
排查group_concat函数主从异常
2017-11-08 07:29:18
网络安全和信息化 2017年10期
收到实例主从异常告警后登录服务器查看发现是由于GROUP_CONCAT()函数导致同步异常,如图1所示。
这是超过了大小被截断触发的 warning,然 后被同步抓取到从而出现同步中断。第一想到的是对userid进行GROUP_CONCAT()后写入到tb_create_users_every_day表的时候发生截断,于是查 看tb_create_users_every_day的表定义的ids列的大小,发现是longblob列,基本排除这个猜想,如图2所示。
排查了表列截断的问题,根据业务的SQL,先将对应的select抽出来,并统计一下每一个GROUP_CONCAT(userid)的长度,发现最大的为1024,并且有个warning,如图3所示。
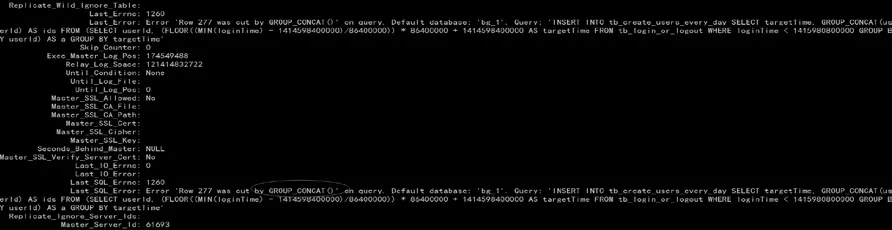
图1 函数同步异常
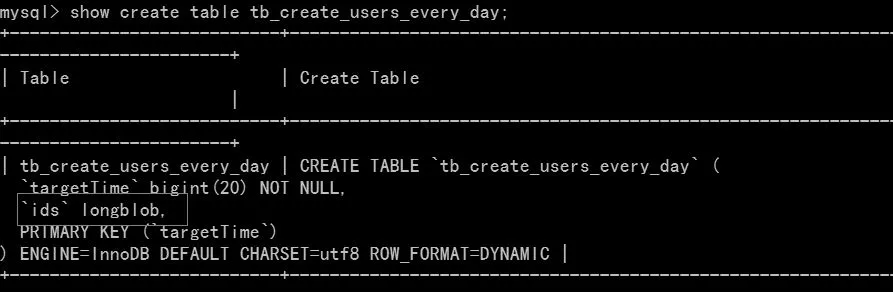
图2 发现longblob列

图3 发现长度1024和warning
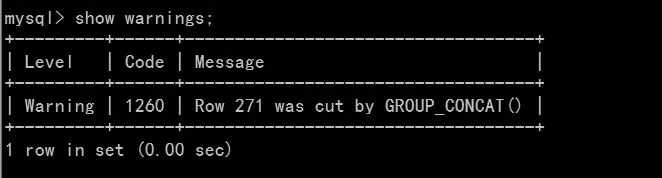
图4 warning报错

图5 验证发现超过1024
查看一下warning的报错,推断应该是由于超过GROUP_CONCAT()的最大限制导致的截断,如图4所示。
为了验证这个猜想,查询一下targetTime为1415894400000的userid通过GROUP_CONCAT()后最大是多少,于是写了如下简单的SQL进行验证,发现确实超过了1024,如图5所示。
通过分析问题已经很清晰了,明显是GROUP_CONCAT()函数有限制最大为1024导致的截断,于是在服务器中搜索对应的group和concat字段的变量,人品大爆发,一下就把对应的变量揪了出来。
最后直接将主从的group_concat_max_len参数设为10240,并重启同步线程,观察slave状态。
猜你喜欢
江苏科技信息(2022年16期)2022-07-17 09:07:36
中华诗词(2019年5期)2019-10-15 09:06:12
海峡姐妹(2018年12期)2018-12-23 02:39:08
制造技术与机床(2017年6期)2018-01-19 02:41:22
人生十六七(2016年16期)2016-11-20 01:13:39
电测与仪表(2016年24期)2016-04-12 00:21:04
海峡姐妹(2016年2期)2016-02-27 15:15:50
探测与控制学报(2015年4期)2015-12-15 15:00:56
图书馆建设(2015年10期)2015-02-13 03:48:27
新世纪图书馆(2014年7期)2014-09-19 12:20:40
