
基础教育文本资源搜索引擎网页机器人设计与实现
2017-10-30 22:24刘异赵辉
中国教育信息化·高教职教 2017年10期
刘异+赵辉

摘 要:在基础教育领域,为方便学生、教师、家长、教育机构等搜索相关教育文本资源,提出了专用于基础教育文本资源搜集的快速高效的智能化网页搜索机器人理论。文本自动分类、文献自动文摘和自动关键词提取是网页机器人的重要组成部分。由分析Web网页格式的文档引出基础教育文本资源信息挖掘模块,设计提取关联文本信息的算法, 研究在搜索引擎中如何通过对互联网海量多媒体教育信息的自动抓取、主题检测、专题聚焦,实现对教育网络的监控和专题的追踪等功能,以报告及图表等多种分析结果的形式提供分析依据,设计基础教育文本监控分析系统,为提供全面搜索教育网络服务。
关键词:自动分类;自动文摘;自动关键词提取;Web文档;搜索引擎;基础教育资源
中图分类号:G202 文献标志码:A 文章编号:1673-8454(2017)19-0037-04
前言
读网时代,越来越多的人使用Internet查找资料辅助工作、学习,网络充斥着人们日常生活的方方面面。各种搜索引擎从海量互联网资源中为用户检索到所需的信息,其中有通用型的搜索引擎,如Google、Baidu, 也不乏特定型的搜索引擎,如提供基础教育文本资源搜索服务的网页机器人。[1]文本监控分析系统,通过底层索引器将网页机器人采集到的信息进行分类,建立主目录、子目录存储在索引数据库中,定时更新数据库保证数据库信息与Web内容同步,更新的具体实现通过网页机器人遍历指定范围内的整个Web空间,不间断地从一个Default.aspx网页转到另一个newspage.aspx网页,从一个站点切换到下一个站点,将采集到的信息更新到数据库中。
一、基于Mashup的基础教育文本资源信息挖掘模块信息采集与整合
Web2.0时代,数据源形式多样是互联网基础教育文本资源信息的一个重要特征。除基础教育新闻、基础教育BBS论坛等传统信息源外,出现了基础教育CastBox、基础教育Blog、Wiki、聚合基础教育新闻等新型的Web2.0信息交互模式,产生的信息量越来越大。而不同信息源中所蕴涵的基础教育文本资源信息具有重复性或关联性,如果网页机器人分别对这些信息源进行搜索,得到的结果中很大一部分信息可能是重复的,或者相关联的信息没有搜索到,这样搜索的效率不高。另一方面,传统的基础教育文本资源信息采集过程中,添加或更新不同类型的信息源,可能需要调整网页机器人的采集策略,难以适应Web2.0时代的信息源类型多样化的特点。因此,有必要对来自不同信息源的基础教育文本资源信息进行整合和融合。
作为一种新型的基于Web的数据集成技术,Mashup技术[3]是将多个支持WebAPI的不同应用进行堆叠而形成的新型Web服务,它兼容性好,适用于多种不同的外部网络数据源格式,应用面广,涵盖外部公共APIs、XML、RSS、Atom、Feed、Web services、HTML等,具有Web2.0的特点。因此,本系统使用Mashup技术开发可视化的Mashup工具,供信息搜集人员对多种不同来源的基础教育文本资源信息进行整合与融合,形成Mashup站点。(如图1所示)这样网页机器人可以从Mashup站点采集各种互联网基础教育文本资源信息,以提高搜索的效率。
二、文本自动分类
信息检索、内容管理及信息过滤等流程困难重重,各种电子格式的文本文档数量以指数爆炸性增长,有效的解决办法是自动处理未分类文档,判断它所属的预定义类别属于一个或多个类别。根据现有的数学法则,构造出一个能把数据库中的数据映射到指定类别中的分类函数模型,缩短文本内容检索、文本数据存储的处理时间。
分类函数模型的构造有神经网络分析法、统计方法及机器学习方法等。人工神经网络分析法主要是针对小规模识别问题,不适用于大规模小样本集群识别问题。[4]支持向量机分类法是万普尼克等人依据统计学提出的,网页机器人运行有限条件下小样本的决策规则对各个测试集依次进行测试,产生极小误差。它无需进行迭代运算,优于神经网络分析法,处理数据时局部不会出现极小值。[5]
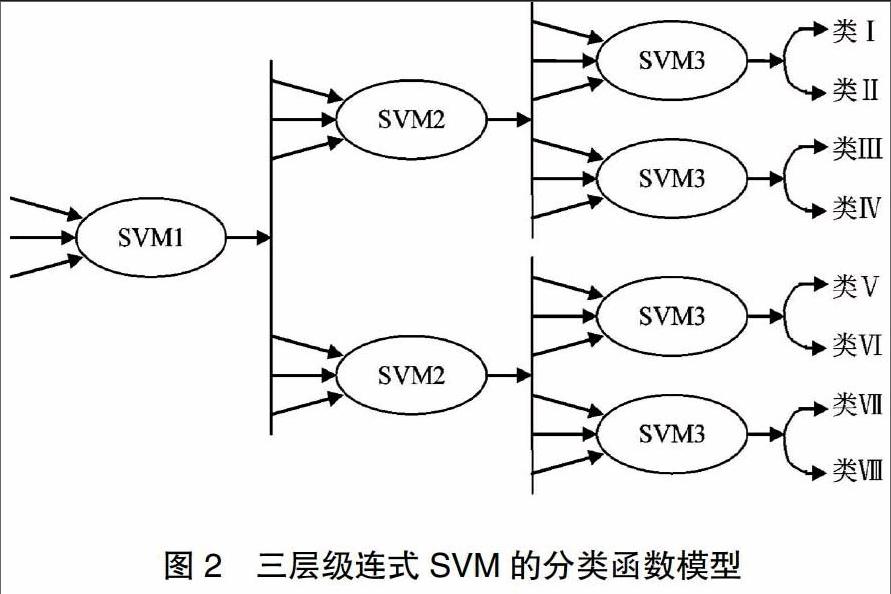
通常情况下,支持向量机分类法适用于两个模型的分类,对于多个模型的分类通过完全二叉决策树的级连式SVM模型构造。假设分类函数模型类别数是M,SVM级数是N,那么N= [log2M],得到级连式SVM分类数据处理能力是2N≥M。三层级连式SVM的分類函数模型如图2所示。
三、文献自动文摘
文献自动文摘就是通过网页机器人浏览原始文献,自动提取文摘内容。自动文摘是“一份用网页机器人自动提取文献内容的缩短的精确表达而无须补充解释或评论”。[6]自动文摘技术包含文字分词、句法分析器、词性注释工具和自然语义处理等。
自动文摘技术目前有两种实现方法:[7]一种是基于统计理论的方法,另一种是基于自然语言处理的方法。统计方法直接抽取原始文献句子组合成文摘内容,而自然语言处理方法则是运用更深层次的机器学习技术如语义分析理解原文,推理出文摘内容,文摘语句与原文并不相同。
组合词是文章的重要组成部分,包含各类术语、文本关键词、实体命名等。在分词系统中,组合词能表达独立的特定语义,但是容易被误切分为多个与原文主题意思相悖的词组。解决方法是根据句子内容、位置、线索词和用户偏好等关键因素使表达句子含义的组合词获取优先级别的权重值,消除冗余内容,输出文献文摘。下面介绍几种自动文摘的关键技术。
1.组合词识别与分词结果修正技术
分词是中文文本处理的第一步。由于网上数字化信息资源的扩增,汉语词法分析系统内分词词典的词库量并不完善,词库更新速度跟不上资源扩增速度,导致不能智能识别出大规模的由两个及两个以上的词构成的组合词。解决方法是:网页机器人使用基于词序列频率有向网的中文组合词提取算法识别出组合词。[8]结束识别操作,修正分词结果,还原那些被分词系统切碎歪曲文章大意的组合词。[9]
2.组合词的权重计算技术
为了使表达句子含义的组合词获取优先级别的权重值,需要考虑词频、同义词现象、词性、词长、位置等因素因子。词频,即词出现的次数。在统计词频之前,先将意思相同或相近的同义词词频合并为一个,再将这些词频叠加。同义词现象在句子中出现的频率较高,比如多名笔者频繁用相同的词表达相同的意思,一笔者频繁用不同的近义词表达相同的意思。现代汉语词性包含两类14种,其中名词、名词性词组是表达句子中心主题的核心词,这类组合词具有较高优先级别的权重值。词长,即词的字节长度。实验表明,关键词容易在4~6个字的词中产生,故四个或四个以上词长的词被赋予更高优先级别的权重值。另外,可以通过判断组合词的优先位置获取关键词,比如能大致反映核心意思的词是一篇文章的标题,故位于文章主、副标题的词是重点排查词。
3.段落句子的权重计算技术
句子的内容决定这句话在段落中的重要程度,需要考虑组合词的权重值、线索词的权重值、用户喜好、句子的位置等因素因子。组合词的权重值,即对各类术语、文本关键词、实体命名等组合词计算权重值,权重值越高,句子所含信息量越大,句子重要度越高。线索词是“总而言之”、“综上所述”等带有明显标志的词和词组,常用来标识段落中的重要句子。[10] “首先”、“其次”、“最后”等表示段落层次关系的线索词应当优先提取,输出文摘操作变得简单,效率大幅度提高。为获取定制化的文献自动文摘,使文摘句子投用户所喜好,网页机器人需要收集用户固定喜好的词集进行权重值计算。而句子的位置重要度一般依据每个段落的第二句话通常为段落的中心主题句,优先考虑这句话所包含的重要信息。
四、自动关键词提取
为了高效地处理互联网海量多媒体教育信息,技术人员在信息采集、资源检索、文献自动文摘、文本自动分类、文本信息聚合等方面开展了大量研究,发现网页机器人怎样遍历文献提取关键词是做好研究工作的关键基石。
关键词描述文章中心主题内容,以满足不同人群依据个人喜好检索文本信息。关键词极其精炼的优点使它能以极小的计算代价进行文本关联性度量,提高进行信息采集、资源检索、文献自动文摘、文本自动分类、文本信息聚合等操作的处理效率。文本内容检索是关键词应用最广泛的领域。用户在搜索框内输入查询关键词,搜索结果出现全部含有此关键词的网络文本资源。
“关键”的度量与“词”的选择是关键词提取技术需要攻克的难点。“关键”的度量技术不能应用于短语的现象比比皆是,故对于短语以及未登录词这一部分关键词的提取工作困难重重。为此,笔者将关键词提取技术分成两大部分分析处理,包括单个关键词提取和多个词串关键词提取。该技术依托分离函数模型的中文关键词提取算法设计出不同的关键词特征,提高关键词抽取的准确度。
关键词提取是典型的多标签分类问题,技术人员往关键词分类函数模型输入一组训练样本,使用机器学习方法判断出此模型中的每一个候选词或词串是关键词还是非关键词,标注候选词,接着判断新的候选关键词,循环往复执行。
1.生成单个候选关键词与多个候选词串关键词
前面提到,分词是中文关键词提取的第一步。需要强调的是,数字、标点符号不是单个候选关键词。词串在成为候选关键词串之前要进行过滤处理,一般选取1﹤词长﹤5的词串作為候选词串,删除中文词串中的数字、标点符号等无用字节,而英文候选词串提取会先把开头词、结尾词过滤掉。
2.分离函数模型
词串是把一系列的词按照某种分类方式组合在一起的一串词,具有链式结构特点。不同于传统意义上的等同,词与词串二者有所区别。因此,笔者针对词和词串设计出不同的特征,分开训练、学习单个关键词样本集和多个关键词串样本集,获取单个关键词模型与多个关键词串模型。然后依次应用这两个不同的模型对单个候选关键词和多个候选词串关键词进行判断,可以往此分离函数模型中任意添加词与词串的关键特征,效果明显优于不考虑分离的整体函数模型。
3.不同关键词特征选取
因为分离函数模型是分别对词与词串构造分类模型,所以对应的模型可以选取不同的关键特征。特征TF×IDF使用统计学方法评估单个词语对文档集或语料库中指定文档的重要程度,实验表明特征TF×IDF存在一些缺点:
(1)以“词频”特征单一衡量单个词的重要度,重要的词出现次数不多的情况时有发生(TF值不高)。
(2)算法不能反映单个词位置,比如网络文档,应结合HTML的结构特征计算权重值。
(3)IDF值简单,不易调整权重值,不足以反映单个词的重要度和特征词的分布情况。
针对TF×IDF不足,另外选取了两个特征NWT和TF×IF。NWT是一篇文章词数总数,它被用于解决小型文档候选关键词TF值不高的问题。“TF×IF=候选关键词在某份文档中出现的频率/候选关键词在整本文档集中的词频数”。TF×IF很好地解决了位置、分布情况的问题。
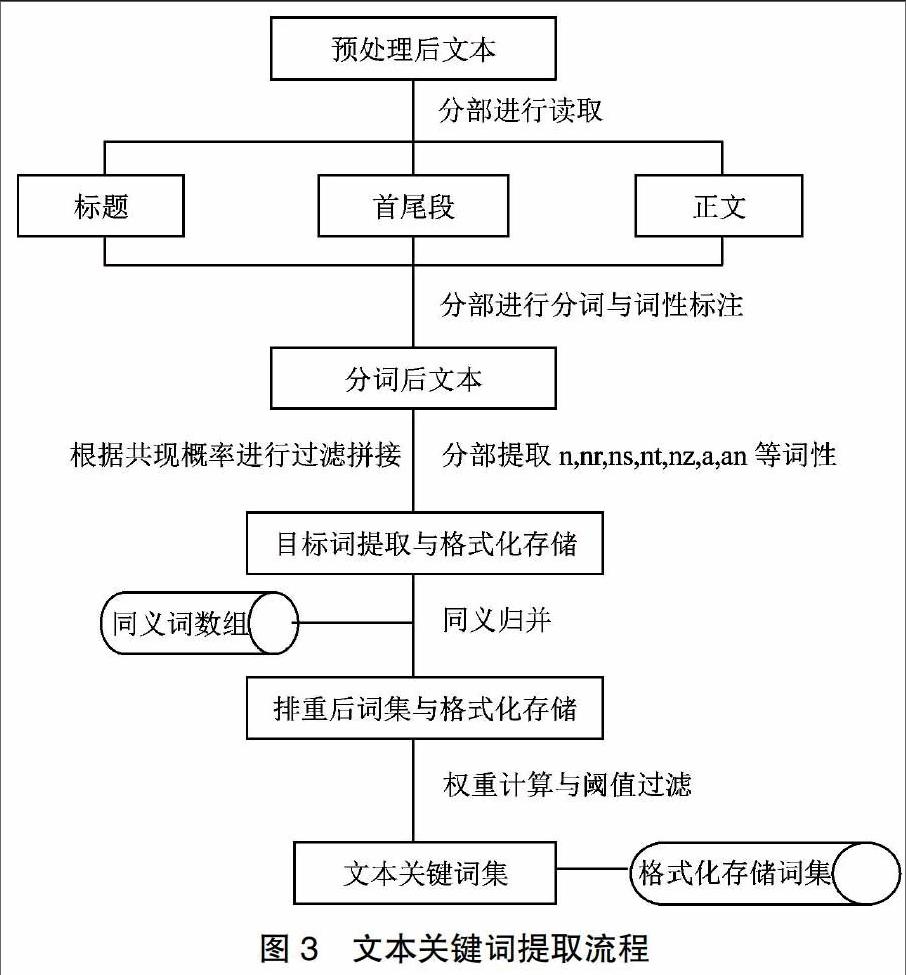
文本关键词提取流程如图3所示,包括分部读取文本、拼接分词、关键词提取、过滤存储和权重值计算五大流程。
分部读取文本是为了赋予标题、起始段、正文和末尾段等段落不同的位置权重。分词采用汉语词法分析系统,根据共现概率原理(即经常出现在同一个段落的若干词为共现词,共现的概率越高,词与词相互之间的关联就越密切)对分词结果进行过滤拼接。通过统计海量文本数据,对各词词性进行标注发现:虚词、标点或符号成为关键词的概率几乎为0,而实词(如名词、动词、形容词等)成为关键词的概率较高。提取实词可以消除提取噪音,提高提取速率。提取关键词的同时,对相应词频、位置信息、出现文章数等信息进行格式化存储。
关键词提取的存储过程中可能会出现大量重复的相同词汇或同义词数组,故需要进行同义归并和排重处理。使用词语自动匹配算法合并相同含义的词语,并累加相应词频数,同一词语出现在不同的文章里还需要对出现的文章次数进行累加。为了方便统一处理,同义归并需定义同义词数组,只要计算机在文章中匹配到同义词,就用该数组的第一项同义词词组替代,累加并统计出相应词频数。
结合一定时间内基础教育话题受关注程度来对话题进行建模:〒=(n,rfi,Di,rdi,α),其中,n表示一定时间范围内的时间单元个数;rfi是该话题在时间单元i中相关通告的通告频率;Di是在时间单元i中通告的总数;rdi是话题在时间单元i中的通告天数;α是一个时间单元的天数。采用向量内积计算公式对热点词进行权重值计算,设置开关上下限阈值,过滤掉权重值较低的词汇,获得文本关键词集,将词集存放在索引数据库中。
结束语
基础教育文本资源搜索引擎网页机器人有着宽广的前景,在基础教育产业必然会独树一帜大放异彩,人工智能成为教育技术学学科近年来研究的新热点。本文提出了基于Mashup的基础教育文本资源信息挖掘模块信息采集与整合的方法,介绍了面向互联网环境的基础教育文本资源搜索引擎网页机器人的关键技术,它是数字媒体技术、自然语言处理、模式识别及机器学习等交叉学科的一个研究方向,具有重要的理论价值和实际应用背景。到目前为止,对基础教育文本智能化网页搜索机器人的研究取得了实质性进展,但这仅仅是探索的第一步,网页机器人理论研究还不成熟,笔者会在今后的科研工作中加强反思、修正和完善,将进一步的研究实践应用到基础教育网站中,为基础教育文本资源网页搜索服务,提高网页机器人搜索效率。
参考文献:
[1]程斯辉.试论基础教育的本质[J].中国教育学刊,2004(1):15-19.
[2]孙茹.搜索引擎的智能化发展方向[J].科技传播,2015(1):125-129.
[3]潘雪峰,花贵春,梁斌.走进搜索引擎[M].北京:电子工业出版社,2011.
[4]李晓黎,刘继敏,史忠植.基于支持向量机与无监督聚类相结合的中文网页分类器[J].计算机学报,2001(1):62-67.
[5]陈毅松,汪国平,董士海.基于支持向量机的渐进直推式分类学习算法[J].软件学报,2003(3):451-460.
[6]國际标准ISO214-1979(E)规定.[EB/OL].http://baike.baidu.com/item/.
[7]Ye S R,Chua T S,Karl M Y,et al.Document concept lattice for text understanding and summarization.Information Processing and Management,2007,43(2):1643-1662.
[8]Chen J C,Zheng Q L,Li Q Y,et al.Chinese combined-word detection based on directed net of word-sequence frequency.Application Research of Computers,2009,26(10):3746-3749.
[9]Institute of computing technology Chinese academy of sciences.ICTCLAS 2009.http://ictclas.org/[2009-4-6].
[10]Guo Y H,Zhong Y X,Ma Z Y,et al.Introduction of the development of automatic summarization.Information Learned Journal,2002,21(5):582-591.Text Basic Education Resources Search Engine Web Robot.
猜你喜欢
法制与社会(2016年32期)2016-12-01
文艺生活·中旬刊(2016年9期)2016-11-07
中国卫生(2015年12期)2015-11-10
警察技术(2015年3期)2015-02-27
新疆大学学报(自然科学版)(中英文)(2014年2期)2014-11-06
技术经济与管理研究(2014年11期)2014-03-11
科学导报·学术论坛(2013年5期)2013-06-26
微型计算机·Geek(2009年1期)2009-12-15
