
扇束滤波反投影算法在DSP中的移植及加速
2017-11-21 04:56公安部检测中心井冰张凡忠芦朋张啸
中国安全防范技术与应用 2017年5期
■ 文/公安部检测中心 井冰 张凡忠 芦朋 张啸
扇束滤波反投影算法在DSP中的移植及加速
■ 文/公安部检测中心 井冰 张凡忠 芦朋 张啸
本文针对扇束滤波反投影算法在定点DSP中的移植和加速进行研究。首先介绍了滤波反投影算法在DSP移植过程中需要进行的文件配置、定点化、添加库函数等工作。其次针对滤波反投影算法的特点,并结合DSP硬件结构,总结出一整套的优化加速方案。最后,在TMS320C6455 DSK开发平台上进行实验。实验结果表明,优化加速方法获得较高加速比,DSP重建的图像有较高的质量。
扇束滤波反投影 DSP 缓存优化 流水线优化
1 引言
电子计算机断层扫描(CT)图像具有无影像重叠、空间和密度分辨率高、可直接进行数字化处理等优点,通过近十几年的发展已经成为非接触无损检测的主流技术,并广泛应用于安全检查领域。与医用CT相比,安检CT具有被检物品种类复杂、扫描和成像速度要求高、具有智能分析和报警等功能,这使得对安检CT的技术要求在很多方面超过了对医用CT的技术要求。
与通用处理器相比,数字信号处理器(DSP)采用将程序指令存储和数据存储分离的哈佛结构,指令系统采用流水线技术,具有良好的并行性,内部集成硬件乘加法器和高速存储器,适合大量重复性的乘加运算。近几年,基于DSP的CT图像重建加速引起广泛关注。文献[2]提出一种基于DSP的锥束CT图像重建的综合加速技术,通过C代码优化、汇编优化和编译器优化的综合使用,获得了较高的加速比;文献[3]利用三角函数的周期性减少运算规模,从算法的角度提高运算效率,同时引入查找表减少复杂运算的延迟;文献[4]介绍了DSP移植过程中的运算定点化方法,同时借助增强型直接内存存取(EDMA)构建双缓存结构,提高了数据的吞吐率,获得了较高加速比。
相对于浮点型DSP,定点DSP在主频、带宽、数据传输率及成本方面都具有明显优势。本文考虑将扇束滤波反投影(FBP)算法移植到TMS320C6455 DSK开发平台,并进行优化加速。首先介绍扇束滤波反投影算法,并研究滤波反投影算法移植到DSP的关键步骤和具体处理方法。其次,在确认移植成功后,从多个角度研究分析DSP加速方法。最后,从重建速度和重建图像质量两个方面对比分析软硬件重建的结果。
2 扇束滤波反投影算法介绍
本文采用的重建算法是扇束滤波反投影算法,图1为等距探测器扇束投影形成示意图。

图1 扇束滤波反投影算法所用坐标系统



S1为经过待建点的射线L与探测器的交点,U为加权因子,由图1所示几何关系有:
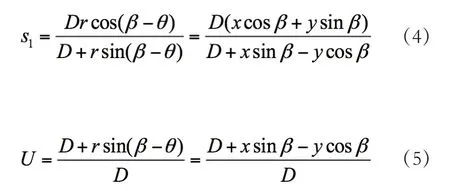
归纳起来主要包括投影加权、卷积滤波、加权反投影三步:
1)正弦图中的每一行一维投影信号每个点进行一次加权。
2)正弦图中的每一行一维投影信号和滤波器进行卷积。
3)反投影,实际是两部分,第一是计算投影地址,第二是根据投影地址插值累加求和。
文献[6]表明,这三部分的运算量分别占总运算量的0.0016%,1.6%,98.36%。
由式(1)~式(5)可知,滤波反投影算法的完成需要三重循环。若在360°扫描视角内,视图数为M,每个投影视角下采样点数为N个,要重构一个N×N的图像,需要M×N×N次式(4)所示的的计算。
3 扇束滤波反投影算法在DSP中的移植
3.1 动态存储分配函数
在算法移植过程中,若有malloc, new等内存分配函数,需要保留足够大的存储空间,将编译器选项中heap_size的值设置为足够大,否则内存分配函数会执行错误。若存储空间在片外,需要在第一次调用内存分配函数前,初始化相应的存储空间,否则函数可执行成功但空间指向未定。
3.2 配置.cmd文件
.cmd文件是设置指定程序和命令在存储器的资源配置,包含Memory和Section两部分。Memory用于划分L1缓存、L2缓存、EMIFA和DDR2的起始地址和大小,其中L1缓存和L2缓存可以根据需要配置成SRAM或者Cache;Section主要用于将不同程序和不同变量分配到指定的存储空间,特别要注意.system用于程序中的malloc、new等函数动态分配的存储空间。
3.3 变量定点化
IEEE-754标准是使用最广泛的浮点运算标准,为许多 CPU与浮点运算单元所采用。IEEE-754 标准规定的浮点数由三部分组成:符号位、指数位、尾数位。尾数由小数部分和隐含整数位1构成,它可表示成式(6)形式:

单精度浮点数由32比特构成,而双精度浮点数由64比特组成,其符号位、指数位和尾数位分布图2所示。

图2 单双精度浮点数数据位分布
编译环境支持直接表示为浮点的数据,即支持数据类型定义为 fl oat或double,但其在内存中是按指数形式存放的。定点DSP对于定义为浮点型的数据,无硬件单元直接进行计算,而是以整形数据形式,通过软件算法进行浮点运算,这将大大降低DSP的运算速度。
3.4 IQmath库的使用
IQmath库函数是经过高度优化的高精度数学运算函数,符合对精度和实时性要求高的场合。IQmath库能将浮点运算精确地转换成定点运算,并拥有比使用ANSI C语言编写的代码更快的运算速度。IQmath库里包含的函数都是采用Q格式定点数作为输入输出,支持从Q0到Q31的定点格式,并提供了专用的定点库函数,包括:格式转化函数、算数函数、三角函数、数学函数和其它函数。
IQmath库的使用时应注意:1)确定_iqN时,应避免数据溢出。可用软件对算法进行模拟得到极限值,在_iqN可以覆盖的范围内选择N的值;2)不同_iqN数据类型之间转换耗时较小,统一精度可以加快运算;3)变量进行算数运算时,需要统一_iqN数据类型;4)变量进行大小比较时,可统一成整型后进行比较;5)大数之间进行乘除法等运算时,精度会有较大损失,精度要求较高时应避免;6)在内层循环中谨慎调用IQmath库函数,一方面可以缩减开发周期,获得较高精度。但另一方面会影响流水排布,运行时间会大大增加。
3.5 DSPLIB库的使用
DSPLIB是具有C语言接口的DSP函数库,包含多个经过汇编优化且C语言可以直接调用的通用数字信号处理程序,包括自适应滤波、相关性运算、FFT/IFFT、卷积滤波、数学运算、矩阵运算等。在算法移植过程中,主要用到DSPLIB中的FFT/IFFT和卷积滤波等函数,其中FFT/IFFT的使用可以获得百倍以上的速度提升。
4 扇束滤波反投影算法在DSP中的加速优化
4.1 算法的优化
根据滤波反投影算法,在每个扫描视角内,需要计算投影地址S1和加权因子U。观察式(4)和式(5),投影地址和加权因子都是投影视角的函数,的取值范围是。这就可以充分利用三角函数的恒等变换同时计算、、和的值,如图3所示。
4.2 编译器选项
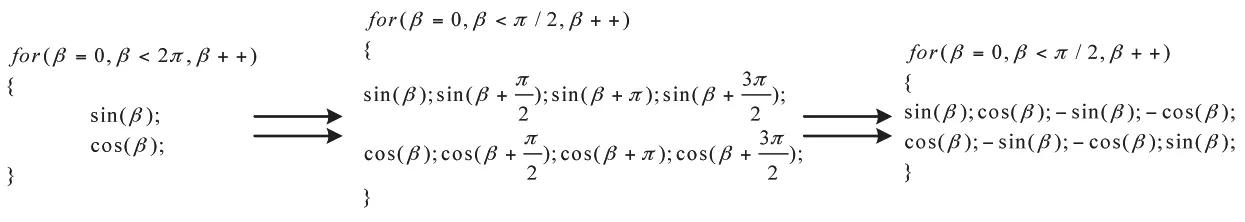
图3 利用三角函数恒等变化

图4 四个视角同时进行的反投影运算
编译器优化的原则是以代码空间换取时间,尽量使运算流水线化、并行化。其中一些选项的意义如下:
-o3:表示编译器将执行各种优化循环的方法,如软件流水、循环展开和单指令多数据流等。
-pm:表示联合所有源程序文件进行程序级优化,代码尺寸同时得到优化。
智能节点接收到检测模块采集的数据后与节点内存储的值相比较,数据异常会自动发送命令至控制模块,例如在温室大棚中,控制模块控制排风扇、加热器、遮阳网电机、喷淋设备、CO2发生器等设备进行空气温湿度、光照和土壤温湿度的调节,同时上发至监控终端指示环境参数和设备工作状态。
-mt:使能编译器假定程序中没有使用存储器混迭技术。
另外,人为添加修饰符向编译器提示优化信息。如:关键字restrict用以限定指向特定对象的唯一指针,关键字volatile用以修饰指向确定地址的指针。句柄MUST_ITERATE可告知编译器至少要执行的循环次数,强制编译器自动循环展开。句柄DATA_SECTION和CODE_SECTION可将数据段和代码段放入指定的存储空间。句柄DATA_ALIGN用来设定变量地址对齐方式,便于程序打包访问连续使用的数据。
4.3 存储器优化
在DSP中,存储器部分的优化包括缓存的优化,内存的优化,寄存器的优化和数据传输效率的提高。
对Cache的优化。尽量在一个函数或者一个语句块中多处理数据,如此这部分代码在L1P中驻留的时间就会比较长,反复运行之下L1P的命中率就会提高。此外,最好能使连续被处理的数据长度接近L1D,这样L1D的命中率也会提高。所以,将程序运算部分拆分成N个处理块,每个处理块数据长度接近于L1D,从而L1D和L1P的命中率都会提高。
对内存的优化。DSP存储空间非常有限,内存使用完后应及时释放;将动态内存分配改为静态内存分配;如果必须使用动态内存分配,一定要在使用完后,添加free函数进行内存释放;调整内存布局,将全局变量、静态变量、堆栈等移入片内;将频繁使用的代码段也移入片内。
对寄存器优化。关键字register限定用寄存器保存变量。使该变量的访问变的非常快。将反复使用的变量用关键字register限定,可有效提高代码运行速度。存储器读写速度对比如图5所示。

图5 存储器读写速度对比
在数据传输方面,可在内存和缓存之间构建带有EDMA的双缓存结构,数据读写时采用乒乓操作模式,消除了CPU读写内存引发的延迟,其结构如图6所示。对连续使用的数据连续存储,可以使用内联函数_memd8()和_itod()进行双字节访问,减少数据访问开销。

图6 四个视角同时进行的反投影运算
4.4 增强流水排布
增强流水排布的主要思想是将运算合理的分配到多个DSP运算单元中,充分利用乘加和逻辑运算单元,提高运算并行性。另一方面,采取措施避免流水线被打断,减少流水线中的延迟。具体措施如下:
a.将复杂运算拆分,提高并行性,如图7所示;
但乘加运算不要拆分,DSP内部集成了硬件乘法器和硬件加法器,合并乘加运算可更高效地使用硬件资源。
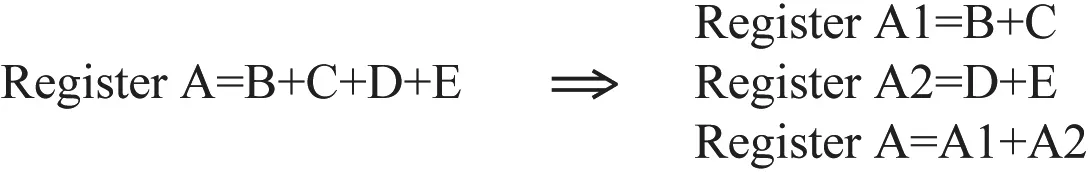
图7 拆分复杂运算,提高并行性
b.将小循环展开,使可能的并行指令数增加,从而改进流水编排,改进代码性能。循环展开为每次迭代计算8个点为宜,平衡两边通道的计算量,并且一次处理的8个32bit数据相当于两行L2 Cache Line,减少数据访问冲突。
c.对复杂循环进行拆解,避免寄存器数量不足。若寄存器数量不足,数据会被存储到内存中,将影响数据访问速度。
d.在循环内去除条件分支语句。条件分支跳转时都存在数据和地址进出堆栈的过程,带来延迟间隙,导致流水线被做空,严重影响代码运行速度。对分支语句,可用逻辑判断语句的方式代替:
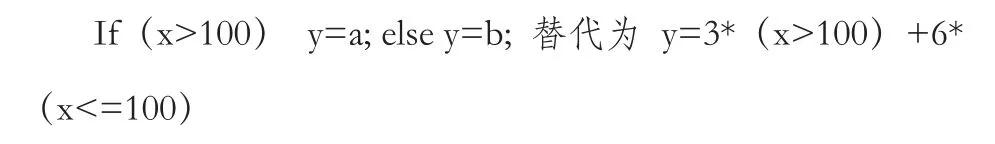
e.循环结构中不能包含函数调用。若出现函数调用,则循环中出现了跳转指令,流水排布便会被打断。
f.减少出入栈带来的时间延迟。减少局部变量的使用,改为全局变量。局部变量使用时,会有出入栈所带来的时间延迟,而全局变量的存储地址固定,访问速度高。对调用次数频繁的数据和小函数,应当采用宏操作,可减少出入栈带来的开销。
g.对循环计数器应使用int或unsigned int型,不能使用short或unsigned short,避免符号扩展。循环计数方式应该递减,这样可以直接对应汇编语句,减少额外开销。
h.注意避免提前退出循环,这会引起流水排空出错,从而影响整个代码的运行结果。
4.5 使用查找表
遇到复杂的运算,通过构建查找表的方式避免直接运算。复杂运算的过程就变为查表的过程,查找表的使用在运算速度和运算精度两个方面都有较大获益。但查找表大小不应超过十几KB,过大的查找表会增加数据搜索的负担。当查找表为多维数组时,应对其进行分解,并使用指针寻址,尽量避免使用“[]”下标运算符。
4.6 减少重复运算
减少重复运算也是DSP优化加速的重要措施。对反复用到的中间变量,可以计算一次并多次使用;在多重循环中,能在循环外(或外层循环)进行的运算,应放到循环外(或外层循环)。
5 实验分析
5.1 重建耗时对比
实验中,DSP主频为1GHz,选用720个投影视角,重建大小为768*768的切片图像。为保证图像精度,数据都采用32bit位宽,最终耗时为8.751s。表1表示引入不同的优化加速方法后,DSP的耗时情况。其中引入IQmath库,执行效率约为引入前的约11.2倍;增加编译器、存储器优化,增加流水排布后,执行效率为增加前的6.2倍;去除内层循环中函数调用,效率为去除前的7.1倍。最终代码执行效率为无优化措施的约1200多倍。表2表示优化加速后,算法各个阶段的耗时及占比,结果与文献[6]结果相当。
5.2 重建结果对比
图8和图9分别表示在PC和DSP平台上,经过滤波反投影算法重建后的切片图。从视觉上对比,DSP的重建结果与PC的重建结果基本一致。图10和图11分别表示在PC和DSP平台上,经过滤波反投影算法重建后切片图的像素统计直方图,其中横坐标为像素位置,纵坐标为像素值大小。虽然像素绝对值有较大差异,但归一化后的像素值误差很小。
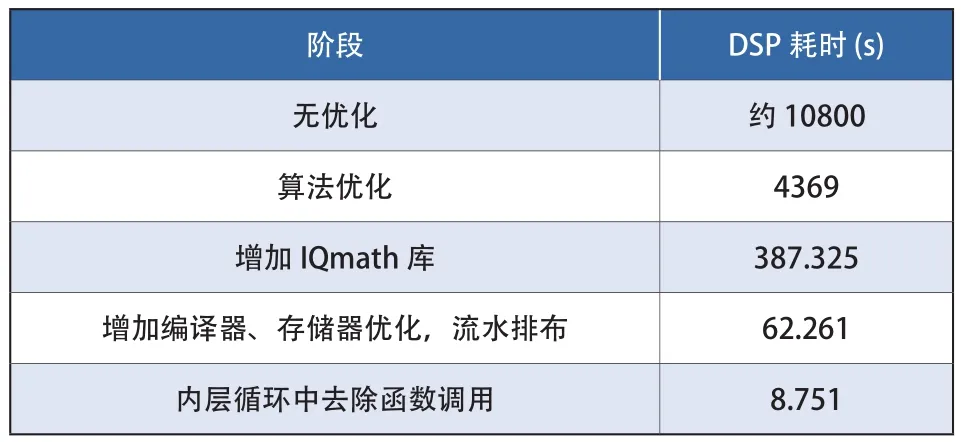
表1 各优化阶段耗时对比
6 结语

图8 PC重建的二维图像

图9 DSP重建的二维图像

图10 PC重建的像素直方图
本文实现扇束滤波反投影算法在定点DSP上的移植,并进行优化加速。在移植方面,介绍了动态存储分配,cmd文件配置,变量定点化、IQmath库和DSPLIB库的使用;在优化加速方面,从算法、编译器、存储、增加流水排布、使用查找表和减少重复运算等方面提出一整套的优化方案。最后,从重建速度和重建结果两个方面对比分析,实验结果表明,优化加速方法获得较高加速比,DSP重建的图像质量较高。由于扇束滤波反投影算法有良好的并行特性,后续可以考虑在FPGA或多核DSP平台上实现该算法,可获得更好加速效果。

图11 DSP重建的像素直方图

[1]马晓鹏.CT式行李安检系统反投影算法研究及其硬件设计[D].南京:东南大学,2010.
[2]王超,李建新,王大会,闫镔,李磊.锥束CT图像重建算法在DSP上的加速方法研究[J]. CT理论与应用研究,2010, 19(4): 19-26.
[3]傅健,路宏年.扇束工业CT滤波反投影重构算法的快速实现[J].计算机应用研究,2003, 20(3): 51-53.
[4]Ricardo A, Neri C, Sergio A, et al.Cache-optimized implementation of the filteredbackprojection algorithm on a digital signal processor[J]. Journal of Electronic Imaging.2007, 16(4).
[5]曾启明,李琰,纪震.PET图像的DSP重建方法[J].数据采集与处理,2013, 9, 28(5): 633-637.
[6]刘晓平.扇束卷积反投影法的程序优化[J]. CT理论与应用研究,1996, 5(1):35-37.
[7]TMS320C6455 Fixed-Point Digital Signal Processor [Z].Texas Instruments Inc. 2012.
[8]IEEE Standard for Binary Floating-Point Arithmetic,ANSI/IEEE Std.754-1985,1985:7-20.
[9]孙毅刚,王庆勇,张红颖.基于定点DSP的ART算法实现研究[J].现代电子技术,2010, 33(18) :17-20.
[10]TMS320C64x+IQmath Library User’s Guide [Z]. Texas Instruments Inc. 2008.
[11]TMS320C64x DSP LibraryProgrammer’s Reference [Z].Texas Instruments Inc. 2003.
[12]王鹏凯.基于DSP系统的Adaboost人脸检测算法实现[D].南京:东南大学,2010.
[13]LIANG Wenxuan, ZHANG Hui, HU Guangshu.Optimized Implementation of the FDK Algorithm on OneDigitalSignal Processor[J]. Tsinghua Science and Technology.2010,12, 15(1):108-113.
[14]沈海涛.图像无损压缩研究与DSP实现[D].西安:西北工业大学,2007.
[15]李忠锋.基于C6000 DSP的JPEG2000图像压缩技术研究[D].武汉:华中科技大学,2004.
猜你喜欢
计算机研究与发展(2021年3期)2021-04-01
铁道通信信号(2020年7期)2020-02-06
计算机与网络(2019年9期)2019-10-21
电脑报(2019年31期)2019-09-10
当代陕西(2019年13期)2019-08-20
电子制作(2018年16期)2018-09-26
火控雷达技术(2016年3期)2016-02-06
海军航空大学学报(2015年1期)2015-11-11
电脑爱好者(2015年21期)2015-09-10
空间控制技术与应用(2015年3期)2015-06-05
