
基于卷积神经网络的车辆品牌和型号识别
2017-11-01 08:58黎哲明蔡鸿明姜丽红
东华大学学报(自然科学版) 2017年4期
黎哲明, 蔡鸿明, 姜丽红
(上海交通大学 软件学院, 上海 200240)
基于卷积神经网络的车辆品牌和型号识别
黎哲明, 蔡鸿明, 姜丽红
(上海交通大学 软件学院, 上海 200240)
车辆品牌和型号的识别属于细粒度分类领域的一类问题, 与只针对不同物体的图像识别相比, 待分类的车辆品牌和型号之间差异较小, 分类较困难.卷积神经网络在静态图像上具有强大的特征发现能力, 近年来在图像分类问题中成果显著.结合卷积神经网络和开源的大量标注数据集设计出了完整的车型识别模型, 引入区域分割从而提高了识别的准确率, 同时根据移动互联网的特性设计了交互方式.通过试验验证, 该方法可以有效地解决查询图片识别具体车辆品牌及型号的问题.
车型识别; 细粒度分类; 卷积神经网络; 区域分割; 图像处理
车型识别有着广泛的应用前景, 如,在智能交通领域能够利用车型识别对道路交通情况进行统计, 在汽车销售领域可帮助潜在购车用户更好地了解感兴趣的车辆信息.车型识别的范围较广, 不仅仅局限于数字和字母,而且由于无法对固定的区域进行特征提取, 因此面临着较大的挑战.
在车辆图片识别领域研究中, 车辆所属交通工具的分类(bus、truck、van、small car)问题的解决已取得了比较理想的成果.文献[1] 利用图像的SIFT(scale invariant feature transform)特征并结合支持向量机训练出分类器, 有效完成车辆所属交通工具的分类.文献[2] 提出一种2阶段分类方法: 第1阶段采用支持向量机、K近邻、随机森林和多层感知机4种分类器接收Gabor和PHOG(pyramid histogram of oriented gradients)特征进行分类, 这一阶段的输出可作为第2阶段的输入, 通过旋转森林对未区分的结果进行进一步分类处理.与上述研究相比, 精确分类具体车辆品牌和型号(car make and model recognition)更具有挑战性.待分类的类别之间差别细微, 属于细粒度分类问题(fine-grained classification), 其对图像特征的提取及分类有着更高的精度要求.与车型识别类似的研究中, 文献[3-4]提出了结合卷积神经网络与大量的训练数据,分别实现对狗和花类图片的品种分类的方法.目前, 针对精确分类车辆品牌和型号的研究中, 文献[5-6]分别对车辆前后视图的特定区域进行特征提取, 之后与标注库中的图片匹配得到分类结果; 文献[7]提出了一种首先提取图像的全局形状特征以获得与标注图像集的相似度, 再结合选定的局部直方图特征相似度并计算相似度加权和, 以此改进分类效果的方法.
由以上研究现状可知, 车型识别的研究主要存在以下两个问题: (1) 对于能够满足任意角度查询图片的条件下, 识别的粒度还停留在交通工具上的分类; (2) 能够精确到具体车辆品牌和型号的分类往往需要限定查询图片的拍摄角度, 只能从特定拍摄角度, 如前视图或后视图的图像中完成车辆识别及分类过程.因此, 如何实现对不同角度的图片都能完成车型识别是一项极具挑战的任务.
针对上述两个问题, 本文提出了一种基于卷积神经网络(CNN)的车型识别方法, 借助深度神经网络强大的特征提取能力, 取代传统人工选择的SIFT等特征及分类器训练, 完成对细节特征的发现, 以实现对不同角度查询图片的车型识别.同时, 结合当前更为普遍的移动互联网模式, 采用手机客户端和云服务器的模式进行系统设计.本文工作包括以下3点: (1) 利用卷积神经网络完成大量车型标注图像集的特征提取及分类器训练, 实现对各种不同角度的车辆图片进行车型分类的目标; (2) 通过区域识别等方法完成车辆区域和背景区域的切割, 去除背景噪声达到提高识别精度的目标; (3) 针对移动互联网的特性通过图像压缩等技术减小客户端与服务器的图像传输成本, 提高响应速度.
1 云环境下移动端车型识别处理框架
移动用户的规模随着互联网的发展而高速增长, 移动互联网服务变得更加便捷和快速.但不论是基于特征选择还是卷积神经网络的车辆图片识别问题均属于计算密集型工作, 而移动设备自身的计算和存储能力有限, 且电池续航能力较差, 难以完成整个图像处理和识别分类的过程.
因此, 为了解决移动设备便捷性与计算能力不足之间的矛盾, 采用移动客户端和云端服务相结合的模式.云环境下移动端车型识别处理框架如图1所示, 主要由应用层和服务层两部分组成.应用层将查询图片传输到服务层, 为了降低图片传输的等待时间, 应用层将在尽可能不丢失图像信息的基础上采用图像压缩技术减小查询图片的大小.服务层在收到查询图片后进行的操作包括图像预处理、车辆区域切割提取、模型分类3个部分, 其中,车辆区域切割是为了将图像中的车辆区域与背景区域分离, 减少背景像素带来的噪声干扰.

图1 云环境下移动端车型识别处理框架图Fig.1 Mobile car make and model recognition processing framework in cloud environment
2 基于卷积神经网络的车型识别
2.1图像采集及传输
应用层面向使用移动设备的用户, 通过将直接拍摄车辆或者来源于互联网的图片作为查询图片提交给服务层处理.
为了减小图片的传输成本, 在应用层需要对查询图片进行压缩, 但又需要尽可能保证压缩后的图片质量不被破坏以达到理想的识别效果.为了兼顾两者, 本文采用谷歌在2017年开发的Guetzli压缩工具, 该工具可通过对图片全局量化表进行微调, 对DCT(discrete cosine transform)系数的高频部分实现有选择的丢弃.试验证明, 该工具能在不损失图片质量的情况下达到最高35%的压缩率, 可有效完成图片压缩.车辆图片采用Guetzli压缩前后的图片如图2所示, 压缩前图片的大小为488 KiB, 压缩后可减小到320 KiB.

(a) 压缩前

(b) 压缩后
2.2图像预处理
由于拍摄角度和光线等因素可能会造成拍摄的图片质量不高, 因此服务层在接收到来自应用层的查询图片后需要对图像做一些预处理, 主要的操作包括图像去噪和图像增强两部分,这两种操作均采用小波变换的方式实现. 首先对图像进行小波变换, 得到图像的不同频率分量的小波变换系数.其次, 对高频系数进行适当的增强处理, 再进行小波逆变换, 达到图像的细节或边缘增强的目的. 由于噪声大多属于高频信息, 当进行小波变换之后, 噪声信息大多集中在高频子块之中, 对这一部分系数进行抑制, 可达到一定的噪声去除效果.
2.3车辆区域分割
无论是车辆的训练图片还是查询图片, 往往都包含着需要识别的车辆区域及其背景区域.对于车型识别, 所有背景区域都应该作为噪声去除.车辆区域分割要解决的主要问题是确定车辆在图片中的位置信息.
在传统方法的实现中, 区域分割的解决基本都遵循“设计手工特征(hand-crafted feature)+分类器”的思路.该过程包含区域搜索的步骤, 类似于计算机用一个小的矩形窗口不断在图像上滑动和缩放, 然后采用分类器预测当前滑动窗口所在区域是否存在感兴趣的对象.但是, 手工选择的特定特征(如SIFT等)往往不能充分体现图片的特征, 达不到理想的效果.随着卷积神经网络在图像分类上的应用, 研究发现将其与区域划分结合后,卷积神经网络能够更有效地解决区域分割这一问题.rCNN(regions with CNN)即是一个基于上述思想而提出的区域分割算法[8], 流程包括以下4个步骤:
(1) 1张图像生成1 000~2 000个候选区域;
(2) 对每个候选区域, 使用卷积神经网络进行特征提取;
(3) 提取的特征送入每一类的SVM(support vector machine)分类器, 判别是否属于该类;
(4) 使用回归器精细修正候选框位置.
其中, 候选区域的生成采用选择性搜索方法[9], 该算法可在图片中选出多个区域, 这些区域将作为物体识别的候选区域.对图像进行区域提取后, 将每个区域作为输入, 利用卷积神经网络进行特征提取.采用开源框架Caffe[10]进行神经网络的训练, 以ILSVRC图像数据作为训练集.神经网络的设计共分为8层: 前5层为卷积层,其后 2层为全连接层, 最后1层为标签层.在神经网络的训练过程中, 为了适配网络, 将输入图像向下取样为227像素× 227像素的大小, 将图像按比例缩放至短边为227像素, 然后截取长边中间227像素的部分.
由于选择搜索算法对于每一张图片都将产生大量的建议区域, 数量过多且互相重叠, 有许多冗余的区域, 因此在进行物体识别后, 采用贪心的非极大抑制算法对区域进行筛选, 具体算法如下:

Require:所有预测区域集合RS所有预测类别列表C={C1,C2…Cn}每个区域的预测类别列表及相应分数Ensure:保留的区域集合RS1Loop:对于每一个预测的类Ci1.RSi={}2.将RS按Ci的预测分数从高到低排序3.将最高的区域加入RS中4.计算其他区域与RSi中区域面积的交集并集之比IoU5.如果IoU均小于一定阈值,加入到RSi中End:RS1=RS1∪RS2∪...∪RSn
在本文中, 将阈值设为0.5, 实现对预测分数非最大的区域进行抑制, 从而避免区域的重复标注.贪心的非极大抑制算法获得的车辆区域分割结果如图3所示, 其中图3(a)为采用选择性搜索生成的候选区域.随后对这些候选区域通过卷积神经网络进行特征提取,并利用SVM进行分类, 其中结果大于0.5的区域认为是车辆区域.最后通过非极大抑制算法完成区域的合并, 得到如图3(b)所示的输出结果.

(a) 选择性搜索方法

(b) 贪心的非极大抑制算法图3 采用贪心的非极大抑制算法获得的车辆区域分割结果Fig.3 Products of region segmentation using greedy non-maximum suppression algorithm
2.4基于卷积神经网络的车型分类器实现
在完成对车辆区域和背景区域的分割之后, 将分割出的车辆区域作为输入进行分类器的训练.
本文结合卷积神经网络和斯坦福大学提供的标注车辆图片库[11]中的16 185张图片和196种车辆类别进行试验, 用于解决车辆图片的细粒度分类问题.采用的神经网络模型结构为AlexNet[12]的修改版, 一共包括8层: 5层卷积层和3层全连接层, 最后一层全连接层为输出分类层.第1层卷积层采用96个大小为11 × 11和步长为4 ×4的卷积核, 得到的输出再经过池化操作后得到大小为27 × 27 × 96的输出隐层, 同时也作为第2层卷积层的输入.之后的操作与上述相似, 各卷积层的卷积核大小分别为5 ×5、3 × 3、3 × 3和3 × 3, 过滤器数量依次为256、384、384和256, 步长均为1 × 1.其中, 第3和第4层卷积层将卷积后的结果直接作为下一层输入, 而第2和第5层在卷积后还需要再进行池化操作.池化层均采用大小为3 × 3和步长为2 × 2的max pooling(特征最大汇总), 每次计算可以减少一半的神经元, 起到减少计算量以及有效控制过拟合的作用.同时根据训练集的样本类别个数,将最后全连接层的输出大小修正为196.
模型采用ReLu函数代替传统的Logistics函数作为激活函数, 使得前向传播和利用偏导计算反向梯度都变得更容易, 避免了指数和除法之类的复杂操作.同时, 抛弃输出为0的隐层神经元, 以此增加网络的稀疏性, 也在一定程度上达到缓解过拟合的作用.采用减法归一化对卷积特征进行归一化操作. 减法归一化是针对一个卷积特征而言, 反映了一个卷积特征中某个位置与邻域位置的关系.减法归一化的具体操作是将目标位置与邻域位置进行加权和相减, 邻域位置的权值大小与邻域位置距离目标位置的长度有关.
在训练之前, 首先采用贪心的非极大抑制算法将所有的标注样本进行车辆区域与背景区域的分割, 并将车辆区域剪裁成224像素 × 224像素的大小以符合网络输入.数据集按照9∶1的方式分割为训练集和测试集. 卷积神经网络结构如图4所示, 训练集训练完成后利用测试集评估结构的好坏.
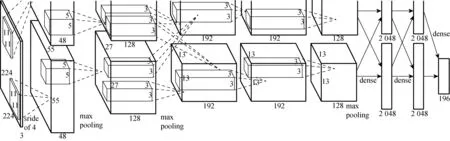
图4 卷积神经网络结构Fig.4 Framework of CNN
2.5服务结果生成
通过训练完成的车型分类器得到了具体车型后, 可结合网络中的开放数据获得如车速、排量等基本信息.除此之外, 也可以采用主题模型LDA(latent dirichlet allocation)等方法对汽车论坛中的用户评论数据进行挖掘, 总结出关键字后提供给应用层用户, 使其获得更多的相关信息.
3 系统实现及验证
3.1系统实现
基于卷积神经网络的车型识别系统实现界面如图5所示, 分别包含安卓移动客户端的实现界面和后台识别服务界面.
3.2试验环境
利用深度网络开源训练框架Caffe, 在Intel Corei7、GTX540环境下进行训练, 数据集采用斯坦福开源车辆数据集.
3.3试验结果对比与讨论
本文试验方法与针对车辆后视图[4]、前视图[13]的车型分类或是任意角度的交通类型分类[14]的识别结果对比如表1所示.
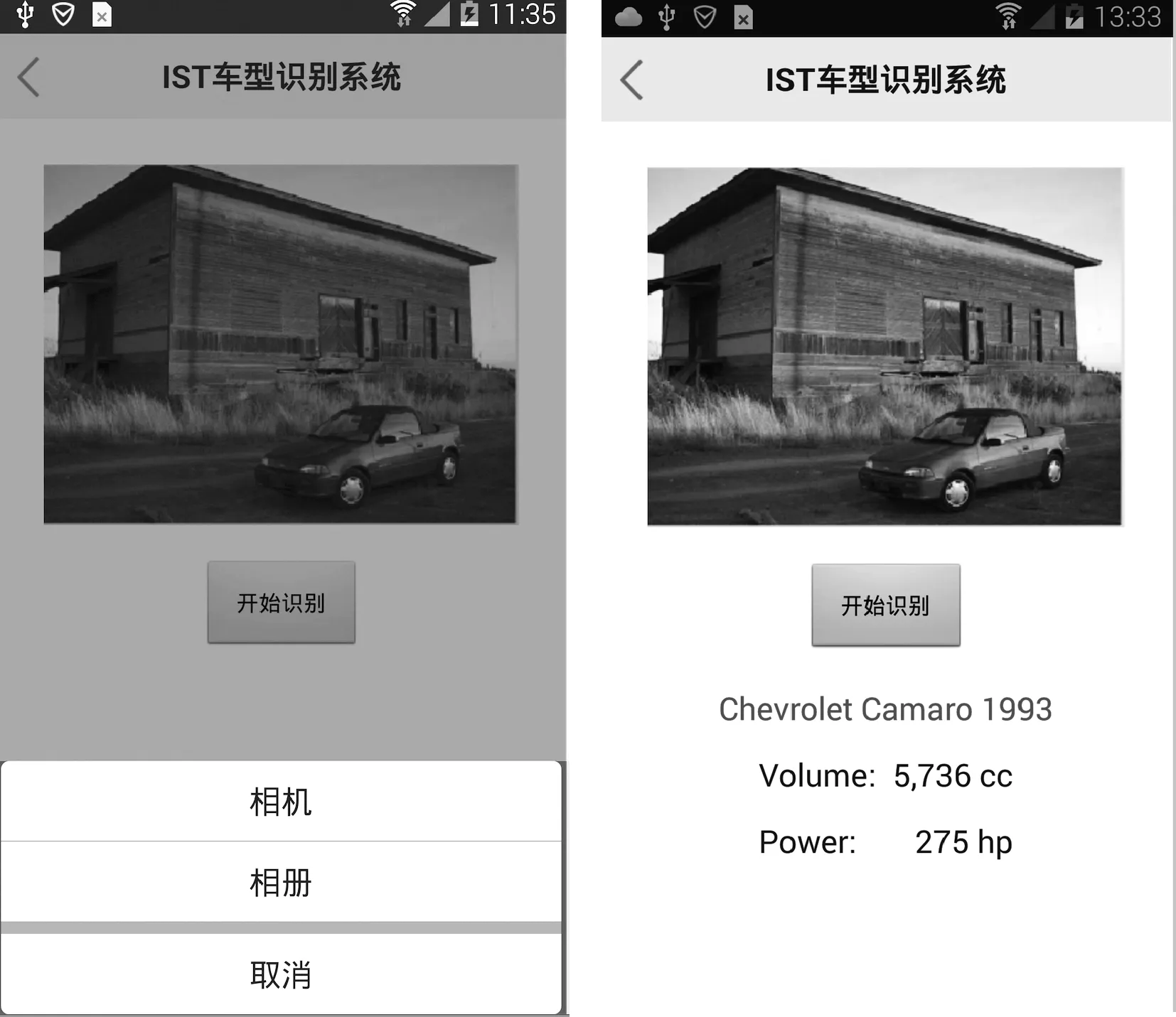
(a) 安卓移动客户端实现界面

(b) 后台识别服务界面

项目本文系统文献[4]文献[13]文献[14]准确率/%92899197适用对象任意角度车辆后视图车辆前视图任意角度方法rCNN区域分割+卷积神经网络特征提取和分类人工特征提取、匹配人工特征提取、匹配卷积神经网络或人工特征提取+SVM分类器识别粒度车辆品牌、型号车辆品牌、型号车辆品牌、型号车辆交通类型存在问题训练时间较长需要预先选定特征、受选择的特征影响较大需要预先选定特征、受选择的特征影响较大,测试集合较小识别粒度较大,只能精确到bus、truck等交通类型
由表1可以看出, 本文系统在车辆交通类型的识别上取得了非常好的效果, 可以保证较高准确率的同时还不用对查询图像的拍摄角度作出限制.但在细粒度分类应用于具体车辆品牌和型号的研究中, 往往只能在某个特定角度的查询图片中取得不错的结果, 该现象的主要原因为缺少大量多角度的标注样本及人工选择的特征泛化能力较弱.
本文结合卷积神经网络、区域分割技术和公开的大量标注数据集, 解决了对任意拍摄角度的车辆图片在品牌和型号上的细粒度分类问题, 其准确率与传统单视图识别相当甚至更好.
4 结 语
由于缺乏足量的标注样本和强大的车辆特征, 实现对任意角度的图片精确到车辆品牌和型号的识别是一个尚未被充分研究的问题.本文采用卷积神经网络模型, 凭借其在静态图片上展现出的强大的特征提取能力, 同时结合SVM分类器的训练, 在车辆类别分类问题的解决上取得了较优的成果.利用rCNN预先分割出车辆区域, 减少背景区域对分类带来的噪声影响, 提高了车型识别的准确率.
下一步工作将研究不同压缩算法和预处理算法对图像效果造成的影响; 尝试使用更快速的rCNN模型提升区域分割环节的处理速度; 考虑不同网络模型结构对分类准确率的提高和影响.
[1] JANG D M, TURK M. Car-Rec: A real time car recognition system[C]//Applications of Computer Vision (WACV), 2011 IEEE Workshop on. IEEE. 2011: 599-605.
[2] ZHANG B. RELIABLE classification of vehicle types based on cascade classifier ensembles[J]. IEEE Transactions on Intelligent Transportation Systems, 2013, 14(1): 322-332.
[3] LIU J, KANAZAWA A, JACOBS D, et al. Dog breed classification using part localization[C]// European Conference on Computer Vision. Springer Berlin Heidelberg. 2012: 172-185.
[4] NILSBACK M E, ZISSERMAN A. Automated flower classification over a large number of classes[C]//Computer Vision, Graphics & Image Processing, 2008. ICVGIP’08. Sixth Indian Conference on. IEEE. 2008: 722-729.
[5] SANTOS D, CORREIA P L. Car recognition based on back lights and rear view features[C]//Image Analysis for Multimedia Interactive Services 2009. WIAMIS'09. 10th Workshop on. IEEE. 2009: 137-140.
[6] PETROVIC V S, COOTES T F. Analysis of features for rigid structure vehicle type recognition[C]//British Machine Vision Conference. 2004: 587-596.
[7] ABDELMASEEH M, BADRELDIN I, ABDELKADER M F, et al. Car make and model recognition combining global and local cues[C]//Pattern Recognition (ICPR), 2012 21st International Conference on. IEEE. 2012: 910-913.
[8] GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2014: 580-587.
[9] UIJLINGS J R R, SANDE KEAV D, GEVERS T, et al. Selective search for object recognition[J]. International Journal of Computer Vision, 2013, 104(2): 154-171.
[10] JIA Y, SHELHAMER E, DONAHUE J, et al. Caffe: Convolutional architecture for fast feature embedding[C]//Proceedings of the 22nd ACM International Conference on Multimedia. ACM. 2014: 675-678.
[11] KRAUSE J, STARK M, Deng J, et al. 3d object representations for fine-grained categorization[C]//Proceedings of the IEEE International Conference on Computer Vision Workshops. 2013: 554-561.
[12] KRIZHEVSKY A, SUTSKEVER I, HINTON G E. Imagenet classification with deep convolutional neural networks[C]//Proceedings of the 25th International Conference Neural Information Processing Systems. 2012: 1097-1105.
[13] 姚钦文. 基于卷积神经网络的车脸识别研究[D].杭州: 浙江大学计算机学院, 2016.
[14] HUTTUNEN H, YANCHESHMEH F S, CHEN K. Car type recognition with deep neural networks[C]//Intelligent Vehicles Symposium (IV). IEEE. 2016: 1115-1120.
(责任编辑:杨静)
CarMakeandModelRecognitionBasedonConvolutionalNeuralNetwork
LIZheming,CAIHongming,JIANGLihong
(School of Software, Shanghai Jiao Tong University, Shanghai 200240, China)
The recognition of car make and model is a kind of problem of fine-grained classification area. It’s hard to classify them due to the subtle difference among classes compared to other common image recognition problems. While powerful feature-found ability of convolutional neural network(CNN) on static image has made remarkable achievements in the image classification problem. Therefore, a complete model based on CNN is designed by combining the large open source data sets, region segmentation is applied to raise the accurate while the interaction is designed according to the characteristics of mobile internet. Experiment shows that this method can effectively solve the problem.
car make and model recognition; fine-grained classification; convolutional neural network; region segmentation; image processing
TP 391
A
1671-0444 (2017)04-0472-06
2017-04-28
国家自然科学基金资助项目(61373030,71171132)
黎哲明(1992—),男,福建龙岩人,硕士研究生,研究方向为信息可视化. E-mail: lizheming@sjtu.edu.cn
蔡鸿明(联系人),男,教授,E-mail: hmcai@sjtu.edu.cn
猜你喜欢
车迷(2022年1期)2022-03-29
北京航空航天大学学报(2021年9期)2021-11-02
中国交通信息化(2020年11期)2021-01-14
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
电子技术与软件工程(2017年14期)2017-09-08
计算机应用(2017年4期)2017-06-27
汽车与安全(2015年12期)2015-09-10
车迷(2015年12期)2015-08-23
