
一种高性能低复杂度的基于串匹配的屏幕图像无损压缩算法
2017-10-13 22:13蔡文婷陈先义周开伦王淑慧
电子与信息学报 2017年2期
林 涛 蔡文婷 陈先义 周开伦 王淑慧
一种高性能低复杂度的基于串匹配的屏幕图像无损压缩算法
林 涛 蔡文婷*陈先义 周开伦 王淑慧
(同济大学超大规模集成电路研究所 上海 200092)
传统无损压缩算法对屏幕图像的压缩效果不佳。该文根据典型屏幕图像的特性,以LZ4HC(LZ4High Compression)算法为具体实现基础,提出一种基于串匹配的高性能低复杂度(String Matching with High Performance and Low Complexity, SMHPLC)的屏幕图像无损压缩算法。相对于传统字典编码无损压缩算法,新算法提出了以像素为搜索和匹配单位,对未匹配串长度、匹配串长度以及匹配偏移量这3个编码参数进行联合优化编码,并对参数进行映射编码。实验结果表明,SMHPLC具有高性能和低复杂度的综合优势,大幅降低编码复杂度,提高了编码效率。使用移动的文字和图形类的AVS2通用测试序列作为测试对象,对于YUV和RGB两种格式,SMHPLC算法比LZ4HC总体节省码率分别为22.4%,21.2%,同时编码复杂度降低分别为35.5%,46.8%。
无损压缩算法;屏幕图像编码;字典编码;LZ4High Compression (LZ4HC)
1 引言
随着移动互联网的飞速发展以及虚拟化技术的日益成熟,在市场需求的推动下,移动平台和云计算平台[1]逐步得到广泛的应用。云计算平台作为传统计算机和网络技术发展融合的产物,通过整合分布式资源,可以把海量的数据存储和程序执行迁移到云端,提高安全性,降低成本和能耗[2]。作为云计算平台的典型应用之一,桌面云可以实现用户在瘦客户端或者其他与网络连接的设备(如普通台式机、笔记本电脑、智能手机等)通过网络访问数据中心云端服务器和应用程序[3]。用户由传统的终端至应用的访问模型变为从本地客户端连接到桌面云获取到应用并显示在屏幕上。因此,提高屏幕图像的传输效率是亟需解决的重要问题[4]。
屏幕图像包含自然图片和文本图形等。对于拍摄的自然图像,现有的图像和视频编码标准(如JPEG, H.264/AVC, AVS, HEVC等)具有出色的编码性能。但对于计算机产生的文本、图形、图标等区域,传统视频编解码器的效果并不理想。为了提高屏幕图像编码的性能,国际电信联盟(ITU-T)、国际标准化组织(ISO)和国际电工委员会(IEC)联合启动了基于屏幕图像编码(Screen Content Coding, SCC)标准的研究。
对于屏幕图像中非连续色调内容,基于串匹配的字典编码有很好的压缩性能。字典编码的基本原理是建立一个已经完成编码的历史数据的空间(字典),在其中寻找待编码数据的匹配串(即参考串),以编码匹配参数(匹配的位置,匹配的长度)替代当前数据串写入码流。当前主流的字典编码算法中,Gzip和zlib有很高的压缩率但处理器资源消耗较大,速度较慢[9]。Bzip2和7zip算法有很好的压缩效果,但对计算资源的消耗比Gzip和zlib还要高得多。LZ4作为当今高性能的无损压缩算法的典型代表,编码速度远超zlib并且解码速度近乎是其5倍。它的编码速度能达到超过400 MB/s,解码速度也能超过1.8 GB/s。作为LZ4的高压缩率(High Compression, HC)版本[13],LZ4HC以更全面的搜索方式弥补了LZ4进行快速搜索而引起压缩比的损失,虽然编码时间有所增加,但解码时间不受影响,是目前商用屏幕图像编码产品的首选算法。
屏幕图像由像素构成。而传统的LZ4和LZ4HC等算法都是以字节为单位,将像素的3个分量看成3个独立的字节,未充分利用像素的冗余,尤其是匹配串的位置可能不是整像素的边界而降低了编码效率。
针对传统字典编码无损压缩算法的这些缺陷,本文提出了基于像素为单位的字典编码无损压缩算法,结合典型屏幕图像的特有统计特性,采用对匹配参数进行映射和可变字节联合优化编码的方式进一步提高压缩性能,同时也大大降低计算复杂度。
2 本文提出的方法
本文以LZ4HC算法为具体实现的基础,提出一种充分利用屏幕图像的数据特性的基于串匹配(String Matching)的高性能低复杂度(High Performance Low Complexity)屏幕图像无损压缩方法:SMHPLC算法。
2.1 传统的LZ4HC算法的基本原理
LZ4HC的压缩后码流的数据[14]由4个部分组成:未匹配串长度、未匹配串字节、匹配串长度及匹配偏移量。如图1所示,写入码流的数据依次为1个字节的Token, 0至多个字节的Literal Length (未匹配串长度),0至多个字节的Literals(未匹配串字节),两个字节的匹配串Offset(匹配偏移量)以及0至多字节的Match Length(匹配串长度)。Token的高4位表示Literal Length,低4位表示Match Length,取值范围均为0~15。当未匹配串长度或者匹配串长度小于15时,则不需要消耗额外的字节,否则剩下的长度1次消耗1 Byte写入码流,直到写入的最后一个字节小于255,每个字节表示的长度范围是0~255。Offset是当前串距离参考串的偏移量,以Byte为单位,范围是1~65535。匹配串的默认最小允许长度为4 Byte,因此将Match Length减去4后再进行编码,实际最小值为0。下文中提到的Match Length均为实际编码的Match Length。
LZ4HC利用散列表(Hash Table)查找最佳匹配串,通过键值对(key, value)的映射关系进行搜索。默认的Hash表大小是16 kB。Hash表中存放具有相同Hash值且离当前待编码位置最近的参考点与参考基(Base)之间的距离,如式(1)所示。LZ4HC中还分配了链表(Chain Table)数组用来多次尝试匹配以获取最长匹配串,当前位置对应的参考索引(index)取低16位作为链表的下标,如式(2),式(3)所示,计算index与Hash表中对应值之间的差值delta,并将其存入链表数组中。下面提到的索引均为当前地址到Base的距离,默认的Base位置为输入的压缩数据块的起始位置减去64 kB。默认链表使用内存是64 kB,故Offset只需要两个字节。对当前待匹配串前面的字符串按每4 Byte采用至之间的黄金分割素数2654435761U计算Hash值。搜索Level可设定的最大值为16,即最大搜索次数为。

(2)
(3)
搜索过程如下:

图1 数据块的输出码流的格式
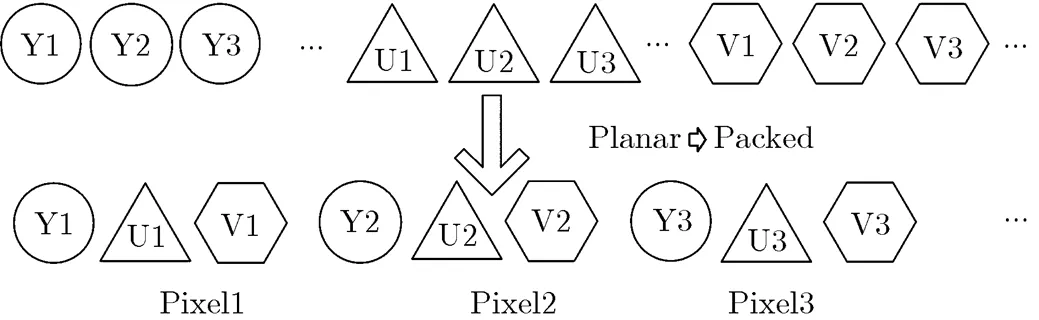
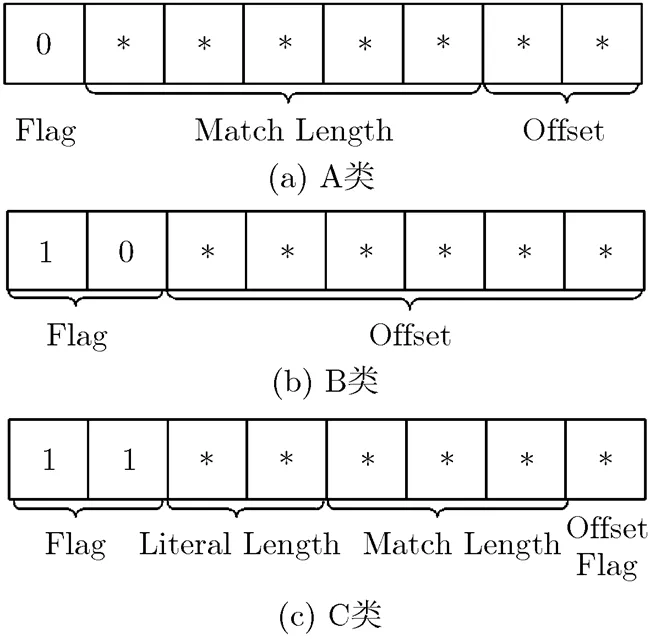
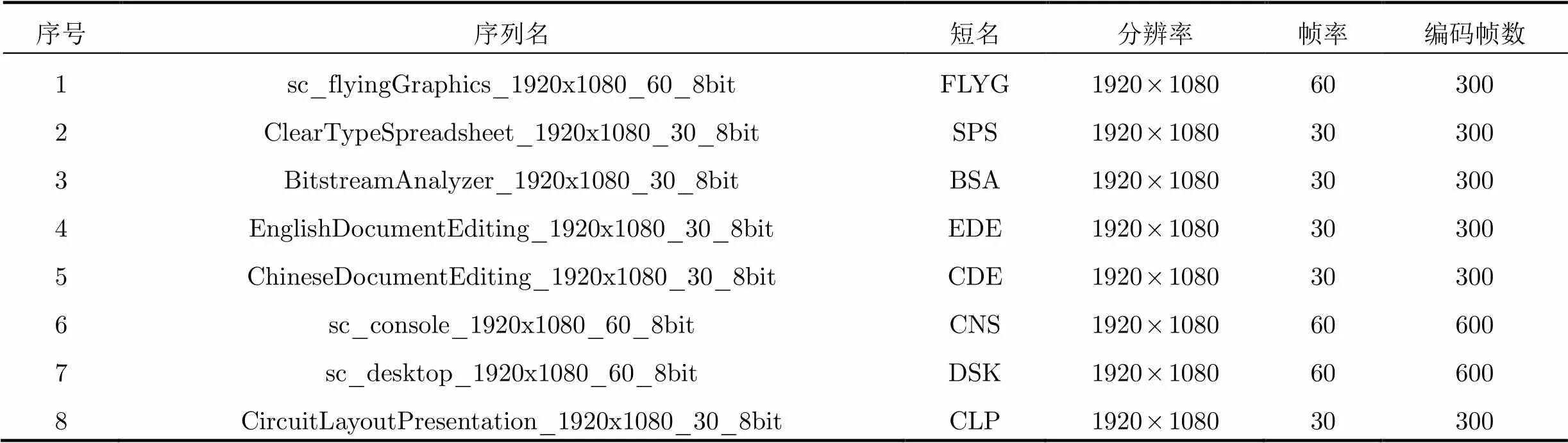
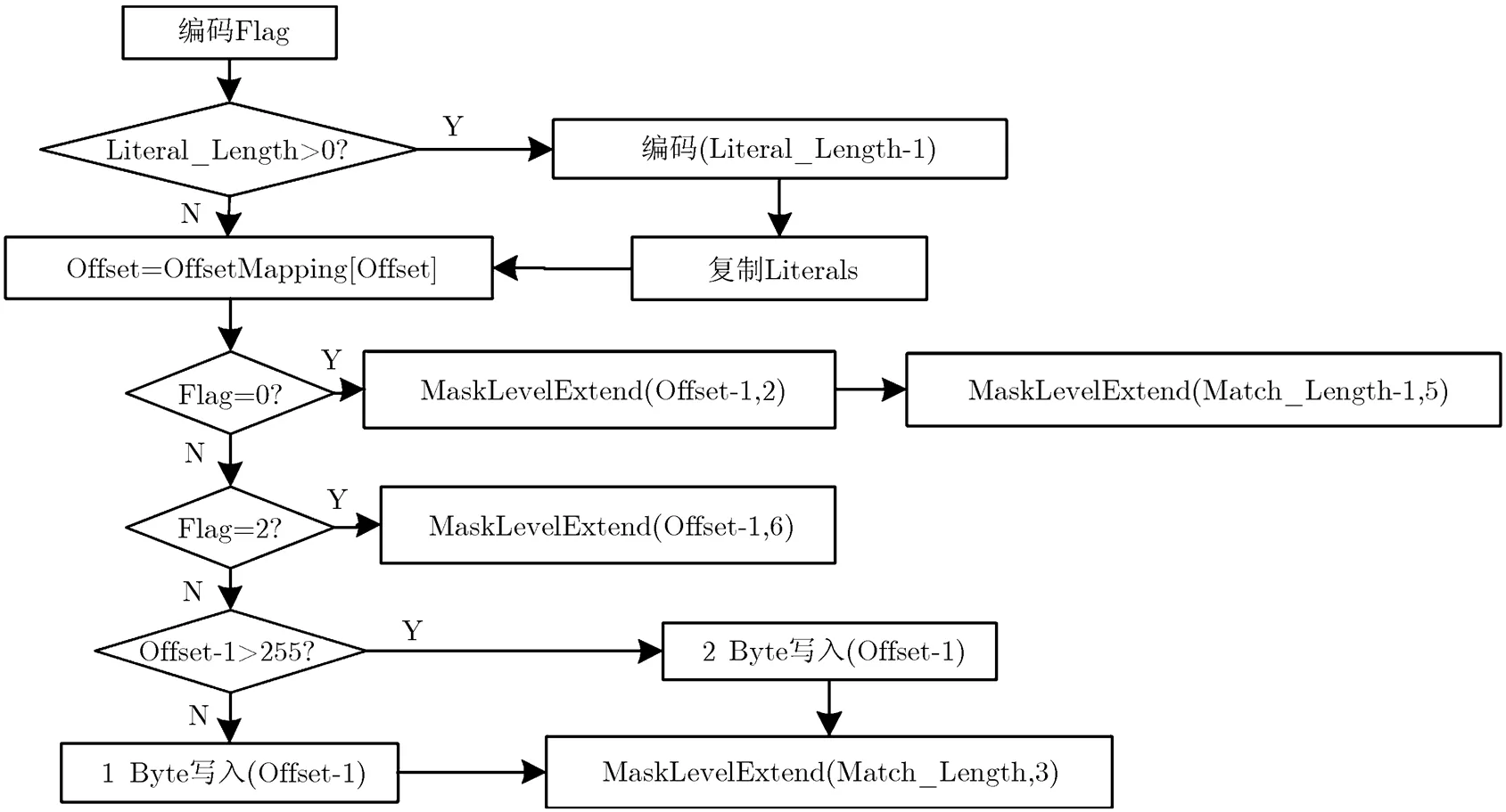
(1)当前地址指针ip,当前地址索引为index,上一次已编码的串的起始地址索引为nextTo Update。若index (2)计算当前待编码位置的Hash值hcur。最佳匹配长度ml 置为0。 (3)若该位置为首次寻找匹配,则根据hcur获取Hash表中的匹配位置;否则,从Chain Table中获取匹配位置。匹配位置索引matchIdx,对应的地址为ref。 (4)如果ref在限制条件的范围内且不超过搜索次数, (a)如果ref等于ip,继续计算匹配长度。获得该匹配位置的匹配长度为mlt。若mlt>ml,则ml=mlt。 (b)否则跳转到步骤(3)。 不符合匹配前提条件,则跳转到步骤(5) (5)按照图1数据块的输出格式编码Literal Length, Literals, Offset, Match Length,写入码流中。 默认的最小匹配串长度是4 Byte,若当前位置未搜索成功,则将当前指针ip右移4 Byte继续进行下轮搜索。默认设置下,当待编码串长度大于13 Byte的时候才会进行Hash搜索匹配,且最后5 Byte总是Literals。传统的LZ4HC在Hash搜索后还会扩大范围进行第2次搜索,本文改进该算法时并没有采用。 2.2 SMHPLC算法 针对屏幕图像特性和传统字典编码算法的缺陷,本文提出如下改进以提高编码效率和降低计算复杂度: (1)将基于字节的搜索和匹配改为基于像素的搜索和匹配。 (2)对Literal Length和Match Length等匹配参数进行联合优化编码。 (3)建立映射数组,将匹配参数中出现频度很高且数值很大的区段映射为数值较小的区段。 SMHPLC算法的整体框架如图2所示,主要分为更新Hash Table和Chain Table,在最大搜索次数的限制内寻找最佳匹配,和编码 (包括3个编码参数,以及复制Literals)这3个部分。 2.2.1 基于像素的搜索和匹配 对输入的编码块(也可以是整幅图像)按照水平或者垂直扫描顺序把图像数据排列成像素串,如图3所示,以YUV色彩格式为例,将Y, U, V 3个分量以该顺序打包成一个像素Pixel(YUV)。基于此,本文将传统算法中连续4 Byte计算Hash值的方式改为计算1个像素的Hash值,即连续的3 Byte的Hash值。所以在进行Hash搜索前,以像素为单位增加index,将位置信息存入Hash Table和Chain Table中。在搜索最佳匹配串时,匹配串的长度也以像素为单位来计算,最小匹配串长度则是一个像素(即3 Byte)。这样,既能找到更长匹配串,也能将有关匹配参数的数值缩小为原来的1/3,从而进一步提高编码的性能。 图2 SMHPLC算法的整体框架 图3 像素打包排列 本文提出的方法对YUV色彩格式或者RGB色彩格式的屏幕图像均有效,同时对按照水平或者垂直扫描顺序排列的屏幕图像也都同样有效。对于大多数屏幕内容,水平扫描比垂直扫描的编码压缩性能相对高一些。但对于有些屏幕内容,如垂直线条比较多的屏幕图像,垂直扫描的编码压缩性能高一些。 2.2.2 对匹配参数的联合优化编码 使用LZ4HC和SMHPLC,以8个移动的文字和图形类的AVS2屏幕与混合内容视频编码通用测试序列[15]为统计样本空间,对测试数据分别进行搜索Level为4时基于像素和字节匹配的Literal Length和Match Length的联合分布统计。联合分布结果如表1所示,按像素匹配时,Literal Length = 0同时Match Length = 0的情形比例达到24.10%,而按字节匹配时只占4.12%。由此可见,按像素匹配时,如果沿用LZ4HC的方法,Token的高4位和低4位均为0,另外还消耗2 Byte编码Offset,总共消耗3 Byte来编码这种匹配串。实际上,可能更好的策略是在Token中拿出1 bit或者2 bit作为Flag,将剩下的比特用来编码Offset,在某些情况下可以不需要额外的字节就能完成一个匹配串的编码。因此,本文进行了如下两种方案的尝试: 方案1: A类 Token中的最高位0表示Literal Length和Match Length 均为0的情形; B类 Token中的高两位10表示Literal Length等于0且Match Length大于0的情形; C类 Token中的高两位11表示Literal Length大于0且Match Length不小于0的情形。 表1 Literal Length和Match Length联合分布(%) 方案2: A类 Token中的最高位0表示Literal Length等于0且Match Length大于0的情形; B类 Token中的高两位10表示Literal Length和Match Length均为0的情形; C类 Token中的高两位11表示Literal Length大于0且Match Length不小于0的情形。 经实验,方案2优于方案1,故本文采用了方案2,并在此基础上继续对3个匹配参数的编码进行改进。 传统的LZ4HC编码Match Length和Literal Length都是用1 Byte表示0~255,多个字节逐个累加的方式编码1个长度。对上述测试序列进行Match Length的统计,长度小于256所占比例高达99%,除Token编码的长度外最多只需要1 Byte就可以编码Match Length的整个长度。因此,本文提出了根据掩码分段编码的算法(记为MaskLevelExtend),编码部分描述如表2所示。 这样,根据输入的编码参数值所在的掩码区间分成4段进行编码,以只利用Token中分配的比特数,或者还需要额外的1 Byte、2 Byte或更多字节进行编码,可以大幅减少字节消耗,提高数据压缩率。 基于像素匹配的Offset的最大值为65535/3= 21845,经统计Offset小于255的部分占总数的70.3%,因此为所有的Offset都分配两个字节造成了很大的浪费。针对C类Literal Length>0且Match Length=0和Literal Length>0且Match Length>0的情形,本文提出在Token中再利用1 bit作为Offset是否小于255的标志,当Offset小于255时只分配1 Byte,以此进一步提高压缩率。对于A类和B类,由于Literal Length等于0,可以将Token中除去标志位以外剩下的比特共同编码Match Length和Offset,通过尝试不同的分配策略找出最佳方案。经试验,A, B, C类中最终的Token比特分配如图4所示。 图4 A, B, C类中Token的比特分配 表2 掩码分段编码的算法的编码 2.2.3 对匹配参数的映射 映射的思想是将匹配参数中部分出现频度较高且需要较多字节编码的值映射为频度较小且字节消耗较少的值,从而减少总体字节消耗。根据对Match Length和Offset的频度统计,建立映射数组,从数组中取出该匹配参数值对应的映射值后,再对该映射值进行后续的编码。 本文采用了整体映射与局部映射相结合的方案,取值如表3所示。对于整体映射,考虑Token中各编码参数的比特分配以及频度统计,建立上文中A, B, C 3类情况均适用的Offset映射数组。对于局部映射,统计情况A中Match Length和Offset的联合频度,对满足映射要求的Match Length和Offset建立联合映射对,在编码参数前进行局部一一映射。由于情况B实际只编码Offset,比较不同的掩码分段区间内出现的频度,选取合适的数值进行映射。映射的具体过程为,在进行分类编码前,首先对Offset进行整体映射,从映射数组中取得对应的映射值作为接下来编码的Offset。然后在A, B两种情况下,对待编码的Match Length, Offset进行该情况下的局部映射,再对参数的映射值进行编码。由于情况C下Token中用于编码的Match Length的比特数较少,所以该情况未进行局部映射。 表3 整体映射和局部映射取值 在LZ4HC算法基础上实现的SMHPLC算法的流程如图5所示,Flag的取值范围为0, 2, 3,分别对应A, B, C 3类情形。 本文的实验在lz4-r127[16]代码基础上实现SMHPLC算法,并且使用表4所示8个AVS2屏幕与混合内容视频编码通用测试序列的前10帧来测试和评估SMHPLC算法的性能和复杂度。 表4 8个AVS2屏幕与混合内容视频编码通用测试序列 图5 SMHPLC算法编码流程 每个序列有RGB和YUV两种色彩格式。实验的硬件环境为Intel(R) Xeon(R) CPU X5460 @3.16 GHZ。 实验比较了传统的LZ4HC算法,在其基础上实现的SMHPLC算法,zlib算法和LZMA算法之间的性能和复杂度(使用HEVC标准制定工作组和AVS标准制定工作组规定的编解码运行时间来衡量复杂度)。 表5和表6是两种色彩格式下SMHPLC算法和传统的LZ4HC算法在相同的搜索Level下总体的压缩后码流比特率、编码时间和解码时间的比较。比较的搜索Level的范围为4至14,随着搜索Level的增加,YUV格式下SMHPLC算法与LZ4HC算法的比特率之比和解码时间之比均逐步减少,虽然编码时间的比值有一定的增大,但SMHPLC算法的编码速度依然远超过LZ4HC算法。RGB格式下这两种算法的比特率之比、解码时间之比、编码时间之比与YUV格式下有相似的变化趋势。LZ4HC本身是一种极低复杂度的算法,YUV格式下SMHPLC算法减少了35.5%~47.5%的编码时间,性能却提高了17.3%~22.4%,RGB格式下减少了45.3%~51.3%的编码时间,性能提升了18.4%~21.2%。同时,SMHPLC算法仍然保持着很快的解码速度,YUV格式下解码时间只增加了15.7%~29.9%,RGB格式下解码时间只增加了14.9%~25.7%。 表5 YUV格式下SMHPLC算法与LZ4HC算法的比较 表6 RGB格式下SMHPLC算法与LZ4HC算法的比较 表4, 表5中不同的搜索Level的LZ4HC算法的平均比特率都不同,从约100 Mbps到130 Mbps不等。实际上,RGB序列FLYG在Level为4时的比特率是342389.7 kbps,而YUV序列CLP在Level为14时的比特率是55120.8 kbps。这些实验结果表明本文的方法对不同比特率的码流都有效。由于对比算法LZ4HC,zlib与本文方法均为无损压缩算法,所以压缩后重建图像都具有与原始图像相同的图像质量。 表7比较了搜索Level为6至9时两种色彩格式下zlib算法与SMHPLC算法之间的编码性能和复杂度。在相同Level下对于YUV和RGB序列,zlib算法总体比特率分别比SMHPLC算法增大2.4%~5.2%与1.3%~5.7%,反而消耗了超过1倍至2倍的总体编码时间,总体解码时间也多出了1倍左右。 表8比较了搜索Level为2的LZMA与搜索Level为12时两种色彩格式下SMHPLC算法之间的编码性能和复杂度。对于YUV序列,LZMA-2算法的总体比特率比SMHPLC-12算法低10.3%,但是需要消耗更多的编解码时间,编码时间增加了178.3%,同时解码时间增加了接近4倍。对于RGB序列,LZMA-2算法的总体比特率只比SMHPLC-12算法低6.4%,但编码时间增加了190.7%,解码时间增加了超过4倍。 表7 zlib算法与SMHPLC算法的比较 表8 LZMA-2算法与SMHPLC-12算法的比较 通过分析屏幕图像的特点,本文提出了基于像素串匹配的SMHPLC算法,在对典型屏幕图像测试序列的Literal Length, Match Length以及Offset这3个匹配参数进行统计和分析的基础上,提出了分类编码的思想对这些参数进行联合优化编码。此外,还引入了参数映射编码。SMHPLC算法不但大幅减少编码复杂度,而且大幅提升了压缩性能,降低了比特率。从实验结果来看,对于YUV序列Level为13时SMHPLC算法对于测试序列的压缩后码流比特率比LZ4HC算法总体降低了22.4%,对于RGB序列Level为12时总体降低了21.2%。SMHPLC算法达到的对屏幕图像的压缩后码流比特率比zlib算法对于YUV和RGB序列分别降低了2.4%~5.2%和1.3%~5.7%,减少的编码时间均超过1/2,同时解码时间也都降低了约1/2。LZMA-2算法虽然在比特率上比SMHPLC-12算法有一定的优势,但是其编解码时间却比SMHPLC算法长很多,特别是对于RGB序列编码时间长190.7%,同时其解码时间也长了超过4倍,但是码流比特率只降低了6.4%。所以SMHPLC算法在高性能低复杂度方面的综合优势是其他算法难以比拟的。 对SMHPLC算法还可以做进一步优化。在降低比特率方面,可以对匹配参数采用编码效率更高的熵编码方案,进一步提高整体编码效率;在降低算法复杂度方面,可以考虑更佳的Chain Table的存储和索引的方式,减少搜索时间。 [1] LIN Tao, ZHOU Kailun, and WANG Shuhui. Cloudlet-screen computing: A client-server architecture with top graphics performance[J]., 2013, 13(2): 96-108. doi: 10.1504/ IJAHUC.2013.054174. [2] 李德毅, 张天雷, 黄立威. 位置服务:接地气的云计算[J]. 电子学报, 2014, 42(4): 786-790. doi: 10.3969/j.issn.0372-2112. 2014.04.025. LI Deyi, ZHANG Tianlei, and HUANG Liwei. A down-to-earth cloud computing: Location-based service[J]., 2014, 42(4): 786-790. doi: 10.3969/ j.issn.0372-2112.2014.04.025. [3] WANG Haiyang, WANG Feng, LIU Jiangchuan,Enabling customer-provided resources for cloud computing: Potentials, challenges, and implementation[J].,2015, 26(7): 1874-1876. doi: 10.1109/TPDS.2014.2339841. [4] SHIRMOHAMMADI S, ABDALLA M, AHMED D T,Introduction to the specialsection on visual computing in the cloud: Cloud gaming and virtualization[J].2015, 25(12): 1955-1959. doi: 10.1109/TCSVT.2015.2473075. [5] 张培君, 王淑慧, 周开伦, 等. 融合全色度LZMA与色度子采样HEVC的屏幕图像编码[J]. 电子与信息学报, 2013, 35(1): 196-202. doi: 10.3724/SP.J.1146.2012.00746. ZHANG Peijun, WANG Shuhui, ZHOU Kailun,Screen content coding by combined full-chroma LZMA and subsampled-chroma HEVC[J].&, 2013, 35(1): 196-202. doi: 10.3724/ SP.J.1146.2012.00746. [6] 陈先义, 赵利平, 林涛. 一种新的用于屏幕图像编码的HEVC帧内模式[J]. 电子与信息学报, 2015, 37(11): 2685-2690. doi: 10.11999/JEIT150261 CHEN Xianyi, ZHAO Liping, and LIN Tao. A new HEVC intra mode for screen content coding[J].&, 2015, 37(11): 2685-2690. doi: 10.11999/JEIT150261. [7] LIN Tao, ZHANG Peijun, WANG Shuhui,. Mixed chroma sampling-rate high efficiency video coding for full-chroma screen content[J]., 2013, 23(1): 173-185. doi: 10.1109/TCSVT.2012.2223871. [8] ZHAO Liping, LIN Tao, ZHOU Kailun,. Pseudo 2D string matching technique for high efficiency screen content coding[J]., 2016, 18(3): 339-350. doi: 10.1109/TMM.2015.2512539. [9] DHAWALE N. Implementation of Huffman algorithm and study for optimization[C]. International Conference on Advances in Communication and Computing Technologies (ICACACT), Mumbai, 2014: 1-6. doi: 10.1109/EIC.2015. 7230711. [10] BARTIK M, UBIK S, and KUBALIK P. LZ4 compression algorithm on FPGA[C]. IEEE International Conference on Electronics, Circuits, and Systems(ICECS), Cairo, 2015: 179-182. doi: 10.1109/ICECS.2015.7440278. [11] ALMEIDA S, OLIVEIRA V, PINA A,. Two High-performance Alternatives to ZLIB Scientific-data Compression. Computational Science and Its applicationsICCSA 2014[M]. Switzerland, Springer International Publishing, 2014: 623-638. [12] SANG D K, LEE S M, SANG M L,. Compression Accelerator for Hadoop Appliance. Internet of Vehicles – Technologies and Services[M]. Switzerland, Springer International Publishing, 2014: 416-423. [13] YANN Collet. LZ4-extremely fast compression[OL]. https:// github.com/Cyan4973/lz4.git, 2016.3. [14] YANN Collet. LZ4 Block Format Description[OL]. https:// github.com/Cyan4973/lz4/lz4_Block_format.md, 2016.3. [15] AVS工作组文件(AVS2-P2 20110149-T-469). AVS2-P2屏幕与混合内容视频编码(S&MCVC)通用测试条件[S]. 2016.3. Documents of AVS2 working group. Common conditions for AVS2-P2 Screen and Mixed Content Video Coding (S&MCVC)[S]. 2016.3. [16] ARTEM Zaytsev. LZ4-r127[OL]. https://github.com/avz/ mysql-lz4.git, 2016.3 . Lossless Compression Algorithm Based on String Matching with High Performance and Low Complexity for Screen Content Coding LIN Tao CAI Wenting CHEN Xianyi ZHOU Kailun WANG Shuhui (,,200092,) Traditional lossless compression algorithms are not efficient for screen content coding. To take the full advantage of special characteristics of screen content, a lossless compression algorithm based on String Matching with High Performance and Low Complexity (SMHPLC) is proposed. It is implemented on the basis of LZ4HC (LZ4 High Compression). The main new ideas are using pixel instead of byte as the basic unit for string searching and matching, adopting joint optimal coding of three parameters of literal length, match length and offset and mapping for three parameters. Experiment results show that SMHPLC has both high coding efficiency and low complexity. Compared to LZ4HC, SMHPLC not only has a coding complexity reduction of 34.6%, 46.8%, but also achieve overall bit-rate saving of 22.4%, 21.2% in YUV, RGB color formats respectively for AVS2 common test sequences in moving text and graphicscategory. Lossless compression algorithm; Screen content coding; Dictionary coding; LZ4High Compression (LZ4HC) TN919.8 A 1009-5896(2017)02-0351-09 10.11999/JEIT160560 2016-05-28;改回日期:2016-11-19; 2016-12-29 蔡文婷 caiwenting@tongji.edu.cn 国家自然科学基金(61601200, 61271096),高等学校博士学科点专项科研基金(20130072110054) The National Natural Science Foundation of China (61601200, 61271096), Specialized Research Fund for the Doctoral Program of Higher Education (20130072110054) 林 涛: 男,1958年生,教授,主要研究方向为多媒体算法和SoC设计. 蔡文婷: 女,1990年生,硕士生,研究方向为视频编码算法. 陈先义: 男,1981年生,博士生,研究方向为视频编码算法. 周开伦: 男,1977年生,博士生,讲师,研究方向为视频编码、屏幕图像编码、多媒体集成电路等. 王淑慧: 女,1973年生,副研究员,研究方向为视频编码、屏幕图像编码等.



3 实验结果




4 结束语
猜你喜欢
销售与市场(营销版)(2021年10期)2021-11-21
销售与市场(营销版)(2019年6期)2019-06-21
中国惯性技术学报(2019年6期)2019-03-04
网络安全技术与应用(2017年9期)2017-09-20
计算机应用与软件(2017年8期)2017-08-12
中央民族大学学报(自然科学版)(2017年2期)2017-06-11
信息安全与通信保密(2016年2期)2016-09-08
火控雷达技术(2016年3期)2016-02-06
浙江理工大学学报(自然科学版)(2015年10期)2015-03-01
郑州大学学报(工学版)(2013年1期)2013-09-13
