
基于专家系统的高级持续性威胁云端检测博弈
2017-11-07 10:11吕世超石志强孙利民
计算机研究与发展 2017年10期
胡 晴 吕世超 石志强 孙利民 肖 亮
1(中国科学院大学网络空间安全学院 北京 100049) 2(物联网信息安全技术北京市重点实验室(中国科学院信息工程研究所) 北京 100093) 3(厦门大学通信工程系 福建厦门 361005) (huqing@iie.ac.cn)
2017-06-10;
2017-08-01
国家重点研发计划项目(2016YFB0800202);国防基础科研计划项目(JCKY2016602B001);国家自然科学基金项目(U1636120,61671396);北京市科委科技计划专项项目(Z161100002616032);CCF启明星辰鸿雁基金项目(2016-010) This work was supported by the National Key Research and Development Program of China (2016YFB0800202), the National Defense Basic Scientific Research Program of China (JCKY2016602B001), the National Natural Science Foundation of China (U1636120, 61671396), Beijing Municipal Science and Technology Commission Program (Z161100002616032), and the CCF-Venustech Hongyan Research Initiative (2016-010).
石志强(shizhiqiang@iie.ac.cn)
基于专家系统的高级持续性威胁云端检测博弈
胡 晴1,2吕世超1,2石志强1,2孙利民1,2肖 亮3
1(中国科学院大学网络空间安全学院 北京 100049)2(物联网信息安全技术北京市重点实验室(中国科学院信息工程研究所) 北京 100093)3(厦门大学通信工程系 福建厦门 361005) (huqing@iie.ac.cn)
云计算系统是高级持续性威胁(advanced persistent threats, APT)的重要攻击目标.自动化的APT检测器很难准确发现APT攻击,用专家系统对可疑行为进行二次检测可以减少检测错误.但是专家系统完成二次检测需要花费一段额外的时间,可能导致防御响应延迟,而且专家系统本身也会产生误判.在综合考虑APT检测器和专家系统的虚警率和漏报率的基础上,用博弈论方法讨论在云计算系统的APT检测和防御中,利用专家系统进行二次检测的必要性.设计了一个基于专家系统的APT检测方案,并提出一个ES -APT检测博弈模型,推导其纳什均衡,据此研究了专家系统对云计算系统安全性能的改善作用.此外,当无法获得APT攻击模型时,提出了一种利用强化学习算法获取最优防御策略的方案.仿真结果表明:基于WoLF-PHC算法的动态ES -APT检测方案较之其他对照方案能够提高防御者的效用和云计算系统的安全性.
高级持续性威胁;云安全;专家系统;博弈论;强化学习
随着云计算技术的发展,越来越多的数据被上传到云端,其中不乏金融、医疗、政务、通信、工业、农业等关系到国计民生的重要数据,导致云计算系统成为高级持续性威胁(advanced persistent threats, APT)的主要攻击目标.针对云计算系统的APT攻击主要是为了窃取机密信息.在达到目的之前,APT攻击者会反复尝试,搜集大量目标系统的资料,并根据目标系统的防御情况不断调整攻击方案,直至成功[1].近年来,人们在APT防御方面做了大量研究.但实际情况表明,由于APT攻击不断尝试新的攻击手段、大量利用0day漏洞且擅于隐藏和擦除痕迹,很难准确检测到APT攻击.尤其是自动化的APT检测器,在工作过程中都会产生大量的虚警和漏报.虚警会导致错误的防御,给APT防御者带来人力、物力、财力以及时间上的损失.漏报更是为APT攻击继续深入提供便利,增加了攻击者窃密或实现其他攻击目的的机会.
为了缓解APT检测器的不准确性带来的危害,本文提出一种基于专家系统(expert system, ES)的APT攻击检测方案,简称ES -APT检测方案.专家系统一般是指计算机程序系统,用人工智能技术和计算机技术来模拟人类专家解决专业领域问题[2].本文的专家系统是由计算机专家系统和多个人类信息安全专家组成的多专家协作系统.在ES -APT检测方案中,APT防御者借助APT检测器和专家系统对目标系统进行检测.APT检测器持续扫描云计算系统,并根据防御者设置的时间间隔对所收集到的信息进行综合分析.当APT检测器报警时,触发专家系统进行二次检测,如果专家系统确认报警正确,则防御者采取措施阻断APT攻击,并修复由攻击造成的损失.从APT检测器报警到专家系统给出判断所经历的时间称为响应时间.在实际运行中,专家系统的判断也可能出错.
针对已知攻击模型的APT攻击,本文根据ES -APT检测方案提出一种ES -APT检测博弈模型,以APT攻击者和云计算系统的防御者为博弈的参与方.在该模型中,APT检测器和专家系统的虚警率和漏报率是公共知识.APT攻击者的策略是选择发动攻击的时机,防御者的策略是设置APT检测器进行综合分析的时间间隔.求解该模型的纳什均衡,可以得到防御者的最优策略.
动态的ES -APT检测博弈则用来研究无法获知APT攻击的攻击模型时APT防御者如何进行防御决策.本文提出一种基于WoLF-PHC算法的防御策略优化方案,并用模拟仿真验证了该方案的可行性和提升APT防御者效用的能力.
本文的主要贡献有3个方面:
1) 提出了一种ES -APT检测方案来缓解APT检测器的不准确性带来的危害,并基于该方案构建了一个以APT攻击者和防御者为参与人的ES -APT检测博弈模型;
2) 推导了ES -APT检测博弈的纳什均衡,并用数值分析揭示了APT检测器和专家系统的虚警率、漏报率,以及专家系统二次检测造成的防御延迟对博弈双方效用和云计算系统安全性的影响;
3) 在动态博弈中,基于WoLF-PHC算法设计了一种防御策略优化方案,用模拟仿真验证了该方案的可行性,并对比了该方案和其他对照方案的性能.
1 相关工作
博弈论在网络与信息安全相关领域应用广泛,涉及主动防御[3]、安全协议[4]、隐私保护[5-6]和攻击检测[7]等.在APT检测与防御方面,大量工作表明:博弈论是一种研究和解决APT攻击问题的有效方法.
文献[8]提出了一种防御隐蔽攻击的重复博弈框架FlipIt,研究了针对不同攻击策略的占优防御策略;文献[9]基于FlipIt框架研究了当APT攻防双方的时间、成本等资源受限时的近似最优防御策略,还提出了一个以防御者为主导者、攻击者为追随者的序贯博弈模型,设计了基于动态规划来获取防御者的近似最优策略的算法;文献[10]考虑了隐蔽攻击者逐步获取资源而防御者只能部分消除攻击立足点,且无法弥补任何已经发生的信息泄漏的情形,并构建博弈模型推导出最佳防御策略;文献[11]和文献[12]用前景理论论述了当APT攻防双方并非完全理性时,他们的主观程度对双方决策和效用的影响,设计了基于Q-learning的动态防御方案;文献[13]进一步用累积前景理论对APT攻防博弈进行了讨论;文献[14]分析了内部泄密者和APT攻击者的联合威胁,给出了可能存在内部泄密者时防御者的最优策略;文献[15]通过双层博弈模型研究攻击者与泄密者之间的交易以及攻击者与防御者之间的博弈,并求解了子博弈完美均衡;文献[16]用演化博弈论来捕捉长期连续的APT攻击行为,通过建立2个离散策略的APT防御博弈模型,研究了攻击策略和防御策略的动态稳定性.
然而,以上研究均未涉及检测APT攻击时可能出现的虚警和漏报.实际应用中,在忽略APT检测的不准确性[17]的情况下做出的防御决策,可能会对防御效能产生负面影响.本文提出ES -APT检测方案来提升APT检测的性能,并基于此构建APT攻击者和无法准确检测到攻击的防御者之间的博弈模型,从静态和动态2个方面为防御者提供更好的防御策略.
2 系统模型
本节介绍ES -APT检测方案以及基于此方案的ES -APT检测博弈的基本模型,并建立APT攻击者和防御者的效用函数.
2.1ES-APT检测方案
ES -APT检测方案如图1所示.APT检测器持续监听云计算系统的各类信息,并按防御者设定的检测时间间隔对这段时间内所监测到的数据进行综合分析,判断云计算系统是否已被攻击.如果检测器认为系统没有遭受攻击,则防御者开始部署下一次检测时间间隔;反之,检测器给出告警,同时触发专家系统.专家系统综合考量检测器收集的信息和其他与云计算系统相关的信息,进一步辨别系统是否安全.只有专家系统确认了攻击确实发生,防御者才会采取防御措施对APT攻击进行阻断.

Fig. 1 The scheme of detecting APT attacks with an expert system图1 ES -APT检测方案
2.2基本模型
ES -APT检测博弈是一个非合作博弈,有2个参与人:1)手段高明、隐蔽性强的APT攻击者;2)基于ES -APT检测方案进行防御的APT防御者.假设在一次博弈的起始点,云计算系统处于安全状态.攻击者和防御者基于对APT检测器和专家系统的虚警率、漏报率的考虑,在不知道对方如何决策的情况下,分别选择攻击时间y和检测时间间隔x.攻击者可以选择y=0,即立刻攻击,而防御者不能选择x=0,因为APT检测器根据0时间内的信息不可能判断是否存在攻击.归一化之后有y∈[0,1],x∈(0,1].不论攻击者采用何种手段进行攻击,从其发动攻击到攻击生效都需要经历一段时间z,且z>0.假设APT检测器和专家系统只能发现已经生效的攻击,其中APT检测器在检测时耗费的时间可以忽略不计,专家系统用于二次检测的耗时记为t.ES -APT检测博弈中部分可能出现的攻防互动情况如图2所示.
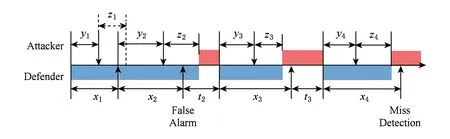
Fig. 2 Illustration of an ES -APT detection game图2 ES -APT检测博弈示意图
虚警是指系统未遭受攻击时被认为受到攻击,漏报则是系统遭受攻击后依然被认为处于安全状态.若用S表示系统的真实状态,s表示APT检测器判定的系统状态,s′表示专家系统复检之后给出的系统状态,下角标0和1分别指代未受攻击和受到攻击,则APT检测器的虚警率pm和漏报率pf分别为
pm=Pr(s0|S1),
(1)
pf=Pr(s1|S0).
(2)

(3)

(4)
以上Pr(·|·)为条件概率.
APT攻击者和防御者所争夺的云计算系统具有一定的价值,记为C,其大小取决于该系统对攻击者和防御者而言的重要性.C本为防御者所有,如果博弈的结局是云计算系统处于受攻击状态,则攻击者从防御者处夺走这部分价值.
2.3效用函数
在推导效用函数之前,先给出一个度量ES -APT检测博弈性能的指标——安全率的定义.
定义1. 安全率.一次博弈中,云计算系统处于未受攻击状态的时间在博弈总时长中所占的比率称为安全率,记为R.
在ES -APT检测博弈中,APT防御者的效用由4部分组成:
1) 安全率带来的收益;
2) 从设定的检测时间间隔获益,间隔越长,APT检测器收集的信息越多,越有利于APT检测器和专家系统做出正确判断,GD表示单位时间的获益;
3) 修复云计算系统所需的开销CR;
4) 如果博弈的最后已生效的APT攻击没有被发现,防御者输掉云计算系统价值C.
攻击者的效用由3部分组成:
1) 安全率带来的损失;
2) 发动攻击时要付出的攻击成本CA;
3) 如果博弈的最后APT攻击生效且没有被阻断,攻击者获得云计算系统价值C.
为了确定ES -APT检测博弈中防御方的效用函数uD和攻击方的效用函数uA,我们将所有参数进行归一化处理,并分类讨论博弈中所有可能出现的情况.从APT检测器准确性的角度,所有情况可归为四大类:检测器正确判定系统未受攻击、错误判定系统受到攻击、正确判定系统受到攻击和错误判定系统未受攻击.
1) 检测器正确判定系统未受攻击
如图2中序号为1(即字母下角标为1)的博弈所示,该情况出现的前提条件是y+z>x,即在检测器检测之前,攻击尚未生效,其出现的概率是1-pf.此时云计算系统的安全率为1,防御者不需要进行修复操作,且不会失去C.这种情况下博弈双方的效用分别为
uD1(x,y)=1+xGD,
(5)
uA1(x,y)=-1-I(y≤x)CA,
(6)
其中,I(·)为指示函数,括号内条件为真时I(·)=1,否则I(·)=0.
2) 检测器错误判定系统受到攻击
图2中序号为2的博弈是检测器错误判定系统受到攻击时,攻防双方可能的交互情况之一.检测器错误判定系统受攻击的前提条件是y+z>x,概率为pf.检测器告警后,专家系统进行复验.考虑到专家系统复验耗时较长,在其完成验证之前,原本没有生效的APT攻击可能会生效,所以云计算系统的安全率为min((y+z)(x+t)).

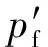
(7)
(8)
3) 检测器正确判定系统受到攻击
如图2中序号为3的博弈所示,检测器正确判定系统受到攻击的前提条件是y+z≤x,即在检测器检测之前,攻击已经生效,其出现的概率是1-pm.此时检测器会触发专家系统进行验证,考虑到专家系统的响应时间,云计算系统的安全率为(y+z)(x+t).专家系统认同检测器的可能性是1-,否定的可能性是.如果攻击被确认,防御者将修复云计算系统;反之,云计算系统得不到修复,其价值被攻击者夺走.该情况下防御者和攻击者的效用分别为
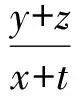
(9)
(10)
4) 检测器错误判定系统未受攻击
图2中序号为4的博弈展现的是检测器错误判定系统未受攻击的情况,其前提条件是y+z≤x,概率为pm.此时APT攻击被APT检测器漏掉,云计算系统被攻击者控制,攻防双方的效用为
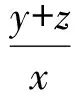
(11)
(12)
综合以上分析可知,防御者的效用函数为
uD(x,y)=I(y+z>x)[(1-pf)uD1+pfuD2]+
I(y+z≤x)[(1-pm)uD3+pmuD4],
(13)
攻击者的效用函数为
uA(x,y)=I(y+z>x)[(1-pf)uA1+pfuA2]+
I(y+z≤x)[(1-pm)uA3+pmuA4].
(14)
将式(5)(7)(9)(11)代入式(13),并整理可得:
uD(x,y)=xGD+I(y+z>x){1-pf+

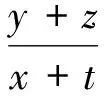
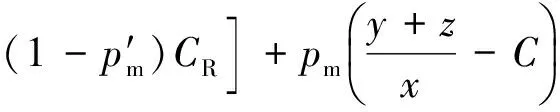
(15)
同样地,将式(6)(8)(10)(12)代入式(14),并整理可以得到攻击者的效用函数如下:
uA(x,y)=I(y+z>x){(1-pf)[-1-
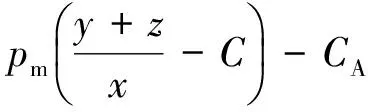
(16)
类似地,还可以得到安全率的表达式,如式(17)所示:
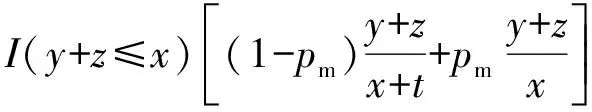
(17)
3 混合策略ES -APT检测博弈
混合策略博弈是纯策略博弈的扩展.运用混合策略可以增加博弈双方行为的不确定性,增加对方准确预测己方行动的难度.本节详细介绍混合策略ES -APT检测博弈中攻防双方的策略空间,求解混合策略均衡,并通过数值分析研究混合策略下ES -APT检测方案的可行性和博弈的性能.
在混合策略ES -APT检测博弈中,APT防御者从策略空间{mM}1≤m≤M中选择检测时间间隔x,APT攻击者从策略空间{nN}0≤n≤N中选择攻击时间间隔y.混合策略是指攻防双方各自按照一定概率,随机地从策略空间中选择一种纯策略作为实际的行动[18].因此,防御者的混合策略为α=[αm]1≤m≤M,其中αm=Pr(x=mM)是将APT检测时间间隔设为x的概率;攻击者的混合策略为β=[βn]0≤n≤N,其中βn=Pr(y=nN)是将攻击时间间隔设为y的概率.由混合策略的定义知
一般而言,不论防御者还是攻击者都无法准确估算APT攻击发起之后,需要多长时间生效,亦即z是一个随机值.为简便起见,以下把z看作常数.
混合策略博弈中的效用函数为期望效用函数.通过对式(15)和式(16)应用期望效用函数理论,得到防御者与攻击者的期望效用函数分别为
(18)
(19)
3.1混合策略纳什均衡
用(α*,β*)表示混合策略ES -APT检测博弈的纳什均衡,有:
(20)
定理1. 如果式(21)的解存在,则式(21)中(α*,β*)是混合策略ES -APT检测博弈的纳什均衡:
(21)
其中,1≤m≤M,0≤n≤N,1ζ是一个ζ维的元素全为1的列向量.
证明. 式(20)是一个有约束条件的优化问题,其拉格朗日函数LD表示为
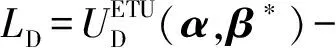
(22)
其卡罗什-库恩-塔克(Karush-Kuhn-Tucker, KKT)条件为
(23)
将式(23)与式(18)和式(22)联立可得:
(24)
求解式(24)即可得到式(21)中的第1行.类似地,运用KKT条件可求得式(21)中的第2行.证毕.
为了使以上结论更为直观,我们在引理1中讨论了ES -APT检测博弈混合策略均衡的一个简单实例.
引理1.M=2,N=1时,当且仅当条件I1和I2都成立时,式(25)和式(26)给出的(α*,β*)是混合策略ES -APT检测博弈的唯一纳什均衡.
(25)
(26)
条件是:
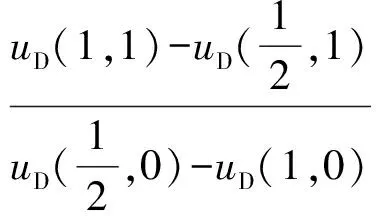
或:

(27)
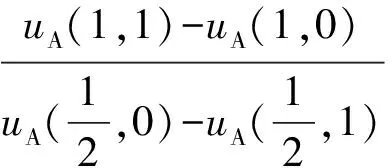
或:
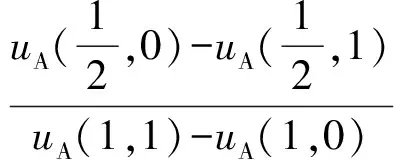
(28)
将式(15)(16)代入式(25)(26)求解知,当M=2,N=1时,混合策略ES -APT检测博弈有唯一纳什均衡,由式(29)给出:
(29)
其中:

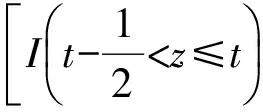

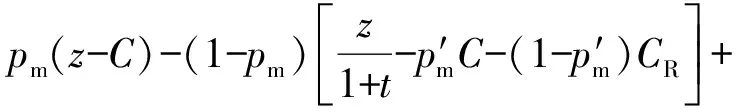
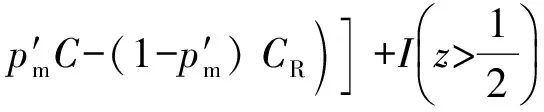
3.2数值分析
本节用数值分析对混合策略ES -APT检测博弈的性能进行研究,主要关注3个指标:APT防御者的效用、APT攻击者的效用和云计算系统的安全率.首先研究专家系统不参与决策时,APT检测器的虚警率、漏报率对以上3个指标的影响;然后分析专家系统参与决策时检测器虚警率、漏报率的影响;最后讨论专家系统的响应时间、虚警率和漏报率对以上指标的影响.为了达到更好的分析效果,本文选取的基本参数是GD=0.24,C=0.25,CR=0.1,CA=0.82.
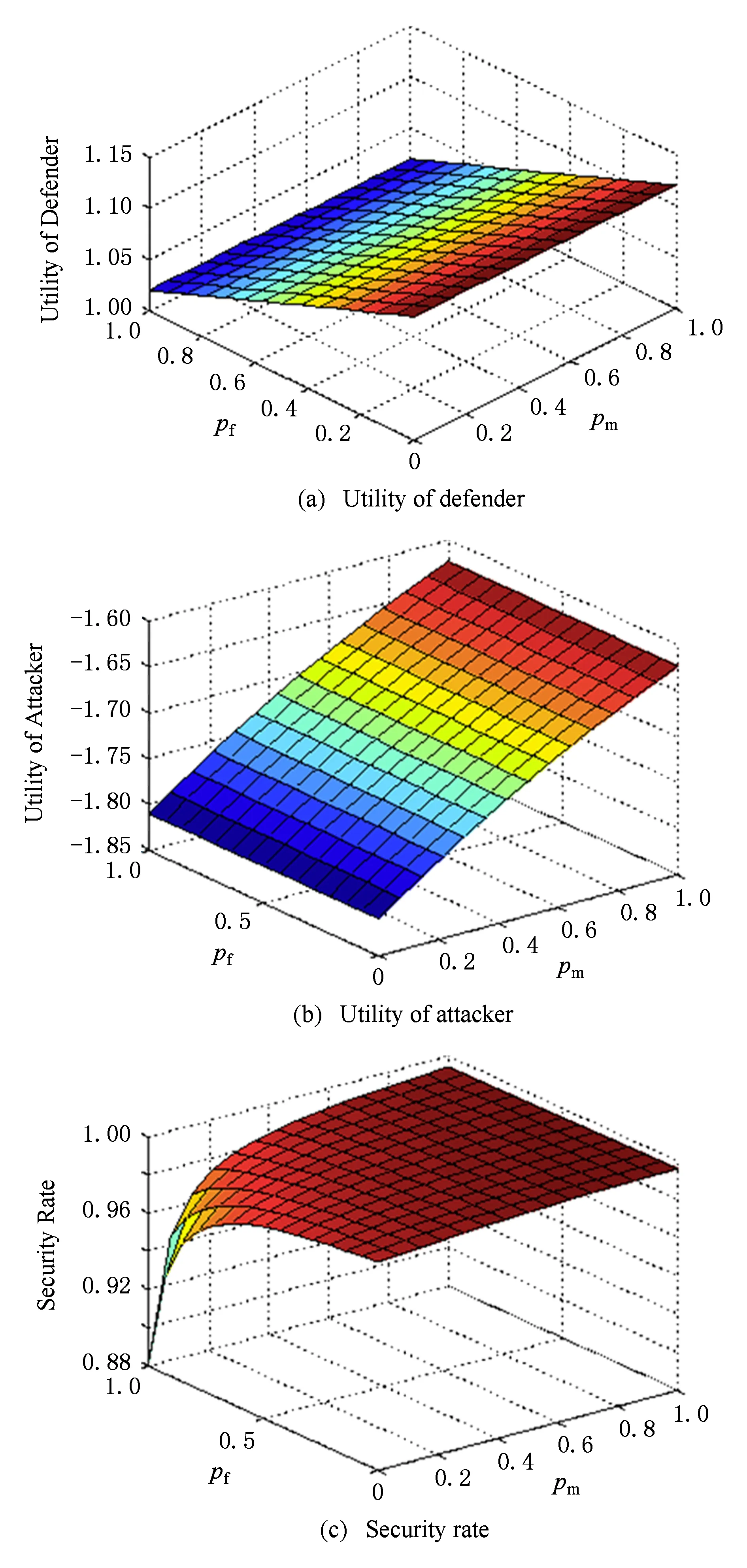
Fig. 3 Performance of the static game over error rates of the APT detector without ES图3 无专家系统时APT检测器错误率对静态博弈的影响
图3显示了专家系统不参与检测时,APT检测器的漏报率和虚警率对混合策略ES -APT检测博弈性能的影响.如图3(a)所示,采用混合策略时,APT防御者的效用不受APT检测器的漏报率影响,但随检测器虚警率的增加而降低,如检测器虚警率从0增加到1时,防御者效用从1.12减少到1.02.图3(b)表明APT攻击者的效用不受检测器虚警率影响,而漏报率的上升能让攻击者效用增加,如检测器的漏报率从0增加到1时,攻击者的效用增加10.3%.APT检测器的漏报率和虚警率对云计算系统安全率的影响如图3(c)所示.当漏报率降低、虚警率增加时,安全率降低,尤其当漏报率接近0、虚警率接近1时,云计算系统的安全率急剧下降.这是因为,对攻击者而言,虚警率越高,APT攻击发动之后、生效之前,因检测器虚警而被防御者阻断的可能性越大.为了尽可能多地窃取信息,APT攻击者必须加快攻击速度,让攻击尽可能在被检测器正确发现之前生效,从而更长时间控制系统.对防御者而言,漏报率接近于0、虚警率接近于1意味着几乎每次检测时检测器都会告警.为了减少虚警出现的次数,防御者会延长检测周期.也就是说,在漏报率低虚警率高的情况下,攻击者会加快攻击速度,而防御者会延长防御周期,从而导致安全率急剧下降.
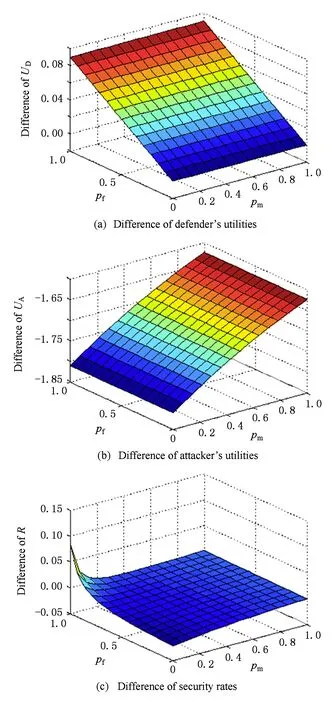
Fig. 4 Performance difference of the static game over error rates of the APT detector between with and without ES图4 有无专家系统情况下APT检测器错误率对静态博弈影响之差
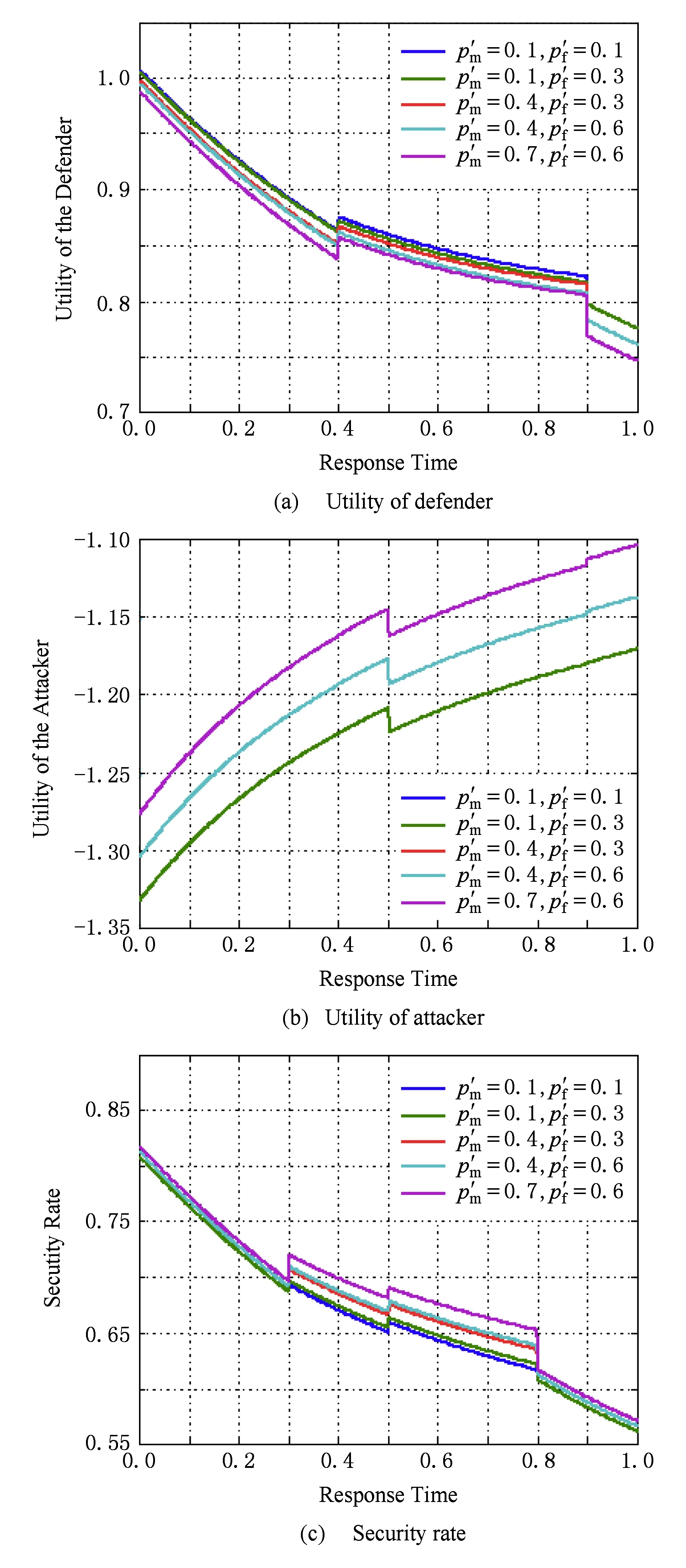
Fig. 5 Performance of the static game over the response time and error rates of ES图5 专家系统性能对静态博弈的影响
综上所述,引入专家系统进行二次检测,可以缓解APT检测器的虚警和漏报给防御者效用以及云计算系统安全率造成的负面影响,提升防御者效用并减少APT检测器的虚警和漏报造成的安全率的波动.而为了使专家系统发挥更好的作用,必须提升专家系统的性能,减少响应时间,降低其漏报率和误报率.因此,在与APT攻击者的对抗中,专家系统必须不断学习,扩充知识库,对APT攻击者的攻击手段进行深入研究,关注并预测新的攻击方法,尽可能先于攻击者发现0day漏洞等.
4 动态ES -APT检测博弈
APT攻击者为了达到攻击目的会不断尝试新的方法.因此,在实际中很多APT攻击者的攻击模型是未知的,其攻击成本、攻击生效时间等因素也不确定.为了应对这种情况,我们用动态ES -APT检测博弈来分析攻击者与防御者之间的行为交互,提出一种基于强化学习算法,即赢或加速学习策略爬山算法(win or learn faster policy hill-climbing, WoLF-PHC)的最优决策方案.在动态ES -APT检测博弈中,防御者用基于WoLF-PHC的最优决策方案来选择防御策略.
策略爬山(policy hill-climbing, PHC)算法是Q-learning算法的扩展,提升了其学习效率.而WoLF-PHC则通过将赢或加速学习(win or learn faster, WoLF)原则用到PHC算法上,进一步提高了算法的收敛性[19].WoLF-PHC和Q-learning一样是离策略算法,不依赖系统模型,且都通过式(30)更新质量矩阵
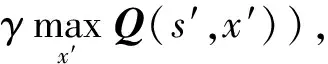
(30)
其中,s是状态,x是防御者的动作,uD表示防御者的瞬时效用.在动态ES -APT检测博弈中,用攻击的整个周期表示系统状态,即s=y+z.最大Q值通过ε-greedy算法选取,即:
(31)
其中,ε∈(0,1),通常是一个很小的正数,M是防御者策略空间中动作的总个数.
基于WoLF-PHC的动态ES -APT检测方案见算法1.
算法1. 基于WoLF-PHC的动态ES -APT检测.
2) fork=1,2,3,… do
3) 更新状态s,s=y+z;
4) 对应s,以概率π(s,x)选择动作x;
5) 依据x对云计算系统进行检测;
6) 观察uD和接下来的状态s,更新状态s;
7) 依据式(30)更新Q;
9) 通过π(s,x)←π(s,x)+Δ更新π(s,x),
10) end for
我们用基于Q-learning的动态ES -APT检测方案[20]作为对照,如算法2所示.
算法2. 基于Q-learning的动态ES -APT检测.
1) 初始化所有参数:μ=0.75,γ=0.7,ε=0.1,y+z=0,Q(s,x)←0;
2) fork=1,2,3,… do
3) 更新状态s,s=y+z;
4) 通过式(31)选择动作x;
5) 依据x对云计算系统进行检测;
6) 观察uD和接下来的状态s,更新状态s;
7) 依据式(30)更新Q;
8) end for
5 模拟仿真
(32)
仿真结果如图6所示.图6(a)展示的是防御者的效用随实验方案运行次数的变化.基于WoLF-PHC动态检测方案,防御者的效用在15次之后收敛到1.125左右,400次的平均效用约为1.116.当采用Q-learning方法时,防御者的效用在35次之后收敛到1.075左右,400次的平均效用约为1.064.Q-learning方法的平均效用比WoLF-PHC方法低大约4.9%,收敛速度也明显较慢.基于ε-greedy算法,防御者的效用一直维持在0.995上下,其平均效用比WoLF-PHC低10.8%.
从图6(b)可知,当防御者基于WoLF-PHC部署动态的ES -APT检测方案时,云计算系统的安全率从0.860逐步上升到1,在算法运行大约18次时收敛,整个400次运行过程中安全率的平均值为0.994.基于Q-learning检测算法,安全率最终能与WoLF-PHC达到同样水平,400次的平均值为0.993,但是Q-learning算法收敛较慢,在大约30次左右收敛.而基于ε-greedy算法,安全率一开始就能上升到0.90左右,但最终也只能维持在这个水平,其400次的平均值比WoLF-PHC检测方案低约10%.
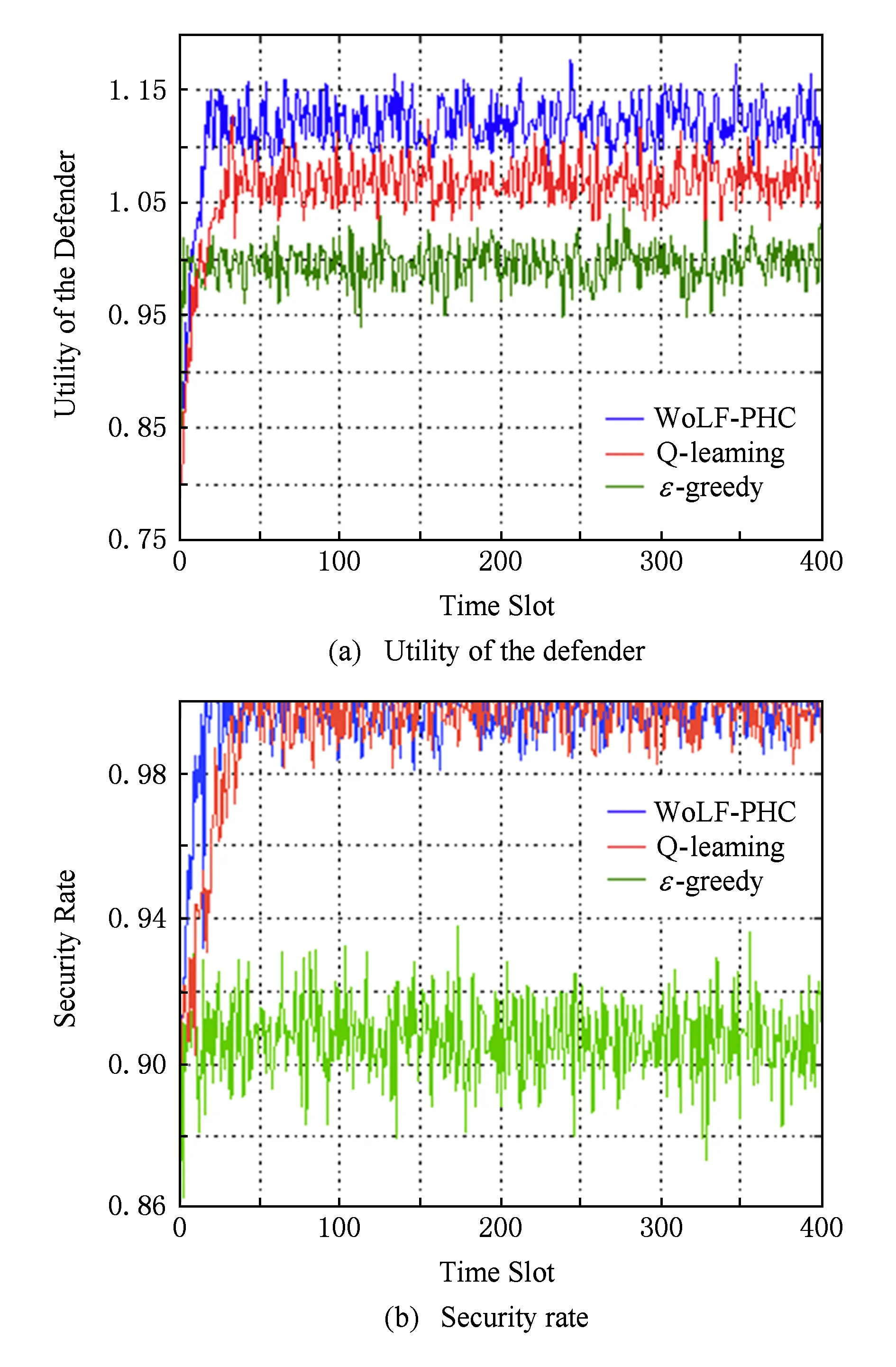
Fig. 6 Performance of the dynamic ES -APT detection game图6 动态ES -APT检测博弈性能图
从图6结果可以看出,基于WoLF-PHC的动态ES -APT检测方案比Q-learning的收敛性好,而且与2种对照方案相比,能明显提高防御者的效用和云计算系统的安全率.
6 总 结
本文提出了一种基于专家系统的APT检测方案,并在此基础上建立了2种ES -APT检测博弈,一个静态博弈和一个动态博弈,求解了静态博弈的混合策略均衡,并用数值分析研究了其性能.数值分析结果显示,虽然专家系统的响应时间和虚警、漏报率对云计算系统的安全率以及攻击者的效用有一定的负面影响,但总体来说,基于专家系统的APT检测方案能够消除因APT检测器的不准确性造成的安全率和防御者效用的降低.通过提升专家系统的性能,可以更好地改善云计算系统的安全性能.在动态博弈中,基于WoLF-PHC算法设计了一种ES -APT动态检测方案,并与基于Q-learning和ε-greedy算法的方法进行了比较.仿真结果表明:在ES -APT动态博弈中,基于WoLF-PHC的ES -APT动态检测方案能让防御者优化其策略,达到更好的防御效果.与Q-learning相比,WoLF-PHC能让防御者更快地获得其最优策略.较之Q-learning和ε-greedy,WoLF-PHC能提高防御者的效用,同时也让云计算系统的安全率更高.
[1] Cole E. Advanced Persistent Threat: Understanding the Danger and How to Protect Your Organization[M]. Rockland, Massachusetts: Syngress Publishing, 2012: 11-36
[2] Coombs M J, Bolc L. Expert System Applications[M]. Berlin: Springer, 1988: 55-63
[3] Lin Wangqun, Wang Hui, Liu Jiahong, et al. Research on active defense technology in network security based on non-cooperative dynamic game theory[J]. Journal of Computer Research and Development, 2011, 48(2): 306-316 (in Chinese)
(林旺群, 王慧, 刘家红, 等. 基于非合作动态博弈的网络安全主动防御技术研究[J]. 计算机研究与发展, 2011, 48(2): 306-316)
[4] Tian Youliang, Peng Changgen, Ma Jianfeng, et al. Game-theoretic mechanism for cryptographic protocol[J]. Journal of Computer Research and Development, 2014, 51(2): 344-352 (in Chinese)
(田有亮, 彭长根, 马建峰, 等. 安全协议的博弈论机制[J]. 计算机研究与发展, 2014, 51(2): 344-352)
[5] He Yunhua, Sun Limin, Yang Weidong, et al. A game theory-based analysis of data privacy in vehicular sensor networks[J]. International Journal of Distributed Sensor Networks, 2014, 10(1): 1-14
[6] He Yunhua, Sun Limin, Yang Weidong, et al. Privacy preserving for node trajectory in VSN: A game-theoretic analysis based approach[J]. Journal of Computer Research and Development, 2014, 51(11): 2483-2492 (in Chinese)
(何云华, 孙利民, 杨卫东, 等. 基于博弈分析的车辆感知网络节点轨迹隐私保护机制[J]. 计算机研究与发展, 2014, 51(11): 2483-2492)
[7] Wang Yichuan, Ma Jianfeng, Lu Di, et al. Game optimization for internal DDoS attack detection in cloud computing[J]. Journal of Computer Research and Development, 2015, 52(8): 1873-1882 (in Chinese)
(王一川, 马建峰, 卢笛, 等. 面向云环境内部DDoS攻击检测的博弈论优化[J]. 计算机研究与发展, 2015, 52(8): 1873-1882)
[8] Marten V D, Ari J, Oprea A, et al. Flipit: The game of stealthy takeover[J]. Journal of Cryptology, 2013, 26(4): 655-713
[9] Zhang Ming, Zheng Zizhan, Shroff N B. A game theoretic model for defending against stealthy attacks with limited resources[C] //Proc of the 6th Decision and Game Theory for Security. Berlin: Springer, 2015: 93-112
[10] Farhang S, Grossklags J. Flipleakage: A game-theoretic approach to protect against stealthy attackers in the presence of information leakage[C] //Proc of the 7th Decision and Game Theory for Security. Berlin: Springer, 2016: 195-214
[11] Xu Dongjin, Li Yanda, Xiao Liang, et al. Prospect theoretic study of cloud storage defense against advanced persistent threats[C] //Proc of the 60th Global Communications Conf. Piscataway, NJ: IEEE, 2017: 1-6
[12] Xiao Liang, Xu Dongjin, Xie Caixia, et al. Cloud storage defense against advanced persistent threats: A prospect theoretic study[J]. IEEE Journal on Selected Areas in Communications, 2017, 35(3): 534-544
[13] Xu Dongjin, Xiao Liang, Mandayam N B, et al. Cumulative prospect theoretic study of a cloud storage defense game against advanced persistent threats[C] //Proc of the 36th IEEE Int Conf on Computer Communications (IEEE INFOCOM WKSHPS 2017). Piscataway, NJ: IEEE, 2017
[14] Hu Pengfei, Li Hongxing, Fu Hao, et al. Dynamic defense strategy against advanced persistent threat with insiders[C] //Proc of the 34th Int Conf on Computer Communications (IEEE INFOCOM 2015). Piscataway, NJ: IEEE, 2015: 747-755
[15] Feng Xiaotao, Zheng Zizhan, Hu Pengfei, et al. Stealthy attacks meets insider threats: A three-player game model[C] //Proc of the 34th Military Communications Conf (IEEE MILCOM 2015). Piscataway, NJ: IEEE 2015: 25-30
[16] Abass A, Xiao Liang, Mandayam N B, et al. Evolutionary game theoretic analysis of advanced persistent threats against cloud storage[J]. IEEE Access, 2017, 5(1): 8482-8491
[17] Xiao Liang, Li Yan, Han Guoan, et al. Phy-layer spoofing detection with reinforcement learning in wireless networks[J]. IEEE Trans on Vehicular Technology, 2016, 65(12): 10037-10047
[18] Osborne M J, Rubinstein A. A Course in Game Theory[M]. Cambridge, Massachusetts: MIT Press, 1994: 29-40
[19] Bowling M, Veloso M. Rational and convergent learning in stochastic games[C] //Proc of the 33rd Int Joint Conf on Artificial Intelligence. San Francisco: Margan Kaufmann, 2001: 1021-1026
[20] Hu Qing, Lü Shichao, Shi Zhiqiang, et al. Defense against advanced persistent threats with expert system for Internet of things[G] //LNCS 10251: Proc of the 12th Int Conf on Wireless Algorithms, Systems, and Applications. Berlin: Springer, 2017: 326-337
AdvancedPersistentThreatsDetectionGamewithExpertSystemforCloud
Hu Qing1,2, Lü Shichao1,2, Shi Zhiqiang1,2, Sun Limin1,2, and Xiao Liang3
1(SchoolofCyberSecurity,UniversityofChineseAcademyofSciences,Beijing100049)2(BeijingKeyLaboratoryofIOTInformationSecurityTechnology(InstituteofInformationEngineering,ChineseAcademyofSciences),Beijing100093)3(DepartmentofCommunicationEngineering,XiamenUniversity,Xiamen,Fujian361005)
Cloud computing systems are under threaten of advanced persistent threats (APT). It is hard for an autonomous detector to discover APT attacks accurately. The expert system (ES)can help to reduce detection errors via double-checking suspicious behaviors. However, it takes an extended period of time for the ES to recheck, which may lead to a defense delay. Besides, the ES makes mistakes too. In this paper, we discuss the necessity of the ES to participate in APT detection and defense for a cloud computing system by game theory, based on the consideration of miss detection rates and false alarm rates of both the APT detector and the ES. The ES -based APT detection method is designed, and the ES -APT game between an APT attacker and a defender is formulated. We derive its Nash equilibrium and analyze how the ES enhances the security of the cloud computing system. Also, the dynamic game is studied, in case that the APT attack model is unknowable. We present a reinforcement learning scheme for the cloud computing system with ES to get the optimal strategy. Simulation results show that, with the knowledge of the ES, both the defender’s utility and the cloud computing system’s security are improved compared with benchmark schemes.
advanced persistent threats (APT); cloud security; expert system (ES); game theory; reinforcement learning
TP393.08

HuQing, born in 1985. PhD candidate. Member of CCF. Her main research interests include advanced persistent threats and IOT security.

LüShichao, born in 1985. PhD candidate, engineer. Member of CCF. His main research interests include wireless communication systems security (lvshichao@iie.ac.cn).

ShiZhiqiang, born in 1970. PhD, senior engineer, PhD supervisor. Senior member of CCF. His main research interests include industrial control system security, cyber security, etc.

SunLiMin, born in 1966. PhD, professor, PhD supervisor. Senior member of CCF. His main research interests include IOT security, cyber security, etc (sunlimin@iie.ac.cn).

XiaoLiang, born in 1980. PhD, professor, PhD supervisor. Senior member of CCF. Her main research interests include network security, wireless communications, smart grids, etc (Lxiao@xmu.edu.cn).
猜你喜欢
建材发展导向(2021年7期)2021-07-16
中国药学药品知识仓库(2021年18期)2021-02-28
商品与质量(2020年18期)2020-11-27
冰雪运动(2018年3期)2018-12-29
火力与指挥控制(2018年10期)2018-11-13
现代农业科技(2017年5期)2017-04-19
电子制作(2017年10期)2017-04-18
现代农业科技(2017年1期)2017-03-06
现代经济信息(2016年4期)2016-06-20
中西医结合心血管病电子杂志(2014年8期)2015-07-20
