
基于hadoop的高校私有云平台建设研究
2017-11-14 11:59陈伟
商丘职业技术学院学报 2017年5期
陈 伟
(宿州职业技术学院 计算机系,安徽 宿州 234101)
基于hadoop的高校私有云平台建设研究
陈 伟
(宿州职业技术学院 计算机系,安徽 宿州 234101)
随着教育信息化的不断推进,高校信息化建设在飞速发展的同时也面临着业务系统混乱及海量数据存储等问题,现有的校园网络平台已不能满足日益增长的信息化需求.针对这些问题,本文在研究hadoop的基础上结合云计算技术,提出构建高校私有云平台,以实现海量数据存储和高速处理,同时为高校各种业务系统提供统一的基础设施平台.
云计算;高校;Hadoop;私有云
1 云计算
1.1 云计算概述
云计算开创了信息技术的新模式,已经不仅仅是一种技术,更是一种商业计算模型.云计算将大量的计算任务分布在虚拟化的资源池上,使用户可以像使用水电一样的在资源池中获得各种资源和服务,随时获取,按需使用,按使用付费.这里的资源池即是“云”,是虚拟化的计算资源,由大量计算服务器、存储服务器、宽带资源等构成.云计算将这些大量的计算资源集合起来通过软件方式实现资源自动管理,无须人工干预.用户按需获取的资源主要指信息服务、计算能力和存储空间[1]57-59.
与传统计算模式不同,云计算是基于互联网的计算模式,数据和程序主要是保存在互联网上即“云端”,与本地机器的存储和计算能力等关系不大,云客户端只要能接入互联网,就可以随时随地访问云端提供的服务.
1.2 公有云和私有云
公有云是将服务和基础设施提供给组织和企业,提供公共的云计算服务和存储[2]34-39.公有云把数据和应用程序存放在公有云的平台上,用户可即付即用,无须进行基础设施的前期投资和建设,公有云属于开放的云平台.
私有云属于自己搭建的云平台,可以在原有网络设备基础上进行整合部署,提高资源利用率,成本较低,无须支付额外费用,能够根据实际需求进行安全策略定制,实现系统的安全和可靠性,对于高校云平台而言,私有云是很好的选择.本文选择使用开源的云计算系统Hadoop立足于现有的校园网络设备和资源自行搭建私有云平台,既节省成本又提高了资源利用率.
1.3 教育云
云计算应用于教育领域,可以在课堂教学、实验教学和辅助教学等诸多方面提供高效服务[3]79-86.教育云是云计算与教学结合的产物,是新技术应用于教育领域的体现,利用云计算技术,对多种资源进行整合优化统一部署,实现高效率的资源共享.同时,教育云也为高校办公提供了更为高效的平台支撑,教务、财务、总务等业务应用可以共享基础平台,实现资源优化共享,通过云平台的分布式计算机存储,提高数据处理效率.
2 Hadoop平台介绍
Hadoop 是Apache公司的一个分布式云计算平台,作为一个开源项目,Hadoop为云计算研究提供了很好的平台支撑,得到了学术界和商业界的广泛关注,同时成为构建私有云的主流平台之一[4]24-29,[5]22-27.
Hadoop发展至今经历了第一代Hadoop1.x和第二代Hadoop2.x.Hadoop1.x主要以HDFS (Hadoop Distributed File System)分布式文档系统和MapReduce (Google Map Reduce 的开源实现)分布式平行计算框架为核心.由于Hadoop1.x在扩展性、稳定性、资源管理等方面存在问题,对Hadoop1.x进行了改进,于2010年发布了第二代Hadoop2.x,新增加了核心组件Yarn框架.
2.1 HDFS分布式文件系统
HDFS是Hadoop分布式文件系统,是Hadoop生态系统的核心组件.HDFS分布式文件系统能够运行在廉价的硬件上,部署成本较低,能够进行故障检测与恢复,具有高级容错功能,采用流式数据访问,注重数据访问的高吞吐量,能够处理大数据集.
在Hadoop2.x中HDFS与之前有很大的变化,Hadoop1.x中HDFS包含一个主节点NameNode和若干个子从节点DataNode,新版本中HDFS的管理节点NameNode可以以集群的方式同时部署多个,并且互相独立,解决了单点故障问题,增强了NameNodes的水平扩展能力和高可用性.NameNode节点负责管理元数据,存储文件系统的名字空间及数据块到具体DateNode的映射.节点DataNode作为集群的存储节点需要在所有的NameNode中进行注册,定时向NameNode反馈信息,并且处理NameNode下达的操作指令,负责实际数据的存储.HDFS分布式文件系统架构如图1所示.

图1 HDFS分布式文件系统
HDFS系统架构主要包括两部分:命名空间Namespace 和 块存储Block Storage.Block Pool为存储块池,是块的集合,每个Block Pool与一个Namespace相对应,属于同一Namespace的一组块,Block Pool之间是独立的互不影响,DataNode节点为所有的Block Pool存储块.对于hadoop来说,NameNode的作用至关重要,好比计算机的CPU,一旦停止工作整个集群系统就会瘫痪且不可恢复.为了保证集群正常运转,在HDFS中通过同时启动两个NameNode来解决单点故障问题,这两个NameNode并不是同时工作,而是把一个设为工作(Active)模式,另个设为待命的(Standby)模式.系统工作过程中,两个NameNode要进行数据的同步,DataNode向两个NameNode同时反馈块的信息,并通过Zookeeper来进行心跳监测监控,当处于工作模式的NameNode出现宕机失效时,可以快速切换到待命的NameNode,保证系统正常且数据不会丢失.
2.2 MapReduce分布式计算(MR2)
MapReduce是Hadoop中的并行计算框架,是一种编程模型,用于海量数据分布式计算.目前在Hadoop2.x中使用的是第二代MapReduce框架(MR2).MR2包括3部分内容:编程模型、数据处理引擎和运行时环境.编程模型是把输入数据解析为键值对,通过Map()函数,映射成新的键值对,再通过Reduce()函数将key相同的value进行规约处理;数据处理引擎由MapTask和ReduceTask组成,负责Map阶段和Reduce阶段的数据处理;运行时环境由资源管理系统YARN和作业控制进程ApplicationMaster构成,其中,YARN负责资源管理和调度,而ApplicationMaster仅负责一个作业的管理.
2.3 YARN框架
Yarn是分布式的资源管理系统,用于资源管理和作业的调度,是为了弥补第一代MapReduce框架的不足而产生的新框架.Yarn具有通用性,不仅可以用于MapReduce计算框架还可以作为其他框架如Spark等的管理平台.Yarn的架构如图2所示.
ResourceManager(RM)在整个集群中只有一个,作为全局资源管理器,负责系统全部资源的管理和调度,其中包括调度器(Scheduler)和应用管理器(Applications Manager).Scheduler是RM的核心,主要负责给应用程序调配资源,Applications Manager负责应用程序监控、状态跟踪、失败任务重启等工作.
NodeManager(NM)是每个节点上的管理器,负责监控节点资源情况,并发送给RM,同时负责执行来自AM的任务请求.
ApplicationMaster(AM)是框架特殊的库,负责与RM的Scheduler协商进行资源的申请,并且与NM一块监控资源使用及任务执行情况.
Containe是资源的分配容器,包括cpu,内存,磁盘等属性.
图2中Yarn的工作流程可描述如下:
RM通过NM定时搜集Node的信息;Client向RM提交计算作业;RM在一个Node上产生一个AM;AM向RM申请计算资源,RM根据资源状况以及分配策略,分配合适的资源(container)给AM;AM得到资源后,管理这些资源,完成计算任务.
3 私有云平台部署
3.1 高校私有云架构模型
高校私有云架构模型如图3所示.

图2 Yarn架构图
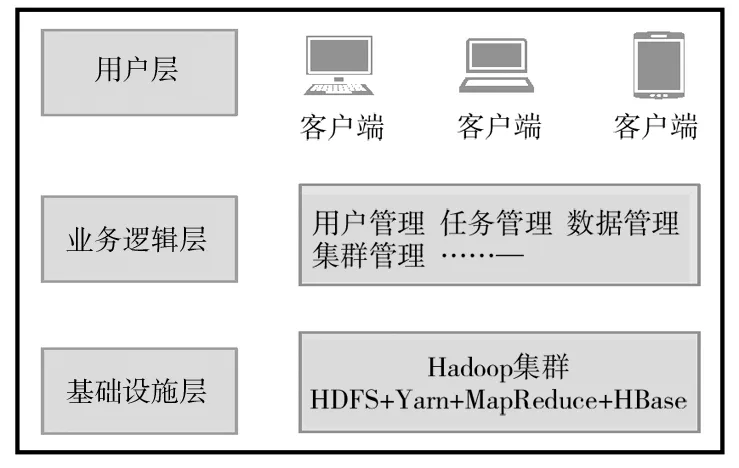
图3 高校私有云平台计算模型
用户层是用户与云平台进行交互的接口,用户通过Web浏览器向平台发送请求,平台通过用户验证后返回信息给用户;业务逻辑层主要用于Web服务器程序和存储系统之间的通讯,与底层集群建立连接,其功能主要包括用户管理、任务管理、资源管理等;基础设施层是整个云平台应用的基础环境,由多台廉价的计算机组成,属于系统的底层部分,通过Hadoop集群构建,为系统提供分布式存储和海量资源数据计算.下面就通过部署基础设施层来对基于Hadoop的高校私有云平台进行研究.
3.2 hadoop基本平台搭建
hadoop平台有3种搭建方式,分别是单机模式安装、伪分布式安装、全分布式安装.本文采用全分布式安装方式,通过3台普通机器进行模拟集群部署.下面介绍集群部署步骤.
3.2.1 集群安装配置
集群安装采用虚拟机的方式进行,虚拟机软件采用VMware 9.0.2版本,虚拟机上安装3个客户机系统作为集群计算节点,操作系统安装CentOS-6.8,集群节点主机名和IP分配如表1.

表1 集群节点主机名和IP分配表
为了保证集群中每台机器能够相互访问,需要以下操作:
1) 关闭防火墙:在每台主机上执行service iptable stop和chkconfig iptables off两条命令.
2) 关闭selinux:通过修改配置文件/etc/sysconfig/selinux/文件实现,把文件中SELINUX值修改为disabled,重启系统生效.
3) 修改每台主机/etc/hosts文件,设置主机名和IP地址的对应关系,文件内容修改如下:
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.1.128 hadoop01.cw
192.168.1.129 hadoop02.cw
192.168.1.130 hadoop03.cw
3.2.2 配置SSH实现节点无密码登陆
1) 在hadoop01上生成密钥
[root@hadoop01 ~]# ssh-keygen-t rsa
2) 拷贝密钥到其他机器
[root@hadoop01 ~]# ssh-copy-id 192.168.1.129
[root@hadoop01 ~]# ssh-copy-id 192.168.1.130
同样方法在hadoop02和hadoop03上生成密钥并拷贝到其他机器,即可实现3台机器无密码登陆.
3.2.3 Jdk环境配置
由于Hadoop是采用Java开发的,需要在每台主机安装JDK的环境.
1)在oracle官网下载jkd安装包jdk-8u121-linux-i586.gz,解压至/home/softwares/目录.
2)配置环境变量,在/etc/profile文件尾部添加以下语句.
export JAVA_HOME=/home/softwares/jdk1.8.0_121
export PATH=$PATH:$JAVA_HOME/bin
3)刷新配置,使环境变量生效,命令为source /etc/profile.
4)通过命令java -version验证是否安装成功,若显示java version "1.8.0_121"等信息则说明安装成功.
5)使用scp命令发送jdk文件至其他机器,同时在每台机器配置环境变量.
3.3 hadoop安装与配置
3.3.1 下载安装
在hadoop01上下载hadoop-2.7.3.tar.gz,解压缩至/home/softwares/目录即可.
3.3.2 配置文件修改
Hadoop配置文件路径为/home/softwares/hadoop-2.7.3/etc/hadoop,通过以下步骤进行配置文件的修改.
1)修改hadoop-env.sh文件,这是hadoop 的环境变量文件,需要设置JDK的安装位置,该文件第25行配置为export JAVA_HOME=/home/softwares/jdk1.8.0_121.
2)修改文件 core-site.xml 配置如表2.

表2 core-site.xml配置信息
3)修改文件 hdfs-site.xml 配置如表3.

表3 hdfs-site.xml 配置信息
4)修改 mapred-site.xml 配置文件 配置如表4.

表4 mapred-site.xml 配置信息
5)修改Yarn-site.xml 配置文件 配置如表5.

表5 Yarn-site.xml配置信息
6)修改slaves如下
192.168.1.128
192.168.1.129
192.168.1.130
3.3.3 hadoop启动
1)格式化hadoop,命令如下:
[root@hadoop01 hadoop-2.7.3]# bin/hadoop namenode -format
2)发送hadoop01主机上hadoop文件至其他两台机器,如下操作:
[root@hadoop01 softwares]# scp -r hadoop-2.7.3/ 192.168.1.129:/home/softwares/
[root@hadoop01 softwares]# scp -r hadoop-2.7.3/ 192.168.1.130:/home/softwares/
3)启动相关服务
由上可知,namenode节点配置在192.168.1.128即hadoop01上,在此主机上运行sbin/start-dfs.sh命令启动hadoop,运行sbin/mr-jobhistory-daemon.sh start historyserver启动jobhistory.在hadoop02上运行sbin/start-yarn.sh启动yarn,最后可通过jps命令查看每台主机运行进程,结果如下:

4210 Jps
3938 NodeManager
此时通过浏览器也可进行web页面查看,如在浏览器输入地址http://192.168.1.128:50070查看hdfs的namenode运行情况,输入http://192.168.1.129:8088查看yarn运行情况[6]60-72.
3.3.4 测试与分析
以WordCount词频统计为例,测试系统是否运行正常,包括HDFS存储及MapReduce分布式计算.
1)在/home/datas下创建文本文件test.txt,内容为“hello world this is a test this is a world a a is a world”.
2)上传test.txt文件至HDFS,命令为bin/hdfs dfs -put /home/test.txt /chenwei-test.在浏览器输入http://192.168.1.128:50070查看hdfs中上传文件情况,如图4所示.

图4 HDFS文件系统目录
3)执行词频统计命令WordCount,把统计结果放入/chenwei-test-out中,命令为 bin/hadoop jar share/hadoop/MapReduce/hadoop-MapReduce-examples-2.7.3.jar wordcount / chenwei-test / chenwei-test-out.打开chenwei-test-out目录可以看到part-r-00000文件,即为统计结果.
4)执行bin/hdfs dfs -cat /chenwei-test-out/part-r-00000查看词频统计结果如图5.
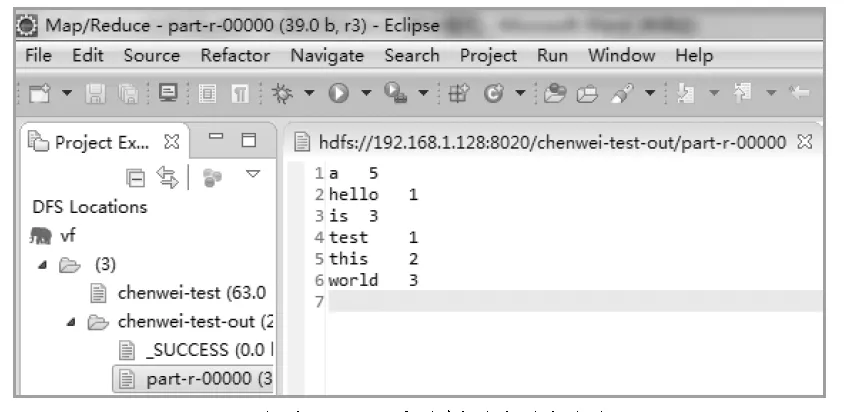
图5 词频统计结果
从以上测试来看,HDFS分布式文件系统能够正常上传存储文件,yarn框架能够进行任务的调度和管理,在yarn框架上实现了MapReduce分布式计算,集群部署完全能够正确运行.至此,基于hadoop私有云平台搭建成功.
4 结语
云计算技术在教育领域中的应用,促进了教育信息化的发展.本文通过基于hadoop高校私有云平台的构建,为高校信息化建设提供了基础平台,可以把原有业务系统移植过来,实现统一管理和部署,还可以在此平台基础上开发相关应用服务高校、服务师生,如教学平台、资源管理平台等,这将有待于进一步深入研究.
[1] 刘 鹏. 云计算(第二版)[M]. 北京:电子工业出版社,2011.
[2] 薛 嘉. 云计算下教学互动平台的探究和设计[D].成都:西南交通大学,2014.
[3] 虚拟化与云计算小组. 云计算实践之道:战略蓝图与技术架构[M].北京:电子工业出版社,2011.
[4] 翟永东. Hadoop分布式文件系统(HDFS)可靠性的研究与优化[D].武汉:华中科技大学,2011.
[5] 饶丹鹃. 多媒体教学资源云共享平台设计研究[D].南京:南京师范大学,2013.
[6] 刘 鹏. 实战Hadoop开启通向云计算的捷径[M].北京:电子工业出版社,2011.
ResearchontheConstructionofPrivateCloudPlatforminCollegesBasedonHadoop
CHEN Wei
(SuzhouVocationalTechnicalCollege,Suzhou234101,China)
With the advancement of educational informatization, the informatization construction in colleges has developed rapidly. Meanwhile, it is facing many problems such as chaos in business system and mass data storage issues, etc. Thus, the existing campus network platforms cannot meet the growing demands for informatization. To solve these problems, the author proposes to build a private cloud platform basing on researches on Hadoop which is combined with cloud computing technology to achieve mass data storage and high-speed processing as well as to provide a unified infrastructure platform for business systems in colleges.
cloud computing; Colleges; Hadoop; private cloud platform
G647.24;TP391.6
A
1671-8127(2017)05-0089-06
2017-08-02
安徽省高校自然科学研究重点项目“基于云平台的职业教育资源管理研究”(KJ2016A778);安徽省高校优秀青年人才支持计划重点项目“云计算环境下高职教育教学平台的构建”(gxyqZD2016586);安徽省高校自然科学研究重点项目“智能算法在群体动画制作中的应用与创新研究”(KJ2016A781);安徽省质量工程项目“基于Blackboard的高职程序设计类课程翻转课堂教学模式研究——以ASP.NET课程为例”(2016jyxm1039)
陈 伟(1982- ),男,安徽阜阳人,宿州职业技术学院讲师,硕士,主要从事计算机网络研究。
[责任编辑冰竹]
猜你喜欢
小资CHIC!ELEGANCE(2022年1期)2022-01-11
数学物理学报(2020年3期)2020-07-27
军事运筹与系统工程(2019年4期)2019-09-11
电子制作(2018年11期)2018-08-04
能源(2017年10期)2017-12-20
能源(2017年5期)2017-07-06
中国交通信息化(2017年3期)2017-06-08
知识就是力量(2017年2期)2017-01-21
燕山大学学报(2015年4期)2015-12-25
雷达与对抗(2015年3期)2015-12-09
