
多标签图像的识别分类处理算法*
2017-10-19 05:47:48徐有正
计算机时代 2017年10期
徐有正,黄 刚
(南京邮电大学计算机学院,江苏 南京 210003)
多标签图像的识别分类处理算法*
徐有正,黄 刚
(南京邮电大学计算机学院,江苏 南京 210003)
目前卷积神经网络已在单标签图像的识别上得到了高效的应用,而多标签图像的识别需要处理包括尺寸、形状、布局等多个对象,所以单标签图像分类的网络模型架构不能很好地识别出复杂的对象布局和多标签图像场景。文章提出了端到端方式训练的多标签图像识别算法,在对图像进行随机缩放和裁剪后,再进入卷积神经网络,其输出经过池化分类层,筛选出有效区域。同时提出加权、动态的欧式距离损失函数用于神经网络的优化。实验结果显示,该算法有效提高了多标签图像识别的精度。
多标签图像;卷积神经网络;图像识别;动态损失函数
0 引言
近几年图像识别技术迅速发展,卷积神经网络(Convolutional neural network,CNN)[1]已经能很好地应对单标签图像识别问题[2-3]。而对于多标签图像,尽管可以通过单标签数据集(ImageNet[4])进行训练,从而实现自动识别,但却不能识别多标签图像中的复杂对象和布局。
目前有一些方法用于解决以上多标签图像分类问题[3],其中一种是将多标签识别问题转化为单标签预测问题,即对图像内的对象进行分析定位并分类,但收集对象边界信息需要耗费大量的计算资源。另一种方法是引入对象方案。如MCG[5]通过计算某个点的像素是否属于边缘的概率,对边缘图进行一系列操作得到UCM图,但结果有不可预测性,需要计算数千个方案实现高召回率。魏等人是通过聚类算法选择对象方案的一小部分,从所有方案中提取标签,再通过池化层处理获取图像分类结果[6]。杨等人提取了200个对象方案,通过双流CNN网络编码成为Fisher矢量,用于表示每个多标签的对象[7]。但他们忽略了多标签图像中的标签关系,且都不是端到端的可训练的方法。在网络训练过程中,由于对象方案仅能覆盖部分信息,都会不可避免地使部分有效信息缺失。
1 端到端方式训练的多标签图像识别
本文提出了端到端方式训练的多标签图像识别算法,在进入卷积神经网络之前,通过对图像进行随机缩放和裁剪,再经过卷积神经网络的分类。
由于不同区域对应不同的标签,为了实现高召回率,本文设计出了新的最大池化分类层,该层通过对比所有样本,筛选出被激活的得分最高区域,并通过反向传播算法优化网络。为了进一步提高图像识别的准确度,本文提出了新的动态损失函数用于神经网络的训练。该损失函数根据每个标签的置信度,惩罚那些置信度低的标签来校验网络,以此更好地监督网络训练过程。
1.1 预处理
在图像预处理阶段,本文方法将一个图像I采用随机缩放的方法,保持其长宽比将其宽缩放至x像素,变为图像M。在依次采用随机比例a∈[0.5,1]重新缩放{M1,M2,…,Mt},最后再从 Mt中随机裁剪出 b 个224×224的图像{O1,O2,…,Ob}。最终得到k(k=a×b)个不同信息的特征子图。在进行训练时,单从一个特征子图上看,并不能很好地计算原图像中所有内容。考虑到这一点,本文方法将来自同一个图像的样本的特征子图都放,在同一个mini-batch进行训练。整体处理过程如图1所示。

图1 处理全过程
1.2 融合分类
随机缩放和裁剪的处理将一个图像生成了k个不同的特征子图,每一个子图都代表着不同尺度和位置的信息。因为子图中仅能提供有限的识别信息,甚至仅覆盖小部分。所以问题的关键是如何让这些动态生成的子图代表整个图像中的有效信息。本文方法在共享卷积神经网络后增加一层最大池化分类层以解决这个问题。如公式⑴,我们用pnkc∈Rn×k×c来表示一个mini-batch的预测分数。其中C={1,2,…,c}表示一个不同类别的标签集合,c是其中一个分类。每一次训练的mini-batch的大小为N,n表示{1,2,…,N}其中一个样本数据,k表示第k个子图。

经过最大池化分类层的合并处理,某个特征子图最适合代表的某个分类,其预测值将会最大,便于筛选每一个分类最容易被识别的特征,详细处理过程如图2所示。

图2 融合分类示意图
1.3 动态欧式距离损失函数
Softmax regression作为Logistics regression的一种扩展,常常多用于解决多分类问题。该损失函数如公式⑵。

其中,N为mini-bacth的大小,Pn是第n个样本经过归一化处理后,得到正确标签的概率。其表达式如公式⑶。

其中,C是所有类别标签的总个数。tn是第n个类别中原始预测分数。
然而直接将Softmax的损失函数用于多标签分类问题显然是不合适的,因为从上述的公式中可以看出,从每一次的mini-batch的训练中,它只能计算出一个正确标签的概率。而我们一个图片中是多个标签,即对应着多个类别。
针对多标签识别问题的分析如下。
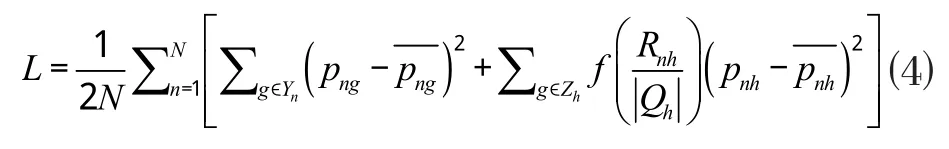
假设该识别系统中共20个分类,当进行图像识别时,该系统会针对当前图像对所有的分类得出一个预测值。例如一个图像中有狗,人,帽子,那么在理想状态下,狗,人,帽子的预测值都会比较高,其他如马,车等类别的预测值就会降低。但是在实际操作中,所有预测值并不都是完美的,有可能错误的类别预测值会很高。所以针对这样的情况,本文提出了一种动态的基于欧式距离的损失函数,如公式⑷。其中N表示一个mini-batch中所有样本,n表示第n个样本。Rnh所表示的是第n个样本中第h个错误标签的预测值。代表的是错误标签集合的基数。Yn代表的是分类正确的集合,Zh表示错误集合。png代表的是第n个样本中第g个类别中实际正确标签的预测值,pnh代表的是第n个样本中第h个类别实际错误标签的预测值。f是用于学习排序的重新加权函数,如公式⑸所示。用和来表示第n个批次的期望输出值,本文就直接用1和0来表示。从公式⑷可以看出,如果错误的样本数很多,通过加权函数的运算将会使整体的损失函数变大,从而达到惩罚效果。

本文采用了随机梯度下降法来优化,其优化过程如下。

将式⑹分解,以便于计算。如公式⑺⑻所示。

综合公式⑹-公式⑻,可以容易地计算梯度,并可通过标准误差反向传播算法来最小化损失函数。
2 实验
本次实验采用了PASCAL VOC 2007数据集和PASCAL VOC 2012数据集。VOC是一个多标签的数据集。其中PASCAL VOC 2007数据集中共有9953幅图像用于训练和测试。该数据集中每个图像都存在着1-7个对象,每个对象对应着10个分类中的一类。PASCAL VOC 2012数据集具备更多的数据,共22531幅图像。在测试集中并没有正确标签,所以需在最后用PASCAL VOC评估服务器来测试结果。本文采用了VGG-16作为CNN的模型。VGG有很多版本,它的特点是连续的卷积层多,计算量也比较大。
训练:在训练前先使用ImageNet数据集来预训练CNN模型,以便初始化网络,再在VOC数据集上进行微调。复制所有预训练的参数,并将偏置初始值设为0,设置学习速率为0.0002,最后全连接层的学习速率设置为0.002。
测试:先将已经训练好的CNN模型后添加三层全连接神经网络,使其转换为完全卷积神经网络,后添加的全连接网络此时并不需要训练。开始测试图像,先将图像将宽分别缩放为{256,384,512,640,768}五个不同尺度的图像,并保持长宽比。最后分别在完全卷积模型中训练五个不同尺度。
3 实验结果对比与分析
本文将此方法与当下流行的比较先进的方法进行比较。其结果在图3中可以看出。本文方法在两个数据集中的表现都明显优于其他方法。HCP-VGG引入了对象提案的办法,它和本文的方法相比略麻烦,因为需要先提取数百个对象提案,然后再对不同类型的对象进行后续处理,最后才能学习到多标签图像的识别方法。本文方法可以直接利用随机抽取样本的方式,生成一个图像多角度的样本,不需要选用上百个对象就可以达到不错的识别率。
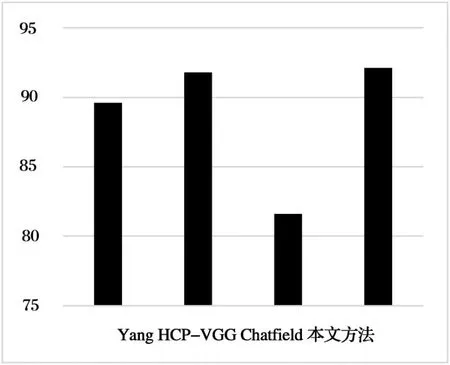
图3 各种方法准确率对比
⑴ 本文方法共分为随机缩放,随机截取和动态损失函数优化三个步骤。为了探究预处理的必要性,本文重新采用PASCAL VOC 2007数据集,对每个步骤进行单独测试。单尺度随机裁剪:直接将图像的宽缩放至256像素,直接进行随机裁取。
⑵ 随机尺度无裁剪:采用无裁剪的随机尺度的方法,因此不需要使用合并类别最大池操作。
⑶ 使用加权动态欧式距离损失函数。
实验结果如表1所示,如果采用了单一尺度随机裁剪方法,识别率对比本文方法下降了2.1%。如果采用随机尺度单一裁剪的方法,识别率相比本文方法也下降了1.3%。如果采用了标准的欧几里德损失函数,识别率也比本文方法少了0.6%。
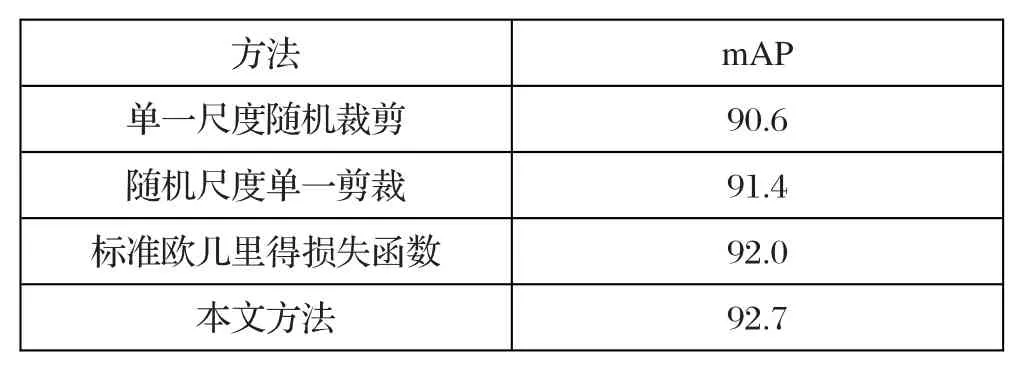
表1 不同方法结果比较
4 总结
针对多标签图像的识别问题,目前大多数有效方法是采用对象提案法来解决的,即在训练之前,生成上百个对象区域,再用离线对象建议训练网络,这些方法实际上是不断修复调整候选区域。而本文方法并非如此,其本质是直接寻找有效区域,从而节省了大量的计算机计算资源。另外,本方法不局限于一种卷积神经网络,可更换其他卷积神经网络,因而有广泛的适用性,具有较好的应用前景。
[1]常亮,邓小明,周明全,武仲科,袁野,杨硕,王宏安.图像理解中的卷积神经网络[J].自动化学报,2016.9:1300-1312
[2]C.Xu,D.Tao,and C.Xu,"Large-margin multi-view information bottleneck," IEEE Trans. Pattern Anal.Mach.Intell.,2014.36(8):1559-1572
[3]Donahue J,Jia Y,Vinyals O,et al.DeCAF:a deep convolutional activation feature for generic visual recognition[C]//InternationalConference on International Conference on Machine Learning.JMLR.org,2014:I-647
[4]J.Deng,W.Dong,R.Socher,L.-J.Li,K.Li,and L.Fei-Fei,"ImageNet:A large-scale hierarchical image database,"in Proc.CVPR,2009:248-255
[5]P.Arbeláez,J.Pont-Tuset,J.T.Barron,F.Marques,and J.Malik,"Multiscale combinatorial grouping,"in Proc.CVPR,2014:328-335
[6]Wei Y,Xia W,Huang J,et al.CNN:Single-label to Multi-label[J].Computer Science,2014.
[7]Yang H,Zhou J T,Zhang Y,et al.Exploit Bounding Box Annotations for Multi-label Object Recognition[J].Computer Science,2016.
Recognition and classification algorithm for multi-label image
Xu Youzheng,Huang Gang
(School of Computer Science and Technology,Nanjing University of Posts and Telecommunications,Nanjing,Jiangsu 210003,China)
Convolutionalneuralnetwork hasbeen widely applied in single-tagged imagerecognition.Formulti-labelimage recognition,it is necessary to deal with various objects including size,shape,and layout and so on.Therefore,the network model architecture of single-label image classification cannot recognize well in complex object layout and multi-label image scene.The multi-label image recognition algorithm trained by the end-to-end training method is proposed in this paper.After random zooming and cutting the image is processed by convolutional neural network,and then the effective area is screened through the pooled classification layer.Meanwhile,a weighted and dynamic Euclidean distance loss function is proposed also for the optimization of neural network.Experimental results show that the accuracy of multi-label image recognition is improved effectively.
multi-label image;convolutional neural network;image recognition;dynamic loss function
TP391.4
A
1006-8228(2017)10-04-04
2017-08-16
国家自然科学基金项目(61171053);南京邮电大学基金(SG1107)
徐有正(1992-),男,江苏宿迁人,硕士研究生,主要研究方向:机器学习与图像识别。
黄刚(1961-),男,江苏南京人,教授,硕士研究生导师,主要研究方向:计算机软件理论及应用。
10.16644/j.cnki.cn33-1094/tp.2017.10.002
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
电子制作(2019年16期)2019-09-27 09:34:50
中国交通信息化(2019年4期)2019-07-13 05:51:34
电子制作(2019年11期)2019-07-04 00:34:38
电子制作(2018年19期)2018-11-14 02:37:04
车迷(2018年11期)2018-08-30 03:20:32
电子制作(2018年14期)2018-08-21 01:38:16
海峡姐妹(2018年3期)2018-05-09 08:21:02
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
公民与法治(2016年10期)2016-05-17 04:12:58
