
数据挖掘在胎儿心率上的规则预测研究*
2017-10-21 03:47:03黄立勤
网络安全与数据管理 2017年19期
陈 宋,黄立勤
(福州大学 物理与信息工程学院,福建 福州 350108)
数据挖掘在胎儿心率上的规则预测研究*
陈 宋,黄立勤
(福州大学 物理与信息工程学院,福建 福州 350108)
瞬时胎心率是监测胎儿健康状态的一种重要方式。当前,监控胎儿心率是重要而复杂的任务,正确的自动化分类和规则提取是非常必要的。医疗诊断自动化系统,不仅加强医疗保健,同时也可以降低成本。设计了一个有效挖掘规则,并根据给定的参数来预测胎儿的风险水平。采用C4.5、Classification and Regression Tree(CART)、随机森林分类器来进行系统比较。该系统的性能评价由分类精度、产生规则数量构成。实验结果表明,基于随机森林分类器的系统具有高精度(99.4%)的预测胎儿健康状态的潜力,同时,产生的规则数量精简且可供于医生决策。
随机森林;瞬时胎心率;规则提取;C4.5;CART
0 引言
数据挖掘(也称为数据库中的知识发现)是一个过程,包括应用数据分析和发现算法。现今,数据挖掘在实践中得到了有效的应用,如行为检测、医疗诊断等。越来越多的用户已经意识到数据挖掘在医疗中的意义。现今,在医疗领域,临床试验的结果往往是基于医生的直觉分析和经验,这会导致错误和巨大的医疗成本,甚至加剧患者病情。目前,许多医院拥有了一些病人的信息收集管理系统来保存病人数据。这些信息系统通常会产生大量的数据,这些数据信息很少用于临床决策。
本文专注于使用数据挖掘技术进行胎心监护数据预测。在实际使用中,观察胎儿的健康状态主要利用胎心监护数据,胎儿心率(Cardiotocogram,CTG)[1]包括两个不同的信号,其瞬时胎心率(Fetal Heart Rate,FHR)和子宫活动的信息可用于早期识别病理状态(即遗传心脏不足、胎儿疼痛或缺氧等),协助医生预测胎儿的健康状态。
目前,医生主要根据胎心监护仪的设备显示信息来判断胎儿状态,无法知晓分类结果的规则。因此,本文研究将胎心数据应用在可解释分类器上,在提高数据分类精度的情况下,产生直观的规则供医生决策。
1 相关工作
Miranda Lakshmi等人[2]挖掘学生的教学数据并利用ID3、C4.5和CART 算法来分析决策树算法的性能。Seema Sharma等人[3]提出了一种基于C4.5分类器不同香农熵来分类。Badr Hssina 等人[4]提出了经典算法ID3,并详细讨论了C4.5,然后与CART分类器做详细比较。Harvinder Chauhan和Anu Chauhan[5]使用WEKA[6]数据挖掘工具在不同大小的可用数据集上实现C4.5算法,同时,在包含有噪声的数据、缺失的数据和大量的数据集上计算精度。但是,医生仅仅依靠分类精度是远远不够的,目前,越来越多的行业应用数据挖掘技术在提高分类精度前提下提取数据规则,提取的信息可用于基于回归的决策医疗数据分析。规则提取算法首先在神经网络下使用[7],但是该算法产生的是不可解释的模型。随后的几年中,Nahla[8]和Chaves[9]等人提出基于支持向量机的规则提取算法,普遍基于黑盒模型,规则提取比较模糊。
正因为规则提取能提高行业工作效率、收益和成本、保持最高水平的护理[10],所以本研究应用数据挖掘技术提取胎心率规则并提高分类精度,能够满足医院的短期目标和长远需要。
2 材料和方法
2.1数据集
本研究所使用的数据集方法是从加州大学欧文分校(University of California Irvine,UCI)[11]上获取,其中包括一些指示性的特征。三位产科医生决定标记CTG数据为正常或病理状态且给出了每个属性的解释。CTG数据有21个特征,8个是连续的,13个是离散的。每个样本标记胎儿状况正常或异常。
2.2C4.5决定树分类器
C4.5是机器学习算法中的一个分类决策树算法。C4.5利用“信息增益”得到一个新的测量称为“增益比”。正是基于此,C4.5采用了信息增益率这样一个概念。信息增益率使用“分裂信息”值将信息增益规范化。分类信息定义如下:
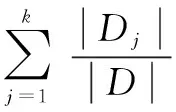
(1)
信息增益率定义:

(2)
选择具有最大增益率的属性作为分裂属性。不过该分类器在构造树的过程中,需要对数据集进行多次的顺序扫描和排序,因而导致算法的低效。
2.3CART分类器
分类和回归树在20世纪80年代被提出,它的主要特征是属性(节点)的分割,并在每个终端节点分配给类结果(或回归的预测值)时做出决策。CART使用基尼指数选择最好的分裂节点。每个子节点重复搜索过程,继续递归,直到不可能进一步分裂或停止。在此过程中产生了大量的分支,而后,通过修剪分支产生最优节点。
CART使用基尼索引来选择具有最大值的属性信息。基尼指数公式:
(3)
2.4随机森林分类器
随机森林分类器是利用多棵树对样本进行训练并预测的一种分类器。简单来说,随机森林是由多棵CART树构成的。对于每棵树,它们使用的训练集是从总的训练集中有放回采样出来的,这意味着,总的训练集中的有些样本可能多次出现在一棵树的训练集中,也可能从未出现在一棵树的训练集中。在训练每棵树的节点时,使用的特征是从所有特征中按照一定比例随机地无放回地抽取的。
决策树中分裂属性的两个选择度量:
(1)信息增益
如果选取的属性为A,那么分裂后的数据集D的基尼指数的计算公式为:
(4)
对于特征选取,需要选择最小的分裂后的基尼指数。也可以用基尼指数增益值作为决策树选择特征的依据。选择具有最大信息增益的属性为分裂属性。
(2)基尼指数
分裂后的数据集D的基尼指数的计算公式为:
(5)
分裂属性选择规则:选择具有最小基尼值的属性为分裂属性,在构造过程中,该算法会遍历所有可能的分割方法。不需要对决策树生成过程进行剪枝。
3 实验结果及讨论
3.1测量性能标准
真负类率(True Negatives,TN)、假负类率(False Negatives,FN)、真正类率(True Positives,TP)和假正类率(False
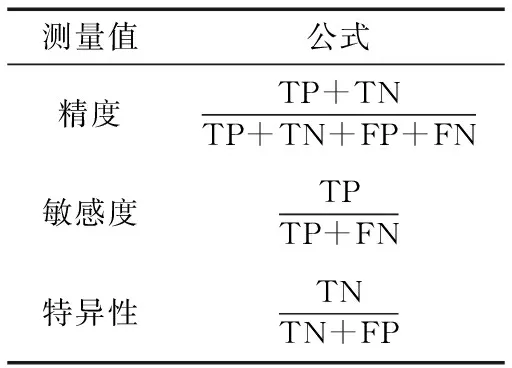
表1 分类器测量值
Positives,FP)是用来分类性能计算的。敏感性和特异性均为统计学检验测试样本的度量。
在表1中,应用测量给出了它们的数学表达式。
3.2实验结果
(1)精度对比
将所有CTG数据分为两部分,一部分用于训练,其余部分用作试验组。该过程调用了10-fold交叉验证[12],避免选择特殊的数据用于训练和测试。精度如表2所示。
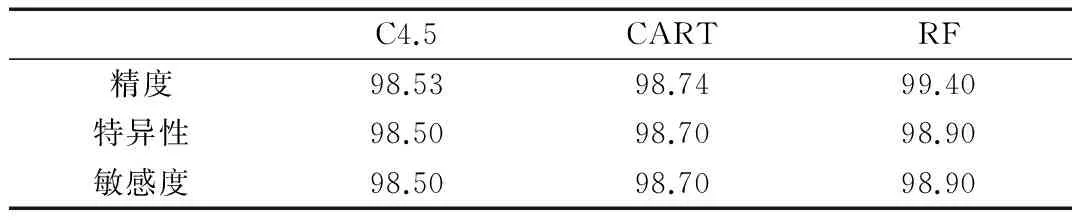
表2 样本分类精度的对比 (%)
(2)CTG数据集规则提取结果
字符为数据集的特征属性,三类算法规则提取流程如图1~图3所示。英文字符为胎儿心率数据的特征属性。冒号后的数值用数字2代表胎心率状态糟糕,用数字1代表胎心率状态正常。
3.3结果讨论
实验表明,随机森林的分类精度最高达到99.40%。同时,随机森林产生的规则更加精简,对于医生的决策帮助更有益。

图1 C4.5算法在CTG数据集上提取规则

图2 CART算法在CTG数据集上提取规则

图3 RF算法在CTG数据集上提取规则
4 结论
胎心监护记录广泛用于检测胎儿健康状态,将其应用在机器学习上,可以依据分析结果采取必要的行动。未来工作将主要进行选取精准的规则算法研究。
[1] 王乃平. 胎心监护仪的产前应用[J]. 河北联合大学学报(医学版), 2009,11(2):188-189.
[2] MARSDEN C A, JR O J B, GULDBERG H C. An analysis on performance of decision tree algorithms using student’s qualitative data[J]. International Journal of Modern Education & Computer Science, 2013,5(5):18-27.
[3] SHARMA S, AGRAWAL J, SHARMA S. Classification through machine learning technique: C4.5 algorithm based on various entropies[J]. International Journal of Computer Applications, 2014,82(16):28-32.
[4] CERVONE G, FRANZESE P, EZBER Y, et al. Risk assessment of atmospheric emissions using machine learning[J]. Natural Hazards & Earth System Sciences,2008,8(5):991-1000.
[5] CHAUHAN H, CHAUHAN A. Implementation of decision tree algorithm C4.5[J]. American Journal of Sports Medicine, 2013,39(12):2611-2618.
[6] HALL M, FRANK E, HOLMES G, et al. The WEKA data mining software: an update[J]. Acm Sigkdd Explorations Newsletter, 2009,11(1):10-18.
[7] GALLANT S I. Connectionist expert systems[J]. Communications of the Acm, 1988,31(2):152-169.
[8] BARAKAT N H, BRADLEY A P. Rule extraction from support vector machines: a sequential covering approach[J]. IEEE Transactions on Knowledge & Data Engineering, 2007,19(6):729-741.
[9] CHAVES A D C F, VELLASCO M M B R, TANSCHEIT R. Fuzzy rule extraction from support vector machines[C]. International Conference on Hybrid Intelligent Systems, IEEE,2005.
[10] SILVER M, SAKATA T, SU H C, et al. Case study: how to apply data mining techniques in a healthcare data warehouse[J]. Journal of Healthcare Information Management Jhim, 2001,15(2):155-164.
[11] BACHE K,LICHMAN M.UCI Machine Learning Repository[EB/OL]. http://archive.ics.uci.edu/Irvine,CA:University of California, School of Information and Computer Science. 2013.
[12] 邓蕊,马永军,刘尧猛.基于改进交叉验证算法的支持向量机多类识别[J].天津科技大学学报,2007,22(2):58-61.
Study on rule prediction of data mining in fetal heart rate
Chen Song, Huang Liqin
(College of Physics and Information Engineering, Fuzhou University, Fuzhou 350108, China)
Fetal heart rate is an important way to monitor fetal health. At present, the monitoring of fetal heart rate is an important and complex task, and correct automatic classification and rule extraction are necessary. Medical diagnostic automation systems will strengthen health care, but also reduce costs. In this study, we designed an effective rule to predict the risk level of fetus. Then, we used C4.5, Classification and Regression Tree(CART), random forest classifier to evaluate the system. The performance of the system is evaluated by the classification accuracy, which produces the number of rules. The experimental results show that the system based on the random forest classifier has high accuracy(99.40%)in predicting the health status of the fetus, while the number of rules produced is simplified and can be used for decision making.
random forest; fetal heart rate(FHR); rule extraction; C4.5; CART
TP301.6;Q-332
A
10.19358/j.issn.1674- 7720.2017.19.005
陈宋,黄立勤.数据挖掘在胎儿心率上的规则预测研究[J].微型机与应用,2017,36(19):16-18.
国家自然科学基金重点项目资助(61471124)
2017-04-01)
陈宋(1989-),男,硕士研究生,主要研究方向:人工智能与机器学习。黄立勤(1973-),通信作者,男,博士,教授,主要研究方向: 高性能计算、人工智能与机器学习、医学图像处理等。E-mail:lqhuangfzu@163.com。
猜你喜欢
现代仪器与医疗(2022年2期)2022-08-11 09:52:56
成都信息工程大学学报(2021年4期)2021-11-22 07:44:40
考试与评价·高二版(2021年1期)2021-09-10 14:44:53
电子测试(2018年1期)2018-04-18 11:52:35
环球人物(2017年7期)2017-04-17 10:12:29
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
环球时报(2016-08-25)2016-08-25 06:36:24
母子健康(2016年2期)2016-05-18 16:53:20
为了孩子(孕0~3岁)(2016年3期)2016-03-11 20:18:04
