
基于MIC平台的三维瑞雷面波有限差分并行模拟
2017-11-01 09:02曾瑞庚熊章强张大洲
物探化探计算技术 2017年5期
曾瑞庚, 熊章强,2, 张大洲,2
(1.中南大学 地球科学与信息物理学院,长沙 410083;2.中南大学 有色金属成矿预测教育部重点实验室, 长沙 410083)
基于MIC平台的三维瑞雷面波有限差分并行模拟
曾瑞庚1, 熊章强1,2, 张大洲1,2
(1.中南大学 地球科学与信息物理学院,长沙 410083;2.中南大学 有色金属成矿预测教育部重点实验室, 长沙 410083)
三维地震波动方程有限差分数值模拟,受到计算量大且内存消耗大地制约而计算效率较低,严重影响其发展和应用。目前,一种全新的异构众核协处理器,为三维并行计算提供了一条解决计算效率和数据存储问题的重要途径。基于三维有限差分计算的特点,介绍了面向MIC(Many Integrated Core)平台的三维瑞雷波有限差分并行算法移植和性能优化,采用ofload模式将计算核函数加载到MIC上,在MIC协处理上使用openMP多线程并行方式,并通过循环合并、nocopy数据传输、SIMD向量化和CPU+MIC协同计算方式进行优化。通过模型计算可知:三维数值计算程序在MIC上具有近线性加速比, MIC+CPU协同并行计算的性能可以达到纯CPU节点的4.5倍,大大提高了计算效率。通过对模拟结果与解析解的比较,以及对频散曲线特征的分析,验证了数值模拟的正确性。
MIC平台; 瑞雷面波; 有限差分; offload模式
0 引言
瑞雷面波具有衰减小、信噪比高、分辨率高以及在层状介质中的频散特性等优点,在近地表工程勘察以及石油勘探静校正等领域有着广泛地应用。目前,有关瑞雷面波勘探的研究在空间上从二维转向三维,在反演方面的研究也从传统的频散曲线反演逐渐转向更为精确的波形反演。快速、高效地获取不同地质模型下的波场信息,是当前瑞雷面波研究领域亟待解决的问题。
有关瑞雷面波的有限差分数值模拟,国内、外学者已经进行了大量的研究工作[1-2]。根据当前的计算机硬件及软件的发展趋势,采用并行计算技术增大数据存储量,减小正演模拟时间是一条非常有效的途径。当前,一种基于MPI和OpenMP的并行算法得到了众多研究者的青睐。方金伟等[3]研究了一种基于OpenMP的一阶声波方程波场并行算法,该方法在微机商用多核CPU上获得了2倍多的性能提升;何兵寿等[4]引入消息传递接口技术(MPI),实现了二维弹性波动方有限差分并行求解,大大提高了弹性波动方程的计算效率;张明财等[5]基于MPI并行算法对三维瑞雷面波进行正演模拟,阐述了三维模型区域划分方法和进程间的通信方式,达到了扩大模型规模、加快模拟速度的目的;宋鹏等[6]针对三维声波方程模拟的大计算量和大内存消耗问题,研究了基于MPI+OpenMP的三维声波方程数值模拟并行算法,大大节省了内存消耗。
由于当前计算机以及计算技术的迅速发展,高性能计算开始进入异构、众核时代。随着CUDA的日趋成熟,以GPU为加速器的GPGPU已逐渐成为研究的热点。Komatish D等[7]研究了三维有限差分波场模拟在NVIDIA GPU上的实现,取得了理想的加速效果;龙桂华等[8]采用了MPI+CUDA的方式在GPU集群上实现了大尺度三维地震波数值模拟;Intel于2012年推出的基于MIC(Many Integrated Core)众合架构的处理器Intel Xeon Phi协处理器,因其成本低、性能高等特点得到了重大关注。与GPGPU不同的是,MIC是基于传统CPU架构和X86指令集开发的协处理器,在兼容性、编程模式高度一致性和编程简易性等方面具有优势[9]。
笔者从三维交错网格有限差分出发,基于CPU+MIC平台,使用MIC的offload编程模式,对有限差分算法进行了移植和优化。
1 三维瑞雷面波波动方程
在三维各向同性介质中,一阶速度-应力弹性波波动方程可表示为[10]:
(1)
其中:i、j、k∈{x,y,z};ρ为介质的密度;fi表示体力i的分量;vi表示速度i的分量;σij表示应力分量;δij为克罗内克函数;λ、μ为拉梅系数。
笔者所采用的是时间2阶空间4阶交错网格有限差分算法,其各分量定义方式和具体公式参考文献[5]。自由边界条采用声学-弹性介质边界代替自由边界法[11],吸收边界条件采用非分列式完全匹配层(NPML)边界条件[12]。
2 MIC平台移植和优化
MIC是基于与CPU一致的x86指令架构,即可以看成一个协处理器,也可以当做一个独立的节点,具有非常灵活的编程模式(图1)。与常规CPU相比MIC拥有50个以上核心,其中每个核心支持4个硬件线程,其性能优于超线程。MIC协处理器与CPU结合紧密,可以在不改动源代码或者改动很少的情况下使用该协处理器。本文采用CPU为主,MCI为辅的编程模式,即MIC offload模式[13]。这种模式应用最为普遍,符合传统的协处理器应用方式。MIC支持现有的编程标准工具和语言(C、C++、FORTRAN等)和常用的并行技术(如Pthread、MPI、OpenMP等),笔者使用了MPI+ OpenMP混合并行方法以实现MIC和CPU间的协同计算。

图1 MIC架构图Fig.1 Architecture of MIC
2.1 MIC平台实现
offload模式适合串行程序中含有计算量大且并行度高的函数或者代码段。有限差分正演模拟中速度和应力的计算是程序中最耗时的部分,这部分的差分计算具有良好的并行度和空间局部性,适合在MIC上并行处理。如图2所示,程序主函数在CPU上运行,运行到需要并行计算部分时,通过在速度和应力计算函数上添加offload编译指导语句,将该函数加载到MIC上并行处理。offload引语本身不会指示代码并行执行,需要借助于OpenMP、MPI、Pthreads等并行编程方式实现。

图2 offload模式流程图Fig.2 Flow chart of offload mode
三维有限差分算法总体上由一个四重循环组成,最外层为时间循环迭代,其次分别为空间上的x、y、z循环,这部分循环计算采用OpenMP多线程并行方式可以很好地并行化。OpenMP是通过引语的方式对程序的循环语句并行化,其要求是循环语句不存在相互依赖关系。由于在时间循环上当前的结果依赖于上一次的循环结果,所以不适合OpenMP的并行。对于空间循环任一x、y、z方向上的循环都是独立的,不存在相关性,因此可以在任一方向上对循环指定并行。使用offload指导语句结合openMP,即可实现在MIC上的并行计算。
2.2 性能优化
针对MIC架构的特点,笔者从循环合并、nocopy数据传输、SIMD向量化、CPU+MIC协同计算四个角度对程序进行优化。
1) 循环合并。为了提高OpenMP在MIC上多线程并行计算性能,将空间方向上的3层循环合并为2层循环,提高每个线程上循环计算的长度以减少线程并行的开销。图3为对150×150×100的网格模型在开启不同进程数量情况下,循环合并和未进行循环合并对运算速度的影响。当线程数量小于循环计算长度(150)的时候,循环合并后比未合并需要更多的计算时间。然而线程数超过循环计算的长度时(>150),循环合并后的计算时间比循环未合并时少,最高获得1.7倍的计算速度,循环合并具有更好的计算性能。
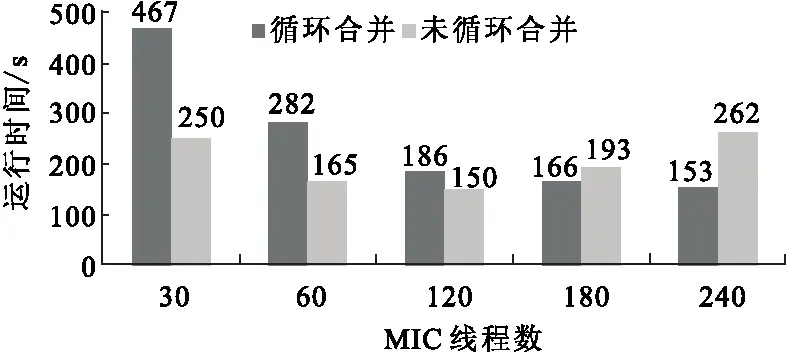
图3 循环合并对计算时间的影响Fig.3 Effect of loop confution with different threads number
2) nocopy数据传输优化。CPU和MIC之间在硬件上是通过PCI-E进行数据传输,这直接导致了CPU和MIC之间的传输速度较慢,因此要尽量减少CPU和MIC之间的数据传输。在默认情况下offload的in、out等语句每次开始时在MIC上申请空间,结束后释放空间。但计算过程中大部分变量不需要每次都在MIC上重新申请和释放空间,这些空间和数据在时间循环过程中可以重复利用。可以利用nocopy语句来减少CPU和MIC的数据传递。如图4所示,首先在时间循环开始之前为MIC上所需的变量分配空间,并把变量的值传入到MIC中。在时间迭代过程中,CPU和MIC之间只传输必要的数据,而中间变量则使用nocopy来表示以减少数据传递,时间循环迭代完毕后释放MIC上的空间。这种方法可大大减少MIC和CPU之间的数据通信,提高并行效率。
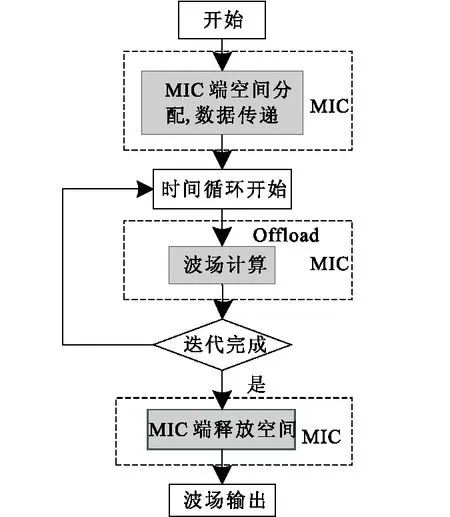
图4 数据传输优化Fig.4 Optimization of data transfer
3) SIMD向量化。向量化是使用向量处理单元进行批量计算的方法,MIC的处理器支持512bit宽的指令,利用这些指令级别的并行可以很好地提高程序性能。有限差分算法的循环体是大量而重复的循环计算,且涉及到连续的存储空间访问。通过在循环语句前添加!DECMYM IVDEP语句使循环自动向量化,同时编译器将忽略假定的数据依赖关系强制循环向量化。
4) CPU+MIC协同计算。MIC的offload模式仅把程序中高度并行计算任务提交给MIC,而CPU只负责控制管理,这使得CPU的计算资源没有得到充分利用。如果把计算任务同时交给CPU和MIC,就可以充分利用两者计算资源,提升计算效率。由于MIC卡和CPU之间计算能力不同,为了达到CPU和MIC的之间的负载均衡,需要对MIC和CPU的计算任务进行合理的分配。
笔者采用MPI多进程方式进行任务分配,主进程把模型数据广播给所有进程,其中一个进程负责调用CPU并启用OpenMP多线程进行计算,另一个进程负责调用MIC并把数据传输到MIC中进行计算。CPU和MIC之间的负载均衡采用静态任务划分方法[14],即让CPU和MIC分别对同样网格大小的模型做一次计算得到程序在CPU和MIC的计算时间比值,根据这个时间比值来对模型任务进行划分。MIC+CPU协同运算示意图如图5所示。

图5 CPU+MIC协同运算示意图Fig.5 Cooperative computation with CPU and MIC

项目配置CPU2个Intel(R)Xeon(R)E5-2609CPU,主频2.50GHz,4核,10ML3cacheMIC1个IntelXeonPhi7110p,主频1.238GHz,61核,244线程,内存CPU:32GB MIC:16GB软件CPU:CentOS6.3x64编译器:Intel○RFortranComposerXEMIC驱动:MPSS3.4.3
3 模型测试与计算
3.1 模型测试
为了测试程序在MIC中的并行效率,设计一个大小为150×150×100的模型,网格间距dx=dy=dz=1,总网格数为2.25×106。采样间隔为0.1 ms,采样时长为0.3 s。使用了一台MIC服务器进行计算,计算环境配置如表1所示。
加速比(speedup),是同一个任务在单处理器系统和并行处理器系统中运行消耗的时间的比率,用来衡量并行系统或程序并行化的性能和效果,其计算公式为:
Sp=T1/TP
(2)
其中:Sp是加速比;T1是单处理器下的运行时间;TP是在有P个处理器并行系统中的运行时间。
图6为程序在单个MIC上运行的加速比和计算时间,以测试程序在MIC中的可扩展性和稳定性。从图6中可以看出,计算加速比随着线程数的增加几乎呈线性增长,每个核的线程均开启的情况下,最高加速比达到34.4,多核计算加速比几乎达到线性。
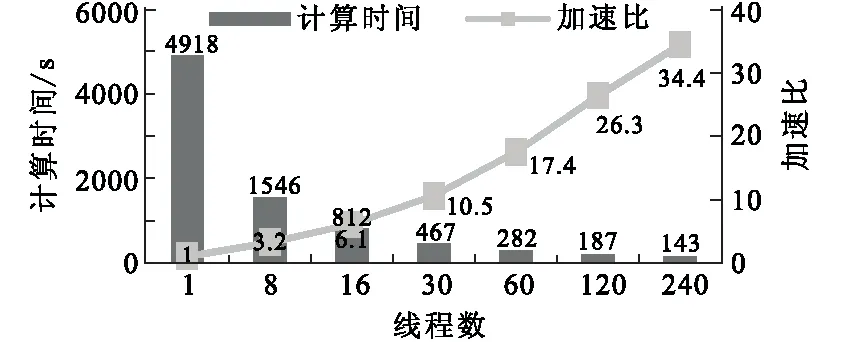
图6 程序在MIC卡上的运行时间和加速比Fig.6 The runtime and speed-up ratio on MIC
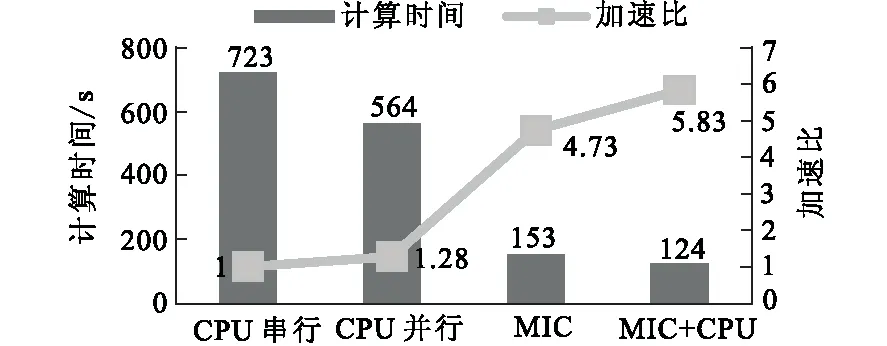
图7 异构并行的计算效率对比Fig.7 Performance comparision of heterogeneous parallel computation
图7为程序分别在CPU上串行计算(单核)、CPU上openMP多线程并行计算(8个线程)、MIC上多线程并行计算(240个线程)、MIC+CPU协同计算的计算时间和加速比。对比图6和图7可以看出,MIC的单核计算能力比CPU单核弱很多,在MIC线程数为240的情况下的计算能力是单核Xeon CPU的4.7倍,是CPU节点在开启8个OpenMP线程情况下的3.7倍。采用CPU+MIC协同运算相对于纯CPU节点加速比达到了4.5,异构并行获得了更好的加速效果。
3.2 均匀半空间瑞雷面波正演计算
为了验证本文有限差分并行计算算法的正确性,设计一均匀各向同性介质模型。模型大小为300 m×300 m×200 m ,网格间距dx=dy=dz=1。纵波速度vp=1 000 m/s,横波速度vs=577 m/s,密度ρ=2 100 kg/m3。震源为25 Hz的高斯一阶导函数,位于模型的(150,150,0)处。采样间隔为0.1 ms,采样时长为300 ms,延时为40 ms。
图8为检波器距离震源100 m处水平速度分量vx和垂直速度分量vz的数值解和解析解的对比,其中解析解由Lamb问题解析法得到,其中格林函数的计算采用Cagniard-de Hoop 解析法[15-16]。从图8可以看出,vx和vz的数值解与对应的解析解吻合较好,其均方差为分别为4.1%和4.0%。
图9为在y=150 m的平面上速度分量vx、vy、vz分别在110 ms、160 ms、240 ms时刻的波场快照。 从图9中可以很清楚地看到瑞雷面波、纵波和横波。沿深度方向,瑞雷面波的能量集中于大约25 m内,深度超过这个距离后,P波开始变得清晰,这说明瑞雷面波的穿透深度约为一个波长。此外,在吸收边界处没有产生强烈的反射,说明本文中使用的边界条件是有效的。
图10为各分量波场记录,其中瑞雷面波的同向轴皆为直线,这说明瑞雷面波在均匀各向同性介质中没有发生频散。图11为用垂直速度分量vz提取的频散曲线,从图中可知,均匀介质中的频散曲线为一条直线,其相速度约为530 m/s,且未发生频散现象,这符合面波相关理论。以上实例计算,说明了数值模拟的正确性。
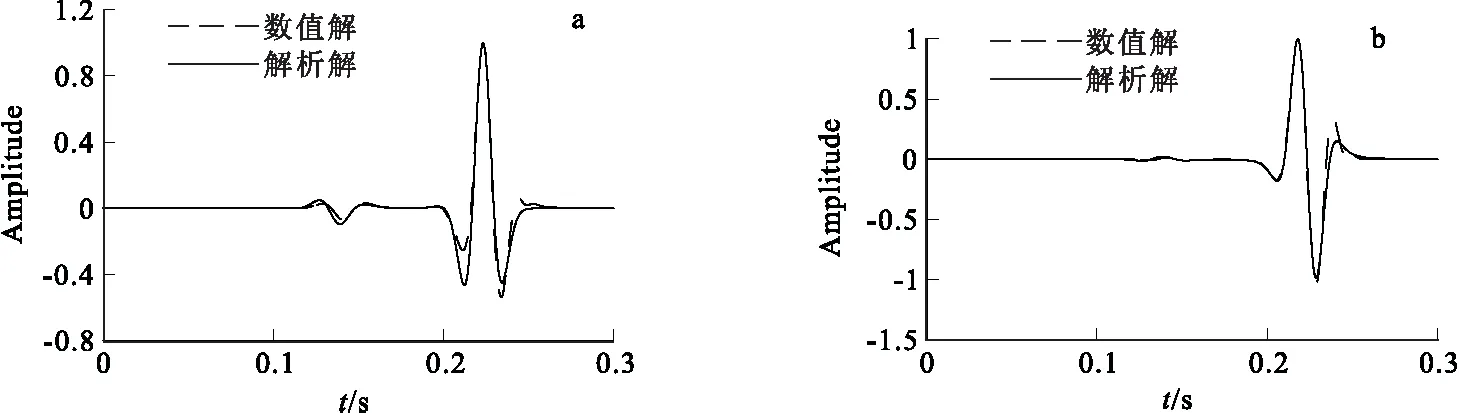
图8 vx和vz分量数值解与解析解对比(距离震源100 m)Fig.8 Compersion of numerical solution and analytical solution with vx and vz component(a)水平速度分量vx; (b)垂直速度分量vz

图9 各方向速度分量在x=150 m平面上不同时刻的波场快照Fig.9 The snapshot at plane of x=150 m with different velocity component(a)vx分量在110 ms时刻;(b) vx分量在160 ms时刻;(c)vx分量在240 ms时刻;(d)vy分量在110 ms时刻;(e) vy分量在160 ms时刻;(f)vy分量在240 ms时刻;(g)vz分量在110 ms时刻;(h) vz分量在160 ms时刻;(i)vz分量在240 ms时刻
3.3 水平层状介质模型瑞雷面波正演计算
设计一个3层水平层状速度递增模型,模型参数如表2所示。震源采用25 Hz的高斯一阶导数,模型大小为300 m×300 m×200 m,网格间距取dx=dy=dz=1。

表2 水平层状模型参数
图12为在y=150 m的平面上速度分量vx、vy、vz分别在120 ms、180 ms、260 ms时刻的波场快照。由于层状介质中各层的参数不同,从图12中可以很明显看出频散,且大部分能量聚集在地表附近。由于反射界面的存在,由震源激发的波与在各界面发生多次反射的波相互叠合形成了多模态的瑞雷面波。
图13(a)为x=150 m平面上vz分量的单炮波场记录。为了分析在瑞雷面波在层状介质中的频散特性,在vz分量波场记录上利用相移法提取频散曲线,如图12(b)所示。图中白色方块为该模型参数下计算得到的解析解[17],从图中可见基阶模式和高阶模式的频散曲线吻合得较好。
4 结论
计算效率的高低是影响三维数值计算在实际应用中的重要因素。笔者利用Intel最新推出的MIC平台协处理器Xeon Phi具有较高的加速比和良好可扩展性的特点,将三维瑞雷面波数值模拟在MIC平台的offload模式程序进行移植并优化,包括循环合并、nocopy数据传输优化、编译自动向量化以及CPU+MIC协同计算。通过对所设计的均匀介质模型进行波场模拟测试可知:基于OpenMP的并行程序在MIC上具有近线性加速比,MIC+CPU协同并行计算的性能为单个CPU节点的4.5倍。因此,利用MIC+CPU协同并行计算方式,可极大提高计算效率,为后续的全波形反演、波动方程叠前深度偏移等提高计算效率。此外,针对大规模计算问题,利用MPI多进程方式可以将程序扩展到单节点多MIC卡或者MIC集群上计算。
致谢
感谢中南大学高性能计算中心提供计算平台。
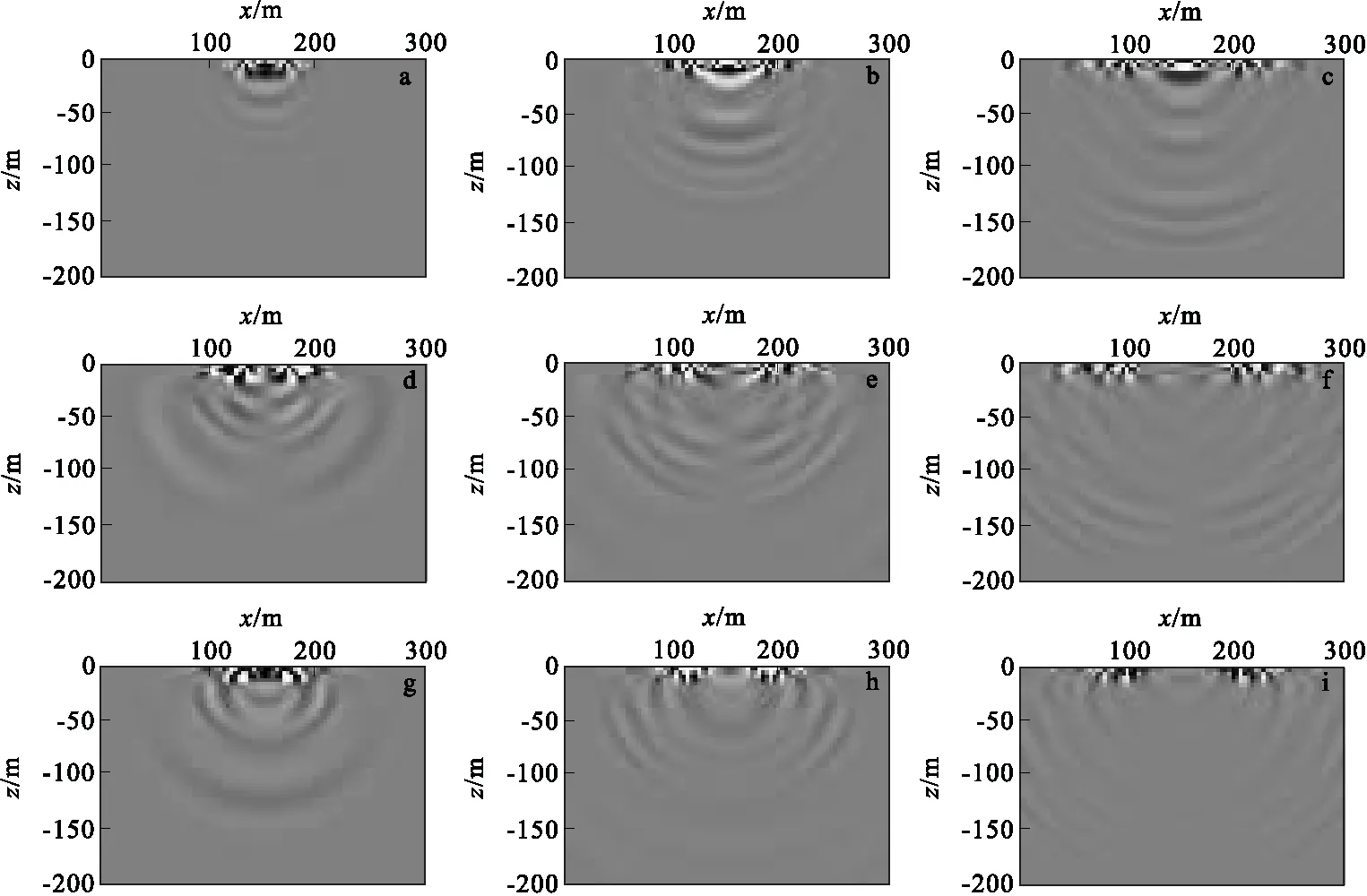
图12 各方向速度分量在x=150 m平面上不同时刻的波场快照Fig.12 The snapshot at plane of x=150 m with different velocity component(a)vx分量在120 ms时刻;(b) vx分量在180 ms时刻;(c)vx分量在260 ms时刻;(d)vy分量在120 ms时刻;(e) vy分量在180 ms时刻;(f)vy分量在260 ms时刻;(g)vz分量在120 ms时刻;(h) vz分量在180 ms时刻;(i)vz分量在260 ms时刻

图13 单炮vz波场记录及其频散曲线Fig.13 Wave record of vz conponant and its dispersion curves(a)x=150 m平面上的波场记录;(b)频散曲线
[1] 董良国, 马在田, 曹景忠, 等. 一阶弹性波动方程交错网格高阶差分法[J]. 地球物理学报, 2000,43(3):411-419.
DONG L G, MA Z T, CAO J Z, et al, Astaggered-grid high-order difference method of one-order el-astic wave equation[J]. Chinese Journal Geophysi-cs, 2000,43(3):411-419.(In Chinese)
[2] PETER M, JOZEF K, LADISLAV H. 3D fourth-order staggered-grid finite-difference schemes: stabil-ity and grdi dispersion[J]. Bulletin of the Seismol-ogical Society of Americal, 2000,90(3):587-603.
[3] 方金伟, 白洪涛, 孙惠敏. 基于OpenMP的一阶声波方程波场并行算法[J]. 物探化探计算技术, 2015, 37(5): 622-627.
FANG J W, BAI H T, SUN H M, A parallel algori-thm of wave field using first-order acoustic wave equation based on OpenMP[J]. Computing Tech-niques for Geophysical and Geochemical Explorat-ion, 2015,37(5):622-627.(In Chinese)
[4] 何兵寿,张会星,韩令贺.弹性波方程正演的粗粒度并行算法[J]. 地球物理学进展,2010,25(2):650-656.
HE B S, ZHANG H X, HAN L H. Forward modeling of elastic wave equation with coarse-grained parallel algorithm[J]. Progress in Geophysics, 2010,25(2): 650-656.(In Chinese)
[5] 张明财,熊章强,张大洲. 基于MPI的三维瑞雷面波有限差分并行模拟[J]. 石油物探,2013,52(4):354-362.
ZHANG M C, XIONG Z Q, ZHANG D Z. 3D finite difference parallel simulation of Rayleigh wave based on Message Passing Interface[J]. Geophysical Prospecting for petroleum, 2013,52(4):354-362.(In Chinese)
[6] 宋鹏, 解闯, 李金山, 等. 基于MPI+OpenMP的三维声波方程正演模拟[J]. 中国海洋大学学报(自然科学版), 2015(09): 097-102.
SONG P, XIE C, LI J S, et al, The 3D modeling of acoustic wave equation based on MPI+OpenMP[J]. Periodical of Ocean University of China, 2015(09):097-102.(In Chinese)
[7] Komatish D, Tomatitsch D. Accelerating a three-dimensional finite-difference wave propagation code using GPU graphics cards. Geophys[J], 2010, 182(1): 389-402.
[8] 龙桂华,赵宇波, 李小凡, 等. 三维交错网格有限差分地震波模拟的GPU集群实现[J]. 地球物理学进展, 2011(06): 1938-1949.
LONG G H, ZHAO Y B, LI X F, et al, Accelerati-ng 3D staggered-grid finite-difference seismic w-ave modeling on GPU cluster[J]. Progress in Ge-ophysicals, 2011(06): 1938-1949.(In Chinese)
[9] INTEL. Intel Xeon Ph Coprocessor DEVELOP-ER’S QUICK START GUIDE[OL].https://software.intel.com/sites/default/files/managed/ee/4e/intel-xeon-phi-coprocessor-quick-start-developers-guide.pdf,2013.
[10] HELSTHOLM S O. Finate-difference seismic m-odeling including surface topograrhy Texas U-niverzones [J].Physics of the Earth and Plantetary Interiors,2002,132(1):219-234.
[11] XU Y X, XIA J H, MILLER RD, Numerical invertigation of implemention of air-earth boundry by acoustic-elastic boundry approach[J]. Geophysics,2007,72(5):147-153.
[12] QIN ZHEN, LU MINGHUI, ZHENG XIAODONG,et al. The implemention of an improved NPML absorbing boundry condition in elastic wave modeling[J]. Applied Geophysics, 2009:113-121.
[13] 沈铂, 张广勇, 吴韶华, 等. 基于MIC平台的 offload并行方法研究[J]. 计算机科学, 2014,41(6A): 477-480.
SHEN B, ZHANG G Y, WU S H, et al. Research of offload paralel method based on MIC platform[J]. Computer Science, 2014,41(6A):477-480.(In Chinese)
[14] 王恩东, 张清, 沈铂, 等.MIC高性能计算编程指南[M].北京:中国水利水电出版社,2012.
WANG E D, ZHANG Q, SHENG B, et al. Many Integrated Core High Performance Programming Guid[M].Beijing: China Water&Power Press, 2012.(In Chinese)
[15] HOOP, A.T.DE. A modification of cagniard's method for solving seismic pulse problems[J]. Applied Scientific Research, 1960, 8(1):349-356.
[16] 巴特.地震学的数学问题[M]. 郑治真,译.北京: 科学出版社, 1976.
BART M.Mathematical problem of seismology[M].Zhen Z Z, translator.Beijing: Science Press, 1976.(In Chinese)
[17] HISADA,Y.An efficient method for computing green's functions for a layered half-space with sources and receivers at close depths[J].Bulletin of the Seismological Society of America,1994:1456-1472.
3DfinitedifferenceparallelsimulationofRayleighwavebasedonMICplatform
ZENG Ruigeng1, XIONG Zhangqiang1,2, ZHANG Dazhou1,2
(1.Central South University School of Geosciences and Info-Physics, Changsha 410083, China;2.Central South University Key Laboratory of Metallogenic Prediction of Nonferrous Metals, Ministry of Education, Changsha 410083, China)
The development and application of Numerical simulation of three-dimensional seismic wave equation is hindered for its huge computation and large computer memory. In recent years, MIC (Many Integrated Core), as a new kind of heterogeneous core coprocessor, provides a better choice for three-dimensional parallel modeling. Based on the characteristic of 3D finite difference computation, we introduce the code migration and performance optimization on MIC platform. We offload the kernel function to MIC with openMP parallel method, and optimize the performance by loop confusion, data transfer optimization, SIMD vectorization and CPU+MIC cooperative computation. Through the model computation, the speed-up ratio on MIC is nearly linear. The performance of the MIC+CPU cooperative computation was 4.5 times faster than pure CPU compute node. The method is verified by the comparison of numerical simulation result and analytical solution, as well as by the analysis of dispersion curves from wave record.
Many integrated core; Rayleigh wave; finite difference; offload model
P 631.4
A
10.3969/j.issn.1001-1749.2017.05.11
2016-09-14 改回日期: 2016-11-06
国家自然科学基金(41274123);博士点基金(20130162110066)
曾瑞庚(1990- ),男,硕士,主要从事瑞雷波正演研究,E-mail:rgzeng01@163.com。
1001-1749(2017)05-0649-08
猜你喜欢
石油地球物理勘探(2021年6期)2021-12-04
山西电子技术(2021年3期)2021-06-28
地震研究(2021年1期)2021-04-13
石油地球物理勘探(2020年5期)2020-10-17
石油地球物理勘探(2020年5期)2020-10-17
物探化探计算技术(2020年1期)2020-04-08
网络安全技术与应用(2020年1期)2020-01-07
通信技术(2019年9期)2019-10-09
长江大学学报(自科版)(2015年23期)2015-12-04
天然气勘探与开发(2015年1期)2015-02-28
