶斯模型已成为统计学、机器学习等领域内研究的热点,其基本方法为将一个复杂分布分解为简单分布(有限或无限个)的加权平均,根据训练数据来确定训练模型中简单分布的个数。非参数贝叶斯模型是常用的数据分布拟合工具之一,需要假设参数服从先验分布,为了后验概率推断方便,一般采用共轭先验。非参数贝叶斯模型解决了参数学习的随着数据增长模型参数个数不变,也解决了非贝叶斯学习无参数先验信息的问题。流行的非参数贝叶斯模型很多,如Beta过程、高斯过程、狄利克雷过程(dirichlet process, DP)等[1-3]。这些模型在自然语言处理诸多领域都有应用,如语言模型[4]、词性标注[5]、短语归纳等[6-10]。狄利克雷过程作为一种随机过程(stochastic process,SP)是有限维狄利克雷分布的推广,是无限维分布上的分布;从另一个角度来说,狄利克雷过程也是一种随机度量,每一种划分都会得到一种狄利克雷分布。由于作为无限维的狄利克雷过程描述起来和构造相对困难,有几种等价形式来解决这些问题,如中餐馆过程(chinese restaurant process)、波利亚罐子模型(polya urn scheme)和截棒过程构造(stick breaking construction)等。狄利克雷过程有很多变形,如PYP[10]、层次化的狄利克雷过程(hierachical dirichlet process,HDP)[11-12]、依存DP[13]和非参树模型[14]等,这些模型面向于不同的任务,很好的符合了任务的建模过程。
短语归纳[6-10]作为机器翻译系统的重要组成部分,一直是研究的重点。传统的方法是把单词对齐和短语抽取看成两个过程,而这样会把对齐错误引入到短语抽取过程中,且抽取过程无法考虑到对齐信息。本文主要把非参数贝叶斯模型中的狄利克雷过程应用到机器翻译的短语归纳中。本文的方法可以归为从不同领域的数据出发基于实例权重的翻译模型融合方法[11]。本文主要创新是在多个领域归约短语表时候进行模型级融合。
1 机器翻译概率模型
整个机器翻译过程为先进行训练以获得翻译过程使用的短语对,接着使用这些短语对进行解码,两个过程是息息相关的。翻译过程为给定训练语料

(1)
本文认为在解码过程中隐含着训练过程中的参数集Θ(包括翻译模型的权重,扭曲模型和语言模型的权重等),即贝叶斯框架为
P(e|f,
(2)
式中:P(Θ|
P(Θ|
(3)
式中:P(
P(
(4)
2 翻译模型描述
2.1短语归约的产生式模型
在机器学习中,按照建模对象的不同,可以分为产生式模型(联合概率建模)和判别式模型(条件概率建模)。本文采用产生式模型,可以根据产生式模型得到判别式模型的条件概率。同步上下文无关文法(synchronous context-free grammar, SCFG)的规则不是都可以转换成反向转录语法(inversion transduction grammar, ITG),但是使用转换后的文法对于机器翻译性能几乎没有影响[16]。基于这点,本文采用ITG进行短语归约。传统方法对于最小短语对进行建模,忽略了更大粒度的短语,本文采用文献[9]的方法,可生成各种粒度的短语,不需要通过小粒度短语启发式的生成大粒度的短语,同时相对文献[7]中的方法有更少生成操作,模型训练起来更加容易。
从形式化上,句子似然概率P(
由于规则类型的不同,左右子节点的情况也不一样,所以把子节点用椭圆圈起来。按照无限维的HMM[17],本文把一个规则的生成过程拆分成3个部分: 1)根据短语对隐参数θt产生该规则的根节点短语; 2)根据规则隐参数θx生成该规则类型; 3)根据规则类型和短语对隐参数θt生成当前父节点短语zi的子节点短语lzi和rzi。ITG文法中的一元规则和二元规则对应了3种规则类型:一元规则的发射类型、二元规则的正向调序和反向调序。规则类型隐参数θx服从于Dirichlet分布,θt服从于无限维的PYP。 PYP相对于Dirichlet过程来说更加泛化,除了含有Dirichlet过程中两个参数:基分布超参H(用于获得概率分布的位置)和强度超参s(用于控制分布和基分布拟合情况),还增加了打折超参d(使得聚类特性满足幂律,虽然原来的Dirichlet过程中的参数会让富有的聚类更加富有,但无法满足幂律)。具体的算法如下:
θt~PYP(s,d,H)
θx~Dirichlet(α)
for each nodezi=
generatezi|θt~θt
generate a symbolxi|θx~θx
Ifxi=Emission then
zi|θt~θt, generateanewphrase
Ifxi=Monotone then
lzi|θt~θt,rzi|θt~θt, concatenatelziandrziwithmonotone
Ifxi=Reordering then
lzi|θt~θt,rzi|θt~θt, concatenatelzianrziwithreordering
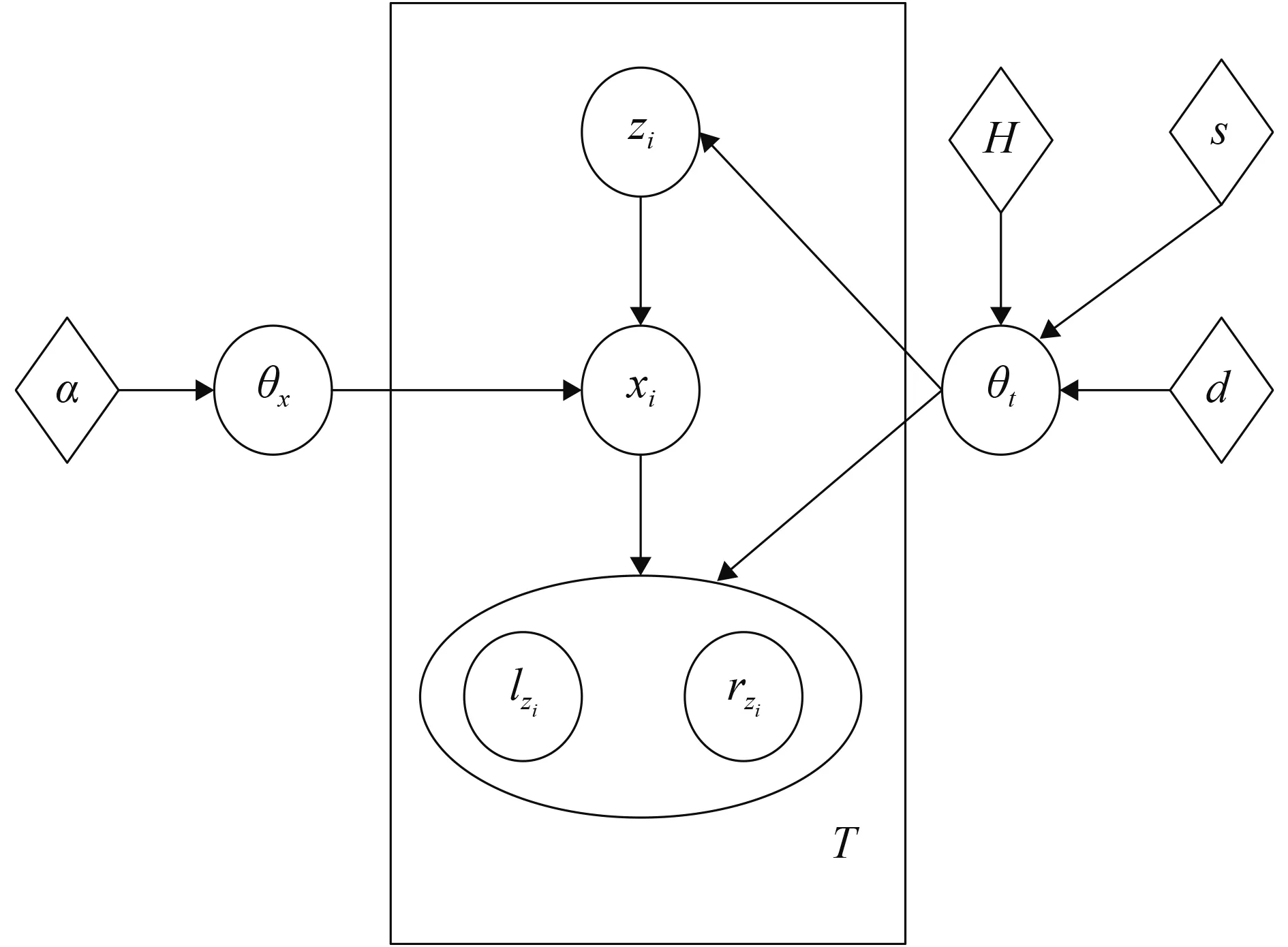
图1 部分推导树的图模型Fig.1 The graph model of partial derivation tree
2.2多领域短语归约模型
参照文献[18],假设不同领域的数据来自于不同数据分布,因此需要不同的通道来处理不同的数据分布,每个通道对应一个领域。进行多通道融合的时候,整个多领域短语归约的过程相当于分就餐区域的中餐馆过程。中餐馆过程刻画了多领域短语归约模型的聚类特性,只列出一个层次的,图2给出了多领域短语归约的图模型,图3为多领域归约的中餐馆过程。

图2 多领域的短语归约模型Fig.2 Multi-domain phrase induction model
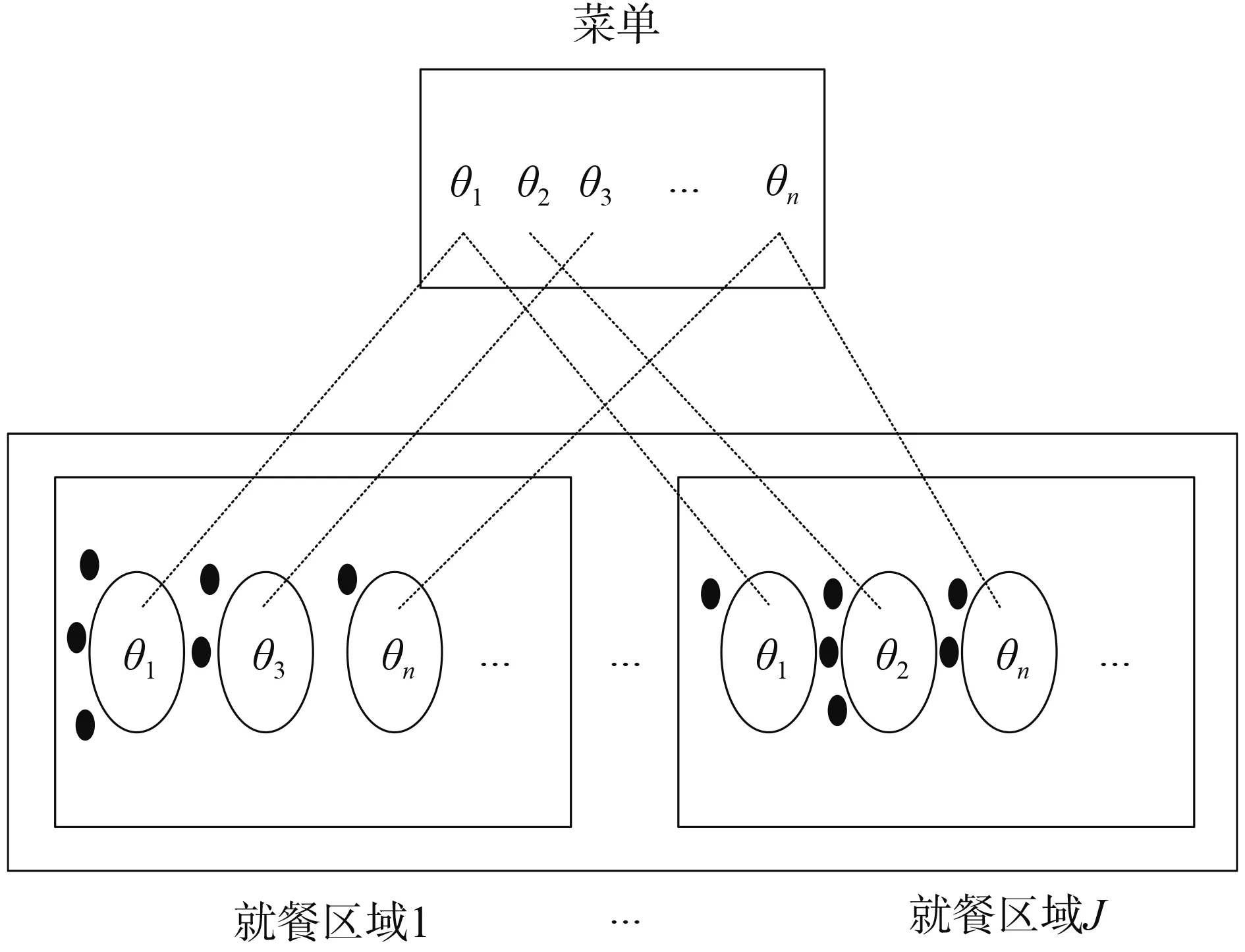
图3 多领域短语归约的CRP过程Fig.3 CRP procedure of multi-domain phrase induction
在图2中描述了不同领域的部分推导树共享同一个短语对隐参数θt,这里共有J个领域,每个领域中的短语对都根据共享参数生成。在图3中上一层相当于菜单(用于共享),下一层相当于顾客(表示短语,以黑点进行表示)进行就餐的过程,同一短语可以在同一就餐区域的不同桌子,也可以在不同的就餐区域。就餐区域相当于通道。θi是按照概率分布θt取出来的原子,而每个原子在下一层可以看成菜单。菜单中的每道菜为θi(1≤i≤n,表示上一层共生成了n道菜,注意建模过程是无限维,但生成的结果是固定维数的),下一层没有确定桌子的数量表示还没有完成所有的短语聚类。
3 归纳语约训练
对于单通道情况来说,每个短语对zi的后验预测概率为

(5)

式(5)可以描述为当一个顾客来到餐馆时有两种选择:


基础分布的概率定义如下:
(6)

本文提出的方法是在多通道下进行的,在计算总的后验预测概率的时候,需要对于每个通道中的后验预测概率进行加权平均
(7)
(8)

1)从所有含有推导的双语句对中选出一个句对,减少当前推导的短语对;
2)自底向上的对于句对进行双语分析并计算源语言的跨度概率;
3)根据跨度概率自底向上的采样一个推导;
4)增加新推导的短语对;
最终翻译的条件概率可以通过公式(8)计算。采样过程中需要对于每个桌子上的顾客数进行调整(顾客等可能的离开中餐馆),当桌子空时就把桌子取消掉。
4 翻译实验和分析
4.1翻译系统配置
实验中分别从口语翻译任务和常规文本翻译任务出发,采用两个数据集进行验证该方法的有效性,训练语料分别是来自IWSLT2012语料和LDC语料。其中IWLST2012含有HIT部分和BETC部分。LDC语料包括LDC2003E14、LDC2003E07、LDC2005T10、LDC2005E83、LDC2006E34、LDC2006E85、 LDC2006E92(总共含有500k的句对)。使用隐藏狄利克雷分配模型(LDA)对于LDC语料进行划分[20],划分时把中英文句子连接在一起共同反应同一领域。不需要对IWLST2012划分。在口语翻译任务中,语言模型的训练语料采用训练语料中的英文;翻译模型采用IWSLT2012提供的开发集(含有3k中英文句对)和测试集(含有1k中英文句对)。在常规文本翻译任务中,语言模型的训练语料采用英文GigaWord语料中xinhua部分和训练语料的英文句子;为了更好的度量翻译结果,在标准集NIST03(含有919中英文句对),NIST05(含有1 082中英文句对)和NIST06(含有1 664中英文句对)上进行,这些测试集即作为开发集又作为测试集,互相衡量的翻译性能,更加全面考虑机器翻译的性能。
为了更好的度量不同归约方法对于翻译系统的影响,翻译系统采用开源的Moses中的短语翻译系统[21],选用短语翻译系统的好处为忽略掉句法结构带来的影响。语言模型采用加入Kneser-Ney平滑的Srilm训练的五元模型[22]。翻译质量的度量采用大小写不敏感的BLEU[23],训练时采用20轮迭代的间隔注入的松弛算法(margin infused relax algorithm, MIRA),为了获得最好的参数权重,独立运行MIRA 10次,把获得最高BLEU分数的调参结果用到测试集上。采用文献[24]方法,所有的显著性测试在显著性水平为0.05下进行。
4.2不同短语归约方法的比较
在两种训练语料(不分领域)上进行比较,主要是体现本文归约方法的优越性。为了更好的比较采用3个基线系统:第一个基线系统为采用GIZA++ Model 4词对齐后,使用Grow-Diag-Final-And启发式获得两个方向的对齐,最后再抽取短语,该基线系统表示为Heu-Model4。第二个基线系统为选用文献[9]中方法,同本文相比使用了相似的调序建模,但是没有对于非终结符号中的短语进行建模;这个基线方法也使用了启发式方法抽取短语,只是在计算短语翻译概率的时候,利用了采样器获得的短语对分布;该基线系统表示为Ali-Phr-Heu-Com。本文提出的方法表示为Ali-Phr-Mod-Com,短语归约模型的最大短语长度为7。选用这3个基线系统的原因为:第一个基线系统是传统的短语抽取方法;第二个基线系统使用了相似的非参数贝叶斯方法,但是没有本文模型表现能力强(不同粒度的短语,层次化的PYP相对于非层次的DP)。
通过和Heu-Model4基线系统比较,发现Ali-Phr-Heu-Com系统提高了0.8;通过和Ali-Phr-Heu-Com基线系统比较,发现Ali-Phr-Mod-Com系统提高了0.42。总体来说,实验结果说明了Ali-Phr-Heu-Com系统好于传统的启发式方法。表1给出了在常规文本上的实验结果,使用典型的NIST翻译任务中语料作为开发集和测试集。

表1 在常规文本翻译任务上不同短语规约方法的比较表
表1的性能比较见表2。
总体来说,在3个测试集合上Ali-Phr-Heu-Com系统好于Heu-Model4系统,Ali-Phr-Mod-Com系统好于Ali-Phr-Heu-Com系统。

表2 表1系统的性能比较表Table 2 The performance comparison of table 1
4.3多领域短语归约的实验
在多领域实验中,除了对于第一个基线系统进行简单加权外,使用了经典翻译系统Moses的基于混淆度最小的自适应方法[25],该基线系统表示为Moses-Per。
表1和表3的性能比较见表4,在每个开发集上性能的提高说明了本文方法在更大规模的常规文章翻译任务的有效性。表3的性能比较见表5,说明本文方法的有效性。总体来说,通过不同多领域归约方法的比较,Ali-Phr-Mod-Com-DA系统相对于Ali-Phr-Heu-Com-DA提高的性能高于Ali-Phr-Heu-Com-DA系统相对于Heu-Model4-DA系统提高的性能,说明了本文方法对于强大基线系统的有效性。
不管是在多领域之间,还是在单领域和多领域之间,本部分的实验结果与在IWSLT2012的实验结果比较起来提高的性能较少,可能的原因是IWSLT2012中的2个领域比较明显的区别,而在常规文本中划分的领域区分性不大。从表1、2中可以看出Moses_Per好于Heu-Model4,但性能不多,可能的原因是本文已经尝试了很多种权重配置方案;本文的文本是正规化文本,从语言模型的角度区别性不是很大,所以导致基于语言模型评价标准的混淆度不能捕捉到更多领域间的信息。本文方法超过了Moses_Per,可能是因为更好考虑了每个短语生成过程中领域间相互影响,Moses_Per虽然考虑到了每个领域中实例情况,但没有考虑到每个实例生成过程。本文提出的单领域归约方法Ali-Phr-Mod-Com和多领域归约方法Ali-Phr-Mod-Com-DA超过了所有基线系统。

表3 在常规文本翻译任务上多领域归约的比较表

表4 表1和表3系统性能比较表

表5 表3系统的性能比较表
4 结论
1)本模型把传统对齐和短语抽取过程进行一起建模,在采样的过程中获得对齐;
2)本模型中含有ITG归约过程中每一层的短语,而且可以分治的回退到下一层从而生成粒度更细的短语。对于短语归约过程中每层产生规则和短语进行了详细的模型描述,并给出了进行采样估计概率时的后验预测概率;为了更好地理解多领域模型使用中餐馆过程进行描述;
3)在2种类型的语料上进行了验证,通过实验发现本文方法超过了经典的基线系统(包括传统方法和没有对于短语建模的非参数贝叶斯短语归约),且做了显著性测试以证明方法的统计意义。
从实验结果中可以看出,本文的建模方法对于SMT性能的提高起到了一定作用。
[1] THIBAUX R, JORDAN M I. Hierarchical beta processes and the indian buffet process[C]//Proceedings International Conference on Artificial Intelligence and Statistics.New York, USA, 2007: 564-571.
[2] RASMUSSEN C E, WILLIAMS C K I. Gaussian processes for machine learning[M]. USA: MIT Press, 2006.
[3] NEAL R M. Bayesian mixture modeling[C]//Proceedings of the Workshop on Maximum Entropy and Bayesian Methods of Statistical Analysis. Philadelphia, USA, 1992: 197-211.
[4] GOLDWATER S, GRIFFITHS T. A Fully Bayesian approach to unsupervised part-of-speech tagging[C]//Proceedings of the Annual Meeting of the Association for Computational Linguistics. Czech Republic, 2007: 744-751.
[5] BLUNSOM P, COHN T. Inducing synchronous grammars with slice sampling[C]//In Proceedings of the Human Language Technology: The 11th Annual Conference of the North American Chapter of the Association for Computational Linguistics. Los Angeles, California, USA, 2010: 238-241.
[6] BLUNSOM P, COHN T, DYER C, et al. A gibbs sampler for phrasal synchronous grammar induction[C]//Proceedings of the 47th Annual Meeting of the Association for Computational Linguistics. Singapore, 2009: 782-790.
[7] DENERO J, BOUCHARD-COTE A, KLEIN D. Sampling alignment structure under a bayesian translation model[C]//Proceedings of the Conference on Empirical Methods in Natural Language Processing. Waikiki, Honolulu, Hawaii, 2008: 314-323.
[8] KAMIGAITO H, WATANABE T, TAKAMURA H, et al. Hierarchical back-off modeling of hiero grammar based on non-parametric bayesian model[C]//Proceedings of the Conference on Empirical Methods in Natural Language Processing. Lisbon, Portugal, 2015: 1217-1227.
[9] NEUBIG G, WATANABE T, SUMITA E, et al. An unsupervised model for joint phrase alignment and extraction[C]//The 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies (ACL-HLT). Portland, Oregon, USA, 2011: 632-641.
[10] TEH Y W. A hierarchical bayesian language model based on pitman-yor processes[C]//Proceedings of the 21st International Conference on Computational Linguistics and 44th Annual Meeting of the Association for Computational Linguistics. New York, USA, 2006: 985-992.
[11] LIANG P, PETROV S, JORDAN M I, et al. The infinite pcfg using hierarchical dirichlet processes[C]//In Proceedings of the Conference on Empirical Methods in Natural Language Processing. Prague, Czech REpublic, 2007: 688-697.
[12] TEH Y W, JORDAN M I, BEAL M J, et al. Hierarchical dirichlet processes[J]. Journal of the American statistical association, 2006, 1(101): 1566-1581.
[13] MACEACHERN S, KOTTAS A, GELFAND A. Spatial nonparametric bayesian models[C]//Proceedings of the 2001 Joint Statistical Meetings. New York, USA, 2001: 1-12.
[14] BLEI D M, GRIFFITHS T L, JORDAN M I, et al. Hierarchical topic models and the nested Chinese restaurant process[C]//Advances in Neural Information Processing Systems.New York,USA, 2004: 17-24.
[15] ZHU Conghui, WATANABE T, SUMITA E, et al. Hierarchical phrase table combination for machine translation[C]//Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics. Sofia, Bulgaria, 2013: 802-810.
[16] ZHANG Hao, HUANG Liang, GILDEA D. Synchronous binarization for machine translation[C]//Proceedings of the 2006 Meeting of the North American Chapter of the Association for Computational Linguistics (NAACL-06). New York, USA, 2006: 256-263.
[17] XU Z, TRESP V, YU K, et al. Infinite hidden relational models[C]//Proceedings of the Conference on Uncertainty in Artificial Intelligence. Cambridge, MA, USA,2006: 53-62.
[18] BRODY S, LAPATA M. Bayesian word sense induction[C]//Proceeding of the 12th Conference of the European Chapter of the Association for Computational Linguistics Association for Computational Linguistics. Singapore, 2009: 103-111.
[19] KAMIGAITO H, WATANAB T, TAKAMURA H. Hierarchical back-off modeling of hiero grammar based on non-parametric bayesian model[C]//Proceedings of the Conference on Empirical Methods in Natural Language Processing. Lisbon, Portugal, 2015: 1217-122.
[20] LIU Zhiyuan, ZHANG Yuzhou, CHANG E Y, et al. Plda+: parallel latent dirichlet allocation with data placement and pipeline processing[C]//ACM Transactions on Intelligence Systems and Technology. New York, 2011: 1-18.
[21] KOEHN P, HOANG H, BIRCH A, et al. Moses: open source toolkit for statistical machine translation[C]//Proceedings of the 45th Annual Meeting of the ACL on Interactive Poster and Demonstration Sessions. ACL, Stroudsburg, USA, 2007: 177-180.
[22] STOLCKE A. Srilm-an extensible language modeling toolkit[C]//Proceeding of The International Conference on Spoken Language Processing 2002. Denver, USA, 2002: 332-330.
[23] PAPINENI K, ROUKOS S,TODDWARD D, et al. Bleu: a method for automatic evaluation of machine translation[C]//Proceedings of 40th Annual Meeting of the Association for Computational Linguistics.Philadelphia, Pennsylvania, USA, 2002: 311-318.
[24] KOEHN P. Statistical significance tests for machine translation Evaluation[C]//Proceedings of the Conference on Empirical Methods in Natural Language Processing. Barcelona, Spain,2004: 231-239.
[25] SENNRICH R. Perplexity minimization for translation model domain adaptation in statistical machine translation[C]//Proceedings of The European Chapter of the Association for Computational Linguistic. Avignon, France, 2012: 539-549.
本文引用格式:刘宇鹏,马春光,朱晓宁,等. 机器翻译中多领域的非参贝叶斯短语归纳[J]. 哈尔滨工程大学学报, 2017, 38(10): 1616-1622.
LIU Yupeng, MA Chunguang, XIAONING Zhu, et al. Bayesian non-parametric phrasal induction of domain adaptation in machine translation[J]. Journal of Harbin Engineering University, 2017, 38(10): 1616-1622.
Multi-domainbayesiannon-parametricphrasalinductioninmachinetranslation
LIU Yupeng1,2, MA Chunguang2, Zhu Xiaoning3, Qiao Xiuming3
(1. School of Software, Harbin University of Science and Technology, Harbin 150001, China; 2.College of Computer Science and Technology, Harbin Engineering University, Harbin 150001, China; 3.School of Computer Science and Technology, Harbin Institute of Technology, Harbin 150001, China)
Domain adaptation has always been a key research field of machine translation, in which phrase induction is a top priority. The traditional weighted method did not take into account the entire phrase induction process. This paper proposed a method that uses hierarchical Pitman-Yor process to extract phrase pairs. Multiple channels were introduced into the model to balance the weight of various fields in the phrase induction process. From the point of the model, the generative model was expressive, and the alignment and phrase extraction were modeled together, which overcame the effect of wrong alignment on the original phrase extraction performance. From the view of complexity, the model is independent of decoding and easy to train. From the perspective of multi-domain combination, the process of phrase reduction combination takes into account the entire reduction process better. Machine translation performance was validated on two different types of corpus. Compared with the traditional method of weighted multi-domain and heuristic phrase extraction in single domain, the performance measured by BLEU score was improved.
multi-domain machine translation; Bayesian non-parameter; phrasal induction; Pitman-Yor process (PYP); generative model; block sampling; Chinese restaurant process; BLEU score
10.11990/jheu.201605081
http://www.cnki.net/kcms/detail/23.1390.U.20170816.1550.038.html
TP391.2
A
1006-7043(2017)10-1616-08
2016-05-24. < class="emphasis_bold">网络出版日期
日期:2016-08-16.
国家自然科学青年基金项目(61300115);中国博士后科学基金项目(2014M561331);黑龙江省教育厅科技研究项目(12521073).
刘宇鹏(1978-),教授.
刘宇鹏,E-mail:flyeagle99@126.com.
猜你喜欢
通信技术(2021年12期)2022-01-25
法律方法(2021年4期)2021-03-16
科学(2020年5期)2020-11-26
中国惯性技术学报(2019年3期)2019-10-15
舰船电子对抗(2016年5期)2016-12-13
铁道通信信号(2016年6期)2016-06-01
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
民族古籍研究(2014年0期)2014-10-27
外语教学理论与实践(2014年2期)2014-06-21
航天器工程(2014年5期)2014-03-11
