
图书馆的大数据处理和应用策略
2017-11-01 18:00韩凤勇
河南图书馆学刊 2017年10期
韩凤勇
关键词:图书馆;大数据;数据处理;应用策略
摘 要:文章介紹了图书馆大数据的来源、特点和大数据的处理技术,分析了图书馆应用大数据技术的实际意义,提出了图书馆运用大数据处理技术开展信息服务的策略与方法。
中图分类号:G250文献标识码:A文章编号:1003-1588(2017)10-0125-03
1 背景
大数据一般需要新处理模式才能具有更强的决策力、洞察力和流程优化能力,以便取得海量、高增长率和多样化的信息资产。其数据处理方式不同于传统意义上的数据处理,而是由一定的统筹能力、敏锐的趋势判断能力、强大的决策能力和流程优化能力所构成的全新处理模式。近年来,随着云技术、近距离无线通信技术、物联网等技术的不断成熟,各种信息资源大量出现,给人们的工作和生活带来了极大的便利,值得一提的是图书馆数字技术的应用在给人们阅读带来便捷的同时,也影响着图书馆工作的方方面面。
2 图书馆的大数据
2.1 大数据的来源
图书馆大数据来源包括:(1)商业数字平台。图书馆采购的数字资源和平台,如超星手机图书馆、读秀、百链系统、CNKI学术期刊以及各种图片、音频、视频等资源库。(2)自建资源库。大量图书、期刊、光盘的MRAC数据及这些图书、期刊随书的音、视频数据及本馆制作的各类特色资源库等。(3)互联网数据。读者网络浏览信息、图书的评论信息、读者的网上社交信息、读者所处地理位置、读者的阅读倾向、读者消费记录等个人信息。(4)传感器数据。馆内安装的温度、客流、声音、防火、安全等传感器不停地对周围进行检测,并不断生成具有分析价值的数据。(5)RFID(无线射频技术)。目前,国内许多图书馆已经使用了RFID技术对文献进行管理,人们对这些安装有RFID芯片的文献进行跟踪、分析、研究、总结,能够得出许多有价值的大数据信息。
以上所提到的图书馆大数据按结构归纳,可分为结构化数据和非结构化数据。存储在SQL Server等关系数据库中的图书馆数字资源库和各平台产生的数据,从结构上划分属于前者;而音频、视频、图片等文献属于非结构化数据,此类数据比结构化数据容量大出许多。
2.2 图书馆大数据的特点
图书馆的大数据满足“3V”定义,即规模大(Volume)、变化多样(Variety)、价值密度低(Value)。其特点有:(1)数据量大。如:国家图书馆2005年开始信息化建设,2010年数字资源量就达到了480TB,2011年增长到了561TB,到2012年数字总资源已达到807.3TB,近年来更是呈爆发式增长态势。(2)数据多样性。图书馆的大数据有本馆制作的特色资源、商业数字平台及各应用系统的结构化数据,另外,还有非结构化的音、视频文件及图片等数据。(3)价值密度低。价值密度的高低与数据总量的大小成反比。以视频为例,一部一小时的视频,在连续不间断的监控中,有用的数据可能仅有一二秒,也就是说虽然信息量很大,但必须将大量数据信息统筹分析研究,才能从中挖掘出有价值的数据,而这个挖掘的过程,是目前大数据背景下亟待解决的难题。
3 研究图书馆大数据的意义
3.1 节约成本
在共享、合作、开放的理念下,图书馆不需要添置大量的硬件设备,只需通过大数据技术即可进行信息管理,其可将电子文献储存在第三方供应商的大数据服务器上,通过网络共享解决读者使用的问题。
3.2 方便使用
图书馆以现有资源为依托,对读者阅览习惯、行为模式的大数据进行分析,这是一种对现有资源的分析与挖掘。图书馆运用其分析结果为不断提升智能化管理水平,提高服务质量提供了决策依据,提高了读者利用图书馆的效率,改善了读者的阅读习惯。
3.3 建立更加完善的信息服务机制
图书馆对大数据进行分析和研究,能够指导读者从众多信息中准确找到自己所需的信息,使馆员更为准确、智能地预测读者需求,进而提高图书馆的服务效能。
4 大数据处理技术
4.1 并行数据库
并行数据库是处理数据的一种技术,出现在20世纪80年代,属于关系型数据库,是建立在并行计算和MPP环境基础上的数据库,主要存储结构化数据,它通过纵向(Scale Up)和横向(Scale Out)的扩展来实现。纵向扩展是增添高性能的CPU、增加RAM容量或更换更快的硬盘,以提升某节点的性能,但扩展是有限的;横向扩展指在节点增加服务器形成集群,使并行数据库的处理能力得到提升,如果某一节点性能较低,便会影响该集群的整体处理能力,这种处理方式对单个节点硬件的要求较为苛刻,成本较高。
4.2 云计算
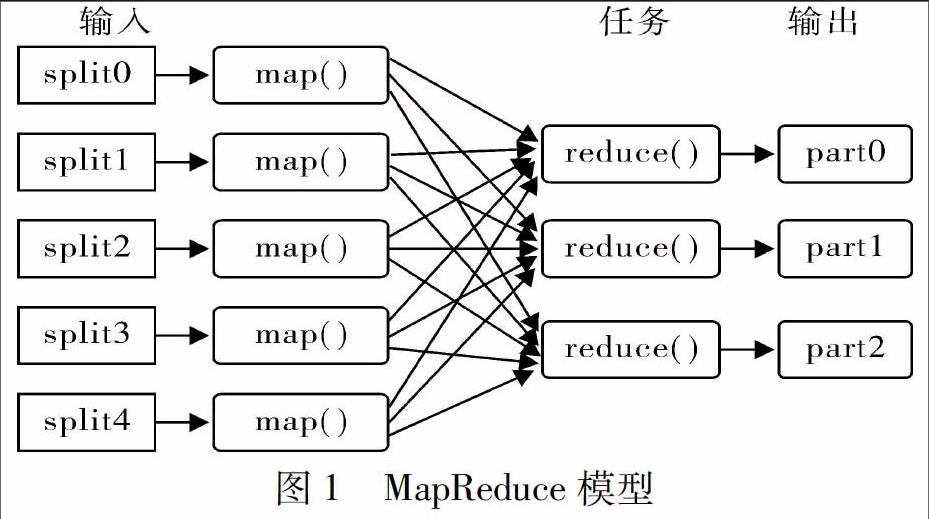
云计算技术是以网格计算为基础逐步发展成熟起来的一种新兴技术,具有并行和分布式计算的特点。其本质是海量的数据存储和数据的并行计算,技术比较成熟,可行性比较高。目前,云计算主要有以下几种技术:(1)谷歌公司的不开源分布式文件可扩展系统,为巨量数据存储、搜索而设计,用于大型分布式数据的访问。它运行在普通的硬件上,有自己的容错机制,能够为众多用户提供总体性能较高的服务。(2)Hadoop分布式文件系统(HDFS),是能够运行在通用硬件上的分布式文件系统,具有高度容错机制以及开源性的分布式文件系统,适合部署在廉价的设备上,提供带宽比较高的数据访问。目前雅虎、淘宝等许多互联网公司都采用该文件系统。(3)编程模型(Map Reduce)是处理大数据的基础。编程模型用于并行运算大于1TB的数据集,其概念Reduce(归约)、Map(映射)及模型内涵,是从函数式编程语言借鉴而来,这针对不熟悉分布式并行编程的人员来说,可以通过该模型方便地将程序运行在分布式系统上,其流程见图1。
5 处理图书馆的大数据
5.1 大数据的存储endprint
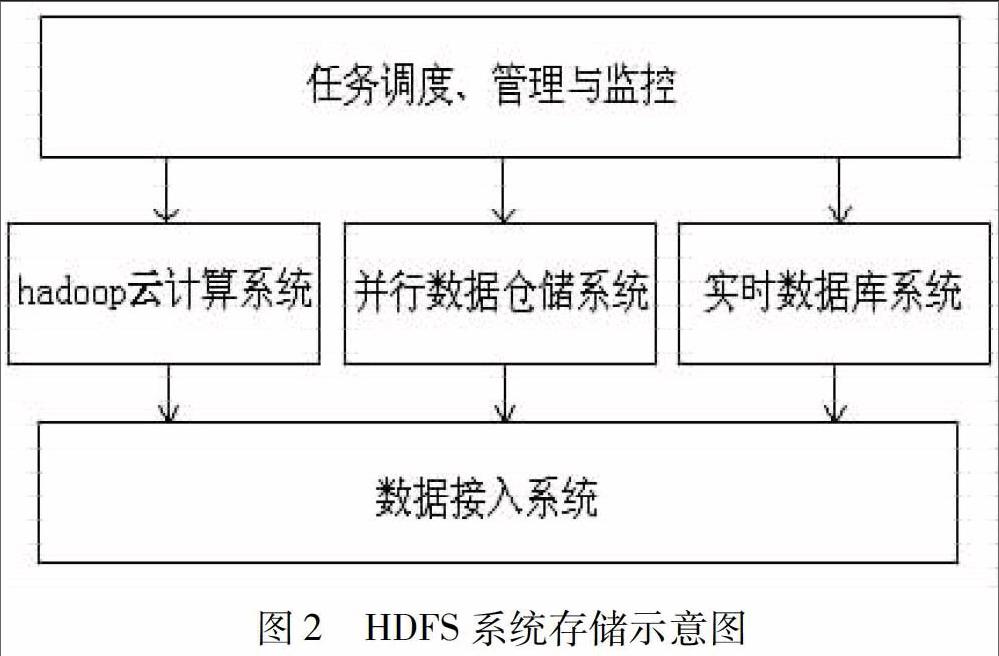
图书馆虽然可以利用HDFS来存储图书馆大數据,但是无法满足实时性的要求,因此需要对大数据分类并使用不同方式进行存储。如实时性较高的数据应存储到实时数据库,实时性要求不高的数据或各业务系统产生的数据应存储到并行数据仓库,大量的历史数据和非结构化数据应存储到HDFS系统(见图2)。
5.2 大数据的展现
图书馆的大数据经过分析会有许多结果呈现在用户界面上,用户界面要注重结构设计、交互设计、视觉设计,应做到易用性、规范性、合理性、排错性、节能性,符合页面布局合理、易操作、响应时间短等要求。
6 图书馆大数据的应用策略
6.1 建立图书馆内部数据资源集成库
图书馆应通过科学的方法,运用大数据技术对本馆现有的“小数据”进行收集、整理、挖掘和分析,逐步建立本馆自己的信息数据资源集成库,可优化服务流程,提高服务效率。
6.2 建立信息核心资源数据模块
图书馆在掌握读者信息需求的基础上,要从“小数据”应用开始积累经验,并通过整合优化内外部信息资源的数据构架,从源头上为建立核心资源数据模块夯实基础,使之能尽快投入到信息服务平台的运营中。
6.3 建立非结构化的信息库
目前,以手机、PAD为代表的个人智能终端设备,已经成最主要的个人信息来源,所以图书馆很有必要建立社会化、非结构化的信息库。提升图书馆信息数据资源的整体分析能力,有利于加快实现图书馆信息资源智能化服务步伐。
6.4 云技术和大数据技术融合
建立信息全面、内容丰富的数字图书馆,需要强大的数据发现能力、数据处理能力和数据存储能力,这些都需要先进的数据分析技术作为保障。
目前,要解决上述问题,云计算技术是一种最好的技术方案。图书馆应用云技术处理大数据,应做到以下几点:(1)充分利用云技术,创建大数据基础架构,让大数据在云平台上运行,这是云技术的灵魂,也是推进图书馆转型升级的必由之路。(2)利用云技术构建信息资源“数据集合”,这是目前嫁接分布式处理的最经济、最有效的手段,充分显示了云技术的优势,图书馆可通过第三方供应商构建图书馆信息服务云,解决“数据集合”的问题。(3)图书馆运用云技术对大数据进行分析,围绕读者个性化需求,精心设计读者的个性化服务方案,以释放出更多的潜在价值。
6.5 选择适合自身的大数据解决方案
存储、处理和分析大数据就需要有相应的数据挖掘技术解决方案,目前国际上较为成熟的方案有Intel的Spark开源集群计算环境,华为的OceanStor9000大数据存储系统,IBM的IBMPower分析应用平台。它们拥有各自的特点和优势,图书馆应根据自身情况选择一款适合自己的软件,作为知识管理的应用平台。
7 结语
数字化信息的增长催生出了“大数据”的概念,并逐渐地渗入图书馆工作中,这必将影响或改变图书馆的服务。展望未来,大数据服务技术与热点会不断涌现,它将对图书馆知识服务的拓展和深化带来重大影响。图书馆未来的工作将是“数据驱动”的图书情报工作。图书馆的大数据技术及服务将是一项复杂的系统工程,涉及数据的管理水平、数据的处理技术及数据服务的创新等,需要广大图书馆员共同努力。
参考文献:
[1] 张德丰.云计算实战[M].北京:清华大学出版社,2012:44-47.
[2] 刘刚.Hadoop应用开发技术详解[M].北京:机械工业出版社,2014:10-20.
[3] 张兴旺.图书馆大数据体系构建的学术环境和战略思考[J].情报资料工作,2013(2):12-17.
[4] 王天泥.知识咨询:大数据时代图书馆的知识服务增长点[J].图书与情报,2013(2):74-77.
[5] 姜山,王刚.大数据对图书馆的启示[J].图书馆工作与研究,2013(4):52-54.
[6] 裴昱.大数据时代图书馆用户行为信息的利用方式[J].图书馆学刊,2013(8):44-46.endprint
猜你喜欢
计算技术与自动化(2022年1期)2022-04-15
科技创新导报(2021年33期)2021-04-17
智富时代(2019年4期)2019-06-01
智富时代(2019年4期)2019-06-01
小太阳画报(2018年1期)2018-05-14
电子技术与软件工程(2016年24期)2017-02-23
考试周刊(2016年77期)2016-10-09
考试周刊(2016年77期)2016-10-09
成才之路(2016年26期)2016-10-08
小天使·一年级语数英综合(2014年8期)2014-06-26
